融合多尺度边界特征的显著实例分割
2022-08-16张红艳房婉琳
何 丽,张红艳,房婉琳
天津财经大学 理工学院,天津300222
显著性检测是计算机视觉应用中的一项基本任务。因为相对于视线中出现的所有物体,人们往往会更加关注于自己所感兴趣的物体,而感兴趣的物体就是显著物体。显著性检测在目标识别、图像视频压缩、图像检索、图像重定向等中有着重要的应用价值。但是,显著性检测只是能够获得显著性区域的位置,却无法区分出各个实例。实例分割不仅要在实例层级上进行目标的分类和定位,还要在像素层级上得到精确的分割掩码,是一种更接近人类真实视觉感受的计算机视觉任务。但实例分割得到的分割结果是除去背景外的所有物体,这之中包括显著物体和不显著物体。为了实现基于显著性检测的实例识别,Li 等人正式提出显著实例分割的概念。显著实例分割是目前计算机视觉领域中的一个较新的研究方向,其目的在于检测出图像中的显著物体,并对各个显著物体进行像素级的分割。最近,Fan 等人提出的S4Net(single stage salient-instance segmentation)利用了目标对象和其周围背景的特征分离能力,提出了基于区域特征提取层ROIMasking 的显著实例分割。但是,为了对图像进行深层次的特征提取,卷积神经网络会进行多次的卷积和池化操作,使得到的特征图尺寸与输入图像相差数倍,再经过上采样操作恢复到原尺寸后,会造成目标对象细节信息或边界信息的丢失,从而导致目标对象的边界分割粗糙,整体分割效果变差,并最终影响分割的精确度。
上述方法未充分考虑到实例的边界信息对分割结果影响,为了解决此问题,本文在S4Net 模型的基础上,提出了一种新的结合实例边界特征提取的端到端显著实例分割方法(salient instance segmentation via multiscale boundary characteristic network,MBCNet)。该方法借鉴了在边缘检测和语义实例分割的思想,在S4Net 的基础上并行设计了一个多尺度融合的边界特征提取分支,以更好地提取实例边界的特征信息,实现了将边界特征信息与显著性实例分割的有效整合;为实现在同一网络中并行训练目标实例的边界特征提取和显著实例分割两个任务,在MBCNet中设计了一个边界-分割的联合损失函数。为验证MBCNet 的先进性,本文在saliency instance 数据集上将MBCNet与目前主要的显著实例分割方法进行了实验比较。实验结果显示,MBCNet 在mAP和mAP两个评估指标上均获得了明显优势。本文的贡献主要体现在以下三方面:
(1)将目标实例的边界特征提取整合到了实例分割模型中,设计了一个多尺度融合的边界特征提取分支,该分支以基础网络中F3、F4 和F5 三个层次的特征作为输入,并通过与实例分割分支联合训练的方法实现对实例多尺度特征的有效融合。
(2)针对边界特征提取分支,提出了带有混合空洞卷积和残差网络结构的边界细化模块,该模块在训练中可以学习到实例不同层次的特征,获得更加丰富的实例边界信息。
(3)针对训练过程中目标实例的边界特征提取和显著实例分割任务,提出了一个边界-分割联合损失函数,通过共享特征层将边界特征提取分支学习到的实例边界信息传递到分割网络中,使得在同一深度网络中,能同时实现实例边界特征提取和显著实例分割两个任务。
1 相关工作
1.1 实例分割
实例分割任务既要完成目标检测中的定位任务,又要尽可能做到像素级的分类准确。实例分割方法目前也主要分为两大类:两阶段实例分割和单阶段实例分割。两阶段实例分割方法主要包括自下而上的基于语义分割的方法和自上而下的基于检测的方法。自下而上的分割思路是首先进行像素级别的语义分割,然后通过聚类和度量学习等手段进行实例识别。这种方法的泛化能力较差,在类别多的复杂场景中性能不佳。自上而下的方法则需要先在图像中产生目标候选框,然后对候选区域做分类与回归。而实现目标候选框提取的模型代表为Faster R-CNN,该模型使用区域选择网络(region proposal network,RPN)取代选择性搜索(selective search)来产生候选框,真正实现了端到端的训练,大大减少了计算量,并在时间和精度上获得了较大提升;Mask RCNN在Faster R-CNN 网络基础上添加了一个分割分支,提出了使用ROIAlign 方法来替代ROIPooling,并取消了两次取整操作,使得分割精度得到进一步提升。但相对于输入图像,分割分支处的特征图会进行多次的下采样操作,导致分割边界产生锯齿状,非常不利于对实例边界的预测。单阶段实例分割受单阶段目标检测的启发,具有速度优势。Bolya等提出的YOLACT模型具有最大的优势就是实时性,它将实例分割任务拆分成两个并行的任务:首先通过一个Protonet 网络,为每张图片生成一组不依赖于任何实例的原型掩码;然后对每个实例预测其线性组合系数,并通过线性组合生成实例掩码。Xie等提出的PolarMask 模型参考了FCOS(fully convolutional onestage object detection)模型的设计思想,用极坐标的方法将实例分割任务转化为实例中心的分类和密集距离回归的问题,因为极坐标是由距离和角度确定的,所以可以很好地利用极坐标的方向优势获得物体的轮廓。
单阶段方法在计算速度上优于两阶段,分割精度也在逐渐逼近两阶段,甚至有赶超的趋势。但由于实例分割任务中不是所有类别和物体都是显著的,相较于本文任务,仍存在很大的不同。
1.2 显著实例分割
显著实例分割的概念是由显著性检测扩展而来,显著性检测是通过检测到图像中最显著的物体,并将它们从中分割出来的一项任务。早期的显著性检测主要分为两种:自底向上学习模型和自顶向下学习模型。这些模型主要根据图像的颜色、亮度、纹理等特征,基于局部或全局对比度来进行学习。之后Liu 等将机器学习算法应用于显著性检测任务中。近年来,基于卷积神经网络(CNN)的深度学习在显著性检测中表现出明显的优势,Li等提出的基于多尺度深度特征(multiscale deep features,MDF)的显著性检测算法通过对输入图像分别进行被考虑区域、相邻区域和整个图像三个尺度的特征提取,将获得的三个卷积神经网络与具有两个全连接层的深度神经网络相结合,实现了多尺度信息的提取与融合;Zhao 等利用CNN 提取出超像素局部和全局上下文特征,对图像进行单尺度分割,然后通过卷积神经网络的分类与回归,实现对图像的显著性检测。为了解决显著目标不完整的问题,于明等提出基于多图流形排序的显著性检测算法。根据超像素的颜色和空间特征,分别构造K 正则图和KNN 图,利用流形排序算法计算得到显著性值。常振等在传统基于贝叶斯模型的显著性检测基础上,提出一种结合图像背景先验和凸包先验的多尺度显著性检测算法,通过超像素分割将原图分割成不同尺度的超像素进行融合,有效减少噪声和冗余,使得显著区域更为明显。卢珊妹等提出多特征注意力循环网络进行显著性检测,利用空洞卷积和注意力机制来进行多尺度特征提取与融合。
显著性检测只关注于显著性目标区域的检测,属于二元问题,而显著实例分割则需要在其基础上,得到显著物体的像素级实例识别与分割。因此,Li等正式定义了显著实例分割任务,并提出了MSRNet(instancelevel salient object segmentation)模型。该模型利用多尺度深度网络得到显著区域图(salient region map)和显著物体轮廓图(salient object contour map),然后依次经过MCG(modified conjugate gradients)和MAP(mean average precision)方法对轮廓图进行计算,从而获得更加精确的显著物体建议框。因为显著物体建议框和显著区域存在一定的差异,于是使用条件随机场(conditional random field,CRF)方法对两者的差异点进行多分类,最终得到显著实例的分割结果。但MSRNet 高度依赖于轮廓图和后期获得的实例建议框,且计算量大。
之后,Fan等人提出了一个端到端单阶段的显著实例分割网络S4Net。与实例分割中使用ROIPooling和ROIAlign方法提取建议框内的特征信息有所不同,S4Net模型借鉴了GrabCut的思想,利用目标对象和其周围背景的特征分离能力,提出了基于区域特征提取层ROIMasking 的显著实例分割方法。其中,二值ROIMasking通过检测分支获得特征图和建议区域,并为建议区域生成二值掩膜,然后通过扩张得到二值ROIMasking 的扩张建议区域。与二值ROIMasking相比,扩张后的区域能够获得更多的背景信息,从而使分割分支具有更大的感受野。为了更好利用兴趣区域周围的背景信息,S4Net 通过将感兴趣区域周围的掩码值设置为-1,将二值ROIMasking 升级为三元ROIMasking,使分割分支能够更好地识别建议框之外的背景。但是,S4Net 存在与Mask R-CNN 模型类似的问题,即深度网络中的多次卷积和下采样会使实例边界分割不平滑,从而导致整体分割效果差。
最近,Pei 等人提出了一种新的MDNN 模型,该模型框架是无提案、无类别的。MDNN 模型使用密集连接的子区域化网络(densely connected subitizing network,DSN)对子区域进行预测和计数,使用密集连接的全卷积网络(densely connected fully convolutional network,DFCN)进行显著区域检测,然后基于得到的子区域计数和显著区域,采用基于自适应深度特征的谱聚类算法对显著区域进行分割,得到最终的显著实例。
1.3 边缘检测
边缘检测主要分为传统方法和基于深度学习的方法。传统方法大多是利用图像的底层特征如颜色、纹理、亮度差异来进行边缘的判断与切分,如传统的检测算子Sobel、Canny等;基于信息理论设计的手工特征SCG(sparse code gradients)、gPb(globalized probability of boundary)等。传统边缘检测方法大都依赖于人为设置的经验值,存在很大的局限性。深度学习因其自身强大的学习能力,对图像信息进行像素级到语义级的信息提取,可以更好地获取细节到全局的信息,明显优于传统方法。Xie 等提出的整体嵌套边缘检测(holistically-nested edge detection,HED),通过全卷积神经网络和深度监督网络来进行图像到图像的预测,解决了端到端的训练和多尺度的特征学习问题。Yang 等借鉴全卷积网络在语义分割任务中的应用思想,提出了一个全卷积编解码网络(object contour detection with a fully convolutional encoder-decoder network,CEDN),该网络使用编码-解码的卷积神经网络架构进行物体轮廓的提取,用VGG16 初始化编码器,解码器采用交替的池化层和卷积层组合而成。CEDN 可以支持任意尺寸的图像输入,且相比于底层边缘检测,更加侧重于高层目标轮廓的检测。因为CNN 下的实例分割往往存在边界模糊和准确度低的问题,董子昊等在HED 的基础上,提出多类别边缘感知的图像分割方法。其中利用亚像素的图像增强算法来实现多尺度的特征融合,构建出用于边缘检测深度多尺度编解码模型,从而获得更加精确的边缘特征。
2 MBCNet显著实例分割模型
为了改进显著实例分割中存在的边界分割粗糙问题,提升显著实例分割的精度,本文在基准方法S4Net 的基础上,提出一种融合多尺度边界特征的端到端显著实例分割方法(MBCNet)。该方法利用边缘检测思想,通过设计一个目标实例的边界特征提取分支,结合带有混合空洞卷积和残差网络结构的边界细化模块来促进实例边界信息的提取。该方法可以在同一深度神经网络框架下同时完成目标实例的边界特征提取和显著实例分割任务,并利用提出的边界-分割联合损失函数,将提取到的边界特征通过网络共享层传递到分割分支中,以此来进行网络的训练。
MBCNet 主要由基础网络和三个主要的分支网络组成,整体网络框架图如图1 所示。在图1 中,基础网络选用ResNet50+FPN 模型作为主干结构进行特征提取。ResNet50+FPN输出的5个有效特征层,能够为后续各分支提供不同尺度的特征信息。MBCNet的三个分支分别是:显著实例定位分支、显著实例分割分支和目标实例的边界特征提取分支。显著实例定位分支采用单阶段目标检测方法,对图像中的显著实例进行定位;显著实例分割分支采用S4Net 中的实例分割分支,实现对显著实例的像素级分割;目标实例的边界特征提取分支是本文提出的一种新的多尺度融合的边界特征提取分支,该分支通过带有混合空洞卷积和残差网络结构的边界细化模块来提取实例的边界特征信息,并通过网络共享层进行边界信息的传递。
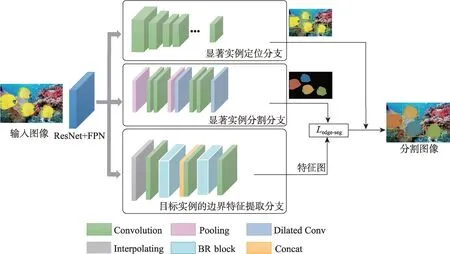
图1 MBCNet的网络结构Fig.1 Network structure of MBCNet
2.1 目标实例的边界特征提取分支
由于不同实例的大小和位置关系的不同,现有的实例分割任务中分割的结果仍存在实例边界不光滑等问题。而现有基于深度学习的边缘检测主要使用编码器-解码器(encoder-decoder)结构的边缘检测算法。该类算法利用深度神经网络中的卷积、池化等操作所构成的编码器对输入图像的像素位置信息和图像特征信息进行编码,然后利用反卷积或上采样等操作所构成的解码器来还原图像的语义信息和像素的位置信息。借鉴于边缘检测任务的实现思想,本文在ResNet50+FPN 基础网络完成初步特征提取的编码部分的基础上,构建了一个新的目标实例的边界特征提取分支,用来完成边界特征提取的解码部分,以更好地实现对目标实例边界特征的细化处理。为了更清晰地获取目标实例的边界特征,边界特征提取分支融合了多个边界细化模块。关于边界细化模块的具体介绍见2.2 节,边界特征提取该分支的具体网络结构如图2 所示。
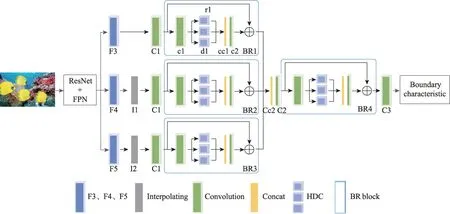
图2 边界特征提取分支的网络结构Fig.2 Network structure of boundary feature extraction branch
为了进一步融合图像的空间和语义信息,并使模型在不过多增加计算压力的同时,能够学习到多尺度的特征信息,本文选取基础网络ResNet50+FPN的F3、F4 和F5 三个特征层作为边界特征提取分支的输入。MBCNet通过对F4 和F5 两个高层特征图分别进行双线性插值(I1、I2)来调整特征图尺寸,使得插值后和低层特征图F3 保持相同的分辨率,以便于后续对不同层次的特征图进行信息融合。然后分别通过普通卷积(C1)操作后送入边界细化模块(BR1、BR2、BR3)。经过边界细化模块处理的特征层首先采用级联(Cc2)操作,对多尺度的边界特征进行信息整合,然后使用一个1×1 的卷积(C2)进行信道压缩,使信息整合后的特征层通道数变为64;将整合后的特征层再次送入边界细化模块(BR4)中,以一个更全面的感受野来提取特征的整体信息;最后通过一个卷积核为3×3、通道数为1 的卷积(C3)得到目标实例的边界特征结果。具体的目标实例的边界特征提取分支的各层参数如表1 所示。
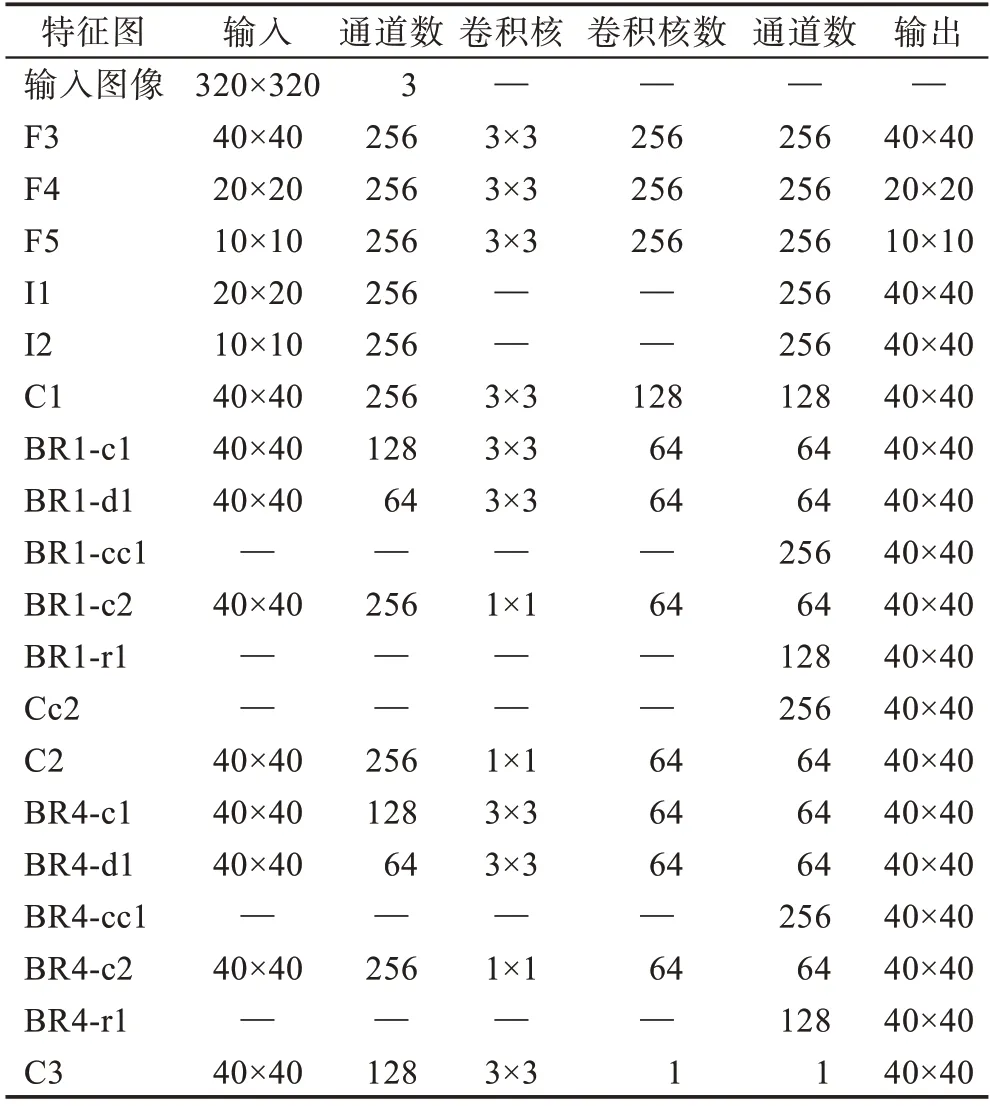
表1 目标实例的边界特征提取分支各层参数Table 1 Parameters of each layer of boundary feature extraction branch of target instance
目标实例的边界特征提取分支不仅可以很好地利用基础网络输出的特征中所包含的实例边界信息,而且经过多次边界细化模块的学习,可以有效增大特征的感受野,更好地获得实例细节处的边界特征。同时,边界特征提取分支和显著实例分割分支可以同时进行训练,并将各自学习到的特征信息通过网络共享层进行信息融合。边界特征提取分支将学习到的实例边界特征送回网络共享层,在网络共享层实现实例边界权重信息的更新,使得显著实例分割分支不仅能够通过自身网络结构学习到实例的整体特征信息,还能够利用边界特征提取分支学习到的实例边界特征信息,进一步提升显著实例分割任务的分割精度。
2.2 边界细化模块
目前的实例分割方法在实例的整体分割精度上已经获得了很大提升,但在实例边界的分割上仍不尽如人意。因此,受到文献[25]的启发,为了获得更加完整的目标实例边界特征,本文构建了边界细化模块(boundary refinement block,BR block),具体结构如图3 所示。
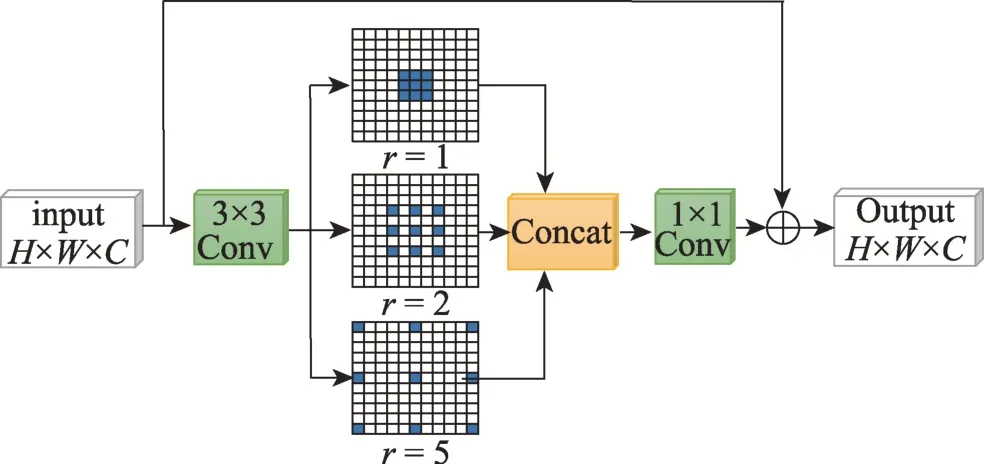
图3 边界细化模块结构Fig.3 Structure of BR block
边界细化模块采用残差网络结构,首先使用一个3×3 的普通卷积进行初步的特征提取,然后利用ReLU 激活函数滤掉其他冗余信息;为了获得不同范围的特征信息,在边界细化模块中使用3 种不同感受野的卷积核组合而成的混合空洞卷积(hybrid dilation convolution,HDC)来对特征图进行边界信息的提取;最后通过残差结构将原始输入的特征图与经过卷积等一系列操作后的特征图进行维度拼接与特征融合,在提升特征提取精度的同时,可以获得丰富的实例边界特征信息。
相比使用普通卷积造成的感受野范围有限,并且如果增大感受野则必须增大卷积核,使得计算量增加,而连续使用相同空洞率的空洞卷积会造成网格(gridding)效应等问题。混合空洞卷积可以在不改变卷积参数量的前提下,通过增大空洞率来提升卷积核的感受野。同时,混合空洞卷积的特征提取能够覆盖所有的像素点,可以提取到不同尺寸实例的特征,能够获得目标实例在整个图像上更远距离的上下文信息,得到更加细致的边界特征。因此,本文使用了一个空洞率=[1,2,5],核大小为3×3 的混合空洞卷积,通道数均为64,分别进行不同空洞率的空洞卷积后,再利用一个1×1 卷积进行特征融合,特征融合方法如式(1)所示。
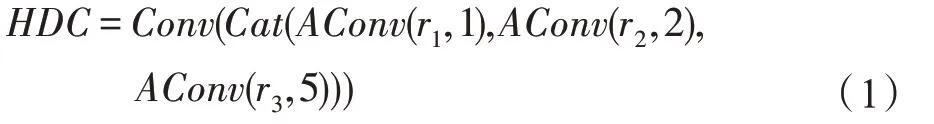
其中,(·)为普通卷积;(·)为完成通道数的叠加;(,)是空洞率=的空洞卷积。
边界细化模块可以让分割网络更加关注实例的边界特征,更好地实现实例整体与边界的拟合。
2.3 损失函数
针对图1 描述的显著实例定位、显著实例分割和目标实例的边界特征提取三种不同的学习任务,这里分别使用由分类损失、回归损失、边界-分割损失构成的多任务损失函数来联合训练模型,并将模型总的损失函数定义如式(2)所示:

其中,为分类损失;为回归损失;为边界-分割联合损失。
使用S4Net 中的定义,计算方法如式(3)所示。在显著实例定位分支中,由于负样本数通常远多于正样本数,式(3)通过分别计算正样本和负样本的损失来避免在训练过程中损失函数被负样本支配的问题。
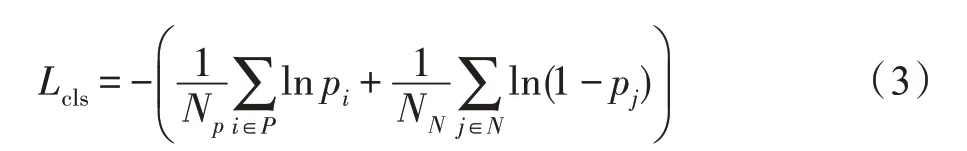
采用Fast R-CNN中的平滑L1 损失函数,计算方式如式(4)和式(5)所示。

目标实例的边界特征提取分支的作用是通过网络中的特征共享层将学习到的实例边界特征信息传递到实例分割分支中,以达到提升边界分割效果的作用。根据分支的结构,这里为显著实例分割和目标实例的边界特征提取双分支训练定义了一个新的联合损失函数,其计算方法如式(6)所示。为了更好地权衡显著实例分割和目标实例的边界特征提取对分割结果的影响,引入一个比例系数(0 ≤≤3)。

在式(6)中,为显著实例分割分支的损失函数,采用的是Mask R-CNN中使用的交叉熵损失函数;为目标实例的边界特征提取分支的损失函数,定义为预测边界和真实边界之间的均方误差,计算方法如式(7)所示。

3 实验与分析
3.1 实验数据集
本文实验使用的数据集选取的是Li 等提出的专门用于显著实例分割任务的数据集saliency instance,数据集中的图像主要选自数据集DUT-OMRON、ECSSD、HKU-IS、MSO,大都含有多个显著目标,其中多个目标可能是分离的,也可能是相互遮挡的。该数据集最初收集了1 388 张图片,由3 名人工标注者进行标注。为了减少标签不一致对训练结果的影响,最终选择1 000 张具有相同标注结果的高质量显著实例图像。本文以这1 000 幅图像作为实验数据集,随机选取500 张图片用于训练,200 张用于验证,300 张用于测试。
3.2 实验环境和评价指标
实验的硬件环境为NVIDIA Quadro K1200,训练时的初始学习率设置为0.002,权重衰减为0.000 1,动量为0.9。实验在一个GPU 上共训练40 000 次迭代。实验基于Tensorflow 框架,以ImageNet 训练的ResNet-50 模型为预训练模型。
实验评价指标使用不同IoU 阈值下的平均精度均值(mAP)来进行模型性能评估和相关实验比较。mAP 采取COCO 数据集定义的计算方法,且算法中的IoU 采用掩膜IoU,计算方式如式(8)和式(9)所示。其中,表示一张图片中显著实例的个数,表示数据集中图片的总数量。以mAP为例,表示使用IoU 是否大于0.5 来确定预测的掩膜在评估中是否为阳性,其余IoU 阈值的指标表示方法相同。这里主要使用实例分割研究中常用的mAP和mAP两个评价指标对MBCNet的有效性进行评价。
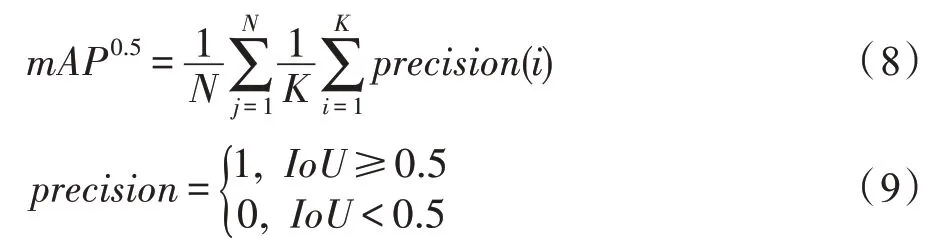
3.3 实验结果分析
实验对比主要从相关模型的mAP 指标、实例分割结果可视化、不同实例个数对分割结果的影响等方面进行,将本文提出的MBCNet与显著实例分割领域目前表现较好的MSRNet、S4Net 和MDNN 进行实验对比。由于MSRNet 和MDNN 的模型没有提供可复现的代码,且MBCNet 模型是在S4Net 的基础上提出的,这里对MSRNet 和MDNN 的实验结果比较仅限于mAP 指标。以下对比实验中,不做特殊说明时,MBCNet中联合损失函数的比例系数取值均为1。
由于显著实例分割是一个较新的研究任务,目前关于显著实例分割模型的研究并不多。在显著实例分割领域有较好表现的模型主要有Li 等提出的MSRNet,Fan 等提出的S4Net 和Pei 等提出的MDNN。因此,这里将MBCNet分别与这三个模型进行实验对比,结果如表2 所示。
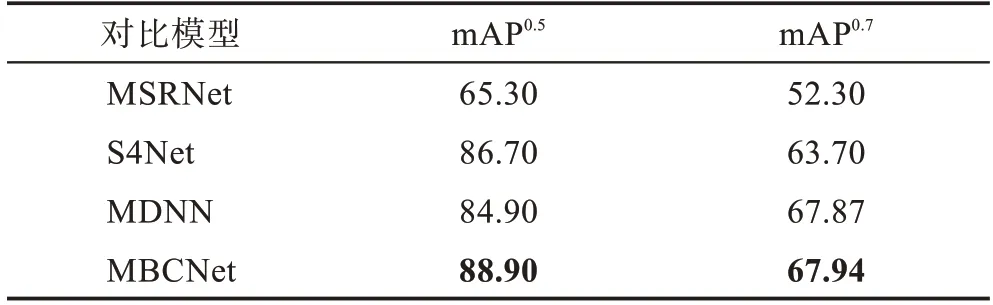
表2 不同模型的实验结果对比Table 2 Comparison of experimental results of different models %
通过表2 对比可以看出,本文提出的MBCNet 在mAP和mAP两个评估指标上均获得了明显优势。其中,在mAP、mAP上较MSRNet 分别提升了23.60 个百分点、15.64 个百分点,较S4Net 分别提升了2.20 个百分点、4.24 个百分点,较MDNN 分别提升了4.00 个百分点、0.07 个百分点。而且,在训练时间上,S4Net 训练整个网络共花费3.97 h,MBCNet 的训练时间为4.5 h。虽然MBCNet 的训练时间与S4Net相比有一定提升,但MBCNet在额外增加了边界特征提取分支网络的前提下,模型训练时间提升的幅度有限,并且在测试方面,MBCNet 仍能保证和S4Net一样的速度,0.148 s可以完成对一张图片的分割。
由此表明,MBCNet 中的目标实例的边界特征提取分支和带有混合空洞卷积和残差网络结构的边界细化模块的引入对提升显著性实例分割的准确率起到了很好的提升作用,但在模型训练时间上增加的开销有限。
为了更好地说明MBCNet 中的实例边界特征提取分支对显著实例分割的贡献,这里选择了测试集中部分图像的分割结果与目前表现较好的S4Net 分割结果进行了比较,对比结果如图4 所示。

图4 分割结果的可视化对比Fig.4 Visual comparison of segmentation results
从图4 结果对比可以看出,S4Net 模型的分割结果中出现了显著物体定位错误(A、D)、边界分割模糊不准确、存在多余分割(B)、实例分割存在部分缺漏(C、D)和实例分割不连续(E)等现象。而MBCNet的分割结果相对较好,无论是多个目标是相互分离的,还是存在相互遮挡,MBCNet 都能更好地进行区分,实例边界更加清晰,分割效果也更加完整。这主要是因为边界特征提取分支的引入,使得模型在显著性物体定位时能够获得更加完整的实例边界信息。并且,混合空洞卷积的边界细化模块也提升了模型对实例细节的处理能力,让目标实例的边界和细节更加清晰、细致,使分割出来的实例更加完整。
为了进一步说明MBCNet 在分割实例边界细节上的良好表现,图5 展示了MBCNet 和S4Net 在分割显著实例边界细节处的结果对比。仔细观察图5 可以发现:在A 组图中,S4Net 对动物的腿部只分割出了一部分,而MBCNet可以将动物的腿部完整地识别出来;在B 组图中,MBCNet 对人的脚部轮廓划分更加完整;在C 组图中,S4Net 对人的整个手肘和小臂造成了遗漏,而MBCNet能够更好地将人的手肘和小臂分割出来。

图5 边界细节划分的结果对比Fig.5 Comparison of boundary detail partition
总体来说,在MBCNet 模型中,通过网络共享层可以将边界特征提取分支学习到的目标实例边界信息传递到实例分割分支中,使得分割任务在关注实例整体特征的同时,还能关注到其边界和细节处的特征信息,进而能够更清晰地识别目标实例的边界,提升目标实例的分割完整性,最终达到提高模型分割效果的目的。
表3 展示了S4Net和MBCNet对不同实例个数的图像分割所得到的不同分割结果。从表3 可以看出,随着图像中实例个数的增加,两种方法的分割性能都呈下降趋势。但是,MBCNet 在mAP指标下完全优于S4Net,并且在mAP指标下,当实例个数不大于2时,MBCNet的分割效果优于S4Net。因此,可以验证本文提出的MBCNet,不论在稀疏显著实例还是密集显著实例的分割场景下,都能保持良好的分割性能。
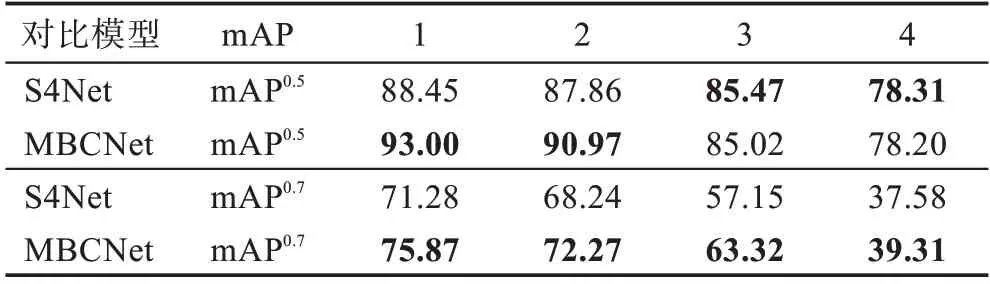
表3 不同实例个数的分割结果对比Table 3 Comparison of segmentation results with different number of instances %
为了获得最佳的多尺度融合效果,实验中对基础网络输出的5 个特征层按顺序进行了不同尺度的融合实验,结果如表4 所示。
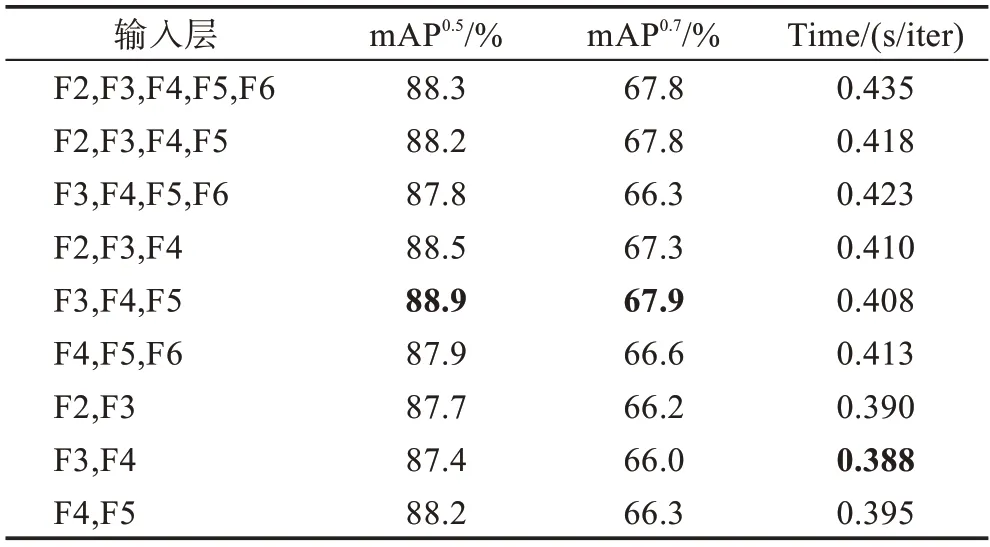
表4 多尺度融合策略对分割结果的影响对比Table 4 Comparison of effects of multi-scale fusion strategies on segmentation results
从表4 中可以看出,当边界特征提取分支输入的特征层数大于3 时,模型在mAP和mAP两个指标上获得了相对较好的结果,但每次迭代训练的时间会随着特征层数的增加而增加;当输入的特征层数为2 时,虽然模型迭代训练的时间减少了,但模型在mAP和mAP两个指标上的值也有不同程度的下降,这说明输入特征层数过少会导致目标实例边界特征信息的丢失;当输入的特征层数为3 时,F3、F4、F5三个特征层的融合(MBCNet)获得了最好的分割效果和时间效率。另外,从实验结果的比较中可以看出,最底层的F6对边界特征信息提取的贡献并不明显。
为了验证边界细化模块在MBCNet中的有效性,本文在保持模型其他部分不变的基础上,对边界细化模块在边界特征提取分支上的各种组合分别进行了实验。其中,Base 表示边界特征提取分支中不使用边界细化模块,Base+BR1+BR2+BR3 表示仅对基础网络的F3、F4 和F5 三个特征层边界信息提取使用边界细化模块,Base+BR4 表示仅对融合后的多尺度信息使用边界细化模块,Base+BR1+BR2+BR3+BR4表示对三个特征层和融合后的多尺度信息均使用边界细化模块,实验结果如表5 所示。
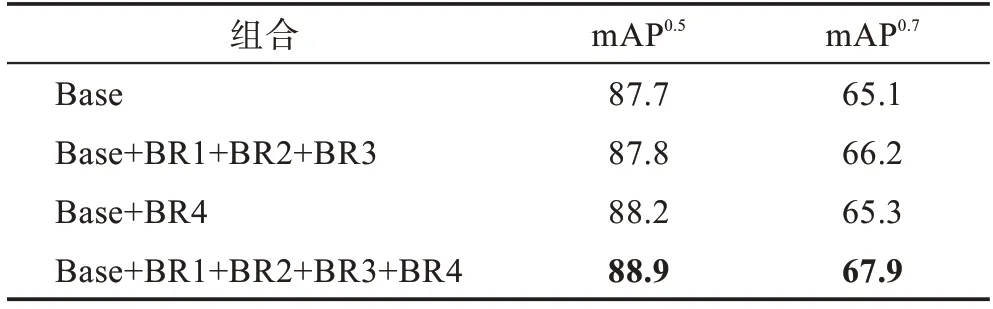
表5 边界细化模块各种组合的实验结果对比Table 5 Comparison of experimental results of various combinations of BR block %
从表5 中可以看出,Base+BR1+BR2+BR3+BR4在mAP和mAP两个指标上的结果最好,并且Base+BR1+BR2+BR3 和Base+BR4 在两个指标上的结果均优于Base,这说明边界细化模块在边界特征提取分支中的使用可以进一步提升模型的显著实例分割效果。为了最大化边界细化模块的作用,本文提出的MBCNet 模型将BR1、BR2、BR3、BR4 同时增加到边界特征提取分支中,获得了最佳的显著实例分割效果。
为了验证边界细化模块中的混合空洞卷积和残差结构在MBCNet中的有效性,本文分别构建了不使用残差结构和不使用混合空洞卷积的网络结构,并将其记作MBCNet_noResidual 和MBCNet_noHDC。在MBCNet_noHDC 中,使用普通卷积替代混合空洞卷积,除此之外,其他所有训练参数、训练的方法和迭代次数均保持一致,结果如表6 所示。
从表6 中可以看出,在mAP和mAP两个评估指标上,MBCNet 均优于MBCNet_noHDC 和MBCNet_noResidual,这说明使用混合空洞卷积和残差结构能够达到提升分割效果的目的。混合空洞卷积可以在不增加额外计算量的情况下,扩大感受野,为边界特征提取分支提供更完整的边界上下文信息,减少学习过程中的有用信息丢失。残差结构的使用可以实现输入特征信息和卷积等特征提取操作后的特征层信息的有效融合,为目标实例的边界特征提取提供更加丰富的有用信息。残差网络结构的引入虽然增加了少量的训练时间成本,但可以使模型的分割效果获得较大幅度的提升。
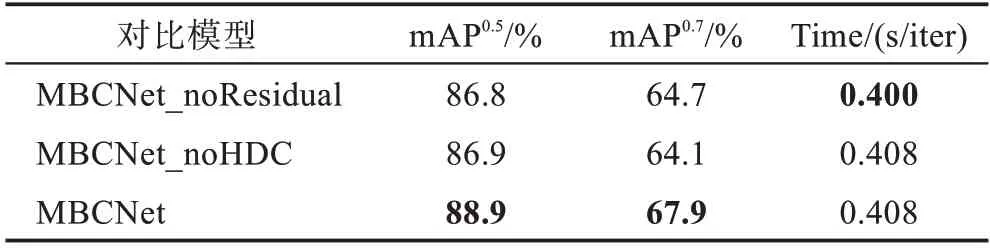
表6 混合空洞卷积和残差结构对分割结果影响对比Table 6 Comparison of influence of HDC and residual structure on segmentation results
为了更进一步说明混合空洞卷积对边界特征提取的有效性,图6 展示了混合空洞卷积对分割结果的影响。左列展示的是MBCNet的分割结果,右列展示的是MBCNet_noHDC 的分割结果。

图6 MBCNet和MBCNet_noHDC 的分割结果的可视化对比Fig.6 Visual comparison of segmentation results between MBCNet and MBCNet_noHDC
从图6 中可以看出:在A 组左图中,人和狗的整体和边界进行了很好的区分,而右图则视为一体,这表明混合空洞卷积可以很好地将密集的实例区分开来;B、C 组左图中因为混合空洞卷积自身有着可以增大感受野范围的优势,所以对于图像中较大尺寸的目标实例会产生较为显著的分割效果,而右图中没有混合空洞卷积支撑的MBCNet_noHDC 则无法以一个较为全面的感受野来进行实例的整体识别,导致了分割结果的不连续和存在部分缺失的情况;D 组图中虽然两个模型都将挨着的两朵花区分开来,但MBCNet 因为可以对细节进行更好的处理,所以在两朵花的连接处它表现出了边界细节特征提取的优势,获得了更佳的分割效果;在E 组图中,左图的MBCNet 对小尺寸目标实例的特征提取更加完整,相比右图MBCNet_noHDC 来说得到了更好的整体和边界的分割效果。
3.3.7 联合损失函数中的取值分析
本文在设计联合损失函数时,定义了一个比例系数,用来权衡显著实例分割分支和边界特征提取分支对学习结果的影响。为了获得最佳的值,这里对的取值进行了对比实验,实验结果如图7所示。
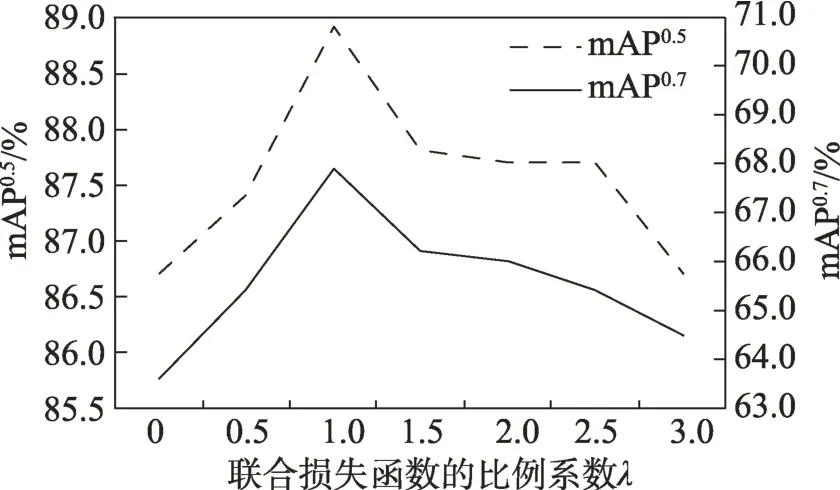
图7 联合损失函数中λ不同取值的结果对比Fig.7 Comparison of different values of scale factor λ of joint loss function
从图7 中可以看出,从0 开始增加的值,模型在mAP和mAP两个指标上的值均呈上升趋势;当=1.0 时,模型在这两个指标上的值均达到了最高;之后随着值的增加,mAP和mAP两个指标的值逐渐下降。这说明,值的变化对模型的性能会产生不同程度的影响,同时也说明本文提出的边界特征提取分支和联合训练方法对模型的性能具有重要影响。
为了说明本文提出的边界-分割联合损失函数的作用,这里分别比较了在S4Net 的实例分割分支中使用的、在MBCNet 的显著实例分割分支和目标实例的边界特征提取分支中分别使用的和,以及使用边界-分割联合损失函数的mAP和mAP,结果如表7 所示。
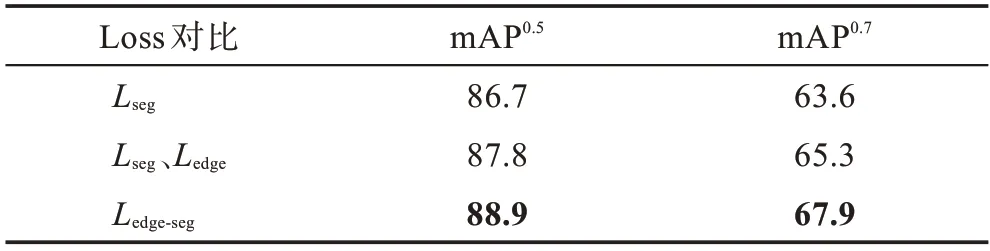
表7 不同组合的损失函数结果对比Table 7 Comparison of loss function of different combinations %
从表7 的结果对比可以看出,使用本文提出的边界-分割联合损失函数获得了最好的分割效果。这表明边界特征提取分支在联合损失函数的监督下,能够通过网络中的特征共享层将学习到的实例边界特征信息传递到实例分割分支中,进一步提升分割质量。
4 结束语
本文充分考虑到边界特征对实例分割结果的影响,提出一种结合实例边界信息的端到端显著实例分割方法MBCNet。在MBCNet 设计了一个多尺度融合的边界特征提取分支,使用带有混合空洞卷积和残差网络结构的边界细化模块来获得更加完整的实例边界特征信息和实例细节信息,并通过网络共享层实现实例分割过程中边界特征和语义特征的有效整合。为了实现在同一个网络中同时完成实例分割和边界特征提取两个任务,在MBCNet构造了一个边界-分割的联合损失函数。实验结果表明本文方法在显著性实例分割任务中的有效性,验证了实例边界特征提取分支的引入可以进一步提升显著性实例分割的准确率。本文方法在mAP和mAP分别达到了88.90%和67.94%,高于同任务模型S4Net上的结果。
