高光谱成像结合模式识别无损检测猕猴桃成熟度*
2022-08-12尚静黄人帅张艳张书琴孟庆龙
尚静,黄人帅,张艳,张书琴,孟庆龙
(1. 贵阳学院食品与制药工程学院,贵阳市,550005; 2. 贵阳学院农产品无损检测工程研究中心,贵阳市,550005)
0 引言
“贵长”猕猴桃产自贵州省修文县,其果肉细嫩且多浆、果汁酸甜爽口,深受广大消费者的青睐[1]。猕猴桃属于后熟水果,为了延长果子贮藏时间,果农经常采摘还没有完全成熟的果子,但是如果采摘太早,果子过于生硬不仅会影响口感而且果子容易受冷害[2]。
通常水果成熟度的传统判别方法有:专业人员凭借经验判别,或者通过测量水果的可溶性固形物含量(soluble solids content,SSC)来判别。然而这些方法的缺陷包括人工判别误差较大,利用折射仪测量SSC不仅破坏样本而且很难实现批量检测。因此,开展水果成熟度的无损检测对于指导确定采收时期以及采后贮藏具有非常重要的意义。近几年,基于高光谱成像的快速无损检测方法具有不破坏检测对象、检测速度快、无污染等诸多优势,受到国内外广大科研学者的关注,已被广泛地应用于水果品质的无损检测领域[3-8]。目前,世界各地研究人员已开展了关于苹果[9-10]、香蕉[11]、猕猴桃[5, 12-13]、桃子[14]、李子[15]、梨[16-17]以及草莓[18]等水果品质的无损检测,并取得了一定的成果。Li等[7]利用高光谱成像技术结合线性判别分析(Linear discriminant analysis,LDA)构建了樱桃成熟度识别模型,其正确识别率达到了96.4%。邵园园等[19]采用高光谱成像技术结合人工神经网络实现了对肥城桃成熟度的预测,结果表明:基于前向选择算法优选的特征波长构建的识别模型对肥城桃成熟度的识别正确率为98.3%。而对于“贵长”猕猴桃成熟度的无损识别却鲜有报道。
本文利用可见/近红外高光谱成像系统采集不同成熟阶段“贵长”猕猴桃的高光谱图像;然后分别比较3种光谱预处理方法(二阶导数、标准正态变换以及多元散射校正)对原始光谱的预处理效果;最后采用偏最小二乘判别分析(Partial Least Square Discrimination Analysis,PLS-DA)方法和简化的K最近邻法(Simplified K Nearest Neighbor,SKNN)构建判别“贵长”猕猴桃成熟度无损识别模型,以期为开发“贵长”猕猴桃成熟度的无损识别装备奠定一定的理论基础。
1 材料与方法
1.1 试验材料
“贵长”猕猴桃于2019年9—10月采摘于贵州省修文县龙关口猕猴桃果园,随机从不同的果树上采摘不同成熟阶段(Ⅰ:9月17日采摘,Ⅱ:9月28日采摘,Ⅲ:10月7日采摘,Ⅳ:10月19日采摘)的猕猴桃果子,其SSC分布分别为Ⅰ:5.1%~5.5%,Ⅱ:5.6%~7.0%,Ⅲ:7.1%~9.0%,Ⅳ:9.1%~11.6%。每个成熟阶段的猕猴桃果子采摘100个,共采摘400个完好无损的样本。样本采摘后马上送到实验室,用软纸轻轻地擦掉样本表面的灰尘,对其依次编号后,在室温(22±2)℃条件下进行实验。采用Kennard-Stone算法[20]将400个猕猴桃样本按照3∶1的比例划分为300个校正样本集(每个成熟阶段75个样本)和100个预测样本集(每个成熟阶段25个样本)。
1.2 试验仪器
高光谱成像系统,型号为GaiaField-F-V10。系统结构框图如图1所示,其中,CCD相机的曝光时间为9.5 ms,样本距离镜头大约40 cm。
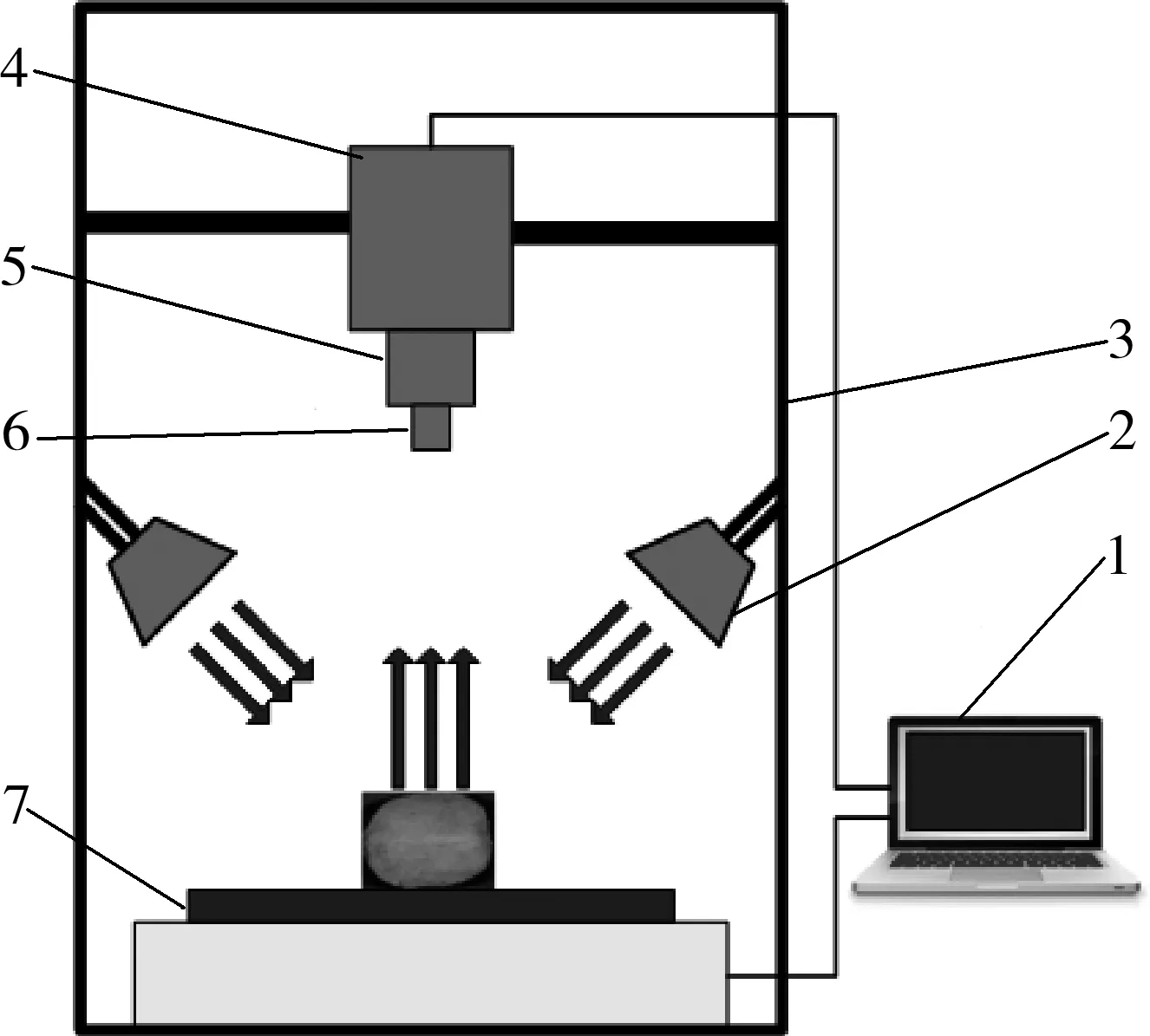
图1 高光谱成像系统框图Fig. 1 Schematic diagram of hyperspectral imaging system1.计算机 2.溴钨灯光源 3.暗箱 4.CCD相机 5.成像光谱仪 6.镜头 7.电动平移台
折射仪,型号为ATAGO PAL-α,检测范围为0%~85%,检测精度为±0.2%。
离心机,型号为TD4Z-WS,最高转速为4 000 r/min,转速精度为±30 r/min。
榨汁机,型号为JYZ-V911,额定转速为50 r/min。
1.3 试验方法
1.3.1 高光谱图像采集与校正
将猕猴桃样本依次放置于电动平移台,逐个扫描样本。获取完所有样本的高光谱图像后,采集全白以及全黑的标定图像Rwhite和Rblack,对所有猕猴桃样本的高光谱图像Roriginal进行反射率校正,得到校正后的高光谱图像Rref,校正公式
(1)
1.3.2 猕猴桃SSC测定方法
在获取完所有样本的高光谱图像后马上测定其SSC,先将猕猴桃样本榨汁后再离心(转速3 000 r/min,离心时间5 min),再把猕猴桃汁涂抹在折射仪的折光棱镜上,连续按测量键多次,当折射仪显示屏最后3次显示的值相同时记下该值,作为该样本的SSC参考值。
1.3.3 建模方法
1) 光谱预处理方法。试验分别运用二阶导数(Second Derivative,SD)、标准正态变换(Standard Normal Variation,SNV)以及多元散射校正(Multi-scatter Calibration,MSC)对原始的光谱反射率数据进行预处理,以消除原始光谱中的噪声信号。其中,SD方法用于消除线性背景偏移,通过对原始光谱数据求二阶导数实现预处理;SNV方法用于校正因散射而引起的光谱误差,使原始光谱数据标准正态化,即先将原始光谱减去该光谱数据的平均值,再除以该光谱数据的标准偏差;MSC方法可以有效地消除散射对光谱的影响,即先计算所有样本光谱的平均光谱,然后将平均光谱作为标准光谱,每个样本的光谱与标准光谱进行一元线性回归,求得各光谱相对于标准光谱的斜率与截距,在每个样本原始光谱中减去截距同时除以斜率,最终实现MSC校正。3种预处理方法的计算公式如式(2)~式(4)。
SD法的计算公式

2[A(v)]+A(v+Δv)+2[A(v+
2Δv)]}
(2)
式中:A(v)——SD法的原始光谱;
v——波数;
Δv——光谱数据的波数间隔。
SNV法的计算公式
(3)
式中:Zij——标准正态化后的光谱,i=1,2,…,n;
xij——SNV法的原始光谱;

Si——第i个样本光谱数据的标准偏差;
n——样本个数;
p——光谱点个数。
MSC法的计算公式
(4)
式中:Ai——第i个样本的原始光谱;

Ai(MSC)——校正后的光谱;
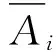
2) 模式识别方法。分别运用偏最小二乘判别分析(Partial Least Square Discrimination Analysis,PLS-DA)方法以及简化的K最近邻法(Simplified K Nearest Neighbor,SKNN)构建猕猴桃成熟度无损识别模型,这两种方法是模式识别中经常运用的有监督统计模式识别方法[21]。其中,PLS-DA方法是将猕猴桃的光谱数据看作自变量X、猕猴桃的类别信息(成熟阶段:Ⅰ、Ⅱ、Ⅲ、Ⅳ)作为因变量Y,Y是一个以0,1为元素的矩阵,当猕猴桃属于某类成熟阶段时,则该样本在Y中对应列的元素值=1,否则为0。建模时分别将X与Y的每一列数据进行偏最小二乘回归分析,进而获得类别信息矩阵,最后依据该类别信息矩阵的每一列数据与1接近的程度判别猕猴桃样本属于哪类成熟阶段。而SKNN方法是基于一种简化的算法——类重心法构建的,即将校正集中每一类别(成熟阶段:Ⅰ、Ⅱ、Ⅲ、Ⅳ)样本点的重心求出,然后分析预测集样本点与各类别重心的距离,当预测集样本点距离哪一类别重心的距离最近,就属于哪类成熟阶段。
1.4 数据分析
利用软件Spectral SENS(Spectral Imaging Ltd.,Finland)采集所有猕猴桃样本的高光谱图像,采集获得的猕猴桃高光谱图像数据在ENVI 5.4(Research System Inc., USA),MATLAB R2016b等软件中进行处理与分析。
2 结果与分析
2.1 不同成熟阶段猕猴桃图像
图2给出了不同成熟阶段(成熟阶段:Ⅰ、Ⅱ、Ⅲ、Ⅳ)‘贵长’猕猴桃的图像。
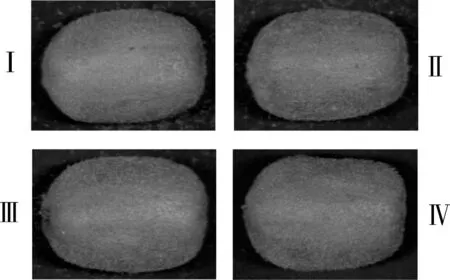
图2 不同成熟阶段猕猴桃图像Fig. 2 Images of different maturity kiwifruit
从图2中可以看出,猕猴桃表皮颜色较深,且不同成熟阶段的猕猴桃表皮颜色差异不明显,仅通过外部图像难以判别出猕猴桃的成熟度。因此,需要依据不同成熟阶段猕猴桃的可溶性固形物含量以及光谱差异来识别猕猴桃的成熟度。
2.2 不同成熟阶段猕猴桃的SSC和平均光谱
图3给出了不同成熟阶段(Ⅰ、Ⅱ、Ⅲ、Ⅳ)猕猴桃可溶性固形物含量统计分布图,从图3中可以看出,不同成熟阶段猕猴桃可溶性固形物含量的平均值分别为Ⅰ:5.3%、Ⅱ:6.4%、Ⅲ:8.0%、Ⅳ:10.2%,即随着猕猴桃的逐渐成熟,其可溶性固形物含量逐渐增大。图4分别给出了4个成熟阶段猕猴桃样本的平均光谱曲线,从图4可见,在波长675 nm附近具有一个吸收峰,该吸收峰是由猕猴桃表面叶绿素的吸收引起的,反映了猕猴桃表面颜色信息,在波长980 nm附近的吸收峰则是由水分的吸收引起的,体现了猕猴桃水分含量信息。进一步从图4中可以看出,在630~690 nm、740~780 nm以及960~1 010 nm之间,不同成熟阶段猕猴桃的光谱值存在差异,导致此光谱差异的主要原因是不同成熟阶段的猕猴桃内部成分含量不同(可溶性固形物含量等)。因此,依据此光谱差异构建猕猴桃成熟度无损识别模型。
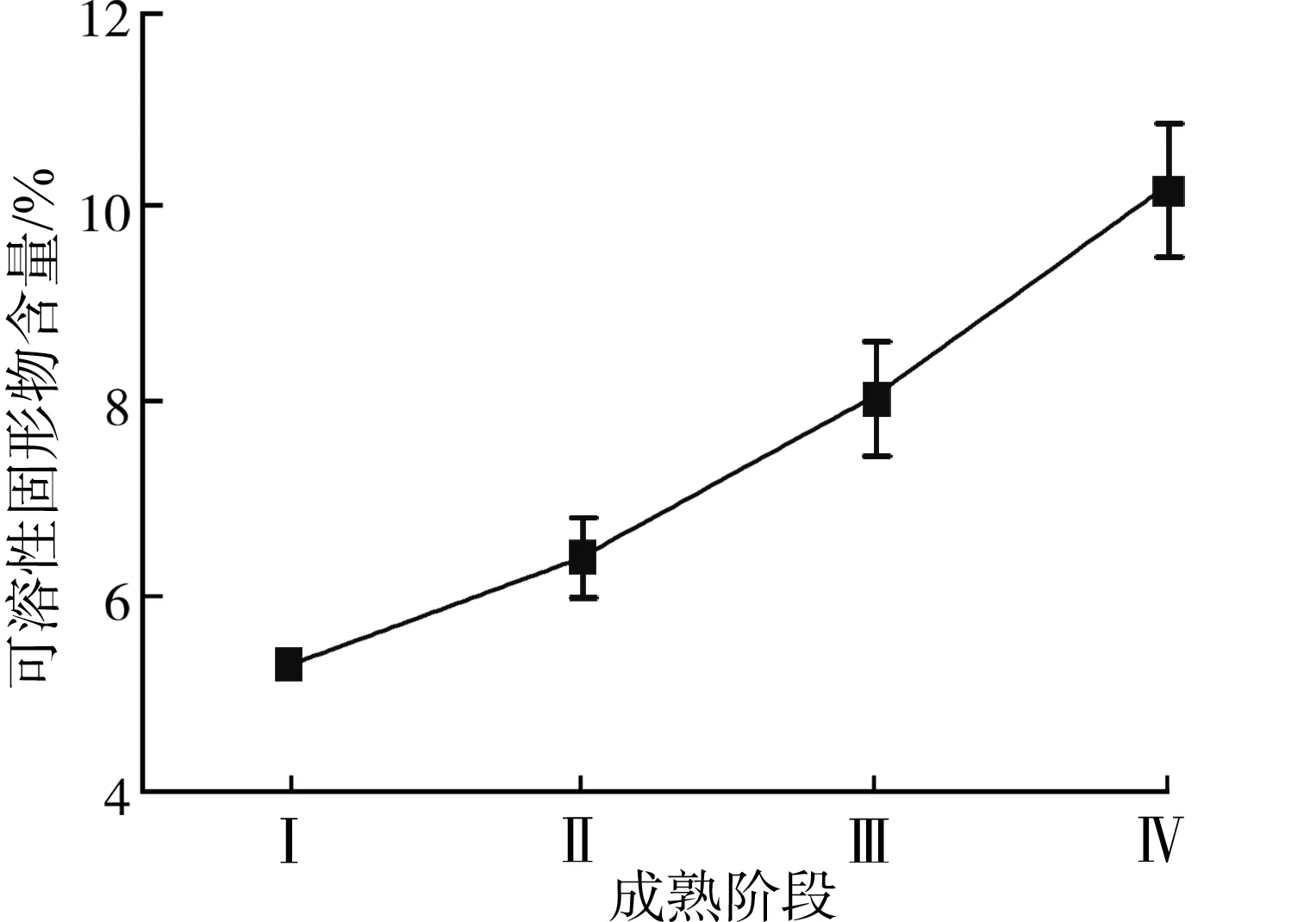
图3 不同成熟阶段猕猴桃可溶性固形物含量统计结果Fig. 3 Statistics results of soluble solids content of different maturity kiwifruit
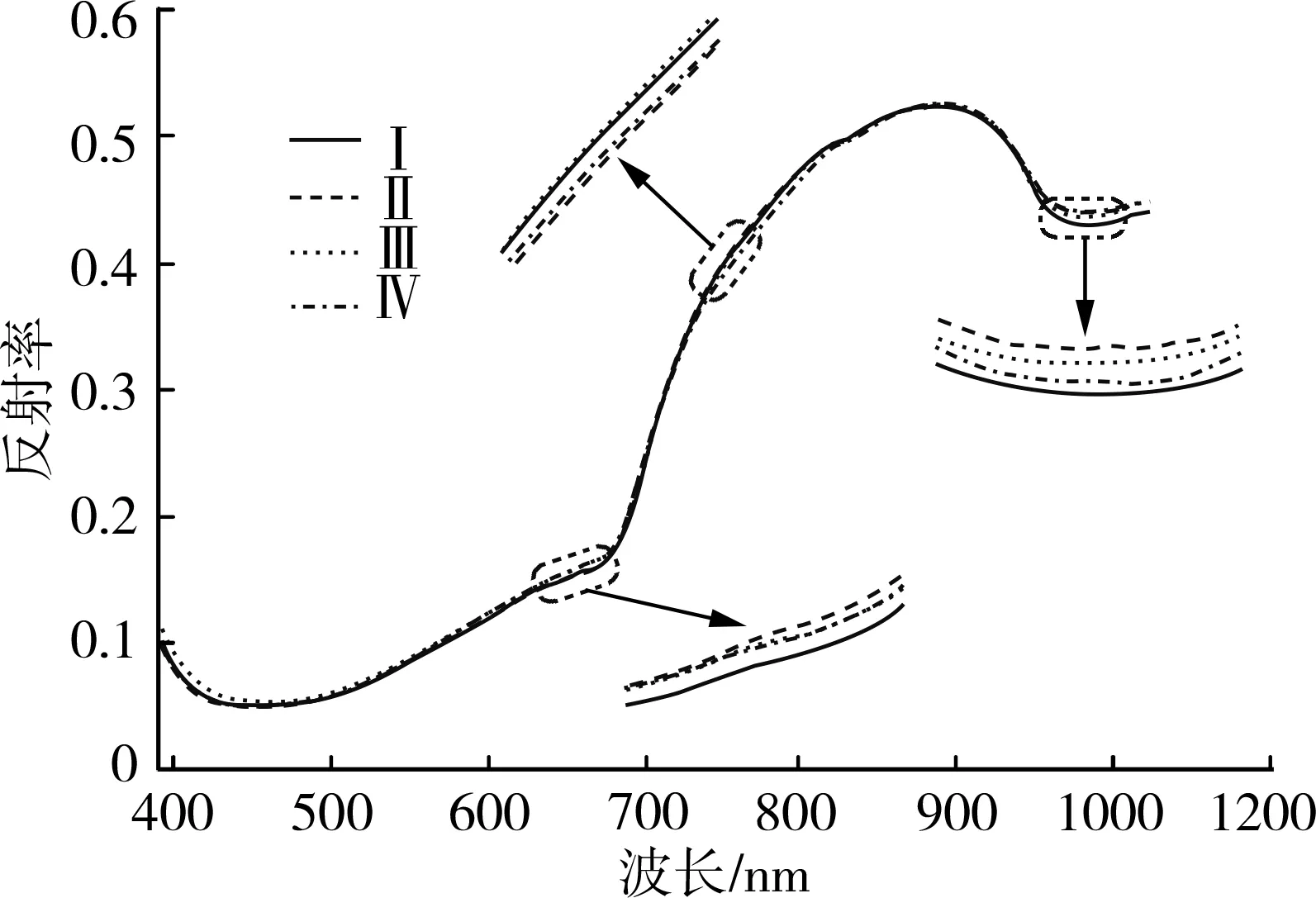
图4 不同成熟阶段猕猴桃平均光谱Fig. 4 Average spectra of different maturity kiwifruit
2.3 不同光谱预处理方法对原始光谱的预处理效果
由于原始反射光谱中包含一些噪声,为了提升识别模型的精确度和稳定性,分别运用SNV、MSC以及SD对原始的反射光谱数据进行预处理。图5分别给出了所有猕猴桃样本的原始反射光谱以及经过SNV、MSC和SD预处理后的相对反射光谱。对比图5(a)与图5(b)、图5(c)、图5(d)可以发现,预处理后的光谱曲线要比原始的光谱曲线平滑些,这说明光谱经过预处理消除了部分噪声和背景干扰信息。
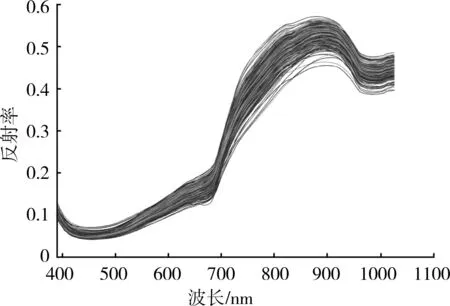
(a) 原始的光谱
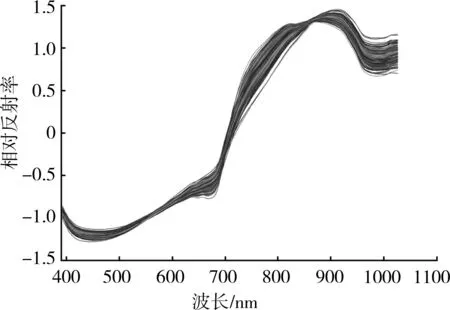
(b) SNV预处理后的光谱
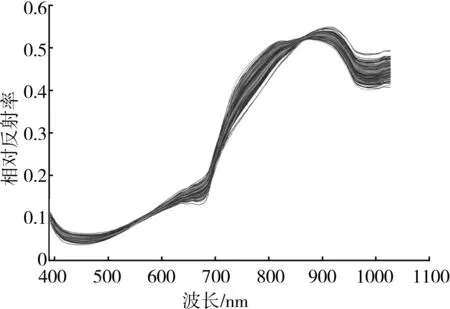
(c) MSC预处理后的光谱

(d) SD预处理后的光谱图5 猕猴桃反射光谱Fig. 5 Reflectance spectra of kiwifruits
以PLS-DA判别模型为例,分别将经SNV、MSC以及SD预处理后的光谱数据作为自变量,样本的类别信息(成熟阶段:Ⅰ、Ⅱ、Ⅲ、Ⅳ)作为因变量,比较3种光谱预处理方法对原始光谱的预处理效果。表1给出了基于不同光谱预处理方法的识别模型对猕猴桃成熟度的识别结果,从表1可以得出,基于SD预处理后的光谱构建的识别模型对猕猴桃成熟度的正确识别率达到了100%,而基于SNV和MSC预处理后的光谱构建的识别模型的正确识别率最高为96%,说明SD预处理方法对样本原始光谱的预处理效果相对较优。
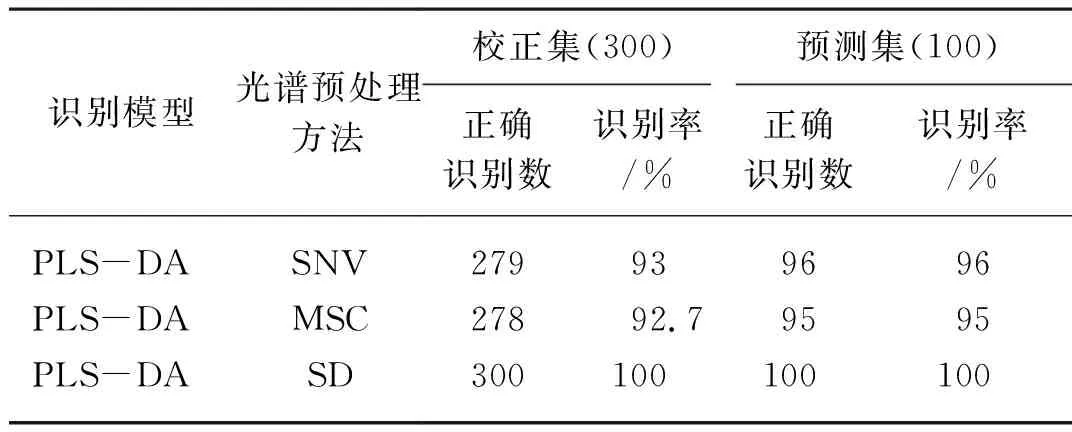
表1 基于不同光谱预处理方法的识别模型对猕猴桃成熟度的识别结果Tab. 1 Discriminant results of different models based on different spectra preprocessing methods
2.4 不同判别模型对猕猴桃成熟度的识别结果
将经SD预处理后的光谱数据作为自变量,样本的类别信息(成熟阶段:Ⅰ、Ⅱ、Ⅲ、Ⅳ)作为因变量,比较两种判别模型(PLS-DA、SKNN)对猕猴桃成熟度的识别效果。表2给出了不同识别模型对样本的识别结果,从表2中可见,相比于SKNN识别模型对判别猕猴桃成熟度的正确识别率(98%),PLS-DA识别模型对判别猕猴桃成熟度的正确识别率高达100%。同时,图6分别给出了PLS-DA和SKNN两种识别模型对预测集中猕猴桃成熟度判别结果的混淆矩阵,从图6中可以看出,PLS-DA识别模型对预测集中不同成熟阶段的猕猴桃判别均正确,而SKNN识别模型对预测集中猕猴桃成熟阶段Ⅲ中的2个样本误判为成熟阶段Ⅰ,表明PLS-DA模型的性能要优于SKNN模型。
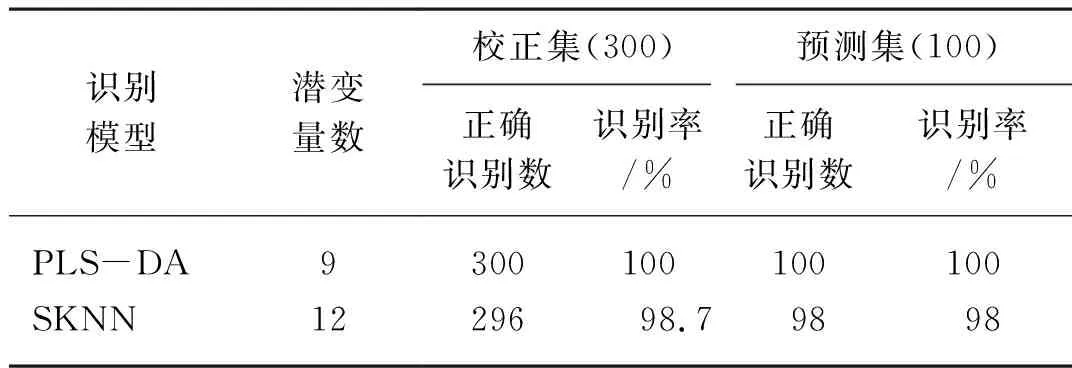
表2 不同识别模型对样本的识别结果Tab. 2 Discriminant results of different models
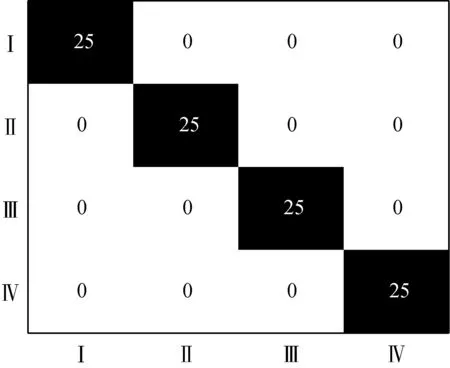
(a) PLS-DA

(b) SKNN图6 识别模型的混淆矩阵Fig. 6 Confusion matrix for the recognition models
3 结论
1) 以不同成熟阶段的“贵长”猕猴桃为研究对象,利用可见/近红外高光谱成像系统获得所有样本的高光谱图像,并获取整个猕猴桃样本区域的光谱反射率,比较3种光谱预处理方法(SNV、MSC、SD)对原始光谱的预处理效果。最后采用偏最小二乘判别分析(PLS-DA)方法和简化的K最近邻法(SKNN)构建判别“贵长”猕猴桃成熟度无损识别模型。
2) 相对于SNV和MSC两种光谱预处理方法,基于SD预处理后的相对反射光谱构建的PLS-DA识别模型对猕猴桃成熟度的正确识别率达到了100%,表明SD预处理方法具有相对较好的预处理效果。依据猕猴桃成熟度识别率及混淆矩阵,可以得出,构建的PLS-DA识别模型对猕猴桃成熟度的识别性能(正确识别率为100%)要优于SKNN识别模型的识别性能(正确识别率为98%)。
3) “贵长”猕猴桃成熟度识别模型的建立为快速、无损检测其成熟度提供了理论支撑,为开发“贵长”猕猴桃成熟度无损检测装备奠定一定的理论基础。
