基于改进CycleGAN的道路场景语义分割研究
2022-08-09张如涛汪鸿浩
张如涛,黄 山,汪鸿浩
四川大学 电气工程学院,成都 610065
语义分割是一种将图像中每个像素分类为属于对象类的方法,它是图像分析和计算机视觉中重要的研究领域,有着广泛的应用场景。例如,无人车驾驶[1]、医疗影像分析[2]、地理信息系统[3]等。其中道路场景的语义分割就是无人驾驶中最关键的技术之一。
近年来,基于卷积神经网络的语义分割在不断发展,2015年Long等人提出了全卷积网络(fully convolutional networks,FCN)[4],提出了一种全新的端到端的网络,使得图像语义分割有了突破性的进展。然而主流的基于卷积神经网络的分割方法基本上都属于监督式学习[5],有监督的图像分割通常需要大量带有其自身区域级标签的图像,但是在图像分割常用场景中,无论是缺陷分割[6]、医疗影像,或是自动驾驶,都很难准备足够的训练数据。道路场景的样本数据存在道路的巨大差异性和种类的多样性,准备足够的训练数据是不容易的,况且语义分割任务的逐像素注释是一个耗力且耗时的过程,因此基于弱监督学习的分割方法已经成为该领域的研究热点。
Goodfellow等人在2014年提出生成对抗网络模型(generative adversarial networks,GAN)[7],是目前深度学习中重点研究话题之一,并在无监督领域、生成领域、半监督学习领域以及强化学习领域[8]都有广泛的应用。随后,一些学者开始将GAN用于语义分割领域,如Luc等人[9]用对抗训练方法来训练分割模型,Metzen等人[10]提出生成对抗扰动语义分割模型来提高分割的准确度。GAN在训练中不断学习模拟数据的分布进而生成和训练数据相似分布的样本,在一定程度上解决了训练数据需要大量的像素级的标注的问题。但是GAN训练模型依然需要成对的训练数据集,并且在训练过程中容易产生模式崩溃[7]的问题。
针对于上述问题,利用循环生成对抗网络(cycle consistent adversarial networks,CycleGAN)[11]来进行语义分割,CycleGAN相较于传统的GAN,其主要优势表现为:(1)降低了数据集的要求,不需要成对的数据集,也可以免去大量的像素级的注释;(2)将随机噪声的输入替换成了真实图像的输入,提高了生成图像的质量。但是CycleGAN在训练过程中依然会存在训练不稳定的问题。
本文在循环生成对抗网络的基础上对目标函数进行改进,将网络中的对抗损失替换成最小二乘损失[12],提高了生成图像的质量并增加了稳定性;使用Smooth L1损失[13]来解决训练中存在的模式崩溃问题;最后增加了特征损失[14],能够有效约束生成图像,使得生成图像较好地保存自身信息,提高生成图像质量。
1 网络结构
循环一致性对抗网络CycleGAN是在生成式对抗网络GAN的基础上发展而来,CycleGAN中引入了循环一致性损失[10]来使得网络不需要成对的数据集进行训练,不需要在训练数据间建立一对一映射,降低了对训练数据的要求。
1.1 生成式对抗网络GAN
GAN主要应用了博弈论中零和博弈的思想,就是通过生成网络G和判别网络D不断博弈,进而使G学习到数据的分布。相较于传统的网络模型,GAN存在两个不同的网络,训练方式采用的是对抗训练方式。由此可知,GAN是由生成器和判别器组成,生成器G主要通过输入随机噪声来生成图像,判别器D来判断G生成的图像是否和真实图像相似,将判断的结果反馈给生成器,根据反馈的结果再训练生成器,使生成器能生成更接近于真实数据的图像,最终达到一个均衡状态。GAN的目标函数如公式(1)所示:
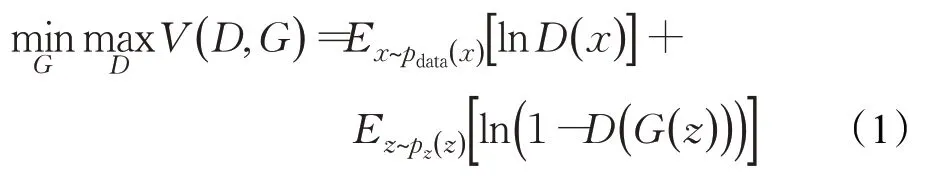
其中,x表示为真实数据,z为随机输入噪声,G(z)是生成器由输入z生成的图像,pdata(x)为真实数据分布,p z(z)是用于z采样的先验分布。目标函数所展现出来的就是一个极小-极大化问题,即只考虑生成器G,希望D(G(z))尽量接近于1,即生成的图像都被判断为真实数据,此时所期望的目标函数值最小;只考虑判别器D,则希望D(G(z) )接近于0,即生成的图像都能被判断出是假的,此时所期望的目标函数值最大。当D(G(z))=0.5时,就会达到平衡状态。
1.2 循环生成对抗网络CycleGAN
CycleGAN是由Zhu等人[11]在2017年提出的,它是由2个生成器和2个判别器组成,其实现原理如图1所示。给定两个样本空间X和Y,为了避免X域中的图片都转换为Y中同一张图片,CycleGAN会同时学习生成网络G和F,要求将X域的图片转换到Y域后还能再转换回来,就此引入了循环一致损失。图1(a)是总模型结构,包含两个映射函数G:X→Y和F:Y→X,X域中的样本通过生成器G来生成Y域中的图像,同样的Y域可以通过生成器F生成X,图1(b)、(c)则分别描述了X→Y→X和Y→X→Y的过程,在图1(b)中,X域中的样本x通过生成器G生成Y域中的样本,̂再通过F生成样本̂,希望生成的̂和原x是一样的,即,它们之间的差就是一个loss;类似地,图1(c)是一个对偶反向循环的过程,对于Y域中的每个图像y,希望生成的̂和原y是一样的,即

图1 CycleGAN原理图Fig.1 CycleGAN schematic
1.3 CycleGAN的原损失函数
在CycleGAN网络训练中,损失函数是必不可少的,起到了至关重要的作用,CycleGAN主要包含了对抗损失和循环一致性损失。
(1)对抗损失
生成对抗网络(GAN)的思想就是对抗训练,就是利用对抗损失来对不断优化生成器和判别器,CycleGAN也利用了此对抗损失来优化网络,通过判别器对生成样本和真实数据进行打分,生成器希望判别器将生成的图片判定为真实图片,而判别器希望能够准确判别出是真实数据还是生成样本。其中对于映射G:X→Y及其对应的判别器DY的损失函数如下:

(2)循环一致损失
循环一致性损失是CycleGAN引入的新损失函数,当源域的图像经过生成器到目标域,又通过生成器回到源域,循环一致损失用来约束源域的原始图像和重建图像的相似程度,使生成回来的图像接近于原始输入图像,以此来优化生成器来生成想要的目标域的图像,CycleGAN用L1范数来计算此损失,其函数如下:
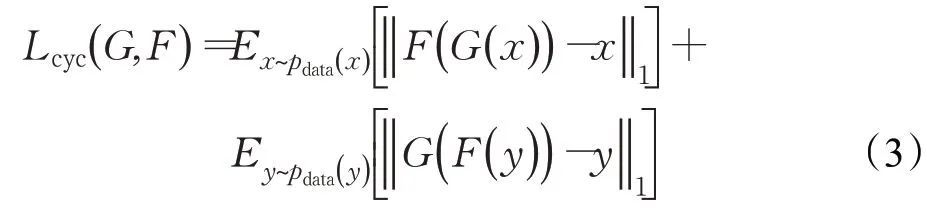
(3)目标损失
目标损失是CycleGAN的训练目标,它是由两个映射的对抗损失和循环一致性损失组成,其中两个映射分别是G:X→Y和F:Y→X,则CycleGAN原始目标函数如下所示:

2 CycleGAN改进
2.1 最小二乘
本文采用最小二乘损失来替换原对抗损失函数,原对抗损失函数在训练过程中可能存在梯度消失的问题,文献[12]指出,最小二乘可以根据样本与决策边界的距离对样本进行惩罚,从而会产生更多的梯度来更新生成器,这样会使得网络在训练中更加稳定,也会生成更高质量的图像。则生成器G及其对应的判别器DY的损失函数如下:

同理,生成器F及其对应的判别器D X的损失函数如下:

2.2 SmoothL1范数
CycleGAN原网络的循环一致损失使用的是L1范数损失函数,即最小绝对值误差,其函数如式(7)所示:

其中G和F都为生成器。L1范数相较于L2范数[15]更加鲁棒,无论对于什么样的输入值,都有着稳定的梯度,就不会导致梯度爆炸[16]的问题,但是却在中心点不能求导,以至于不方便求解。
L2范数损失如式(8)所示:

本文则采用了Smooth L1范数来代替L1范数损失函数,SmoothL1范数损失结合了L1范数和L2范数各自的优点,也就是光滑后的L1,使其在中心点也能够求导,便于求解,则其损失函数定义为:

此函数即为文中所改进后的循环一致损失。
2.3 特征损失
CycleGAN网络中,X域的图像通过生成器G生成Y域的图像,再通过生成器F生成X域图像,即重建图像,此时希望重建图像和X域输入图像相似,便引入循环一致损失。同时对抗损失也只是判定生成的图像是不是目标域风格的图像。而道路场景的语义分割中,不同颜色区域所代表的是不同类别,但X域到Y域的生成图像可能随意改变图像固有的类别颜色,导致最后的分割精度下降。
针对这个问题,根据文献[14]的理论,本文便在网络中引入了特征损失函数,此损失能够实现映射G:Y→Y和F:X→X。生成器G的作用是用来生成Y域风格图像的,所以当输入Y域图像y时也应该生成Y域风格的图像,此时要求G(y)与y尽可能接近,以此来保证类别能够分割成其对应的颜色。加入特征损失函数后,生成器G在原有输入的基础上增加了图像y的输入,生成器F也增加了图像x的输入,也就是让生成器将转换后的图像与原图像进行差异比较,进行反馈优化。利用L1损失来计算此差异并不断优化,此特征损失能够保证在生成目标域图像的时候还能获得目标域图像的特征,从而提高生成图像的质量。其损失数定义如下:
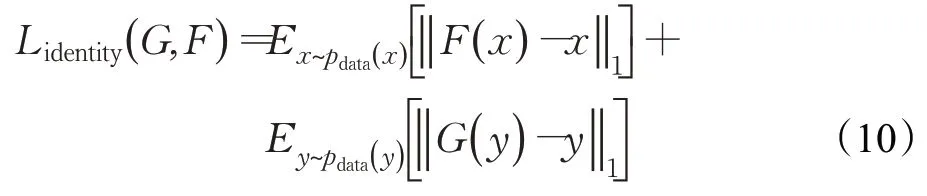
加入特征损失之后,生成器都在原输入的基础上增加了一个输入,则本章改进之后的分割原理图如图2所示,图中只展示了正向训练图,反向训练图与正向相似。图中X域的真实图像经过生成器G生成Y域的虚假图像,此时判别器会判断生成的图像和Y域真实的图像的真假,通过判断的分数来不断优化网络。同时Y域中生成的虚假图像又会由生成器F生成X域的图像,也就是重建X域的原始图像,并用循环一致损失SmoothL1来不断缩小重建图片和原始图像的差异,即提高它们的相似度。在网络中引入特征损失,即在生成器G增加Y域图像的输入,经过生成器G同样生成Y域的图像,并用特征损失L1进行约束,减小图像间的差异以此确保在生成图像时,能获取目标图像的特征。在对抗损失、循环一致损失以及特征损失的共同作用下,网络得到更进一步的优化,能够使得Y域中生成的图像越来越真实,图像质量越来越高。

图2 CycleGAN中正向网络训练图Fig.2 Forward network training in CycleGAN
经过以上的改进之后,便可以确定总的目标损失,则本章改进CycleGAN后的目标损失函数如下:

其中,λ和μ分别是循环一致性损失和特征损失的权重,λ依然采用原网络中的默认值10,但是μ的变化会影响整个分割的效果,所以本章最后也会讨论不同的μ值对实验效果的影响。且此目标损失函数主要是为了实现
2.4 Instance Normalization
CycleGAN的生成器由编码器、转换器和解码器组成。其中编码器由3个卷积层构成,转换器由6或9个残差块组成,每个残差块又由2个卷积层组成,解码器则是由3个反卷积层构成。CycleGAN的判别器只有编码器部分,是由5个卷积层构成。在原网络的生成器和判别器结构中,除了判别器的第一个卷积层后没有归一化层,其他所有的卷积层后都有归一化层,且使用的归一化方法都为batch normalization(BN),而本文将生成器和判别器中的归一化层均换成instance normalization(IN)[17]。BN是把每一个mini-batch的数据拉回到均值为0方差为1的正态分布上,这样能保证数据分布一致,可以避免梯度消失问题,其原理如下:
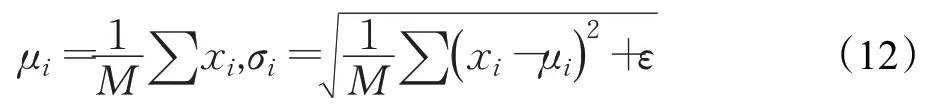
其中,M是mini-batch的大小。IN针对的是图像像素,对像素进行归一化,且IN是对一个批次中单个图片做归一化,这有利于图像风格转换,且能保持图像间的独立性,其原理如下:

根据文献[17],BN适用于判别模型中,如图片分类。由于判别模型的结果取决于数据整体分布,而BN正是对每个batch归一化来保证数据分布的一致性。但BN对batchsize的大小较敏感,要是batchsize太小,则BN不足以代表整个数据分布。IN则适用于生成模型中,如图像风格迁移,本文所做的分割正是在此基础上进行实现的。由于生成图像的好坏依赖于某个图像实例,而BN做归一化就不适合图像迁移中,但是用IN就能够保持图像间的独立,并且加速训练模型的收敛。
综合以上的改进,本文的生成器和判别器的具体结构如图3所示,其中判别器中C64中是不使用归一化层的。

图3 生成器和判别器结构Fig.3 Generator and discriminator structure
3 实验与结果分析
3.1 数据集及实验环境配置
本文采用了在图像语义分割领域常用的Cityscapes数据集[18],该数据集包含50个城市不同的街景,包括20 000张粗注释图片和5 000张高像素级注释图片,5 000张精注释图片中又包含2 975张训练图片、500张验证图片和1 525张测试图片。
实验则在Cityscapes数据集的训练图片中随机选取了1 032张原道路图像和1 032张标注图像作为训练数据,并用验证图片中的200张图像进行测试。在进行实验之前,首先将选取的训练图像进行处理,统一压缩为256×256像素的图像。
本文所进行的实验环境为Windows10系统,CPU为Intel®Core™i5-8250U@1.80 GHz CPU,16 GB内存。服务器为戴尔Precision T3430,Linux系统,具体操作系统为Ubantu20,有两块Nvidia1080Ti显卡,Python3.6,使用Pytorch框架。实验中,batchsize设置为1,程序运行200个epoch,前100个epoch保持学习率不变为0.000 2,后100个epoch将学习率设置为线性衰减到0。整个网络使用Adam优化器进行优化。
3.2 性能评价指标
本文采取图像语义分割中常用的性能指标[19]来进行对实验结果的评价,指标包括像素准确率PA(pixel accuracy)、像素准确率平均值MPA(mean pixel accuracy)和平均交并比MIoU(mean intersection over union)。
PA表示标记为正确的像素占总像素的比例,其公式如下:

MPA是对PA的改进版本,表示为每个类内被正确分类像素数的比例,计算每类的正确率后求取平均值,其公式如下:
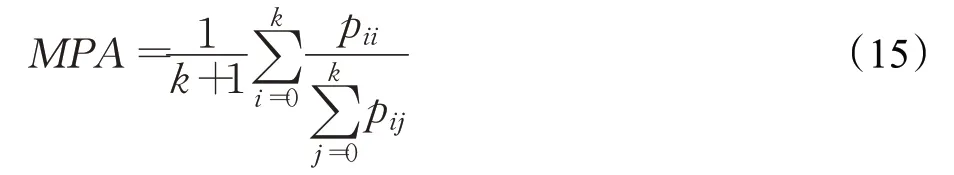
MIoU是用于分割问题的标准评价指标,计算的是两个集合的交集与并集的重合比例,而在语义分割中,计算的是真实分割与系统预测的分割间的交并比。这个比例可以被重新定义为真实正例的数量比上总数量(包括真实正例、错误负例和错误正例),其公式如下:

其中,k表示类别,这里假设有k+1个类(包括无效类或背景),p ij表示本属于类i但被预测为类j的像素数量,p ii表示真实正例的数量,同样的,pij和p ji可以分别解释为错误正例和错误负例。
3.3 对比实验结果
本文所进行的实验分三部分,首先用CycleGAN原网络处理数据进行实验用于对比。接着按照本文所指出的在CycleGAN原网络基础上改进损失函数来进行实验,其中包含加入特征损失和更换归一化层的实验。最后讨论了特征损失的权重值μ的不同对实验结果的影响。
3.3.1 主观结果分析
从实验结果中随机抽取6张图像进行展示,如图4和图5所示。其中图4是用原道路图像生成分割图像,从左到右依次是原道路图像、CycleGAN、Ours、Ours(+instance)和标注图像;图5是用标注图像生成道路图像,从左到右依次是标注图像、CycleGAN、Ours、Ours(+instance)和原道路图像。由图4可以看出,原CycleGAN生成的分割图像效果较差且有小部分的失真现象,甚至将整体背景分割为同一类,而按本文的方法生成的图像基本上能将各类分割出来,相对于原网络效果更好,同时在本文改进的基础上将网络中生成器的归一化层batch normalization换成instance normalization后,生成图像的质量更高,且整体道路分割效果更接近于标注图像。但是相较于标注图像,还是存在不足的地方,对道路边缘和轮廓的分割比较差,且对背景分割颜色的划分不够明确,也就是在对类的划分中没有将具体的某一类划分成其所属类的颜色。同样在图5中,对比于原网络生成的道路图像,本文方法生成的道路图像细节处理的更好,图像更接近于原道路图像。

图4 道路图像生成分割图像Fig.4 Road image to segmentation image

图5 标注图像生成道路图像Fig.5 Annotate image to road image
3.3.2 客观结果分析
除了主观结果外,还需要用具体数据来说明。根据上述介绍的在语义分割领域常用的三个性能指标来进行比较,对比结果如表1所示。
由表1可以看到,将原网络中的对抗损失(交叉熵损失)和循环一致损失(L1范数)改成最小二乘和SmoothL1范数后,像素精确率PA和交并比MIoU都有不同程度的提升。且在改进损失函数的基础上引入了特征损失,各性能指标又进一步提升,即表中Ours所展示,其中像素精确率PA和交并比MIoU都提高了约4个百分点,而平均像素准确率MPA却下降,这里的原因是原网络没有准确地将各类分割出来,由图4看出,原网络生成的图像将几类统一分割为一类,就会造成某一类的精确率很高,也就提高了平均的精确率。虽然本文方法没有将某一类划分为标注图像相同的类,但却将每一类都准确划分出来,在分割效果上是优于原网络的。而且在本文基础上将生成器归一化层换成instance后三个参数指标都提高了约2个百分点。

表1 生成图像性能指标Table 1 Generate image performance indicators
为了更能说明各个改进损失函数的作用,这里呈现改进前后损失函数的收敛曲线,如图6所示。图6(a)为原CycleGAN网络,生成器的损失很难收敛,甚至在5上下波动,导致生成图片的质量很差,图片某些部分还会失真。在将对抗损失和循环一致损失换成最小二乘和SmoothL1之后,如图6(b),生成器的损失有明显的下降,且循环损失也有下降的趋势。图6(c)是在(b)的基础上引入特征损失后的损失收敛图,可以看出生成器的损失更加稳定了,循环一致损失和特征损失也在150个epoch之后逐渐收敛。图6(d)是将生成器中归一化层换成了IN后的损失收敛图,肉眼上相较于(c)没有明显的差异,但是表1数据验证了会产生更好的性能。

图6 损失函数收敛图Fig.6 Loss function convergence graph
从主观结果和客观数据的展示上都体现出了本文方法在原网络的基础上生成图像的质量有一定提升,更接近于标注图像。
3.3.3 讨论μ对结果的影响
引入的特征损失在一定程度上保证了图像特征的保留,使得生成图像的质量更高,但是特征损失的参数的不同也会对结果有影响,这里讨论了μ为不同值时的各性能指标变化,如图7和图8所示。其中图7是在不同μ值下各个性能指标的变化折线图,图8则随机选取3张在不同μ值下生成的图像。

图7 不同μ值下各指标值Fig.7 Each index value with differentμ

图8 不同μ值下的生成图像Fig.8 Generated image with differentμ
图7讨论了μ分别为0、0.5、1、5、7、10的情况,在没有引入特征损失的时候,生成的图像不能很好地保留原图像的特征,使得生成图像的质量不高。而随着μ的增大,训练模型会出现过拟合的状况。且从图7的折线图能够看出当μ的值在1左右时各个性能参数值是最好的,所以在引入特征损失的同时需要对特征损失参数的选取做恰当的取舍。
4 结语
本文研究了基于循环生成对抗网络的语义分割,在CycleGAN的基础上进行改进,主要是将原网络中的对抗损失和循环一致损失L1范数用最小二乘和Smooth L1范数代替来增加训练的稳定性且提高生成图像的质量,并在此基础上加入特征损失保证图像的特征保留使得生成的图像更加真实。文中研究结果显示改进后的网络相比于原网络在各方面的性能都有一定的提升,但特征损失的引入会使得小部分生成图像效果较差,而且生成的图像和真实标注的图像会存在一些差距,为了让生成图像质量更高,并减小和标注图像的差距,未来的工作会在网络的改进上做进一步的研究。
