跨域图像检索综述
2022-08-09李浩然周小平
李浩然,周小平,王 佳
北京建筑大学 电气与信息工程学院,北京 100044
由于文本所承载的信息已经远不能满足人类的需求,图像成为当今时代最常用的信息载体。互联网上每天都在生成海量的各式图像,可见光、红外、光学、夜晚、素描等在不同条件下产生的图像在日常生活中随处可见。图像,已经成为当今时代人们交流信息的主要途径。
随着大量图像的产生,许多群体对于从数据库中检索图像有着现实需求。关于图像检索的研究已经持续了几十年[1],但是人们之前只有同域图像检索的需求,即查询图像和检索结果属于同一视觉域。随着多视觉域图像在网络随处可见,用户对于跨域检索图像的需求也日益迫切。它比同域图像检索更具有价值和应用前景,因为用户可以使用任意的图像去检索跨视觉域的同类物体图像。因此,利用某一视觉域图像查找另一视觉域中相同物体的跨域图像检索就成为当今的研究热点。
跨域图像检索的关键挑战是视觉域鸿沟问题,即不同视觉域图像有不同的成像表达方式且它们的特征存在于不同的空间中。具体来说,来自不同成像载体、光谱、机理以及不同光照条件,图像的颜色、纹理、亮度、梯度、灰度特征都存在很大的区别。同样由于拍摄角度不同,在拍摄物体时也会存在遮挡的问题。另一方面,即使是同类物体它们的图像也会有巨大差异,导致类内距离大于类间距离。所以跨域图像检索的难点就可以总结为如何将两个不同视觉域的图像联系起来以检索最相近的图像。
综合以上分析,跨域图像检索在各个领域的需求会越来越高,深入研究现有的跨域图像检索方法具有重要的学术研究意义。
1 跨域图像检索概述
在过去的几十年中,人们对基于内容的图像检索(content-based image retrieval,CBIR)进行了广泛的研究。从一开始的图像低级特征提取,例如颜色、形状、纹理、空间特征。之后因为深度学习的出色性能,使用深度学习进行图像检索的技术[2]也逐渐出现在人们的视野中。然而,上述所有研究都是基于相同视觉域的图像检索。
与同域图像不同的是,跨域图像是指同一类物体在不同视觉域下的图像。例如红外图像[3]、草图[4]、漫画[5]等,这些图像分别属于不同的视觉域。由于跨域图像在不同条件下形成,不同视觉域的图像在颜色、形状、纹理等方面差异大。基于跨域的图像检索技术是通过X域(源域)图像检索Y域(目标域)的图像,以将两种不同域的图像进行准确匹配。因此,上面所述的基于内容的图像检索技术在跨域这种特殊情况下就受到影响。这在很大程度上激发了对跨域图像检索研究的热情,针对不同的建模方法本文将现有跨域图像检索方法大致分为两类:基于特征空间迁移的跨域图像检索方法和基于图像域迁移的跨域图像检索方法。跨域图像检索方法分类如图1所示。
基于特征空间迁移的跨域图像检索方法把研究的重点放在了提取特征的能力和如何更准确地比较特征向量相似度上。具体地,首先对不同视觉域图像分别提取特征,通过特征提取器将原本不属于同一空间的图像特征向量映射到同一空间中,实现特征空间的迁移。随后在损失函数的帮助下把相同类的特征距离拉近,不同类的特征距离拉远。最后,不同视觉域的图像就可以计算两者之间的特征距离达到跨域图像检索的目的。而基于图像域迁移的跨域图像检索方法把研究聚焦在了图像本身,其核心思想是把源域图像的视觉效果通过生成模型转换为目标域图像的视觉效果,这样跨域检索任务就变为了同域图像检索任务。这种方法在特征提取之前就把两个图像的视觉域鸿沟消除,有效地解决不同图像视觉效果差异大的问题。两类方法如图2、图3所示。
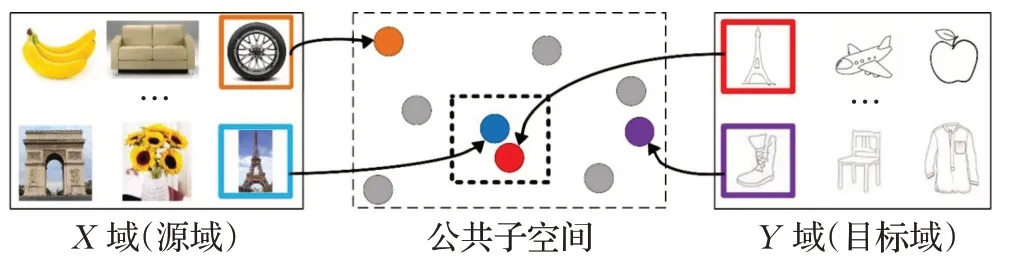
图2 特征空间迁移方法Fig.2 Feature space migration method
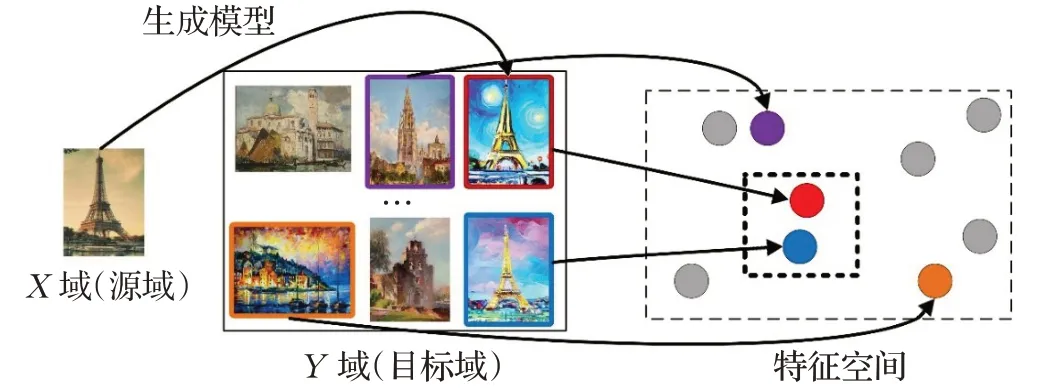
图3 图像域迁移方法Fig.3 Image domain adaptation method
2 基于特征空间迁移的跨域图像检索
基于特征空间迁移的方法是目前跨域图像检索的主流方法。研究人员认为即使图像在不同视觉域,但是如果两者具有相同的高级语义信息那它们之间也存在潜在的相关性。其主要思想是通过特征提取器将两个视觉域的图像特征通过映射函数映射到公共子空间中,这样就能为两个不同视觉域的图像生成相同的特征向量形式进行特征的直接比较。方法如图4所示。
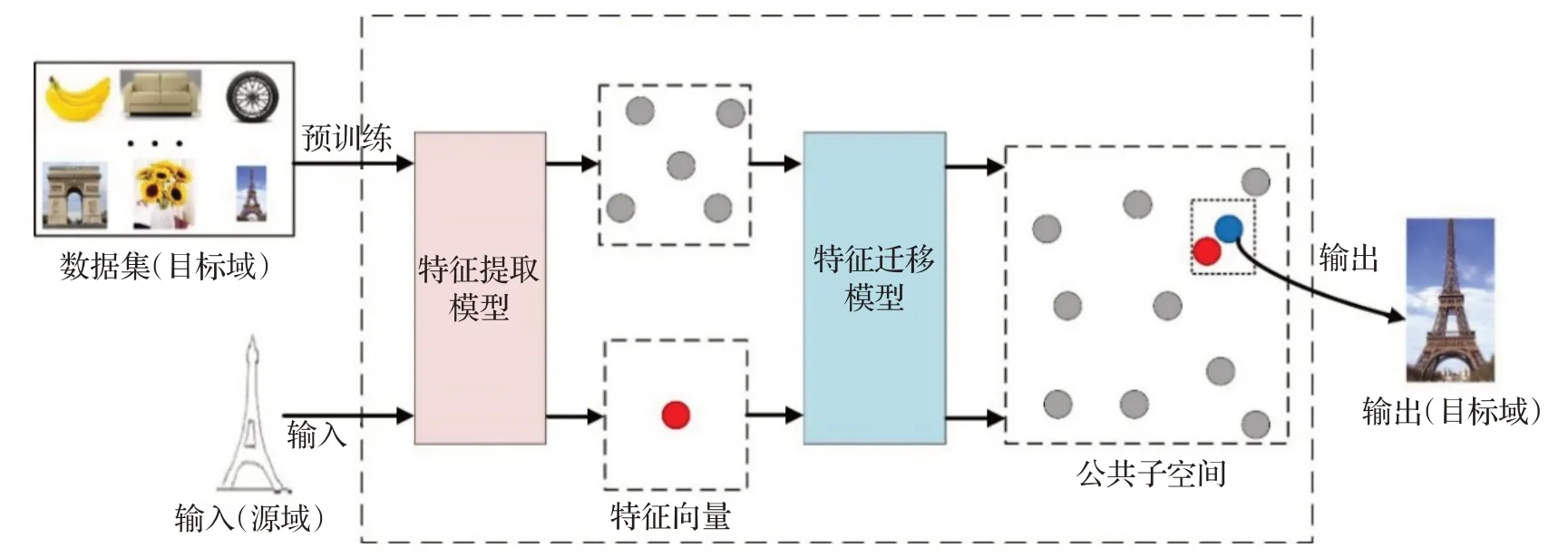
图4 基于特征空间迁移的跨域图像检索方法Fig.4 Cross-domain image retrieval method based on feature space migration
现有的特征提取方法可以根据特征类型分为三种:低级、中级和高级。低级特征提取方法依赖于手工特征,流行的手工特征包括颜色、纹理、形状。这些低级特征不能有效地表示背景不同的各类视觉域图像,导致限制了检索性能[6]。中级特征提取方法通过聚合局部特征,如向量局部聚合描述符[7]。然而对于同类图像也包含具有不同方位、尺度和照度的情况,中层特征不能准确描述图像的丰富信息。随后许多工作[8]尝试使用深度神经网络(DNN)来提取高级的语义特征,这些特征在解决这一问题上已被证明比传统的手工特征具有更优越的性能。因此,大多学者针对两域图像之间差异性的问题对DNN进行了改进并应用到跨域图像检索中。针对特征空间迁移方法不同的改进位置,本章将从四个方面对其分类总结。
2.1 针对图像特征区域建模
在一定情况下,影响跨域图像检索性能的不是图像主体部分的差异而是图像成像时面临的复杂背景问题,甚至有时可能存在遮挡物体主体部分的情况。针对以上问题,不同学者从图像特征区域入手在提取特征时检测物体目标和其语义部分,帮助模型将注意力放在图像特征最优的区域以获得更有判别性的特征。
Liu等人[9]首先构建了一个包含特征点的跨域服装数据集,随后提出一个依赖于标注服装属性和特征点的FashionNet网络用于跨域服装检索,跨域服装数据集如图5所示。该方法帮助模型将重点放在数据的特征点上,抑制了背景差异造成的影响。但是该方法需要提前注释好的数据,因此对于前期工作要求较高。而王志伟等人[10]不仅考虑到关键位置特征,还利用目标检测算法YOLOv3分别提取了图像的全局、主体和局部区域,经过神经网络提取特征后融合并添加颜色、纹理等低级特征进行补充,提升了检索精度。

图5 注释的特征点Fig.5 Feature points of annotations
另一种方法是从原始图像中通过注意力机制帮助神经网络模型关注特定区域的主体特征,忽略非主体的干扰因素。Ji等人[11]利用数据库图像的属性信息定位图像的注意力区域,提出了利用标签信息帮助定位数据库图像的注意力TagYNet和利用候选数据库图像来定位查询图像的注意力CtxYNet,在实验数据集上较FashionNet的准确率有了明显提高。但是该方法依赖于注意力机制的性能,一旦注意力的性能无法准确描述图像的关键性将会丢失某些重要信息。刘玉杰等人[12]对此作出改进,首先在VGG[13]网络中添加注意力模块获取图像的注意力特征图,同时为了防止注意力丢失部分关键信息通过引入短连接的方式将重要特征与全局的特征信息结合,获得了不错的效果。但是该方法需要手动调整参数,且在图像光线不足和受到遮挡时结果不好,也证明了需要进一步的优化。Fan等人[14]则设计了新的注意力DBA-Net,该网络在考虑图像关键特征的同时对局部细节也有很好的涉及,因此即使图像受到遮挡和外观相似的影响时也能具有较高的准确度。Yu等人[15]则在添加注意力模块外又引入了shortcut connection[16]解决跨域图像错位的问题,同时保留了粗粒度和细粒度两种信息,在实验中也证明了其效果。
在研究中发现现有的解决方案大多关注细节信息和空间层面信息,而忽略了通道信息。因此,Chen等人[17]关注通道和空间两个层面的信息,引入了通道注意力、自注意力和空间注意力以挖掘各个维度上的细粒度细节,不仅在细粒度检索同时在粗粒度检索中也获得了优异的性能。葛芸等人[18]分别为通道层面和空间层面提出了多尺度池化通道注意力和范数空间注意力,在两个层面上自适应地给关键特征加权,对不同尺度的特征都有关注,mAP值可以达到92.4%。
目前针对图像特征区域建模的方法重点关注了跨域图像检索中源域和目标域图像受到背景干扰、物体被遮挡、跨域图像错位等造成的视觉域影响,因此利用人类的视觉系统机制,通过注释特征点和注意力机制帮助神经网络模型把注意力放到图像的关键区域,增强对主体细节特征的学习。但是这种方法还存在一些问题,首先标记特征点的方法依赖大量的人工对图像进行注释,需要在前期耗费人力和时间用于标注数据集的工作。另外,对数据进行关键点的标注也会面临不同物体关键位置变化的问题,所以对专业能力也有一定的要求。因此有研究人员选择了添加注意力的方法,然而该方法为了获得更好的效果牺牲了网络结构,在神经网络结构以外添加多个不同的注意力分支,增加了模型训练的时间和计算量。同时图像特征区域建模的方法对于成像设备造成的视觉差异不能很好的解决,具有一定的局限性。
2.2 针对神经网络结构建模
不同于针对图像特征区域的方法是帮助神经网络关注图像关键区域,针对特征空间迁移改进的另一个角度是从特征提取器入手,通过多个神经网络模型结构提高对不同特征的提取能力来完成跨域图像的检索。随着深度学习技术的飞速发展,DNN在不同的应用领域展现了巨大的潜力[19]。DNN作为特征提取器可以在数据集上进行调整用来提取丰富的语义特征,特别是对于图像域变化丰富的多视觉域图像来说,同类物体的图像会因为相机的变化和光照的影响导致图像颜色、纹理发生改变,因此需要确保特征提取器不会受到图像低级特征过多的影响,之后进行特征对比时才会比较精确,为跨域图像检索提供基础。
Lei等人[20]使用ImageNet预训练的VGG网络作为初始化网络,从草图和图像的轮廓中提取深层特征以进行跨域图像检索。随后使用草图数据微调预训练的神经网络模型,最后使用微调模型提取草图特征并检索对应的图像轮廓。同样的,Ha等人[21]利用预训练的VGG网络跨域检索建筑信息模型(building information modeling,BIM)和自然图像完成室内定位的任务,在特征清晰的地点达到了满意的效果。Kim等人[22]特意针对跨域问题提出了两阶段的预训练方法,在通过ImageNet训练后,增加一个使用多域未标记数据的自监督预训练步骤,以让模型在新域上获得区分能力和对域转移的不变性,与只预训练一次的模型比较得到了更好的性能。
上述方法最大的优势是解决了DNN模型对训练样本的依赖问题,同时使用预训练的神经网络不需重新训练就已经具备一定的提取特征能力,节省了时间和计算成本。但是不同域的图像存在巨大的视觉差异,单纯使用预训练的神经网络不能很好地应用到跨域的检索任务。针对这个问题,大部分的研究工作开始通过结合多个神经网络来解决视觉域鸿沟,其中包括孪生神经网络[23]、三重神经网络[24]、四重神经网络[25]。
基于孪生神经网络的跨域图像检索主要衡量两个输入的相似程度。Shi等人[26]对航拍图像首先应用极坐标变换使得图像的视图方向大致与街景图像相似,而后引入孪生神经网络学习街景和航拍图像的深度特征,实验数据显示提出的方法提高了现有方法的性能,在top-1的召回率上提高了1.5倍。Park等人[27]发现现有跨域检索方法侧重于学习图像的全局表示而忽略了局部的重要特征,因此提出在孪生网络中加入一个CMAlign模块强制网络提取像素级局部特征,最终融合所有特征形成最终的特征,提高了在孪生网络结构中检索的精度。Ma等人[28]则认为现有方法只是将特征映射到公共空间而忽视了域的特定信息,因此他们关注了视觉域的独有信息,在孪生网络中首先提取域的独有特征,并引入域变换方案和双空间特征融合模块,将独有特征补充到共有特征中,准确率可以提高到99.32%。Miao等人[29]在孪生网络中加入了Refinement模块[30]提取图像关键点特征,随后采用知识蒸馏策略融合全局和局部特征,以确保判别的一致性。但是该方法容易受到遮挡的影响,应用在现实数据中容易出现错误。Li等人[31]在孪生网络基础上采用了多尺度注意力机制抑制卫星图像转为街景图像后的变形区域,而为了进一步提高跨域检索的能力,其通过困难样本挖掘方法让网络关注困难样本以突破性能的瓶颈。
此外,研究者们也开始利用三重神经网络将数据形成三元组的形式,让同样本间的距离尽可能缩小,不同样本之间的距离尽可能增大。Yu等人[32]使用三重神经网络提取ImageNet数据集的边缘图预训练模型,弥合了两域图像的视觉域差距,其中设置的训练三元组由两个正样本和一个负样本组成,如图6所示。然而为了得到好的检索效果,该方法经历了非常复杂的训练过程,同时依赖边缘图提取算法可能会导致边缘的映射质量对其结果有较大的影响。因此Lin等人提出了TC-Net[33],TC-Net不需要将照片转换为边缘图,而是直接输入RGB图像避免复杂的预训练同时防止纹理信息丢失。在不同数据集测试的检索准确率较以往方法[32]可以提高26.81%。而李奇真等人[34]选择更先进的边缘检测算法[35]移除弱边缘像素保留强边缘像素获得了更清晰的轮廓图,随后将轮廓图与彩色图像融合弥补跨域图像的差距,在三重网络中得到了更有区别性的特征表示。
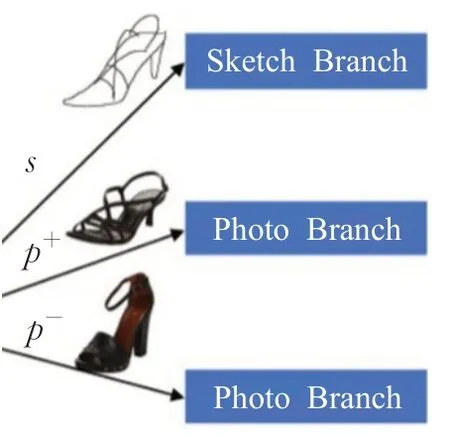
图6 三元组结构Fig.6 Triple structure
进一步的,研究者们认为在训练时增加更多的限制,可以更好地增加类间距离和减小类内距离,因此提出利用四重神经网络来对跨域图像进行检索。对于某些视觉特征可能难以描述,但在文本中可以描述的情况,Song等人[36]通过四重神经网络来联合图像输入和文本输入。四元组分别为图像、文本、正样本图像和负样本图像,通过在三重神经网络上增加一个文本分支网络,提高检索的准确性,结果表明当图像和文本联合建模时每种模式都可以彼此受益。但是该方法缺乏视觉感知方面的相关属性,会因纹理缺失造成无法准确检索的问题。Fuentes等人[37]提出了一个名为Sketch-QNet的四重神经网络架构,以此希望特征空间能够将共享形状和颜色的图像与仅共享形状的图像区分开来。同时,该方法通过边缘保留平滑滤波器[38]、k均值聚类、Canny边缘检测器[39]将训练集的每个样本合成为彩色草图,Sketch-QNet在基于彩色草图的检索问题上取得了最新的成果,同时解决了三重神经网络对于弱相关样本不能很好区分的问题。Dos等人[40]通过四重神经网络对来自声纳的声学图像和卫星航拍图像进行匹配,利用自适应粒子滤波器进行状态估计,解决了灰度水声图像和航空光学图像间的跨域检索。
上述方法通过结合多个神经网络的方法解决了跨域图像检索的问题,其重点在于如何训练模型。单结构神经网络通过预训练的方式避开了DNN需要大量样本训练的问题,同时节省了训练时间,但是仅使用通用数据集预训练的方式不能弥补两个视觉域之间的鸿沟,尤其是当面临类间距离小于类内距离时,预训练的模型没有对跨域图像深入的学习因此无法对其进行区分。多分支神经网络改进了网络结构,使用多个神经网络并行接受多个输入。对于学习跨域图像的类间距离和类内距离具有更好的效果,改善了跨域图像检索的检索能力。但是随着多分支神经网络的研究,研究人员发现为了提高在不同视觉域下图像的检索性能,需要进一步在神经网络上增加注意力机制帮助模型在更复杂的环境下完成跨域检索,以至于模型结构愈发复杂,参数量过大的问题也因此需要消耗大量的计算成本。另外,随着跨域图像检索需求越来越大,仅通过多分支网络来区分不同域图像已经无法满足需求,需要更有针对性的方法才能应对更复杂的图像域。
2.3 针对损失函数建模
除了改变神经网络结构以外,另一个解决方法是使用有效的度量方式来衡量跨域图像的相似性。度量学习[41],也称为距离度量学习(distance metric learning,DML)。它的关键思想是在训练过程中从不同角度减少同类样本之间的特征距离,同时尽可能地扩大不同类别样本之间的特征距离。度量学习算法的提高主要在改进损失函数上,损失函数对于跨域图像检索的优化有重要的作用。几个常用的损失函数分别是对比损失[42]、三重损失[43]和softmax损失。
对比损失的核心思想是缩小正样本对的距离,增大负样本对的距离,如图7所示。Reale等人[44]用小卷积滤波器训练了两个网络VisNet和NIRNet,并通过创建具有对比损失的孪生网络来耦合两个网络的输出特征。但是在现实中通常存在视觉相似性很小的正对,这些样本对如果使用原始的对比损失可能会导致模型的过度拟合和较差的泛化能力。因此Wang等人[45]提出了稳健对比损失,它通过减轻对正对的惩罚以防止模型过度拟合,同时还结合了softmax损失函数,实验证明通过将稳健对比损失与softmax损失相结合可以增强神经网络在跨域图像检索时的泛化能力。Cheng等人[46]则基于对比损失提出了MCL(modified contrastive loss),MCL为正样本添加了区间约束,同时MCL使用新的在线采样策略使每个类别被抽样的可能性相等,解决了不平衡分类的问题。
图7 对比损失示意图Fig.7 Contrast loss diagram
三重损失最早由Schroff等人提出,三重损失相比对比损失增加了一个样本,更多的考虑正样本对与负样本对之间的相对距离,如图8所示。它解决了对比损失的一个限制,如果两个样本是不同的,对比损失将拉大两个样本的距离,如果其中一个样本已经位于集群的中心,对比损失的效果将会减弱。Bui等人[47]使用三重损失来学习从自然图像中获得的草图和边缘图之间的跨域映射,但是当面对一些复杂度高的图像时,三重损失训练的收敛速度会明显变慢。Xiong等人[48]在三重损失的基础上结合softmax损失和中心损失[49],从而使训练过程能够学习到更多的判别特征并且更容易收敛。Arandjelovic[50]设计了一种新的三重损失以处理街景图像的不完整和嘈杂的位置注释以及因拍摄时间不同造成的光照影响。Ibrahimi等人[51]在跨域图像检索任务中评估了度量学习中四种三重损失的变体:N-pair loss[52]、lifted loss[53]、angular loss[54]和hard-triplet loss[55],实验显示将多种损失函数结合比使用单独的损失函数表现更好。Faraki等人[56]通过提出的跨域三元组损失CDT,以将从一个域获得的显式度量与来自另一个域的三重样本在一个统一的损失函数中关联起来,从而更好地对齐跨域图像。
图8 三重损失示意图Fig.8 Triple loss diagram
Deng等人[57]则基于softmax损失提出了新的算法ArcFace,该方法通过在深度特征与其相应权重之间的角度上部署角惩罚余量,提高模型的判别力并稳定训练过程。然而,ArcFace中固定的附加角余量经常会导致训练数据集的过拟合。为了解决这个问题Jiao等人[58]提出了Dyn-arcface,其将ArcFace的固定角余量替换为自适应角余量。它可以根据每个类中心与其他类中心的距离来调整,减少固定附加角余量引起的过拟合程度。实验结果表明,所提出的算法可以实现比ArcFace更好的性能,特征中心之间的距离也比ArcFace更加分散,缓解了过拟合的问题。
此外,研究者们也对不同跨域环境提出了有针对性的损失函数,使跨域检索模型进一步拟合视觉域鸿沟。Wu等人[59]为跨域行人重识别提供了一个中心聚类损失,减少跨域图像之间相同身份的特征距离,同时增加不同身份的特征距离,在跨域行人重识别上具有较好的性能。Cheema等人[60]提出Unit-Class Loss以考虑单个样本以及整个类分布来增强网络的特征学习,同时可以从未对齐的面部图像中学习域不变的身份特征,最终可以得到99.5%的精确度。Paul等人[61]结合了新的语义邻域损失和混合预测损失,来弥合已见类和未见类的知识鸿沟并有助于在未知域的检索能力。Gao等人[62]为了在特征提取阶段就能够缩小不同域的特征距离,为此设计了一个跨模态知识蒸馏损失,该损失能够在模型提取不同图像域的独有特征时缩小不同域特征之间的距离,最终提高了模型跨域检索的能力。
在跨域图像检索中,损失函数作为神经网络的最终目标,引导模型朝着最优方向发展,同时影响着训练模型的效率和容量。在小规模数据集上,研究人员提出了不同的损失函数来训练神经网络,包括对比损失、三重损失,它们旨在加强类内紧凑性和类间可分离性,然而对比损失只有两个样本互相比较,跨域图像经常存在类间相似而类内不相似的情况,所以在没有上下文关系时只比较两个样本容易出现错误,同时对比损失也存在容易过拟合的问题。而随着数据集规模越来越大时,三重损失在N个图像上可以产生O(N3)个样本,因此三元组数量也会激增导致训练时间过长不易收敛。另一方面,不同跨域图像面临着不同环境,因此针对不同的研究环境,研究人员提出了不同的损失函数,为跨域图像检索实现了更好的效果。但是新提出的损失函数只能解决本身的任务,不能很好地的泛化到其他跨域图像检索任务。同时上述文献结构复杂、参数量大,导致运行时间长,离实际应用还存在一定距离。
2.4 针对编码空间建模
目前基于特征空间迁移的跨域图像检索方法都关注于如何提高检索精度,利用不同优化方法增强模型检索能力。但是当图像数量越来越多时,为提高跨域检索性能而增加的模型结构会给硬件设备带来极大的挑战。因此检索时会付出高昂的时间成本,难以部署在移动设备进行实时检索。考虑到实际需求,在检索精度提高的同时追求更高的效率是现实且必要的。哈希学习可以在保持原有空间关系的基础上,将复杂的高维特征向量转换为简洁的二进制编码的形式,减轻计算难度的同时提高检索效率。显而易见,将跨域图像检索方法与哈希学习相结合具有更大的优势,是未来研究的热点之一。
跨域图像检索与传统的哈希算法已经有大量的研究,Kalantidis等人[63]使用局部敏感哈希[64]将图像片段表示为二进制向量,然后测量查询和排名靠前列表中的结果之间的相似性,这种方法在节省查询时间上非常有效。但是由于传统的哈希算法对图像的颜色、纹理和形状等特征描述不清晰,导致传统哈希算法的检索精度并不高。Liu等人[65]为基于草图的图像检索(sketch-based image retrieval,SBIR)提出了第一个深度哈希模型(deep sketch Hashing,DSH)来加速SBIR。该方法考虑了具有深度哈希技术的快速跨域检索,提出了一种半异构深度框架并将其合并到端到端二进制编码框架中,其中的哈希编码显著减少了检索时间和内存占用,加快了检索速度。但是其也存在较明显的缺陷,该方法训练和测试样本都是固定的,在现实应用中不能保证没有新的样本类型,所以在零样本的情况下该方法通常会失败。针对这个问题,Shen等人[66]随后提出了一个端到端的三重网络架构ZSIH来学习共享的二进制表示并对跨域数据进行编码,随后利用Kronecker融合层[67]和图卷积来减轻跨域图像的异质性并增强数据之间的语义关系,成功解决了大规模跨域零样本哈希任务。Xiong等人[68]则引入了一种图像变换策略解决跨域检索问题,通过提出的深度跨域哈希网络DCMHN将RGB三个通道的图像转换为四种类型的单通道图像,之后通过三重损失结合哈希编码进行特征降维,最后生成高效的二进制码后进一步提高了检索的准确率和效率。Du等人[69]为跨域掌纹检索提出了基于深度哈希的方法,该方法将对抗训练、最大均值差异和深度哈希统一起来,帮助网络掌握跨域检索的域不变特征,而哈希值使得模型更容易运算比较出跨域掌纹图像的相似性。Wu等人[70]认为深度哈希网络继承了深度学习和基于编码方法的优点,其对干扰的强鲁棒性、低存储成本和快速匹配速度的优点适合进行跨域图像检索,随后又结合了空间变换网络[71]克服图像错位和旋转的问题,提高了跨域检索精度。
综上所述,应用哈希学习处理跨域图像检索任务减轻了计算机处理大规模数据的压力,提高了检索速度。对于传统的哈希学习方法,检索效率比之前的方法有很大的提高,但是其对图像颜色等特征描述不清晰导致在跨域检索时精度不高。在深度哈希学习方面,由于深度学习拥有较强的特征提取能力,哈希学习开始更多地与深度学习结合完成跨域图像检索的任务。但是应用哈希学习轻量化模型会对检索精度造成一定的影响,从结果上来看精度没有之前的高。因此如何弥补精度的损失是未来需要研究的重点,因为这是跨域图像检索能否广泛实际应用的关键。
2.5 基于特征空间迁移的方法总结
总体看来,基于特征空间迁移的方法在跨域图像检索已经有了实质性的进展,但在真实场景下仍然面临许多挑战。首先针对图像特征区域建模的方式依赖人工在图像上标注特征点和添加注意立机制,因此需要耗费大量的人力和训练时间,同时标注数据要具有专业领域的知识,对于成像光谱之间的差异也不能很好地弥补,因此如何优化模型能更有效地获取图像最优特征区域并减少对标注信息的依赖是未来的一个研究方向。其次针对神经网络结构建模的方式对正确配对的样本需求很大,需要人工对样本决定是否为正样本或者负样本,同时模型结构也在不断复杂,给未来实际应用带来了难题。未来研究可以考虑模型结构复杂对于检索造成的负面影响,在不降低检索能力的情况下优化模型结构。针对损失函数建模的方式,研究人员充分考虑了不同的应用场景,因此也提出了不同的损失函数以拟合不同视觉域之间的鸿沟。但是研究中发现如何使用损失函数并没有明确的标准,在很多情况下都是试用不同的损失函数或者以组合的方式探索最佳的方法,同时新提出的方法泛化性不高只能针对特定问题,所以该领域还需要进一步研究提高损失函数的泛化性。最后针对编码空间建模的方式从思考如何提高模型检索效率的角度入手,将跨域图像检索与哈希学习结合,实现了在减轻计算难度和减少计算时间方面的突破,但是这势必会带来检索精度的下降,如何平衡两者关系是研究人员未来需要进一步思考的问题。
3 基于图像域迁移的跨域图像检索方法
为了解决视觉域鸿沟的问题,基于特征空间迁移使用标记的数据、配对的数据训练模型,学习不同视觉域图像之间的映射关系,但是在样本不够充足时存在局限性。而基于图像域迁移的跨域图像检索方法把研究聚焦在了图像本身,其核心思想是把源域图像的视觉效果通过生成模型转换为目标域图像的视觉效果,实现跨域图像间的风格统一,解决不同视觉域之间的风格差异,这样跨域检索任务就变为了同域图像检索任务。此外也可通过图像域迁移的方式合成新的图像用来扩展数据规模,提高模型的泛化性,缓解图像的域差。因此该类方法是目前的研究热点,也是未来跨域图像检索的研究趋势。基于图像域迁移的跨域图像检索方法如图9所示。
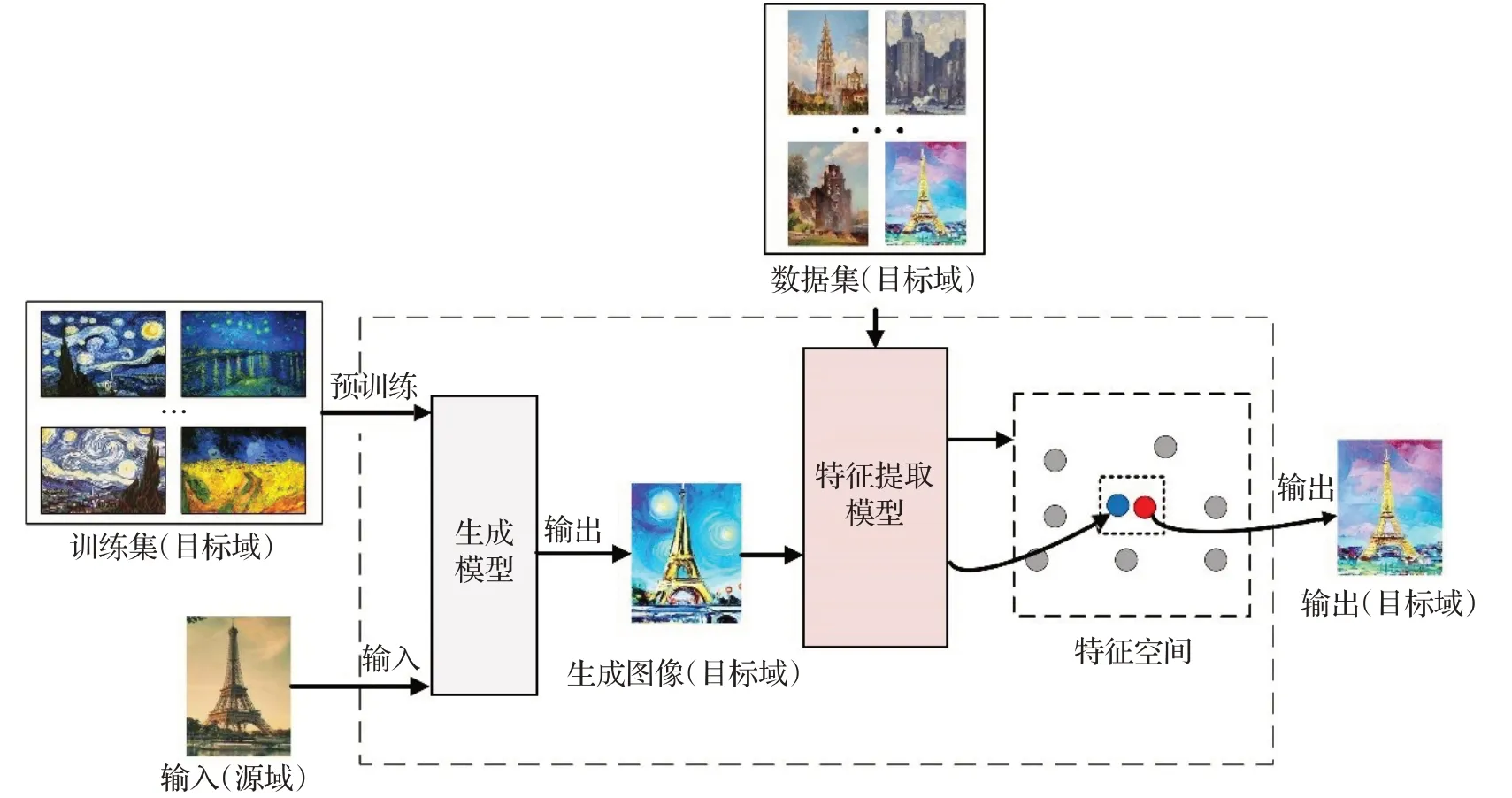
图9 基于图像域迁移的跨域图像检索方法Fig.9 Cross-domain image retrieval method based on image domain adaptation
基于图像域迁移的方法是通过生成模型实现的。研究者将常见的生成模型分为两种:基于编码器-解码器和基于生成对抗网络(generative adversarial network,GAN)[72]。
3.1 基于编码器-解码器的生成模型
编码器-解码器是机器学习中较为常见的模型框架,它主要由两部分构成:编码器(encoder)和解码器(decoder)。编码器是一个可以接受多种形式的输入并输出特征向量的网络,而解码器是一个从编码器获取特征向量并输出与实际输入或预期输出最近似结果的网络。这样的模型将图像作为输入,并通过编码器生成潜在代码,然后解码器将其用作输入以生成共享相同语义信息的图像。
Pang等人[73]通过编码器-解码器的生成图像,将原本具有丰富纹理和复杂背景信息的自然图像转换为简单的草图,消除了两者的域差,实现了跨域之间的图像检索。通过此模型在数据集上的大量实验表明,所提出的方法在未见过的测试数据上也有良好的效果。同样的,Kampelmühler等人[74]提出了第一种通过完全卷积的编码器-解码器结构来完成复杂图像到抽象的线条转换,通过自适应实例归一化(AdaIN)代替批量归一化使得可以根据物体类别不同调节解码器,同时利用感知相似性损失帮助实现具有域鸿沟的图像转换。Sajid等人[75]首先通过k-means聚类算法用于提取的特征,以获得人脸图像分区缩小检索空间,随后利用编码器生成老化人脸图像参考集补偿人脸的变化,mAP较原先提高16.96%。Liu等人[76]利用编码器结构提取跨域图像的共有特征和独有特征,又采用最大均值差异约束两个模态之间的共享特征,使它们具有相同的分布,并减少像素错位和相似红外图像的干扰。上述方法都是在两域之间通过一次相似度比较检索图像相似度,而Lei等人[77]认为这样产生的检索结果易受到输入图像质量的影响,所以提出了通过融合两个检索流的方式提高检索精度。通过两个检索流的融合,避免了计算一次相似度容易受到输入图像质量影响的弊端,同时提高了单一检索流的检索效果。大量转换图像会导致同类别图像之间风格差异较大,Sain等人[78]针对此类问题提出了一个基于跨域变分自编码器(variational auto-encoder,VAE)[79]的模型,该模型将每个图像分解为共享部分和独有部分。同时为了将模型可以应用到未来不同的图像风格,该模型添加了两个风格自适应组件来训练跨域VAE模型,改善了由于类内差异大造成的检索误差同时可以将其推广到风格不可知的情况。Zhao等人[80]引入编码器解码器来在语义上对齐两种视觉域图像之间的数据分布,不仅可以生成具有相同噪声的跨域图像,而且还能纠正未对齐的原始数据集,准确率可以达到99.9%。
编码器-解码器能够生成图像的功能解决了跨域图像检索中域鸿沟的问题,它将源视觉域图像转换为目标域图像,从源头解决了不同视觉域之间的差异。但是由于它们是对真实图片和生成图片进行像素级别的监督,所以对于全局信息没有办法很好的关注,会存在导致生成的图片比较模糊的问题而影响检索精度,因此大部分都应用在了对纹理需求不高的领域,这是它存在的一个缺点,也阻碍了方法的广泛使用。
3.2 基于生成对抗网络的生成模型
Goodfellow在2014年提出的生成对抗网络是生成式模型的另一个热门方法,GAN网络由生成器网络和判别器网络组成,通过两者在训练过程中相互竞争使得它们共同进步。生成器会不断产生更真实的样本,而判别器会不断地识别假样本提供判别能力。目前,基于生成对抗网络的跨域图像检索方法是研究的热门。根据生成对抗网络在跨域图像检索任务中不同的目标,将方法归纳为以下两种:转换图像风格和增加样本多样性。
Regmi等人[81]使用单应变换矩阵将航拍图像转换为街景并保留重叠视野中的像素,然后利用生成对抗网络转换地面图像,实现了卫星图像的跨域检索。Lin等人[82]利用cGAN[83]的两个判别器强制生成的服装图像具有丰富的纹理,而且在语义上与时装图像相关。与非生成方法相比,平均可以实现5.34%的性能提升。但是提出的方法由两个阶段组成,因此不是端到端的模型,想应用到现实场景下还需要进一步改进。受到CycleGAN[84]的启发,Xiong等人[85]提出了cycle-identity-GAN(CI-GAN),CI-GAN在CycleGAN的生成器和判别器之外设计了一个预训练的身份分类器模块帮助模型提高判别能力。该模块在训练期间给生成图像赋予身份和类别信息,因此身份分类模块保证了生成图像后图像内容的不变性,在公共数据集上的实验结果显示了对提高跨域检索性能的有效性。种衍文等人[86]提出姿态标准化网络(IIPN)生成不同姿态的行人图像,然后对行人进行全局对齐和局部对齐,最后使用多粒度特征融合防止小尺度重要特征丢失,提升了模型性能,但是生成预定义的多姿态图像也极易产生额外的推理误差。Chen等人[87]利用CycleGAN将没有纹理的BIM渲染图像转换为具有生动纹理的逼真图像,用于从BIM模型中提取空间信息和估计室内摄像头位置来定位,定位和摄像头方向误差分别为1.38 m和10.1°。Zhang等人[88]受到了特征空间迁移中DSH的启发,提出了一个基于哈希的生成模型生成域迁移哈希(generative domain-migration Hashing,GDH)。GDH加入了一个注意力层,引导模型在学习过程中关注更具代表性的区域。实验表明,GDH方法相比DSH方法能大幅提升准确率,检索时间和内存使用度也有了下降。更进一步的,Bai等人[89]提出DMGAN在转换图像风格后进行跨视觉域图像检索,同时提出一种孪生网络SLN(similarity learning network),SLN包括用于学习类别信息的分类损失和用于减少自然图像与生成图像之间距离的相似度损失,该方法相比于单独使用孪生网络检索精确度有了较大的提高。
Toker等人[90]利用图像域迁移的思想解决包含巨大域鸿沟的街景图像与卫星图像之间的跨域图像检索问题,提出的方法在农村等没有大型数据集的地方也能正常估计图像的地理位置信息,检索效果如图10所示。结果显示,提出的方法在top-10的召回率可以达到89.14%。Zhang等人[91]提出了新的TripleGAN模型用于处理从人体到平铺图像的跨域服装图像转换,它考虑了在生成器中使用类别条件和用于生成具有更多细节服装图像的三元组损失结构,结果也表明了提出模型的有效性。

图10 合成图像后检索Fig.10 Image retrieval after generation
跨域图像检索任务经常面临数据集的缺乏导致模型在训练时产生过拟合的问题,为了解决类似问题通过生成模型生成多样的数据添加到训练数据中提高模型的泛化能力。Zhong等人[92]提出了CamStyle,其中使用CycleGAN和标签平滑正则化(label smooth regularization,LSR)[93]来补充训练图像。但是CycleGAN生成的图像包含大量噪声,因此需要LSR帮助其减小噪声造成的影响,同时随着成像设备数量的增长,CamStyle的训练次数也会越来越多,造成了计算资源的浪费。为此Liu等人[94]提出了UnityGAN,依靠UnityGAN学习每个相机的风格数据来获得适合所有相机风格的UnityStyle图像,避免了多次训练的弊端,使得生成图像更加高效。同时UnityGAN生成的图像效果更加清晰,不需要额外的结构减少噪声的影响,克服了CycleGAN容易变形的问题。Zhou等人[95]应用starGAN[96]在目标数据集上学习图像风格转移模型,以增强样本多样性。又提出增量优化学习,挖掘所有训练样本的潜在相似性,改进后对检索准确度有所改善。
基于生成对抗网络的方法相比于编码器-解码器的方法最大的不同就是引入了对抗的思想。通过对抗模型可以帮助生成模型更好地学习观测数据的条件分布,另一方面,利用生成对抗网络生成更多样性的图片缓解了跨域图像检索数据不够的问题帮助模型学习到更好的判别特征。但是生成对抗网络训练难度大,需要大量的计算,而受限于现有生成模型的生成质量并没有达到理想状态,新生成的图像有可能存在噪声干扰、物体扭曲等现象,对检索性能造成负面影响。此外,若是将含有噪声的样本作为训练数据也会对特征学习增加困难,因此在某些领域的跨域图像检索还没有很好的普及。相信随着生成模型的不断进步,这种方法将逐渐被更多领域的学者使用。
3.3 基于图像域迁移的方法总结
综上所述,基于图像域迁移的方法是继特征空间迁移后新的热门方法,相比特征空间迁移,它不需要人工标注数据就可以生成新的图像用于改善检索环境。基于编码器解码器的生成模型优点在于它建立在神经网络之上可以使用随机梯度下降进行训练,在生成多种复杂数据方面显示出广阔的前景。但是由于该方法计算生成图片和原始图片的均方误差,会更倾向于产生模糊的图片而影响图像检索的精度,因此只能在对纹理要求不高的特定领域使用,具有一定的局限性。基于生成对抗网络的图像域迁移跨域图像检索方法是无监督的另一种生成模型,GAN网络生成的图片清晰度要好于编码器-解码器,正因如此也在更多的跨域任务中被选择。但是生成对抗网络训练难度比编码器解码器模型大,需要大量的计算成本,容易影响模型的泛化能力,因此未来探索更优的训练策略和设计更好的生成对抗网络是解决此类问题的关键。另外,此类方法的生成模型和检索模型大多是分开进行的,在实际应用中也存在困难,因此也需要进一步研究端到端的生成模型。
4 相关数据集
在跨域图像检索中训练数据一直是令研究人员想要解决的问题,丰富的数据也是算法进步和评估模型能力的基础。因此本文在查阅跨域图像检索各领域的文献后,梳理总结了11类25个不同领域的跨域图像数据集,供未来的学者使用,数据集详细介绍如表1所示,部分数据集和检索结果如图11所示。

图11 部分数据集和检索结果Fig.11 Part of dataset and retrieval result

表1 常用跨域图像检索数据集Table 1 Common datasets of cross-domain image retrieval
5 方法性能对比
为更加清晰地展现各类方法在实际实验中取得的成果,对上文综述过的文献从关键结构、数据集和性能进行对比总结。其中常用的评价指标包括:准确率(accuracy)、查准率(precision)、查全率(recall)、平均精度均值(mean average precision)。为了更好地说明性能评价标准,对检索结果定义如表2所示。性能对比结果如表3、表4所示,两种方法的综合比较结果如表5所示。

表2 结果定义Table 2 Definition of search results
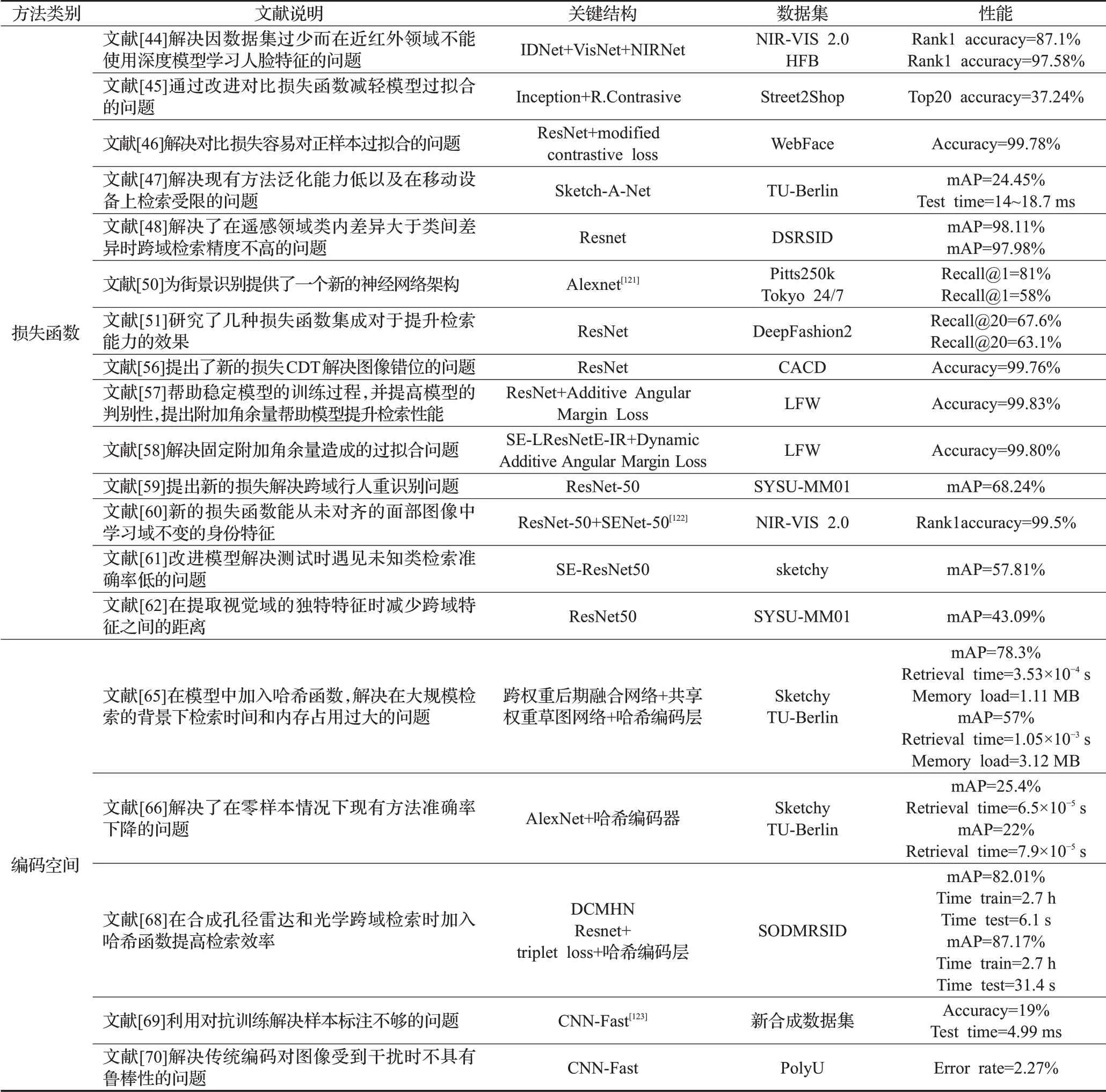
表3 (续)
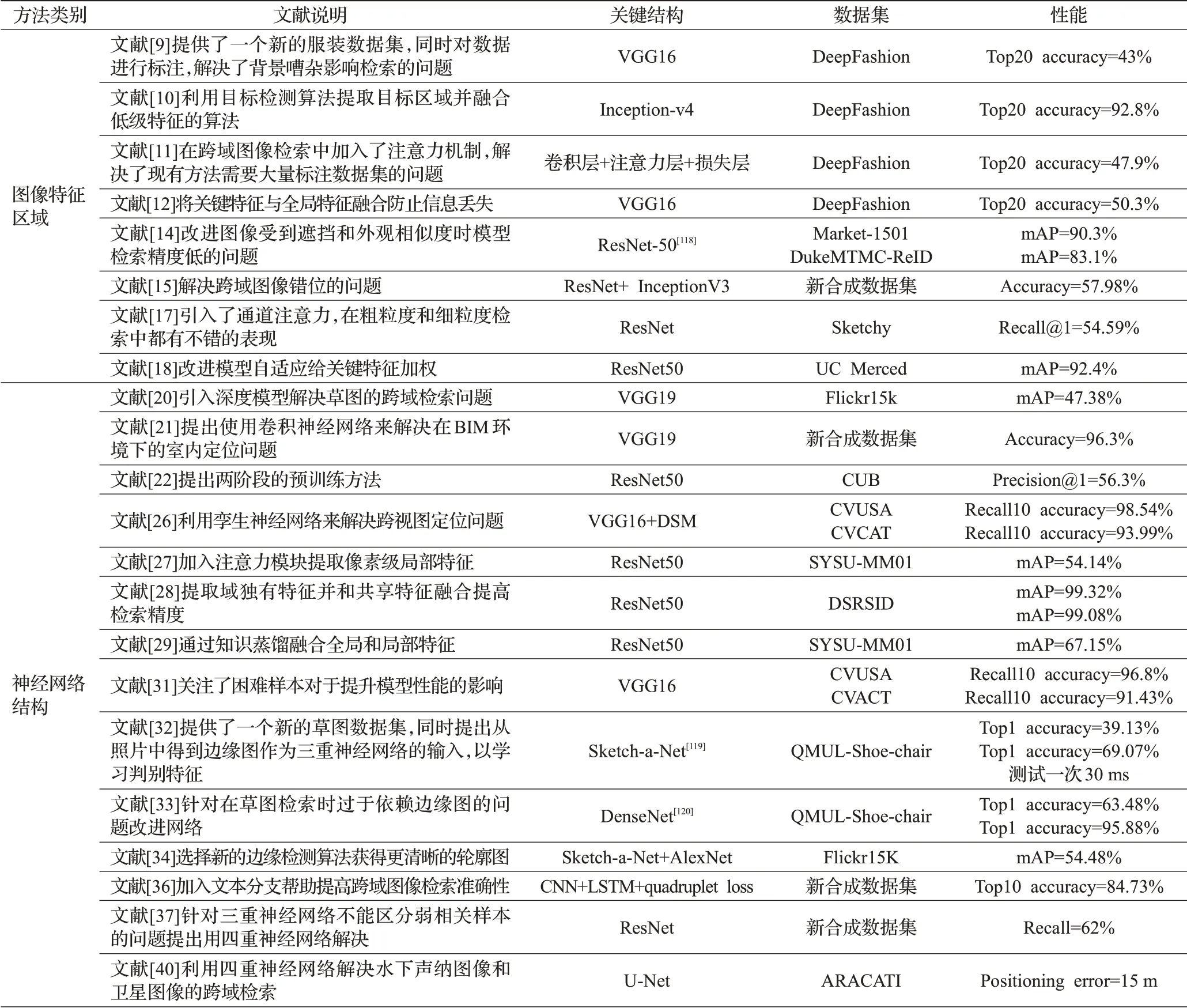
表3 基于特征空间迁移的跨域图像检索方法性能对比Table 3 Performance comparison of cross-domain image retrieval method based on feature space migration
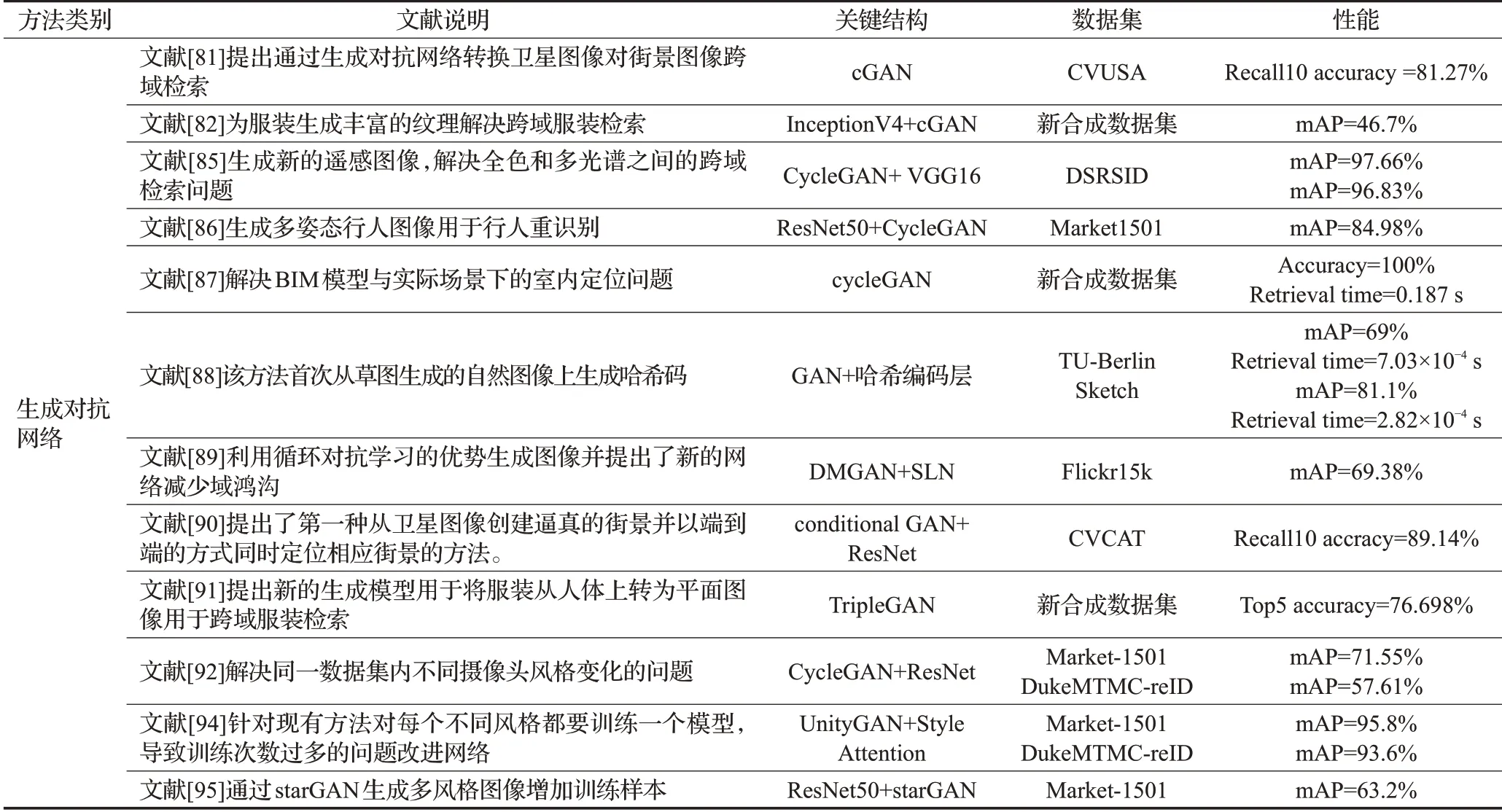
表4 (续)

表4 基于图像域迁移的跨域图像检索方法性能对比Table 4 Performance comparison of cross-domain image retrieval method based on image domain adaptation

表5 跨域图像检索方法对比Table 5 Comparison of cross-domain image retrieval method
准确率是正确预测的样本占总样本的比例,准确率定义为:
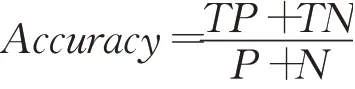
查准率是预测的正样本中实际为正样本的比例,查准率定义为:
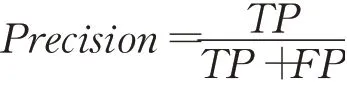
查全率是预测为真的正样本占所有正样本的比例,查全率定义为:

平均精度均值是多个检索的平均精度(AP)的均值,AP是求出多个检索查准率的平均值,因此平均精度和平均精度均值定义为:
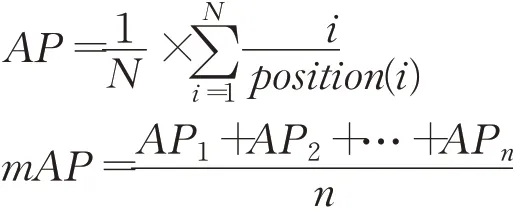
N表示正样本数,position(i)表示第i个正样本在检索结果中的位置,n代表检索的次数。
从文献[20]和文献[34]的实验数据可以看出,文献[20]通过预训练的单结构神经网络模型在Flickr15k数据集上mAP为47.38%,而文献[34]通过三重网络在Flickr15k数据集上提高了检索性能,达到了54.48%,证明了通过增加神经网络结构可以提高检索效果。而文献[27]和文献[59]的实验数据相比,两者都是通过孪生神经网络添加注意力机制在SYSU-MM01数据集上进行实验,但是文献[59]针对红外图像提出了新的损失函数帮助检索性能提高了14.1个百分点。文献[32]和文献[66]则证明了通过对特征进行二进制编码可以有效提高检索效率,两者的检索时间分别为3×10-2s和6.5×10-5s。文献[44]通过孪生神经网络解决数据过少的问题,文献[80]则利用编码器解码器生成样本来解决图像域之间的鸿沟,实验结果从原有的87.1%提高到了99.9%,证明了图像域迁移的方法可以解决跨域图像检索问题。文献[90]利用生成对抗网络生成新样本并获得了89.14%的检索结果,但是其性能没有特征空间迁移方法中文献[31]的高,表明图像域迁移方法想进一步提高需要完善生成模型的性能。
综上所述,随着针对图像特征、网络结构和各类损失函数的改进,基于特征空间迁移的跨域图像检索方法性能逐渐增强,检索精度较高,但是关于检索速度以及内存占用方面没有提及。而针对编码空间建模的方法加入了哈希学习后,精度上有所下降,但是在轻量化模型方面取得了不错的效果,因此如何保证精度的情况下减少检索时间和内存占用是未来需要研究的内容。基于图像域迁移的跨域图像检索方法是未来最值得关注的方向,随着生成模型的性能提高,越来越多的跨域图像检索领域开始使用生成模型减少图像域之间的鸿沟,此外在训练样本不足时也能通过生成模型增加样本数量,帮助模型学习特征。虽然在精度上没有基于特征空间迁移方法突出,但是由于对训练样本没有过高的要求,也让它成为近年来最热门的研究方向。
6 总结与展望
跨域图像检索是一个重要的研究课题,旨在解决跨视觉域图像检索时的域间差异。本文深入分析了跨域图像检索问题,对跨域图像检索进行了综述,以促进相关研究。实现跨域图像检索对于社会多个领域研究有着重要意义,随着上述方法取得了一定成果,跨域图像检索的方法也在不断改善和发展,但是目前也有一些问题需要未来进一步解决。
(1)模型的自适应。现有跨域图像检索方法都是针对固定两个域之间的,所提出的方法确实能够在两个特定视觉域之间获得理想的检索结果。然而,它们无法泛化到其他两个域之间进行检索,而是需要重新训练模型。随着图像域种类越来越多,为不同视觉域都训练一个模型不现实。因此未来可以利用迁移学习的优势,将在一个视觉域训练的模型自适应地迁移到另外一个视觉域,以此提高模型的泛化能力。
(2)基于特征空间迁移的弱监督方法。在基于特征空间迁移的训练过程中,需要大量的样本作为训练集。而如今多领域的跨域样本数量并不能满足需求,因此基于特征空间迁移的模型可能会面临过拟合的问题。在未来,设计在弱监督环境下使用的特征空间迁移方法是研究者需要研究的方向。
(3)模型实际部署。现有方法通过添加不同功能的分支结构达到了提高跨域检索准确度的目的,但是受到实际应用时设备的限制,这种方法无法在现实的移动设备中部署。因此,探索更轻量化的跨域图像检索模型也是未来研究的趋势。
(4)模型不可跨多域检索。两个域之间的图像检索是研究人员主要的研究方向,但是在大数据的背景下对于模型可以跨多个域的检索能力赋予了更大的期待。在未来,一定会有多视觉域的大型数据集,所以跨多域图像检索是该领域的一个研究难点也是未来需要突破的方向。
