基于集成算法的上市公司财务困境预警模型
2022-08-09陈辉远姜慜喆冯家兴
陈辉远,姜慜喆,冯家兴
(1.武汉理工大学 安全科学与应急管理学院,湖北 武汉 430070;2.华中科技大学 管理学院,湖北 武汉 430070)
改革开放以来,我国社会主义市场经济飞速发展,市场环境日新月异,各个行业的竞争日益激烈,对公司而言,决策稍有不慎就会陷入财务困境。财务困境是指企业现金流量不足以补偿现有债务的情况,是导致企业出现生存危机的重要因素。公司财务困境不仅给公司股东与利益相关者带来直接损失,如果大量上市公司同时出现财务困境,也会影响金融市场的发展,进而整个经济环境会遭受巨大的冲击。因此,在财务困境出现之前就对公司发出预警,使公司能够及时应对或者规避可能发生的财务风险,对公司风险管理具有重要意义[1]。
目前的财务困境预警研究主要集中在指标选取和模型优化这两个纬度,在指标选取方面,传统的判定指标仅包含了财务指标,但近年研究表明,一些非财务因素同样会影响公司财务的稳定性[2]。在模型优化方面,以往的研究通常使用统计学分析方法,但统计学方法依赖于限制性假设,存在一定的局限性。随着信息技术的发展,机器学习已成为目前财务困境模型构建的主流方法。
在样本选取方面,以往的大多数研究是基于平衡数据集进行预测,即将财务困境公司和财务正常公司的比例设置为1∶1。但上市公司财务困境预警问题是一个典型的非平衡问题,因为财务困境公司的数量要远远小于财务正常公司的数量,极可能导致构建的模型不能全面地反映真实的公司财务困境情况。石晓军等[3]研究发现,当选择少数类和多数类样本比例达到1∶3时,模型泛化性能最强。故笔者按照1∶3的比例选取财务困境公司与财务正常公司,以提高财务困境预警结果的真实性。
目前的研究大多致力于提升不同机器学习模型的准确性,较少研究不同非平衡数据集对模型预测的影响。基于此,笔者对比分析在平衡数据集与非平衡数据集下多种单分类器模型与集成分类器模型的表现,选出更适用于财务困境预警指标体系的模型构建方式,提高上市公司对财务困境的预警能力。
1 文献综述
1.1 财务困境预警指标选取
传统的财务困境预警指标大多使用财务指标,其可以反映企业生产经营的过程和成果,主要包含偿债能力指标、运营能力指标、盈利能力指标和发展能力指标等。但由于财务指标主要来自财务报表资料,属于定量指标,大多数不包含影响企业长期竞争优势的因素,如企业内部治理结构等定性指标。由于目前的会计制度采取权责发生制的基本原则,公司内部人员可以通过这一制度虚构某些交易事项,实现对财务数据的操控,这在一定程度上影响了财务数据的真实性。因此笔者引入非财务指标完善财务预警指标体系,如TANG等[4]将公司管理指标引入财务困境预警指标体系中,综合考虑了董事会结构、股权结构、内部控制信息和审计意见等方面的信息,研究表明在财务困境指标体系中纳入管理指标能够提高模型的准确性。
1.2 财务困境预警模型研究
在模型优化方面,现有的模型分析方法主要分为两大门类,即统计学分析方法和机器学习方法。统计学方法主要包括判别分析(DA)、逻辑回归(Logistic)以及因子分析(FA)等,其中运用的最广泛的就是Logistic回归法,如宋鹏等[5]综合考虑财务、现金流和公司治理指标,建立基于Logistic回归的中小企业财务困境预警模型。但随着公司规模的扩大,传统的统计学方法已经不能很好地处理财务困境预警模型[6],且统计学模型依赖于限制性假设,如需服从正态分布、具有独立性和线性关系,这些都限制了统计学模型在财务困境预警方面的有效性和适用性。
随着人工智能技术的发展,机器学习在财务困境预警模型优化财务方面取得了很好表现。集成算法是一种新的机器学习范式,它将多个基分类器结合起来解决同一个问题,并使用某种特定的规则整合各个基分类器的输出结果,往往可以获得比单个分类器更好的学习效果,显著地提高学习系统的泛化能力。2004年,谢纪刚等[7]首次将集成分类器应用于上市公司财务困境预警研究,以决策树和神经网络为子分类器,从实验上证实了集成分类器在提高财务困境预警准确性方面的有效性。集成算法按照个体学习器之间的关系,可以分为Bagging、Boosting、Stacking三大类。Bagging是基于自助采样法获取随机样本集进行训练的不同的基学习器,然后对不同的基学习器得到的结果投票得出最终的分类结果。CHOI等[8]提出了基于投票的集成算法,预测建筑行业承包商在预测点两年前和三年前是否会发生财务困境,帮助业主避免项目期间因财务困境造成的损失。Boosting通过反复学习得到一系列弱分类器,以及把弱学习器组合提升为强学习器的过程。SUE等[9]构建DT、LR以及SVM三个基分类器,分别使用Bagging和Boosting的方法集成这3种分类器,结果表明,Bagging-DT和Boosting-DT在财务困境预警方面具有更高的准确度。Stacking是将测试集和预测集用所有训练好的基模型对整个测试集或者训练集进行预测,最后基于新的训练集或测试集进行训练或预测的过程。KIM等[10]利用Stacking算法集成SVM、NN和DT三个模型,调查1988年至2010年间美国酒店公司财务困境的主导因素,提高了预测方法的性能和准确性。
因此,笔者提出基于集成算法的财务困境预警模型,结合财务指标和非财务指标,利用合成少数类过采样技术(SMOTE)处理非平衡数据,采取遗传算法提取有效特征,通过构建多个单分类器和集成分类器来预测财务困境,为上市公司建立财务困境预警机制提供经验。
2 研究模型
财务困境预警模型的研究中,国外研究大多依据企业是否破产[11]来对财务困境进行分类。在国内,由于破产或者退市上市公司数量较少,因此一般采用是否被特殊处理(ST)作为企业陷入财务困境的标志[12]。根据中国证券上市交易规则,财务状况和其他财务状况异常的上市公司将被指定为ST公司,其中异常主要有两个原因:①上市公司经审计连续两年的净利润均为负值;②近一年经审计的每股净资产低于股票面值。这意味着预测上市公司近两年的财务困境情况意义不大,因此笔者将ST公司首次被ST年度前3~5年的数据带入运算,充分发挥它的预警功能。
笔者利用财务指标以及管理指标搭建财务困境预警指标体系,使用7种常见的机器学习算法构建上市公司财务困境预警模型,框架如图1所示。总体可分为3步:数据获取、数据预处理和特征工程及模型构建。从国泰安数据库(CSMAR)和中国研究数据服务平台(CNRDS)中获取所需的财务指标与管理指标,将其分别储存在T-3数据集、T-4数据集和T-5数据集中。再利用SMOTE过采样技术对非平衡数据集进行处理,使用遗传算法进行特征选择,最后通过模型评估指标判断模型性能。
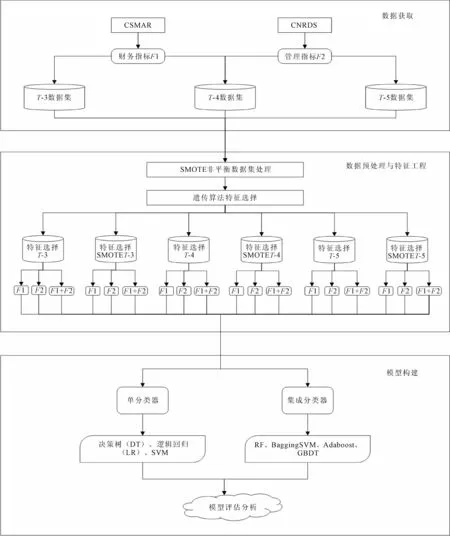
图1 财务困境预警研究框架
2.1 数据获取
笔者选择了271家在2012—2020年被首次列为ST的上市公司,其中2012—2020年的ST公司数量分别为20、14、26、21、26、24、28、48、64,并按照“行业相同,资产规模相近”的原则选择与之相匹配的健康样本。由于被列为ST的公司仅占中国上市公司的小部分,健康公司与ST公司在数量上具有明显的不平衡性,故按照1∶3的比例选取了2012—2020年的813个健康公司作为对照样本。实验所需的财务指标和管理指标分别从CSMAR和CNRDS获得。
2.1.1 财务指标选取
财务指标是最能反映财务状况和经营成果的相对指标,但不是所有的财务指标对财务困境预警都有用。笔者在已有研究的基础上,从盈利能力、偿债能力、比率结构、营运能力、发展能力和每股指标6个方面通过CSMAR数据库收集了55个财务指标,如表1所示。此外,笔者使用ST公司首次ST年度前3年、前4年和前5年的指标来进行财务困境预测,即如果1个公司在2020年首次成为ST公司,将获取该公司2017年(T-3)、2016(T-4)和2015年(T-5)的所有相关指标。获得的数据分别存储在T-3、T-4和T-5数据集中。
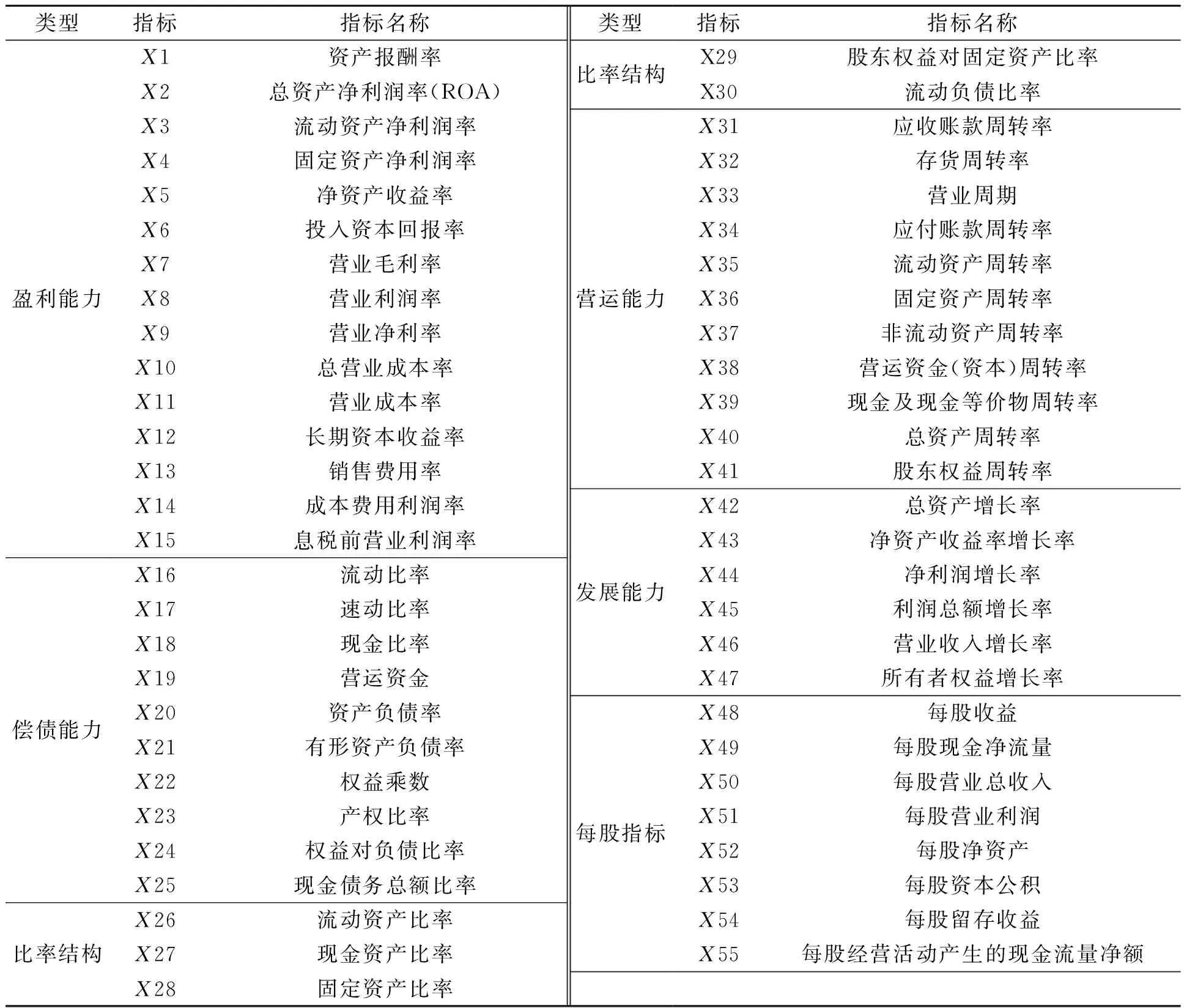
表1 财务指标
2.1.2 公司管理指标
由于我国外部企业治理尚未完善和成熟,上警方市公司的内部治理结构同样也是财务困境发生的重要影响因素[13]。笔者从董事会结构、股权结构、内部控制信息和审计信息4个方面收集了14个公司管理指标,如表2所示。

表2 管理指标
2.2 数据预处理与特征工程
首先对3个原始样本集中的缺失值用每列数据的均值进行填补,并对变量进行归一化处理。由于采取1∶3的比例选取对照健康公司样本,数据具有明显的不平衡性,如果直接运用该数据集进行建模,预测时很可能会偏向多数类的健康公司,使模型性能大打折扣。笔者选取SMOTE算法对预处理后的三个样本集进行均衡化处理,SMOTE算法即合成少数类过采样技术,是基于随机过采样算法的一种改进方案,其基本思想为对少数类样本进行分析,并将少数类样本人工合成新样本添加到数据集中,得到T-3 SMOTE、T-4 SMOTE和T-5 SMOTE共3个新样本集。
近年来,许多研究表明机器学习算法的效果容易受不相关和冗余特征的负面影响,进行特征选择不仅可以减少训练时间,剔除冗余特征,同时可以增强模型泛化能力,防止过拟合。特征选择方法可以被大致分为3类:filter法,wrapper法以及混合算法。LIANG等[14]通过实验对比了多种特征选择方法对财务困境预警的影响,发现基于wrapper法的遗传算法在处理财务困境问题时具有优越的性能。遗传算法具有良好的全局搜索能力,当其用作特征选择的搜索策略时,可以在考虑分类准确率的同时兼顾特征子集的目标函数,从而获得更好的分类性能。此外,LIU等[15]通过基于遗传算法的Bagging模型分析2005—2014年中国上市公司财务指标,为公司财务风险管理提供有效的支撑,再次验证了遗传算法在财务困境预面的优越性。综上,笔者基于遗传算法对T-3、T-3 SMOTE、T-4、T-4 SMOTE、T-5和T-5 SMOTE共6个样本集进行特征选择。
2.3 模型构建
笔者对比分析了3种单分类器以及4种集成分类器在财务困境预警方面的预测性能,3种单分类器分别是决策树(DT)、逻辑回归(LR)、SVM,4种集成分类器分别是随机森林(RF)、Adaboost、BaggingSVM以及梯度提升树(GBDT)。
2.3.1 单分类器
决策树(DT)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图结构来呈现这些规则,其中根节点和每个内部节点都表示1个特征值的测试,每个叶字节点代表1种类别标签,具有模型复杂度低、可解释性高等多种优点。逻辑回归(LR)是一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,被广泛应用于二分类问题中的广义回归算法,由于逻辑回归在线性问题上表现良好,并且训练速度较快,因此被广泛地应用在金融领域。SVM模型通过在数据空间中找出一个超平面作为决策边界来对数据进行分类,并使分类误差尽量小来找到全局最优解,能够很好地解决高维数据的非线性分类问题,使得该模型在各类研究中被广泛利用。
2.3.2 集成分类器
笔者使用的4种集成算法分别属于Bagging法(随机森林、BaggingSVM)和Boosting法(Adaboost、GBDT)。Bagging法通过有放回抽样从原始样本集中抽取n个训练样本,通过k轮抽取获得k个相互独立的训练集,按照平均或多数投票方法来组装基分类器的分类结果。随机森林和BaggingSVM分别以决策树和SVM作为基分类器,集成所有的分类投票结果,将投票次数最多的类别指定为最终输出。该方法可以降低噪声对分类效果的影响,提高分类效果的准确性。Boosting法的主要思想是将弱分类器整合成一个强分类器,Adaboost通过加权多数表决的方式将弱分类器进行线性组合,在减少错误率高的分类器的权重的同时增加错误率小的分类器的权重。而GBDT则通过拟合残差的方式逐步减小残差,将每一步生成的模型组合得到最终的模型。Bagging法和Boosting法都是将弱分类器组装成强分类器的算法,但由于Bagging法选取的是独立同分布的训练集来训练基分类器,而Boosting训练集的每一次选择的训练集都根据上一次学习的错误率结果取样,因此Boosting法的分类精度在大多数数据集中要优于Bagging法。
2.4 评估指标选取
选择合适的模型评估指标对判断不同模型的效果具有重要的意义,在面对非平衡数据集的时候,需要寻找捕获少数类的能力和将多数类判错后所付出的成本进行平衡,因此笔者选取混淆矩阵和AUC曲线作为模型的评估指标。
混淆矩阵中包含4个参数,分别为真阳性(TP)、真阴性(TN)、假阳性(FP)以及假阴性(FN)。在财务困境预警模型中,财务困境企业被定义为阳性样本,财务健康企业被定义为阴性样本。笔者基于混淆矩阵选择了4个表示类别性能的评估指标:准确率、精确度、召回率和F值。
准确率(Accuracy)是所有预测正确的样本占总样本的比重,从整体判断模型的分配效果,如式(1)所示。
(1)
精确度(Precision)表示所有被预测为正确的样本占全部预测为正确的样本的比例,是多数类判错后所需付出成本的衡量。如式(2)所示。
(2)
召回率(Recall)表示所有预测为正确的样本占实际的正确样本比例。召回率越高,代表选出真正的财务困境样本就越多。如式(3)所示。
(3)
召回率和精确度是此消彼长的,为了同时兼顾两者,引入F值作为考量精度和召回率平衡的综合性指标。如式(4)所示。
(4)
AUC (Area Under Curve) 被定义为ROC曲线下的面积,ROC曲线是以假正率和假负率为轴的曲线,所以AUC表示预测为正的概率比预测为负的概率高的可能性。AUC的取值范围一般在0.5和1之间,当AUC大于0.9时,则模型表现优异。
3 实证分析
3.1 特征选择结果
笔者采取遗传算法对SMOTE处理前后的T-3、T-4、T-5数据集进行特征选择,特征选择结果如表3所示。在T-3、T-3 SMOTE、T-4、T-4 SMOTE、T-5和T-5 SMOTE 数据集中分别选择了32、41、32、41、36和33个指标,其中,T-3数据集和T-4数据集在经过均衡化处理后,选取指标的数量有明显提升,而T-5数据集则没有太大变化。从指标选取的总体情况来看,6个数据集平均选取了29.3个财务指标,占55个财务指标的53.27%;选取了6.5个管理指标,占14个管理指标的42.85%。财务指标的选取比例要略高于管理指标,故财务指标在指标选取中具有更明显的价值。在29.3财务指标中,平均选取了10个盈利能力指标,4.2个偿债能力指标,2.2个比率结构指标,5.3个运营能力指标,2.8个发展能力指标和4.8个每股指标,在每个细分指标总数中的占比分别为66.67%、42%、44%、48.18%、46.66%以及60%,由此可见盈利能力指标在财务指标中是贡献最突出的指标。同理分析管理指标,董事会结构、股权结构、内部控制信息和审计意见分别选取了2.7个、1.2个、1.8个和0.8个,在每个细分指标总数中的占比为0.54、0.4、0.45和0.4,可得出董事会结构为管理指标中贡献最突出的指标。
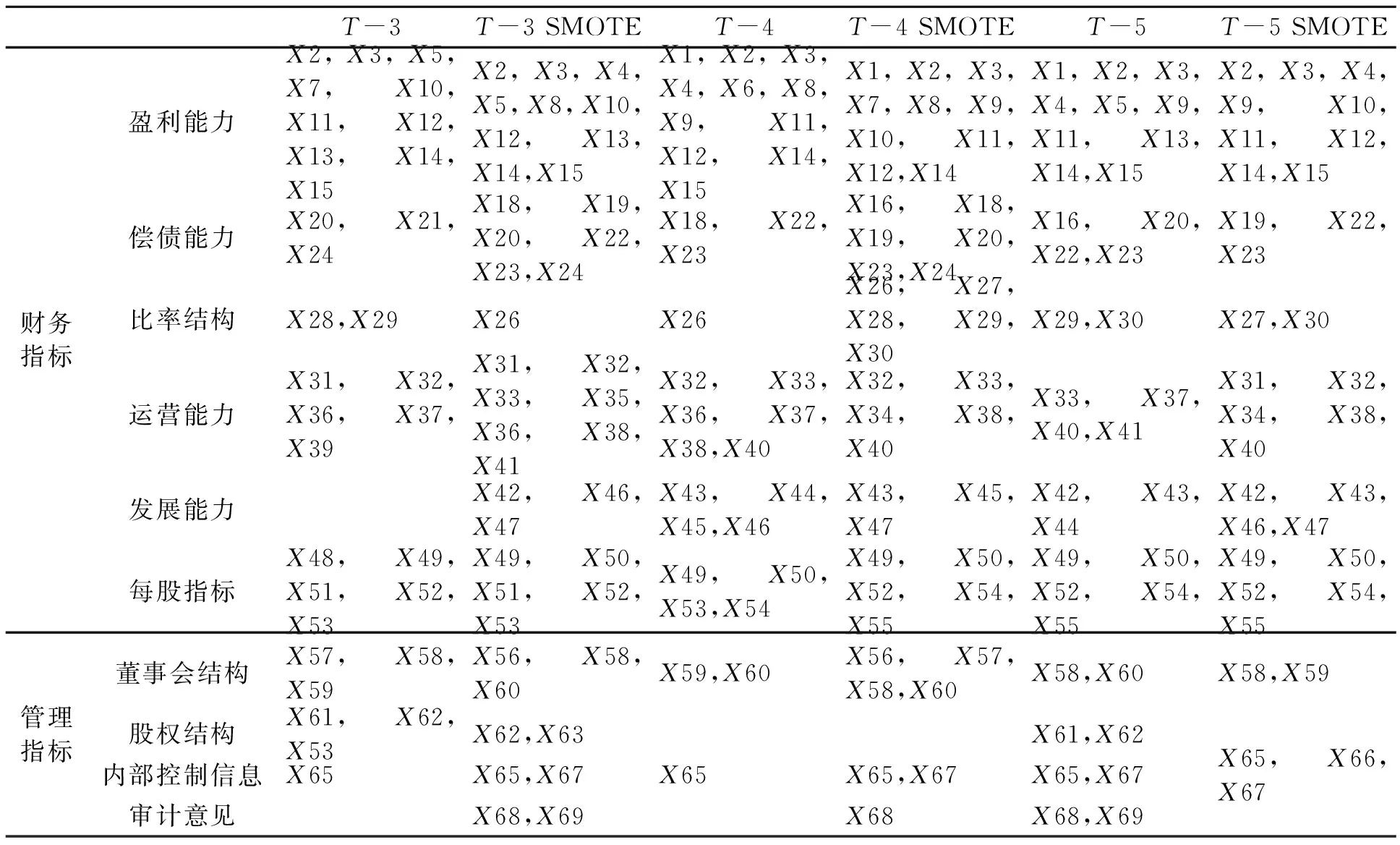
表3 遗传算法特征选择结果
3.2 模型评估结果
笔者根据遗传算法特征选取结果,得出了不同模型在各个数据集上的评估指标。如表4、表5所示。
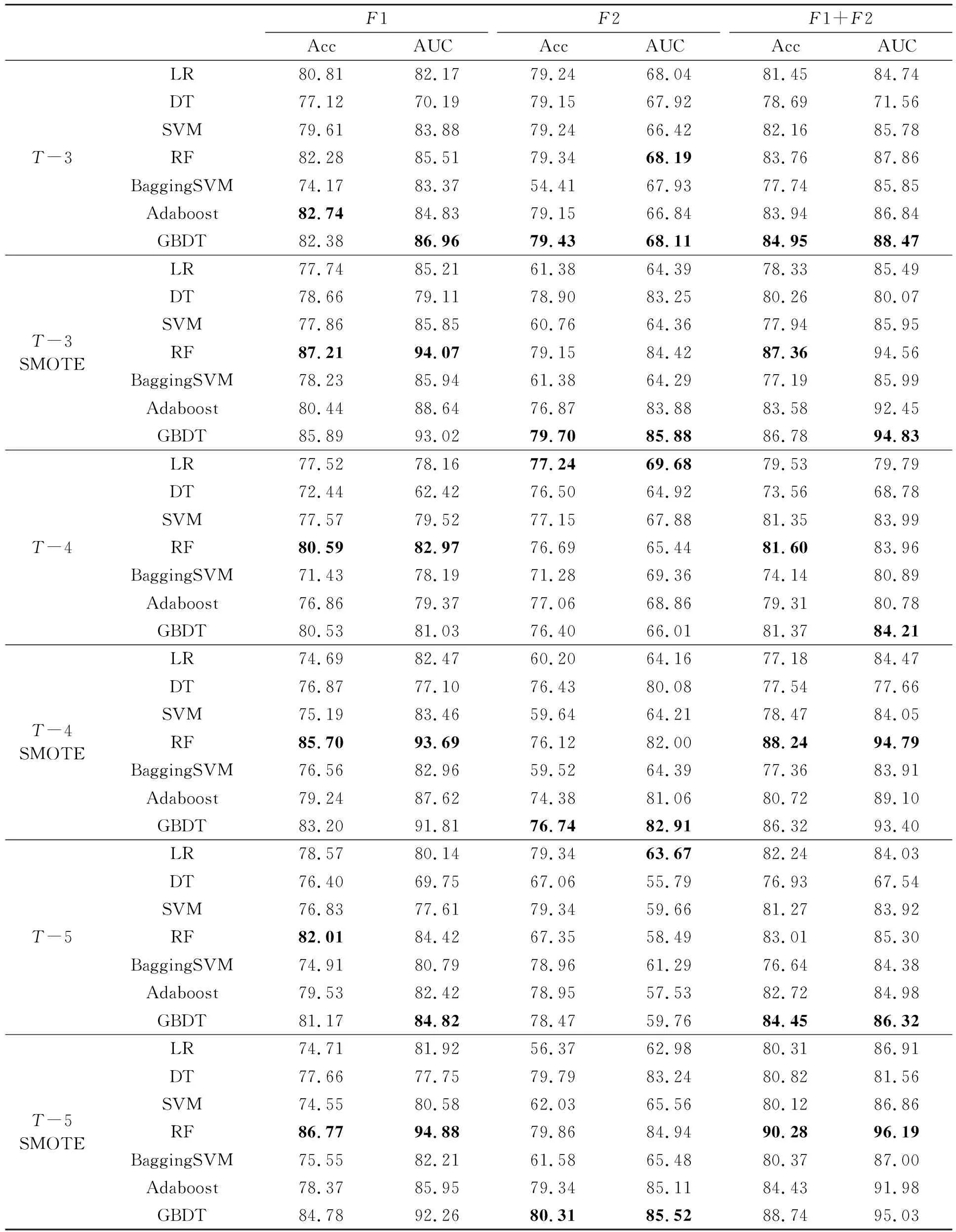
表4 准确率、AUC值评估效果
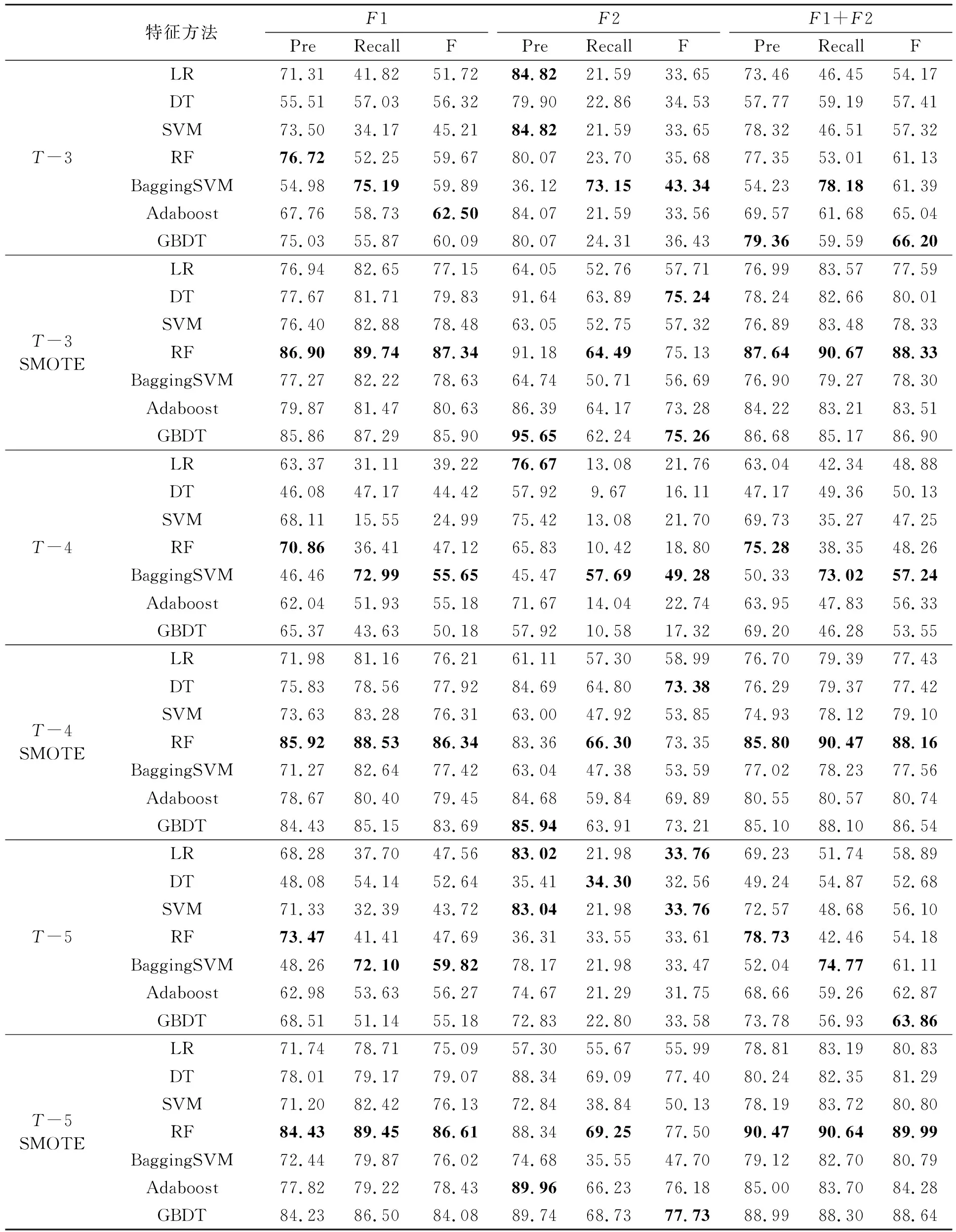
表5 精度、召回率和F值评估效果
表4是不同模型在准确率和AUC曲线上的表现,其中每个数都是十次交叉验证后的平均值,每个数据集下模型的最大值以粗体表示。传统的模型评估中准确率表现优异,但在面对非平衡数据集时,准确率会使模型严重偏向占比更多的类别,无法正确地评估多数类样本和少数类样本的错分代价,导致模型的预测效果严重失真。经过SMOTE技术对非平衡数据集进行处理后,AUC值得到了明显提高。在非平衡数据集中,无论是仅考虑财务指标还是综合考虑财务指标及管理指标,均为T-3年度表现最优,其中F1(T-3)为86.96%,F1+F2(T-3)为88.47%,然后是T-5年度和T-4年度。但在平衡数据集中,T-5年度有着最高的AUC值,F1(T-5 SMOTE)为94.88%,高于F1(T-3 SMOTE)和F1(T-4 SMOTE)。SMOTE在处理低维数据F2时能显著地提升模型效果,平均提升值为15%。由此可见,进行SMOTE处理不仅对模型性能有大幅度提升,同时能够实现在更长的时间区间上进行财务预警。在进行非平衡数据集处理前后的3个时间跨度中,RF和GBDT在F1和F1+F2内都取得了优异的性能。如果仅考虑管理指标,逻辑回归也有着出色的表现。
表5比较了LR、DT、SVM、RF、Bagging SVM、Adaboost和GBDT在T-3、T-4和T-5三个时间跨度上非平衡数据集处理前后的模型的精度、召回率和F值,每个数据集下模型的最大值以粗体表示。在精度方面,无论是仅考虑财务指标还是综合考虑财务指标与管理指标,集成分类器都具有更好的分类性能,如RF和GBDT。RF在F1的3个时间跨度上均拥有最好的表现,经过SMOTE处理后,其在F1+F2上也表现良好。其中F1(T-3)为76.72%,F1(T-4)为70.86%,F1(T-5)为73.47%,F1+F2(T-3 SMOTE)为87.64%,F1+F2(T-4 SMOTE)为85.80%,F1+F2(T-5 SMOTE)为90.47%。GBDT在F1+F2(T-3)上表现较好,为79.36%。但是仅考虑管理指标时,单分类器如LR和SVM的表现更优。在召回率方面,非平衡数据集上表现最好的模型是BaggingSVM,平衡数据集上表现最好的模型是RF。召回率和精度是此消彼长的,如F1(T-3)中,RF模型的精度为76.72%,召回率为52.25%;但BaggingSVM模型的精度为54.98%,召回率为75.19%。经过非平衡数据集的处理后,召回率指标有着大幅度的提升,在F1、F2和F1+F2上分别提升了34.6%、33.6%以及30.1%,而精度指标提升幅度较小,分别为14.5%、9.5%和14.8%。由此可见,非平衡数据对召回率的影响高于对精度的影响。
F值是考量精度和召回率平衡的综合性指标,它被定义为精度和召回率的调和平均数。在非平衡数据集中,如果仅考虑财务指标或者综合考虑财务指标和管理指标,T-3年度表现最优,其次是T-5年度和T-4年度,但仅考虑管理指标时,T-4年度表现更优,然后是T-3年度和T-5年度。在平衡数据集中,仅考虑管理指标或综合考虑财务指标和管理指标时,均是T-5年度表现最优,再者是T-3年度T-4年度,而仅考虑财务指标的则是T-3年度表现更优。说明在数据平衡后,仅考虑财务指标的数据在短期财务困境预警上的表现更好,而综合考虑财务指标和管理指标的财务困境预警模型能够为更长时间区间上的预测效果提供支撑。
6 结论
笔者构建包含财务指标和管理指标的上市公司财务困境预警指标体系,利用SMOTE过采样技术对非平衡数据集进行处理,运用遗传算法对财务指标和管理指标进行特征选择,并通过3种单分类器(DT、LR、SVM)和4种集成分类器(RF、BaggingSVM、Adaboost、GBDT)建立财务困境预警模型,采取多种评估指标综合评判模型性能。结论如下:
(1)选取2012—2020年被列为ST公司的271家上市公司,并使用1∶3的比例选取813家健康公司作为对照组,通过CSMAR和CNRDS数据库获取所需的财务指标和管理指标,建立T-3、T-4和T-5三个时间跨度上的非平衡数据集,运用SMOTE技术对其进行处理得到T-3 SMOTE、T-4 SMOTE和T-5 SMOTE三个平衡数据集。实验证明进行非平衡数据集处理能大幅度提高模型性能,加强财务困境预警的准确性。
(2)根据遗传算法进行特征选择可知,财务指标的价值高于管理指标,财务指标和管理指标中贡献值突出的指标分别是盈利能力指标和董事会结构指标。对比各个模型的评估指标后发现,集成分类器在财务困境预警问题上表现更好。
(3)后续研究可以从以下两方面来优化财务困境预警问题:①利用深度学习算法构建财务困境预警模型,如DNN、RNN和BPNN等;②在财务指标和管理指标的基础上加入文本指标构建财务困境预警指标体系,进一步为财务困境预警提供理论支撑。
