基于自适应知识选择的机器阅读理解
2022-08-02李泽政田志兴张元哲
李泽政,田志兴,张元哲,刘 康,赵 军
(1. 中国科学院 自动化研究所 模式识别国家重点实验室, 北京 100190;2. 中国科学院大学 人工智能技术学院, 北京 100049)
0 引言
随着互联网、人工智能行业的迅猛发展,网络空间中的数据规模以指数级速度增长。文本阅读理解作为验证理解文本数据的重要手段,在近些年来也迎来了蓬勃发展。该任务在形式上表现为:给定问题,系统要求根据给定的文档输出正确答案。近年来,得益于海量数据的大规模获取和深度学习的方法的应用,机器阅读理解任务取得了长足的进展。
尽管经典的机器阅读理解模型已经在一些简单的测试样例下取得了很好的性能,然而在面对更为复杂且贴近真实应用场景的情况时,已有方法的表现仍然捉襟见肘,在需要推理的场景下问题尤为突出[1-5]。
目前,已有部分工作通过引入外部知识尝试去解决这个问题。如Chen等[1]、Wang等[2]、Yang等[3]主要采用注意力机制融入外部知识;Mihaylov等[4]和Sun等[5]主要采用记忆网络机制融入外部知识;除此之外,Weissenborn等[6]尝试动态融入外部知识,Bauer等[7]采用多跳方式融入外部知识。然而,上述这些方法主要关注的是如何把特定的一个或多个来源的知识融入模型中,却忽略了知识来源选择的问题。引入外部知识时如果对来源不加以区分,可能会给模型输入噪声,进而干扰模型对文本的理解和推断,最终影响模型的测试性能。
如图1所示,该机器阅读理解样例的测试目标是根据给定的故事文本推断其结尾,假设在引入外部知识时,模型有两个知识来源:WordNet[8]和ConceptNet[9]。其中关键词“dinner”的解释分别为:dinner的同义词是supper,dinner是一种“good time to gather”。由于神经网络模型天然具有数据关联的特性,来自于WordNet的“supper”与错误答案E1中的“supper”具有显著的自相关特性,所以模型容易被误导从而导致选择错误答案。而来自于ConcpetNet的“good time to gather”与正确答案E0中的关键词“catch up”具有高度的语义相关性,所以模型更倾向于选择正确答案。

图1 故事结尾推断型机器阅读理解样例
事实上,在自然语言处理领域中,每个知识库都有自身的特点,如WordNet侧重于词语的上下位、同义词,而ConceptNet更侧重于对词语本身概念的解释与语义扩展。如果引入的外部知识库并不包含对回答问题有帮助的知识,则无论采用何种知识融入方式都相当于引入噪声,这反而会降低模型性能。因此本文重点在于探讨如何根据给定文档和问题,自适应地匹配对回答问题有帮助的外部知识库。
本文提出了一种针对机器阅读理解任务进行自适应外部知识增强的方法。首先,根据上下文对多个外部知识库分别检索出对回答问题可能有帮助的知识。然后,基于注意力机制分别得到对每个来源的外部知识感知的上下文编码。接着通过硬性或软性的方式,自适应地确定最合适的外部知识来源,进而挑选出该来源知识感知的上下文编码。最后,将选择出来的编码融入原有模型选出最终答案。本文通过实验证明了对机器阅读理解任务自适应引入外部知识具有必要性和有效性。
本文的主要贡献有三个:
(1) 指出现有机器阅读理解任务中缺乏自适应选择知识源的问题;
(2) 针对该问题提出基于机器阅读理解任务的自适应知识选择模型;
(3) 基于两个常见外部知识库WordNet[8]和ConceptNet[9],在ROCStories[10]数据集的基线模型上准确率提高了1.2个百分点。
1 相关工作
最早的机器阅读理解研究可以追溯到1972年MIT人工智能实验室的一篇报告“Toward a model of children’s story comprehension”。半个世纪之后,微软2013年提出的MCTest[11]数据集、谷歌和牛津大学2015年提出的CNN/DailyMail[12]数据集、最为经典的为斯坦福大学2016年提出的SQuAD[13]数据集,以及基于神经网络的深度学习模型,把机器阅读理解任务推到了前所未有的高度。以抽取式机器阅读理解任务为例,Wang[14]基于RNN架构提出了Match-LSTM模型,Minjoon Seo[15]引入问题与文档之间双注意力机制提出了BiDAF模型,Wang[16]采用文档自注意力机制提出了R-Net模型。在不断涌出的新兴模型推动下,机器在简单机器阅读理解任务上的表现屡屡超过人类水平。于是,现有的机器阅读理解研究向知识增强、识别不可回答问题、多文档机器阅读理解、多跳推理等方向发展。
研究者们对基于机器阅读理解的知识增强任务做了大量研究。Long等[17]提出了一种类似于完形填空的缺失命名实体预测任务。该任务通过从Freebase知识库中检索得到的对于实体的描述用以辅助预测仅仅通过上下文无法预测出的实体。一些研究者对注意力机制按照符合机器阅读理解任务的特性进行改进。Chen等[1]提出了KIM模型,通过收集局部信息进行自然语言推理。Wang等[2]采用了三路注意力机制,分别对问题、文档和外部知识进行编码,从而融合来自外部知识库ConceptNet中的知识。Yang等[3]提出了KT-NET模型,通过打分机制和注意力机制融合来自外部知识库WordNet、Nell的知识。也有一些研究者在记忆网络上进行改进,Mihaylov等[4]把给定问题和从外部知识库检索到的知识作为键进行匹配,按照其相关性作为值进行打分。Sun等[5]在记忆网络的基础上根据外部知识的相关性对候选答案进行打分。
除了基于注意力机制和记忆网络机制以外,针对不同形式的机器阅读理解任务,研究者们也做了大量改进。Bauer等[7]针对生成式的多跳机器阅读理解任务提出了一种新的融合外部知识的方法。该方法基于互信息和词频的打分函数从外部知识库ConceptNet选择对给出答案可能有帮助的常识。Mihaylov等[4]针对完形填空式的机器阅读理解任务提出了一种把外部知识编码作为键值对进行存储的知识网络模型,有效地将上下文与外部知识进行交互融合。Weissenborn等[6]提出了一种通用的融合外部知识的架构,融合外部知识和上下文,和不同下游任务相连接,从而实现动态的融合外部知识。
此外,针对某个特定的外部知识库和某些特定的数据集,研究者们也做了具有针对性的工作。Wang等[19]为了充分利用WordNet的语义关系网,提出了语义关系链的概念,把位置信息作为一种特征融入上下文中。现有的知识库一般以结构化方式存储知识,Pan等[20]针对科学领域的经典问答数据集ARC和OpenBookQA提出了一种融合外部无结构化知识的方法,将来自外部知识库的关于实体的无结构化描述文本进行融合从而辅助选择正确答案。
针对ROCStories数据集,研究者们也提出了一些知识增强的机器阅读理解模型。Li等[21]提出了一种多注意力引入外部知识的方法,把常识引入端到端的神经网络模型。由于ROCStories的给定文档和候选项可以构成一个完整的生活化小故事,Chen等[22]把外部知识归为三类:叙述序列、情感演变和常识知识,对这三类外部知识进行端到端的融入。Tian等[23]提出了一种新颖的图迭代网络方法,把外部知识作为原子融入图网络,模拟人类进行阅读理解的习惯,从而再现每一个样例的场景。
2 模型与方法
为了让模型更好地引入外部知识,我们提出了自适应引入外部知识的方法,具体如图2所示,本文将模型分为三个部分:①问题与文档编码模块;②知识引入模块;③答案选择模块。其中,知识引入模块详解见2.2。
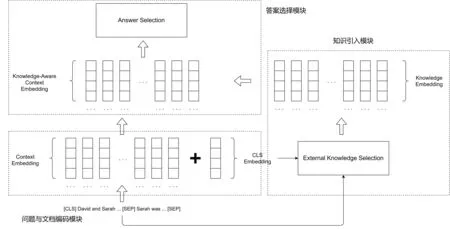
图 2 基于自适应知识选择的机器阅读理解模型框架图
针对问题与文档编码模块,本文采用BERT[24]模型作为上下文(问题与文档)编码模块。针对知识引入模块,我们首先根据上下文的自然语言文本从不同外部知识库中检索出相关知识,然后基于注意力机制得到每个外部知识库知识感知的上下文编码,再通过计算匹配度自适应选择外部知识融入模型。针对答案选择模块,我们通过融入外部知识的上下文编码对不同答案进行打分,以选择最终答案。
2.1 问题与文档编码
本文以预训练语言模型BERT作为编码器,输入句子以字符为单位表示为s={c1,c2,c3,…,ci,…,cl},其中l表示该句子的长度,即该句子中字符的个数。BERT模型的输入为字符序列,在机器阅读理解任务中,输入为[CLS]+q+[SEP]+d+[SEP],其中[CLS]和[SEP]为BERT模型输入的特殊处理字符,q表示问题,d表示文档。BERT模型输出为上下文每个字符对应的隐向量组成的编码(隐向量序列)和代表上下文全局的编码(单个隐向量)。其具体如式(1)所示。
其中,g(·)为BERT编码函数,c为代表上下文全局的单个隐向量,c∈Rd,h为代表上下文的隐向量序列,h∈Rl×d,d为隐层维度。
2.2 知识引入
知识引入模块如图3所示。我们首先基于注意力机制得到外部知识感知的上下文编码,然后依据具有上下文全局信息的编码对不同外部知识感知的上下文编码进行匹配,最后选择合适的外部知识感知上下文编码进行下一步的答案选择。
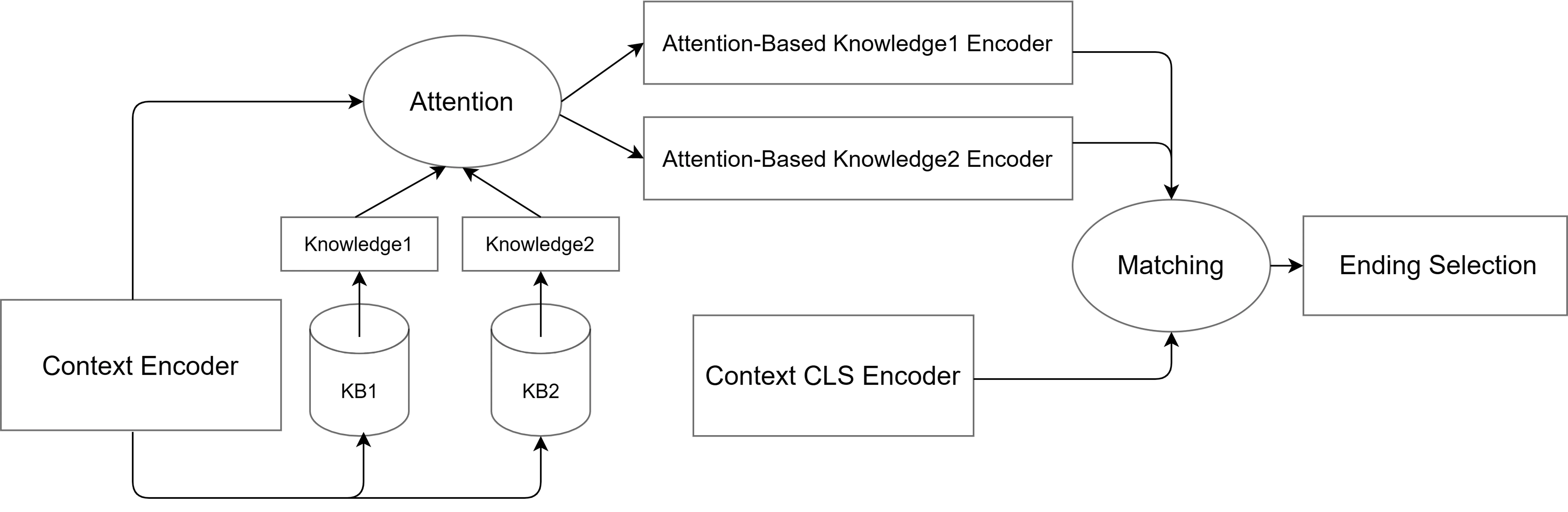
图 3 知识引入模块
2.2.1 基于注意力机制的外部知识感知的上下文编码
对于上下文编码h和外部知识编码k,外部知识感知的上下文编码计算如式(2)~式(4)所示。
其中,k由检索到的外部自然语言文本输入式(1)得到,k∈Rr×d,r为外部知识字符个数。αij为两个隐向量序列每一对单元的相关度。
其中,式(3)对式(2)得到的相关度进行归一化,式(4)以归一化的相关度分数权重对外部知识中每个字符的表示进行加权求和。
2.2.2 基于匹配度打分自适应选择外部知识
本文采用硬性和软性两种选择外部知识的方法,具体计算方式如下。
硬性选择外部知识: 将上下文和外部知识输入式(1),除了能得到h和k之外,还可以得到代表上下文全局信息的ch和代表外部知识全局信息的ck。ch和ck相关度计算如式(5)所示。
其中,s为一个标量,作为ch和ck相关程度的度量,ch,ck∈Rd。
对于多个外部知识库KB1,KB2,…,KBm,则得到多个相似度s1,s2,…,sm,其中,m是外部知识库的个数。自适应选择匹配度最大的那一个作为外部知识源融合原文档的语义表达,本文称之为硬性选择外部知识,如式(6)所示。
其中,v*为与原文档匹配度最大的外部知识感知的上下文编码。
软性选择外部知识: 对于经过注意力机制得到的外部知识感知的上下文编码,我们不仅可以对外部知识源进行硬约束,还可以对其进行软约束,即把来自不同知识库的外部知识加权融入上下文编码,如式(7)~式(9)所示。
其中,σ(·)是sigmoid激活函数,βi即加权因子,m是外部知识库的个数,ws是学习参数向量,vi,ws∈Rd,v*为与软性融合的外部知识感知的上下文编码。
2.2.3 融入外部知识
对于选择得到的外部知识编码v*,与式(1)得到的上下文编码h相加得到新的隐向量序列h*作为下一层神经网络的输入,如式(10)所示。
2.3 答案选择
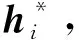
其中,wo∈Rh,该向量是一个参数矩阵,scorei为一个标量。最终选择打分最高的答案a*作为终选答案,如式(12)所示。
其中,n为候选答案个数。
3 实验
3.1 数据集和测试方法
本文采用ROCStories[10]数据集,该数据集由亚马逊众包平台上的工人制作得到。在该数据集的开发集和测试集中,每个样本都包含一个由4句话组成的文档和两个候选单句,其中两个候选单句分别为正负例,其样式如图1所示。本文与Cai等[25]、Chaturvedi等[26]、Cui等[27]、Tian等[23]设置相同,对3 742个样例进行五折交叉验证,评价指标为准确率(Accuracy)。
3.2 参数设置
3.2.1 实验细节
文档与问题编码模块采用BERT-Base模型,其网络层数为12层,隐层维度为768维,多头个数为12,参数规模为110M,占用现存7GB多。实验采用的优化器为Adam[28],Batchsize设置为32,初始学习率为0.000 1,以每轮0.95指数级递减。
3.2.2 外部知识库
WordNet是一个词典知识库。WordNet对名词、动词、形容词和副词等构建了一个语义网络,如“dinner”是“supper”的同位词。WordNet存储知识的格式以结构化数据为主。实验采用的WordNet知识库由Python包nltk加载得到。
ConceptNet是一个常识知识库。不同于WordNet,ConceptNet对各种常识概念构建了一个语义网络,如“dinner”通过“type of”与“good time to gather”相连接。ConceptNet(1)ConceptNet通过官方的API接口http://api.conceptnet.io/c/en/获取。存储知识的格式接近于非形式化、更贴近自然语言的样式。
3.3 基线模型
本文以在ROCStories数据集上进行实验的一系列模型作为基线模型。为简单起见,我们只列举了具有代表性的工作,如表1所示。
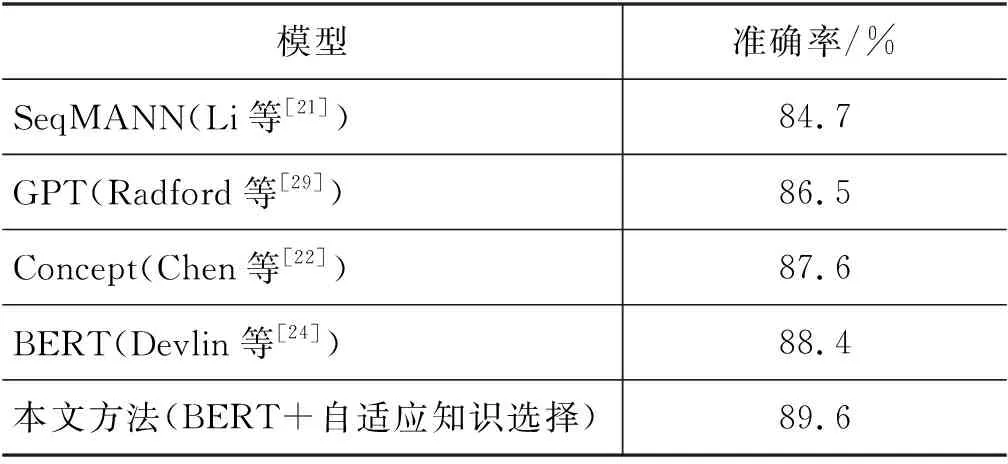
表1 ROCStories数据集各模型性能
SeqMANN:一个采用了多注意力机制引入外部知识的模型,该模型通过大量的无标注样例扩充数据集。
GPT:一个生成式的预训练语言模型,该模型在ROCStories数据集上进行微调。
Concept:一个引入多类知识的模型,该模型引入的外部知识库只有ConceptNet。
BERT:一个预训练语言模型,该模型在ROCStories数据集上进行微调。
3.4 实验结果与分析
3.4.1 与SOTA方法比较
实验结果如表1所示,本文提出的自适应知识选择的方法取得了SOTA的性能。本文方法比SeqMANN高出了4.9个百分点,这说明了BERT作为编码器和自适应选择的有效性。本文比Concept高出了两个百分点,这说明了采用多个外部知识库进行自适应选择的重要性。本文方法比BERT提高了1.2个百分点,比GPT高出了 3.1个百分点,这充分说明了自适应选择外部知识源进行知识引入的必要性。
3.4.2 自适应知识选择的有效性
本文进行以下对比试验,如表2所示: ①“+WordNet”指只引入WordNet一个外部知识库的知识;②“+ConceptNet”指只引入ConceptNet一个外部知识库的知识;③“+WordNet+ConceptNet”指同时引入WordNet和ConceptNet的知识且不加区分;④“+硬性选择WordNet/ConceptNet”指引入硬性选择两个外部知识库的知识;⑤“+软性选择WordNet&ConceptNet”指引入软性选择两个外部知识库的知识。
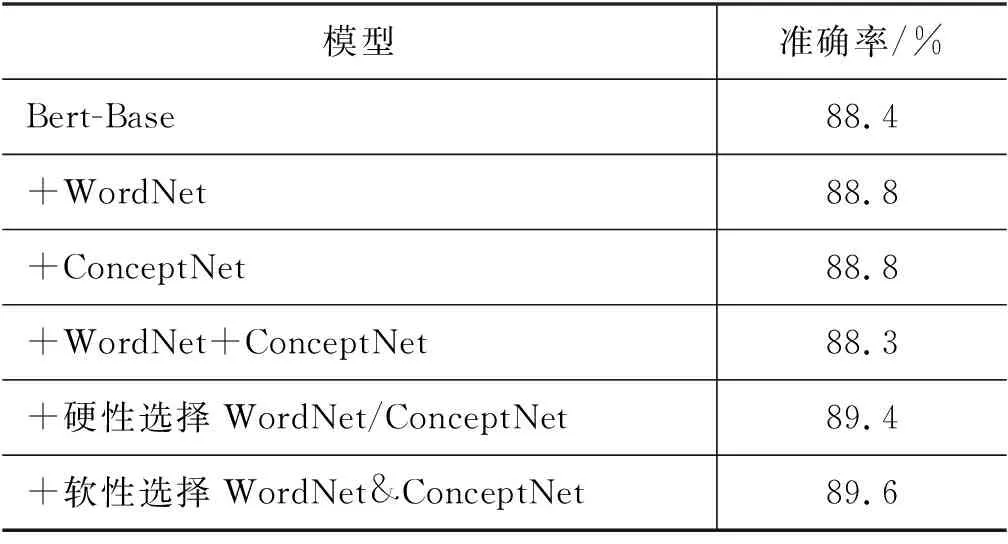
表 2 对比实验结果
“+WordNet”&“+ConceptNet”:在分别引入外部知识库WordNet和ConceptNet的知识之后,模型准确率都有了0.4个百分点的提升,这说明引入知识确实是有效的。
“+WordNet+ConceptNet”:当同时引入多个外部知识库的知识且不加区分时,性能比基线模型反而下降了0.1个百分点,这说明不加选择地引入知识可能会带来模型性能的损失。
“+硬性选择WordNet/ConceptNet”:当引入硬性选择的外部知识时,模型比基线模型高出1.0个百分点,这说明在机器阅读理解任务上对自适应引入外部知识是必要且有效的。
“+软性选择WordNet&ConceptNet”:当引入软性选择的外部知识后,模型性能有了进一步的提升,说明对多个外部知识源的知识进行加权融合,可以取得最佳的效果。我们推测在有限数据集下,软性选择可能在训练上更平滑,所以取得了更优的效果。
3.4.3 样例分析
为了更加直观地分析本文提出的知识选择机制,我们对测试集进行了采样分析,如图4、图5所示,其中数字表示模型内部选择外部知识时的打分,笑脸符号表示引入此知识使得模型得到正确答案,哭脸符号表示引入此知识使得模型得到错误答案。如图4所示,来自WordNet的(hockey,similar to,baseball)的打分为0.06,如果模型选择引入该知识,则可能误导模型选择错误答案E0。来自ConceptNet的(hockey,type of,game)的打分为0.94,如果模型选择引入该知识,由于“game”和“competition”具有高度的语义相关性,模型更倾向于选择正确答案E1。我们可以看出模型确实具有正确区分外部知识源的能力。
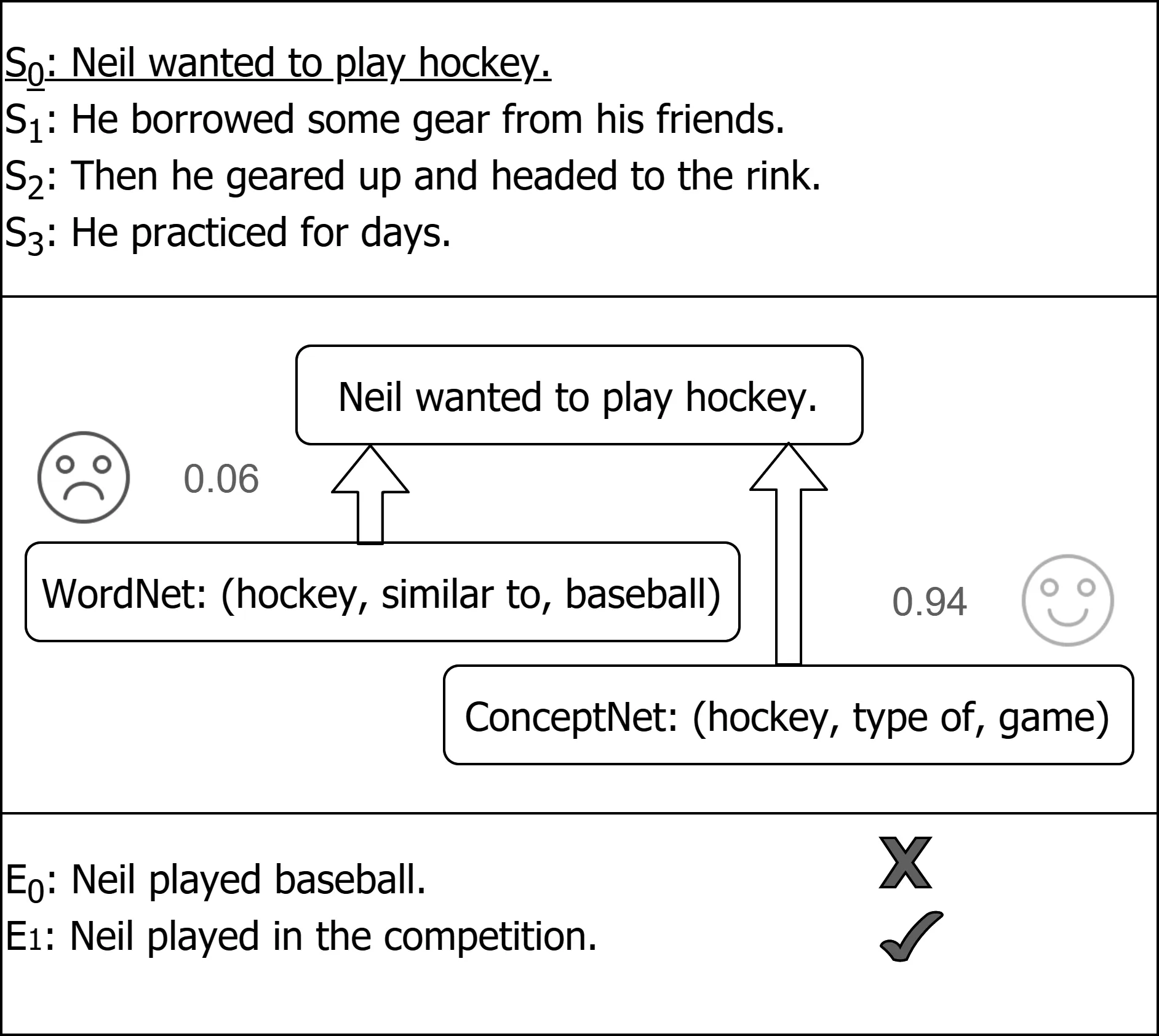
图 4 正样例
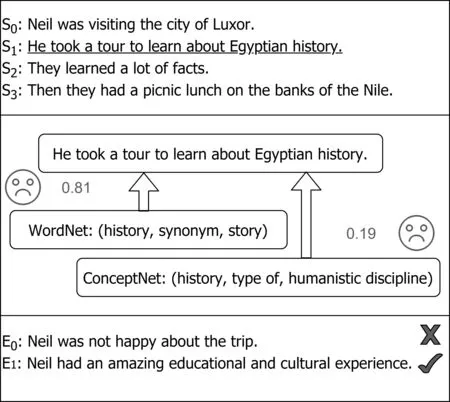
图 5 需要更多外部知识源的错误样例
在采样过程中,我们同样也发现了一些错误样例。通过对错误样例的抽样统计,可以发现模型判断错误主要集中在以下几个方面(表3),其中抽样数量为200。其中,“需要更多外部知识源”表示模型需要更多的外部知识库进行知识引入才能得出正确答案。“需要多跳推理”表示模型需要通过至少大于一步的推理链才能得出正确答案。“其他”表示模型即使通过引入外部知识或推理的途径也很难得到正确答案。如图5所示,无论加入来自何种知识源的外部知识,都不能有效地引导模型,反而会降低模型的性能表现。这说明我们需要进一步扩充多样化的外部知识源。如图6所示,如果想要得到正确答案,则需要从“candy”推理到“food”再推理到“kitchen”。扩充外部知识源和多跳推理可以作为下一步研究的方向。
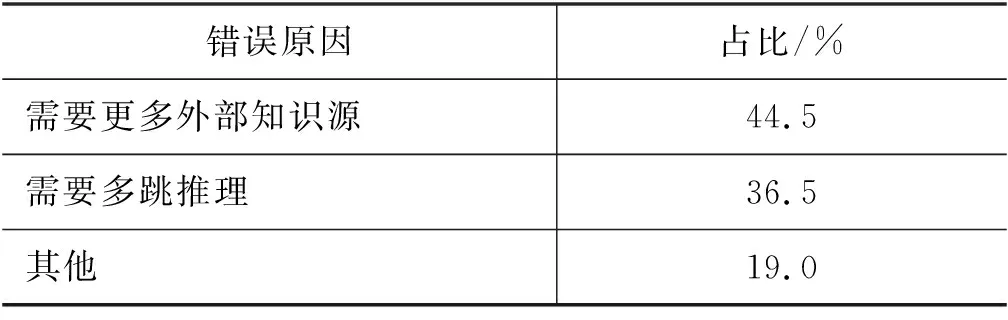
表 3 负样例错误原因比例分析
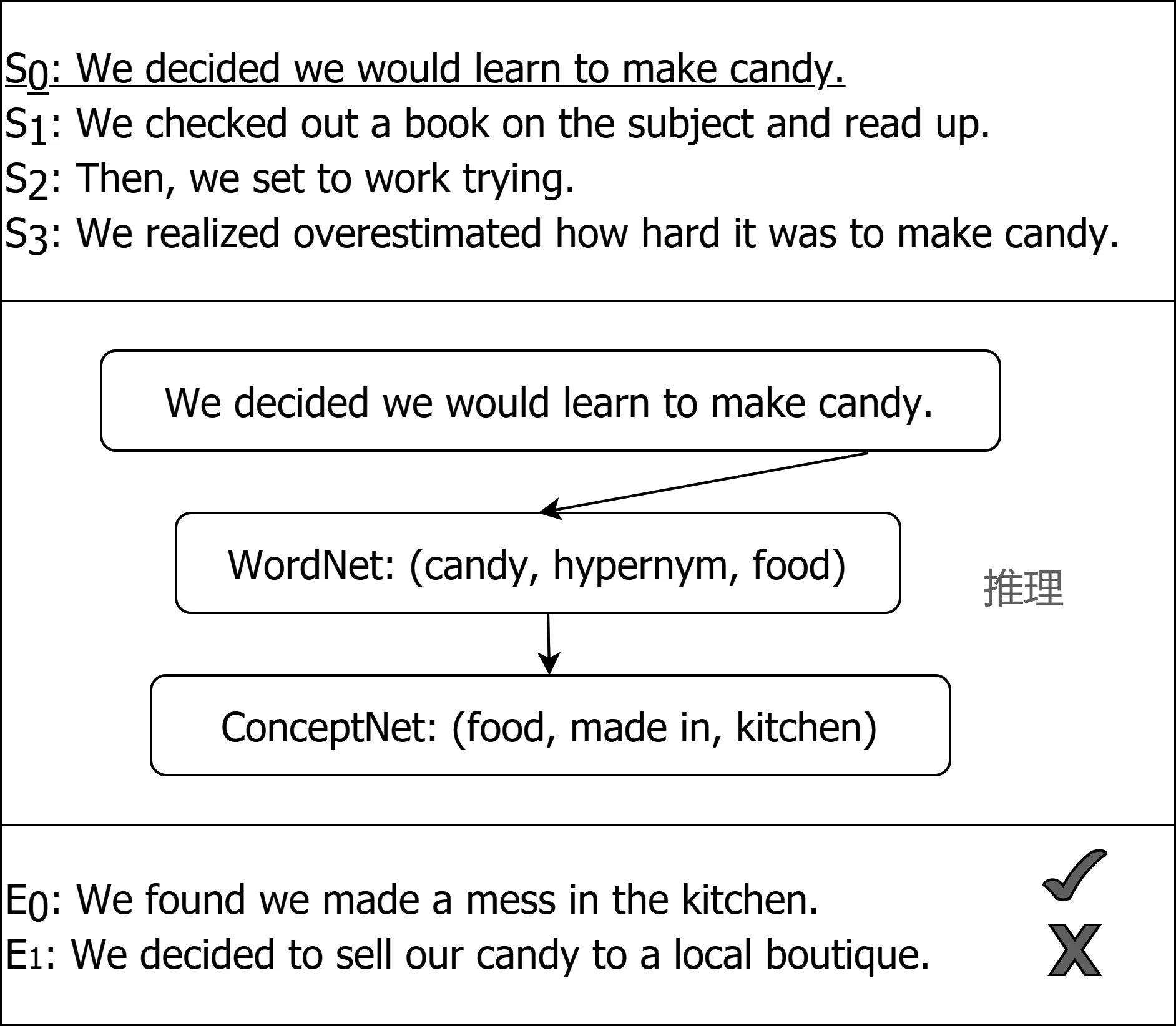
图6 需要多跳推理的错误样例
4 总结和展望
本文致力于引入外部知识来提升机器阅读理解模型的性能。与大多数已有方法不加区分地引入多种知识来源的方式,不同本文提出了一种根据上下文特点自适应选择外部知识来源的方法,以更有针对性地引入外部知识。为了验证该方法的有效性,本文在公开数据集ROCStories上做了充分的实验。结果表明,本文提出的自适应引入外部知识的方法能够较好地提升模型效果。在此基础之上,我们将进一步探索某些特定领域的自适应知识引入方法。
