低频词表示增强的低资源神经机器翻译
2022-08-02朱俊国杨福岸余正涛张泽锋
朱俊国,杨福岸,余正涛,邹 翔,张泽锋
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言
低频词翻译在神经机器翻译中是一个具有挑战性的问题。由于低频词在训练数据中出现次数较少,神经机器翻译模型一般不能充分地学习到准确的低频词的表示,从而影响神经机器翻译模型的性能。在低资源神经机器翻译中,低频词翻译问题则表现得更为突出,这是由于在低资源语言对上双语数据极度匮乏,导致低频词在模型中训练次数更少,使得低频词不能更好的学习到其表示形式。因此在低资源神经机器翻译中,低频词表示不准确的问题亟待解决。
目前,关于词表示增强的方法大致分为两类。一类是基于外部知识融入的方法。该方法通过融入先验知识,从而使单词具有更丰富的含义以达到增强词表示的目的,如融入词典和外部结构信息等。尽管基于外部知识融入的方法,随着外部知识的融入,可以达到增强词表示的效果,但是对于其难点,低频词的表示问题并没有解决,从而使得低频词的表示在现有的神经机器翻译模型中不能得到更好的训练。另一类是基于内部知识增强的方法,该方法通过单语数据重新学习词的表示形式,使词的表示形式包含更丰富的翻译信息,从而使得词的表示更加准确。这种基于单语数据词表示增强的方法兼顾到了词语的准确度和流利度,随机对词表中所有的词语进行表示增强。虽然该方法能在一定程度上缓解低频词表示不准确的问题,但是并没有覆盖所有的低频词。因此,该方法仍没有针对性地解决低频词翻译不佳的问题。
词表示增强方法的核心是如何更准确地学习到更准确的词表示形式,其难点是如何表示低频词。原始的低频词通过one-hot方法[1]表示,其表示形式存在维度过大和语义鸿沟问题。针对低频词翻译的问题,本文提出了一种利用单语数据重新学习低频词表示的方法。该方法采用了基于上下文软替换的思想[2],这种思想利用语言模型通过单语数据学习到更丰富的上下文信息。文献[2]采用随机软替换方法,并且没有针对低频词进行学习。而本文方法利用低频词在训练集单语数据的语言模型中的概率分布重新计算低频词的表示,以替代神经机器翻译中的one-hot表示。这种新的低频词表示能够充分获取单语数据信息,从而缓解低频词翻译不佳的问题。本文在汉-越、越-汉两个方向的低资源神经机器翻译任务中,基于低频词表示增强的翻译模型相对于基线模型在BLEU4[3]得分上分别提升了8.58%和6.06%。
1 相关工作
在神经机器翻译领域,词表示增强的核心问题是如何对低频词表示进行增强,即如何学习更准确的低频词表示。但是在资源稀缺型语言的神经机器翻译中,开展低频词表示问题的研究还相对较少。
针对词表示增强常用的方法可以分为以下两类。一类是基于外部知识融入的方法。Haitao等人[4]从短语统计机器翻译系统中获取词到词和短语到短语翻译知识,然后使用这些翻译知识限制神经机器翻译解码句子时的解码。这种方法在可以不加大训练复杂度的情况下,通过融入句子级词汇增强捕捉翻译歧义。Wang Xing等人[5]提出一种基于短语融入的方法,将统计机器翻译系统中的短语记忆存储的目标短语集成到翻译模型的编解码体系结构中。该方法通过引入短语级词汇改变了原有短语逐词翻译的模式,缓解了短语错配、翻译不当等问题。Huadong Chen等人[6]提出了一种基于句法树融入的方法,通过双向树编码器和树覆盖模型显式地结合源端句法树来改进神经机器翻译模型。Meishan Zhang等人[7]提出了一种基于语法感知词的方法,语法感知词由端到端依存句法分析器的中间隐藏形式表示,然后简单地将语法感知词与普通的词嵌入连接起来。该方法结合句法信息,在原有词语表示的基础上增加了句法信息。第二类是利用数据内部知识增强的方法,该方法没有加入外部知识,使用已有的数据进行翻译知识的获取,一般利用语言模型训练得到。Zhu等人[2]提出用概率分布(由语言模型提供)来随机代替词的one-hot表示。使用语言模型得到词典中每个词的概率分布,这个概率分布表示该词与词典中其他词的相关性,使用词典中所有词的词嵌入加权求和更新该词,加权求和的系数来源于语言模型中的概率分布,最后将所得表示输入到Transformer[8]翻译模型中。与第一类方法相比,该类方法更加准确地增强词的表示形式,让增强后词语的意思更加贴合句子的含义。这两类方法都能达到词表示增强的效果,但并没有针对低频词表示增强做研究。
2 模型
2.1 模型总体概述
神经机器翻译在翻译低频词时经常存在错译问题,由于低频词在训练数据中出现次数少,使得低频词在训练模型中不能够学习到很好的表示形式,导致低频词翻译效果不佳。在低资源神经机器翻译中,由于语料匮乏,低频词分布更加稀疏,使得低频词翻译性能在低资源神经机器翻译中表现更差。
本文通过在Transformer模型中引入语言模型与低频词词典来缓解低频词在神经机器翻译中表示不佳的问题,总体模型结构如图1所示。对于一个给定的源端与目标端句子对(X,Y),有X=(x1,x2,…,xT),Y=(y1,y2,…,yT′),通过语言模型得到每个词的概率分布[P(xi)],使用低频词词典DK确定源端X中的低频词词汇,例如x1,x3为低频词,用语言模型中对应词的概率分布更新原有的源端序列X,得到新的源端序列X′。 在翻译模型和语言模型中,每个词语都被分配一个唯一one-hot向量的ID,例如,词汇表大小为|V|,第i个词语将会用一个|V|维向量表示dk,其中第i维为1,其他维为0。通过更新后的源端序列X′与词典所有词的词嵌入相乘,最终得到Transformer翻译模型的输入。
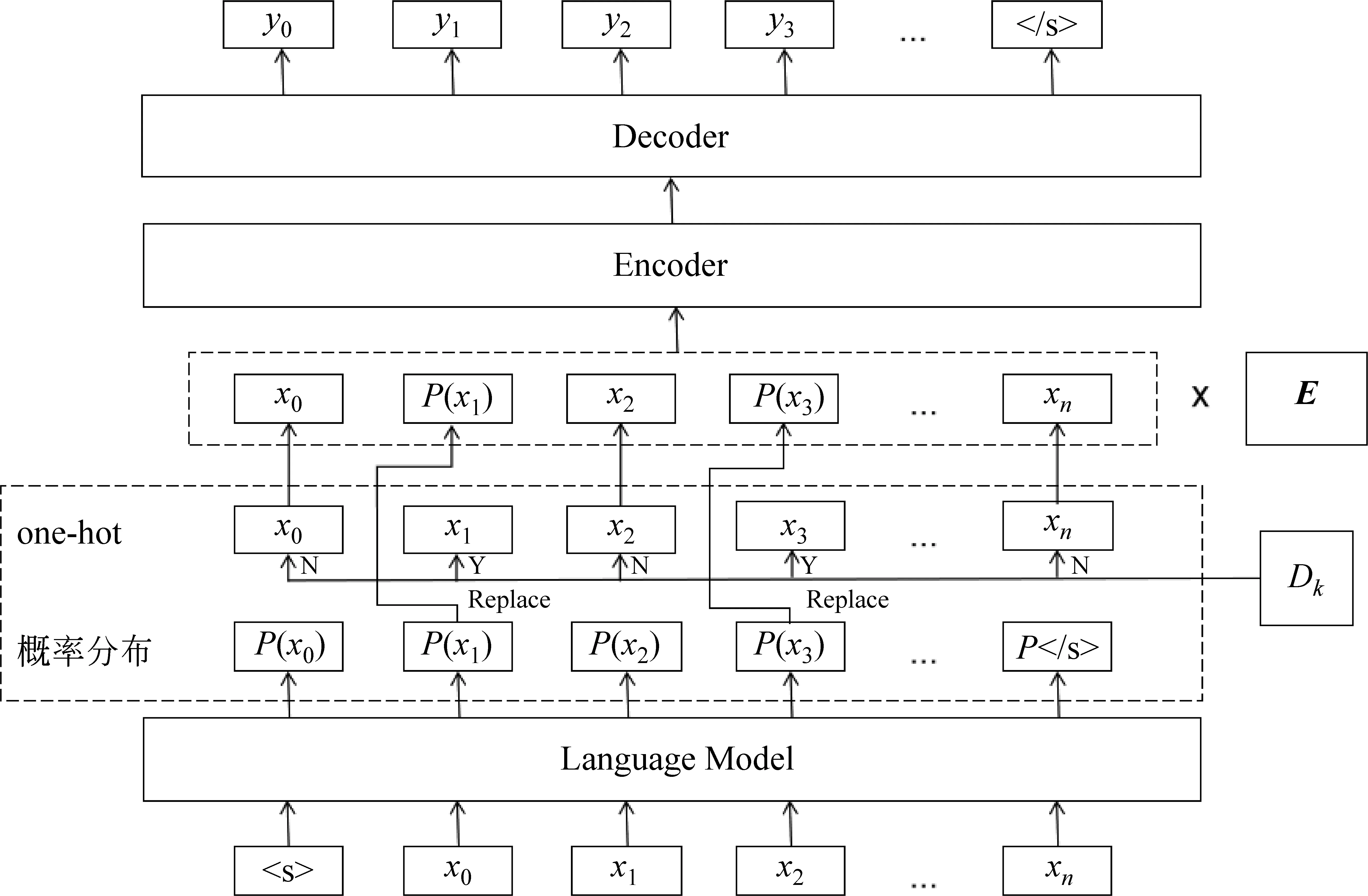
图1 总体模型结构图
2.2 低频词词典构建
以汉越数据集为例,低频词在汉越低资源神经机器翻译中表现不佳,为了区分低频词和其他词语,针对低频词使用本文方法进行低频词表示增强,构建低频词词典。低频词并没有严格定义,本文根据词频分布规律来定义低频词。由低到高统计词频,并根据词频对词典进行分类。通过统计的方式分别构建汉语和越南语低频词词典,以汉语和越南语训练集为目标选取低频词,词频等于k的低频词词典词定义为k类低频词子词典dk,词频k小于或等于K的低频词词典定义为K类低频词词典DK且存在,如式(1)所示。
以2007年为基准年,以2007年通州区的公路里程2 250 km为基准里程,将2007年到2016年的公路里程进行拟合从而得以确定公式中的参数,得到式(1):
根据词频k(k取1到10)分别构建汉语和越南语低频词子词典dk和低频词词典DK,且分别统计出其词典覆盖率,词典覆盖率为该词典大小与总词典大小的比值,总词典由训练集统计得出。
汉语词表大小为47 356,训练集词语总数为 2 275 526。k类低频词子词典中分别有18 496,6 656,3 787, 2 508,1 812,1 397, 1 067, 832,719,593个词语。如图2所示,k类低频词子词典覆盖率随着词频k的增加而降低,有39.06%的词语词频为1,0.25%的词语词频为10。
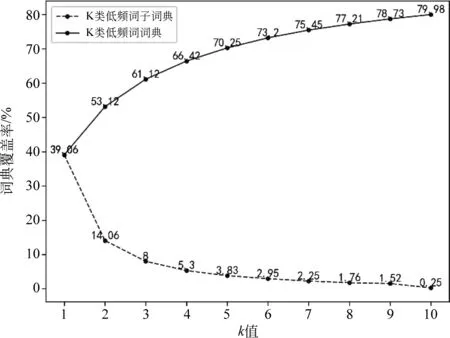
图2 汉语k类低频词子词典与K类低频词词典覆盖率
越南语词表大小为22 732,训练集词语总数为3 189 350。k类低频词子词典中分别有9 428,3 188,1 667,1 006,718,514,393,340,188,223个词语,如图3所示,与汉语k类低频词子词典类似,越南语词典覆盖率随着词频k的增加而降低,有41.47%的词语词频为1,0.98%的词语词频为10。

图3 越南语k类低频词子词典与K类低频词词典覆盖率
实验证明,在汉越语翻译任务上,在5类低频词词典上效果最佳,由图2可知,该类方法可以解决覆盖词典70.25%低频词表示问题;在越南语汉语翻译任务上,在6类低频词词典上效果最佳,由图3可知,该类方法可以解决覆盖词典70.66%低频词表示问题。
据统计,低频词虽然在数据集中词频较小,在10类低频词词典中,汉语和越南语在数据集中占比分别为4.33%和1.66%,但是在词典中的覆盖率非常大,达79.98%。说明在每个句子中大概率会出现低频词,由于低频词翻译效果不佳,从而在整体上拉低了机器翻译的效果。低频词中不乏一些常用词,如表1所示,“回升”“人命”和“结盟”等词语。所以对低频词表示增强的研究是有必要的。
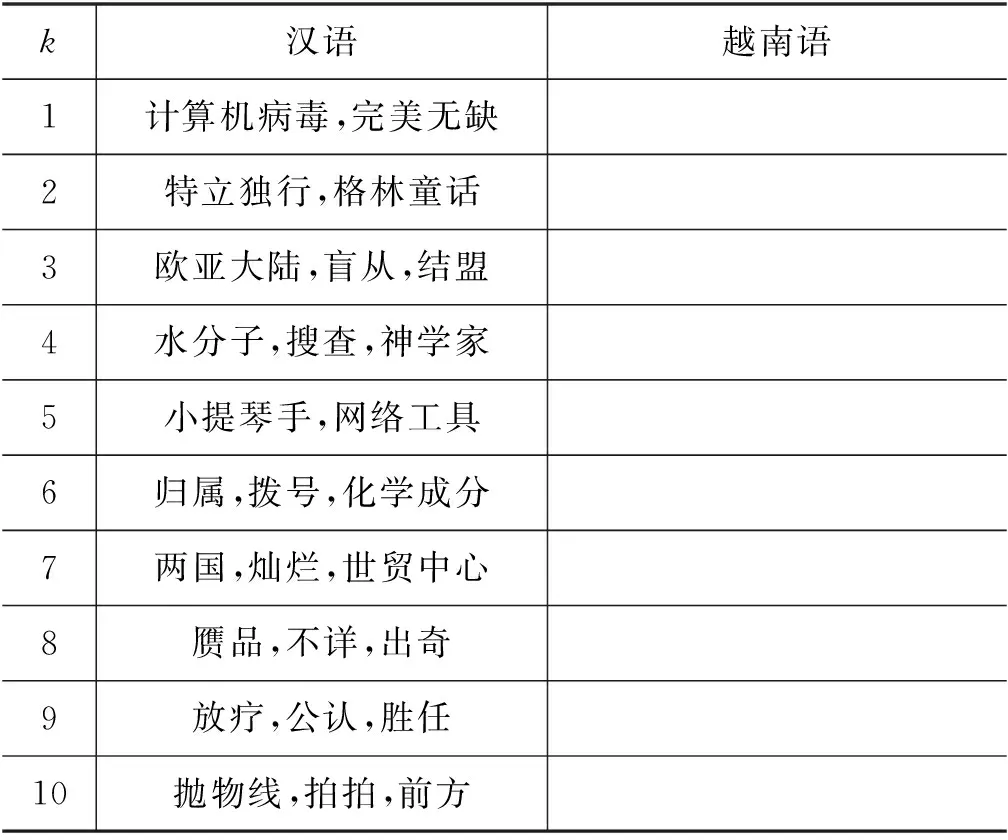
表1 汉语-越南语k类低频词子词典示例
2.3 低频词表示学习

低频词w的概率分布P(w)可以用多种方法计算,本文利用预先训练的6层Transformer decoder作为语言模型来计算P(w)和w前面所有词的条件概率,对于一个句子中第t个词xt,如式(2)所示。
在翻译模型中,每个单词都被分配一个唯一one-hot向量的ID,如图1所示,利用构建的低频词词典DK判断输入的句子中哪些词属于低频词,若xt∈DK为Y,反之则为N,“Y”表示用语言模型所训练出的P(xt)来更新与之对应的词,“N”则表示原词保持不变,从而得到新的源端序列向量表示X′,通过与词典V的词嵌入矩阵E相乘得到翻译模型Transformer的输入,如式(3)所示。
最终经过翻译模型Transformer得到翻译结果,如式(4)所示。
3 实验
3.1 实验数据
本文使用了汉越和汉蒙两个低资源数据集,其统计信息如表2所示。

表2 数据集统计信息
汉越数据集通过将公开IWLST英语-越南语双语平行语料,经过语言学专家将英语译文为汉语,得到汉语-越南语平行语料。在融入本文方法之前对语料进行了清洗和分词处理,最终获得127 481汉越双语平行数据。对于汉语数据,使用结巴分词工具对中文语句进行分词,处理越南语使用tokenizer[9]切开标点,分别从汉越双语平行数据中随机抽取规模大小均为2 000对的汉越双语平行数据作为测试集和验证集。
汉蒙数据集语料采用CCMT 2020机器翻译汉蒙评测数据,约26万,经清洗处理后训练集规模为20万对汉蒙平行语料,分别从汉蒙双语平行数据中随机抽取规模大小均为2 000对的汉蒙双语平行数据作为测试集和验证集。
3.2 实验设置
采用当前主流的Transformer体系结构用于翻译模型,对于汉越、越汉两个翻译任务采用相同的实验配置,实验中统计训练集词表。为了解决低频词的问题,不能去掉低频词,所以采用所有的词作为词典,汉语字典词表大小为47 356,越南语字典词表大小为22 732。每个batch最大Maxtoken为2 048,句子最大长度为128,最大epoch为100轮,dropout[10]设置为0.1,词嵌入维数为512维,隐藏层维度为512维。所有的模型通过Adam[11]优化器来训练,且初始学习率为1×10-4。
在汉越翻译任务中,采用独立的语言Transformer Decoder作为汉语语言模型[12]。汉语语言模型的训练集和验证集来源于翻译模型中的汉语语料,规模分别为127 481和2 000条汉语单语数据;在越汉翻译任务中,语言模型结构与汉越翻译任务中模型结构相同,越南语语言模型的训练集和验证集来源于翻译模型中的越南语单语语料,规模大小与汉语语言模型一致。
在语言模型训练完成之后,保存模型最优的训练参数,并在训练翻译模型时,语言模型的参数固定使用其最优训练参数。本文使用汉语-越南语平行语料分别在汉越和越汉两个任务上对本文提出的方法进行验证。本文采用自助重采样的方法[13](重采样1 000词)在显著性水平p<0.05下,在测试集上使用BLEU4值作为评测指标。
在汉蒙与蒙汉翻译任务中实验设置与汉越实验设置保持一致。
3.3 基于低频词表示增强的模型与基线模型对比
为验证本文所提出的低频词表示增强模型性能,采用了以下两种模型作为基线模型。一是经典Transformer模型(Transformer)[8]: 使用Transformer_base模型在汉越和越汉两个翻译任务进行实验。二是在Transformer基础上,加入语言模型(Transformer+LM)[2],使用语言模型训练结果随机替换翻译模型的输入,替换概率为γ,γ=0.15(γ值为文献[2]中所使用的最优设置)。在汉越和汉蒙两个语言对4个翻译任务上进行实验。实验结果为每个翻译模型BLEU4得分,如表3所示。
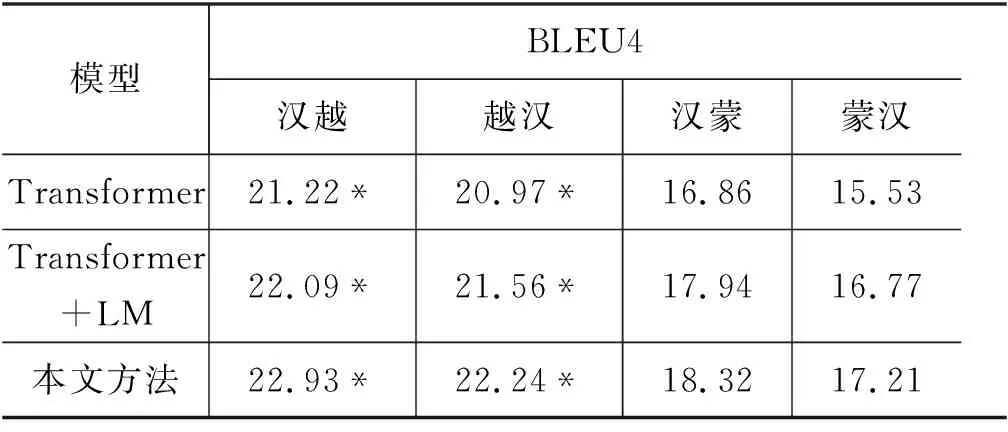
表3 实验结果
从表3可以看出,在汉越与越汉两个方向的翻译任务上,Transformer+LM模型较经典的Transformer模型分别提升了0.87和0.59个BLEU4值;本文方法相较于Transformer+LM模型分别提升了0.84和0.68个BLEU4值。根据上述结果,本文方法在汉越和越汉翻译任务上对比于Transformer模型和Transformer+LM模型,都有比较好的提升,证明本文中所提出的基于低频词表示增强的方法在汉越和越汉翻译任务上是有效的。在汉蒙神经机器翻译任务上本文方法较于经典的Transformer模型提升了1.46个BLEU4值,较于经典的Transformer+LM模型提升了0.38个BLEU4值。在蒙汉神经机器翻译任务上本文方法较于经典的Transformer模型提升了1.68个BLEU4值,较于经典的Transformer+LM模型提升了0.44个BLEU4值。本文方法不仅在汉越神经机器翻译上表现出优势,在蒙汉数据集上同样提高了神经机器翻译的准确率,对于资源稀缺型语言的神经机器翻译低频词表征不佳问题的处理具有可行性。
从实验结果中分析,Transformer+LM模型优于经典的Transformer模型,由于Transformer+LM模型通过语言模型随机引入了词上下文信息,使随机引入词获取到更丰富的信息,证明Transformer+LM模型中引入词上下文信息的有效性。本文方法相较于Transformer+LM模型在翻译性能上也有较大的提升,在本文方法中考虑到低频词的信息,只针对低频词进行上下文的概率估计,提高翻译性能,而不区分低频词和非低频词导致性能下降。从实验结果可以看出,本文方法能够缓解低频词翻译不佳这一问题,在汉越和越汉两个翻译任务上有明显的优势。
为了验证本文方法对于不同数据的有效性,本文对汉越和越汉两个方向测试集的源语言端按照句子长度区间对句子进行了分类,如表4所示。在汉越翻译任务上测试集大小分别为1 322、563和115对平行句对;在越汉翻译任务上测试集大小分别为415、708和877对平行句对。
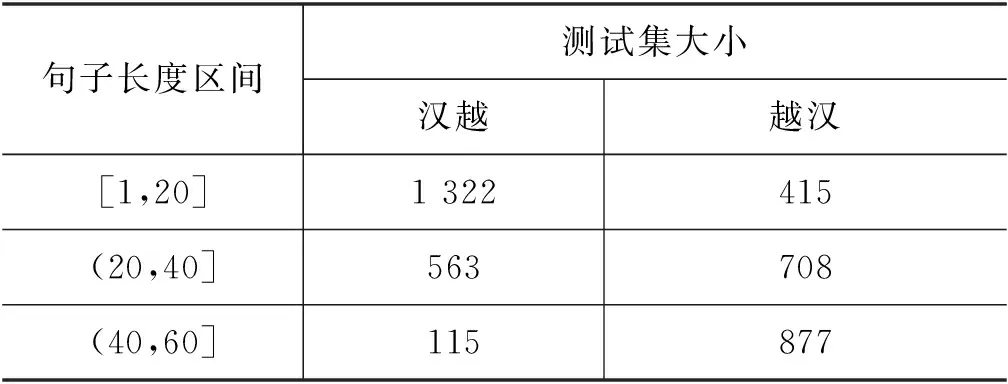
表4 验证集规模
实验结果如表5所示,在句子长度为[1,20]的区间上,本文模型较经典的Transformer模型几乎没有提升,而在句子长度为(20,60]的区间上提升较大。说明本文方法对短句效果不明显,在长句子中效果比较显著。
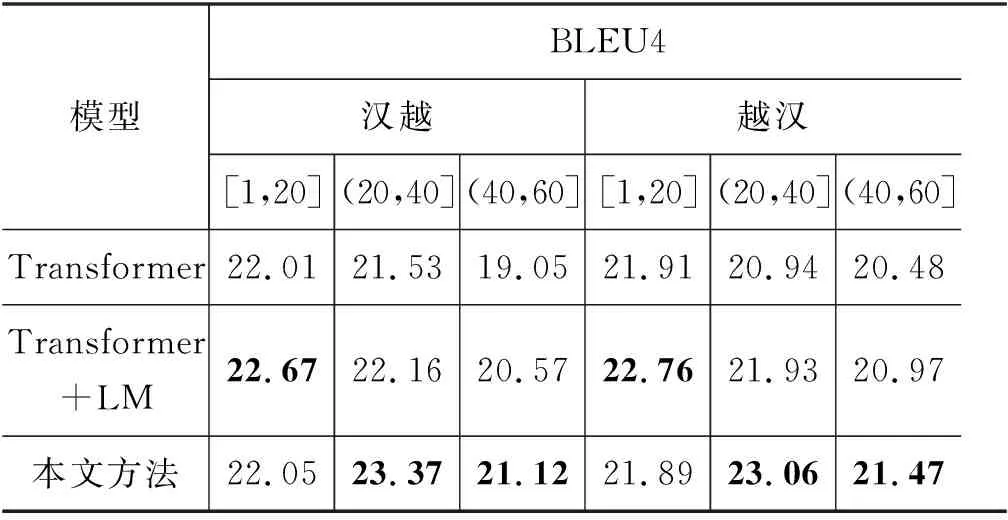
表5 实验结果
3.4 K类低频词词典对模型的影响分析
为了分析低频词出现频率对本文方法的影响,本文方法在汉越和越汉两个翻译任务上,按照出现频率小于或等于K(K=1,2,…,10)的词分别进行模型性能测试,结果如表4、表5所示。
从图4和图5中可以看出,在汉越和越汉翻译任务上,随着K值的增大,整体趋势先上升后下降,在K值分别取5和6时,即低频词设定为在训练集中出现频率小于或等于5和6时(分别占词表大小的70.25%和70.66%),BLEU4值取得最高值;K值为0时为经典Transformer模型结果,当K值取1,2,…,10时,模型性能皆优于经典Transformer模型;在上升过程,当K值等于3时,本文方法模型性能超过Transformer+LM模型;在下降过程中,K值分别取9和10时,Transformer+LM模型性能略优于本文方法。如图4所示,当K值取0时(经典Transformer模型),Transformer+LM模型优于经典Transformer模型,由于Transformer+LM模型中引入了随机词的上下文信息;当K值小于或等于5时,模型效果稳步上升,K类低频词词典中词语出现次数较少,低频词在翻译模型中不能得到更好的表示,用低频词的上下文信息替代低频词表示,从而丰富了低频词的表示信息,使低频词拥有更加丰富的上下文语义信息,使得模型稳步上升。当K值大于5时,即低频词词典中加入出现频率大于5的词语,由于新加入的词本身可以得到比较好的训练, 且训练出的词表示优于语言模型所提供增强后的表示形式。因此,低频词字典新加入的词语,并不能达到优化翻译性能的效果,所以在K值大于5时,翻译效果会不断下降。
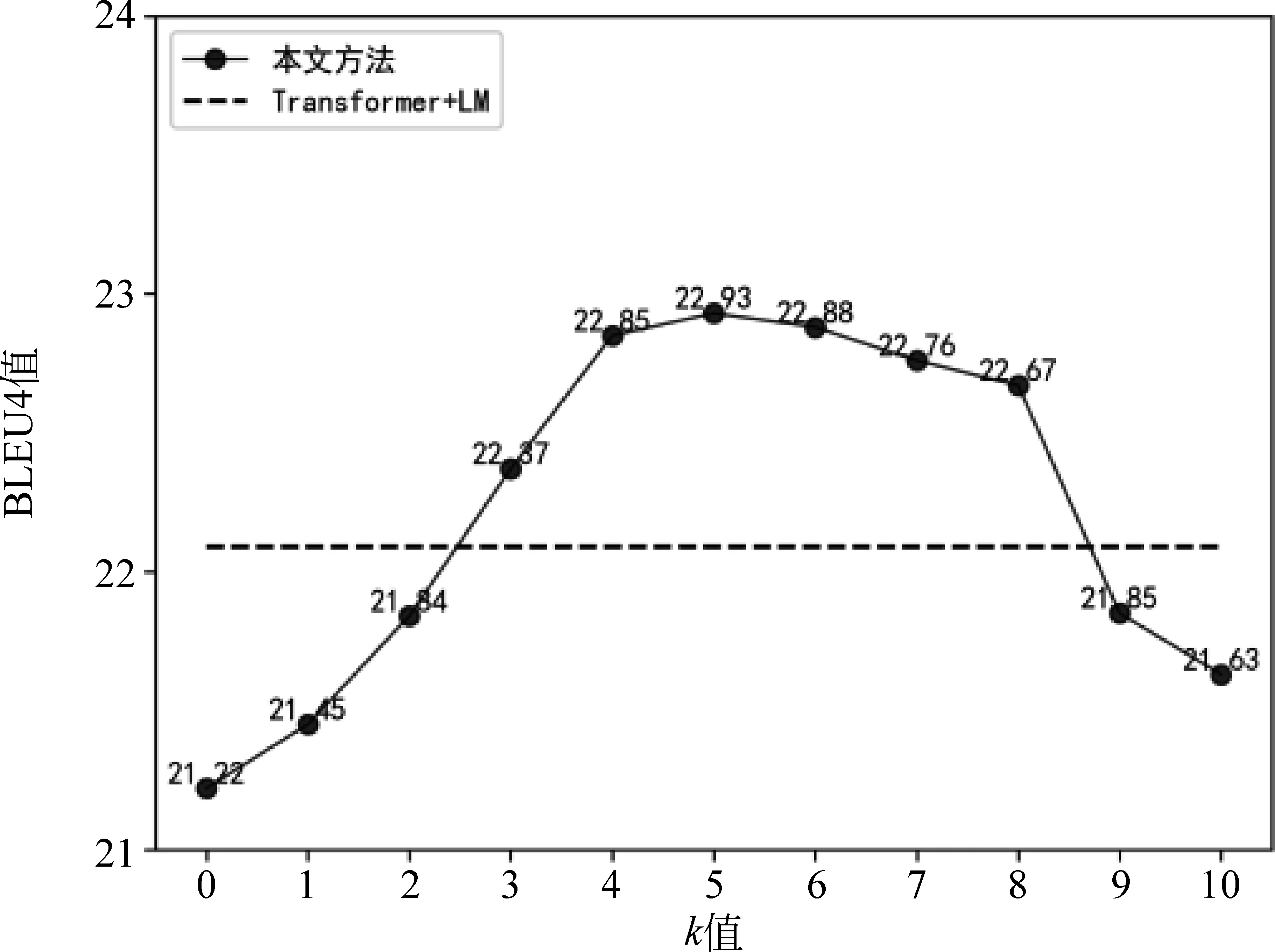
图4 K类低频词词典对汉越模型的影响

图5 K类低频词词典对越汉模型的影响
3.5 实例分析

表6 汉越翻译实例分析

表7 越汉翻译实例分析
4 结论
本文研究旨在缓解低频词在神经机器翻译中表示不准确这一问题,提出了一种低频词表示增强的低资源神经机器翻译方法,该方法利用单语信息增强低频词的表示,改善低频词的翻译效果,使翻译性能得到了提升。实验结果表明本文方法可以在经典Transformer模型和不区分词频的Transformer+LM模型上进一步提升机器翻译模型的性能。
