军人心理测量中融合自然语义信息的视线跟踪时-空相似度算法研究
2022-08-01沈胤宏郑秀娟
沈胤宏,郑秀娟,王 艳,黄 申,张 昀
(1四川大学电气工程学院自动化系,四川 成都 610065; 2空军军医大学军事医学心理学系,陕西 西安 710032; 3西安交通大学电信学部信息与通信工程学院,陕西 西安 710049)
在心理学研究领域,军人心理测量开展最早,与军事活动联系最为紧密,且应用最为广泛。由于军事职业活动的特殊性,要求军人必须通过严格的心理筛查,以保证正常的人才培养[1]。目前,军校心理测量主要分为三个步骤:心理检测、智力测验、人格测验。心理检测通过量表答题的方式进行;智力测验通过纸笔测验进行;人格测验通过结构式访谈方式进行。心理检测和人格测验的测量结果取决于心理医师的专业素养和受试者的诚实程度,因为这两部分容易受到主观因素的影响。因此,一个可对军校心理测量进行客观评估且可辅助医师临床诊断的量化指标显得尤为重要。视线跟踪技术广泛用于心理认知过程中的辅助测量[2-5],在扫描路径理论基础上[6]可以将扫描路径量化为一系列具有时间序列关系的注视点和扫视[7]。眼动扫描路径无论在时间上还是在空间上都具有良好的眼动信息存储功能,它不仅反映了被试看了哪里、看了多长时间,还反映了被试信息处理的顺序,是当前视线跟踪时-空分析研究中广泛应用的视觉行为特征[8]。目前,视线跟踪时-空相似度比较方法已经成功地应用于视觉信息处理过程中的认知研究,例如场景感知[9]、阅读[10]和视觉搜索[11]。近年来,视线跟踪时-空相似度比较算法被用来理解正确和不正确解答物理问题的视觉行为差异[12]和受试的工作经验[13]。同时,视线跟踪时-空相似性可为诊断轻度或中度的认知障碍提供临床依据[14]。因此,我们希望通过分析和比较被试心理测量过程中视线跟踪数据来评估被试潜在的视觉认知差异,进而识别心理差异。在本研究中,我们提出了一种将自评量表的语义信息与视线跟踪时-空相似度结合的算法,用于分析心理测量中被试视线跟踪数据,从而完成目标人群筛查的任务。将主观的心理状态分析转换为客观的视线跟踪时-空模式识别,使得心理评估过程更加客观简便。
1 算法与实验
1.1 视线跟踪时-空相似度算法
1.1.1 字符化方法 视线跟踪时-空相似度比较算法首先需要定义兴趣区(area of interest,AOI),并根据AOI将视线跟踪数据映射为字符串。在前人的工作中,研究人员通常采用网格法和百分制法定义AOI。网格法将刺激所在区域划分为规则大小的AOI(图1A),而百分制法则是将刺激区域划分为大小不同但所含注视点数量相同的AOI(图1B)。使用网格法和百分制法划分AOI都十分简单,且完整地保存了视线跟踪的顺序、形状和长度信息。但是,这两种方法都通过简单的几何区域划分破坏了刺激的完整性和相似性。例如,这两种方法会将一个词语划分为两个完全不同的AOI,或者将一个带有集成语义信息的表达式划分到多个AOI中。这两种方法都过于强调空间位置的相关性,而忽略了基本的语义信息,这对认知领域的研究具有破坏性。语义信息可以独立地影响被试的注意力分配机制,在引导注意力时,语义信息可以覆盖低层次的特征,即使该语义信息与任务无关[15-16]。基于此,我们根据中文语法及中文分词系统[17]重新定义了AOI(图1C),将眼动数据从简单的几何位置映射改进为基于语义信息的映射。AOI被标记为字符,位于同一AOI中的注视点将被映射为同一字符。因此,视线跟踪被表达为一系列连续的字符串,该字符串有序地表达了被试在各个AOI中的时空信息[18]。
1.1.2 视线跟踪时-空相似度算法改进 将眼动数据基于语义信息映射为字符串后,针对其字符串长度差异较为明显以及AOI分布规则等特点,我们对Needleman-Wunsch(NW)算法[19]和SubsMatch(SM)算法[13]做出了改进,以便更好地用于视线跟踪时-空相似度计算。
NW算法是一种全局字符串比对方法,常用于生物信息学中DNA序列的分析。该算法基于网格法将数据字符化,以替换矩阵计算所得的相似性得分最大化为原则对两字符串进行比较。替换矩阵提供了字符编码的AOI之间的欧式距离关系,并且可根据最大相似性得分的回溯路径将两条字符串最相似的部分临时对齐,解决了时间偏移的问题。但以AOI之间简单的欧式距离关系计算所得的替换矩阵存在一定的缺陷,其将所有AOI位于同一维度并假定所有的AOI之间都是规则的空间几何关系,忽视了AOI的分布特点和AOI之间的关联性和语义性。
针对这一问题,本文对NW算法的替换矩阵做出了以下改进:根据语义信息和实验目的对AOI进行两次区域划分。一次区域划分仅根据语义信息(图1C),以基于语义信息的AOI划分方法替代原有的网格法,建立基于语义信息的NW算法命名为NW_Semantic算法。二次区域划分将刺激图像分为3个AOI:问题区域、选项区域、背景区域。以图1C为例,问题区域由a、b、c、d、e组成,选项区域由y、n组成,背景区域由o组成。二次划分用于强调同类区域之间的相似性,以及不同区域之间的差异性。我们对3个AOI之间的距离进行了定义(图1D)。对两次划分的AOI距离进行叠加,得到新的替换矩阵值,用于对齐字符串并计算相似度。我们将进行了两次区域划分的NW算法命名为NW_Semantic2.0算法。
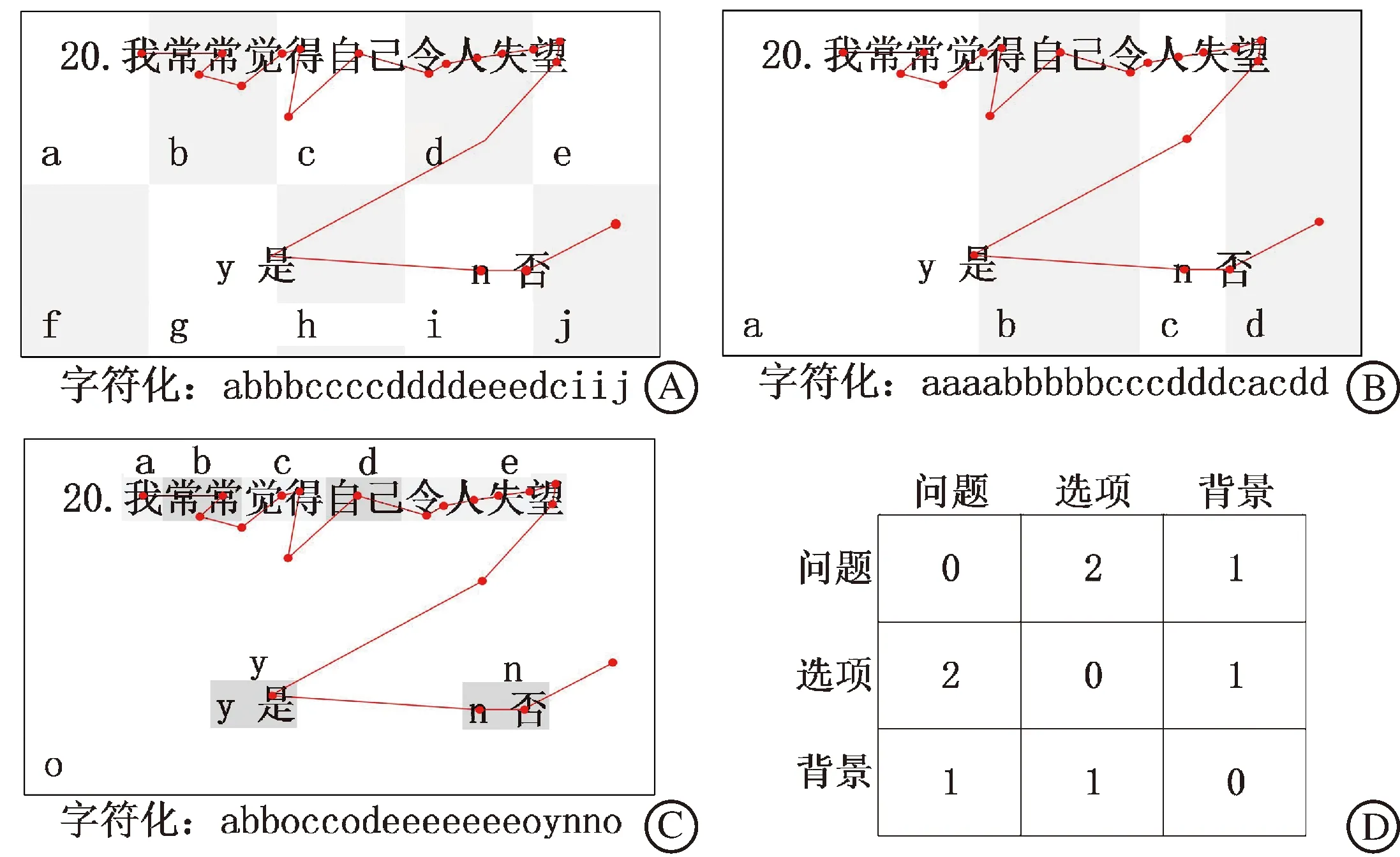
A:网格法;B:百分制法;C:基于语义信息;D:二次划分AOI之间的距离。图1 感兴趣区划分示意图
SM算法是基于重复注视模式频率的视线跟踪时-空相似度比较算法。该算法基于百分制法将数据字符化,然后通过一定大小的滑动窗口将表示视线跟踪的字符串划分为具有特定大小的等长子序列,计算每个子序列出现的频率,以子序列为键,子序列出现频率为值,建立哈希表,通过比较两个哈希表的差异来计算两视线跟踪之间的时-空相似性,其计算流程如图2所示,其中滑动窗口大小设置为2。
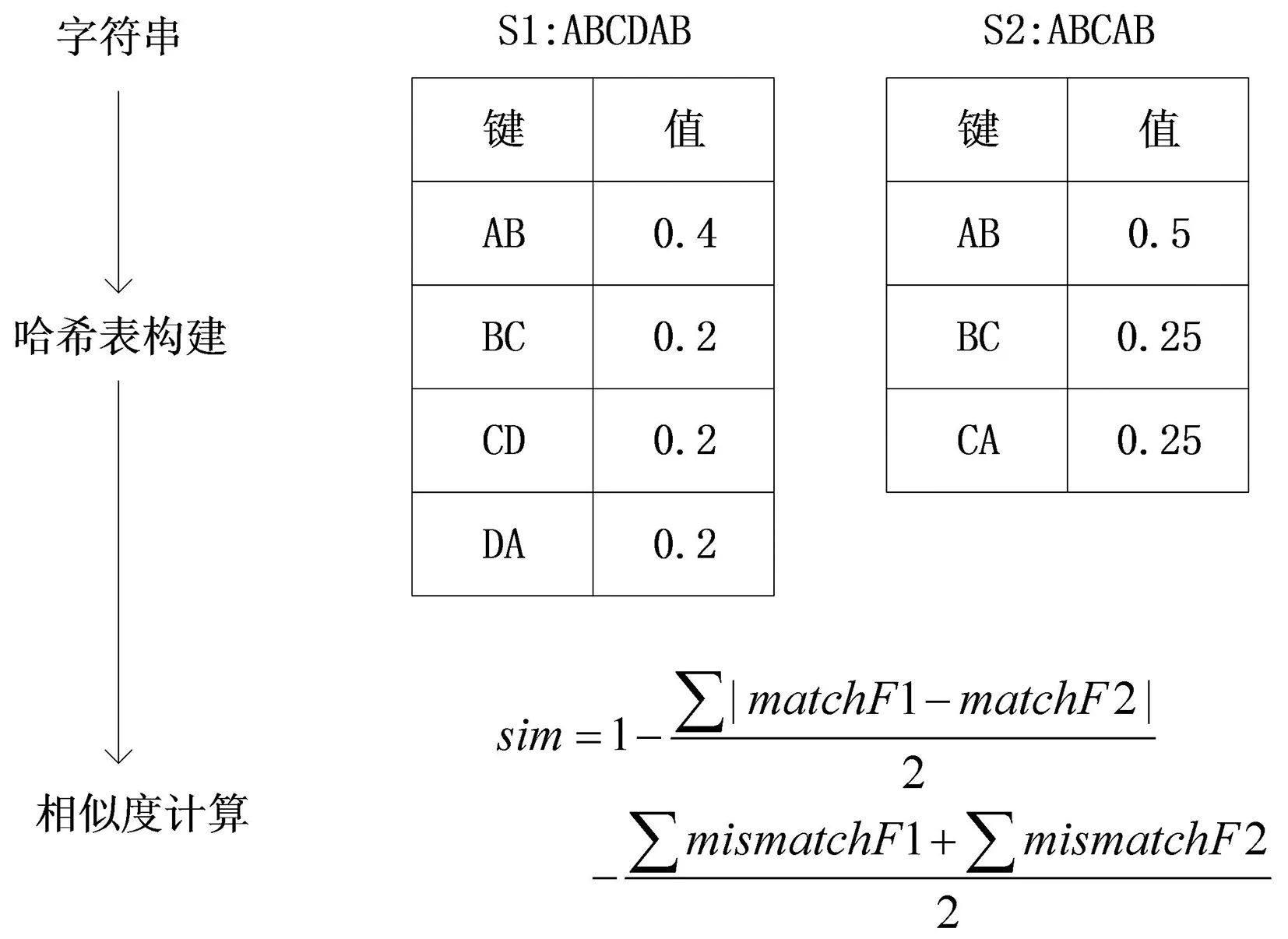
matchF1和matchF2分别表示字符串S1和S2哈希表中同一键对应的值;mismatchF1和mismatchF2则表示不同键对应的值。图2 SM算法流程图
SM算法常用于动态环境下的眼动研究,可通过哈希表中的最大值捕捉反复出现的眼动模式。但SM算法以子序列出现频率之差计算相似度,容易忽略视线跟踪长度这一特征,不能准确地比较字符串差异。以图2为例,字符串S1和S2的相似度为0.600,而S1与字符串S3:ABCDABABCDAB的相似度高达0.950。考虑到抑郁检测实验的设置和所采集的眼动数据特征(从左至右的阅读习惯、静态环境下较少出现反复眼跳行为、较为明显的视线跟踪长度差异),我们将原先SM算法哈希表中的值由子序列出现频率改进为子序列出现频数,并将哈希表相似度计算公式改进如下:
(1)
其中,matchF1和matchF2分别表示字符串S1和S2哈希表中同一键对应的值;mismatchF1和mismatchF2则表示不同键对应的值;M和N分别表示字符串S1和S2的字符长度;w表示滑动窗口大小。
公式(1)调整了SM算法中子序列频率归一化和哈希表比较的顺序,将原算法先归一化再比较改进为先比较再归一化,以此保留了字符串的长度特征。以上文提及的字符串S1、S2和S3为例,经改进后的SM算法计算,字符串S1与S2之间的相似度为0.667,S1和S3之间的相似度为0.625,具有明显的改进效果。本文中将基于语义信息的SM算法命名为SM_Semantic算法,并将改进归一化后的SM_Semantic算法命名为SM_Semantic2.0算法。
上述视线跟踪时-空相似度比较算法在每一个条目上均可计算得一个相似矩阵,该矩阵显示了在该条目上,两两被试的视线跟踪之间的时-空相似值。对相似矩阵进行最近邻分类,可得每位被试在每一个条目上的分类结果。将被试在每一个条目上的分类结果进行降维处理,可确定被试最终的诊断结果。
基于视线跟踪时-空相似度比较算法的抑郁障碍高危人群筛查方法具体步骤如下:步骤1,采集眼动数据并基于语义信息将其映射为字符串; 步骤2,运用视线跟踪时-空相似度比较算法计算两两字符串之间的相似值;步骤3,使用分类器对步骤2的计算结果进行分类,并整理分类结果识别抑郁障碍高危人群。
1.2 实验
近年,随着中国社会经济的发展,抑郁障碍受到了全社会的广泛关注,针对抑郁障碍的研究逐渐深入,发现抑郁倾向和认知风格之间存在相关性,可将视觉认知行为模式作为探索抑郁症客观诊断的重要途径[5]。因此,本文对军人心理测量中的眼动数据进行抑郁障碍高危筛查分析,评估本文提出方法的可行性和有效性。
1.2.1 对象 使用抑郁障碍高危自评量表(Self-Rating High-Risk of Depression Scale,S-hr-DS)[20]进行军人心理测量,实现抑郁障碍高危人群筛查。在前期工作中,S-hr-DS量表研制之初首先对抑郁障碍高危进行定义,之后该量表经过了三年的测试,验明其良好的可信度(状态量表和特质量表的Krumbach指数分别为0.956和0.962)[20]。
本文使用纸质版S-hr-DS开展军人心理测量,获得符合量表抑郁障碍高危诊断标准40人,经专业心理医生观察访谈,临床诊断抑郁障碍高危个体21人。同时随机选取无精神障碍和精神疾病家族史、汉密尔顿抑郁量表(Hamilton Depression Scale)[21]临床诊断评分低于7分,且无明显抑郁易感人格特质的正常人为对照组。所有被试在年龄、智力和教育方面相匹配,无阅读障碍,能够独立完成问卷作答。
1.2.2 数据采集 将S-hr-DS的62个条目制作成62张幻灯片作为眼动刺激,并在每个条目前插入一个校准幻灯片,用于眼动数据采集过程中的坐标校正(图3)。每一位被试头部距电脑屏幕60 cm,并尽可能保持头部静止,眼动校准后,被试读取幻灯片上的内容,然后单击“是”或“否”选项,以回答问题,每个问题的回答并没有时间限制。单击鼠标即可进入下一张幻灯片。在被试阅读并作答时使用眼动跟踪仪记录受试者眼动数据,实验数据采集使用SciEye系列TM300设备,通过SciOne开放API接口进行原始数据处理。
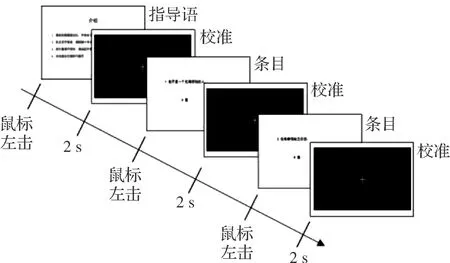
图3 实验流程图
1.2.3 数据分析 针对单个丢失数据采用上下取平均值法进行补充,并剔除视线跟踪率低于80%的眼动数据、眼动数据丢失超过10张幻灯片的被试以及眼动数据丢失超过10名被试的幻灯片。最终,我们获得了19名抑郁障碍高危个体和筛选19名正常人在59张幻灯片刺激下的眼动数据。
基于上述方法获得的有效数据,我们对数据的表征特征和视线跟踪时-空相似度进行了评估。分别运用NW算法、基于语义信息划分AOI的NW_Semantic算法、基于语义信息改进后的NW_Semantic2.0算法,以及SM算法、基于语义信息划分AOI的SM_Semantic算法、基于语义信息改进后的SM_Semantic2.0算法计算两两被试间的视线跟踪时-空相似度,并依据相似矩阵得分对被试进行最近邻分类,识别正常人和抑郁障碍高危人群。选取精确率(accuracy,ACC)、查准率(precision,P)、查全率(recall,R)和F1分数作为评估指标进行上述四类算法结果比较,如公式(2)~(5)。
(2)
(3)
(4)
(5)
其中TP表示实际为真、预测为真的样本数量;FN表示实际为真、预测为假的样本数量;FP表示实际为假、预测为真的样本数量;TN表示实际为假、预测为假的样本数量。
2 结果
为探究抑郁高危人群与正常人在相同语义信息刺激下的眼动差异,我们对AOI划分各异以及算法改进前后的视线跟踪时-空相似度算法进行了评估。由于两类被试的数目相等,设机会水平值为50.00%。表1显示了六类计算模型调至最优参后在眼动数据集上的分类性能,其分类ACC均高于50.00%,最高ACC为80.13%,F1分数为83.41%。足以说明应用视线跟踪时-空相似度比较算法检测抑郁障碍高危人群的可行性。与此同时,无论是NW算法还是SM算法,其基于语义信息分割AOI所建立的计算模型的分类性能均略有提升。而基于语义信息改进后的NW_Semantic2.0算法和SM_semantic2.0算法较改进前提高了近5%左右的分类ACC。这说明基于语义信息改进后的NW算法和SM算法可以更好地识别抑郁障碍高危人群的眼动特征。
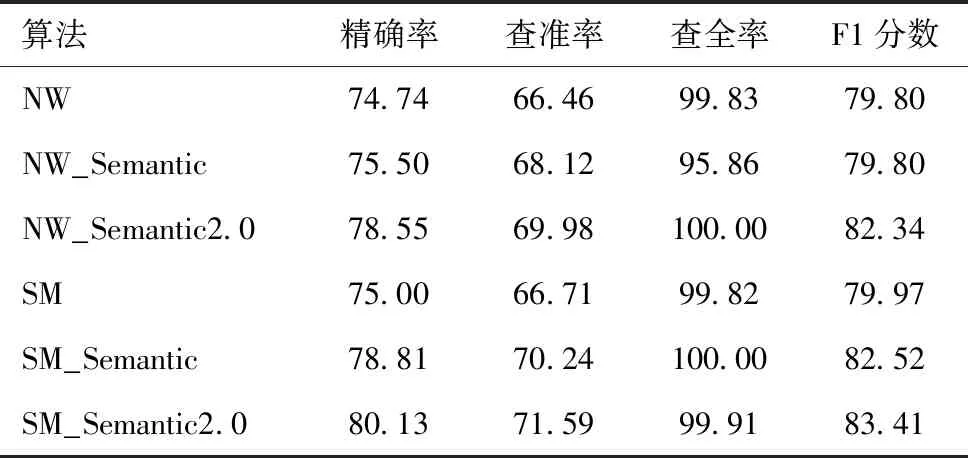
表1 六类算法的筛查性能比较 (%)
图4的混淆矩阵显示了更详细的分类信息,在六类计算模型中,抑郁障碍高危人群在每道题上的分类ACC均很高,而正常人的分类则存在错误。并且单道题的平均检测结果存在很高的假阳性,与表1中的高召回率相对应,该结果有利于开展抑郁障碍高危人群临床诊断前的初筛工作。
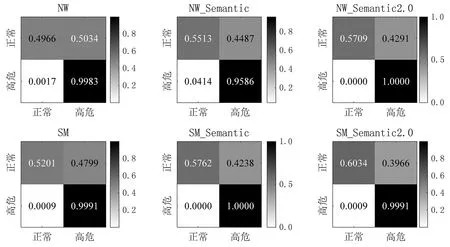
图4 单个刺激条目下被试的分类混淆矩阵
以一个条目的眼动数据筛查正常人和抑郁障碍高危人群存在极大的不确定性,在某些条目上两类人群的眼动数据存在显著差异,筛查效果较好,而在一些没有区分度的条目上,筛查效果不理想。本实验总共有62个条目,每位受试者在每个条目上都有一个预测标签,我们将标签数量最多的类别作为受试者的预测标签,进行降维处理(表2、图4),这样可以发挥整套量表的作用,提高筛查的稳定性。
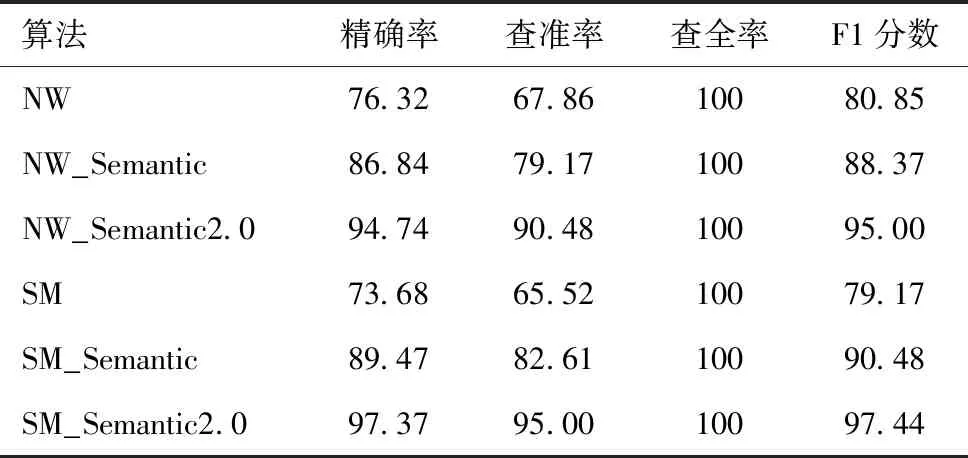
表2 降维后六类算法的筛查性能比较 (%)
经降维处理,NW和SM计算模型的ACC没有较大变化,而NW_Semantic、SM_Semantic和NW_Semantic2.0、SM_Semantic2.0四类计算模型检测的ACC分别提升了10.52%、15.79%和18.42%、23.69%。其中,SM_Semantic2.0算法检测的ACC最高,为97.37%,比SM算法检测的ACC高出23.69%,38人中仅1人检测错误(图5)。为探究降维处理对检测结果造成影响的内部原因,我们针对SM_Semantic2.0算法的分类结果,对分类ACC高于平均值和低于平均值的条目内容及正常人和抑郁障碍高危人群在该条目上的眼动扫描轨迹进行了比较。我们发现大部分分类ACC高于平均值的条目在其内容结构上均存在较为明显的关键性语义词,该类词汇奠定了条目的情感色彩和情景内容。正常人会在关键性语义词汇上注视较长时间,而抑郁障碍高危人群则容易在关键性语义词汇附近发生回视行为,但是这一眼动差异并不具有绝对性,只发生在部分条目。
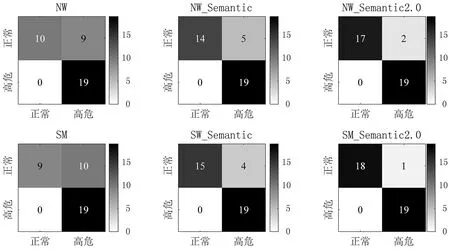
图5 降维处理后被试的分类混淆矩阵
3 讨论
心理医生通过心理测量量表对受试者进行心理评估,从而得出被试者的心理状态,这个过程依赖于受试者的答题结果,心理医生需要对受试者的答题成绩给出相应的分数,通过分数的高低来判定受试者在当前心理维度是否健康。在这个过程中,受试者的诚实度和心理医生的专业素养都会对结果产生一定的影响。我们希望通过一种客观的方法消除这种影响,同时保留通过让受试答题来进行评估这种方式。因此,本文将自评量表评估与眼动数据分析相结合,通过采集受试者在答题时的眼动数据,利用计算机对眼动数据进行分析,来评估受试者的健康情况。利用本文的方法辅助心理医生进行心理测量,让二者的评估结果进行相互印证,可以极大程度地消除由于主观性带来的影响。
在本实验中,所有方法的正确率均高于机会水平50%,表明不同人群在进行心理测验时,眼动模式存在显著的差异性,利用这种差异性可以分类不同的人群,测试受试者是否心理健康。NW算法通过网格化的方法对眼动数据进行字符化,然后对字符串进行全局序列比对。不同的字符代表不同的区域,字符比对的过程就是区域比对的过程,NW算法实际上是比较眼动数据在位置上的差异性。SM算法通过等频分箱的方法对眼动数据进行字符化,然后利用滑动窗口获取子序列以及子序列的频率,通过比较子序列的频率差异来分析眼动数据。这种方法探索的是受试者在答题时的注视转移情况。两种方法的分类ACC为76.32%和73.68%,说明受试者在这两个不同角度均存在眼动模式差异。本文在NW算法和SM算法基础上进行改进,提出了NW_Semantic、SM_Semantic和NW_Semantic2.0、SM_Semantic2.0四种算法。NW_Semantic和SM_Semantic在NW和SM的基础上改进了AOI的划分方法,将原有的AOI划分方法替换为基于语义信息的AOI划分方法,实验结果表明,在ACC上分别提高了10.52%、15.79%,证明了基于语义信息划分AOI的有效性。NW_Semantic2.0在改进AOI划分的基础上进行了AOI的二次划分,加入了对题目区域、背景区域、选项区域的考虑,在欧式距离的基础上添加额外距离,加大三者之间的区分度。SM_Semantic2.0在改进AOI划分的基础上对SM算法原有的归一化方法进行了改进,消除了由于字符串长度带来的影响。二者相比原算法在ACC上分别提高了18.42%和23.69%。
此外,针对具体的眼动扫描模式差异,我们发现正常人停留在关键性语义词上的平均注视时间比抑郁障碍高危人群的更长,并且正常人在回答问题时较少出现回视的眼动模式,具备更好的信息处理能力或记忆力,进一步证明了本文提出的对量表进行语义字符化的合理性。在今后的科研工作中,我们将进一步扩充数据集,探究此方法在心理测量其他方面如自闭症检测、职业评估等的表现。
