基于自陈式量表眼动数据的军人抑郁障碍高危人群客观化识别
2022-08-01苗丹民
黄 申,方 鹏,岳 敏,苗丹民,曹 爽
(火箭军工程大学: 1政治系, 3作战保障学院,陕西 西安 710025; 2空军军医大学军事医学心理学系教学实验中心,陕西 西安 710032; 4解放军中部战区空军医院心理科,山西 大同 037000)
抑郁障碍高危人群是指具有高抑郁易感人格特质的人群[1]。既往研究指出,抑郁障碍高危人群在外界不良因素刺激下,更可能出现亚临床的抑郁状态甚至发展成抑郁障碍[2]。部队作业环境具有高应激、高压力等特殊性[3-5],因而早期准确地筛查出应征青年中的抑郁障碍高危人群,从源头减少部队抑郁障碍的发生率,对促进官兵心理健康具有重要的现实意义。
自陈式量表是目前精神障碍及高危人群的主流筛查工具[6-7]。但在自陈式量表广为使用的同时,也因答题的主观性而备受质疑[8-10]。研究指出,在应聘等高风险情景下,被试在作答量表时普遍存在社会赞许性加工[11],这使得自陈式量表在实际应用场景下出现测量偏差。探索量表答题过程中更为客观化的识别方法有望弥补这一缺陷,提高检出效能。
视线追踪技术(又称眼动技术)可以精确、无干扰地记录人眼视觉过程。眼动技术作为一项成熟的认知神经检测技术,反映了个体视觉追踪、工作记忆、逻辑推理与计划能力等多个方面[12-15]。本研究拟在抑郁障碍高危人群和正常人群作答自陈式量表的过程中,使用眼动技术探索抑郁障碍高危人群客观化识别的可能性。
1 对象与方法
1.1 对象
采用整群抽样的方法,用“抑郁障碍高危人群特质筛查量表”[7]对某军校798名大一新生进行普测,选取量表得分高于均数两个标准差以上且“抑郁自评量表”评分未达到抑郁障碍标准,经精神科临床医生鉴定属于抑郁障碍高危人群的37人组成抑郁障碍高危组,均为男性。剔除眼动采集实验中注视点采集率低于75%的被试(4人),高危组实际人数为33人。
以未达到“抑郁障碍高危人群特质筛查量表”均数两个标准差以上的37人为健康对照组,均为男性。剔除眼动采集实验中注视点采集率低于75%的被试(1人),健康对照组实际人数为36人。
所有被试年龄在18~25岁之间,均无其他类药物的使用,且视力均经过筛查,符合眼动实验要求。本研究已通过空军军医大学西京医院临床试验伦理委员会审核(许可证号:KY20182047-F-1),所有被试均签署了知情同意书,并被告知有随时选择退出的权利。
本研究使用“抑郁障碍高危人群特质筛查量表”测试。该量表共计62题,分为悲观消极、敏感退让、兴趣缺乏、缺乏自信、急躁忧虑以及心态脆弱6个维度。该量表的克朗巴哈系数为0.95,重测信度为0.82[7]。量表中所有题目均为“是”或“否”的迫选题,完成全部题目大约需要10 min。
1.2 方法
1.2.1 试验流程 在实验开始前,将“抑郁障碍高危人群特质筛查量表”的所有题目制作成统一的图片格式,使用Tobii Pro Lab软件完成实验程序的编写。为了保证研究过程中眼动测量的准确性,在实验前调整被试与屏幕之间的相对位置,使被试在实验中与监视器保持65 cm的距离。使用托架固定头部,使被试瞳孔位于屏幕的中央。
进入正式实验后,被试首先在电脑屏幕前完成眼动仪的9点校准,在校准时,被试的视线要求追随屏幕上的红点,校准成功后开始呈现测试材料。被试的任务是根据量表的题目进行“是”或“否”的按键选择,选择完成后自动跳入下一题,直至完成全部量表。每道题目之间均会呈现500 ms的“+”号,以确保被试视线回归屏幕中央。实验流程见图1。
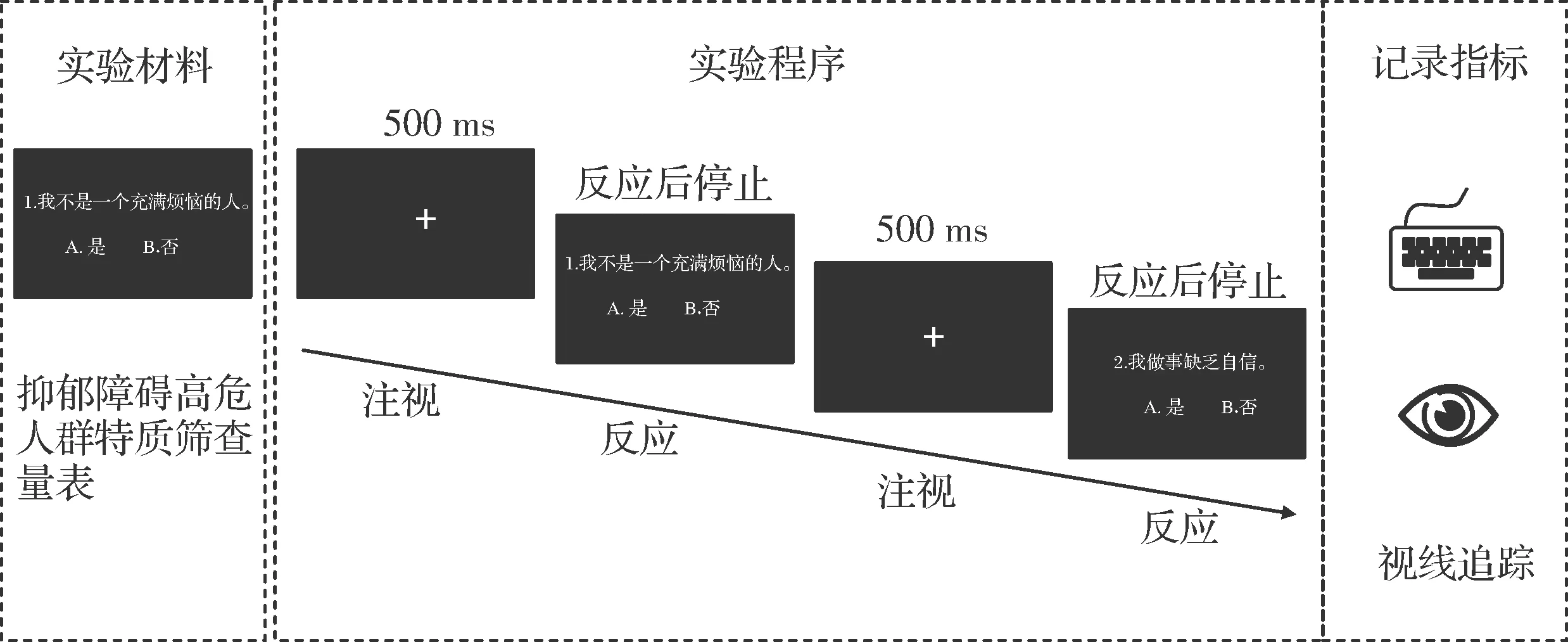
图1 “抑郁障碍高危人群特质筛查量表”结合眼动研究的流程
被试在作答量表的过程中,使用Tobii Pro X30-120眼动仪记录眼动数据。该眼动仪是Tobii公司最新研发的一款屏幕式眼动条,采样频率为120 Hz,即每8.3 ms采集一次视线坐标。
1.2.2 眼动特征提取 眼动数据分析的一个重要工作是对刺激材料划分兴趣区(area of interest,AOI)。本研究针对实验材料的特点,将量表的每道题目划分为3个兴趣区。其中题干部分为兴趣区a(AOI a),选项“是”部分为兴趣区b(AOI b),选项“否”部分为兴趣区c(AOI c)。
使用Microsoft Excel 2017及Tobii Pro Lab提取原始眼动数据并计算眼动特征。对每道题目的每个兴趣区共提取了17种眼动指标,分别为:注视类指标,包括总注视时长、平均注视时长、注视点个数、总注视点时长、平均注视点时长及首次注视时长,反映被试对刺激材料的加工程度;眼跳类指标,包括眼跳个数、开始眼跳峰值速度、结束眼跳峰值速度,反映注视点的转换;访问类指标,包括总访问时长、平均访问时长、访问次数,反映更全面更细节的信息;扫视类指标,包括扫视总时长、平均扫视时长、最大扫视时长、最小扫视时长、扫视次数等,反映被试阅读材料时的加工速度和效率。四类眼动指标从时间和空间的角度全面反映被试在作答量表时的认知过程。
1.2.3 数据处理 使用提取的眼动特征,用随机森林算法构建反应倾向性分类模型,以预测被试的作答选项。随机森林法是以决策树为弱学习器构建的Bagging集成方法,并在训练过程中增添了随机属性选择,具有操作简单、容易实现、计算便捷等特点[16]。使用反应倾向性模型输出的作答选项,用支持向量机(support vector machine, SVM)算法构建人群分类模型,以预测被试是否为抑郁障碍高危人群。SVM是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器。该方法具有较好的“鲁棒性”,适合用于小样本数据的分类学习[17]。本研究使用的机器学习算法均由Matlab软件实现。
2 结果
2.1 被试作答选项的分类准确率
本研究共选取了17种眼动特征。量表中每道题目均被划分成3个AOI,故对于每道题目,共纳入了51个眼动指标作为模型的输入特征。使用随机森林算法构建反应倾向性模型,以预测被试的作答选项。考虑到样本集的规模有限,本研究采用分层交叉验证的方法对模型进行评价,评价指标包括准确率、精确率、召回率和曲线下面积(area under curve,AUC)。准确率是对分类器在整体数据上的评价指标;精确率是对分类器在预测为阳性的数据上的评价指标;召回率是对分类器在整个阳性数据上的评价指标;AUC是受试者工作特征曲线(receiver operating characteristic curve,ROC)右下角的面积,AUC面积越大,表示分类器的性能越好。本量表共有62道题目,其中第36题只有一个“是”的样本,其余皆为“否”,在对样本进行训练测试集划分时,无法满足每个测试集均包含两类结果样本的要求,故无法构建模型,其余61道题目使用眼动特征对被试作答选项的分类结果见表1。其中,最高分类准确率可达97.10%(第39题),最低分类准确率为55.07%(第46题),62道题目平均识别准确率可达80.47%。
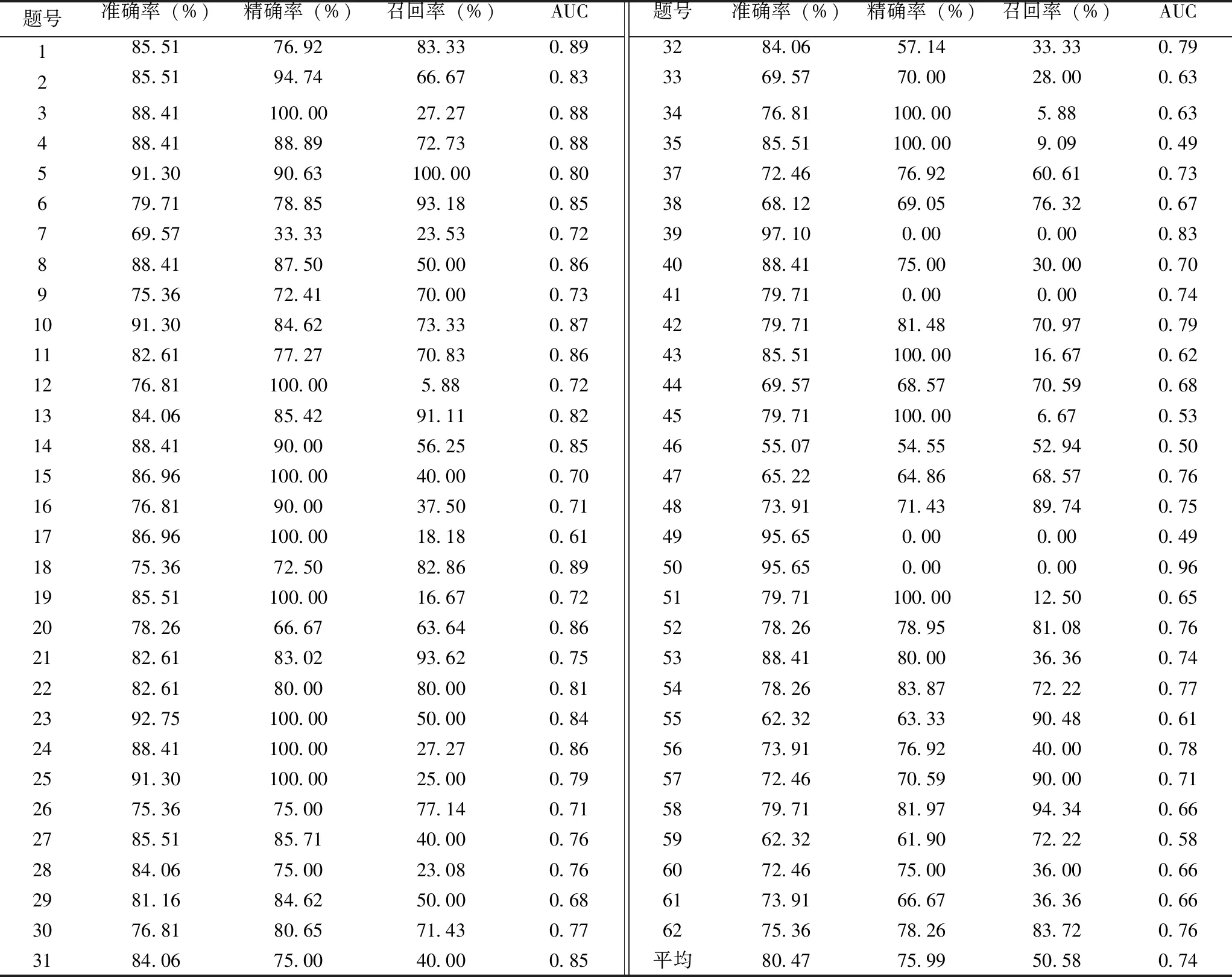
表1 随机森林模型的分层交叉验证
2.2 抑郁高危人群的分类准确率
将2.1中反应倾向性模型的输出结果作为输入特征,即使用眼动数据预测的被试作答选项作为输入特征,使用SVM算法构建人群分类模型,进行人群的分类识别。由于第36道题目无法构建反应倾向性模型,故该道题目的输入特征使用被试实际的作答选项。该模型对正常人群的识别率可达94.40%,对抑郁障碍高危人群的识别率可达81.80%,整体准确率可达88.40%。
3 讨论
作为世界上最重要的心理选拔手段之一[6-7],自陈式量表由于答题的主观性遭受到了越来越多的质疑[8-10]。本研究以自陈式量表为刺激,使用被试作答量表时的眼动数据,通过机器学习算法初步实现了抑郁障碍高危人群的客观化识别,弥补了传统自陈式量表的不足。
本研究发现,在使用眼动数据预测被试的作答选项时,量表中62道题目的分类准确率均高于基线准确率(基线准确率为50%)。同时,62道题目的平均分类准确率达到80.47%,远高于基线准确率。这说明眼动数据可以较好地识别出被试的作答选项,这为抑郁障碍高危人群分类模型的建立奠定了基础。此外,在人群分类模型中,研究发现该模型对抑郁障碍高危人群的识别准确率可达88.40%,这提示我们基于眼动的客观化识别方法有望打破传统量表仅依赖被试主观报告的单一计分模式。
在既往类似研究中,普遍的做法是使用不同人群在量表作答整体维度的眼动数据,构建人群分类机器学习模型[18-20]。虽然这样的方法在数据结果上具有一定的效果,但也存在一些问题。首先,从理论上看,前人的思路分析是默认人群间的眼动具有差异性模式,但从量表作答的过程来看,应是从每个条目的响应过程出发进行眼动分析。其次,前人的研究虽然采用了客观化行为,但在对客观化行为进行数据分析时并没有与量表本身的计分方式进行很好的融合,这使得量表仅仅成为了采集客观化行为的刺激材料,而无法对数据结果赋予更多的心理学解释。
与既往研究相比,眼动数据在该方法中没有直接用于人群区分,而是用于构建题目的反应倾向性分类模型,这使得该技术更加符合量表答题的理论逻辑,并有望解决传统自陈式量表因作答动机、社会赞许性等产生的反应偏差问题。此外,在人群分类模型中,该技术考虑到了所有条目的眼动数据输出结果,而非整体上的平均值,这使得眼动数据与量表的计分方法进行了初步融合,改变了以往靠量表作答计分的传统判别方式。根据本研究的结果,我们认为下一步研究中可以纳入更多的认知神经科学技术,同步采集被试作答过程的客观化数据,并使用这些数据从单个条目出发,构建量表题目的分类识别器,而不是直接将客观化数据进行人群分类。
需要说明的是,既往类似研究中使用的被试大多是精神障碍人群,本研究中的抑郁高危人群本质上不归属于精神障碍,因此实验结论能否推广至精神障碍人群中还需要进一步的实验支持。此外,本研究选取的被试均为男性,且样本量相对较小,因此机器学习构建的模型在实际应用中可能存在一定的误差,尚需更大的样本量对结论的可靠性加以验证。
