基于FUSION模型的碳基固废热解产物产率预测
2022-08-01杨磊宋金玲唐初阳于诗尧杨欣宇
杨磊,宋金玲,唐初阳,于诗尧,杨欣宇
(辽宁科技大学土木工程学院,辽宁 鞍山 114051)
中国拥有丰富的农业残余物、林业废弃物和其他生物质资源,2020 年可资利用的碳基固体废弃物达8.1 亿吨。长期以来,碳基固体废弃物存在利用率低、清洁转化成本高、转化能源产品热值低的问题。特别是农作物秸秆和林业废弃物的直接焚烧,造成了较为严重的环境污染。“十四五”规划后,我国从保护世界生态环境出发,提出在2030 年实现碳达峰,2060 年实现碳中和。为实现这一目标,在大幅减少化石能源使用的同时,必须改变碳基固体废弃物利用的技术路线,即从清洁能源转化生产能源路线向制备高附加值化学品和增加碳汇转型。热解是成熟有效的清洁转化碳基固体废弃物的技术之一,通过低温共热解可将中低阶煤和木屑、棉秆、稻壳及藻类等农林废弃物转化为有价值的化学品、气态燃料和半焦,在减排汇碳的同时能够产生较好的经济效益。但是,在热解和共热解碳基固废的过程中,存在着较为复杂的交互作用,单纯通过实验对热解产物产率进行测定,研究探索极其缓慢,受到人为和实验条件因素影响极大。如果采用数学模型辅助,模拟热解过程中的交互作用,预测热解产物产率,则可以极大提高实验效率,减少探究最佳反应条件的时间。
随机森林模型(RF)、神经网络模型(ML)、支持向量机模型(SVM)和线性回归模型(LR)等基于仿生智能的数学预测模型具有自适应和自学能力,特别适合处理碳基固废热解这种需要同时考虑许多因素和条件的、不精确和模糊的信息处理问题。Zhu 等利用RF 建立数学模型,对木质素纤维素类生物质热解产物进行预测,发现目标生物质的元素和工业分析与其热解产物产率具有高度相关性,并且RF 模型的预测结果受生物质的结构影响大于其元素组成的影响。Tang等通过相关性分析人工干预RF 和SVM 模型,对6 种不同生物质热解气相产物产率进行训练和测试,建立了较为精确的热解产物预测模型。高宁博和李爱民运用ML建立了固体废弃物热解产物预测模型,发现该模型对热解气相产率预测精度较高,对热解焦油产率预测存在一定误差(>10%)。李延吉等运用灰色关联度方法,发现热解最终温度和物料挥发分对生物质热解气相产物产率有较高影响,采用3 层改进ML 方法建立预测模型,取得了较好的预测精度(<5%)。碳基固废在热解过程中,不同组分之间存在极为复杂的交互作用,这极大地影响了热解油、热解水、热解气和半焦的产率和组成。因此目前对热解产物产率的预测多采用单一模型进行,而且单一模型较为适合对热解产物中某一项产物的产率进行预测。
如图1所示,本研究以碳基固体废弃物的工业分析、元素分析、煤样的C NMR固体核磁分析结果及热解试样的混合比例作为模型输入参数,产物产率作为输出参数。以Python为软件平台,分别调用SVM、LR和ML模型进行单一模型的产物产率预测计算,通过软件对预测结果进行效能分析和算法融合,以及进一步的训练和测试,最终建立具有自适应性的碳基固废全产物产率的预测模型。该模型计算速度快,预测精度高,较好解决了热解过程中因交互作用导致的对各产物产率预测精度的影响问题。
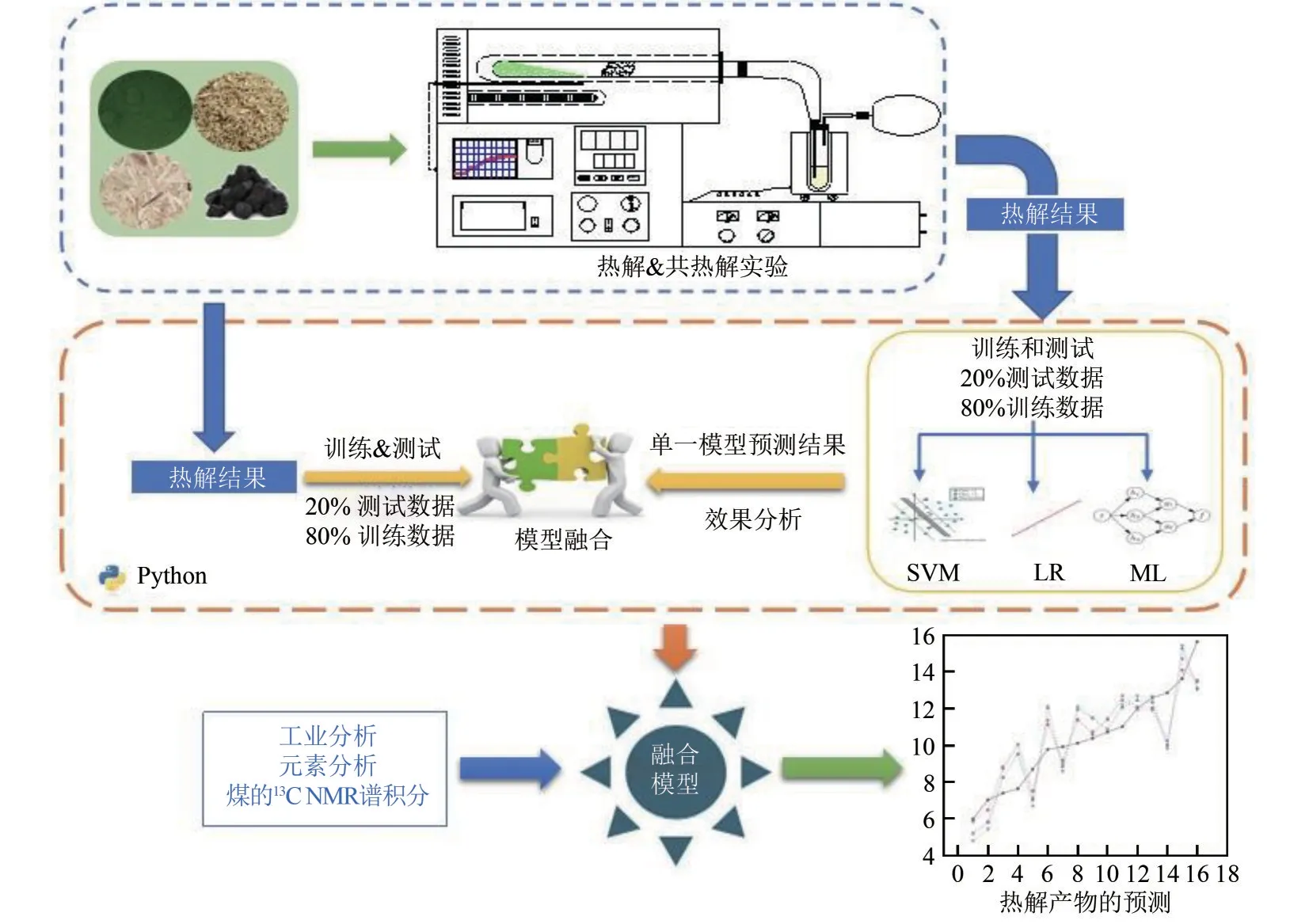
图1 碳基固废热解产物产率预测融合模型
1 实验方法
1.1 样品制备、元素及工业分析
本研究采用棉秆(CS)、稻壳(RH)、木屑(SD)和小球藻(GA)、淮南煤(HN)、神木煤(SM)、大柳塔煤(DLT)和黑山煤(HS)及其混合物为热解实验原料。物料首先被粉碎并研磨至0.178mm(80 目)以下,按照国标(GB/T 474—2008)制备空气干燥基试样后,放入棕色玻璃瓶中,置于5℃饱和湿度冰箱保存。在实验中,生物质和煤的干基样品按照不同的比例[(5/100)~(50/100)]进行混合。生物质和煤的工业分析分别依据GB/T 28731—2012 和GB/T 212—2008 完成。元素分析利用Macro Cube(Elementar,Germany)元素自动分析仪进行测定。上述测定结果如表1所示。
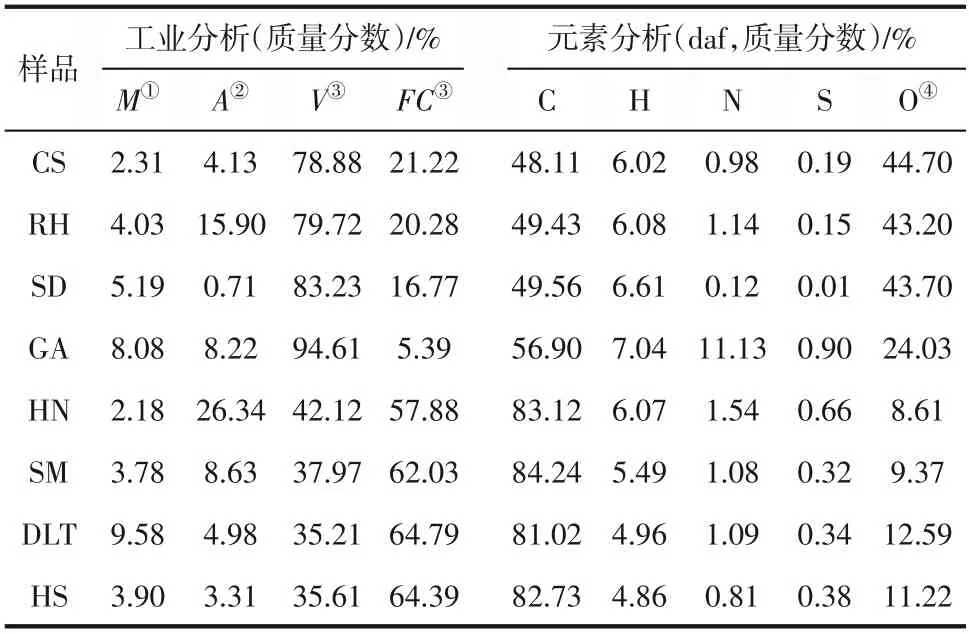
表1 实验原料的工业分析和元素分析
1.2 热解实验
生物质与煤的共热解实验在自制的热解炉中进行,实验装置如图2所示。先将预制的生物质和煤样混合,然后称取约10g混合物,放入石英管反应器中。以5℃/min 的升温速率将混合物从室温加热至600℃。实验后,称量石英管反应器中的半焦重量。将热解油和水用丙酮从冷凝器中冲洗收集,再通过旋转蒸发器在65℃常压条件下,将丙酮去除,然后利用正己烷通过微波辅助方式提取热解油中的正己烷可溶物(主要为烷烃、芳烃及其衍生物),并测定其产率。用气袋收集气体,根据焦炭产率、热解油产率和水产率的不同确定其产率,不同碳基固废热解实验结果可见之前所做工作。
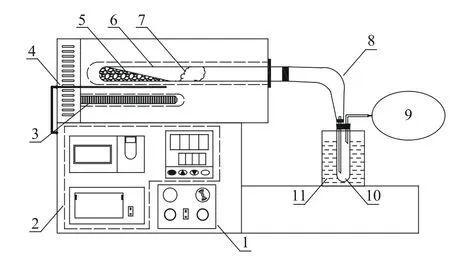
图2 管式干馏实验装置图
2 FUSION模型的建立
碳基固体废弃物的热解可以理解为热分解和自由基反应过程。在热解过程中,随着温度升高,碳基固废会通过化学键断裂释放出大量的小分子自由基,再通过自由基反应生成热解气和热解油。由于碳基固废多为高分子混合物,各组成的热分解性质差异较大,因此在热解过程中存在较为明显的交互作用,导致热解产物分布发生非线性变化。单一算法模型往往难以较为精确地预测因交互作用导致的热解产物分布变化的实际问题。比如,研究发现,SVM 模型和LR 模型对木质素纤维素类的木屑、棉秆的热解产物产率具有较高的预测精度,但对含有脂肪和蛋白质的小球藻的产物预测与实验值相比存在较大偏差。在热解过程中,热解产物分布主要受生物质和煤的热分解性及其热解过程中产生的自由基间的化学反应的影响。因此生物质和煤的工业、元素分析,煤的芳香碳结构都与热解产物产率存在较高的直接相关性。表2 为煤的C CP/MAS/TOSS NMR谱积分结果,具体实验方法可见本文作者课题组之前的工作。
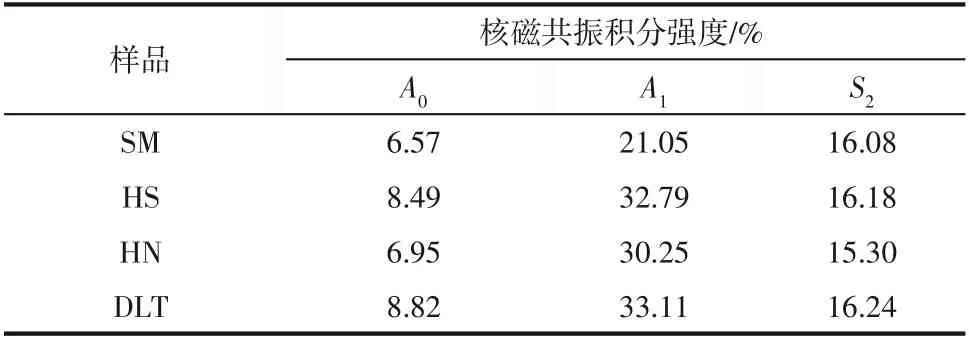
表2 煤的13C CP/MAS/TOSS NMR 谱积分结果
因此确定输入参数为挥发分(, %, daf)、灰分(,%,d)、氢碳比(H/C)、氧碳比(O/C)、生物质在混合物中的质量分数(%,daf)、烷基面积占比(,%)、芳香取代碳面积占比(,%)和含氧官能团面积占比(,%)8个参数。一般地,比照石油产品,用热解油中可溶于正己烷的有机物含量作为评价热解油品质的重要指标,因此模型训练和测试的输出参数确定为热解油产率(Tar,%,daf)、热解油中正己烷可溶物产率(HEX,%,daf)、热解水产率(Water,%,daf)和半焦产率(Char,%,daf)。根据选定参数进行代码编写,选取80%实验数据进行模型训练,20%实验数据用于模型测试。为克服热解交互作用对碳基固废热解产物产率预测精度的影响,本研究首先选择SVM、LR、ML 三种模型,利用热解和共热解实验产物产率结果进行训练和测试,再由机器算法对三种模型进行效能分析和模型融合。融合后的模型再经热解产物产率实验数据进行训练和测试,最终形成具有自适应能力的融合模型。
图3 为FUSION 模型结构。在模型建立的过程中,首先将热解实验结果分为两部分,80%用于模型训练,20%用于模型测试。然后选择适宜的线性回归方程、支持向量机线性函数和神经网络类,将训练用数据集导入。接着调用Python编程语言中的Pandas 机器学习库,生成LR 模型;调用Scikitlearn机器学习库,生成SVM模型和ML模型。再将测试数据集的输入端数据(原料的工业分析、元素分析和煤的C NMR 谱积分结果)导入建立好的LR、SVM和ML这三个单一模型中,将得到的热解产物产率预测结果和实验值进行比对,然后将两者的相对偏差值导入通过Sklearn.metrics 库建立的评价机制,以单一模型的预测精度为标准对单一模型效能进行评价,同时决定其在FUSION模型中的学习权重。将这一权重标准导入单一模型的训练过程,最终将LR、SVM 和ML 模型在权重标准约束下,采用交叉验证的学习方式融合生成具有自适应性的FUSION模型。
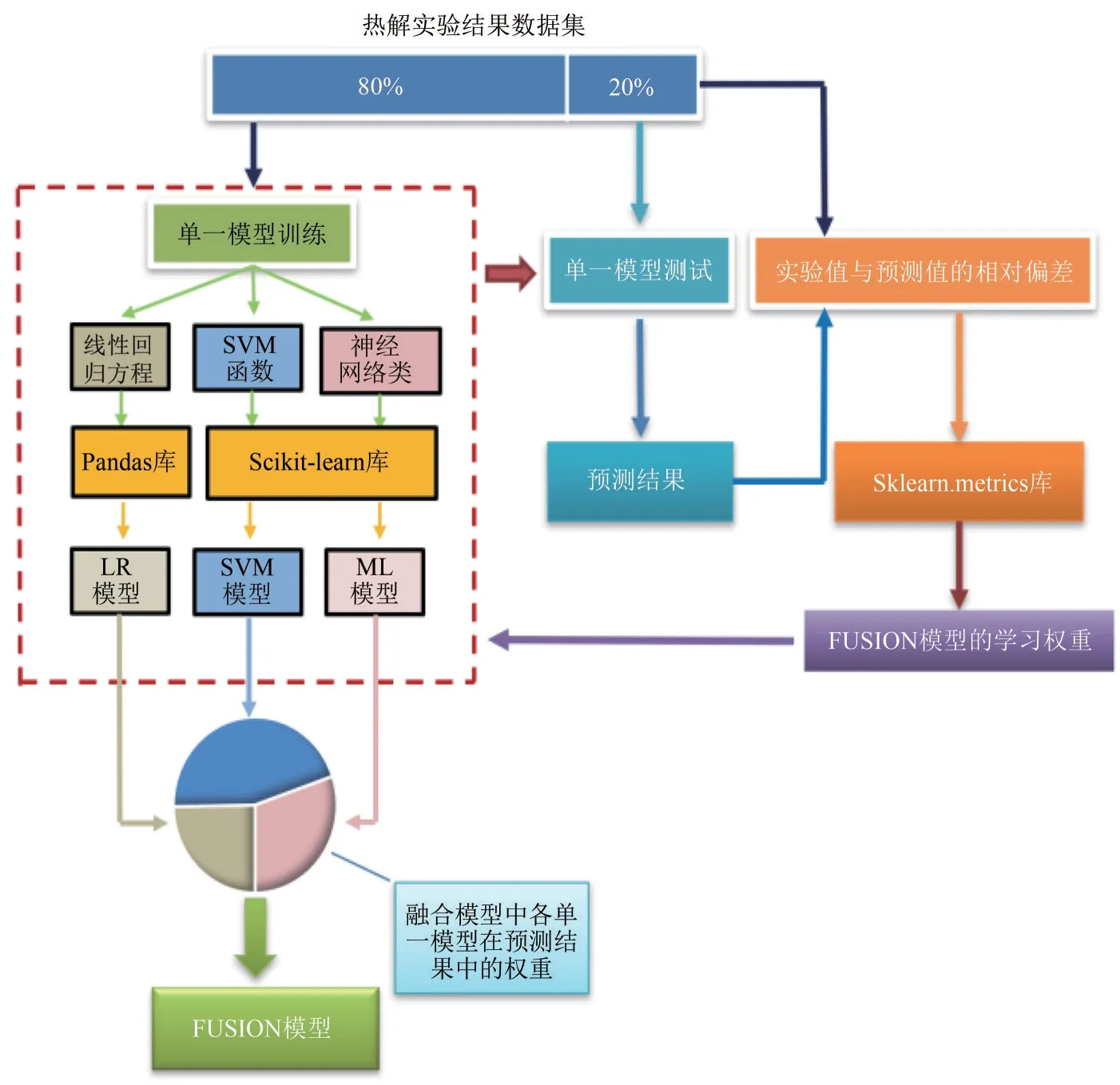
图3 FUSION模型结构图
3 热解模型的训练及能效分析
首先将64组碳基固废热解实验结果导入SVM、LR和ML三种模型中进行训练,然后通过Python平台的融合算法插件对三种模型的训练结果进行效能分析,最终生成FUSION模型。将余下的16组热解实验结果作为测试数据导入上述4种模型,预测值和实验值的相对误差分析、残差分析、均方根误差分析以及决定系数分析等如下所述。
3.1 各模型的均方根误差(RMSE)和决定系数(R2)分析
通过RMSE和评估模型的预测效果,具体计算见式(1)、式(2)。
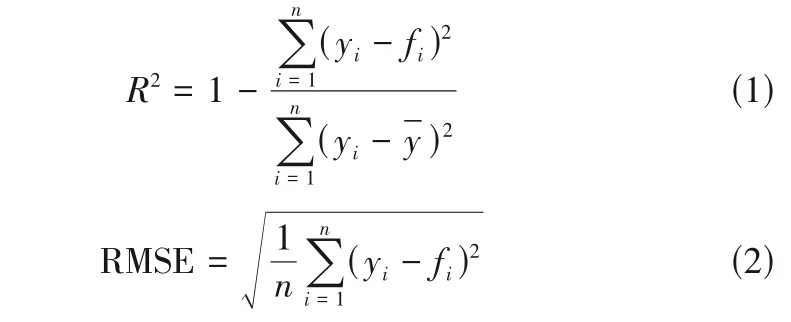
式中,为测试集的数据个数;y、f和ˉ分别为预测值、真实值和真实值的平均值;为建立模型的拟合优度;RMSE为预测值与真实值之间的均方根误差。
根据上述公式计算4种模型对热解产物产率分布的RMSE 值和值,结果如表3 所示。4 种模型的预测效果均可作为预测热解产物产率分布的数学模型,RMSE值均小于0.0713,值均大于0.9995。SVM的预测热解油产率(RMSE<0.0304)显示出比ML和LR更好的准确度,这主要是由于热解交互作用的影响,试样物性与热解产物产率之间存在明显的非线性相关性,SVM 对此类情况的预测效果较好。同时可以发现,LR 在热解水产率预测方面的效果优于SVM和ML,SVM在半焦产率预测方面的效果优于ML和LR。从各模型的RMSE结果分析可知,SVM 的预测效果明显优于ML 和LR,而FUSION 模型的预测效果明显优于三种单一模型。根据预测结果的值可以发现,FUSION 模型和SVM(>0.9999)的整体预测效果明显优于ML(>0.9998)和LR 模型(>0.9996)。上述结果表明,FUSION 模型在拟合优度和均方根误差方面均优于ML、LR和SVM预测模型,说明模型融合提高了预测精度和对热解交互作用的拟合度。

表3 4种模型的RMSE和R2分析
3.2 单一模型和FUSION模型的效能分析
如图4所示,选取16组碳基固废热解后正己烷可溶物产率的实验结果作为测试数据,可以发现4 种数学模型对正己烷可溶物产率的预测效果较好,SVM、LR、ML 和FUSION 模型预测值和实验值的最大相对误差分别为0.85%、0.74%、0.71%和0.7%。FUSION 模型的预测精度最高。4 种模型预测值与实验值的相对误差随着热解正己烷可溶物产率的升高,呈现先升高后降低的趋势。最大相对误差均出现在试样1处,该处生物质在混合物中质量分数为33.33%。随着正己烷可溶物产率的升高,模型预测值与实验值的相对误差逐渐降低。试样9处生物质质量分数为4.76%,该点FUSION模型对正己烷可溶物的产率的预测精度最佳,相对误差仅为0.01。4 种模型的最大相对误差为0.85%,这说明4种模型都能够较好地模拟交互作用对碳基固废热解正己烷可溶物产率的影响,由SVM、LR和ML三种模型融合成的FUSION模型预测效果最佳。
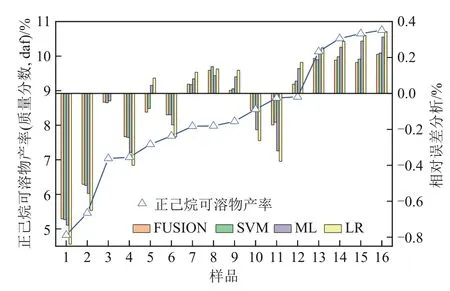
图4 正己烷可溶物产率预测
图5 为热解油产率预测结果,LR 模型的预测值与实验值的最大相对误差为1.68%,明显高于ML(1.22%)、SVM(1.14%)和FUSION 模型(1.00%)的预测相对误差。所有模型的相对误差最大值均出现在试样1处,该处生物质在混合物中的质量分数为4.76%。特别是FUSION模型对16 组共热解热解油试样产率的预测均明显好于其他三种模型。
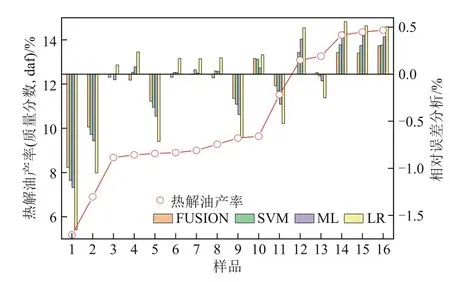
图5 热解油产率预测
如图6 所示,LR、FUSION、ML、SVM 这4 种模型对碳基固废热解水产率的预测值和实验值的相对误差分别为0.31%、0.31%、0.25%、0.25%。说明这4类模型对热解水的预测精度明显高于对热解油和正己烷可溶物的预测精度。FUSION 模型的预测精度低于ML和SVM模型,这可能是由于热解过程中热解水的生成主要由羟基自由基和氢自由基化合生成,该反应不存在中间反应步骤,受交互作用影响较小,因此模型融合对预测精度的提升作用不明显。
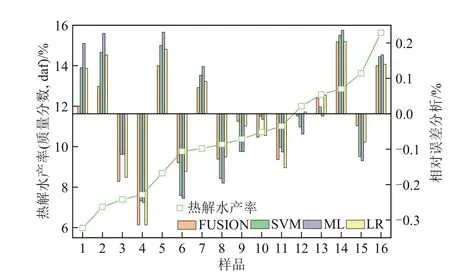
图6 热解水产率预测
如图7所示,在16组共热解试验样品中,ML、LR、SVM 和FUSION 模型的最大相对误差分别为0.17%、0.034%、0.033%、0.033%。可以发现,ML 模型对半焦产率的预测精度明显低于其他三种模型。LR、SVM和FUSION模型的产率预测精度基本相同,且极为接近实验值。
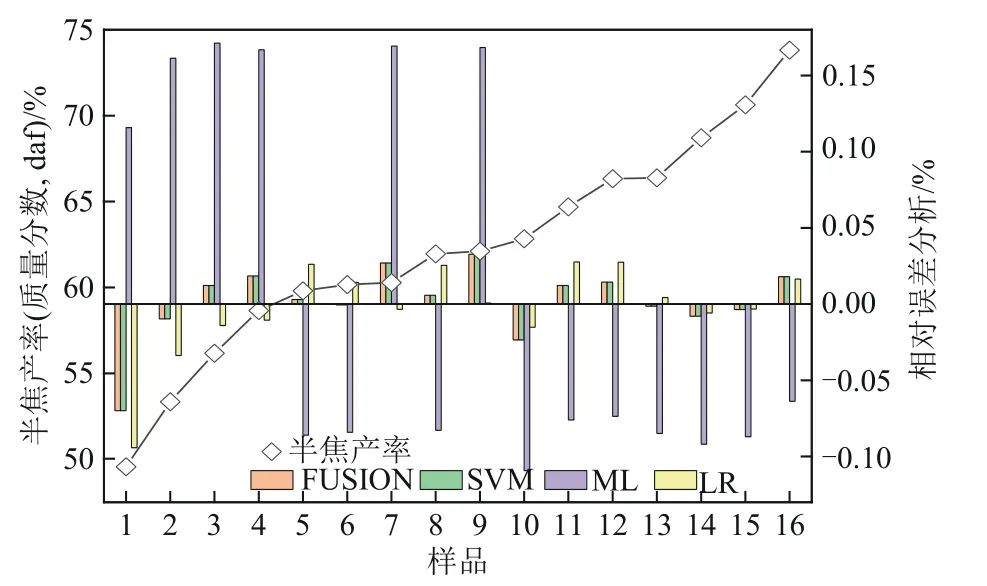
图7 半焦产率预测
总体来看,LR模型对热解油的预测精度较差。ML 模型则不太适合用于预测碳基固废热解的半焦产率。而相对于ML 和LR 模型,SVM 对碳基固废热解各项产物的预测精度较高。相比其他三种单一模型,FUSION 模型在预测正己烷可溶物、热解油、半焦时保持了较高的预测精度,在预测热解水产率时其预测精度与其他三种模型也非常接近。这说明模型融合起到了克服热解交互作用对热解不同产物产率的影响,能够较好地对碳基固废热解全产物产率进行较为准确的预测。其预测值和实验值相比,最大相对误差≤1%。
3.3 SVM和FUSION模型残差分析
根据上述分析,三种单一模型中SVM模型的预测效果优于ML和LR模型,因此本研究选择SVM模型和FUSION模型进行残差对比分析。如图8所示,对于正己烷可溶物、热解油以及热解水三种热解产物FUSION模型的预测值与真实值的离散程度明显优于SVM 模型;对于半焦产率预测,两者的离散程度则近乎一致。
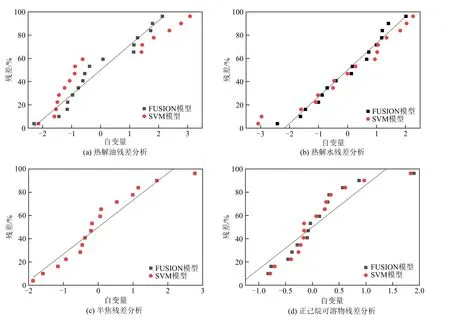
图8 FUSION和SVM模型残差分析
3.4 SVM模型与FUSION模型的相对误差分析
如图9 所示,对于热解油产率预测,FUSION模型的相对误差范围为0.003%~0.1%,平均相对误差为0.22%;SVM 模型的相对误差范围为0.004%~1.141%,平均相对误差为0.256%;对于热解水,FUSION 模型的相对误差在0.006%~0.315%之间,平均相对误差为0.11%,SVM 模型的相对误差在0.007%~0.232%之间,平均相对误差为0.134%;对于正己烷可溶物,FUSION 模型的相对误差在0.02%~0.7%之间,平均相对误差为0.189%,SVM模型的相对误差在0.026%~0.708%之间,平均相对误差为0.193%;对于半焦,FUSION模型和SVM模型的平均相对误差均为0.016%。FUSION模型的误差范围和平均相对误差均要小于SVM 模型,因此FUSION 模型比SVM模型具有更好的预测精度。
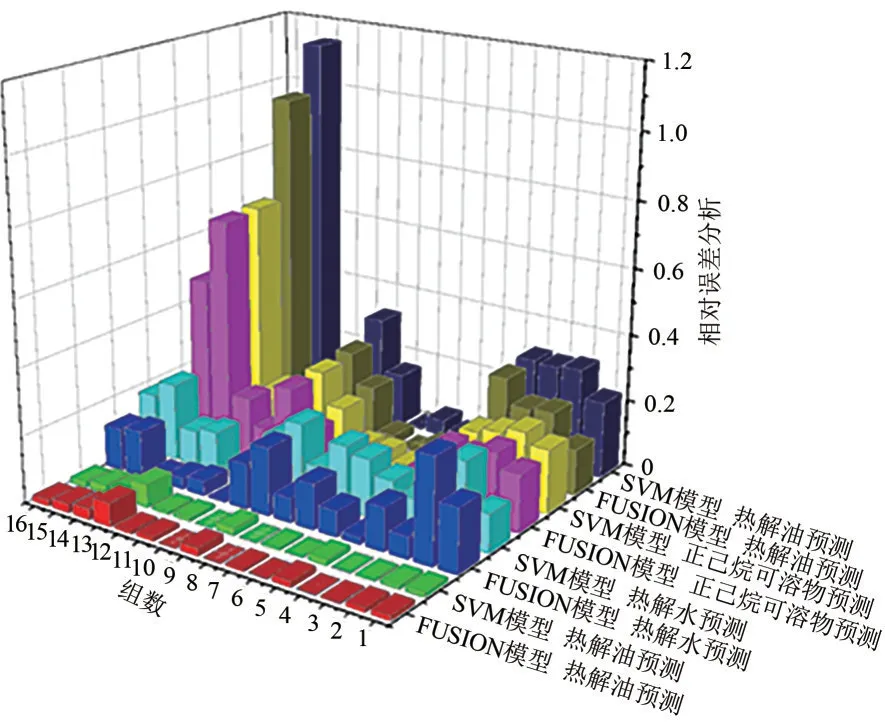
图9 SVM模型与FUSION模型的相对误差分析
4 结论
本文以碳基固体废弃物热解和共热解实验结果为数据源,通过对ML、SVM、LR三种单一模型的训练和融合,建立了具有自适应能力的FUSION模型。通过对三种单一模型和FUSION模型的比较发现,LR模型对热解油的预测精度较低。ML模型在预测半焦产率时存在较大偏差。FUSION 模型则在对热解水、热解油、正己烷可溶物和半焦产率预测时保持了较高的预测精度,其预测值与实验值的最大相对误差≤1%。这说明FUSION 模型能够有效克服碳基固废热解过程中因交互作用对最终热解产物分布的影响,适合用于不同种类的碳基固体废弃物热解产物产率的预测及研究。
