基于改进Jaya算法的置换流水车间调度问题研究
2022-07-15刘梦伊薛燕社马思奕张超勇
刘梦伊,薛燕社,马思奕,张超勇
(1.河海大学 商学院,江苏 南京 211100;2.华中科技大学 机械科学与工程学院,湖北 武汉 430074)
置换流水车间调度问题(permutation flow shops scheduling problem,PFSP)在流程和离散制造企业广泛存在。传统PFSP可以描述为n个工件依次在m台设备上加工的过程,n个工件在m台设备上各加工一次,并且每个工件以相同加工的顺序在设备上进行加工,每台机器上所有任务的执行顺序都必须相同,通过优化每台机器上加工顺序,使得最大完工时间最小。
针对上述传统置换流水车间调度问题,许多学者进行了研究。例如Ruiz等[1]在求解最小化最大完工时间为目标的PFSP时,设计了一种简单有效的迭代贪婪算法。Govindan等 [2]在求解最小化最大完工时间为目标的PFSP时,提出一种混合算法。汤可宗等 [3]提出一种多策略粒子群优化方法,用以求解最小化最大完工时间为目标的PFSP。该方法根据万有引力值划分的子区间,通过信息熵方式度量粒子群的多样性;同时基于蚂蚁路径选择,综合考虑粒子间的距离和惯性质量选出全局最优粒子,为增强群体的全局搜索能力,另行设计了一种新颖的集合变异方式引导群体跳出局部最优。Chen等[4]提出一种改进的离散粒子群优化算法,用以求解最小化最大完工时间为目标的PFSP。该算法提出新的粒子群学习策略,研究如何更加合理地应用全局最优解、局部最优解来指导算法的搜索过程,为了防止搜索过程过早收敛,提出一种新的过滤局部搜索方法,对已审查的解区域进行过滤,并将搜索引导到新的解区域。张敏等[5]提出一种基于改进区块链算法用于求解最小化最大完工时间的PFSP。Fernando等[6]在求解以总流程时间为目标的PFSP时,提出一种有效的构建式启发算法。Karabulut等[7]在求解以最小化总延迟时间为目标的PFSP时,提出一种混合IG算法。
Jaya算法由印度学者Rao[8]于2016年提出,其本质是在求解过程中使所获得的解不断向最好解方向移动,并且远离最差解。与其他智能优化算法相比,它的优势在于需设置的参数较少,原理简单易懂,并且具有较强的寻优能力。针对置换流水车间问题的特点,本文提出一种改进的Jaya算法来对PFSP进行求解,详细介绍改进Jaya算法的实现过程,采用提出的改进Jaya算法对标准实例进行测试,并与其他算法进行对比,验证该算法的有效性。
1 PFSP数学模型
在PFSP问题中,研究最多的目标为最小化最大完工时间,其求解表达式如式(1)~(5)所示。

式中,n为工件总数;m为设备总数;FTi,j为工件i在设备j上的完工时间;PTi,j为工件i在设备j上的加工时间;f1为最大完工时间。
2 改进Jaya算法
2.1 离散化方式
置换流水车间实质上是对n个加工工件序列进行排序。因此相对于标准Jaya算法无需考虑变量j,只考虑个体k和迭代次数i即可,改进Jaya算法(improved jaya algorithm,IJA)的迭代表达式可由式(6)表示。式中,k和i分别为个体和迭代次数;Gk,i+1为第k个个体在i+1代时所对应的工序序列;Gk,i为第k个个体在i代时所对应的工序序列;Gbest,i为种群在i代时所对应的最佳工序序列;Gworst,i为种群在i代时所对应的最差工序序列;r1和r2分别为Gk,i与Gbest,i和Gworst,i的相似度,当Gk,i与Gbest,i或Gworst,i在相同的序列位置有相同的工件时r1=1,r2=1,没有相同工件时r1=0,r2=0。

2.2 种群初始化
初始种群通常对算法对优化结果有较明显影响。一个好的初始种群往往可以使算法更快收敛到最优解或近优解,进而提升算法的效率。为保证初始种群同时满足具有相对较优解和和解广泛分布性这两个条件,本文采用启发式算法和随机生成的方式形成个体,并且要求初始种群中的个体各不相同。目前求解置换流水车间的启发式算法有几十种,其中NEH算法是求解FJSP最好启发式算法之一。因此本文采用NEH算法作为初始种群中的启发式算法。
为保证初始种群同时满足具有相对较优解和和解分布的广泛性这两个条件,第1代中的Gbest,i由NEH算法产生,Gworst,i为Gbest,i个体工件序列的逆序,其余个体则随机产生。
NEH算法主要流程如下。
Step 1计算每个工件在所有设备上的总加工时间;
Step 2将工件1,2,...,n按照总加工时间递减的顺序进行排列,得到初始序列G0,其中,n为工件总数,设i=3;
Step 3选择G0中的第1个工件,用第2个工件插入到第1个工件的前后两个位置,分别计算各自的最大完工时间,然后选择最大完工时间较小的序列,将其前后顺序固定,保存到序列Gt中;
Step 4取G0中第i个工件插入到Gt中所有可能的位置,找到最大完工时间最小的序列并保存得到新的Gt序列;
Step 5i=i+1。若i≤n,转到Step 3,否则,算法终止。
2.3 编码与解码
在PFSP中,所有工件以相同的加工顺序依次在不同的设备上进行加工。根据这一特性,改进Jaya算法采用排列编码的方式进行编码,即将所有工件序号的排列当作一个个体。例如,个体Gk={gk1,gk2,gk3,···,gkn},其表达的含义为个体Gk中对应的工件排序为 1,2,3,···,n。然后每个个体按照个体中工件的排列顺序依次在设备1,2,3,···,m上进行加工。其中,1,2,3,···,m为设备的序号;m为总共有m台设备。本文采用的解码方式为排列解码,按照先到先加工的的规则,依次为各个工件安排加工设备,重复操纵直到工件序列中最后一个工件完成在最后一台设备上的加工。
2.4 个体更新方案
为确保Jaya算法趋近最优解,远离最差解的核心思想不变,本文采用4种方式对除最优、最差个体之外的个体进行更新,可以简单概括为先删除后插入、先保留后补全,具体表达式和步骤如方式1、方式2和方式3所示。最优个体通过迭代贪婪算法进行更新,其步骤如方式4所示。
方式1先删除Gk,i与Gworst,i相同序列位置相同的工件即r2=1;若Gk,i与Gworst,i相同序列位置无相同的工件即r2=0,则随机删除Gk,i中的j个工件,j为大于1小于工件总数1/2之间的随机整数;最后将Gbest,i中对应工件插入到Gk,i中的空缺位置,并且更新前后Gk,i不得完全相同。式(7)为表达式,其中,r1∈{0,1}。示意图如图1所示。
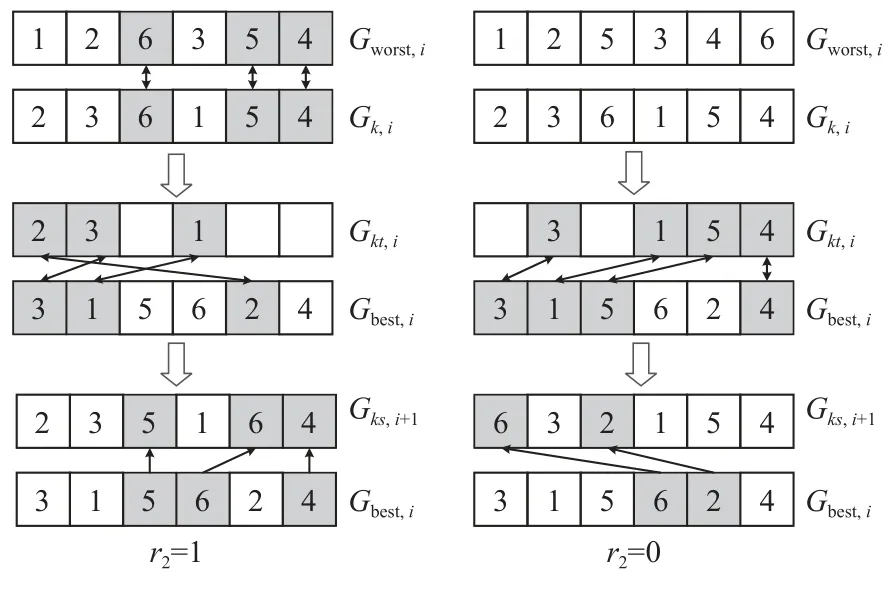
图1 个体更新方式1Figure 1 Individual renewal mode 1

式中,Gks,i+1表示由第i代中的个体k更新后产生的新个体;表示删除Gk,i与Gworst,i相同序列位置相同的工件;表示将Gbest,i中对应的工件插入到Gk,i中的空缺位置,具体步骤如下。
Step 1寻找Gk,i与Gworst,i相同序列位置相同的工件,若有转Step 2,若无转Step 3。
Step 2删除Gk,i与Gworst,i相同序列位置相同的工件,并将删除工件后的Gk,i保存在Gkt,i(临时个体)中,转Step 4。
Step 3随机删除Gk,i中的j个工件,并将删除工件后的Gk,i保存在Gkt,i中,转Step 4。
Step 4用Gbest,i中的工件将Gkt,i中缺少的工件补全,迭代为新的个体Gks,i+1。
方式2首先保留Gk,i与Gbest,i相同序列位置相同工件即r1=1;若Gk,i与Gbest,i相同序列位置无相同的工件即r1=0,则随机保留Gk,i中的j个工件,j为大于1小于工件总数1/2之间的随机整数。再将Gworst,i中对应工件按不同于Gworst,i中的顺序插入到此时Gk,i的空缺位置中,并且Gk,i在更新前后不得完全相同。式(8)为表达式。其中,r2∈{0,1}。示意图如图2所示。

图2 个体更新方式2Figure 2 Individual renewal mode 2
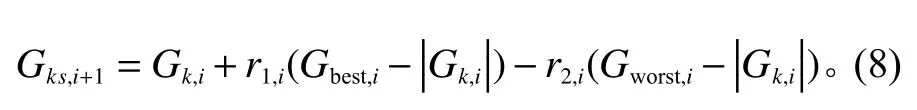
式中,Gks,i+1表示由第i代中的个体k更新后产生的新个体;表示Gk,i中保留Gk,i与Gbest,i中相同序列位置相同的工件;表示将Gworst,i中对应工件按不同于Gworst,i中的顺序插入到此时Gk,i的空缺位置中。具体步骤如下。
Step 1寻找Gk,i与Gbest,i相同序列位置相同的工件,若有转Step 2,若无转Step 3。
Step 2保留Gk,i与Gbest,i相同序列位置相同的工件,并将保留工件后的Gk,i保存在Gkt,i中,转Step 4。
Step 3随机保留Gk,i中的2个工件,并将保留工件后的Gk,i保存在Gkt,i中,转Step 4。
Step 4用Gworst,i中的工件将Gkt,i中缺少的工件补全,迭代为新的个体Gks,i+1。
方式3为进一步增强种群间个体交流,将方式2中的Gworst,i变为Grand,i,其中,Grand,i为第i代个体中除最优、最差和自身个体外的一个随机个体,其余操作和步骤与方式2相同。
方式4对当代最优个体行迭代贪婪搜索,其步骤如下。
Step 1从Gbest,i中随机去除p个工件,形成,将删除的工件按删除顺序组成,设置q=1;
Step 2从中取出第q个工件,插入到中任意位置,取目标函数值最小的插入序列作为新的;
Step 3如果q<p,q=q+1,转到Step 2,否则终止操作,生成Gbest,i+1。
在迭代过程中可能会出现两个极端情况,分别为Gk与Gbest完全相同或Gk与Gworst完全相同,会导致个体中出现重复个体,如果不能及时解决上述问题,可能会使迭代提前陷入局部最优,不利于寻找最优解。本文采取的措施是随机交换Gk中两个工件的位置,这样不仅可以避免个体重复,还增加了种群的多样性。
2.5 局部搜索
本文的局部搜索分为两个阶段,第1阶段针对所有个体,第2阶段仅针对最优个体。
1)第1阶段。
所有个体均采用4种邻域结构进行局部搜索,4种方式分别为向前插入、向后插入、随机交换和中心反转,如图3所示。

图3 4种邻域结构Figure 3 Four neighborhood structures
向前插入:随机选择两个不同的工件,将工序中靠后的工件插入到另一个工件的前面。
向后插入:随机选择两个不同的工件,将工序中靠前的工件插入到另一个工件的后面。
随机交换:随机选择两个不同的工件,将它们在工序中的位置进行前后交换。
中心反转:随机选择两个不同的工件,将这两个工件的中心位置作为反转的对称轴,依次将对称轴两侧包含这两个工件以及这两个工件之间的工件进行反转。
第1阶段的步骤如下。
Step 1令i=1,记个体为Gi,通过4种邻域结构分别对Gi进行局部搜索;
Step 2计算Gi的4种邻域解的目标值,选择最好的邻域解记为;
Step 3如果优于Gi,则令替换Gi,否则Gi保持不变,令i=i+1;
Step 4若i<n+1,则转Step 1,否则结束局部搜索,其中,n表示种群中的个体总数。
2)第2阶段。
对当前种群中的最优个体进行迭代贪婪搜索,通过其毁坏操作和构造操作来对最优个体进行进一步搜索,增大寻找到最优解的概率。其步骤如下。
Step 1设定需要去除的工件个数p。
Step 2从Gbest中随机去除p个工件,形成,将删除的工件按删除顺序组成,设q=0;
Step 3从中取出第q个工件,插入到中所有可能的位置,取目标函数值最小的插入序列作为新的;
Step 4如果q<p,q=q+1,转到Step 2,否则终止操作,生成G*best;
Step 5如果G*best的目标函数值优于Gbest,则令Gbest=G*best,否则Gbest保持不变。
2.6 多样性控制策略
随着种群中个体的不断进化,每个个体将会变得越来越相似,这也意味着种群间的多样性变得越来越差,进而导致搜索停滞,造成算法早熟。这里所称相似度是指种群所有个体中同一工件出现在工件序列相同位置的情况。为避免这一现象的发生,本文采用算法重启机制来增加种群中个体的多样性。当种群内部的多样性指标低于某一门槛值β时,就在当前种群的基础上产生一个新种群,进而使算法在新种群的基础上继续进行搜索。这样,就有可能增大算法跳出局部最优的概率,从而开辟一个新的搜索空间。在新种群中,50%的个体由当前种群中较好的前50%个体组成,另外50%的个体随机产生。为评价种群的多样性,本文使用的评价指标为文献[9]中提到的基于工件位置的矩阵表达式评价方法。
2.7 算法流程
本文求解最小化最大完工时间的流程如图4所示。
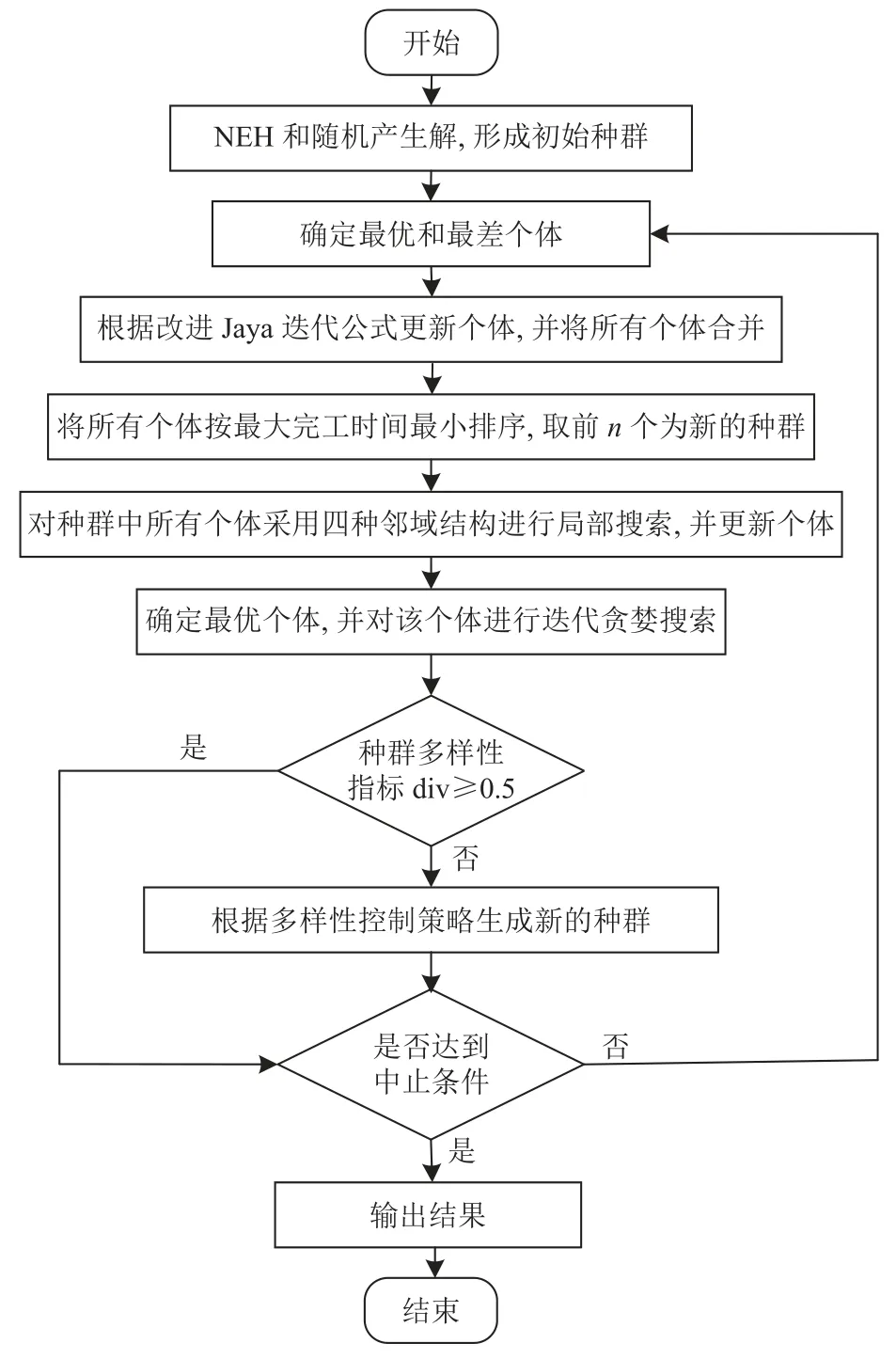
图4 改进Jaya算法流程Figure 4 Flow chart of improved Jaya algorithm
Step 1设置种群规模、终止条件等参数。
Step 2生成初始种群Pt,通过本文中提到的NEH算法和随机的方式生成个体。
Step 3以最大完工时间最小为目标值确定最优和最差个体。
Step 4根据改进的Jaya迭代公式更新个体。除最优和最差个体外,每个个体均采用方式1、2、3共3种方式来更新个体,更新后个体组成的种群为P't,将Pt和P't合并形成Qt。
Step 5以最大完工时间最小为目标将Qt中的所有个体进行排序,取前n个个体组成新的种群NPt,其中,n为种群规模。
Step 6对NPt中所有个体采用4种邻域结构进行局部搜索,并进行个体更新,具体见第1阶段局部搜索。
Step 7确定此时种群中新的最优个体,并对该个体进行迭代贪婪搜索,更新最优个体,具体见第2阶段局部搜索。
Step 8如果div < 0.5,根据多样性控制策略生成新的种群,如果div≥0.5,则保留现有种群。
Step 9在满足终止条件前,循环执行步骤Step 3~6,否则输出结果。
3 实验结果与分析
3.1 参数设置
改进的Jaya算法以C++为编程语言,在Visual Studio 2015开发环境中运行。所有实例在神州K650D上运行,笔记本参数为i7 4710MQ 2.50GHz四核CPU、12G内存。通过对实例的大量测试,最终选择初始种群大小为51,局部搜索的次数为Nmax=5,多样性评价指标的值div=0.5。
本文采用Car、Rec和Taillard实例[1]对算法进行测试,其中,8组Car实例、21组Rec实例和110个Taillard实例。算法的最长运行时间均设为0.3×n×m(s),其中,n代表加工的工件个数;m代表所用到的设备数。每个实例均独立运行10次。
3.2 结果分析
首先对Car实例和Rec实例用改进Jaya算法进行测试,其中8组Car实例均为小规模问题;21组Rec实例的规模从小到大分为7组,各组的实例规模相同。对比算法为文献[10]提出的PSOVNS,文献[11]提出的PSOMA和文献[12]提出的L-HDE。采用最优百分比偏差BRE和平均百分比偏差ARE对测试结果进行评价。计算公式为

其中,Si表示各算法在求解实例时得到的最好解;Sav表示算法在实例的10次运算过程中取得的平均解;UB表示实例的已知上界。从式(9)和式(10)的计算方式可得,当各算法求解的BRE和ARE的值越小,说明算法的性能越好。测试结果统计如表1所示,表1中,n|m为实例的规模;平均值为各算法对29组实例求解结果和的均值。
从表1中可知,在29组实例中,IJA算法得到20个实例的上界,另外3种算法求解到实例上界的个数分别为11、16和18,IJA算法的平均BRE为0.20,另外3种算法的平均BRE分别为1.01、0.50和0.36,表明IJA算法在求解最优解的性能上优于另外3种算法,具有更强的寻优能力。在29组实例中,IJA算法求得的ARE仅在Rec23和Rec25上略差于L-HDE算法,其余26组实例的ARE均优于另外3种算法,IJA的平均ARE为0.33,另外3种算法的平均ARE分别为1.44、0.95 和0.55,表明IJA算法具有更好的稳定性。

表1 基于Car和Rec实例的算法性能比较Table 1 Comparison of algorithm performance based on Car and Rec instances
为进一步测试算法的性能,本文还对110个Taillard实例进行了测试。Taillard实例中每10个实例为一组,每组内的实例规模相同,实例规模从小到大依次递增,最大实例规模为200工件和20设备。对比算法为文献[13]提出的HMSA、文献[14]提出的Proppsed和文献[15]提出的PSOENT。测试结果如表2和3所示。表2中,Sbest为各算法求得对应实例的最优解,加粗的结果表示算法求解到了实例的上界,UB和BRE与表1中的含义相同。表3中的最优解个数表示各算法在求解110个Taillard实例时求解到上界的个数,平均值表示在11组规模不同案例的ARE和的均值。
从表2可知,在110个Taillard实例中IJA求得了49个实例的上界,HMSA、Proppsed和PSOENT分别求得了0、23和31个实例的上界,表明IJA算法在求解最优解的性能上优于另外3种算法,具有比另外3种算法更强的寻优能力。从表3中可知,无论是每组相同规模的平均BRE,还是全部11组共110个实例的平均BRE,IJA算法均优于另外3种算法,表明IJA算法具有更好的鲁棒性。
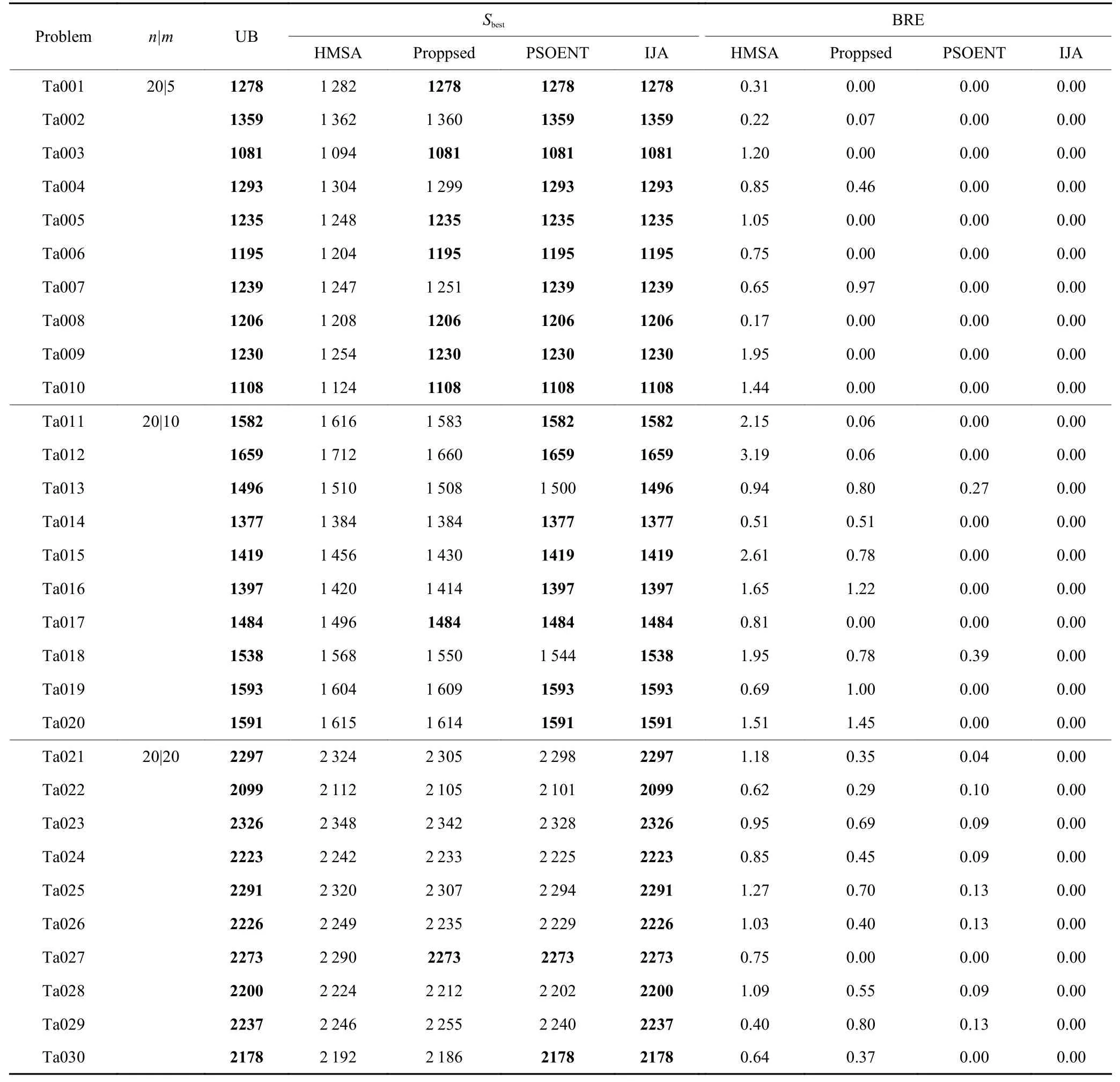
表2 基于Taillard实例的算法测试结果比较Table 2 Comparison of algorithm test results based on Tailard instances

续表
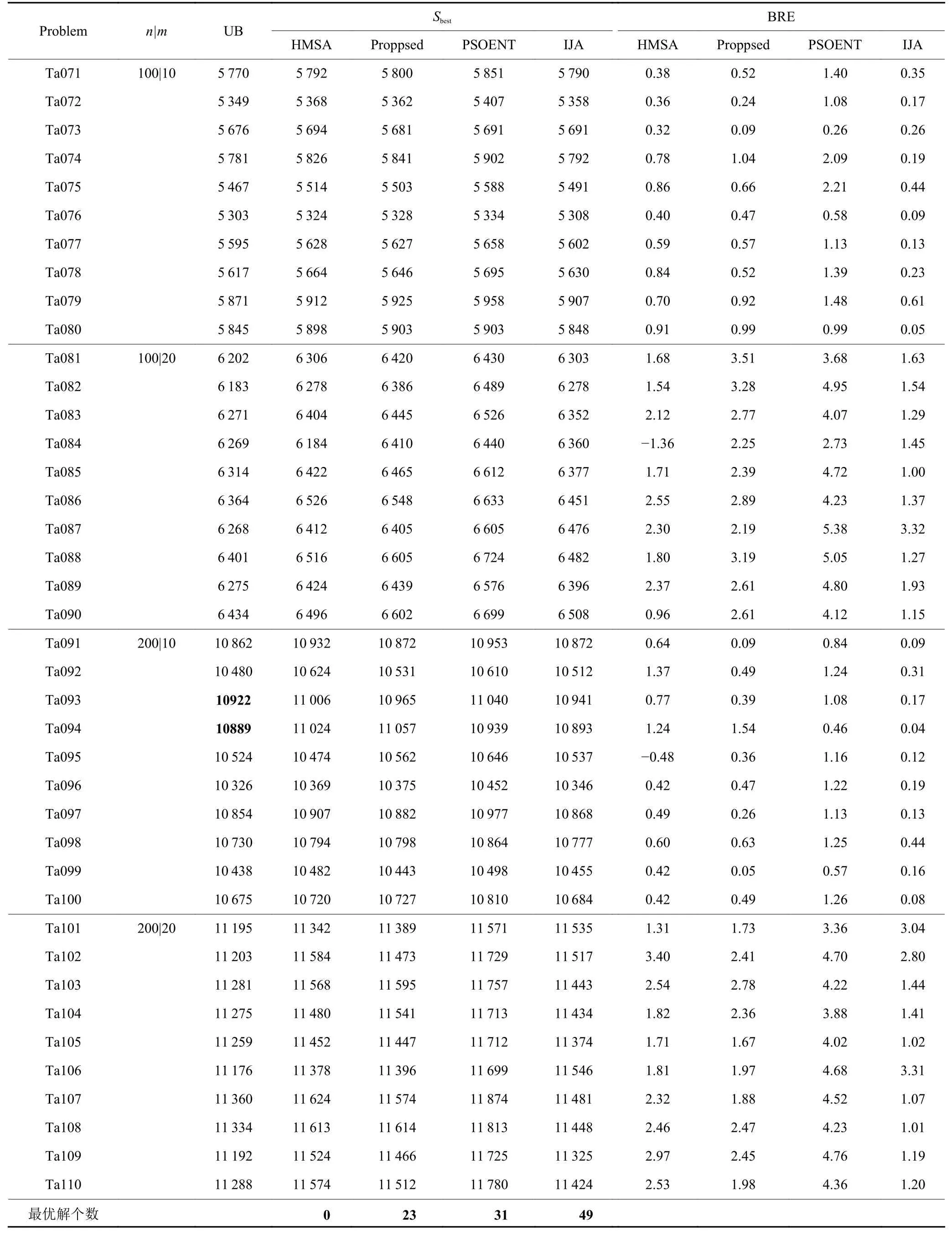
续表

表3 基于Taillard实例的算法稳定性比较Table 3 Comparison of algorithm stability based on Tailard instaces
4 结论
本文针对以最小化最大完工时间为目标的PFSP,提出一种改进的Jaya算法。改进Jaya算法通过NEH和随机的方式产生初始种群,基于Jaya算法趋近最优解、远离最差解的核心思想采用4种方式对个体进行更新,为进一步提高算法的局部搜索能力,采用4种邻域结构对所有个体进行局部搜索,同时还对每代个体中的最优个体进行迭代贪婪搜索,使算法跳出局部最优。为保证种群的多样性,还加入了种群多样性控制策略。最后通过对Car实例、Rec实例和Taillard实例进行测试,并与其他算法进行对比,证明本文所提算法在求解以最小化最大完工时间为目标的PFSP时的有效性和鲁棒性。
