基于三元训练的跨领域依存句法分析
2022-07-15李帅克李正华
李帅克,李 英,李正华,张 民
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
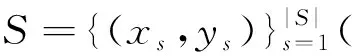
半监督学习中的自学习方法(self-training[3])是一种利用标注数据和无标注数据进行模型训练的代表性方法.其核心思想是利用在标注数据上训练得到的模型去自动分析无标注数据,然后选择高置信度的自动标注数据作为额外训练数据.训练流程如下:首先在标注数据上训练一个模型,然后使用这个模型去预测无标注数据,接着把置信度高的自动标注数据加入到有标注数据中,最后利用拼接后的数据重新训练一个模型.重复上述过程直到模型性能不再提升.三元训练(tri-training[4])与self-training的训练方式类似,不同之处在于tri-training使用多个模型投票进行自动标注数据的选择而非显式的置信度评估.
然而,直接把self-training应用于领域移植的效果往往并不理想.其主要原因是目标领域自动标注数据包含了大量的噪声,此时噪声带来的坏处超过了使用目标领域无标注数据带来的好处,使用该数据反而对模型产生了干扰.因此,如何筛选高质量的自动标注数据是self-training的主要挑战.为了解决此问题,前人做了一些探索.Mcclosky等[5]使用重排序策略获得高置信度的自动标注数据并加入到训练集,成功地把self-training应用到成分句法分析上.Kawahara等[6]通过一个额外的分类器来判别自动标注数据是否可靠,成功地把self-training应用到依存句法分析上.Yu等[7]尝试使用基于句法解析树分值的置信度选择策略和基于Delta分值的置信度选择策略进行依存句法分析.他们的实验结果进一步证实了自动标注数据的质量在领域移植场景下依然至关重要,但是这些方法需要显式的置信度评估.Sogaard等[8]把tri-training应用到了依存句法分析上,使用两个模型的预测一致性进行自动标注数据的置信度评估从而简化了训练流程.Li等[9]运用tri-training的同时使用BERT[10]作为模型的编码层,取得了NLPCC-2019句法分析评测开放赛道上的最佳结果.
Tri-training作为一种简洁的生成自动标注数据的经典方法,目前仍缺乏将其应用于跨领域依存句法分析任务的系统性深入研究.为了解决这个问题,本研究使用3种简单的多模型决策协同训练算法——tri-training,来保证自动标注数据的质量进而提升跨领域依存句法分析性能.这3种算法分别从横向和纵向两个方面完成自动标注数据的筛选:同一时间轮次下3个模型预测一致的数据、同一时间轮次下当前模型之外的另两个模型预测一致的数据、当前轮次之前两轮的模型预测一致的数据.此外,本研究使用目标领域的无标注数据对BERT模型进行微调从而获得领域相关特征以进一步增强模型的编码能力.
为了验证tri-training是否可以提高自动标注数据的质量,进而提升跨领域依存句法分析性能,本研究在NLPCC-2019评测任务发布的依存句法分析领域移植数据(http:∥hlt.suda.edu.cn/index.php/nlpcc-2019-shared-task)上进行了实验.为了进一步分析跨领域模型性能下降的原因以及tri-training和BERT为什么可以提升跨领域模型的性能,本文还设计了详细的分析实验.
1 方 法
本章节会逐次介绍基础模型框架、多模型决策协同训练策略和预训练语言模型的微调过程.首先使用双仿射句法分析器[1]作为基础模型,然后在此模型的基础上使用多模型决策协同训练策略生成高质量的目标领域自动标注数据,从而提升跨领域模型性能.最后使用目标领域的无标注数据对BERT模型进行微调,并将其作为模型的特征进一步提升模型性能.
1.1 双仿射句法分析器
本研究将简明高效的双仿射句法分析器作为基础模型.模型框架如图1所示,该句法分析器包含4个模块:输入模块、双向长短期记忆网络(BiLSTM)编码模块、多层感知机注意力(MLP)模块和双仿射打分模块(Biaffine).
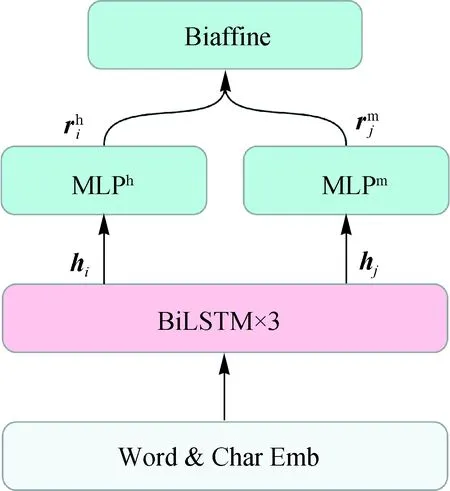
图1 双仿射句法分析器模型框架Fig.1 Framework of biaffine dependency parser
1) 输入模块:把输入句子映射为向量表示.该模块把输入序列映射为输入向量表示X=[x0,x1,…,xn],每一个输入向量xi都由对应的词向量和词向量对应的字符集双向长短期记忆网络(CharBiLSTM)表示组成.
xi=e(wi)⊕CBiLSTM(wi),
其中:e(wi)是冻结的预训练词向量与随机初始化可更新词向量的和;CBiLSTM(wi)是将wi对应的字符输入到一层的双向长短期记忆网络,然后拼接前向、后向最后的隐向量获得的[11],本研究发现在输入模块中用CharBiLSTM替换文献[1]中提到的词性嵌入会带来稳定的模型性能提升.
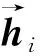
3) MLP模块:对BiLSTM的输出进行降维,去除与句法无关的信息.该模块以隐向量作为输入使用两个不同的MLP模块得到句法向量表示.

4) 双仿射打分模块:使用双仿射函数对有所依存弧进行打分.
其中,sij是依存弧i→j的分值,Wb为双仿射层的参数.本研究参照Dozat等[1]的研究,采用额外的多层感知机对依存关系进行打分,此处不再赘述.
5) 训练损失:采用词级别的非结构化损失函数,即最大化每个词对应的正确核心词的局部概率.假定词wj的核心词是wi,其对应的交叉熵损失为:
其中,n为句子长度.最终所有词的损失累加起来构成句子的损失,不考虑任何树结构约束.
6) 解码策略:分两个阶段按序进行依存骨架树的解析和依存关系的解析.首先是用最大生成树算法[12]得到分值最高的一颗依存骨架树y*.
s=∑(i,j)∈ysij,
其中y是输入x对应的所有可能的依存句法骨架树.然后采用贪婪分类的策略为树中每条依存弧分配一个依存关系,得到一个最优的依存标签树.
1.2 多模型决策协同训练策略
把经典的self-training应用到跨领域句法分析上包括以下几步:
1) 在源领域训练集上训练一个初始模型.
2) 使用初始模型预测目标领域的无标注数据.
3) 把置信度高的自动标注句子加入到源领域训练集构成一个新的训练集.
4) 在新训练集上重新训练一个self-training模型.
5) 重复上述过程直到新模型的性能不再提升.
自动标注数据的质量对模型的性能至关重要,但是目前仍缺乏将其应用于跨领域依存句法分析任务的系统性深入研究.为了解决这个问题,本研究使用3种不同的tri-training算法进行自动标注数据的筛选.即两种横向、一种纵向的tri-training算法,相应的伪代码见附录(http:∥jxmu.xmu.edu.cn/upload/html/202204xx.html).
(i) 算法1(v-tri):首先在源领域训练集上使用不同的随机种子训练3个初始模型,其中包含一个主模型M0及两个辅助模型M1和M2(主模型和辅助模型按照时间顺序进行划分,即第一个训练的模型为主模型,其它的为辅助模型).如果这3个模型在无标注数据上的预测结果一致,则把预测的自动标注数据加入到训练集中.接着在新训练集上重新训练主模型,本研究把主模型的性能在五轮内是否提升作为算法的停止条件.每一轮训练期间都进行停止条件判断,如果不满足停止条件则训练两个辅助模型;否则,将满足停止条件的峰值性能最高的主模型作为最终的模型.先进行模型性能的比较,可以省去不必要的辅助模型训练.最后使用主模型M0在目标领域上进行性能测试.
(ii) 算法2(c-tri):与算法1类似,同样训练3个初始模型,对于每一个模型,将另外两个模型预测一致的数据加入到本模型的训练集中.
(iii) 算法3(i-tri):与Li等[9]类似,将当前轮次之前两轮模型预测一致的自动标注数据加入到当前轮次的训练集中.不同于Li等[9]使用BERT作为编码层,本研究使用BiLSTM作为编码层并使用BERT进行微调(详情见1.3节).
1.3 BERT微调
以BERT[10]为代表的大规模语料上的预训练语言模型往往采用Transformer[13]架构,其优势在于可以使用近乎无限量的无标注数据且学习到的表征可以在多个任务中进行快速迁移.将预训练模型接入一个任务特定的模型,然后在新的数据集上进行微调是一种比较典型的预训练模型应用方式.例如Howard等[14]提出通用语言模型微调,在6种文本分类任务上达到了最佳; Sun等[15]使用目标领域的数据和多任务学习在文本分类任务上进行微调;Xu等[16]提出了评论阅读理解任务并使用后训练策略进行微调.
Li等[17]的工作表明使用目标领域无标注文本对通用预训练模型进行多轮微调,即继续使用掩码语言模型损失函数进行训练,可以在依存句法分析领域移植任务上取得显著的性能提升.鉴于此,本研究使用Google开源的bert-base-chinese(https:∥github.com/google-research/bert)模型作为原始模型,在所有领域的train/unlabeled原始文本上仅使用掩码语言模型损失进行训练.与Li等[18]的工作保持一致,使用BERT的输出b(wi)替换词向量e(wi)作为模型的输入特征进行模型训练,其中b(wi)是由BERT最后4层的输出进行加权求和然后线性映射得到的100维的字表示向量.在训练过程中冻结BERT的参数,不进行更新.
2 实 验
2.1 实验设置
1) 实验数据:本研究在NLPCC-2019评测任务发布的中文依存句法分析领域移植数据集上进行实验.此数据集包含4个领域,共计4×104句,4个领域分别是1个源领域和3个目标领域,其中源领域来自新闻领域的平衡语料库(balanced corpus,BC),3个目标领域语料库分别来自淘宝标题的产品博客(product blog,PB)、淘宝的产品评论(product comment,PC)、网络小说的“诛仙”(ZhuXian,ZX).本研究直接采用官方划分好的训练集、开发集和测试集,具体的各个领域以句子为单位的统计结果如表1所示.

表1 NLPCC-2019评测数据的统计
2) 评价标准:使用无标签/有标签依存分值(unlabeled/labeled attachment score,UAS/LAS)作为评价指标,其中UAS为核心词正确的词数占总词数的比值,即UAS只考虑依存骨架,不考虑依存关系;LAS为核心节点正确且对应依存关系类型也正确的词占总词数的比值,即LAS同时考虑依存骨架和依存关系.评价时,采用官方的评价脚本,直接忽略没有正确核心词标注的词.
3) 预训练词向量:通过Google开源的word2vec(https:∥code.google.com/archive/p/word2vec/)在Chinese Gigaword V3(约1.1×106句、自动分词)和所有领域训练/无标签原始文本上训练10次迭代得到.
4) 基线方法(baseline):源领域训练集上得到的模型直接在目标领域进行测试.
5) 超参设置:除了数据预处理和输入层的参数外,其它的参数和双仿射句法分析器[1]的参数设置与文献[1]保持一致.在预处理阶段根据句子长度对原始文本进行聚类,然后把聚类后的文本划分为若干个批次,每个批次不超过5 000个词.输入层的字符集BiLSTM的输入维度是50,输出维度是100.
2.2 主实验
最终实验结果如表2所示.其中Li等[9]使用BERT作为模型的编码层,其他方法均使用BERT表示作为额外的输入特征.实验结果表明在基线方法的基础上无论是结合FBERT(fine-tuned BERT)还是tri-training训练策略,模型的性能都有大幅度的提升.且基线方法的性能越低,结合FBERT或tri-training训练策略后提升的比例越大.例如,加入v-tri-training(v-tri)后,模型的LAS值在PB、PC、ZX领域上分别同比增长了13.85%(v-tri vs. baseline)、34.78%和14.53%;加了FBERT(baseline-FB)后,模型的LAS值在PB、PC、ZX领域上分别同比增长了24.51%(baseline-FB vs. baseline)、66.63%和21.97%.即使加了FBERT和v-tri后准确率已经有了显著的提升,把两者结合依然可以进一步提升模型性能.这表明两种方法分别是从不同的角度对模型有帮助,在下一节会进行更深入的探究.

表2 测试集上的最终结果
2.3 分析实验
2.3.1 为什么跨领域模型性能会下降,领域的差异在哪里?
从机器学习建模角度来说,跨领域性能大幅度下降的直接原因是测试集和训练集中的潜在数据分布不同.图2给出了通过源领域(src)和目标领域(tgt)训练集得到的模型的BiLSTM模块的输出进行主成分分析(principal component analysis,PCA)降维可视化(具体地:在目标领域开发集上采样100句输入到源领域和目标领域训练集上得到的模型,然后把模型输出的BiLSTM特征进行PCA降维可视化)后的结果,可以发现两者在高维空间上的特征分布确实存在着不同.

图2 源领域数据和目标领域数据上得到的模型的特征分布Fig.2 The feature distributions of different models which are trained with the source domain or the target domain data
从文学语法层次结构角度来说,句子的分布可能会有词语、句法和语义层面的变化.1) 不同领域使用的词语分布是不同的,有些词语是某些领域所特有的,有些词语在不同的领域的出现频率是不同的.图3是不同领域词频最高的10个词,不同领域中词语分布不尽相同.2) 从句法层面,不同领域的语法结构的分布也会发生变化.例如,祈使句、疑问句、陈述句等在不同领域的文本中相对频率发生变化.句法结构的变化会直接导致语序发生变化,无论是传统基于离散特征的模型,还是深度学习模型,都会受到影响.3) 从语义层面,不同领域的文本涉及的话题、概念的分布也可能发生变化.

图3 不同领域中出现频率最高的10个词Fig.3 The top 10 words with the highest frequency on different domains.
2.3.2 为什么tri-training有用?
前面的实验表明tri-training可以大幅度提升模型性能,在此小节探究为什么tri-training有效.语法是对蕴含在语言中的客观规律的描述,反之,当给定大量的语言实例时,有可能总结出语法规律.而tri-training通过对目标领域的大量无标注数据进行迭代,目标领域的部分语法规则有可能被逐步保留下来.对经过tri-training训练策略后的BiLSTM模块的输出进行PCA降维,得到如图4菱形所示的分布.图4的圆点分布与图2的圆点分布一样,都是目标领域训练集上得到的模型的特征分布情况.可以看出,经过v-tri之后学习到的模型与目标领域训练数据上得到的模型的编码空间更加接近,从而使得模型的跨领域性能有所提升,这也在一定程度上印证了上面的猜想.

图4 Tri-training对模型特征分布的影响Fig.4 The effect of tri-training on feature distributions
2.3.3 为什么FBERT有用?
预训练语言模型是在海量的无标注文本上进行训练的,这些文本往往已经涵盖了所有源领域和目标领域,因此预训练模型对跨领域句法分析非常有用[20].同样的,本研究将使用FBERT得到的源领域模型和目标领域上的模型的特征进行对比,可以看到使用FBERT的输出作为句法模型的输入特征后得到的模型有更广的编码空间,从而使得以FBERT表示作为输入的源领域模型与目标领域模型的编码空间有更多的重合,进而提高了模型在目标领域上的泛化能力.
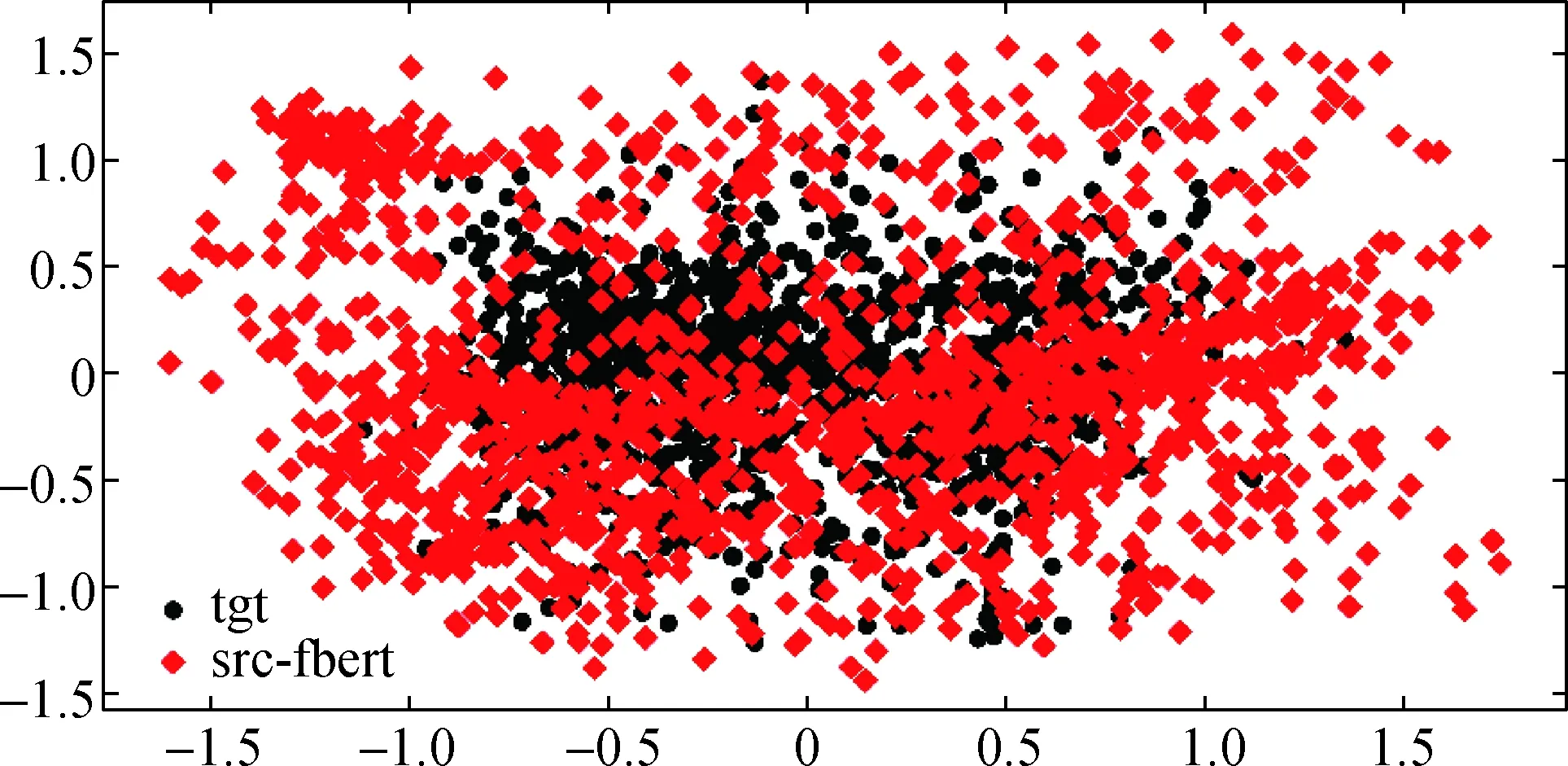
图5 FBERT对模型特征分布的影响Fig.5 The effect of FBERT representations on feature distributions
2.3.4 不同tri-training算法的训练趋势
图6是不同tri-training算法在开发集上的训练趋势.可以看出,不同的tri-training算法皆是增量式地利用目标领域的无标注数据.模型的性能也有着相似的提升趋势,但模型性能的提升主要在前两轮.自学习方法有效的条件是使用大量无标注数据带来的正面影响超过自动标注数据引入的噪音所产生的负面影响.本文中猜测,在训练的后期,无标注数据带来的负面影响超过了正面影响,以至于后期模型的性能不提升甚至有所下降.

图6 不同tri-training训练算法自动标注数据数量和模型性能的变化曲线Fig.6 The change curves of the amount of auto-labeled data and the model performance on different tri-training algorithms
2.3.5 错误分析
图7是不同tri-training算法在ZX开发集上对不同依存标签的预测准确率.得益于tri-training和FBERT,3种算法几乎在所有的依存关系上都有提升,但是各个方法又各有所长.比如说在“adv” 依存关系上,v-tri算法取得了最高的准确率.c-tri在“adjct”依存关系上取得了最高的准确率.而“subj”依存上的最高准确率则是由i-tri算法取得.

图7 不同tri-training算法在ZX开发集上对依存关系的预测准确率Fig.7 The precision of dependency relations by different tri-training algorithms on the ZX development dataset
3 结 论
自动标注数据的质量是自学习方法成功与否的关键,本文使用3种简单的多模型决策系统训练算法(tri-training)来保证自动标注数据的质量进而提升跨领域依存句法分析性能.在NLPCC-2019评测任务发布的数据集上取得了显著的提升并成为了当前最佳,同时还深入探究了导致跨领域模型性能下降的原因以及各个模块的作用.结果表明,经过tri-training之后学习到的模型与目标领域训练数据上得到的模型的编码空间更加接近,从而使得模型的跨领域性能有所提升;使用FBERT后训练得到的模型具有更广的编码空间,从而使得以FBERT表示作为输入的源领域模型与目标领域模型的编码空间有更多的重合,进而提高了模型在目标领域上的泛化能力.
