基于统一描述网络结构模型的链路预测方法
2022-07-14吴翼腾于洪涛顾泽宇
吴翼腾,于洪涛,顾泽宇
(1.信息工程大学 信息技术研究所,郑州 450002;2.中国人民解放军61660 部队,北京 100080)
0 概述
复杂网络链路预测是指运用网络结构信息对节点对之间存在连接的可能性进行预测[1-2]。链路预测具有很强的理论和实际应用价值,可以帮助人们认识复杂网络演化机制与结构信息[3],还可以为生物蛋白质结构网络构建、电子商务商品推荐、资源贸易协调、电信用户通联关系挖掘等任务提供技术支持[4-5]。
链路预测方法主要分为基于网络结构信息相似性、融合网络多维度信息、基于网络结构模型等方法。基于网络结构信息进行链路预测的主要难点是找到网络生成演化机理及生成链路的诱导因素。例如,无标度网络仅由2 条基本假设(网络是不断增长的、增长过程中节点倾向于与度大的节点相连),即可推导出网络中节点的度呈长尾分布这一共性规律[6]。这2 条基本假设通过网络生成机理,解释了度分布不呈正态分布的原因。同样地,如何解释网络中链路的成因来预测未知链路也是链路预测的难点。
基于网络结构信息定义节点对之间相似性的链路预测方法使用单一维度的网络信息或直接明确定义多维度信息的关系,具有理论简洁、效率较高的特点。吕琳媛等[7-8]将节点对的共同邻居数赋予权重,提出共同邻居加权的资源分配指标。YAO等[9-11]提出基于局部拓扑信息加权的相似性指标。刘树新等[12]提出网络中节点间资源传输机理的资源传输匹配度指标。BISWAS等[13-15]考虑网络的社区信息,利用社区信息对经典相似性指标加权,或仅在节点所属社区内计算经典相似性指标,提升链路预测准确度。基于相似性度量的链路预测方法通常是对微观网络结构进行建模,从节点对及其周围的微观结构出发,解析链路形成机理预测链路。
随着网络结构信息研究的深入,网络多维度信息被充分挖掘。为进一步提高相似性指标的准确性和鲁棒性,学者们提出融合网络多维度信息的链路预测方法,例如,组合规则法、OWA 算子融合法[16]、AdaBoost 融合法[17]等基于相似性指标的后端融合方法[18]。基于机器学习或深度学习的链路预测方法将链路预测问题转化为有无连边的二分类问题,本质上也可将其看作多指标经分类器输出的后端融合方法。吴翼腾等[19]详细研究了后端融合方法的理论极限问题,提出并证明了采用组合方法进行链路预测的理论极限定理。后端融合方法主要针对数据建模,侧重于预测的准确性,但却牺牲了算法的可解释性,难以解析网络中链路形成的诱导因素[20]。
基于网络结构模型的链路预测方法从宏观上对网络结构进行建模,首先给出网络生成假设,然后根据网络生成假设求出节点对产生链路的概率,最后利用全概率思想计算某条连边的生成概率,主要包括随机分块模型[21-22]和层次结构模型[23]。随机分块模型假设节点间的连接概率取决于节点所在社区:同一社区内部节点连接概率相同,不同社区间连接概率仅与所在社区有关,通过随机划分节点所在社区,基于某种划分计算社区内和社区间形成连边的概率,并计算社区划分的先验概率,但无法处理重叠社区结构以及节点间的分级与层次结构。层次结构模型对节点间的层次结构进行建模,建立节点连接关系的谱系图,与随机分块模型计算连接概率的核心思想相似,首先计算基于某种谱系图和节点间生成连边概率,然后计算谱系图的先验概率,最后采用全概率思想计算最终的链路形成概率。在基于网络结构模型的链路预测方法中,连边的综合概率加权融合了多种子模型的连边概率,但该融合方法不同于后端融合方法,需对网络结构建模,因此将其概括为综合网络结构信息的前端融合方法。
随机分块模型和层次结构模型从不同角度给出了网络结构描述方式[24],但无法有效处理从宏观、中观网络社区结构到微观低阶环或模体[25]结构中的重叠结构信息,而实际网络中重叠结构无处不在。本文构建一种统一描述网络结构模型,简称USI(Uniform-Structure-Information)模型,既包含节点的层次结构信息,又可使节点从属于不同集合,并基于USI 模型提出一种链路预测方法,通过实验以验证该方法的有效性。
1 问题描述和评价指标
给定t时刻的网络G(V,E),其中,V和E分别表示节点集合和边集合。链路预测的目的是预测未来的t′时刻将要出现的链路或消失的链路,或是预测当前t时刻网络未观测到的链路或错误链路[20],即链路预测方法赋予节点对间链路预测的评分值,按照评分值的大小判定是否存在链路。
为了评估链路预测方法的准确性,需对网络进行训练集和测试集的划分,链路预测方法仅允许运用训练集进行预测。一般使用AUC(Area Under the Receiver Operation Characteristic Curve)衡量预测准确性。AUC 不受有无连边两类样本非平衡性的影响(无连边的节点对远大于有连边的节点对数量),可以理解为在测试集中随机选择一条边的分数值比随机选择一条不存在的边的分数值高的概率[7],即每次从测试集中随机选择一条边,再从不存在的边中随机选择一条边,若前者高则加1 分,若相等则加0.5 分,这样独立比较n次。若有n′次测试集得分高,有n″次两者相等,则AUC 定义如下:

2 统一描述网络结构模型
2.1 统一描述网络结构模型定义
定义1在统一描述网络结构模型中,A0为网络中所有节点组成的集合,集合族Dk中的元素Di也为集合。
1)定义幂集:

对任意i,Ai中具有指定关系f的元素可以组成集合族Dk,Dk={D1,D2,…,Dn}。
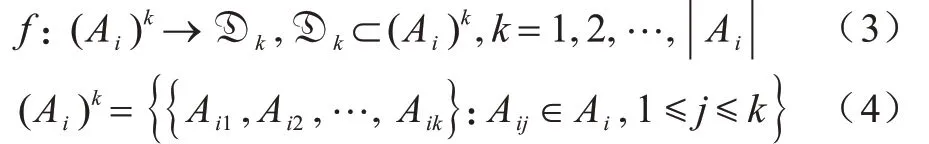
其中:|Ai|表示集合Ai的势,即集合Ai中元素的个数。
特别地,当i=0 时:
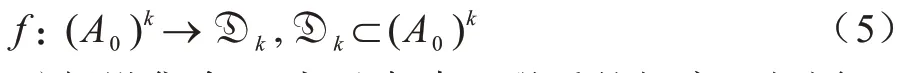
2)假设集合Di内元素建立联系的概率pi相同:
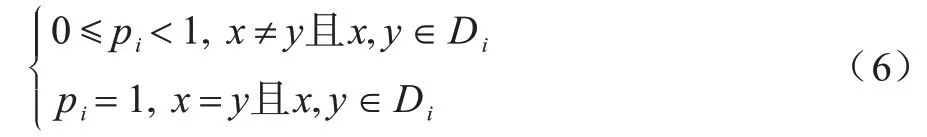
USI 模型可以解释无向网络中各种节点的连接和组织关系,为网络中各类节点的层次关系、重叠关系等建立简明清晰的表示方法。定义1 中的第1 个部分可以理解为有共同特性的元素可以组成集合,第2 个部分可以理解为集合内部元素间发生联系的概率相同。
根据模型定义,组成集合的元素可以是集合或非集合。当集合中元素为非集合时,表示节点对之间存在链路的概率;当集合中的元素为集合时,表示集合与集合建立联系的概率。例如:一个班级中的所有同学组成一个集合,集合中元素为非集合,p表示该班级任意两个同学存在联系的概率;一个学校所有班级组成一个集合,集合中元素班级仍为集合,p表示班级之间建立联系的概率,间接表示班级之间同学建立联系的概率。
定义2在USI 模型中,Ai及其非空子集的元素为i阶元素,i=1,2,…。i阶元素记为X(i),2 阶以上元素称为高阶元素。
定义3在USI 模型中,集合所含元素的阶数称为集合的阶。i阶集合记为X(i),2 阶以上集合称为高阶集合。
例如一个由3 个节点组成的网络,A0={1,2,3},根据定义2,元素1、2、3 都是0 阶元素,根据定义3,A0是0 阶集合。由于元素{Ø,{1},{2},{3},{1,2},{1,3},{2,3},{1,2,3}}=A1,因此元素{1,2}为1 阶元素。设指定关系f为选取A1中包含节点对{1,2} 的元素,则f[(A1)1]=D1={{{1,2}},{{1,2,3}}},f[(A1)2]=D2={{{1,2},{1,2,3}}},当k≥3 时,f[(A1)k]=Ø。显然为i+1 阶集合。由于{1,2}为1 阶元素,因此集合{{1,2}}为1 阶集合。又如,Λ1={{1,2},{1,3},{1,2,3}}是A1的一个非空子集,即Λ1⊆A1,因此Λ1中的元素为1 阶元素,Λ1为1阶集合。同理,因此元素{{1,3},{1,2,3}}为2 阶元素。
USI 模型是对随机分块模型和层次结构模型的一般化推广。随机分块模型假设网络被分成若干个群,两个节点产生链路的概率只取决于节点所在的群,无法体现网络的层次结构和重叠结构信息。层次结构模型将网络用族谱树的形式表示,网络中|A0|个节点作为叶子节点,族谱树通过|A0| -1 个非叶子节点将它们联系起来。将每个非叶子节点赋予一个概率值,每两个叶子节点连边的概率用它们最近共同非叶子节点处的概率表示。层次结构模型中若一个节点从属于某一叶子分支,其本身也属于上一级非叶子节点所属的叶子分支,即可以表示网络的层次结构特性。但是,节点不可从属于同级非叶子节点所属的其他叶子分支,即无法体现网络的重叠性。本质上,层次结构模型可以包含随机分块模型。USI模型假设有某种共同特性的元素可以组成集合,集合中元素建立联系的概率相同。若USI 模型的最高阶集合为1 阶集合,且所有1 阶元素的交集为空集时,USI 模型退化为随机分块模型。若每个集合有且仅有2 个元素,且所有元素从属于唯一的对应阶集合时,USI 模型退化为层次结构模型,层次结构模型可以包含高阶元素。基于该分析,层次结构模型是随机分块模型的推广,USI 模型又是层次结构模型的推广。由此可以进一步得出,随机分块模型和层次结构模型实际上是USI 模型从不同角度退化后的加权组合,加权系数由该模型的合理程度决定,属于链路预测的前端融合方法。当给定指定关系f后,USI 模型可以用于链路预测,具体方法将在后文给出。
USI 模型本身可以看作加权网络模型。只要当i=0、k=2 时,即两元素构成0 阶集合的指定关系f为任意两节点对组成集合,p根据连边权重设定后,USI 模型就可转化为加权网络模型。
2.2 统一描述网络结构模型性质

证明根据命题1,i阶集合经1 次元素的并集运算g可降为i-1 阶集合;该i-1 阶集合经第2 次元素的并集运算g可降为i-2 阶集合;以此类推,经过i次元素的并集运算g可降为0 阶集合。证毕。
推论2i(i≥2)阶集合可以将其元素看作i-1 阶集合,对每个i-1 阶集合通过集合中元素的并集运算g的i-1 次迭代,使原i阶集合降阶为1 阶集合。
证明将i阶集合的每个元素看作i-1 阶集合,根据推论1,每个i-1 阶集合经过i-1 次元素的并集运算g的迭代,可降为0 阶集合,则原i阶集合降为以0 阶集合为元素构成的1 阶集合。证毕。
设3阶集合X(3)=是3 阶元素。根据推论1,该3 阶集合可降阶为2 阶集合,如式(8)所示。该2 阶集合可以降阶为1 阶集合,如式(9)所示。该1 阶集合可以降阶为0 阶集合,如式(10)所示。


3 基于统一描述网络结构模型的链路预测
基于USI 模型的链路预测方法的基本假设是两个节点发生联系的概率主要依赖于其所在的群体(集合)。因此,基于USI 模型的链路预测方法首先根据可利用的信息给出模型中的集合划分,其次利用最大似然估计法估计概率p,最后假设各条路径产生的联系是相互独立的,根据并联概率给出链路预测得分。
3.1 集合划分
对于含有属性信息和真实群组结构的网络数据,可以根据该信息给出指定关系f确定各阶集合的划分组成。对于只含有节点和连边拓扑信息的数据,只能通过算法识别和合理策略给出指定关系f。现对只含有拓扑信息数据的集合进行分析。
根据USI 模型可知,节点对之间链路的成因取决于节点对所属的集合及其概率。理论上,无论何种规模的网络结构均可被USI 模型表示:只需将该种网络结构视作集合,并建立集合元素间的概率。根据实际应用场景,本文主要给出0 阶和1 阶集合的划分方式。
对于0 阶集合,复杂网络的社区发现算法给出了针对仅含拓扑信息数据的0 阶集合划分方式。USI 模型的链路预测方法中引入社区发现算法,按特定社区发现算法划分的结果,规定指定关系f划分0 阶集合。网络中的环也是十分重要的网络结构,1 个长度为h的环,是由h个节点{v1,v2,…,vh}和h条边{
对于1 阶集合,考虑社区发现算法划分0 阶集合两两交互作用的情况,将任意两个0 阶集合组成1 阶集合。为减少计算量,估计p时可设置阈值限定1 阶集合概率p的建立范围,且低阶环不划分1 阶集合。由于仅含拓扑信息,信息量有限,因此暂不考虑2 阶以上集合的划分。
按照上述分析,给出指定关系f的如下3 种策略:
1)当i=0、k=1,2,…,|A0|时,按社区发现算法的划分结果作为指定关系f1划分0 阶集合。假设社区发现算法划分的全体社区结构为集合P,P={V1,V2,…,Vn},则指定关系f1表示如下:
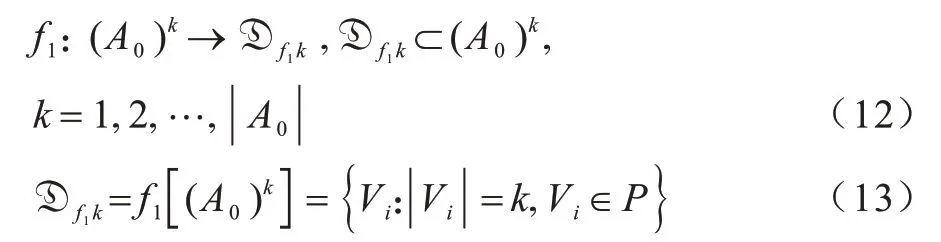
2)当i=0、k=1,2,…,|A0|时,按指定关系f2将只差1 条边构成k阶环的元素组成0阶集合:
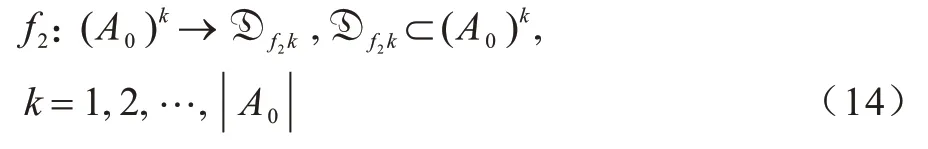
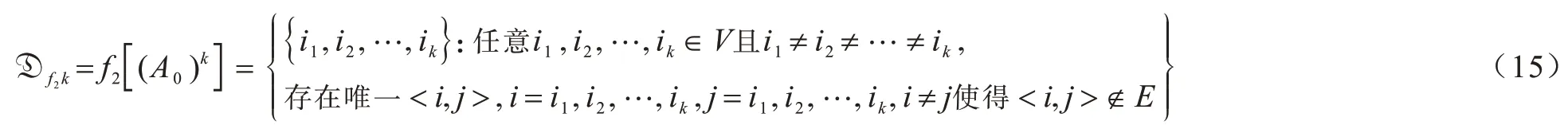
3)当i=1、k=2 时,按指定关系f3将f1划分的0 阶集合两两组成1 阶集合:
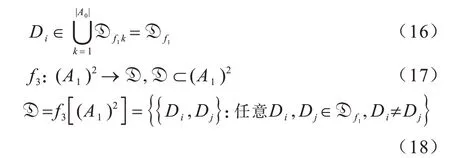
3.2 概率估计
根据集合阶数的不同,概率p的估计可以分为3 种情况,分别为0 阶集合上概率p的估计、1 阶集合上概率p的估计以及高阶集合上概率p的估计。
3.2.1 0 阶集合X(0)上概率p的估计
对于0 阶集合X(0)上概率p的估计,假设:

在仅含0 阶元素组成的集合中,元素与元素间只有连边与非连边,概率p即定义为元素连边的概率。集合中元素连边数为随机变量X,X服从B(N,p)的二项分布,其中,N为集合中元素的最大可能连边数,N=对0 阶集合上概率p的估计采用极大似然估计法,似然函数表示如下:
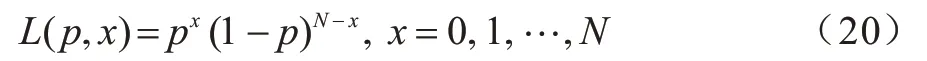
其中:x是0 阶集合观测到的实际连边数。
令:

解得:

如图1 所示,在0 阶集合中共有10 个节点、12 条连边,则概率p的估计值为
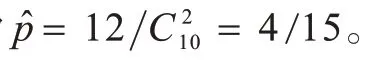
图1 0 阶集合上概率p 的估计示例Fig.1 Example of estimating probability p on 0-order set
3.2.2 1 阶集合X(1)上概率p的估计
对于1 阶集合X(1)上概率p的估计,假设:

考虑到1 阶元素可能存在交集,假设:

集合中1阶元素的最大可能连边数定义如下:

因此对于1 阶集合X(1),集合中1 阶元素间仅存在0 阶元素的连边与非连边,问题同样转化为二项分布B(N,p)的p值估计问题,估计方法与3.2.1 节相同。
如图2(a)所示的1 阶集合不存在交集,只需考虑集合之间的实际连边数(为6)和可能最大的连边数(为6×7=42),则概率p的估计值为=1/7。如图2(b)所示的集合存在交集,因此实际连边数仅考虑交集之外的实际连边(为7)和可能的最大连边(为9×5=45),则概率p的估计值为
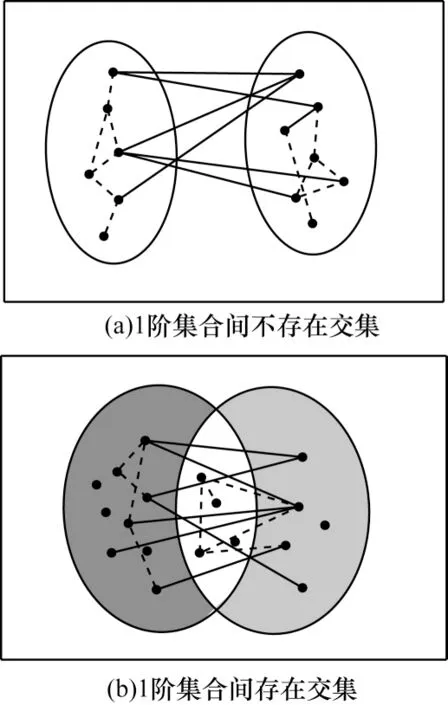
图2 1 阶集合上概率p 的估计示例Fig.2 Examples of estimating probability p on 1-order set
3.2.3 高阶集合X(i)(i≥2)上概率p的估计
根据推论2,将高阶集合通过元素的并集运算迭代降为1 阶集合后,按照1 阶集合上概率p的估计方法进行求解。
3.3 基于并联概率的链路预测得分确定
由于USI 模型中同一节点可以从属于不同阶的不同集合,存在两节点对产生联系的多条路径,与生活中人际交往十分类似,每增加一条两节点产生联系的路径,则两节点产生联系的概率随之增大,因此采用节点对之间各条路径产生联系的概率值的并联概率作为最终链路预测得分。假设产生联系的各条路径在相互独立的条件下,最终链路预测得分可以表示如下:

其中:sxy为节点对xy的最终链路预测得分,即连边概率为节点对在第i个共同集合内连边的概率;Nxy为节点对xy所处的共同集合个数。
按照USI 模型设计,各种规模的网络结构对链路形成的影响,主要体现在链路处于何种网络结构之中。无论何种网络结构,USI 模型都将其视为集合以及集合中元素的连接概率。因此,链路的形成主要由节点对所属集合及其概率决定,节点对从属不同集合,则链路的形成由这些集合的共同作用效果决定。本文方法采用简单的概率并联策略,综合衡量不同集合的共同作用效果。
3.4 与其他链路预测方法的对比分析
基于USI 模型的链路预测方法属于链路预测的前端融合方法。前端融合方法主要包括基于拓扑信息[10-11]、基于社区信息[13-15]加权的相似性、基于网络结构模型等[21-23]方法,一般具有很好的解释性,物理意义明确,侧重于直接从网络的生成演化规律出发进行预测,弱化从数据中学习模式。后端融合方法包括基于相似性的指标融合方法[16-18]、基于机器学习的分类方法[20]等,提高预测准确率的机理是将多维度网络信息拟合成准确率的多元函数,并对目标函数进行优化,使准确率达到最大,侧重于从数据中提取特征,以准确率为最终优化目标。因此,前端融合方法的准确率整体低于后端融合方法,尤其是深度学习方法。
USI 模型的链路预测方法基于基本假设:两节点发生联系的概率主要依赖于其所在群体。使用USI 模型的定义来表述:若节点对从属于哪个集合,则使用哪个集合的概率p来衡量节点对的关系;若节点对从属于多个集合,则使用这些集合共同作用的效果(即概率的并联)衡量节点对之间的关系。由于USI 模型可以将多维度网络结构信息(包括已知的真实网络结构信息)输入进来,因此基于USI 模型的链路预测可以综合利用网络的层次结构、重叠结构、微观结构等网络结构信息。基于以上信息,使用节点对从属集合的连接概率解释链路的生成方式进行链路预测。
4 实验与结果分析
基于USI 模型的链路预测方法在实验过程中选取2 种社区发现算法:1)Reichardt[26],该算法将社区结构理解为自旋组态,使其最小化自旋玻璃态的能量而得到一种社区划分结果;2)SpectralClust[27],对于图G(V,E),利用基于谱分解的图划分算法定义代价函数,求解优化问题得到一种社区划分结果。选取Reichardt算法的尺度参数为[3.0,2.5,2.0,1.5,1.0,0.5],SpectralClust 算法的尺度参数为6,不同尺度参数的社区结构同时作为输入,因此具有层次信息和重叠信息。选取网络中的3 阶环,即k=3。由Reichardt 算法、3 阶环作为输入的方法记为USI-1,由SpectralClust 算法、3 阶环作为输入的方法记为USI-2。
基于USI模型的链路预测方法在FB(Football)[28]、NS(Netscience)[29]、LT(London transport1)[30]、CKM-3[31]、A01[32]、ER(Euroroad)[33]、OP(Opsahl_powergrid)[34]、FWFB[35]8 个网络数据集上进行实验。8 个网络数据集的统计信息如表1 所示,其中,|V|表示网络中的节点数,|E|表示网络中的边数,
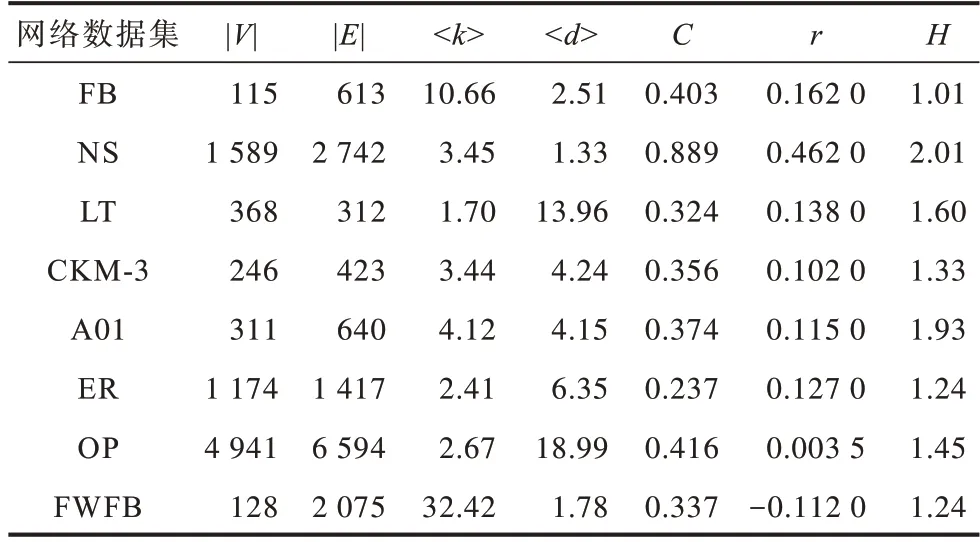
表1 网络数据集统计信息Table 1 Network dataset statistics
在每个数据集上计算节点对的链路预测得分,每个数据集单独计算10 次,每次独立划分训练集和测试集,训练集和测试集的占比分别为90%和10%,最终取10 次计算的平均值作为最终链路预测结果。
选取若干具有代表性的基于节点相似性的链路预测方法进行性能对比,包括基于共同邻居的CN[36]方法、基于共同邻居和节点度加权的AA[37]和RA[8]方法、偏好连接相似性的PA[38]方法、基于局部路径的LP[8]方法、基于 随机游走的LRW[39]和SRW[39]方法(后面的数字表示步数,例如LRW4 表示随机游走的步数为4)、全局相似性方法ACT[39]等10 种方法。将AUC 指标作为评价指标,得到如表2 所示的实验结果,其中排名前2 的指标值用加粗字体标示。由表2 中实验数据可得知,仅使用网络社区结构和3 阶环信息的USI 模型的链路预测方法可显著提升局部结构相似性和全局相似性方法的AUC 指标。尤其在LT、ER、OP 数据集上,USI 模型的AUC 达到0.9 左右,相比其他基于节点相似性的链路预测方法的最优值提升了0.075~0.143,预测准确性显著提升,从而验证了不同规模的网络结构信息对链路形成的影响。
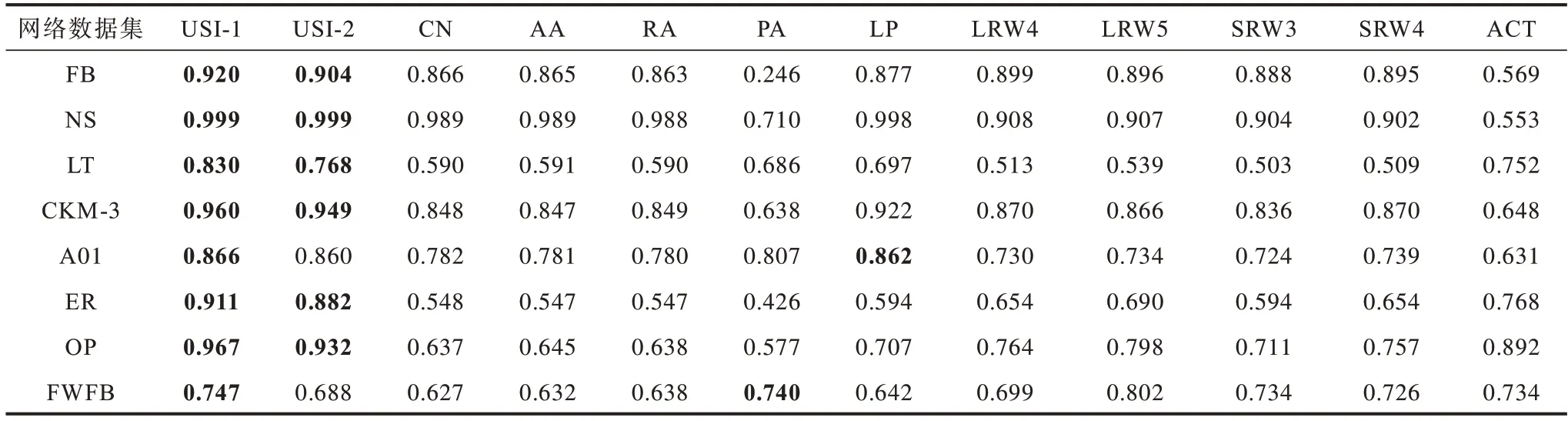
表2 链路预测方法的AUC 结果比较Table 2 Comparison of AUC results of link prediction methods
从方法效率上看,设网络节点数为N1,随机游走的步数为n1,网络中节点平均度为k1,则CN、AA、RA、PA 的时间复杂度为的时间复杂度为LRW、SRW 的时间复杂度为ACT 的时间复杂度为基于USI 模型的链路预测方法的时间复杂度主要分为划分社区结构、集合上度量p的估计、计算并联概率3 个部分。Reichardt 算法的时间复杂度为SpectralClust算法的时间复杂度为O(N1)。设 Reichardt、SpectralClust两种社区发现算法划分了M(M≪N1)个社区结构,组成M个0 阶集合和CM2个1 阶集合,则根据式(22),0 阶集合和1 阶集合上概率p的估计时间复杂度分别为O(M)和3 阶环组成的0 阶集合上概率p的估计可以等价转换为1 次稀疏矩阵的乘法和归一化操作,时间复杂度为设共有个节点对同时从属于2 个以上集合,设N3表示节点对所属共同集合个数的平均值,则根据式(27)并联概率的时间复杂度为O(N3∙N2) ≈N3O(N2)。因此,USI-1 的时间复杂度约为USI-2的时间复杂度约为O(N1+M2+N2)。由实验结果可知,USI-1 方法的链路预测准确性普遍高于USI-2 方法,预测准确性的提升是以方法的时间复杂度换取的,也间接说明网络中观社区结构质量对链路预测具有重要影响,进而验证了基于USI 模型的链路预测方法假设的合理性。对于大规模网络,可选用USI-2 方法,或在集合的划分中选用其他时间复杂度较低的社区发现算法。另外,1 阶集合的划分具有灵活性,在大规模网络中可灵活调整1 阶集合的划分数量,降低时间复杂度。
5 结束语
本文采用笛卡儿积、幂集等概念对多维度网络特征进行统一描述,建立统一描述网络结构模型(USI),并提出一种基于USI 模型的链路预测方法。该方法利用USI 模型对输入信息进行前端融合,描述实际网络的演化机理,并且明确了网络规模对链路形成的影响。实验结果验证了基于USI 模型的链路预测方法的有效性。后续将融合其他的网络结构信息以及连边概率的组合方式,进一步提高链路预测准确率。此外,当USI 模型输入仅为社区发现算法划分的社区结构信息时,即可利用USI 模型的AUC 值对重叠与非重叠社区结构的划分质量进行评价,下一步也将对此进行深入研究。
