基于深度学习的目标检测算法综述
2022-07-14李柯泉陈燕刘佳晨牟向伟
李柯泉,陈燕,刘佳晨,牟向伟
(1.大连海事大学 航运经济与管理学院,辽宁 大连 116026;2.河北金融学院 信息工程与计算机学院,河北 保定 071051)
0 概述
目标检测是对图像中的感兴趣目标进行识别和定位的技术,解决了图像中的物体在哪里以及是什么的问题[1]。已有的研究表明,可靠的目标检测算法是实现对复杂场景进行自动分析与理解的基础。因此,图像目标检测是计算机视觉领域的基础任务,其性能好坏将直接影响后续的目标跟踪、动作识别以及行为理解等中高层任务的性能,进而也影响了人脸检测、行为描述、交通场景物体识别、基于内容的互联网图像检索等后续人工智能(Artificial Intelligence,AI)应用的性能[2-3]。随着这些AI 应用渗透到人们生产和生活的各个方面,目标检测技术在一定程度上减轻了人们的负担,改变了人类的生活方式。
目标检测领域的研究最早可以追溯到1991年由TURK[4]等提出的人脸检测算法。近年来,随着计算机硬件水平的提升、深度学习技术的发展以及各种高质量目标检测数据集的提出,涌现出越来越多优秀的目标检测算法。目标检测算法的发展大致分为两个阶段:第一阶段集中在2000 年前后,这期间所提出的方法大多基于滑动窗口和人工特征提取,普遍存在计算复杂度高和在复杂场景下鲁棒性差的缺陷[5],为使算法能够满足实际需要,研究人员通过研究更加精巧的计算方法对模型进行加速,同时设计更加多元化的检测算法,以弥补手工特征表达能力上的缺陷,代表性的成果包括Viola-Jones 检测器[6]、HOG 行人检测器[7]等;第二阶段是2014 年至今,以文献[8]提出的R-CNN 算法作为开端,这类算法利用深度学习技术自动地抽取输入图像中的隐藏特征,从而对样本进行更高精度的分类和预测。随着深度学习和计算机视觉的不断突破,在R-CNN之后又涌现出了Fast R-CNN[9]、Faster R-CNN[10]、SPPNet[11]、YOLO[12]等基于深度学习的图像目标检测算法。相比传统的目标检测算法,基于深度学习的目标检测算法具有速度快、准确性强、在复杂条件下鲁棒性强等优势[13]。
近年来,基于深度学习的目标检测已经成为计算机视觉领域的一个热门研究方向,研究人员提出了许多新的目标检测算法。本文对基于深度学习的目标检测算法进行综述,阐述目标检测,包括图像目标检测任务、数据集、评价标准、传统目标检测算法的基本框架和存在的问题等。按照是否包含显式的区域建议及是否显式地定义先验锚框两种标准对已有的目标检测算法分类,介绍各类目标检测算法中的代表算法并总结算法机制、优势、局限性和适用场景。基于VOC 2007 和COCO 2018 数据集展示各类算法的性能表现并对各类目标检测算法进行比较。在此基础上,分析目前基于深度学习的目标检测算法面临的挑战和解决方案,展望该领域的未来研究方向。
1 目标检测算法
1.1 目标检测任务、评价指标及公开数据集
图像目标检测是计算机视觉领域最基本也是最具有挑战性的任务之一,主要对输入图像中的目标进行识别和定位。图1 所示为目标检测的一个示例。其中,目标检测的结果由两部分组成:方形边界框的颜色代表了目标的所属类别(识别);方形边界框的尺寸和位置代表了目标在输入图像中的位置(定位)(彩色效果见《计算机工程》官网HTML 版)。

图1 目标检测示例Fig.1 Example of object detection
在目标检测任务中,bgt、bpred分别表示物体的真实边界框和检测到的边界框。bgt、bpred的交并比(Intersection-over-Union,IoU)被用来评价所预测的边界框的准确程度:
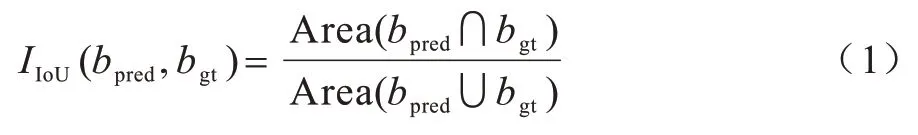
交并比阈值是一个预定义的常数,表示为Ω。当IIoU(bpred,bgt)>Ω时,认为bpred中的图像为正样本(包含物体),否则为负样本(背景)。基于交并比和交并比阈值可以计算目标检测的精确率(P)和召回率(R):

其中:TTP、FFP、FFN分别是真阳率、假阳率和假阴率,分别表示正样本被预测正确的数量、负样本被预测为正样本的数量和背景被错误检测为正样本的数量。计算精确率和召回率时,一般取交并比阈值Ω=0.5。
平均精确率(Average Precision,AP)也是目标检测中常用的指标,其计算公式为:

其中:P(t)表示交并比阈值Ω=t时的精确率。对于多类别的目标检测任务,由于待检测物体可能存在不同的所属类别,通常用平均精确率均值(mean Average Precision,mAP)作为评价指标,其计算公式如下:

本文将以上评价指标统称为精度,这些指标反映了目标检测算法检测到的物体边界框的准确程度。除精度外,速度也是目标检测算法重要的评价指标。最常用的描述目标检测算法速度的评价指标是每秒检测帧数(Frames Per Second,FPS),即算法平均每秒能够检测的图像数量。
目标检测算法的训练和评价一般在特定的数据集上进行。目标检测领域最重要的数据集有Pascal VOC[14-15]、ILSVRC[16]和Microsoft COCO[17]等。
Pascal VOC(Pascal Visual Object Classes)是2005 年—2012 年举办的一项计算机视觉领域的竞赛,其中包含了目标检测任务。VOC 2007 数据集是该竞赛于2005年—2007年使用的数据的集合,VOC 2012则包含了该竞赛2008 年—2012 年使用的全部数据。该数据集中的物体包含了人类、动物、车辆和室内物品4 个大类以及包括背景在内的21 个小类的物体。由于该数据集中的检测任务相对简单,近年来提出的目标检测算法逐渐不再采用VOC 数据集对算法的性能进行评估。ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)也是一项包含了目标检测任务的竞赛。相比VOC 数据集,LISVRC 中物体的所属类目被扩充到200 种,且图像数量和标注物体数量均明显高于VOC 数据集。常用的LISVRC数据集有LISVRC 2014 和LISVRC 2017。Microsoft COCO 数据集是目前最有挑战性的目标检测数据集。虽然该数据集仅包含80 个类目,但该数据集将标注的物体按照尺度划分为小、中、大三类。尤其是引入了大量的小目标物体,这使得该数据集中的前景物体更加密集,增加了任务的难度。Microsoft COCO 数据集包括COCO 2005 和COCO 2018 两个常用版本。表1 列出了不同数据集的训练集、验证集和测试集中图像数量和标注的物体数量,其中,括号内的数字表示数据集中经过标注的物体数量,括号外的数字是数据集中的图像数量。

表1 目标检测数据集图像数量和标注过的物体数量Table 1 Number of images in the target detection dataset and the number of labeled objects
1.2 传统目标检测算法
如图2 所示,传统的目标检测框架中包含了3 个阶段。区域建议的目的是找出输入图像中可能存在目标的区域,这些区域被称为候选区域或感兴趣区域(Regions of Interest,RoI)。由于目标可能有不同的尺寸且可能出现在任何位置,传统方法大多使用不同尺度的滑动窗口对输入图像进行多次遍历得到大量的候选区域[6,18-19]。特征抽取是第二个阶段,该阶段常用尺度不变特征(Scale Invariant Feature Transform,SIFT)[20]、局部二值模式特征(Local Binary Pattern,LBP)[21]、梯度直方图特征(Histogram of Oriented Gradient,HOG)[22]等人工特征抽取方法将感兴趣区域中的图像转换为特征向量。抽取到的特征向量作为第三阶段的输入。在该阶段中,预训练的分类器预测感兴趣区域中物体的所属类别并输出目标检测的结果。级联学习、集成学习等机器学习方法常被应用于这一阶段以提升目标检测的精度。

图2 传统的目标检测算法框架Fig.2 Framework of traditional target detection algorithms
传统的目标检测算法主要存在以下3 点缺陷:1)在区域建议阶段,不同尺度的滑动窗口对输入图像进行多次遍历产生大量的感兴趣区域,在后续步骤中,算法对这些区域进行特征抽取和分类的过程存在大量冗余计算开销,影响算法的运行速度,另外滑动窗口只有几种固定的尺寸,通常不能与目标完美匹配;2)特征抽取阶段仅能获取图像的低级特征,这些特征表达能力不足而且特征的有效性高度依赖具体任务,一旦检测目标有重大变动就要重新设计算法;3)整个目标检测过程被割裂为独立的3 个阶段,无法找到算法的全局最优解,算法的设计依赖设计者对检测目标和具体任务的先验知识。为了弥补这些缺陷,研究人员寻找更加精巧的计算方法对算法进行加速,使算法能够满足实时性的要求,同时设计更多元化的检测算法以弥补人工特征表达能力不足的缺陷。
2 基于深度学习的目标检测算法
深度学习是能够通过监督、半监督或无监督的训练方法自动学习训练数据中隐藏的数据内部结构的一类多层神经网络算法。相比人工抽取低级特征,深度学习能够将输入图像中的像素数据转化为更高阶、更抽象化的层级特征[23]。因此,深度学习抽取到的特征比传统方法具有更强的表征能力和鲁棒性,这一优势使深度学习在计算机视觉领域的研究和应用中体现出不可替代的优越性,尤其是在目标检测领域涌现出大量基于深度学习的研究成果。已有的目标检测算法存在两种分类标准:1)是否存在显式的区域建议[24-25];2)是否显式定义先验锚框[26]。
2.1 按是否存在显式区域建议的算法分类
按照算法是否存在显式的区域建议,可将目标检测算法分为两阶段目标检测算法和一阶段目标检测算法。其中,两阶段目标检测算法又称为基于区域建议的目标检测算法或基于感兴趣区域的目标检测算法。这类算法通过显式的区域建议将检测问题转化为对生成的建议区域内局部图片的分类问题。代表性的两阶段目标检测算法有R-CNN、Fast R-CNN等。一阶段目标检测算法又称为基于回归的目标检测算法。这类算法不直接生成感兴趣区域,而将目标检测任务视为对整幅图像的回归任务。代表性的一阶段目标检测算法有YOLO、SSD 等。图3 所示为这两类目标检测算法的一般框架。
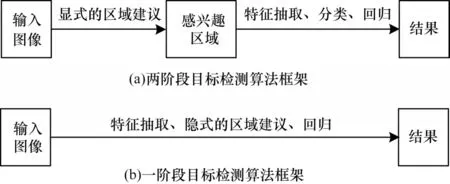
图3 目标检测算法框架Fig.3 Framework of target detection algorithms
2.1.1 两阶段目标检测算法
文献[8]提出的R-CNN 算法最早将深度学习技术成功应用在目标检测领域,该算法是一种典型的两阶段目标检测算法。相较于传统的目标检测算法,R-CNN 算法主要有以下3 点改进:1)在区域建议阶段使用了选择性搜索[27],解决了使用滑动窗口生成候选框导致计算量过大的问题;2)使用卷积神经网络对感兴趣区域进行特征提取,解决了传统方法特征表达能力不足的问题;3)在使用SVM 分类器进行分类的同时,借助回归算法对目标边界进行补偿和修正,以减小感兴趣区域与实际目标的偏差。这些改进使R-CNN 算法相较传统的目标检测算法性能显著提升。R-CNN 算法在Pascal VOC 2007 数据集上的mAP 达到了58.5%,远高于此前传统方法在该数据集上获得的最好结果(如SegDPM[28]为40.4%)。
R-CNN 算法存在以下缺点:1)选择性搜索依赖低级的视觉信息,在背景复杂时很难生成有效的候选框,另外,该过程无法通过GPU 等并行计算设备进行加速;2)在特征抽取时将图像缩放或裁切至固定尺寸,造成信息丢失;3)深度学习方法分别提取每个感兴趣区域中图像的特征,该过程产生大量重复计算;4)R-CNN 中各个部分依旧是割裂的,训练步骤繁琐、耗时,且很难找到全局最优解。
文献[11]提出了SPP-Net 目标检测算法,它是R-CNN 的一种改进,该算法借鉴了金字塔空间匹配(Spatial Pyramid Matching,SPM)算法,在第二阶段引入了金字塔空间池化层(Spatial Pyramid Pooling,SPP)[29]。与R-CNN 相比,SPP-Net 首先通过骨干网络直接得到整个输入图像的特征图,而非分别抽取每个感兴趣区域的特征,减少了计算冗余。然后SPP-Net 引入金字塔空间池化层将特征图中与感兴趣区域对应的部分转化为固定尺寸的特征。由于避免了对感兴趣区域中的图像进行缩放和裁切等操作造成的信息丢失,SPP-Net 的精度相对R-CNN 得到了进一步的提升,它在VOC 2007 数据集上的mAP达到了60.9%。另外,由于SPP-Net 仅需要进行一次卷积操作,其运行速度相对R-CNN 得到了明显的提升。在达到与R-CNN 近似甚至更高精度的前提下,SPP-Net的运行速度是R-CNN的24倍~102倍。SPP-Net的缺点在于:虽然优化了R-CNN 时间开销的问题,其感兴趣区域中图像的特征仍然需要单独保存,存在较大空间开销。此外,与R-CNN 类似,SPP-Net 中的特征提取、分类、回归依旧是割裂的。
针对SPP-Net 算法的不足,文献[9,30]提出了Fast R-CNN算法。相对SPP-Net算法,Fast R-CNN算法主要有两点改进:1)使用感兴趣池化层(RoI Pooling layer)代替了SPP-Net 的金字塔空间池化层,感兴趣池化层与金字塔空间池化层具有类似的功能,能够将不同尺寸的感兴趣区域对应的特征划分为相同尺寸的特征向量,但感兴趣池化层更为简洁;2)提出了新的多任务损失函数,该函数将分类任务与边框回归任务整合到主干卷积神经网络中,使这两个任务能够共享主干卷积神经网络的参数,从而进一步降低了目标检测所需的计算资源。这两点改进使得Fast R-CNN 的检测速度明显提升,并初步实现了端到端的目标检测。该算法在VOC2007 数据集上的检测率分别达到了70.0%。
Fast R-CNN 在区域建议阶段依旧使用选择性搜索生成感兴趣区域。由于选择性搜索无法使用GPU进行加速,制约了目标检测的训练和运行速度。文献[10]提出的Faster R-CNN 算法用区域预测网络(Region Proposal Network,RPN)代替传统的感兴趣区域预测方法。由于提取候选区域网络是基于深度学习的方法,因此可以借助GPU 加速,提升Faster R-CNN 算法训练和运行的速度。
Faster R-CNN 算法使用骨干网络获取输入图像的特征。骨干网络通常是多个卷积层的堆叠,虽然能够获取图像的高级特征,但这些特征具有平移不变性[31-32],不利于对目标框的检测。为了解决这一问题,该算法在第二阶段使用全连接层消除所抽取到特征的平移不变性,但这造成了该算法的两点缺陷:1)第二阶段无法实现对多个感兴趣区域进行计算时的参数共享,产生额外的计算开销,影响算法速度;2)全连接层的加入消除了特征的平移不变性的同时,也造成了信息的丢失,影响算法的精度。
针对Faster R-CNN 算法这两点缺陷,文献[33]提出了R-FCN 算法。该算法主要有两点创新:1)将全卷积网络(Fully Convolutional Network,FCN)应用于Faster R-CNN,使算法第二阶段的计算也实现了参数共享,提升了检测速度;2)提出了位敏得分图和位敏池化层对目标检测任务中的平移不变性和平移可变性进行权衡,使R-FCN 在提升了检测速度的基础上达到和Faster R-CNN 接近的精度。
图4 对有代表性的两阶段目标检测算法进行总结。这些算法的演化主要存在2 个趋势:1)实现参数共享以提升算法运行速度;2)提出新的训练策略使算法从多个割裂的步骤逐步向端到端演化。
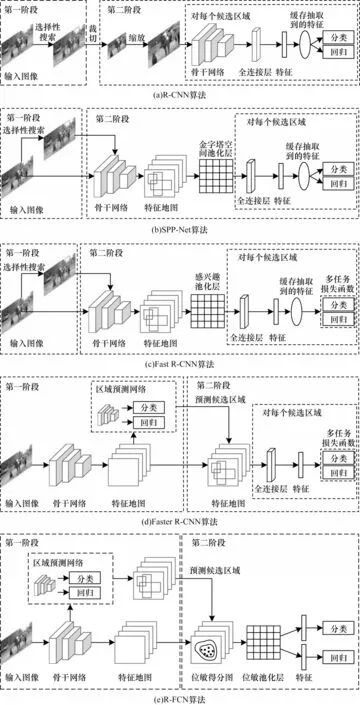
图4 两阶段目标检测算法Fig.4 Two-stage target detection algorithms
2.1.2 一阶段目标检测算法
两阶段目标检测算法在第一阶段生成区域建议,在第二阶段仅针对感兴趣区域中的内容进行分类和回归,丢失了局部目标在整幅图像中的空间信息。为此,研究人员提出了一阶段目标检测算法来解决这一缺陷。
文献[34]提出的基于二进制掩膜的目标检测算法是一种早期的一阶段目标检测算法。该算法采用AlexNet[35]作为骨干网络,但将网络的最后一层替换成回归层。通过回归预测目标的二进制掩膜并以此为依据提取目标边界框。由于单一掩膜难以区分识别的目标是单一的物体还是多个相邻的物体,算法需要输出多个掩膜。这使网络训练变得困难,也导致该算法很难应用于对多个类别目标的检测。文献[36]提出的Overfeat 算法也是一种一阶段目标检测算法的早期尝试。该算法针对分类、定位、检测3 个不同的任务将骨干网络的最后一层替换成不同的分类或回归层,这些任务共享骨干网络的参数。骨干网络由AlexNet 实现,但该算法用偏置池化代替了原本的最大池化以消除特征粒度不足的问题。该算法借助卷积层代替了滑动窗口的操作,大幅提升了目标检测的速度,但是该算法难以实现对小尺寸目标的检测。
文献[12]提出的YOLO 算法是最早具有实际应用价值的一阶段目标检测算法。该算法的骨干网络采用了类似GoogLeNet[37]的结构,直接基于整幅输入图像预测图像中物体的类别和边界框的位置、尺寸等信息。该算法将输入图像划分为S×S个网格,并对每个网格预测B个边界框,对每个网格中的物体分别进行预测。因此,对于具有C个类别的目标检测任务,YOLO 算法的输出y是一个尺寸为S×S×(B×5+C)的矩阵,其中,yi,j表示对第i行第j列网格的预测结果。每个预测的结果包括边界框的位置、尺寸、置信度以及边界框中的物体属于各个类别的概率。这种划分网格的方法避免了大量的重复计算,使YOLO 算法达到了较快的检测速度。在VOC 2007数据集中达到了45 frame/s 的检测速度。另外,由于YOLO 算法基于整个输入图像进行检测,而非基于局部进行推断,这使其背景误检率只有13.6%,远小于已有的两阶段目标检测算法。然而,该算法仍存在以下不足:1)精度相对较差,在VOC 2007 上的精确性只有63.4%,低于Faster R-CNN 等同时期的两阶段目标检测算法;2)对于成群的小目标、多个相邻的目标或具有异常尺寸的目标检测效果较差。
YOLO 算法取得的成功引起了众多研究者的关注,YOLOv2[38]、YOLOv3[39]、YOLOv4[40]等YOLO 算法的改进型算法被陆续提出。其中,YOLOv2 应用了批量正则化、高分辨率分类器、基于聚类的边界框预测、新的骨干网络和联合训练方法等技术来获得更高的精确度。在此基础上,作者训练了名为YOLO9000 的目标检测算法,使YOLO9000 可以检测目标类别的种类达到了9 000 种。YOLOv3 使用了更加复杂的骨干网络,该网络参考了Resnet101[41]使运行速度更快。YOLOv3 还使用了多尺度的特征融合以获取更多小目标的有用信息,从而提升算法对小目标检测的精确度。YOLOv4 应用了新的骨干网络并结合空间金字塔池化和路径聚合网络(Path Aggregation Network,PAN)[42]进行特征融合,从而获得更高的性能。这些方法都为新的一阶段目标检测算法的设计提供了借鉴,也证明了骨干网络设计、高效特征融合等技术对提升目标检测性能具有重要意义。
针对YOLO 算法在小目标检测中的不足,文献[43]提出了SSD 算法,该算法采用了与YOLO 算法类似的网格划分的方法。与YOLO 算法相比,该算法主要有以下4 点改进:1)使用了多尺度特征进行检测;2)舍弃了YOLO 算法中的全连接层,改用全卷积网络;3)为每个网格设定多个具有不同长宽比的先验边界框;4)使用了数据扩增[44]技术。这些改进可使SSD 算法在运行速度上媲美YOLO 算法,同时在性能上不逊于Faster R-CNN,其在VOC 2007 数据集中的mAP 达到了74.3%。但该算法仍存在以下2 点不足:1)先验边界框的尺度需要人工设置而非从数据中学习而来,导致该算法的训练非常依赖经验;2)对小目标的检测效果依旧弱于两阶段目标检测算法。
针对SSD 算法在小目标检测中存在的不足,文献[45]提出了DSSD 算法。该算法将SSD 算法的骨干网络替换为Resnet101 以增强算法的特征提取能力,并引入了反卷积层将抽取到的低级特征转化为较高层次的语义信息。在此基础上,作者又提出一种特征融合方法,将反卷积得到的语义信息与卷积获得的低级特征融合,从而提升了算法的检测精度,尤其是对小目标的检测精度。该算法在VOC 2007数据集中的mAP 达到了81.5%,高于SSD 算法。其在COCO 2018 数据集中对小目标检测的AP 值也达到了13.0%,高于YOLO 算法的10.2%。此外,SSD 的改进算法还有FSSD[46]、RefineDet[47]、M2Det[48]等,这些改进均为SSD 算法的性能带来了提升。
生成的候选框中的内容存在类别不均衡是已有的一阶段目标检测算法精确度普遍低于两阶段目标检测算法的一个重要原因[49]。针对这一问题,文献[50]提出了RetinaNet 算法,基于标准交叉熵损失改进得到焦点损失函数。焦点损失的应用可以使算法根据候选框中的内容自动地调节正负样本对损失的贡献度,使算法更关注于低置信度的样本,从而减小类别不均衡对算法精确度的影响。该算法在多个数据集上达到了接近两阶段目标检测算法的精确度,但是该算法的运行速度明显低于YOLO、SSD 等一阶段目标检测算法。
图5 所示为一阶段目标检测算法。一阶段目标算法的演化存在以下2 个趋势:1)构建具有更强表征能力的骨干网络以提升算法的精度;2)提出新的损失函数以解决目标检测过程中遇到的样本不均衡等问题。
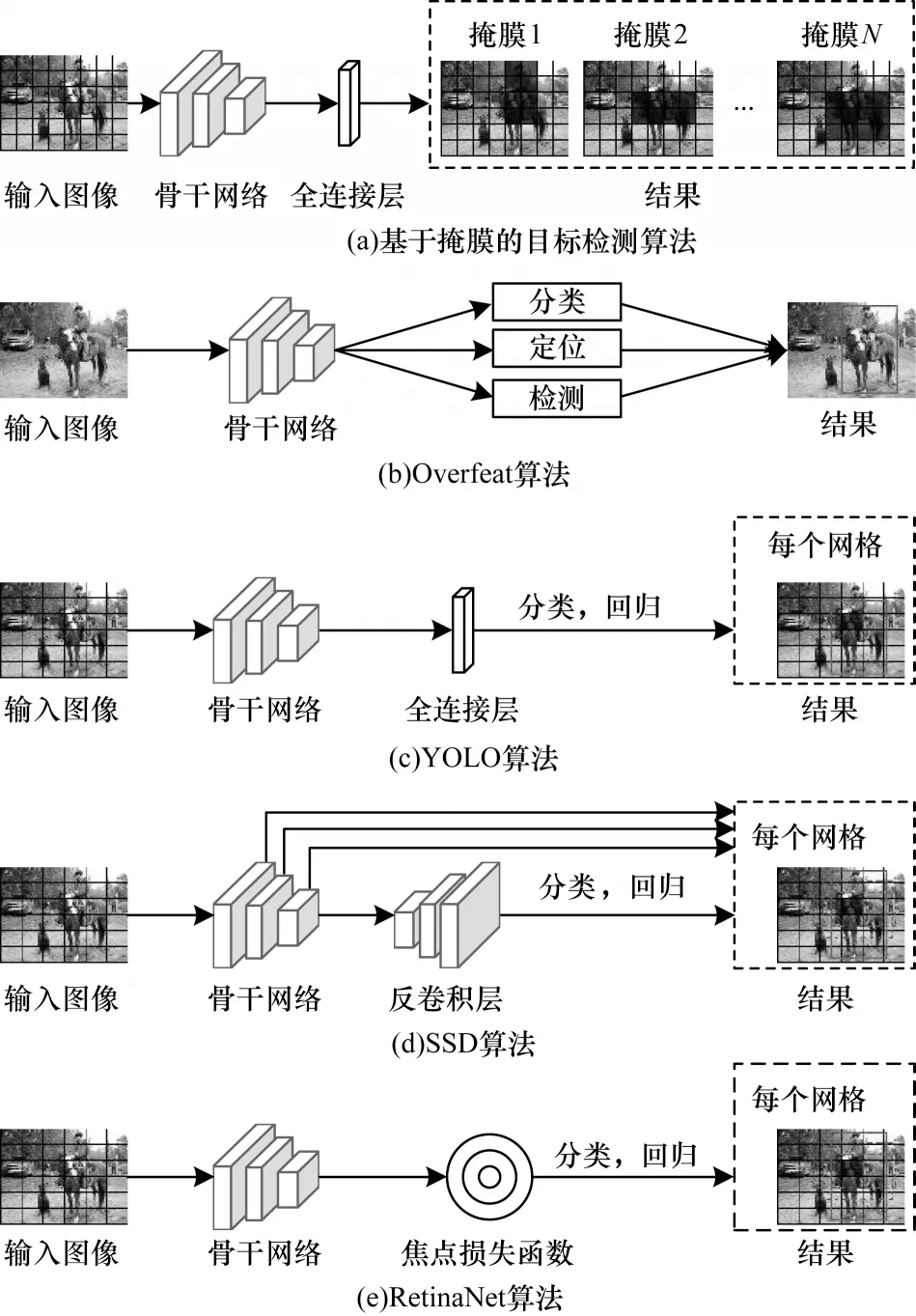
图5 一阶段目标检测算法Fig.5 One-stage target detection algorithms
2.2 按是否定义先验锚框的算法分类
按照是否定义先验锚框可以将已有的目标检测算法分为基于锚框的目标检测算法和无锚框目标检测算法。
2.2.1 基于锚框的目标检测算法
基于锚框的目标检测算法通过显式或隐式的方式创建一系列具有不同尺寸、长宽比的检测框(锚框),然后对锚框中的内容进行分类或回归。前文介绍的大部分目标检测算法,如R-CNN、Faster R-CNN、SSD 均是基于锚框的目标检测算法。其中,基于锚框的两阶段目标检测算法利用选择性搜索等方法显式地创建一系列锚框,基于锚框的一阶段目标检测算法在骨干网络提取输入图像特征的同时,按照预定义的锚框属性隐式地获取检测框中图像的特征。
基于锚框的目标检测算法需要根据物体的尺寸、长宽比在训练数据中的分布确定锚框的尺度、长宽比、生成锚框数量、交并比阈值等超参数。这些超参数的值的选取会影响算法精度。其中的一个示例是锚框超参数的选取对RetinaNet 算法在COCO 数据集中的精确度造成至少4%的改变[50]。这种影响使基于锚框的算法在更换应用场景后往往无法达到令人满意的性能。因此,在目标检测算法中应用锚框不但依赖先验知识,也使算法缺乏泛化能力。
在算法的训练过程中,基于锚框的目标检测算法分别计算每个锚框与物体的真实边界框的交并比。该过程增加了算法的计算量且无法借助GPU等并行计算设备提升速度。因此,锚框的应用提升了算法的计算复杂度,降低了目标检测算法的训练速度。
算法基于锚框获得检测结果:首先两阶段目标检测算法对锚框内的图像分类,然后通过回归等方式调整锚框边界得到物体边界框;一阶段目标检测算法直接基于生成的锚框预测目标的边界框。生成锚框的过程忽略了锚框中前景(物体)与背景的比例,导致训练样本中负样本(只包含背景的锚框)的数目明显多于正样本(包含物体的锚框),存在严重的类别不平衡问题,这是限制目标检测算法精度的一个主要原因。此外,锚框难以检测到异常物体,这导致基于锚框的算法在检测尺度、长宽比异常的物体时召回率过低。因此,锚框的应用限制了目标检测算法的精度。
综上所述,虽然基于锚框的目标检测算法取得了成功,但同时存在以下4 点缺陷:1)锚框的设计依赖先验知识,缺乏泛化能力;2)训练过程大量计算锚框与真实边界框的交并比,造成冗余计算;3)基于锚框生成的训练样本中正负样本失衡,影响检测精度;4)对异常物体检测精度较差。
2.2.2 无锚框目标检测算法
针对基于锚框的目标检测算法的缺陷,研究人员提出了无锚框目标检测算法,这类算法移除了预设锚框的过程,直接预测物体的边界框。因此,这种方法存在3 个优点:1)锚框的参数从数据中学习而来,鲁棒性强;2)训练过程中无需大量重复计算锚框与真实边界框的交并比,节省了训练时间;3)可以避免训练过程中样本失衡的问题。
无锚框目标检测算法可以分为基于中心域的目标检测算法和基于关键点的目标检测算法。
基于中心域的目标检测算法直接预测物体的中心区域坐标和边界框的尺度信息。文献[51]提出的DenseBox 算法是一种早期的基于中心域的算法。它将每一个像素作为中心点,分别预测该点到其所在的物体上下左右边界的距离以及物体属于不同类别的概率,即对输入图像的每一个像素预测一个边界框。然后通过非极大值抑制(Non-Maximum Suppression,NMS)对这些边界框进行筛选。该方法在人脸检测等小目标检测任务的精度明显高于基于锚框的算法,但该算法也被证实不适用于通用目标检测,且对重叠物体检测效果较差。YOLO 算法也是一种早期的基于中心域的目标检测算法,该算法将输入图像划分为S×S个网格,对每个网格,算法预测网格中物体的中心点横、纵坐标(中心点)、物体边界框的长度和宽度(边界框的尺度信息)以及物体属于各类别的概率。由于YOLO 算法只检测离中心点距离最近的物体,导致其召回率偏低,算法的精度低于同时期基于锚框的一阶段目标检测算法,因此无锚框方法在其后续版本的YOLOv2 和YOLOv3 没有被继续采用。尽管其在性能上存在局限性,但DenseBox 算法和YOLO 算法的思想为后续的无锚框目标检测算法提供了借鉴。
文献[52-53]提出的FCOS 算法采用了与DenseBox 算法类似的逐像素预测边界框的思想,并给出一种基于多尺度特征的重叠物体检测方法。在该方法中,骨干网络可以提取输入图像的多尺度特征:浅层特征包含更多细节,对小目标检测有利;深层特征包含更多语义信息,偏向大目标检测。假设重叠的物体具有较大尺度差异,使用不同层次的特征预测不同尺度的物体边界框从而实现对同一区域重叠物体的检测。FCOS 算法的不足主要体现在当所预测的像素与物体实际的中心点存在较远距离时检测结果容易受到重叠物体语义交叠的影响。
文献[54]提出的FoveaBox 算法解决了FCOS 算法的不足。该算法使用了与FCOS 算法相同的思路解决物体重叠的问题,但是引入了可调节的正负样本衰减机制增强了训练过程中正负样本之间的判别度,从而避免重叠区域语义交叠的影响。此外,该算法并非直接预测中心点与边界框各边的距离而是从数据中学习所预测中心点与边界框各边的映射关系从而实现了更强的鲁棒性。
另一类无锚框算法是基于关键点的目标检测算法,一般以热力图的方式预测输入图像中各个点是边界框中的关键点的概率,然后将多组热力图组合得到物体边界框。
文献[55]提出的CornerNet 算法是一种代表性的基于关键点的算法。它首先使用骨干网络抽取输入图像的特征,然后基于这些特征生成两组不同的热力图分别预测图像中各个像素是锚框的左上角点和右下角点的概率、角点对应物体的所属类别信息以及锚框的误差信息,最后根据这些信息配对预测的角点得到物体边界框。该算法完全摆脱了锚框的约束,仅依靠关键点预测物体的边界框且取得了较高的精度。该算法的缺点是仅关注物体的边界信息,忽略了待检测物体本身的特征,对物体的分类不够准确。
文献[56]提出的CenterNet算法改进了CornerNet算法的缺陷。该算法在CornerNet 基础上加入了对物体中心点的预测,这项改进使算法在预测边界框时考虑到边界框内部物体的特征从而提升算法的精度。
以上算法都需要在算法的最后使用非极大值抑制去除冗余的边界框,影响算法速度。文献[57]提出CenterNe(tObject as Point)算法,不再需要去除冗余边框。首先,该算法采用了基于关键点的思想,使用热力图预测物体的中心点。然后,采用基于中心预测的思想,利用所预测中心点处获取的特征预测边界框的长度和宽度从而得到检测结果。这种混合方法的应用使算法不需要借助非极大值抑制去除冗余结构,因此计算比已有的目标检测算法更加简洁。
无锚框目标检测算法的提出是为了弥补基于锚框的目标检测算法在小目标检测的缺陷,在特定场景的小目标检测中的表现优于基于锚框的目标检测算法,但许多无锚框算法也被指出不适合应用于通用目标检测。由于这类算法出现较晚,因此仍有较大潜力实现进一步提升。
表2 对各类目标检测算法的机制、优势、局限性和适用场景进行了总结。
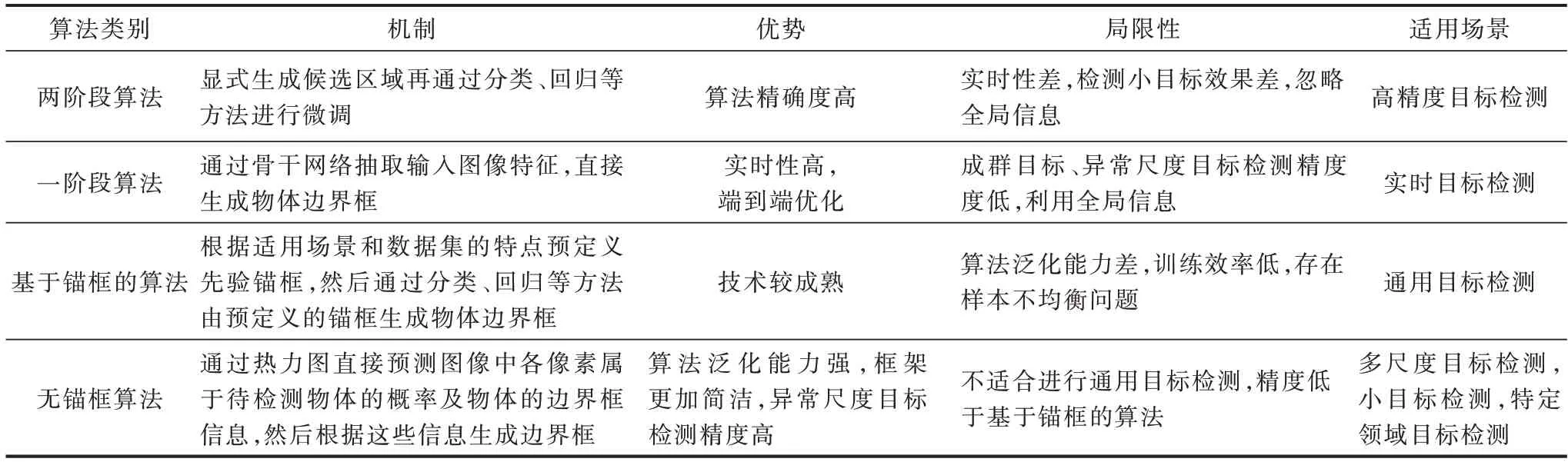
表2 各类目标检测算法的机制、优势、局限性及适用场景Table 2 Mechanism,advantages,limitations and application scenarios of each category of target detection algorithms
3 算法性能比较与分析
本节对一些代表性的基于深度学习的目标检测算法的性能进行比较。
表3 和表4 分别展示了不同目标检测算法在VOC 2007 和COCO 2018 数据集中的性能。其中,注释为“*”的算法为两阶段目标检测算法,未使用“*”注释的算法为一阶段目标检测算法,注释为“†”的算法为无锚框目标检测算法,未使用“†”注释的算法为基于锚框的目标检测算法,在表4 中,APS、APM 和APL 分别表示算法对小尺寸物体、中等尺寸物体和大尺寸物体检测的AP 值。这些算法具有不同的骨干网络、输入图像的分辨率、超参数以及硬件条件,这些因素可能影响算法的最终性能。为了保证所列出数据的参考价值,表中给出的结果尽量选择了已有文献中算法在近似条件下的性能。
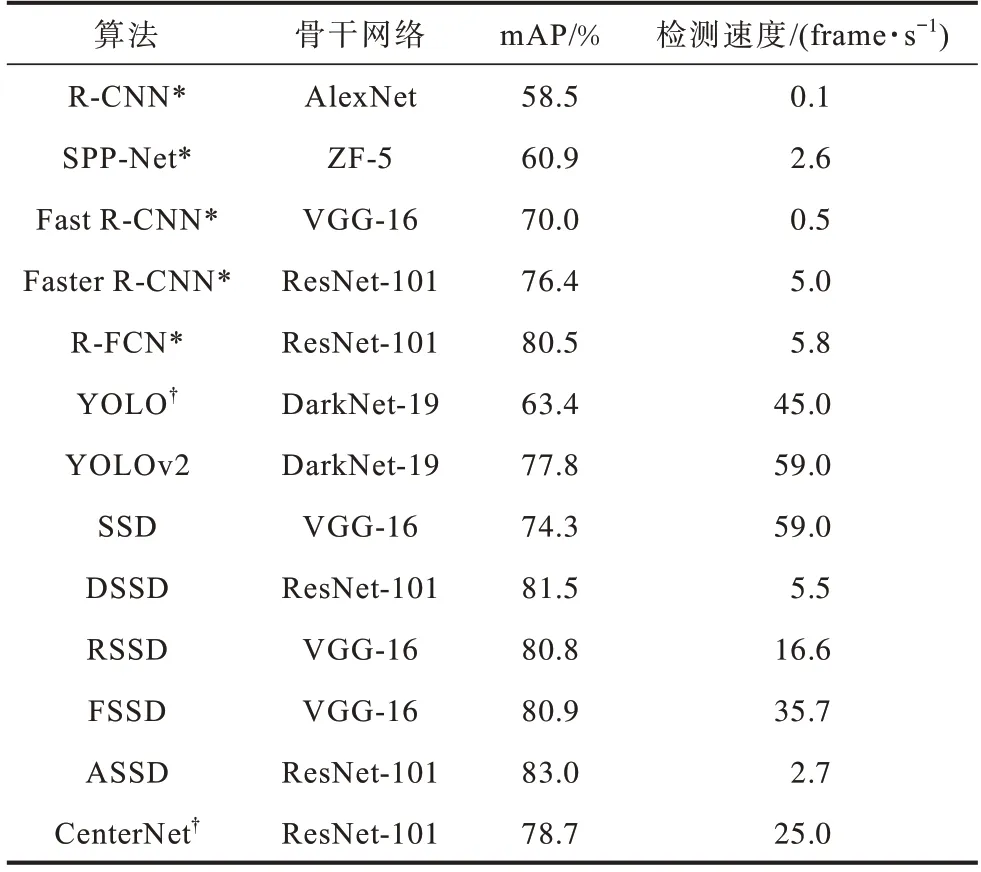
表3 目标检测算法在VOC 2007 数据集中的性能Table 3 Performance of target detection algorithms on VOC 2007 dataset
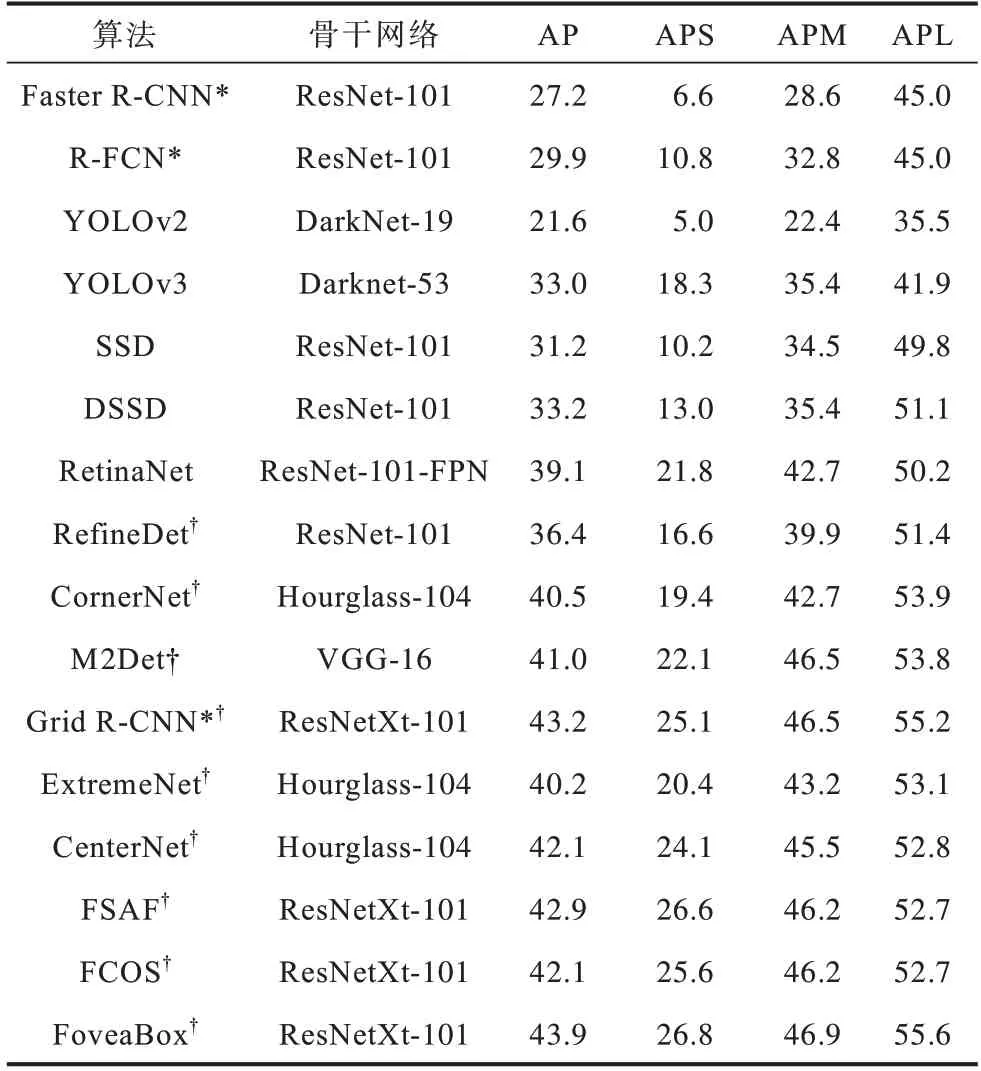
表4 目标检测算法在COCO 2018 数据集中的性能Table 4 Performance of target detection algorithms on COCO 2018 dataset %
从表3、表4 可以得出5 点结论:1)尽管两阶段目标检测算法的运行速度在不断演化中得到提升,依旧明显慢于一阶段目标检测算法;2)借助更复杂的骨干网络以及一些高级深度学习技术,一阶段目标检测算法的精度能够接近甚至超过两阶段目标检测算法,说明骨干网络的设计对一阶段目标检测算法精度的提升具有重要意义;3)在一阶段目标检测算法中,DSSD 和ASSD 的精度明显高于其他算法,但速度也明显慢于其他算法,类似地,YOLO 及其衍生算法速度较快,但精度低于其他一阶段目标检测算法,说明算法的速度和精度依旧难以兼得;4)由于引入了大量小目标物体,增大了目标检测的难度,所有算法在COCO 2018 数据集中的精度均有所降低,说明小目标检测是目前目标检测的一个重要挑战;5)无锚框目标检测算法在COCO 2018 数据集中的精度,尤其是对小物体检测的精度要高于基于锚框的算法,这证明了无锚框目标检测算法是未来重要的发展方向。
4 未来研究方向
目前,基于深度学习的目标检测算法处于快速发展阶段,产生了许多新的理论、方法和应用。本文将未来的研究方向归纳如下:
1)如何获取高质量的目标检测数据集。基于深度学习的目标检测算法是一类数据驱动的算法,算法的精度和鲁棒性依赖于数据集的规模和质量[58]。目标检测数据集的构建依赖于人工标注,工作量极大而且成本高昂。目前这一问题主要有两种解决方法:一种方法是提升对已有数据集的利用效率,如同时使用多个数据集中的数据训练算法[59]或借助数据增强[60]、迁移学习[61]等技术对算法进行训练;另一种方法是借助半自动标注技术[62-63]降低数据标注的成本,但这些方法都不能从根本上解决缺乏大规模目标检测训练数据的问题。随着深度学习技术的发展,半监督和无监督的深度学习方法在目标检测领域的应用能够大幅降低目标检测数据集的标注成本。
2)如何提升骨干网络的性能。深度学习强大的特征提取能力是基于深度学习的目标检测算法取得成功的关键。骨干网络对目标检测算法性能的影响主要体现在精度和性能两个方面:一方面,更加复杂的骨干网络通常具有更强的特征抽取能力,使目标检测算法具有更高的精度,文献[64]通过实验证明了骨干网络的深度、宽度和输入图像的分辨率都会对算法的精度产生影响,另外卷积、反卷积、残差网络等深度学习基本模块和Transformer[65]、图神经网络(Graph Neural Network,GNN)[66-67]等新的神经网络架构在目标检测领域的应用都能提升算法的精度;另一方面,骨干网络的速度决定了目标检测算法的检测速度,SqueezeNet[68]、MobileNet[69]、ShuffleNet[70]等轻量化骨干网络在目标检测领域的应用提升了算法的速度,这些骨干网络存在的共同点是它们都是研究者手工设计的,设计的过程非常耗时且设计的结果并非全局最优。基于神经架构搜索(Neural Architecture Search,NAS)[71]的自动化网络设计和基于AutoML[72]的自动网络压缩能够在较少人工干预下自动求解最优的网络结构。这些技术在目标检测领域的应用有助于构建出具有更高性能的骨干网络。
3)如何提升算法对异常尺度目标的检测精度。已有的目标检测算法在检测异常尺度目标尤其是成群的小目标时存在检测精度偏低的问题。多数算法采用特征金字塔等多尺度的特征抽取方法和构造的损失函数提升算法对异常尺度目标的检测精度[73]。这些方法均缺乏对图像中内容的理解,虽然在一定程度上使问题得到了改善,但都没有从根本上解决这一问题。上下文学习是一种通过算法学习输入图像中“目标与场景”、“目标与目标”之间存在的共存关系的机器学习技术。未来将借助基于类别语义池的上下文记忆模型[74]、图推理[75]和知识图谱[76]等技术,能使算法根据抽取到的特征推断目标的存在,从而提升检测精度。
4)如何实现面向开放世界的目标检测。已有的目标检测算法大多基于封闭的数据集进行训练,仅能实现对数据集中所包含的特定类别的目标检测。在现实应用中,目标检测算法需要检测的目标的类别往往是动态化和多样化的,如在自动驾驶、植物表型分析、医疗保健和视频监控的场景下,算法在训练时无法全面了解推理时预期的类别,只能在部署后学习新的类别,大部分已有的算法无法解决这些需求。面向开放世界的目标检测能够在没有明确监督的前提下,将未知的目标识别为“未知”类别,并且能够在获得这些“未知”类别的标签后逐步对新的类别进行学习而不遗忘旧的类别。这类方法的研究将使基于深度学习的目标检测算法在现实中得到更多的应用。
5)如何基于深度学习进行其他形式的目标检测。目前对目标检测的研究主要集中在图像目标检测,对于其他形式的目标检测,如3D 目标检测、视频目标检测涉及较少。这些目标检测任务对自动驾驶、工业机器人等领域具有重要意义。由于安全性、实时性的要求,导致对目标检测算法的精度和速度有更高的要求,因此难度较高。这些领域背后蕴含着巨大的市场和经济效益,使这些形式的目标检测算法的研究具有较好的发展前景。
5 结束语
深度学习技术可有效提升目标检测算法的性能并使其适用于复杂环境。本文以是否存在显式的区域建议与是否定义先验锚框两种分类标准对已有基于深度学习的目标检测算法进行分类,总结各类算法的机制、演进路线、优势、局限性及适用场景,并对各类目标检测算法在VOC 2007 和COCO 2018 数据集中的性能进行对比和分析。在此基础上,对基于深度学习的目标检测未来研究方向进行展望。
