基于机器学习的高速复杂流场流动控制效果预测分析
2022-07-14余柏杨吕宏强周岩罗振兵刘学军
余柏杨,吕宏强,周岩,罗振兵,刘学军
1.南京航空航天大学 计算机科学与技术学院/人工智能学院模式分析与机器智能工业和信息化部重点实验室,南京 211106
2.空气动力学国家重点实验室,绵阳 621000
3.气动噪声控制重点实验室,绵阳 621000
4.软件新技术与产业化协同创新中心,南京 210023
5.南京航空航天大学 航空学院,南京 210016
6.国防科技大学 空天科学学院,长沙 410073
0 引 言
流动控制技术是流体力学研究的前沿和热点之一,高效的流动控制系统能够显著提高飞行器动力性能、节约大量燃料、降低碳排放。流动控制技术主要分为被动控制和主动控制2 种方式。被动控制[1]不需要额外的能量,具有控制简单、易于实现、设计制造成本低的特点。主动控制[2]则是引入辅助能量的控制方式。主动流动控制技术发展的核心问题是研制高性能的流动控制激励器[3],在不同的应用条件和控制目的下,对激励器的工作性能要求也有所不同,因此获得激励器工作性能参数变化规律,对激励器优化设计和实际应用意义重大。
在激励器工作性能参数研究实验中,传统的方法需要对每个工况参数设置不同数值,通过大量的对比实验来研究各个不同参数对实验结果的影响程度,需耗费大量的时间和资源。机器学习[4]的快速发展为流动控制技术提供了新的发展方向。Minelli 等[5]通过遗传算法实现了高雷诺数钝体绕流开环控制的最优参数预测。Ren 等[6]采用格子Boltzmann 方法求解器第一次还原了层流条件下的控制效果,并对湍流条件下圆柱绕流减阻进行了探究。Rabault 等[7]使用近端策略优化方法完成了圆柱减阻的闭环主动控制。侯宏等[8]在边界层转捩的主动控制中使用了神经网络模型构建了抽吸速度和边界层转捩位置之间的映射关系。这些基于机器学习的主动流动控制技术都取得了比较理想的效果,但其中分析激励器参数对控制效果参数影响的工作较少。因此,本文重点通过已有实验数据研究激励器参数和控制效果参数之间的关系,分析影响控制效果参数的重要因素,指导实验中激励器参数的设置。
本文从有限的实验数据(样本容量小于30)中挖掘数据之间的关系,属于小样本机器学习问题[9]。在机器学习中对小样本问题的处理一般有3 个步骤:1)使用不易过拟合的模型(如非参数化模型);2)简化问题,采用特征重要性分析方法,若存在重要性较弱的特征,可将其删除;3)交叉验证(适用于小样本数据集的模型验证方法)。
高斯过程回归(Gaussian Process Regression,GPR)是一种非参数化机器学习模型,已广泛应用于小样本的非线性问题。罗亦泳等[10]构建了基于GPR的GPS 高程转换模型,将GPR 与其他拟合模型进行对比,通过将17 个GPS 点划分为不同比例的训练和测试数据集,分析了不同比例的训练数据集对不同GPS 高程转换模型精度的影响。罗亦泳[11]将64 期大坝变形观测数据划分为50 期训练数据和14 期测试数据,通过GPR 构建了大坝变形预测模型,并建立了预测结果的方差及置信区间的估计方法,对预测结果进行了可靠性分析。孙斌等[12]为了提高风速预测的精度,采用了一种基于GPR 的风速预测模型,并将GPR 与支持向量机、最小二乘支持向量机和BP 神经网络进行了比较。这些工作均证明了GPR 模型能够成功地对小样本回归问题进行建模,具有较好的推广性。
特征重要性分析是分析监督学习中不同输入参数对输出参数影响程度的方法,可获得重要特征参数,降低数据中冗余信息的干扰,改善模型的性能。常用的方法包括卷积神经网络、LASSO 回归、自动关联确定(Automatic Relevance Determination,ARD)和随机森林(Random Forest,RF)等。张韶辉等[13]利用LASSO 回归分析筛选出了与冠心病密切相关的血脂指标。黄梅等[14]在分类挖掘中采用了基于随机森林的特征重要性分析方法。刘鑫童[15]基于深度卷积神经网络对甲状腺超声图像进行了系统分析并提取了重要特征。Sun 等[16]使用spalart allmaras湍流模型生成的训练数据对ANN 湍流模型进行训练,使用optimal brain surgeon 算法确定输入特征的相关性。已有的这些工作表明:通过特征重要性分析,有效提高了研究者对有监督学习问题的理解;有针对性地利用好重要特征,可以提高模型预测精度。通过特征重要性分析,删除重要性较弱的特征适用于小样本问题中样本容量小于特征维度的情况,而本文数据的样本容量大于特征维度,满足高斯过程回归模型对样本数量的要求,因此本文保留所有特征,重点分析不同激励器参数对控制效果参数的影响程度。
为了验证小样本机器学习中模型的泛化性能,通常采用交叉验证方法将原始数据集划分为训练集和测试集,避免为追求高准确率而在训练集上产生过拟合,保证模型在样本外数据上的预测准确率。训练集和测试集数据的不同划分,会使模型准确率发生明显的变化,为了消除这一变化因素,通常采用K 折交叉验证实现模型验证。胡伟杰等[17]通过GPR 对180 个样本采用5 折交叉验证,预测了导弹气动性能,对比了不同数据划分比例下GPR 模型的预测结果和稳定性。高赫等[18]基于GPR 对2 578 个样本采用了5 折交叉验证,控制了连续式风洞马赫数,采用了随机划分数据集与分组划分数据集2 种策略进行建模。Nematzadeh 等[19]采用不同的机器学习算法作为分类器,对原始乳腺癌和预后性威斯康辛乳腺癌进行分类,利用K 折交叉验证对不同机器学习算法进行了乳腺癌分类比较分析。
在超声速条件下,本文利用逆向等离子体合成射流流动控制技术[20]进行半球体激波控制实验[21]。实验数据包括15 个样本,每个样本的参数包括控制对象参数(头锥直径)、主动激励参数(腔体体积、电极间距、放电电容、出口直径、击穿电压)和控制效果参数(最大脱体距离)。每个样本的电极间距和击穿电压都是相同的,回归模型无法学习这2 个参数与最大脱体距离的映射关系,故实验中不考虑该参数。采用GPR[22]学习得到激励器参数(头锥直径、腔体体积、放电电容、出口直径)到控制效果参数(最大脱体距离)的映射规律,利用K 折交叉验证中的留一交叉验证法评估GPR 模型的预测结果,采用特征重要性分析方法分析各激励器参数对最大脱体距离的影响程度,分析激励器参数影响程度与控制效果预测精度的关系。本文工作对激励器控制对象参数和主动激励参数实验设计具有一定参考价值。
1 研究方案
本文研究方案(图1)可分为4 部分:第1 部分是工程实验环节,使用逆向等离子体合成射流流动控制技术,设置不同的激励器参数进行实验,获得不同参数组合对应的控制效果,并对各个参数属性值进行标准化处理;第2 部分使用高斯过程回归对数据进行建模,得到重要的激励器参数与控制效果参数之间的映射关系;第3 部分采用特征重要性分析对各个激励器参数进行特征重要性排序;第4 部分使用建立好的回归模型对控制效果参数进行预测,并评估模型的预测性能,分析激励器参数影响程度与控制效果预测精度的关系。若预测精度不足,则需要重新调整实验设置,根据激励器参数影响程度和控制效果预测精度的关系增加实验样本;若预测精度满足要求,则可用于指导后续主动流动控制实验。

图1 研究方案Fig.1 Research program
1.1 实验数据
如表1所示,实验采集的数据包含控制对象参数(头锥直径)、主动激励参数(腔体体积、电极间距、放电电容、出口直径、击穿电压)和控制效果参数(最大脱体距离)。激励器头锥直径会影响等离子体合成射流的速度和流场结构。激励器腔体体积[23]是影响射流流场特性的重要结构参数,反映激励器工作气体质量,决定腔内气体温度及压力的变化,并最终影响流场发展及射流速度。电极间距[24]是造成不同等离子体分布的关键结构参数,不同电极间距下外电场分布形态和数值的差异是形成2 种典型分布(类弥散和离散通道)模式的直接原因。放电电容[25]与等离子体合成射流速度呈正相关:大电容产生更多的能量沉积,实现腔体的充分加热,可产生速度更大的等离子体射流和强度更大的前驱激波;小电容所产生的等离子体射流流场内压缩波数增加,前驱激波强度减弱。出口直径[25]会影响等离子体合成射流的速度和耗散时间,且与前驱激波的强度呈正相关。激励器工作击穿电压[23]与激励器所处环境压强呈正相关,与放电频率呈负相关。

表1 实验数据Table 1 Experimental data
在一个开有出口孔缝的小腔体内放电产生等离子体,通过加热腔内气体使等离子体增压膨胀并高速喷出,产生速度高达数百米每秒的高能射流,即等离子体合成射流。射流锋面前方有一道呈球对称的结构,为前驱激波的强压缩波。前驱激波与射流出口孔缝之间的距离即为脱体距离。当高能射流达到最大长度时,前驱激波与射流出口孔缝之间达到最大脱体距离。拍摄等离子体合成射流流场的发展过程,截取高能射流达到最大长度时的一帧图像作为最大脱体距离图像,如图2所示。通过在图像中测量前驱激波最远点与射流出口孔缝2 个像素点之间的距离得到本研究所需的最大脱体距离。

图2 最大脱体距离图像示例Fig.2 An example image of maximum out of body distance
将控制对象参数和主动激励参数作为高斯过程回归模型的输入、控制效果参数作为高斯过程回归模型的输出,其参数设置同表1。图2即显示了一组控制效果参数的实验结果。
在将数据输入机器学习的模型之前,为避免参数数值范围不同对建模效果产生影响,需要将数据进行标准化处理。标准化公式为:

1.2 基于GPR 的控制效果参数预测模型
本文针对激励器控制效果预测的小样本回归问题,提出了基于高斯过程回归的预测模型,模型框架如图3所示。以逆向等离子体合成射流实验为例,输入为4 维参数向量(头锥直径、放电电容、腔体体积和出口直径)。首先将4 维参数向量作为输入数据输入到GPR 模型中训练模型,然后将GPR 模型输出的预测值与实验获得的最大脱体距离真实值进行对比,使用误差评估方法计算最大脱体距离的真实值与预测值之间的误差,得到GPR 模型的预测精度。本文的样本数为15,特征维度为4,满足使用高斯过程回归模型的最低样本容量要求[26]。

图3 基于GPR 的控制效果参数预测模型框架Fig.3 The framework of control effect parameter prediction model based on GPR
1.2.1 GPR 的模型假设
高斯过程可视为定义在函数f(x)上的一个分布,其性质由均值函数和协方差函数决定:

式中:x、x′ ∈Rd,为d维输入向量;m(x)为均值函数;k(x,x′)为协方差函数。
假设训练集为{(xi,yi)|i=1,···,n},n 为训练集样本数。对于回归问题,模型如下:
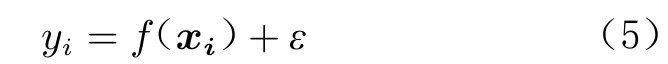
式中:ε~N(0,)为高斯噪声;xi为第i个输入向量,xi ∈Rd;yi为对应的观测值,yi∈R。为计算方便,将yi中心化,均值设置0,这时所有观测值构成的列向量y=[y1,y2,···,yn]T的先验概率分布为:

式中:X为特征矩阵,矩阵中每一行代表一个输入向量;K(X,X)=Kn=(kij)n×n为n×n阶对称正定协方差矩阵,矩阵元素kij=k(xi,xj);In为n阶单位矩阵。
1.2.2 GPR 的训练
假设一个协方差函数的超参数集合为θ=,m为超参数的数量,通常采用极大似然法确定θ的最优值。观测值y的边缘概率分布为:

通过式(7)可以得到训练集的负对数边际似然函数为:

式中,C=K(X,X)+,|C|为矩阵C的行列式。GPR 模型的优化目标为:
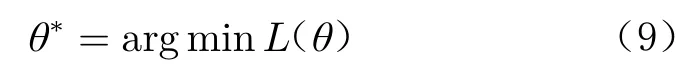
计算L(θ)关于各超参数θi的偏导数,然后采用共轭梯度下降法等优化算法迭代更新超参数来最小化L(θ)。
1.2.3 协方差函数的选择
本文使用的协方差函数有Polynomial(Poly)核、Squared exponential isotropic(SEiso)核、Squared exponential automatic relevance determination(SEard)核、Stationary+Matern(SM)核和Additive(Add)核[27]。
Poly 是一种非标准核函数,比较适用于正交归一化后的数据。根据平方指数协方差函数的超参数取值,可以分为2 种核函数:当向量对应的各个维度带宽取值相同时,得到的核函数就是各向同性的平方指数核,即SEiso 核;当向量对应的各个维度带宽取值不同时,得到的核函数就是各向异性的平方指数核,即SEard 核。SM 协方差函数是将多种单一的核函数相加构成的复杂协方差函数。Add 作为加性协方差函数,在输入向量的各个维度定义基本的协方差函数。
1.2.4 GPR 的预测
对于测试集中的一个样本x*,其对应的预测值f*与观测值y的联合先验分布为:

通过式(10)和一些矩阵运算,可以得到预测值f*的条件概率分布为:
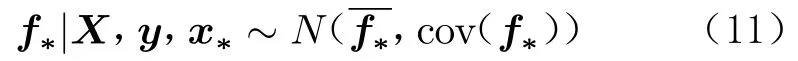
式中:
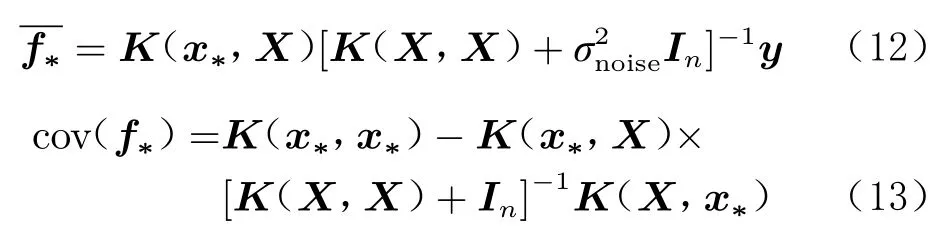
式(12)为预测值,式(13)为预测的方差,可以评估预测的不确定度。
1.3 特征重要性分析
本文使用的特征重要性分析[28]方法有LASSO回归、随机森林和自动关联确定。不同的特征重要性分析方法的准则不同,通过综合比较多种特征重要性分析方法的结果,增加分析结果的置信程度。
1.3.1 LASSO 回归
数据集D={(x1,y1),(x2,y2),···,(xN,yN)},其中N 为数据集样本数。考虑最简单的线性回归模型,以平方误差作为损失函数,则优化目标为:

式中,w 为权重向量。当样本特征很多而样本数相对较少时,式(14)很容易陷入过拟合。为了缓解过拟合问题,对式(14)引入L1 正则:

式中,λ >0,为正则化参数。式(15)为LASSO 的优化目标[29]。LASSO 采用L1 正则,可以产生稀疏解(w 许多分量为0)。根据这一特性进行特征选择,权重绝对值大的分量对结果的影响大。
1.3.2 随机森林
随机森林[30]是以决策树[31]为基学习器构建的模型。RF 可以用于特征重要性分析,计算特征重要性的方法主要有2 种:
1)采用平均不纯度减少准则
通过不纯度能够确定节点,即最优条件。一个森林能够计算每个特征平均减少的不纯度,并把平均减少的不纯度作为特征重要性分析的值。
2)采用平均准确性减少准则
RF 在构建每一棵基决策树时,使用bootstrap的方式对样本进行有放回采样,因此每次都会有一些样本不参与决策树的构建,这些样本即为袋外数据(out of bag data),可以利用这些数据进行特征重要性评估。对于RF 中的每一棵基决策树,先利用袋外数据进行测试得到测试误差,然后将这些测试数据[e1,e2,···,em]的某个特征顺序打乱(改变测试样本特征值)再得到m 个测试误差,将其作为该特征的重要性。若一个特征发生改变对预测结果影响很大,则说明该特征比较重要。
1.3.3 自动关联确定
假设输入空间是二维,x=(x(1),x(2)) ,ARD 核的形式为:

可以看出,随着特定ηi(对输入空间距离的伸缩变换参数)的减小,函数受输入变量x(i)的影响变小。将x=(x(1),x(2))代入式(16)得到 :

假设η2很小,则即:

此时核函数的取值几乎不受输入变量x(2)的影响,说明x(2)对最终输出的影响不大。利用ARD 协方差函数的这个性质,可以判断出不同特征对结果的影响大小,并且整个过程无需人为干预,模型可自适应地从数据中学得这种关系。
2 实验结果及分析
2.1 预测性能评估
采用均方根误差(RMSE)作为训练和测试误差:

模型验证采用K 折交叉验证,其本质是创建一系列训练集和测试集,先计算模型在每个测试集上的准确率,再计算平均值。具体步骤如下:1)将原始数据集划分为相等的K 部分;2)将第1 部分作为测试集,其余作为训练集;3)训练模型,计算模型在测试集上的准确率;4)每次用不同的部分作为测试集,重复步骤2)和3) K 次;5)将平均准确率作为最终的模型准确率。留一交叉验证法是K 折交叉验证的一个特例,将数据子集划分的数量与样本数相同(K=N),每次只留一个样本用于测试,这种方法适用于小样本的情况。由于本文属于小样本问题,且样本的参数取值跨度很大,参数的分布密度较低,因此采用原始数据的4 个激励器参数特征、15 个样本进行留一交叉验证实验,即每次选取14 个样本作为训练数据,留一个样本来评估模型预测的结果,重复实验15 次,取15 次实验结果的平均RMSE 评价模型性能。
不同核函数的训练均方根误差盒状图如图4所示,测试误差均值如表2所示。由图4可知,SM 和Add 核训练误差明显比其他核函数低,表明其对训练数据的拟合程度更好。但由表2可知,这2 种核函数的测试误差明显高于其他核函数,而二次多项式核函数Poly2 虽然在训练数据集上误差高于SM 和Add 核,但在测试数据集上获得了最高的预测精度。这是由于SM 和Add 核所含超参数较多,在样本数较少的情况下容易产生过拟合。多项式核、SEiso核和SEard 核都只含有2 个超参数,在小样本训练的情况下具有较好的泛化性能。

图4 训练数据集上GPR 不同核函数对应的预测RMSE 盒状图Fig.4 Boxplot of RMSE for models with different kernel functions of GPR on training data set

表2 测试数据集上GPR 不同核函数对应的预测RMSE 均值Table 2 Mean RMSE for models with different kernel functions of GPR on test data set
2.2 相关性分析
2.2.1 皮尔逊相关系数
皮尔逊相关系数[32]可以衡量2 个变量(x(1),x(2))的线性相关程度,其值介于-1 和1 之间,计算公式如下:

式中,μ为样本均值,σ为标准差。通过计算逆向射流数据不同特征和最大脱体距离之间的皮尔逊相关系数,得到如图5所示的相关性热图。可以看出,头锥直径、放电电容与最大脱体距离相关性较强,且呈正相关;腔体体积、出口直径与最大脱体距离呈负相关,且出口直径与最大脱体距离之间的线性相关性最弱。
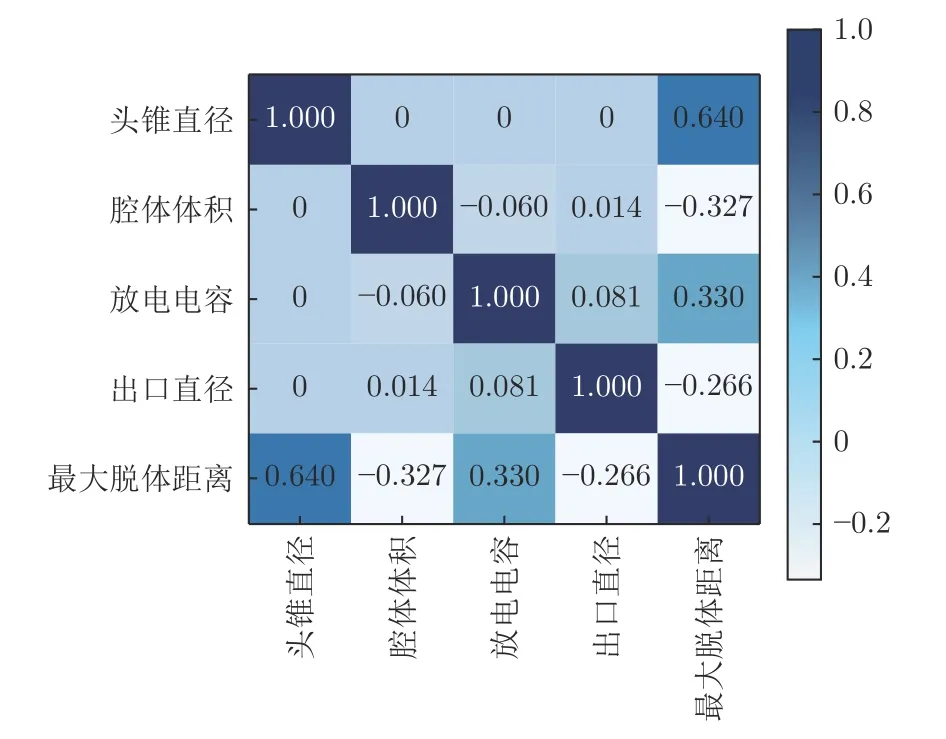
图5 皮尔逊相关系数Fig.5 Pearson correlation coefficients
2.2.2 特征重要性分析
通过皮尔逊相关系数可以初步得出各个特征与最大脱体距离之间的线性相关性,但复杂流场的头锥直径、腔体体积、放电电容、出口直径与最大脱体距离之间并不是简单的线性关系。为了进一步挖掘它们之间的关系,利用ARD、LASSO、RF 这3 种特征重要性分析方法得到各个特征的重要性,如图6~8 所示。
ARD 核函数自适应可以确定重要特征的特点,通过高斯过程回归得到各个维度的带宽L(归一化后),L 越大,则特征对结果的影响越小。定义特征重要性为L–1。由图6可知,头锥直径对结果的影响最大,出口直径对结果的影响最小。这也从某种角度为后期实验指明了方向:对结果影响较小的特征,实验过程中的采样数量可以尽量少;相反,对结果影响较大的特征,实验过程中的采样数量可以尽量多。这样可以最大限度地减少实验次数,增加数据的多样性,从有限的数据中挖掘尽可能多的有用信息。

图6 ARD 特征重要性分析结果Fig.6 Results of feature importance analysis from ARD
由皮尔逊相关系数可知,头锥直径、腔体体积、放电电容和出口直径之间无明显的线性相关性,所以此时可以利用LASSO 来分析特征重要性。将LASSO 的正则化参数设为0.1,得到各个特征权重的绝对值。从图7可以看出,利用LASSO 得到的特征重要性分析结果与ARD 方法的结果完全一致。
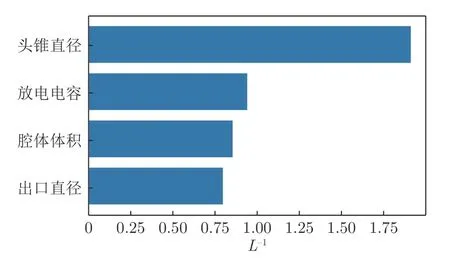
图7 LASSO 特征重要性分析结果Fig.7 Results of feature importance analysis from LASSO
RF 有2 种计算特征重要性的方式,在本实验中采用平均准确性减少准则,因为平均不纯度减少准则对取值个数较多的特征存在一定的偏好,会使特征重要性估计不准确。由于本文只有4 个特征,所以在训练RF 时并没有引入属性扰动,为了增加结果的稳定性,将基决策树的个数设为100。由图8可知,与前述2 种方法一样,RF 的结果也是头锥直径对最大脱体距离影响最大,而出口直径对最大脱体距离影响最小。

图8 RF 特征重要性分析结果Fig.8 Results of feature importance analysis from RF
上述特征重要性分析方法针对实验样本的参数进行,而样本的数量有限,因此实验结果只适用于样本的参数取值范围(头锥直径30~70 mm,腔体体积250~3 000 mm3,放电电容80~640 nF,出口直径1.5~9.0 mm)。 由特征重要性分析结果可知:相对而言,头锥直径对最大脱体距离影响最大;其次是腔体体积和放电电容,这2 个参数对最大脱体距离的影响相差不大;出口直径影响最小。
2.3 特征与预测结果的关系分析
图9和表3显示了最大脱体距离的预测结果,其中红框、绿框和蓝框标注出了预测不够准确的样本。对应表3中的实验数据可以发现,红色方框中样本的头锥直径分别为30 和70 mm,蓝色方框中样本的放电电容分别为80 和160 nF,绿色方框中样本的腔体体积分别为3000、500 和250 mm3。头锥直径作为最大脱体距离最重要的影响特征,放电电容和腔体体积作为次重要的特征,实验数据在这3 个特征上分布密度较低,导致模型的预测不够准确。对比发现黄框中样本的预测相对准确(真实值与预测值误差的均值最小),对应于采样密度较低的出口直径。由于出口直径是重要性最小的特征,因此对最大脱体距离预测精度的影响较小。除颜色框中的样本外,其余样本在各个特征维度上的分布密度较大,因此预测结果均较为准确。根据以上分析,为提高模型预测精度,设计实验时应加大对控制效果参数影响较大的激励器参数的设置密度,减少对控制效果参数影响较小的激励器参数的设置密度,以减少实验次数,最大程度利用实验资源。

图9 最大脱体距离真实值和预测值Fig.9 Real and predicted values of maximum out of body distance

表3 实验数据及预测结果Table 3 Experimental data and prediction results
3 结 论
1)使用逆向等离子体合成射流激波控制实验数据对激励器参数和控制效果参数之间的映射关系进行建模,建立了高斯过程回归模型。对比多种核函数下高斯过程回归的预测效果,采用二次多项式核函数Poly2 的高斯过程回归预测效果最好,因此对于样本量少的数据集,使用“简单”的核函数能够得到更为准确的预测结果。
2)采用3 种特征重要性分析方法(ARD、LASSO、RF)分析各个激励器参数特征对最大脱体距离的影响程度,结果发现头锥直径对最大脱体距离的影响程度最大,放电电容和腔体体积的影响次之且相近,出口直径的影响最小。
3)对结果影响比较大的特征(如头锥直径、放电电容和腔体体积)应增加其采样数量;反之,对结果影响较小的特征(如出口直径)可以减少其采样数量,以减少实验次数。
4)本文提出的应用于逆向等离子体合成射流激波控制实验的控制效果分析方法,也适用于工程设计中其他类似控制问题研究。通过对少量实验数据内隐含的激励器参数和控制效果参数之间的映射关系建模,并对激励器参数进行重要性分析,可以得到合理的实验参数设置方式,提高实验效率和控制效果预测精度。
