基于改进特征提取及融合模块的YOLOv3模型
2022-07-13余汉成
赵 轩,周 凡,余汉成
(南京航空航天大学 电子信息工程学院,江苏 南京 211106)
近年来深度学习方法在许多人工智能子领域取得了突破性进展,例如计算机视觉任务图像识别、目标跟踪、语义分割及传统的图像处理任务等。相比较传统的神经元模型单层/多层感知机,卷积神经网络、循环神经网络等新型结构拥有更好的特征提取能力,神经网络的深度、宽度和分辨率有了显著的改变。基于AlexNet[1]在大规模图像分类任务上的表现,研究人员提出了许多新型网络架构,例如平坦的网络VGG[2]、残差网络ResNet[3]、密集连接的网络DenseNet[4]、感受野网络InceptioNet[5]及其相关的结合和变形。通过对网络尾部的模块和损失函数进行调整,上述各种模型可用于不同的计算机视觉的任务处理中。
目前,基于基本模型[1-5]研究且适用于特定任务的高效架构成为神经网络领域主要的研究方向。为了在特定任务上获取更好的效果,目标检测架构YOLO(You Only Look Once)[6-8]系列、SDD(Single Shot MultiBox Detector)[9]等采用基本通用模型的变形来提升模型的精度:(1)引入矩形锚框的先验信息来规避直接的参数回归;(2)引入网格化的密集检测,通过非极大值抑制进行后处理;(3)采用多尺度检测。
多尺度特征融合、多尺度检测在神经网络中被广泛使用[8-12]。YOLOv3[8]采用多尺度上采样融合增加了小目标的检测精度。SSD[9]采用多个尺度同时检测目标。图像金子塔池化[11]和图像金字塔检测[12]显著提升了目标检测的精度。然而YOLOv3[8]模型有进一步提升的空间:(1)3个尺度(13×13,26×26,52×52)之间采用不同长宽的先验锚框,同时其3个尺度的标注框相同,检测层不同尺度之间的特征有待进一步融合;(2)引入可变形卷积模块可进一步增强YOLOv3残差模块的特征提取能力。基于上述两点,本文提出一种改进的YOLOv3模型,并在工业检测数据集上对该模型的性能进行测试。
在深度学习领域已有多个目标检测数据集,例如大规模目标检测数据集VOC2007(Visual Object Classes Challenge)、VOC2012、COCO2015(Common Objects in Context)、COCO2017。然而,对于工业领域的工业目标检测仍然缺乏相应的标准检测数据集。文献[12]通过标注构建了工业工具检测数据集,其包含了大量的工业工具手工标注检测框,有助于进一步研究目标检测框架在工业领域的应用。
1 针对工具库的工业目标检测
获取良好的数据集对深度学习模型的训练有重要作用。采集图像的方法对工业目标检测模型的泛化能力有一定影响。不同的获取条件(光照、视角)将采集到不同的训练数据。采用与作业时相似的环境有利于模型的稳定性。
在工业环境中,当机器人开始操作工业场景中可用的标准工具和设备时,它们需要识别工具并知晓它们的用途。本文研究的工业工具数据集[12]是作者在2017年9月至2018年5月期间通过计算机视觉和人工智能研究,在典型工厂收集的常用工具的图像(共有11 765张图像)。该数据集包含8个对象类型的照片,且这些对象类型可以由合格的工作人员识别。数据集在工厂、车间、装配线和施工现场场景等5个不同场景中收集,拍摄背景如图1所示。

图1 工具库的拍摄背景图
文献[13]采用Kinect 2.0图像传感器,以30帧的帧率、1 024 ×575的RGB(Red Green Blue)图像分辨率和512 ×424的深度图分辨率来收集数据。由于工业的检测下标注数目较少,本文通过改变采集数据时的直线距离来增加数据量(物体到相机的距离在1~5 m内变化)。在采集数据的同时,周围的环境设定与工人工作的环境一致(例如光照);工具的摆放姿势也设定为工人视角下常见的姿势。采集工作员在采集数据的同时尽量平稳行走且保持拍摄目标的一致性。为了计算摄像机的固有参数,本文使用了一个已知尺寸的校准板。校准板的大小、校准参数和 OpenCV(Open Source Computer Vision Library)校准工具的信息都包含在数据集内。
2 基于多尺度上采样融合的YOLOv3 改进
近年来,特征金字塔(尺度信息融合)在多种计算机视觉任务中被广泛使用。例如,在目标检测中,不同尺度行人图像区域的几何信息较为相似,但离相机镜头较近的行人拥有更多像素区域,而离相机较远的行人则与之相反。在图像处理中,不同尺度的图像块相结合可为模型带来更多的优势。YOLOv3[8]通过多尺度检测显著提升了小目标的检测精度,说明高效利用特征金字塔有利于增加深度网络模型的鲁棒性。
2.1 基于尺度特征融合的模型改进
文献[14]提出了尺度间自适应融合的目标检测网络,加强了不同尺度之间的特征融合。基于该研究,本文进一步改进YOLOv3的特征融合方式。典型的多尺度融合方式如下:
(1)平坦方式,多尺度的特征检测输出。从原始的输入图像中提取高层特征并不断降低特征分辨率,最终网络将得到不同分辨率的输出特征。将每一尺度的分辨率特征输入到最终的回归提取层,随后网络将不同尺度的检测框输出并进行后处理;
(2)采样方式,从上到下的特征检测输出。低分辨率的特征上采样与高层的特征做残差来进行特征融合;
(3)密集方式,从上到下再到上的连接结构,相同分辨率的特征之间存在跳跃连接。在YOLOv3结构中,低分辨率的特征通过上采样的方式转化为高分辨率特征,而后与高分辨率特征进行堆叠。YOLOv3的特征提取网络采用多尺度的信息,然而3个尺度的检测层存在以下问题:(1)3个尺度的目标检测分支采用不同长宽的锚框。对于低分辨率尺度,特征融合程度较高,适合检测比较大型的物体,因此低分辨率尺度分配的锚框长宽较大;高分辨率尺度的特征更加细节,适合检测比较小型的物体,因此低分辨率尺度分配的锚框长宽较大;(2)对于检测任务,3个尺度的检测输出虽然相同,但其特征有一定的差异;(3)提取层需要回归目标的中心点和偏移量。对于目标的3个尺度,中心点的特征依然有差异。根据上述发现,3个尺度的检测层特征之间需要进一步融合,此方式可能有助于不同尺度之间的特征融合,弥补单一尺度上的检测损失。
本文采用密集方式来改进YOLOv3框架,以促进不同尺度之间的特征融合方式,改进结构如图2所示。如图2所示,特征提取网络YOLO层不做改动,只对网络3个尺度的检测输出分支做相应的改动。通过插值的上采样方式,低分辨率的检测层特征被采样到中分辨率层,中分辨率的检测层被采样到高分辨率层来促进不同分辨率之间特征的融合。由于YOLOv3网络框架一般采用文本文件定义,工程上可通过Route+upsample+route形式来实现Up+route模块。

图2 YOLOv3多尺度上采样融合改进示意图
2.2 模型改进实验
本文实验采用Darknet-53网络,模型训练及测试采用Pytorch深度学习框架,并采用RTX 2080ti单GPU(Graphics Processing Unit)进行训练,CPU(Central Processing Unit)为AMD 3900x。
针对不同的数据集,需要采用K-means聚类算法调整先验锚框的大小。针对本文的工具库,YOLOv3的先验锚框大小需要提前做预处理,来达到更高的IOU值。锚框的训练采用 “维度训练”的方法为:对于不同长宽的锚框,与当前标注框的IOU值最大的锚框用于训练,训练时其相应的维度设定为真(True);其余的维度设定为假(False)。IOU的定义如下
(1)
式中,IN表示两区域的交集;OUT表示两区域的并集。本文沿用K-means算法对原始的二维长宽数据进行聚类。当聚类的初始化节点个数增加时,聚类中心的个数增加(锚框的数量增加),相应的锚框组和真实标注框的平均覆盖率也会增加。
对于YOLOv3的多尺度检测模型,本文沿用9种不同类型的锚框(即9个聚类中心点),并将大型的锚框分配给低分辨率特征,将小型的锚框分配给高分辨率特征。
神经网络的输入图像分辨率在一定程度上影响网络的性能,本文实验沿用原始YOLOv3的输入分辨率,将所有的输入图像填充为长宽相等的图像,并将其缩放到416×416分辨率,在一定的范围内采用多尺度训练。工具库数据集包含11 765张图像,本实验以0.9/0.1的划分进行训练和测试。基本的训练模型使用检测框几何分量的均方误差(Mean Square Error,MSE)损失
(2)
式中,x、y、w、h依次为中心点的宽度、高度坐标和检测框的宽度、高度。当检测框的几何分量与标注框有差异时,LMSE的值相应的变大,网络通过梯度的反向传播对模型的参数进行优化。类别损失采用二元交叉熵(Binary Cross Entropy,BCE)损失函数。
(3)
对于目标区域和非目标区域,本文采用加权损失来平衡训练过程
LALL=λ1LO+λ2LNO
(4)
式中,LO为目标网格的交叉熵损失;LNO为非目标网格的交叉熵损失;λ表示相应的加权参数。目标检测框架采用统一的指标,即模型对所有类别的平均决策(Mean Average Precision,MAP)来衡量模型的性能
(5)
式中,APc表示某一类别的准确率。具体训练设定如表1所示。
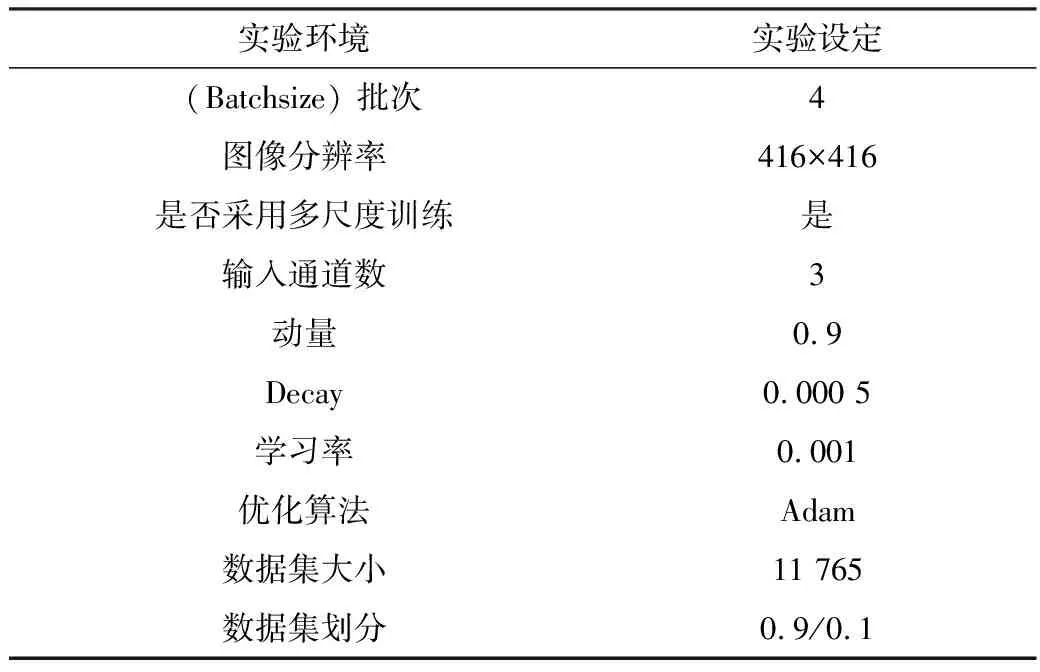
表1 基本模型的超参数表
由于工具库数据集并未开源代码的具体训练参数,因此本文实验均和YOLOv3本身比较。YOLOv3在数据集上的训练大约花费16个小时,共150次(Epoch)。

表2 改进模型与原始模型MAP比较表
其中MAP1表示基本模型,MAP2表示改进模型。最终,相较于原始的模型,多尺度的融合模型提升了3.2点MAP,提升了框架在工具库测试集上的精度。
3 基于可变形卷积层的改进
本文研究的工业抓取数据集依然存在以下特点:(1)由于机器人在检测工具的过程中会面临不同的检测视角,因此数据集包含大量物体视角变换;(2)工具的不同放置角度增加了任务的难度。由于卷积层在图像空域共享视野,其无法良好地适应局部特征的几何变换。若能增强网络在空域的特征提取方式,则有可能提升网络模型在工具库上的检测精度。
3.1 可变形卷积单元
除了大量卷积架构,卷积核本身也有较多变化/推广形式被研究,例如带洞卷积[15]、活动卷积单元[16]、可变形卷积[17]、移动端快速网络[18]。可变形卷积单元(Deformable Convolutional Networks,DCN)通过引入局部偏移量参数来改变卷积和空域的采样形状。在原始栅格数据的基础上,DCN给每一个空域位置加上相应的偏置参数(即水平和垂直方向的偏移量)。此时,卷积层仍然共享视野空域,但局部的偏移量特征改变了卷积模块的采样位置,增加了对不同空域特征的自适应能力。原始2D卷积层包含以下步骤:
步骤1对局部特征采样规则的特征点R;
步骤2根据卷积核的权值计算特征点的加权和。其中,R的定义为
R={(x,y)},x/y∈{-1,0,1}
(6)
式(6)表示以局部图像特征点为中心的周围9个网格。对于特征点位置p0,其输出为
(7)
式中,W为滤波器权值;b为偏置分量;pn为p0的邻域位置。可变形卷积对式(7)的每个邻域位置为pn+p0,增加了相应的偏移量Δpn。
(8)
DCN的偏移量计算如图3所示。
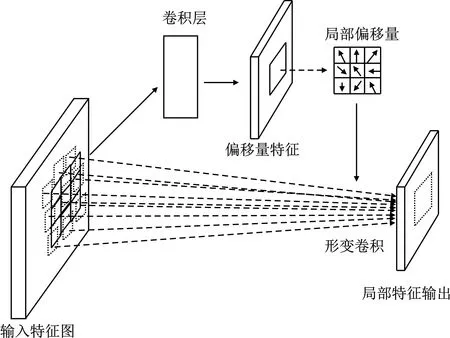
图3 可变形卷积模块的偏移量计算示意图
3.2 残差模块改进及实验结果
基于可变形卷积单元,本文对YOLOv3网络进行改进:采用可变形卷积层替换原始的卷积层来提升残差模块的特征提取能力。对于卷积层提取出的特征信息,网络前端提取的特征多为边缘、颜色等底层信息,网络的中层和后层往往包含高层的语义信息。基于以上分析,本文在章节2.1多尺度融合模型的基础上进一步改进卷积层的特征提取模块。
本文在特征语义信息较高的层改动两个卷积层。表3为加入改进可变形卷积层的实验结果表。

表3 YOLOv3基础模型与改进模型的MAP精度比较表
从表3可以看出,加入可变形卷积层可以更进一步地提升网络在工具库的检测精度。
其中,模型1为Base-YOLOv3,模型2为Up-route,模型3为Up-route+DCN。由表4可以看出,除“Clamp Tools”和“Marker”以外改进模型提升了各类的准确率,其中“Polish Tools”提升高达13.15。相比于基本模型,比较改进模型提升较为明显;相对于YOLOv3基本框架,本文的平均检测精度更高。
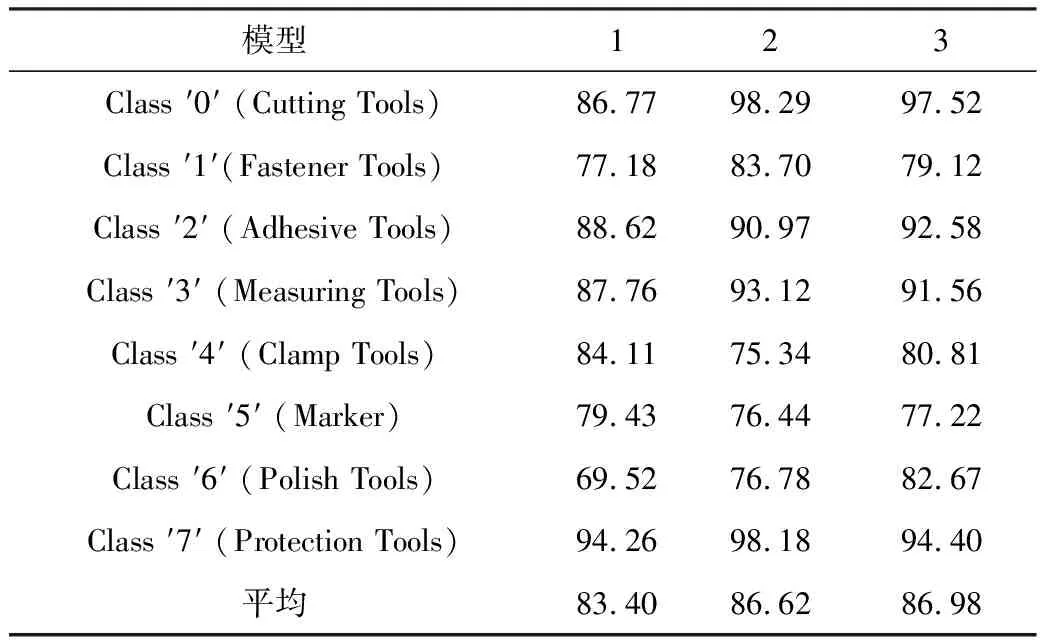
表4 单个类别的MAP比较表
图4为可变形卷积改进结构示意图,本文用可变形卷积层替换了残差模块的第二个卷积单元。图5为检测结果的可视化举例,本文模型精准地检测出了各类型工具的区域。从图5的实例图像中来看,检测框的边界与物体的实际边界极其接近,说明本模型能够精确定位工具在图像中的位置。
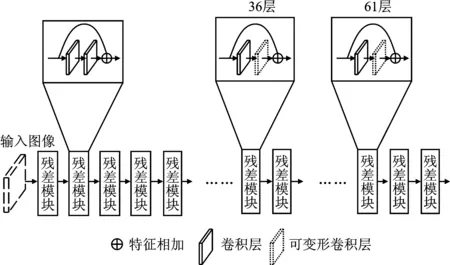
图4 基于可变形卷积层的YOLOv3改进模型图

图5 YOLOv3框架的目标检测结果图
尽管DCN和多尺度融合能增强YOLOv3网络的识别精度,但额外的卷积层和堆叠的特征加大了原始网络的计算量。表5中,相比原始YOLOv3,改进模型的计算速度与原始模型相似,不影响实时性能。所有数据均在以下硬件环境中进行测试:CPU Intel Core i7-8750H;NVIDIA 1060显卡(notebook)。实验中,从工业抓取数据集中提取出50张测试图像用于计算平均运行时间,结果如表5所示。

表5 改进模型与原始YOLOv3运算速度比较表
4 模型及结果分析
4.1 检测结果分析
由表4可知,除“Marker”及“Clamp Tools”以外,本文提出的模型显著提升了各类别的检测精度。通过对不同模型的测试,实验的某些训练模型在“Marker”及“Clamp Tools”上超过了原始YOLOv3模型,但并未达到最高的平均MAP(例如另一模型A “Clamp Tools”准确率为87.10,MAP为85.90)。在优化过程中,由于深度学习模型的非凸性质及类别间的差异模型,对其中某几类的优化有可能会导致其他类别的精确度下降。当大部分类别的准确率都显著提升时,可以认为模型的整体准确率有了提升。
4.2 优化失败的改进尝试
类似于文献[8],本文罗列出一些改进来尝试提升对改进模型的理解:(1)在改进方法1中,将表1的优化算法替换为SGD(Stochastic Gradient Descent);(2)在改进方法2中,将35层和60层的卷积核用可变形卷积替换,如图4所示;(3)在改进方法3中,尝试加入如式(9)所示的IOU(Intersection-over-Union)损失LIOU;(4)在改进方法4中,采用IOU和MSE线性叠加的损失。实验的结果如表6所示。

表6 失败的改进尝试
LIOU=1-IOU
(9)
由改进方法1的实验结果可知,Adam算法稳定性优于SGD。改进方法2的实验结果说明在残差模块中,改动较少的卷积核稳定性更高。对于改进方法3和改进方法4,由于IOU本身为尺度无关的统计量,单纯引入IOU损失函数无法有效地优化网络,需要在本文提出的改进模型中进一步探索IOU损失函数的应用。
5 结束语
本文通过两种改进方式提升了YOLOv3目标检测框架在工业目标检测数据集上的检测精度。第1种方式分析了不同尺度之间锚框检测层的特点,采用不同检测尺度之间的特征融合来改善目标检测网络的检测精度。第2种方式通过分析工业数据集的特点,带入相应的可变形卷积层来拟合视角、几何变换。实验结果表明,以上两种技巧能对原始的YOLOv3目标检测模型实现稳定的提升。通过对比实验和失败案例,本文证明了改进模型的正确性和高效性。本文提出的改进模型仍存在进一步提升的空间。YOLOv3模型采用聚类的方法得出先验锚框,然而对于特定的类别锚框的长宽比有一定的特点(例如行人标注框的宽高比一般比较小)。而从特征学习的角度自适应地学习锚框长宽,可改善本文模型的精度。后续也将基于该策略来进一步提升模型的表现。
