像素邻域差向量协方差特征的多视角人脸检测
2022-07-06薛亚非谷静平
吕 晶,薛亚非,谷静平
(南京师范大学中北学院,江苏 丹阳 212300)
人脸检测是计算机视觉领域非常重要的一个研究分支,被广泛应用于生物特征验证、视频监控、目标跟踪和面部表情识别等领域. 姿态变化、人群遮挡、面部装饰、视角差异、光照不均衡等问题都使得人脸检测面临重大挑战. 虽已有许多研究工作来解决这些问题,但复杂条件下的人脸检测性能仍不能满足实际应用的要求.
早期的人脸检测研究将人脸检测定义为一个刚体检测问题,主要围绕设计不同的手工特征或学习方案,以获得更满意的结果. 具体来说,Haarlike[1]、MB-LBP[2-3]、ICF[4]和SURF[5]等手工特性结合集成学习算法,可在实时运行速度下获得令人满意的结果. 在高端GPU设施的高性能服务器的帮助下,一些商业产品可以在图像或视频中非常准确地捕捉人脸.
本文的目标是设计一个轻量化的人脸检测系统,可以部署在移动或嵌入式设备中,并具有较好的检测性能. 由于通道特征(ICF)[6-7]运行速度快、性能高,可用于高效的人脸特征表示. 在此基础上,像素差向量(PDV)特征[8]的提出极大地提升了性能,但其忽略了不同像素之间的关系建模. 而PDV作为一种一阶运算符,如何将其高阶统计信息应用于特征编码以提升特征表达能力,仍未得到很好的解决. 针对此问题,本文研究了PDV在局部区域内差向量分量之间的协方差信息,提出了一种新的像素差协方差特征,可显著提高多视角人脸检测的性能.
1 相关工作
人脸检测研究的历史可以追溯到至少50年前,文献[1]提供了对早期和当前研究的详细介绍. 人脸检测方法可以根据输入图像类型分为灰度图像和彩色图像两大类. 在早期的研究中,大多数方法都属于第一类. 文献[5]对多尺度的图像使用一组基于神经网络的滤波器,然后将检测结果合并为最终的输出. 作为人脸检测领域的里程碑工作,V&J检测器利用Haar小波[1],对位于指定位置的相邻区域不同大小的平均像素差值进行编码. 通过AdaBoost算法学习Haar特征,并级联实现实时运行. 许多后续研究对这项工作进行了改进,如扩展的Haarlike或不相交的Haarlike feature[1]. 有学者基于分块LBP特征[2]用于正面人脸检测,以较少的特征数目显著提升了检测精度. 文献[3]提出了一种新的基于分布的特征,将识别信息嵌入到特征中以提高人脸检测器的性能. 这些方法均基于图像亮度信息,对光照变化敏感,缺乏颜色信息. 另一类方法利用颜色信息,在目标检测中也被证明是非常有效的. HOG 特征首先被提出用于人体特征建模,也可用于人脸检测. 近年来,基于形变部件模型的人脸检测方法已成为人脸检测的主要方法. 该方法在输入图像分辨率较高的情况下取得了良好的效果. 最近,采用V&J的检测方法流程,积分通道特征也被用于人脸特征表示,在一些公共数据集上取得了较好的结果. 在行人检测领域广泛应用的多特征图滤波策略的成功推动下,类似的思想也被应用于人脸检测中,达到与当前水平相当的性能. 文献[8]对多通道映射中的像素差分关系进行建模,实现了快速准确的人脸检测.
与此同时,基于深度特征的方法[9-12]取得了巨大的性能提升,这得益于最近通用目标识别的进展. 深度特征表示在处理其他视觉任务时也非常有效,但依赖于极为昂贵的GPU和较高的计算复杂度.
2 方法的提出
2.1 像素差向量(PDV)
与局部二进制模式(LBP)编码方式相似,像素差向量的目的是建立局部区域中心像素与其相邻像素之间的关系. 如图1(a)所示,像素差向量是计算位于中心的锚像素ac与周边3×3邻域内像素ai(i=0,1,2,…,7)的差值.多尺度像素差向量是其一种扩展版本,为锚定像素引入了邻域半径r,用于表示不同尺度的像素局部统计信息.在图1(b)中,半径r=1 的邻域用蓝色高亮显示,半径r=2的邻域用黄色方块标注.对于单个半径r,仅对原始PDV可视化8个不同的方向.而对于W×H图像,可以提取不同锚像素(W-r)×(H-r)/(s×s),其中s表示步幅.每个半径为r的块共包含(2r+1)×(2r+1)像素.
2.2 像素差向量协方差特征(PDCF)
像素差分运算是一种一阶算子,可以有效地对局部块内的像素关系进行建模. 众所周知,高阶统计量具有更强的鉴别能力,可用于目标检测领域. 基于此,本文提出了一种像素差分协方差特征,利用PDV中不同分量之间的相关性,提升像素特征的表达能力. 协方差矩阵能够捕获共存的判别模式,有利于模式分类. 从直观上看,两种模式的相关性等共存模式比单一模式更具鉴别力. 具体而言,人脸具有特殊的对称结构和几何结构关系,如眼睛沿着鼻子对称,嘴总是在鼻子下面,面部区域几乎相同. 基于这些先验知识,本文设计了单半径和双半径PDV两种不同情形,分别如图2(a)和(b)所示.
这两个版本的PDCF旨在捕获具有相同或不同半径PDV的不同分量之间的相关性. 如图2(a)所示,对于(2r+1)×(2r+1)像素的图像块,4个分量分别表示为d1、d2、d3和d4.PDV的各分量在不同方向上得到了差分关系,反映了图像局部区域纹理的变化. 计算完PDV后,建立协方差矩阵来对PDV分量之间的相关性进行建模. 可以发现,不同半径的PDV捕获的纹理变化不同,会对人脸检测的性能产生影响.

图2 两种不同类型的PDCF方法Fig.2 Two different types of PDCF methods
2.2.1 单半径的PDCF(PDCF-S)
与计算协方差矩阵的步骤相同,PDCF-S建立在半径为r的PDV上. 如图2(a)所示,为清晰起见,本文只对PDV的4个分量进行了可视化. PDCF-S的目标是在相同大小的局部区域内建立不同元素之间的相关性,并在相同锚点像素下探索不同元素之间的关系. 通过计算协方差矩阵得到每个锚点像素的高阶统计量,可以有效捕获纹理信息. 此外,由于对称特性,PDCF-S特征的维度为(d2-d)/2,其中d通常设置为4或8.
2.2.2 双半径的PDCF(PDCF-D)
PDCF-D建立在多尺度PDV基础上,其中PDV有两个不同的半径r1和r2. PDCF-D的目的是探索不同尺寸的局部区域像素差之间的相关性. PDCF-D不仅可以捕获每个锚点像素处不同方位的差值,还可以接收到相同方位差值之间的相关信息. PDCF-D对PDCF-S具有互补效应. 如图2(b)所示,PDCF-D特征的维度为d2,高于PDCF-S特征.
2.3 复杂性分析
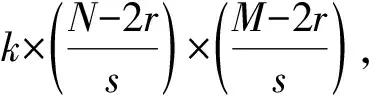
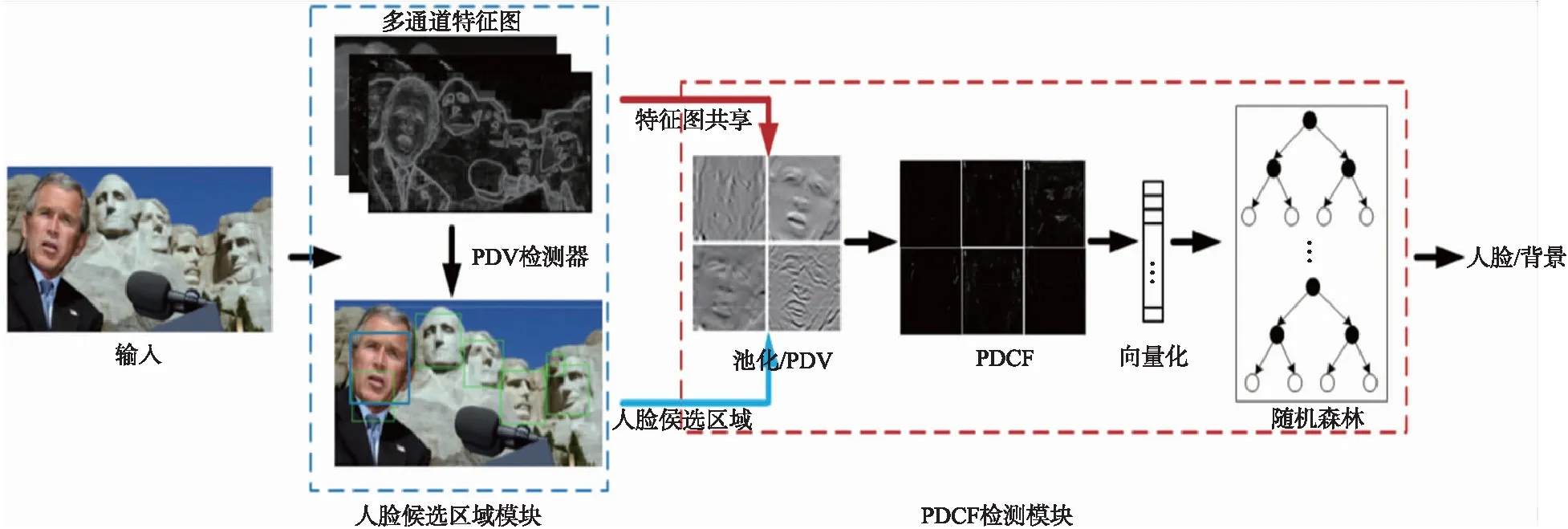
图3 人脸检测流程Fig.3 The process of face detection
2.4 检测框架
对于PDCF检测器的训练,可以按照流程,将PDCF集成到Boosting框架中. 与PDV方法不同,本文方法的PDCF在PDF层之后又增加了一个层. 为了提高人脸检测系统的速度,本文引入了级联结构,该方法在保证检测性能的前提下,能够降低计算复杂度. 整个检测流程如图3所示,其中人脸检测流程包括两个模块:人脸区域提取模块和PDCF检测模块. 前者基于PDV的检测器,运行速度快,召回率高. 后者为本文提出的PDCF检测器,利用PDV的高阶统计量对候选人脸进行细化,能够高效地去除误检.
首先,根据输入图像I计算多通道特征图F,用于计算差分像素特征和协方差特征. 这两种类型的特征都共享F,从而降低了模型的计算复杂度. 其次,利用PDV检测器生成人脸候选区域模块,从而获得疑似人脸区域集合. 对候选人脸区域进行池化并计算PDV特征,在此基础上进一步计算协方差特征并将矩阵展平成特征向量. 最后利用训练好的随机森林对输入的特征向量进行处理得到最终的决策结果. 由于PDV与PDCF相比计算复杂度低,因此适用于获取高质量的候选人脸特征;而利用高阶统计信息的PDCF具有更高的特征判别能力,可以用于过滤候选人脸集合中的困难样本,实现高效的人脸检测.
3 实验及讨论
3.1 实验设置
本文所采用的人脸数据集的详细信息如表1所示,实现的多视图人脸检测器在AFLW数据库上进行训练. 人脸窗口大小设置为80×80像素. 根据不同的侧视角度共训练了5个人脸检测器,分别代表(-INF,-60°]、(-60°,-20°]、(-20°,20°)、[20°,60°)和[60°,INF)的侧视角度区间. 每个视图的平均人脸如图4所示. 俯仰角和平面内旋转角度均限制在[-35°,35°]. 根据侧视角度,每个检测器的训练正样本数目分别为 3 949、8 818、19 724、8 818、3 949张,从PASCAL VOC2007数据集中收集了5 770张不包含人脸的图像作为负样本. 本文实现的检测器利用Boosting算法进行训练,最终每个检测器由2 048个弱分类器组成.
本文采用查准率和查全率曲线及平均查全率两种度量方法对公共数据集上的不同方法进行性能评价,利用文献[4]提供的工具箱进行实验评估.

图4 5种不同视图的平均人脸Fig.4 Average face of five different views

表2 PASCAL数据集上PDCF的参数寻优实验Table 2 Parameter optimization experiment of PDCF
3.2 关于PDCF的讨论
3.2.1 不同半径的参数选择
本节对不同半径的PDCF展开了详细的参数寻优实验,同时也对ACF[7]和PDV[8]两种经典方法进行了比较,具体结果如表2所示. 可以发现,合适尺寸的PDV半径对检测器的平均精度存在一定的影响. 当设置R=3像素时,深度3的决策树具有最高的精度. 采用这种设置的PDCF也明显优于ACF和PDV方法,说明了本文方法具有有效的特征表示能力. 此外,PDCF-S性能略优于PDCF-D,因此在接下来的实验中选择PDCF-S作为默认特征.
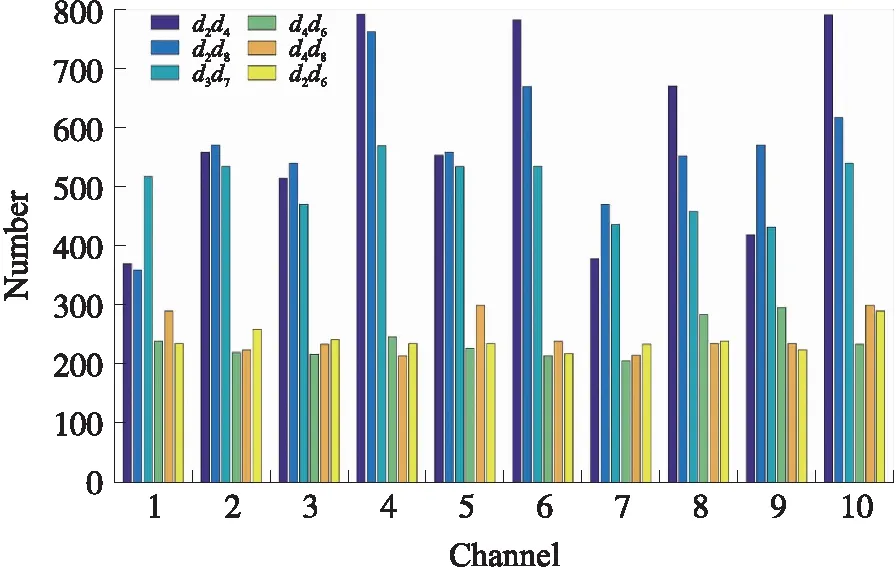
图5 PDCF特征分布分析Fig.5 Characteristic distribution analysis of PDCF
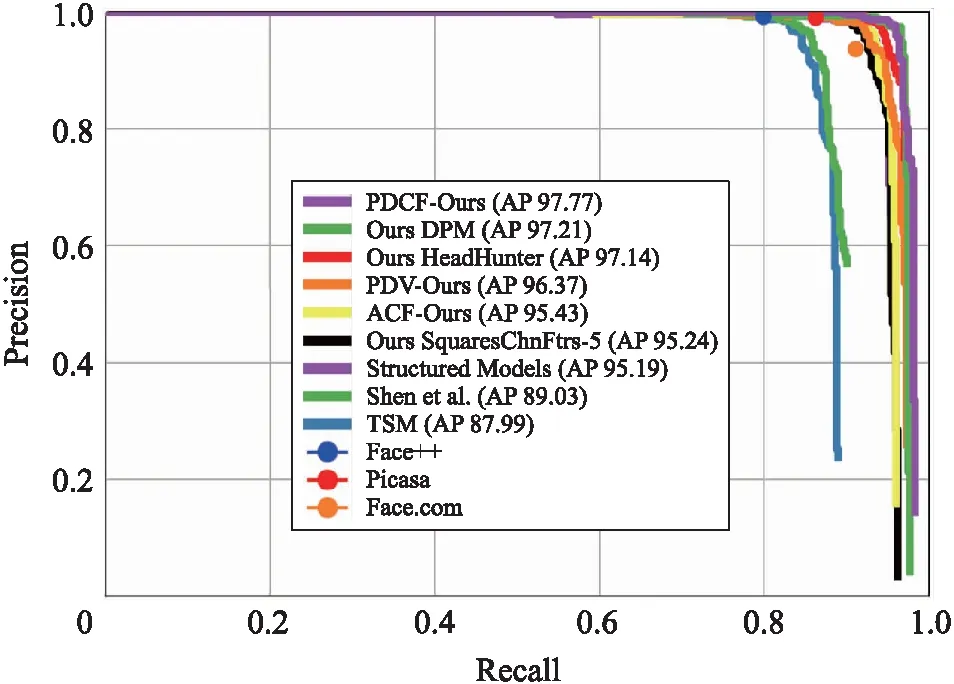
图6 AFW数据集上的对比实验Fig.6 Comparative experiment of AFW dataset
3.2.2 PDCF的分布分析
图5所示为检测模型参数训练中每个通道前 6个学习所得特征的可视化表示. 并不是PDCF的每个特性维度都同等重要,Adaboost算法对d2d4、d2d8和d3d7这3个特征分量选择的频率较高,其他分量的选择频率相对较低. 这说明在模型训练中,PDV在水平和垂直方向上的不相邻元素和对称分量更受青睐. 同时还可以观察到,通道4(梯度大小)、通道6(梯度方向为30°)和通道10(梯度方向为150°)的特征选择优先级高于其他通道特征.
3.3 与主流方法的对比实验
将本文方法在两个公共数据集上与其他主流方法进行比较实验,本文方法记为 PDCF-Ours. 实验采用与PDV-Ours 和ACF-Ours相同的实验设置,以保证公正性.

图7 PASCAL数据集的结果Fig.7 Results of PASCAL dataset
3.3.1 AFW数据集的对比实验
从图6和表3可以看出,本文方法在所有特征中mAP性能表现最优,分别比DPM和HeadHunter方法高出了0.56%和0.63%. 此外,PDV-Ours和ACF-Ours这两个基础算法也具有较好的性能表现,比SquaresChnFtrs-5分别高出了1.13%和0.19%. 在训练数据和参数设置相同的情况下,PDCF-Ours的性能比PDV-Ours和ACF-Ours分别高出约1.4%和2.34%,从而验证了本文方法的有效性. 此外,本文方法与当前先进的深度学习方法[10,12]相比仍有一些差距,但略优于Faceness-Net方法[9]. 由于深度学习模型依赖于额外海量的数据用于模型预训练,还需要高端的GPU进行并行处理,而本文方法属于经典机器学习方法,具有模型复杂度低的特点,对设备算力和功耗的要求会大大降低.

表3 AFW数据集上经典机器学习模型与深度学习模型的平均精度比较Table 3 Comparison of average accuracy between classical machine learning model and deep learning model on AFW dataset
3.3.2 PASCAL数据集的对比实验
PASCAL人脸数据集的实验结果如图7所示. 在mAP方面,本文方法的性能明显优于SquareChnFtr、Structured Model和ACF方法,性能提升达到了4.87%、6.57%和8.59%,也分别比DPM、HeadHunter和PDV方法分别高出约0.15%、0.81%和2.82%. 因而,本文提出的PDCF方法在两个公共数据集上均优于其他基于手工设计的特征. 这一结论也与AFW数据集上的评测结果一致.
如表4所示,本文方法与当前先进的深度学习方法相比尚有较大的差距,最新的RetinaFace方法在该数据集上精度达到了99%以上,而基于FasterRCNN模型的STN方法和Faceness-net方法比本文方法的平均精度分别高出3.66%和1.67%.

表4 PASCAL数据集上经典机器学习模型与深度学习模型的平均精度比较Table 4 Comparison of average accuracy between classical machine learning model and deep learning model on PASCAL dataset
3.4 检测结果比较
AFW和PASCAL数据集的图片检测结果如图8所示. 可以发现,本文的检测器在两个公共数据集的精度和召回率方面表现得非常好. 此外,在手和下巴处存在一些误检,对于漏检场景主要归因于图像中存在的遮挡和模糊问题.

图8 AFW和PASCAL数据集上的检测结果Fig.8 Test results on AFW and PASCAL datasets
3.5 运行时间比较
表5为640×480像素的输入图像在不同检测窗口尺寸下的运行时间比较. 3种方法均使用相同的训练数据,在相同的实验平台上(DELL T7610服务器,双16核CPU 2.6 GHz,内存64G)运行. 在窗口大小为80×80和40×40像素的情况下,PDV方法比ACF和PDCF方法有更快的运行速度. 此外,PDCF方法具有高辨别能力,但同时也提高了计算复杂度,因此略慢于ACF方法,但该方法可滤除图像中大部分的困难负样本. 引入PDV方法作为人脸候选区域提取,可以较好地平衡检测器的精度和速度,最终检测速度可达20帧/s.

表5 640×480图像的运行时间比较Table 5 Runtime comparison of 640×480 images
4 结论
依赖于PDV高阶统计信息的高判别能力,本文提出了一种用于多视角人脸检测的像素差向量协方差特征,该方法有效地扩展了像素差向量特征的一阶统计特性,提升了特征表达能力,提高了多视角人脸检测的性能,实现了一种基于人脸后续区域提取的实时多视角人脸检测系统,对人脸姿态变化具有较强的鲁棒性.
此外,本文引入人脸区域候选模块,可进一步提升检测速度,在不使用GPU加速的情况下,处理分辨率为640×480的图像时,处理速度可达20帧/s,非常适合于部署在低功耗边缘计算设备上.
