基于互信息与支持向量回归的盾构掘进载荷预测方法研究
2022-07-05刘尚林杨凯弘周思阳
周 皓,刘尚林,杨凯弘,周思阳,张 茜
(天津大学机械工程学院,天津 300350)
盾构是一种用于地下隧道掘进的机械装备,能够进行隧道一体成型的工厂化作业,具有重型巨载、结构复杂等特点[1]。掘进载荷是在施工过程中装备控制的重要指标,其主要包括掘进总推力和刀盘扭矩。掘进总推力即为推动盾构向前的动力,刀盘扭矩则使刀盘不断旋转而对土体进行切削破坏。掘进载荷如果调控不当,不仅会影响切削破坏效果,还可能给盾构带来额外损伤,甚至可能引起工程事故,造成经济损失和人员伤亡。因此,正确预测掘进载荷是预估和优化盾构施工时间及成本的重要基础[2-3]。
盾构的掘进是机械装备与周围地质不断作用的过程,受到地质条件、操作参数等众多因素的耦合影响[4],这给掘进载荷的分析造成了一定的困难。在施工过程中所记录的工程实测数据包含了大量运行信息[5],是分析盾构掘进规律的重要信息基础[6]。许多学者利用工程实测数据建立反演回归模型对掘进参数进行了分析。例如:Zhang等[7]利用工程实测数据建立了掘进比能的反演识别模型;郑峥[8]基于工程实测数据进行残差分析,并通过时序分析方法对残差建模,以修正掘进推力的预测模型;褚东升[9]在分析掘进参数相关性的基础上,以掘进速度、总推力、土仓压力和刀盘转速为自变量,建立了刀盘扭矩的经验模型;Song等[10]综合考虑了地质参数、掘进参数和刀盘结构参数对刀盘扭矩的影响,结合实测数据,采用多元非线性回归方法建立了刀盘扭矩的预测模型,并通过对实测数据的统计分析,提出了基于马尔科夫决策的载荷规划;张志奇等[11]统计了不同地质分段的盾构掘进参数,开展了针对盾构掘进速率和刀盘扭矩的多元回归分析,得到了适用于复杂地层的掘进参数回归模型,而胡祥涛等[12]基于实测数据验证了该回归模型的准确性,并对刀盘扭矩进行预测;Avunduk等[13]基于积累的现场实测数据,利用多元回归分析了各种软土参数对掘进总推力和刀盘扭矩的影响;Sun等[14]利用随机森林方法,根据地质参数和掘进参数来预测盾构掘进的动态载荷;Gao等[15]利用时序神经网络建立了对推力、扭矩等关键参数的实时预测模型。综上可知,目前利用工程实测数据对掘进载荷进行分析和建模预测的相关工作主要是基于工程经验考虑掘进速度、刀盘转速、土仓压力等若干核心参数对掘进载荷的影响。然而在盾构掘进过程中影响掘进载荷的因素种类繁多,因此,有效地挖掘工程实测数据,分析众多影响参数对载荷的敏感度,建立适用于盾构数据特征的机器学习模型,是掘进载荷分析与预测的重要研究内容。
本文建立了一种基于工程实测数据分析的掘进载荷特征选择及预测方法。首先,对原始工程实测数据进行极值归一化预处理,以降低不同参数间量纲和量级的差异带来的支配性影响;其次,对在掘进过程中实时记录的众多影响因素进行分析和筛选,并采用互信息算法选择对掘进载荷影响较大的若干主要参数作为输入;接着,采用支持向量回归(support vector regression,SVR)方法提取掘进参数间的非线性耦合关系,对掘进载荷进行预测建模;最后,以采用土压平衡式盾构施工的天津地铁9号线工程为例,对本文建立的方法进行讨论和验证,比较并分析掘进载荷特征选择方式对模型预测表现的影响。
1 基于工程实测数据分析的掘进载荷特征选择及预测建模
本文提出的掘进载荷的分析和预测建模方法主要包括以下3步:1)为了降低盾构工程实测数据中不同参数间量纲和量级的差异带来的支配性影响,对数据进行极值归一化预处理;2)采用非参数检验方法中的互信息算法筛选出对掘进载荷较为敏感的关键参数作为输入特征;3)采用SVR方法对掘进载荷进行预测建模。
1.1 数据预处理
在盾构掘进过程中实时记录有关机器运行的众多信息,如油缸推力、刀盘转速、掘进速率、导向姿态和密封舱压力等。这些不同类别的工程参数的量纲各异,且数值量级差距也十分悬殊。例如,掘进总推力可达上万kN,而掘进速率往往仅为几十mm/min,而它们都是表征机器运行状态的重要因素。
考虑到大多数特征选择及机器学习算法并不具有伸缩不变性,为了防止在数据挖掘时由于数值量级上的差异而可能使某些参数起到支配性的作用,在进行数据分析前须对所有参数进行极值归一化处理,即:

式中:xpre为归一化处理后的无量纲参数;x为归一化处理前的原始数据;xmin为该参数原始数据中的最小值;xmax为该参数原始数据中的最大值。
极值归一化处理可以将有量纲的参量无量纲化,并将值映射至0~1的区间,使得在后续分析中不同量纲和量级的参数能够尽可能地被平等对待,此外,在实际求解时还有利于提升收敛速度及效果。
1.2 特征选择
由传感器采集的工程实测数据包含众多工程参数,而根据工程经验,只须选择关键性的装备性能参数和地质参数用于数据分析[16-17]。因此,为了充分挖掘不同参数与掘进载荷间的变化规律,实现有效的掘进载荷预测,须合理、准确地选取对掘进载荷变化较为敏感的参数作为后续机器学习的输入特征,即特征选择。通过特征选择,可以从众多参数中剔除冗余参数,保留关键特征,以降低模型的复杂度,有利于增强预测效果,降低经验风险。
工程数据往往不服从已知常见的数据分布形式,且它们通过组合的方式对目标变量产生影响[18]。因此,本文采用互信息算法进行特征选择。
互信息是信息论中一种有用的信息度量,它被认为是在一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不确定性[19]。对于2个连续随机变量X、Y,其互信息I为[20]:
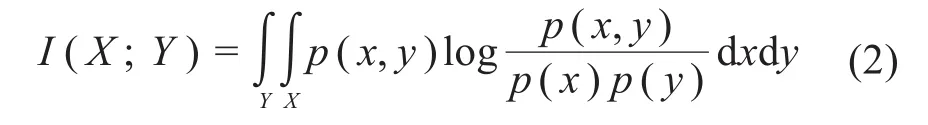
式中:p(x,y)为自变量X和因变量Y的联合概率密度函数;p(x)和p(y)分别为X和Y的边缘概率密度函数。
如果2个变量完全独立,则它们的互信息值为0;互信息值越大,2个变量越不独立,则自变量X更可以作为因变量Y的特征[21]。相较于相关系数等相关性评价指标,互信息的优势在于非参数检验,不要求数据服从特定的已知分布,能更加普适地度量2个变量之间的相关程度,因此适合对关系复杂、分布不明的盾构掘进参数进行特征选择。
1.3 SVR方法
在盾构掘进过程中影响掘进载荷的参数众多,并且参数间的影响呈现复杂的非线性关系。对于此类高维非线性的数据分析问题,为了达到较高的模型精度,学习模型所需要的样本量与特征维度呈指数增长关系,因而对于特征维度高的数据,样本量往往显得不足[22]。SVR作为一种基于统计学理论的机器学习方法,在处理样本量少的非线性数据回归问题时有独特的优势[23-24]。该方法的计算复杂度取决于支持向量的数目,在一定程度上避免了高维样本带来的维数灾难,而灵活的核函数技巧使得该方法能够较为优秀地解决盾构掘进参数间的非线性关系问题。同时,工程实测数据由于在采集时受到工作环境和数据传输的影响,不可避免地含有噪声和离群值[25-26],而采用SVR方法建模时无须依赖整个训练集,仅需少数样本点作为支持向量即可确定预测模型,对噪声和离群值具有一定的鲁棒性[27]。
SVR的基本思路是寻找一个样本空间中的超平面作为预测方程[28],使得若干样本点到该平面的距离最小,而支持向量为距离超平面最远的点。SVR算法如图1所示。
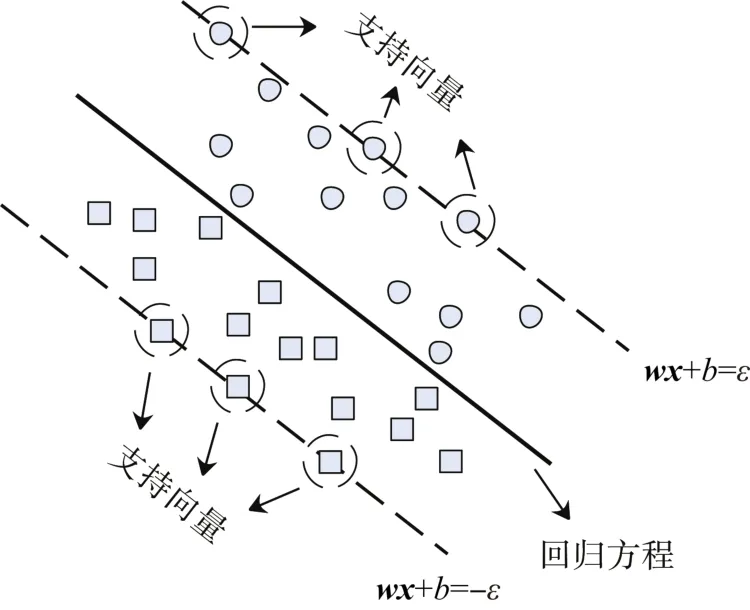
图1 SVR算法Fig.1 SVR algorithm
因此,SVR算法的优化依据即为通过式(3)计算得到的样本点距离该超平面的距离。在非线性问题下,SVR算法通过核函数将原始训练样本映射到更高维中,在扩维后的样本空间中进行计算。
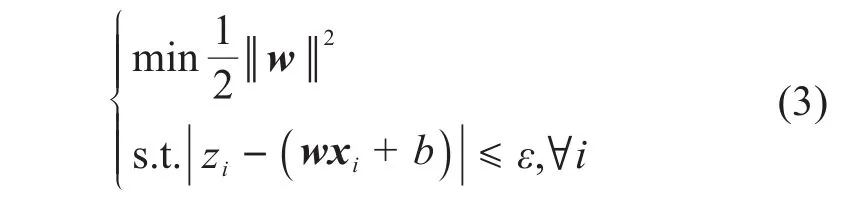
式中:w为权重向量;b为偏置项;ε为偏差;xi为第i个输入向量;zi为目标值。
将经过极值归一化预处理并通过互信息方法筛选出的参数作为输入,利用SVR方法构建掘进载荷预测模型,对掘进总推力和刀盘扭矩进行预测。其预测流程如图2所示。
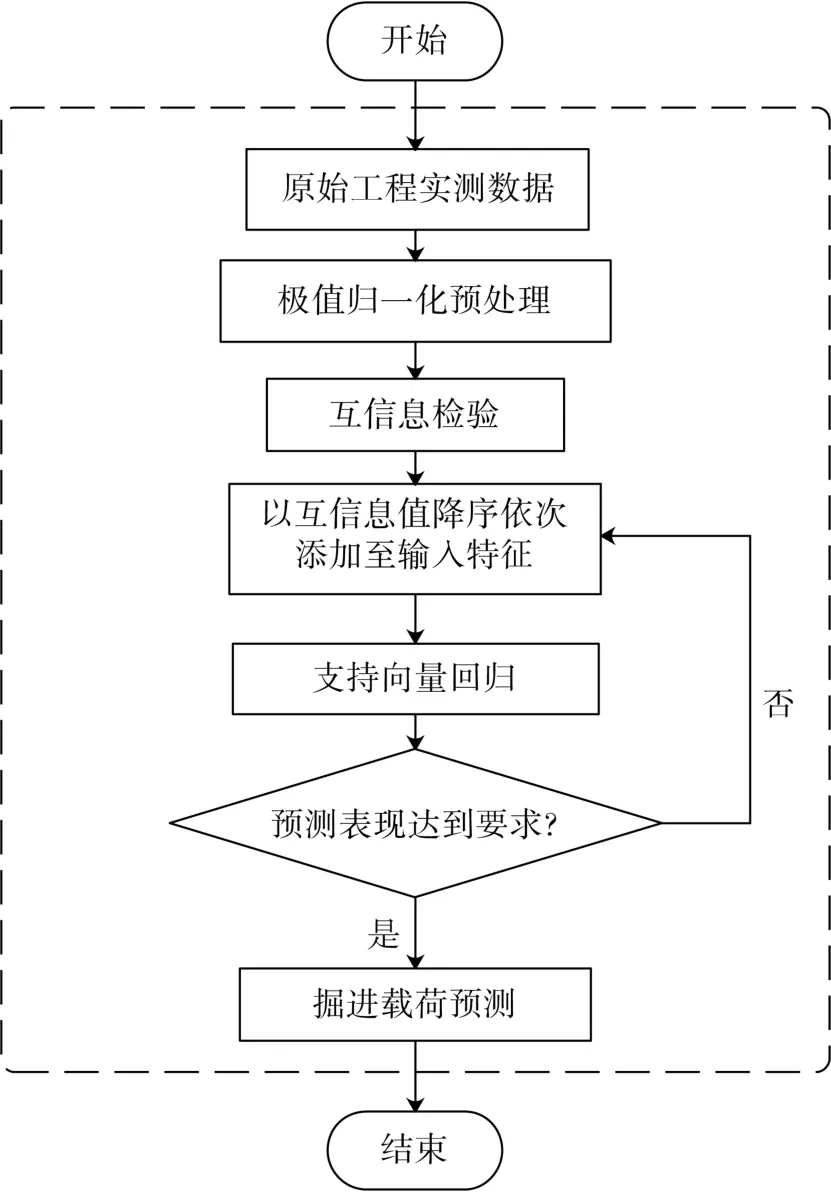
图2 掘进载荷预测流程Fig.2 Predicting process of driving load
2 工程实例
利用所构建的盾构掘进载荷预测方法,对在天津地铁9号线隧道某标段约960环(每环约1.2 m)施工区间所采集的工程实测数据进行分析。该施工区间的地质主要为黏土和粉土等软土,记录的原始数据包含334个参数。对原始数据进行类别及特征分析,首先剔除对掘进载荷预测无明显关联的参数,包括开关类状态参数,常数类参量及与掘进载荷明显不相干的参数如记录时刻、环号、千斤顶选择时间等。获得初步约简后的特征子集,其包含90个特征参数。盾构施工中的部分主要参数如表1所示。

表1 盾构施工中的部分主要参数Table 1 Some main parameters in shield construction
原始数据初筛后的子集仍包含较多特征,因此进一步采用互信息方法进行特征选择。在高维特征的分析中,须综合考虑训练精度、计算成本及可能的过拟合等问题,选取适当个数的特征作为回归模型训练的有效输入。因此,首先就不同特征选取数对掘进载荷预测效果的影响进行讨论。
回归问题的常见评价指标有决定系数R2、平均绝对误差MAE和均方误差MSE,其计算表达式分别如式(4)至式(6)所示。

式中:yi为实测值为预测值为实测均值;n为样本数。
通过R2随特征数的变化情况来选取最终的特征个数,然后按照互信息计算得到的排序结果依次添加特征参数作为输入。同时考虑计算和特征获取的成本、算法训练复杂程度等因素,确定最优输入特征。
采用互信息方法对特征排序后,R2随特征数的变化曲线如图3所示。由图可知,掘进总推力和刀盘扭矩训练模型的R2均基本逐步上升,最终达到稳定的状态,具有较好的预测表现。当输入特征数达到15个左右时,R2均达到0.8以上,预测效果较优。此后,随着输入特征数的增多,R2虽有增大但增长缓慢。当输入特征数达到55个时,R2已经接近最大值,约为0.9。
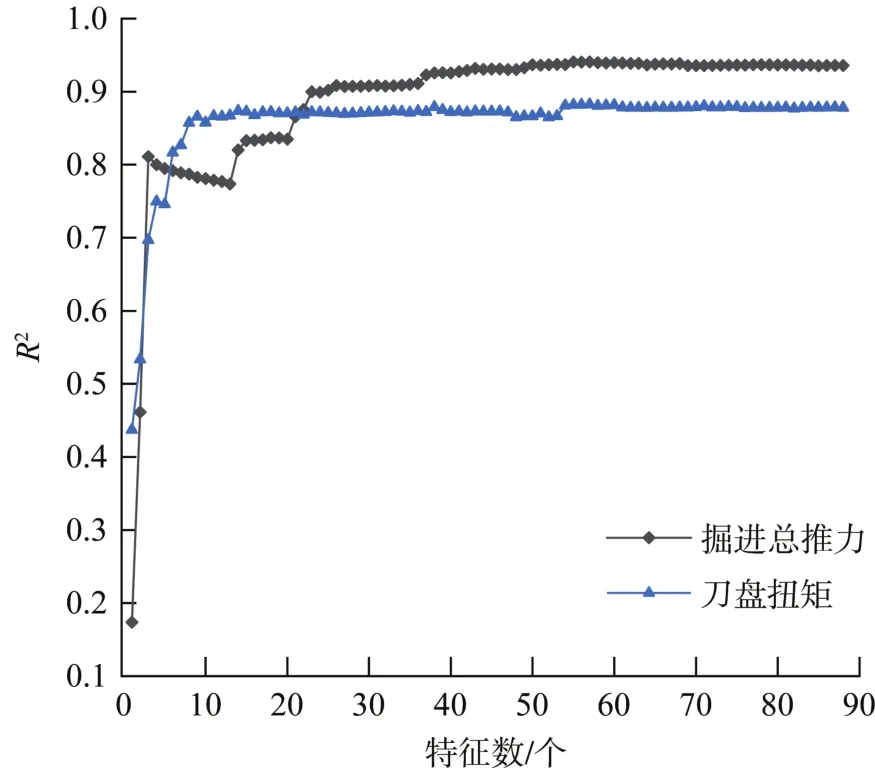
图3 R2随特征数的变化曲线Fig.3 Variation curve ofR2with the number of characteristics
根据实测数据互信息分析结果给出了该工程中对掘进总推力和刀盘扭矩的预测较为敏感的15个排序靠前的特征参数。掘进载荷与各特征参数之间的互信息分析结果如表2所示。由表2可知,掘进总推力与注浆上限、掘进速度、盾构掘进姿态参数等较相关;刀盘扭矩与电气参数、注浆参数等较相关。
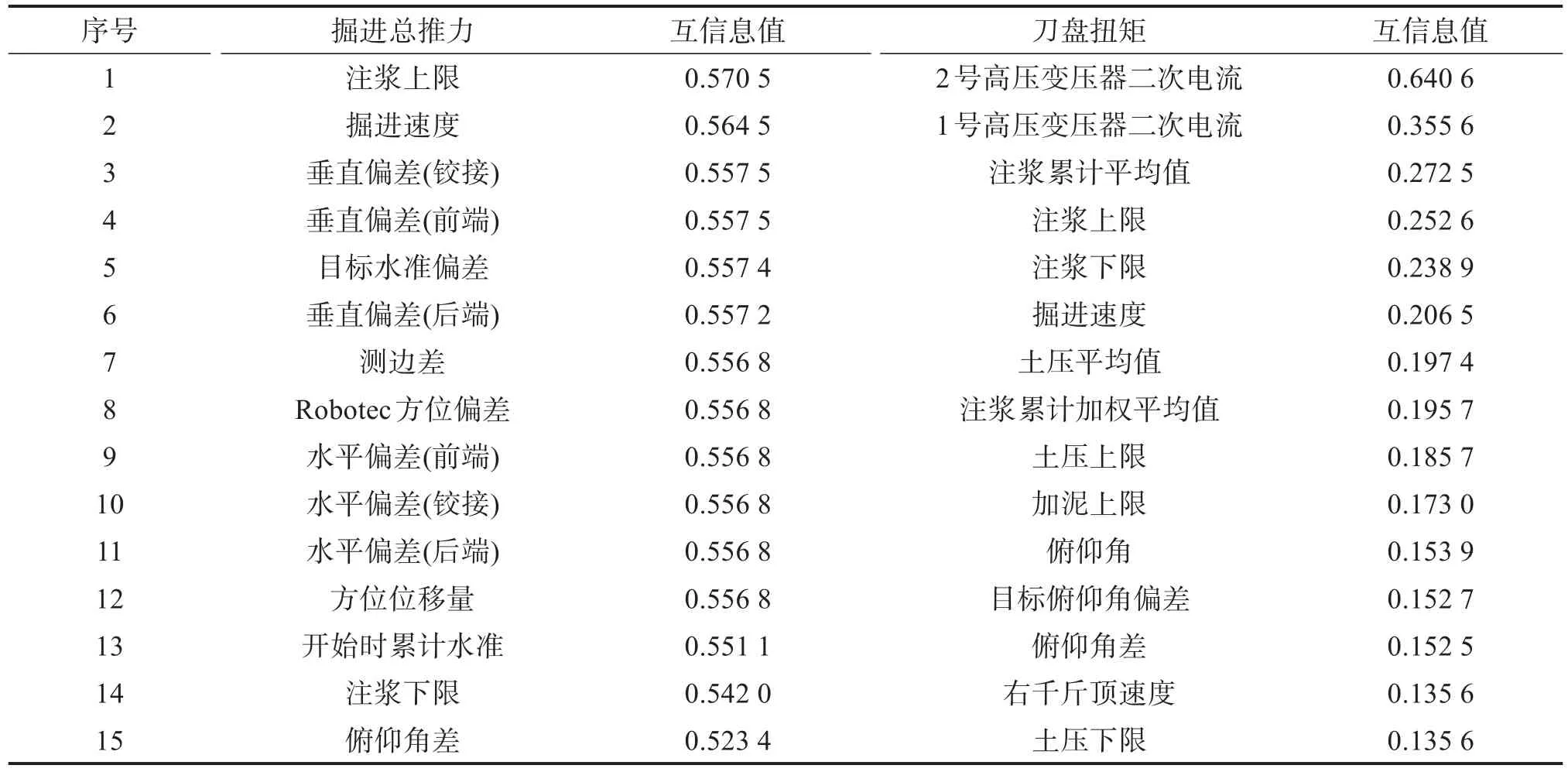
表2 掘进载荷与各特征参数之间的互信息分析结果Table 2 Mutual information analysis results between driving load and feature parameters
为了进一步验证所建立的特征选择与预测建模方法的准确性,将天津地铁9号线盾构施工工程中预留的独立数据验证集用于检验模型预测效果。该数据集未参与模型的训练过程。当输入特征数为15和55个时掘进总推力和刀盘扭矩的实测值与预测值的对比分别如图4和图5所示。图中同时给出了R2、MAE和MSE的值。由图可知,掘进总推力、刀盘扭矩实测值与预测值的变化趋势基本一致,说明选择互信息分析结果中排序靠前的少量参数作为敏感特征并用作模型的输入是合理的。特征数的增多在一定程度上有助于提升模型预测性能,但同时会导致模型复杂度、计算时间和成本增大。因此,在实际建模时,可根据需求确定特征数,平衡特征维度与准确度的关系。
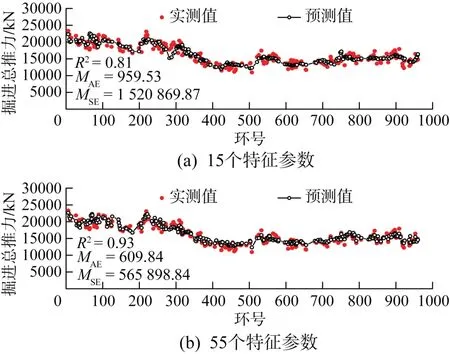
图4 掘进总推力实测值与预测值的对比Fig.4 Comparison between measured value and predicted value of total driving thrust
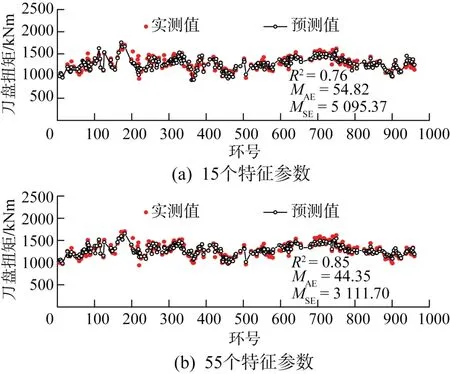
图5 刀盘扭矩实测值与预测值的对比Fig.5 Comparison between measured value and predicted value of cutter head torque
上述研究表明,所建立的基于互信息的特征选择与SVR相结合的盾构掘进载荷预测方法能够从工程实测数据的众多特征中筛选出对掘进总推力和刀盘扭矩较为敏感的参数作为输入特征,来对掘进总推力和刀盘扭矩进行合理、准确的预测。
3 总结
本文围绕盾构施工工程中实测数据分析与掘进载荷预测问题,建立了一种基于互信息的特征选择与SVR相结合的掘进载荷预测方法。对实测数据进行极值归一化预处理,基于互信息计算分析各类参数对掘进载荷影响的敏感度,确定适当的输入特征子集,并通过SVR方法对掘进总推力和刀盘扭矩进行建模预测。结合天津地铁9号线盾构施工工程的实测数据进行了掘进载荷的计算与分析,验证了所提出预测方法的合理性和有效性,并分析了特征数变化对掘进总推力和刀盘扭矩预测表现的影响。结果表明,通过互信息方法选取的少量特征可以建立相对较优的SVR回归模型,当输入特征数逐渐增多时,预测性能逐步上升并达到稳定状态。研究结果为盾构掘进载荷的预测提供了一种思路,也为具有高维、多参量非线性耦合等特点的工程实测数据的分析提供了参考。
