基于特征过滤和PCA降维的混合特征选择方法*
2022-07-04莫云郭岩莫禾胜路仲伟张绍荣
莫云 郭岩 莫禾胜 路仲伟 张绍荣
1 桂林航天工业学院 电子信息与自动化学院,广西 桂林 541004;2 桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004
运动想象脑电属于自发脑电,信号维度高、信噪比低、随机性强[1]。因此,在脑电特征提取过程中通常包含噪声和冗余信息。特征选择可以有效剔除无效信息,选择更加稳定和更具判别性的特征[2]。另外,特征选择可以有效降低特征维度,简化分类模型的复杂度,从而缓解过拟合问题和减少模型训练时间。所以,特征选择是脑电解码非常重要的环节。
现有的特征选择方法通常从两个方面进行划分。第一,从有无监督的角度,现有特征选择方法可以分为有监督、无监督和半监督[3]。有监督特征选择方法一般使用标签信息对特征进行选择,所以其后续的分类效果比较好。无监督特征选择方法主要通过聚类方法实现。当标签数据获取比较困难时,半监督方法是较好的选择。第二,从选择策略考虑,特征选择方法可以分为过滤式、包裹式、嵌入式以及混合特征选择方法。在前期的研究工作中,我们对这些特征选择方法做了较为详细的论述[4]。过滤式、包裹式和嵌入式在脑电特征选择的应用比较常见,包括基于Fisher判别准则[5]、互信息[6]等度量标准的过滤式方法,基于人工蜂群[7]、差分进化算法[8]等搜索策略的包裹式方法,基于最小绝对值收缩和选择算子(Least Absolute Shrinkage and Selection Operator, LASSO)、组LASSO和稀疏组LASSO[9]等稀疏约束的嵌入式方法。混合特征选择方法在脑电特征选择的应用比较少见。应用于其他领域的混合特征选择方法大多基于遗传算法和粒子群算法等智能优化方法[10],模型参数调优比较复杂,模型训练时间长,而且容易得到局部最优解。
针对运动想象脑电的特征选择问题,本文提出计算量少、模型简单且高效的混合特征选择方法,即基于过滤式特征选择和主成分分析(Principal Component Analysis, PCA)特征降维的混合特征选择方法。第一步,特征提取。使用滤波器组(Filter Bank, FB)对原始脑电信号进行带通滤波,之后使用0.5~2.5 s时间窗提取单试次数据,最后对每个时-频分割进行共空域模式(Common Spatial Pattern, CSP)特征提取。第二步,空-频特征选择。分别使用方差、相关系数和Relief算法对特征进行排序,之后对选定的特征子集进行PCA变换,最后结合Fisher线性判别分析(Fisher Linear Discriminant Analysis, FLDA)和10折交叉验证选择最优的特征个数和主成分个数,并训练最优的模型参数。第三步,特征分类。对于新的测试样本,先进行特征选择然后进行PCA降维,最后使用训练模型进行分类预测。使用第三次脑机接口(Brain-Computer Interface, BCI)竞赛的数据集IIIa以及第四次BCI竞赛的数据IIa验证所提出方法的有效性。
1 方法
1.1 特征提取
FBCSP方法[11]使用滤波器组把原始的多通道脑电信号滤波成多个频率子带,然后对每个子带的脑电数据进行CSP变换,并提取对数方差特征。接着把每个子带的CSP特征级联成一个特征向量,再使用特征选择方法选择最优的频带特征,最后使用分类器对选择得到的特征子集进行分类。FBCSP是从多个频率子带中找到最具判别性的CSP特征,从而弥补了CSP的频域信息。FBCSP方法的数据处理流程如图1 所示。

图1 FBCSP方法的数据处理流程图片来源:修改自文献[11]。
经过长时间的发展,FBCSP方法已经不完全特指文献[11]中的方法,而是泛指基于滤波器组的一类CSP方法[12]。本文对FBCSP方法中的特征选择进行了改进和优化。
1.2 过滤式特征选择方法
过滤式特征选择方法的数据处理过程如图2所示。先通过相关的度量准则对特征的重要性进行降序排序,然后选择前K个特征进行分类。K的取值从1到P,其中P为特征维数。使用训练集,针对不同的K值,结合FLDA分类器和10折交叉验证计算其交叉验证准确率。将最高交叉验证平均准确率对应的前K个特征作为最优特征子集,并使用该特征子集训练FLDA模型参数。本文分别使用方差、相关系数和Relief算法对特征进行排序,下面将详细介绍这三种方法进行特征排序的过程。
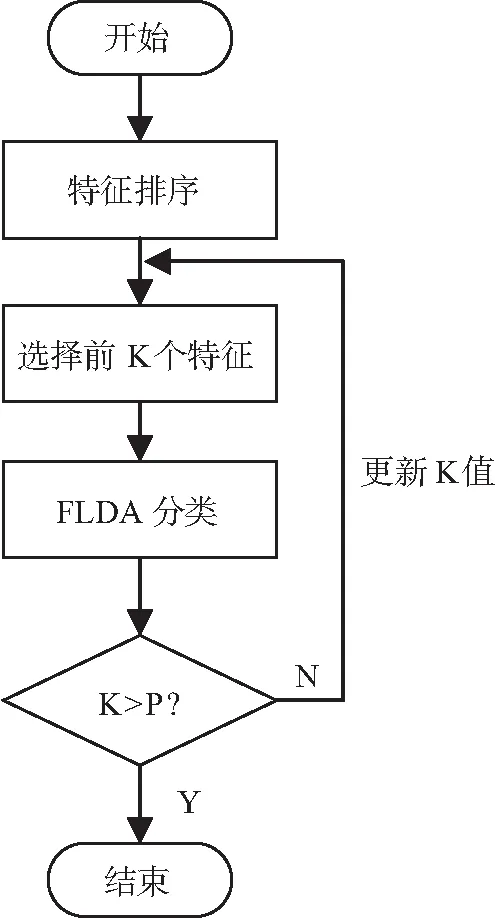
图2 过滤式特征选择方法的数据处理过程
1.2.1 方差特征排序
方差的大小反映了特征变化的情况,方差比较大说明特征的取值变化较大,其包含的信息较多。我们认为变化的特征对分类预测有用,变化很小甚至不变的特征对分类预测没有影响。因此,方差越大,特征越重要。假设X∈N×P为样本矩阵,其行代表一个样本,其列代表一维特征,N表示样本个数,P表示特征维数。xi∈P表示第i个样本,i=1,2,…,N。方差的计算公式如下:
(1)

1.2.2 相关系数特征排序
皮尔逊相关系数(Pearson Correlation Coefficient, PCC)衡量特征与样本标签的相关性,其取值范围为-1~1。相关系数的绝对值越大,特征与标签的相关性越大,特征对分类预测的作用也越大。在特征排序时,先计算特征的相关系数,然后取其绝对值,按绝对值的大小进行降序排序。假设y∈N表示标签向量;yi∈{-1,1},表示标签向量的第i个取值,(i=1,2,…,N)。则特征与标签的相关系数计算如式(2):
(2)
其中:x(:,j)表示所有特征样本的第j列特征,cov(·)表示协方差运算,σ表示标准差。
1.2.3 Relief特征排序
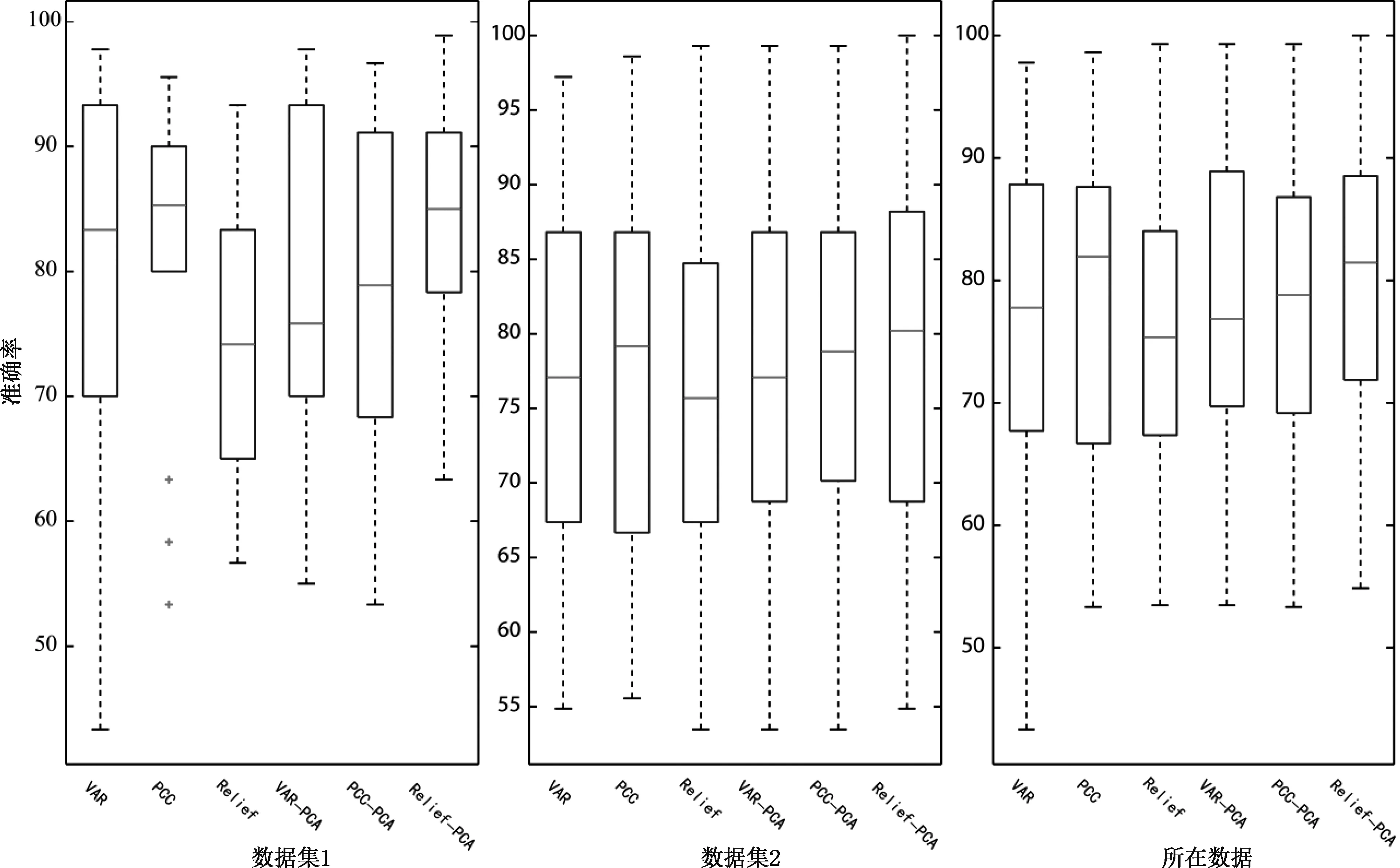
Relief根据特征与样本标签的相关性来权衡特征的重要性,但是其特征权重的计算过程与PCC不同。使用Relief算法计算特征权重的原理如下:首先从训练集中随机选取一个样本x;然后选取与x同一类别的k最近邻样本并计算样本x与它们之间的距离,记为d1;接着选取与x不同类别的k最近邻样本并计算样本x与它们之间的距离,记为d2。如果d1 基于特征过滤和PCA降维的混合特征选择方法的数据处理过程如图3所示。该混合特征选择方法是在过滤式特征选择方法的基础上加入特征降维。具体就是在方差、相关系数和Relief进行特征排序之后,选择前K个特征进行PCA变换。结合FLDA分类器和10折交叉验证选择最优的特征个数和主成分个数,也即寻找特征选择和特征降维的最优组合。在图3中,q表示选择前q个主成分,M表示主成分个数。 图3 混合特征选择方法的数据处理过程 在FLDA模型训练的求解过程中,如果训练样本的数量小于特征样本的维度,类内散度矩阵会变得奇异而不能求逆,影响模型求解的稳定性。为了避免类内散度矩阵奇异,在本文中我们在传统的FLDA模型中加入了l2范数约束,具体如式(3): (3) 其中:w为投影向量,SB表示类间散度矩阵,SW表示类内散度矩阵,更多详细信息请参考文献[14]。在本文中,λ=10-4。 数据集1:第三次BCI竞赛的数据集IIIa。该数据集包含60个电极通道,采样率为250 Hz。该数据集提供了3个健康被试的数据,被试运动想象任务包括左手、右手、脚和舌头。由于本文只处理二分类数据,因此对4种任务进行排列组合得到6个二分类数据子集。其他详细信息可以参考文献[15]或者BCI竞赛官方网站:http://www.bbci.de/competition/iii/。 数据集2:第四次BCI竞赛数据IIa。该数据集包含22个电极通道,采样率为250 Hz。该数据集提供了9个健康被试的数据,与数据集1类似,每个被试都执行左手、右手、脚和舌头四类运动想象任务。二分类数据子集处理与数据集1一样。其他详细信息可以参考文献[4]或者BCI竞赛官方网站:http://www.bbci.de/competition/iv/。 在本文中,使用FBCSP方法[11]进行特征提取,带通滤波器选择6阶的巴特沃斯(Butterworth)滤波器,CSP空间滤波器对数选择m=3。在训练和测试阶段,分类器都为FLDA。参与比较的过滤式特征选择方法包括VAR(方差)、PCC(皮尔逊相关系数)和Relief,参与比较的混合特征选择方法包括VAR-PCA、PCC-PCA和Relief-PCA。 表1给出了数据集1的分类结果。数据集1经过排列组合后一共得到6种二分类任务,每种二分类任务有3个被试,由于空间有限,只把每种二分类的平均分类准确率给出。在表1中,L、R、F、T分别表示左手、右手、脚、舌头运动想象任务,L vs R表示左手和右手的二分类任务。每种二分类任务的最高平均分类准确率加粗显示。从表1可以看出,在过滤式特征选择方法中,PCC方法的分类效果较好,有3种二分类任务取得最高平均分类准确率;在混合特征选择方法中,Relief-PCA方法的分类效果较好,同样有3种二分类任务取得最高平均分类准确率。 表1 各种二分类任务的分类准确率(数据集1) 表2给出了数据集2的分类结果。与数据集1类似,数据集2也有6种二分类任务,但是每种二分类有9个被试。在表2中,Relief-PCA方法的分类效果显著优于其他方法,有5种二分类取得最高的平均分类准确率。在过滤式特征选择方法中,PCC方法的分类效果仍然较好。 表2 各种二分类任务的分类准确率(数据集2) 为了更好地体现两个数据集的整体分类效果,表3给出了所有数据的平均分类准确率。从表3可以看出,Relief-PCA方法的分类效果显著优于其他方法。另外,Relief-PCA方法的标准差也比较小,说明该方法的稳定性和鲁棒性较好。Relief方法的分类效果不佳,但是与PCA结合之后分类效果显著提高。PCA对VAR方法的分类效果具有一定提升,但是PCC与PCA结合后分类效果有所下降。 表3 平均分类准确率(所有数据) 为了更直观地比较各种特征选择方法的分类效果,图4给出了不同数据集使用各种特征选择方法取得的平均分类准确率。从图4可以明显看出,Relief-PCA方法的分类效果最佳,其次是PCC方法。 图4 平均分类准确率(所有数据) 图5给出了所有被试分类准确率的整体分布。从图5可以看到,PCC和Relief-PCA方法的分类准确率中值(图5中长方形里面的“—”符号)比较靠上,但PCC方法在数据集1的分类结果中存在几个异常值(图5中“+”符号)。Relief-PCA方法的最大值(图5中上边虚线的最高点)最优,最小值(图5中下边虚线的最低点)也优于其他方法。这些结果再次证明了Relief-PCA方法的有效性。 图5 分类准确率整体分布 通过以上的结果分析和比较,我们发现PCA对不同过滤式方法的改进效果不一致。PCA对VAR方法的改进效果较小,对PCC方法的改进效果变差,对Relief的改进效果比较显著。PCC-PCA方法效果不佳,可能是因为PCC方法已经考虑了特征与样本标签的相关性,而PCA的引入可能破坏了原有的相关性。 本文的初步研究结果为我们后面的研究工作指明了方向,我们将研究更多的过滤式方法与PCA结合的效果,以及过滤式方法与其他PCA版本(比如核PCA和概率PCA等)结合的效果。 本文提出了基于特征过滤和PCA降维的脑电特征选择方法。通过过滤式特征选择方法与PCA降维的结合,探索有效的混合特征选择方法,提高运动想象脑电解码的性能。本文最核心的思想是同时考虑特征的重要性以及它们之间的相关性。在实验过程中,我们比较了过滤式方法与本文所提出方法的分类结果,包括VAR、PCC、Relief三种方法及其与PCA结合的改进方法。实验结果表明,PCA对不同过滤式方法的改进效果不一致,但PCA对Relief的改进效果显著。在未来的工作中,我们将进一步研究其他方法与PCA及其改进版本的有效结合,提出更有效的特征选择方法。1.3 基于特征过滤和PCA降维的混合特征选择方法

1.4 分类预测
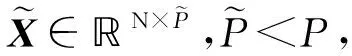
2 实验结果与分析
2.1 实验数据说明和比较方法
2.2 实验结果




3 讨论
4 总结
