基于CPCIe高速总线的机载多核计算处理平台
2022-07-04俞大磊崔西宁李成文刘婷婷周勇
俞大磊,崔西宁,李成文,刘婷婷,周勇
航空工业西安航空计算技术研究所,西安 710065
由于航空电子系统特殊的应用环境,相比于普通的计算机,机载计算处理平台在体积、功耗、重量、可靠性等方面有更加严格的约束。航空电子系统经历了分立式、联合式、综合模块化(IMA)3个重要的发展阶段,在此过程中,机载计算处理平台的架构也从分立式、基于1553B总线的分布式,发展到核心处理机+网络的集中分布式结构,每次架构变化在很大程度上得益于计算处理平台性能的提升。虽然机载计算处理平台的处理性能越来越高,但是体积、功耗、重量等通用质量特性也越来越大。早期联合式航电系统采用的计算处理平台体积小、重量轻,但是性能普遍不高。目前广泛采用的综合模块化计算处理平台可以实现从前端传感器数据处理到后端显示处理的全航电系统高度综合。这种高度综合化的架构一方面带来了体积、重量的上升,另一方面也提出了液冷散热的需求。因此,针对中小型飞机航空电子系统应用环境对计算处理平台体积、重量和散热条件的限制,有必要对计算处理平台进行高性能、小型化、低功耗的设计。目前国内外已经开展了相关的研究,法国和日本的某些厂家推出重量几百克的IMA产品,其中法国Adeneo公司和英国e2v联合研发出的机载多核计算机重量不足300 g。ARINC 公司制订了ARINC836标准来替代现行ARINC600标准,该标准规定了分布式综合模块化航空电子系统的安装方法、连接器及环境适应性要求。相比于ARINC600标准,该标准可使航电设备重量和体积均减少40%以上。未来分布式IMA有可能引进云计算、雾节点等新技术,国内某厂家提出基于云微智能分级分布的航空电子系统架构,采用智能微系统、可变拓扑的网络和标准的软件、硬件、数据接口,实现处理、传感、作动、武器的云节点化。
在体积、重量和功耗(SWaP)严格受限的情况下,提升计算处理平台性能的方式主要有提升处理器的性能和提升总线的性能2种。
从提升处理器性能的方向来说,传统的依靠提升单核处理器工作频率来提升处理器性能的方法已经遇到瓶颈,单纯地提高处理器工作频率会导致不均衡的功耗和散热损耗,并由于芯片内部和外部的串扰、信号延迟和反射引起越来越多的问题。由于多核处理器具有很高的集成度,可以用较低的功耗代价取得较好的系统性能,通过资源共享有效的减小系统的功耗、体积和重量,已成为系统性能提升的有效途径。多核计算体系结构在消费电子领域的研究始终处于最前沿,而出于性能和“Low SWaP”的提升需求,多核处理技术在航空电子系统等安全关键应用领域的适应性将成为亟待解决的关键问题。欧美许多国家已经开始在航空电子系统中推广应用多核处理器,并形成了包括操作系统、系统配置、系统测试、系统监控、系统开发的一整套的高确定性多核处理方案。美国伊利诺伊大学的UPCRC(Universal Parallel Computing Research Center)研究中心、加州大学伯克利分校的ParLab实验室,瑞典的UPMARC(Uppsala Programming for Multicore Architectures Research Center)研究中心,WindRiver、GreenHills、DDC-I等嵌入式操作系统厂商都已开展针对多核处理器的论证和技术验证,取得了一系列的研究成果,AEEC(Airlines Electronic Engineering Committee)完成了ARINC 653标准修订,风河公司开发了操作系统 Wind River 653 3.X。国内众多大公司也已开展多核处理器以及多核操作系统相关研究,国防科技大学和中国科学院相继推出了“飞腾”和“龙芯”系列的多核处理器,航空工业西安航空计算技术研究所研制的国产自主版权操作系统天脉2多核版本已经可以支持多核处理器在航空电子系统中的应用。与采用单核处理器相比,多核处理器的应用可使机载计算处理平台的集成化程度更高,有效降低计算处理平台的体积、重量和功耗。因此从性能、功耗、体积、重量等方面综合考虑,多核处理相比于单核具有显著优势,是提升计算处理平台性能和集成密度,进而确保航空电子系统整体性能的最佳选择。
从提升总线性能的方向来说,当前的计算处理平台大多采用LBE(Local Bus Extension)、VME (VersaModule Eurocard)、CPCI(Compact Peripheral Component Interconnect)、FC (Fiber Channel)等总线作为背板总线,LBE、VME和CPCI总线均属于并行总线,其中CPCI总线极限理论可用带宽为133 MByte/s,带宽和延迟均不能满足计算处理平台日益发展的需求。FC总线传输速率高、时延小、误码率低,但同时也带来了成本、功耗和体积的上升,不满足计算处理平台“Low SWaP”的需求。面向航空电子系统等嵌入式抗恶劣环境,国外厂家大力发展RapidIO、PCIe等高速信号传输技术,RapidIO2.0、PCIe2.0等第2代技术已经成熟,并且得到广泛应用,目前正在向第3代技术发展。CPCIe(CompactPCI Express)在兼容PCIe总线全部接口协议的基础上结合了CPCI总线的机械结构形式,采用高级差分结构(ADF)连接器替代PCIe的金手指式互连方式,这在实现PCIe总线体系结构、突破带宽的同时,可以提供高可靠、高扩展、高兼容、低延时的连接特性,同时保持高速差分信号的完整性。CPCIe采用点对点串行连接代替CPCI的共享并行架构,为每一设备分配独享的通道带宽,保证了每个设备的带宽资源,提高了数据传输率。CPCIe1.0单个收发通道的可用带宽高达250 MByte/s,CPCIe2.0可达到500 MByte/s,CPCIe3.0可达到1 GByte/s。
针对计算处理平台高性能、小型化、低功耗的设计需求,本文研究一种基于CPCIe高速总线的机载多核计算处理平台。首先给出计算处理平台的架构,然后对多核处理的关键技术、CPCIe高速总线设计进行探讨,并对CPCIe总线进行仿真与测试,最后给出系统验证结果。
1 计算处理平台设计
1.1 总体架构
计算处理平台是具备自主航路规划和自主避障功能的某新型无人机航空电子系统的任务处理和管理中心,承担航空电子系统的任务管理、航路规划、数据处理与数据融合、火控计算、综合导航、武器管理、网络通信管理、系统健康管理等功能。计算处理平台包括1块电源模块(PSM)、2块通用处理与输入/输出(I/O)模块(GPIO)及1块数字地图模块(DMM)。各模块功能独立,通过系统内总线连接,在应用的统一调度和管理下共同完成系统功能。
由于计算处理平台在重量、体积和功耗严格受限的条件下要承担大量的高性能计算处理任务,从处理器架构、主频、高速缓存、存储接口、I/O接口和功耗等方面对处理器进行综合考量,最终选择高性能、低功耗的PowerPC架构多核处理器。为了实现2块GPIO模块与DMM模块间的高速数据交换,采用背板CPCIe高速总线实现模块间的数据通信。CPCIe支持点对点拓扑,2个端口独占发送和接收带宽,数据传输延迟低,确定性好,具有结构简单、可靠性高的优点。
计算处理平台采用28 V电源供电,对外提供多种电信号接口,用于实现计算处理平台与飞行控制、惯性导航、雷达、标准武器接口单元、测控系统、维护接口板、任务数据记录器等任务子系统之间的交联通信。对外接口主要包括离散量输入端口,与标准武器接口单元交联的离散量输出端口,与测控系统、维护接口板等设备交联的异步RS422接口,与飞行控制、惯性导航、雷达等任务子系统之间的1553B总线接口,以及与任务数据记录器的1394B总线接口等。计算处理平台架构如图1所示。

图1 计算处理平台架构Fig.1 Architecture of computing processing platform
1.2 计算处理平台设计与实现
计算处理平台的设计与实现充分考虑未来的发展趋势和可升级性,处理器局部资源在满足需求的前提下具有一定的扩展性,尽可能提供更高的处理、通信能力。对于硬件、软件的一些关键接口采用COTS产品,实现标准化、模块化设计。采用“Low SWaP”设计,提高功能集成度,减小计算处理平台的体积、重量和功耗,降低热设计难度。
GPIO模块主要完成航路规划、高性能数据处理、RS422数据、1553B数据和1394B数据的收发及离散信号的输入输出等功能。DMM模块用于存储和处理数字高程地图,主要由1块处理器子卡和1块1 TB的SATA电子盘构成。PSM模块能够将输入的28 V直流电源进行控制转换后输出5 V电源供其他模块使用。计算处理平台内部模块采用多核处理技术,通过CPCIe高速总线完成模块间通信,同时为了提升容错能力,对GPIO模块进行余度设计。
1.2.1 多核处理
为了实现高性能处理,GPIO1、GPIO2、DMM模块均采用高性能、低功耗的多核处理器进行设计。多核处理器中每个核具有独立的L1 Cache和L2 Cache,并且共享L3 Cache、DDR3/DDR4控制器及外设。多核处理器内部集成PCIe2.0、SATA2.0、千兆以太网等丰富的接口资源,方便平台功能的扩展。本方案中的多核处理架构实现了统一内存模型,即所有核共享相同的物理地址空间。这简化了平台设计,整个多核芯片通过共享的存储器总线与主存储器控制器相连,处理器核之间通过一种基于低延时共享物理内存的通信机制来实现相互之间的同步。
1.2.2 CPCIe高速总线
2块GPIO模块和DMM模块通过背板CPCIe总线连接。每个模块通过背板引出两路对外CPCIe高速串行总线,分别与另外2个模块点对点连接。CPCIe总线配置为x1(单通道)模式,电气规范满足PCIe2.0版本规范要求。
点对点连接的架构保证了计算处理平台不通过PCIe交换就可实现内部所有模块的高速信号互连,工程实现阶段可以省去PCIe交换芯片,一方面可以为计算处理平台降低约7 W的功耗,另一方面也解决了可能由于PCIe交换芯片造成单点故障的隐患,提升了计算处理平台的可靠性。
1.2.3 余度设计
2块GPIO模块采用1+1余度方式设计,物理上可以完全互换,实现系统的功能备份和重构。每个GPIO模块由I/O处理模块、1553B多路传输数据总线接口(MBI)子卡和1394B子卡组成,I/O处理模块实现处理器最小系统及离散量输入输出、RS422总线等外围接口电路,通过1路PCI总线至1块PMC背板形式的MBI子卡,对外实现2路双余度1553B总线,通过1路PCIe总线至1块XMC背板形式的1394B子卡,对外实现1路双端口1394B总线。
2 多核处理关键技术
2.1 多核操作系统架构
为了充分利用多核资源,同时考虑任务间的空间隔离,选用VxWorks6.9操作系统。VxWorks6.9引入RTP(VxWorks Real-Time Pro-cess)模式编程,这种模式兼顾了内核保护性和实时性,应用程序相互独立,互不影响,增加了内核的稳定性。多核操作系统架构主要考虑SMP(Symmetrical Multi-Processing)和基于核绑定的SMP这2种OS(Operating System)架构。
SMP架构是对称多处理器架构,一个OS实例同时管理所有CPU内核,应用并不绑定到某个内核。操作系统实现对多核的计算资源分配和外部资源分配。该方式需要专用的操作系统内核,不能简单地通过操作系统改造实现。
基于核绑定的SMP架构是绑定多处理器架构,一个OS实例同时管理所有CPU内核,每个应用被绑定到指定的内核。
从并行性、任务调度、任务确定性、故障隔离、单核软件重用性、负载均衡、外设访问方式、外设管理、核间通信及调试等方面对比SMP和基于核绑定的SMP这2种OS架构,对比结果如表1所示。
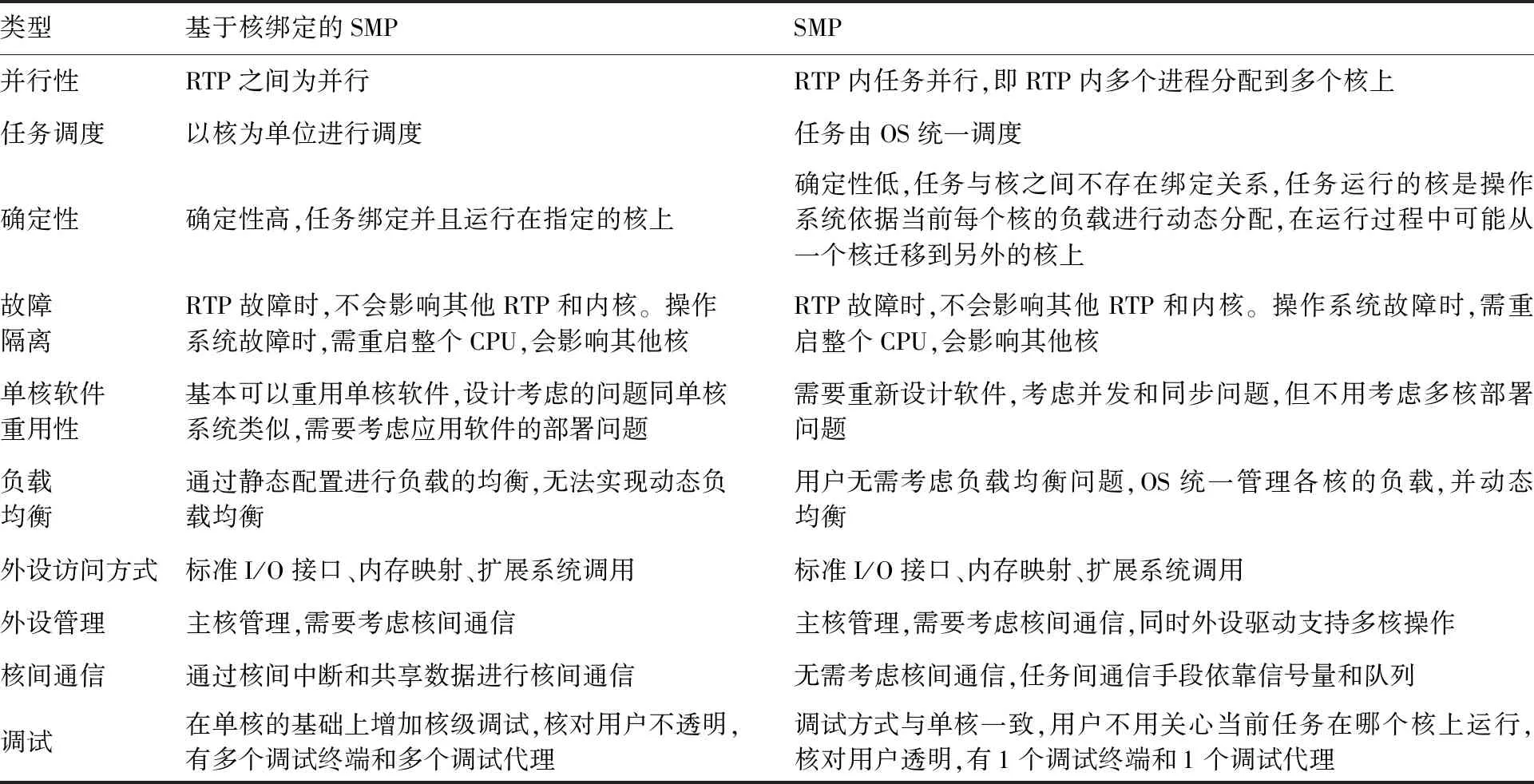
表1 OS架构对比Table 1 Comparison of OS architectures
通过上面的对比,基于核绑定的SMP架构具有实时性高、确定性强、单核移植方便的优点,但是存在应用对核可见、调试麻烦,同时运行时无法实现动态负载均衡,需要通过静态配置进行负载的均衡等缺点。SMP架构具有任务间的并发性好、调试简单、可以实现动态负载均衡,更加有效地利用多核资源等优点,但是存在单核应用移植麻烦、需要考虑任务间的并发、确定性低,任务运行期间可能会在核间进行动态迁移等缺点。
机载计算处理平台应用于安全关键领域的航空电子系统,是一种强实时嵌入式计算平台。考虑后续扩展性(处理器核数)、计算处理平台确定性、继承性(已有应用软件支持并行执行的复杂度)、技术先进性(多核资源管理)、耦合性(2个核的任务松耦合)等方面因素,操作系统采用核绑定SMP架构。
2.2 基于核绑定的SMP调度机制
基于核绑定的SMP主要依靠任务设置亲和性(taskCpuAffinitySet)和CPU预留(vxCpuReserve)2种方法实现。
虽然任务在任何处理器核上运行的默认SMP操作可以提供最佳的总体负载平衡,但是对于安全关键领域的航空电子系统,通过任务设置亲和性的方法将特定的任务分配给指定的处理器核可以极大提高任务的确定性。操作系统使用专用函数组可以将任务绑定到指定的处理器核上,以此实现任务设置亲和性的功能。设置了亲和性的任务只能运行在指定的处理器核上,没有设置亲和性的任务,仍然可以在所有核上运行。对于RTP程序来说,如果创建RTP的任务指定了核,那么该任务创建的RTP也指定了相应的核。
由于没有设置亲和性的任务作为全局队列仍然会运行在所有的处理器核上,因此即使是设置了亲和性的任务,仍然存在被其他任务中断运行的可能。操作系统提供了CPU预留功能,将CPU预留给那些设置了CPU亲和性的任务。被预留的CPU,除了绑定的任务,其他任务不能在该CPU上运行,这样可以有效地保证绑定任务不被其他任务抢占,进而改善系统的性能。
2.3 CPCIe共享外设确定性设计
多个核上的应用可能出现对CPCIe的并发访问,如果未加互斥保护,可能出现设备I/O混乱。如果保护不当,又会造成设备访问拒止或超时。CPCIe共享外设的确定性设计主要通过如下2种方法。
1) 支持设备独占模式。设备绑定在指定核上运行,其他核不使用该设备。在应用使用固定设备场景中,应用、核及设备形成一个资源域,域之间相互隔离。利用处理器硬件的IOMMU(Input/Output Memory Management Unit)机制,限定在域内访问设备,域内的任务只能在指定核上运行。通过这种方式建立核与设备的确定性连接关系。例如将CPCIe设备分配给核心1使用,核心1通过执行驱动程序操作该设备,只有运行在核心1上的应用才能使用该设备。
2) 支持基于互斥保护的设备共享模式。对设备驱动程序进行互斥保护,只有获得了互斥锁的核才能执行驱动程序操作设备。核心1和核心2共享物理设备,在设备驱动层增加互斥锁保护,形成临界区,2个核通过获取互斥锁进入临界区,运行于核心1上的应用和运行于核心2的应用都能够使用该设备。
本方案采用设备独占方式对CPCIe共享外设进行确定性设计,支持处理器核对CPCIe的独立访问。
3 CPCIe高速总线
3.1 CPCIe设计规范
CPCIe规范中对机械结构和电气结构均作出了详细规定。机械结构中包括模块和插槽、差分连接器和欧卡,电气结构中包括PCIe协议和SMBus。PICMG为CPCIe系统定义了不同的插槽和模块类型,以满足不同细分市场的需求。插槽的类型包括系统槽、Type1外设插槽、Type2外设插槽、混合外设槽及交换槽。模块的类型包括系统模块、Type1外设模块、Type2外设模块及交换模块。
CPCIe规范使用CPCI连接器、高级差分结构(ADF)连接器和电源连接器来定义不同的插槽和模块。高级差分结构(ADF)连接器主要用于传输高速差分信号,特征阻抗为100 Ω,频率在3 GHz时输入衰减小于1 dB,具有高可靠的高速信号传输、高接触密度并支持高可靠的信号转发等特性。计算处理平台内部GPIO1模块、GPIO2模块和DMM模块通过背板CPCIe总线互连,每个模块设计2路CPCIe2.0接口与另外2个模块互连,均为x1模式,物理上为一对同时工作的发送和接收通道。由于所有CPCIe高速差分信号都在背板上传输,如何确保高速信号的数据完整性是CPCIe系统的关键技术。GPIO模块和DMM模块选用的背板连接器遵守标准CPCIe规范,采用1个CPCIe电源连接器,2个2排10列拥有20个差分对的高级差分结构(ADF)连接器和1个110脚防插错CPCI连接器。CPCIe高速总线互连架构如图2所示。
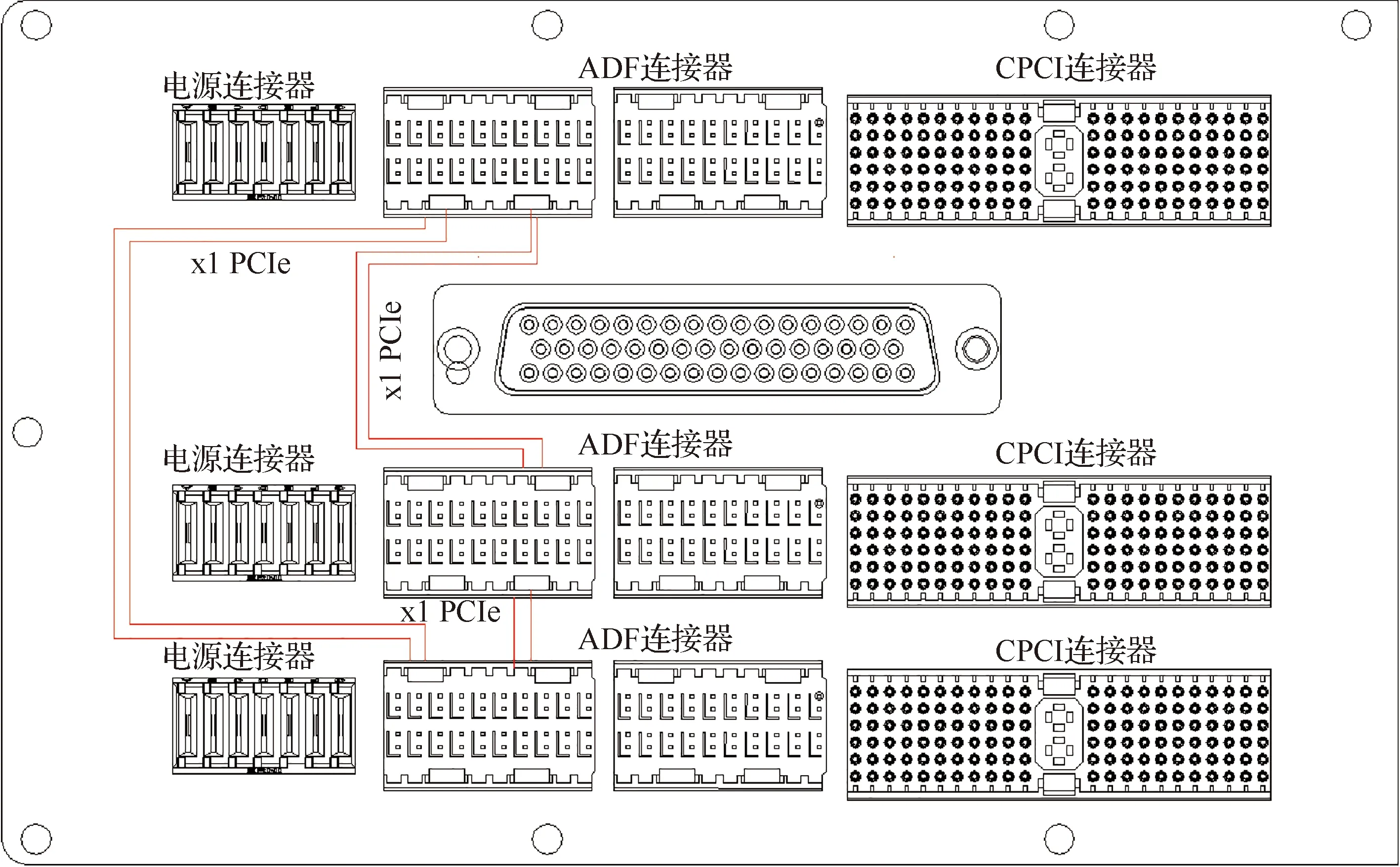
图2 CPCIe高速总线互连架构Fig.2 Interconnection architecture of CPCIe bus
CPCIe规范支持系统插槽及其他几种不同链路宽度和类型的插槽,在开发背板时可以从中选择这些插槽类型。CPCIe规范定义了用于通信接口类型、插槽类型和背板中每个插槽的接口的描述符。有了这些描述符,通过创建一个应用程序,用户可以获取系统的通信接口类型、插槽类型等能力。系统模块和背板包含用于读取背板能力记录的SMBus,能力记录足以描述PCI、PCIe1.0等不同的接口,背板能力记录还可以对背板进行唯一标识。CPCIe背板具有串行可擦除可编程只读存储器(EPROM),EPROM连接到SMBus,用于存储背板标识和能力记录。
3.2 CPCIe信号完整性和工艺要求
机载计算处理平台对传输在PCB上的CPCIe高速差分信号的信号质量有很高的要求。由于高速PCB的设计需要考虑介质、平面分割、信号的等长等不同的因素,因此需要通过仿真来提供PCB设计依据,在电路设计之初就采用仿真工具进行仿真验证,并根据仿真结果不断的修改设计。
CPCIe数据传输方法使其非常适合使用FR4材料制作PCB,为了确保高速信号的数据完整性,背板高速数据信号需严格进行阻抗匹配。CPCIe的收发差分信号对,使用蛇形走线严格控制等长,同时CPCIe需要在发射端和接收端之间交流耦合。
实际PCB布板时由于布线密度太高,CPCIe无法实现同一层布线,故采用多层布线。在多层PCB制造过程中,钻出通孔后需要通过孔壁沉铜来保证贯通孔导电,以此联通不同信号层信号线,此时没有在信号路径上的一段过孔就成为一个过孔残桩(Stub)。PCB设计时贯通过孔带来的Stub对CPCIe高速信号的信号完整性有很大的影响,因此需要对Stub进行背钻处理,这时从背面选择一个比过孔孔径大一点的钻头,把没有在信号路径上的一段过孔的铜壁钻掉,使这段过孔失去导电性能,从而消除Stub,这就是背钻过孔工艺。
4 CPCIe总线仿真与测试
CPCIe总线仿真采用Ansys 3Dlayout仿真工具。仿真针对基于CPCIe架构的计算处理平台方案,评估CPCIe2.0高速总线的多级连接器、过孔、长走线等问题引起的总线物理特性,同时为了保持未来的可扩展性,对CPCIe3.0高速总线也进行了仿真。仿真采用图1中计算处理平台作为高速总线系统互连模型,模型设计过程中考虑了所有现场可编程逻辑门阵列(FPGA)、CPU模型及中间所有连接器模型,同时对模块、背板的厚度也进行了预计。
4.1 无源链路仿真
4.1.1 插入损耗
为了满足输入、输出的电平要求,CPCIe2.0协议要求插入损耗在1.25 GHz时不得大于13.2 dB,在0.625 GHz时不得大于9.2 dB。对于PCIe3.0协议要求,本次仿真的系统属于经多级连接器的长链路互连,应采用在1 GHz时不得大于6.5 dB、在4 GHz时不得大于20 dB的要求。
通过仿真,并加入CPCIe2.0、CPCIe3.0协议的要求,插入损耗的结果如图3所示。从仿真结果可以看出,插入损耗满足协议要求,实际链路在1.25 GHz,衰减为-4.87 dB,即信号衰减了其最大允许衰减幅度的24.35%。在2.5 GHz,衰减为-9.96 dB,即信号衰减了其最大允许衰减幅度的49.8%。
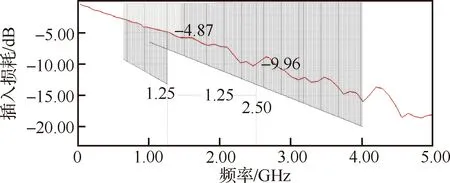
图3 插入损耗仿真结果Fig.3 Simulation results of insertion loss
4.1.2 回波损耗
回波损耗是由于传输链路中阻抗不连续产生反射的损耗。对于差模的回波损耗而言,CPCIe2.0协议要求在50 MHz~1.25 GHz频段内小于-10 dB,在1.25~2.50 GHz频段内小于-8 dB。对于共模的回波损耗而言,CPCIe2.0协议要求在50 MHz~2.50 GHz的频段内小于-6 dB。接收端与发送端的回波损耗要求一致。
通过仿真,链路的差模回波耗损结果如图4所示,共模回波耗损结果如图5所示。

图4 差模回波损耗结果Fig.4 Simulation results of differential mode return loss
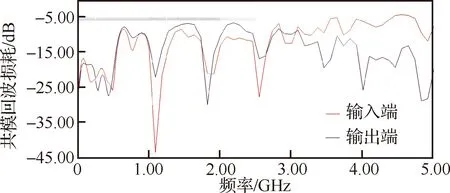
图5 共模回波损耗结果Fig.5 Simulation results of common mode return loss
仿真通过尽可能控制信号上升沿陡峭来趋于实际信号,仿真后通过优化来趋于理想信号,因此要求高频谐波越多越好。且仿真主要是针对电特性进行 优化,因此不考虑8B/10B编码的加窗。
从仿真结果可以看出,共模回波耗损在50 MHz~2.5 GHz 的频段内都远小于-6 dB,满足CPCIe2.0协议要求。差模回波耗损在接近2.5 GHz时有超标1 dB,即协议要求反射小于其幅度的39.81%,实际反射结果为其幅度的44.67%。
对于CPCIe1.0协议,可用带宽为250 MByte/s×8=2 Gbit/s,由于CPCIe1.0采用8B/10B编码,传输速率为2 Gbit/s×10/8=2.5 GT/s(千兆传输/秒),对应频率为1.25 GHz,回波损耗满足要求。对于CPCIe2.0协议,可用带宽为500 MByte/s×8=4 Gbit/s,由于CPCIe2.0采用8B/10B编码,传输速率为4 Gbit/s×10/8=5 GT/s,对应频率为2.50 GHz,差模回波耗损超标。由于目前仿真中未使用背钻过孔,实际设计时需要对链路上的过孔进行背钻处理,可以有效减小反射。
4.2 电气特性仿真
CPCIe属于高速串行总线,其中CPCIe2.0的传输速率高达5 GT/s,即每秒传输5千兆次,如果仅仅衡量某一个周期的信号质量,无法评估整个信号的质量。因此采用眼图来衡量CPCIe高速串行传输的信号质量。在上述仿真的基础上,增加驱动接收模型进行信号的电气特性仿真,发送端波形如图6所示,接收端管脚处波形如图7 所示。
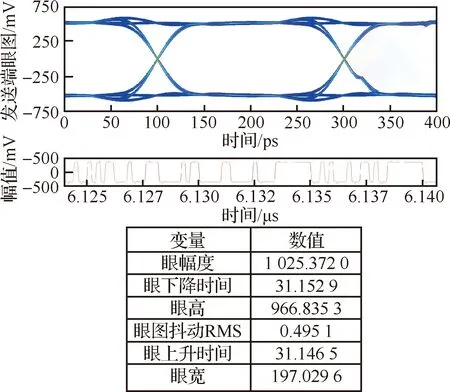
图6 发送端波形Fig.6 Waveform of transmitter

图7 接收端管脚处波形Fig.7 Waveform of receiver
CPCIe2.0电气特性的协议要求信号的数据单元时间为200 ps,差分输入的峰峰值幅度最小100 mV,最大1.2 V,最大的接收端的总抖动为0.4个数据单元时间,眼图张开建议大于0.6个数据单元时间,即120 ps。
经过眼图与协议对比分析,通道的接收端管脚处不满足电气特性的要求。接收端发生了码间串扰(ISI)。这是由于FR4板材带来介质损耗,链路中连接器、过孔、匹配器件等物理结构带来导体损耗,导致信号传输链路频域受限,接收端信号波形在时域上展宽,相邻码元间互相重叠,从而引起码间串扰。码间串扰可以通过均衡来补偿。均衡算法是通道传递函数的逆过程,用于平衡通道对高频和低频衰减的影响,有效降低ISI,最终实现信号无失真传递。CPU处理器的高速SerDes接口中包括了解码器、均衡器和数据恢复单元,均衡器中集成判决反馈均衡(DFE)、前馈反馈均衡(FFE)和连续时间线性均衡(CTLE)等均衡算法,通过配置接收端均衡控制寄存器的参数,就可实现接收端的均衡。接收端内部进行均衡处理后的波形如图8所示。
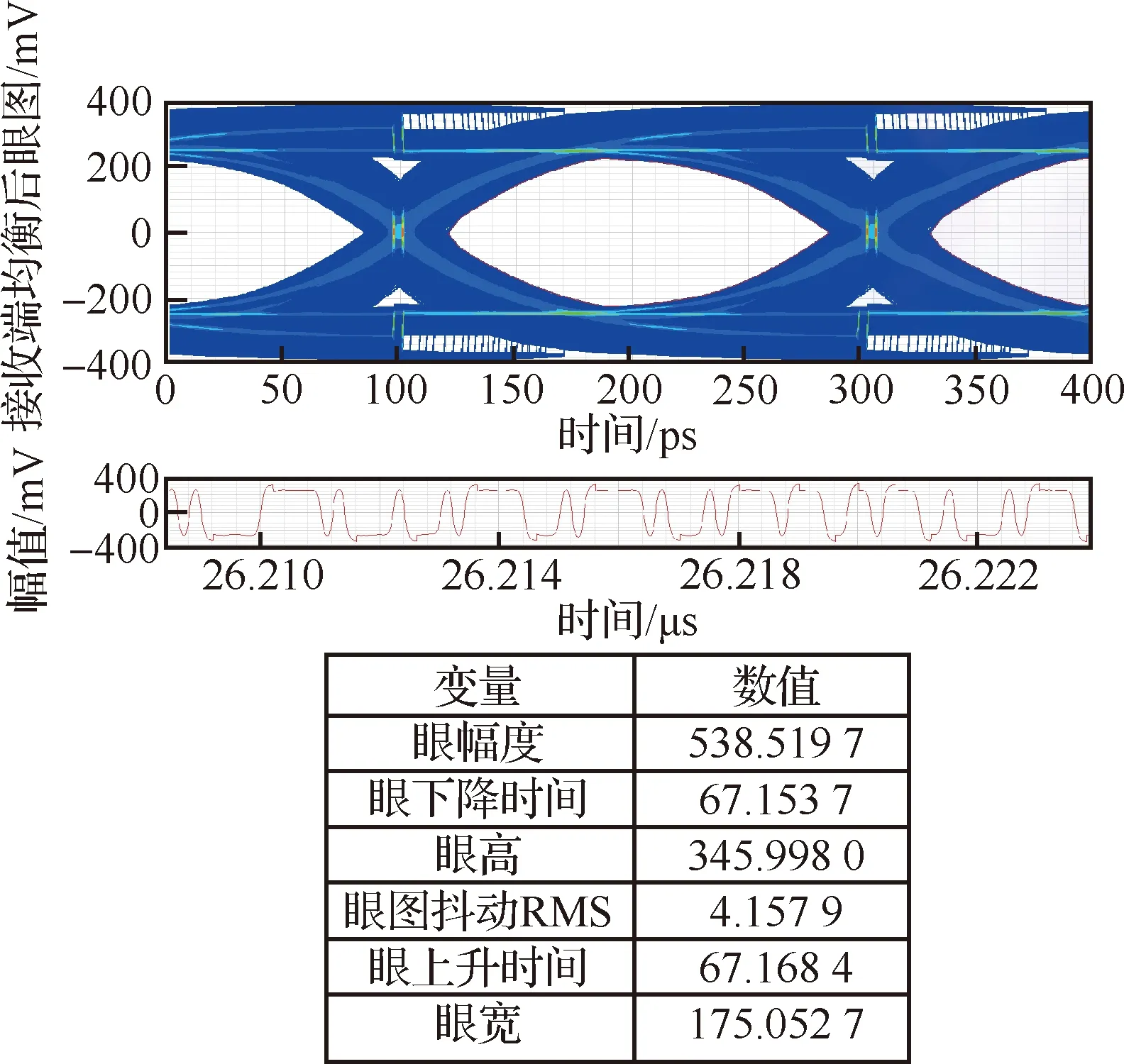
图8 接收端均衡后波形Fig.8 Waveform after equalization at receive
可以看出,通过接收端的均衡处理后,电气特性满足协议要求。由于过度均衡会增加抖动,因此在实际设计过程中会提前评估CPU处理器中接收器的均衡能力,然后根据传输信道调节到一个合适的均衡值。
4.3 性能测试
在计算处理平台中对CPCIe性能进行测试,通过在根节点(RC)和端节点(EP)之间传输固定大小的数据,然后采用在程序中标记时间戳的方法测试数据传输的时间,通过数据大小和时间的比值获取CPCIe传输带宽。CPCIe采用8B/10B编码,导致占用了20%的原始信道带宽。除此之外,CPCIe的实际传输带宽还受到处理层数据包(TLP)中的非数据内容、数据链路层数据包(DLLP),甚至RC端驱动和应用程序的影响。计算处理平台CPCIe性能测试结果如表2所示。通道A设置GPIO1模块为RC,GPIO2模块为EP,实测写通信带宽为287.7 MByte/s,通道B设置GPIO1模块为RC,DMM模块为EP,实测写通信带宽为287.5 MByte/s,通道C设置GPIO2模块为RC,DMM模块为EP,实测写通信带宽为287.5 MByte/s。通过测试可以看出,采用CPCIe进行数据传输能够有效提高整个系统的传输带宽。
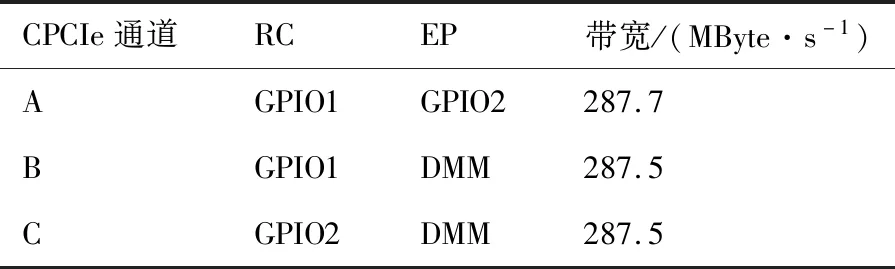
表2 CPCIe性能测试结果Table 2 CPCIe performance test results
5 系统验证
航空电子系统对机载计算处理平台的体积、重量、功耗有严格的约束,随着摩尔定律的发展,基于半导体材料的集成电路里面器件的集成度已经接近了物理的极限,性能和功耗、体积、重量等约束因素的平衡是机载计算处理平台设计必须面对的关键技术挑战。因此,机载计算处理平台已经从单纯提高性能,转变为提高单位能耗性能、单位体积性能和单位重量性能。本方案用性能功耗比(单位MIPS/W)来表示单位能耗的计算能力,用性能体积比(单位MIPS/cm)来表示单位体积的计算能力,用性能重量比(单位MIPS/g)来表示单位重量的计算能力。
本方案提出的计算处理平台已经通过软硬件综合联试及系统综合验证,从性能功耗比、性能体积比、性能重量比3个方面将本方案与传统联合式架构和IMA架构进行对比,传统联合式架构选取了某无人机任务管理计算机,IMA架构选取了某飞机综合处理机,本方案是针对某自主飞行无人机的计算处理平台。性能功耗比、性能体积比和性能重量比3个性能评估指标对比结果如表3所示。与传统的联合式架构相比,本方案实现的计算处理平台性能功耗比提升约7倍,性能体积比提升约24倍,性能重量比提升约15倍。与IMA架构相比,本方案实现的计算处理平台性能功耗比提升约5倍,性能体积比提升约2倍,性能重量比提升约1.7倍,可以满足嵌入式环境对计算处理平台小型化、低功耗、轻重量、高性能的需求。
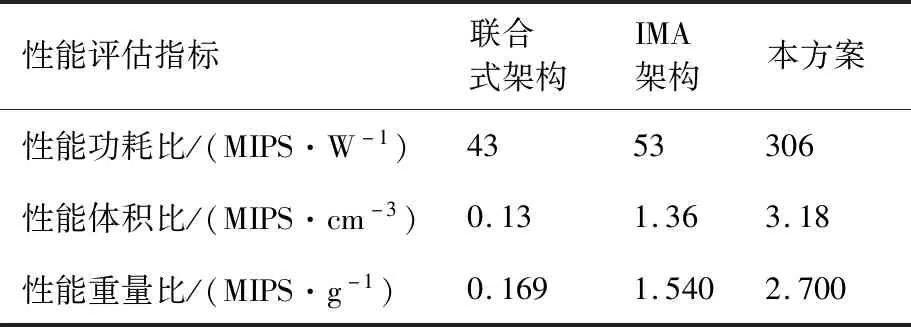
表3 性能评估指标对比Table 3 Comparision of performance evaluation indexes
6 结 论
提出了一种基于CPCIe总线的机载计算处理平台方案。针对机载航空电子系统计算处理平台对高性能、小型化、低功耗的迫切需求,研究了一种基于CPCIe高速总线和多核处理器的机载计算处理平台架构,解决了多核处理和CPCIe高速信号完整性在航空电子系统中的适应性问题,对多核操作系统架构、基于核绑定的SMP调度机制和共享外设确定性设计等多核处理关键技术进行研究,从CPCIe规范和信号完整性工艺对CPCIe高速总线进行设计,并对CPCIe总线信号完整性进行了仿真和测试,验证了方案的信号完整性以及对通信带宽的改善程度。设计并实现了一款基于CPCIe高速总线的分布式机载多核计算处理平台,在该平台上进行了实施验证。采用性能功耗比、性能体积比和性能重量比等评估指标对计算处理平台进行综合评估,具体结论如下:
1) 相比于传统的联合式架构和综合模块化架构,计算处理平台的性能功耗比分别提升约7倍、5倍。
2) 相比于传统的联合式架构和综合模块化架构,计算处理平台的性能体积比分别提升约24倍、2倍。
3) 相比于传统的联合式架构和综合模块化架构,计算处理平台的性能重量比分别提升约15倍、1.7倍。
本方案实现的计算处理平台可以满足中小型飞机航空电子系统对计算处理平台小型化、低功耗、轻重量、高性能的需求,具有一定的工程应用参考价值。
