计算机自适应测验中试题泄露的实时监控方法研究与应用
2022-07-01秦春影吴龙月王爱平
秦春影,吴龙月,王爱平
(1.南昌师范学院数学与信息科学学院,江西 南昌 330032;2.亳州学院电子与信息工程系,安徽 亳州 246800)
0 引言
随着社会电子化的程度越来越高,信息安全问题与社会的每一个成员息息相关,已经渗透到日常的各个方面,对于测验领域也不例外.计算机自适应测验(Computerized Adaptive Testing,CAT)[1-2]是测验发展的新方向,它能根据考生在试题上的作答情况,自适应按顺序安排其后的试题,真正实现了“因人施测”,因而能够更精确地测量出被试的能力.相对于纸笔测验,它有更多的优势,从效度、公平和安全等多个方面对测验进行保证,并且有着更短的测验长度和测试时间,大大提高了测验效率[3].自20世纪80年代起,CAT在美国教育测试中得到了广泛应用,如NCSBN (National Council of State Boards of Nursing)、GMAT(Graduate Management Admission Test)等.20世纪90年代末,美国匹兹堡大学的研究者创建了世界上第1个自适应教学系统[4].而国内CAT的研究主要还是集中在理论上,在应用方面的研究相对较少,相关研究主要有杨业兵开发的中国士兵人格问卷[5]、涂冬波编制的小学儿童数学问题解决的诊断CAT系统[6]和邓远平编制的大学生人格内外向的CAT测验[7]等.
随着CAT在实际应用中的推广,试题泄露这一测验安全威胁也愈发突显.在连续的施测(其含义是测验在多个时间点举行,比如测验在连续的一段时间内举行,考生可以选择合适的时间点参加测验)情况下,CAT中的试题被持续曝光的可能性急剧增加,对题库的安全性形成巨大的挑战.美国的GRE考试曾出现过有组织的大规模盗题的情况[8-9].因此,需要对正在使用的试题进行实时监控,控制各个试题出现的曝光度[10-13].若试题的参数(如难度和区分度等)发生显著性的变化,则必须将试题进行强制“退休”.Zhang Jinming[14]提出了序贯监测程序(Sequentially Monitoring Procedure,SMP),用它来监测CAT中试题的统计特征在测试过程中是否产生变化,从而判断试题是否发生了泄露;但该方法会产生一定的虚报,并且统计检验力在一些条件下不高.本文将在SMP的基础上引入基于残差的R指标(Residual,R),并将它作为考生拟合统计量(PersonFitStatistic,PFS)[15],与SMP方法相结合提出了一种新的PFS_SMP方法,在SMP的基础上判断被标记的试题是否发生真正泄露.PFS_SMP是基于自适应测验展开的,可以实现试题的在线实时检测,即在测验施测的过程中实时检测试题的统计指标,当发现异常时立即切换到安全题库下施测;该方法从试题和被试这2个方面去保证测验的安全性与公平性.最后,通过模拟实验和实证分析来评价新方法的优势与不足.
1 序贯监测程序概述
当一个题库使用较长时间后,针对被使用多次的试题,需要对其进行监测.记在考试过程中第j个试题的得分序列为{U1j,U2j,…,Unj,…},其中n是指作答该试题的第n个考生,而非参加测试的第n个考生.若该考生答对该题,则Unj=1;否则Unj=0.
众所周知,考生在测验试卷上的作答过程是个随机过程,他在每个试题上的作答是个随机事件.若试题的得分只有2种情况,则考生在该试题上的得分服从二项分布.在试题没有被泄露的情况下,对于每一个考生,其正确作答某题的概率与考生自身的能力值和试题的难度、区分度以及猜测度相关,假定P(Uij=1|θi,aj,bj,cj)为考生i正确作答第j题的概率,θi为该考生的能力值,aj、bj、cj分别为该试题的区分度、难度、猜测度,则在施测过程中,该试题的得分序列{U1j,U2j,…,Unj,…}应服从相同的分布.

P1(θ)=eP′(θ)+(1-e)P(θ),
(1)
其中e的大小是未知的,但它只有等于0和大于0这2种情况.当e=0时,该题没有泄露;当e>0时,
P1(θ)-P(θ)=e(P′(θ)-P(θ))>0,
即在试题泄露之后,该试题对于后面的所有考生都显得简单了.而试题的泄露是未知的,泄露点nk的确定也很困难,不同试题的泄露点位置也不一样.因此,监控方法很有必要对试题进行实时监控,在试题泄露后尽快将其甄别出来,以保证CAT的安全性和公平性.
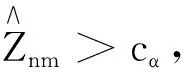
SMP于2014年被Zhang Jinming[14]提出,它的工作原理是:当试题泄露后,该试题的正确作答概率会有较明显提升,利用前后的正确作答概率的差异构造出假设检验的统计量,若统计量的值超过了预设的临界值cα,则认为该试题已经泄露[8].
1.1 Ⅰ类错误
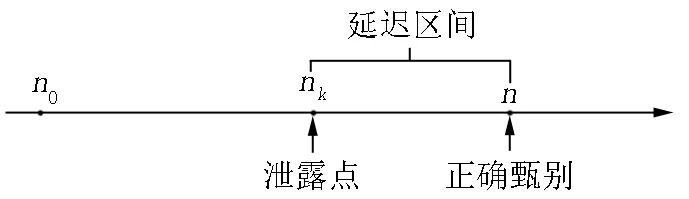
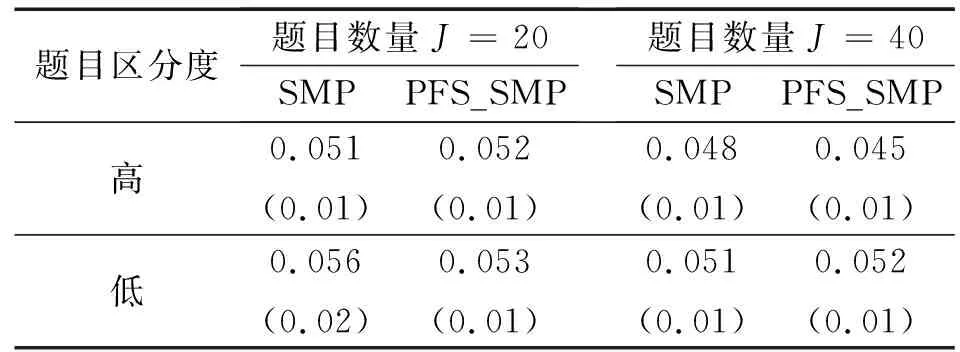
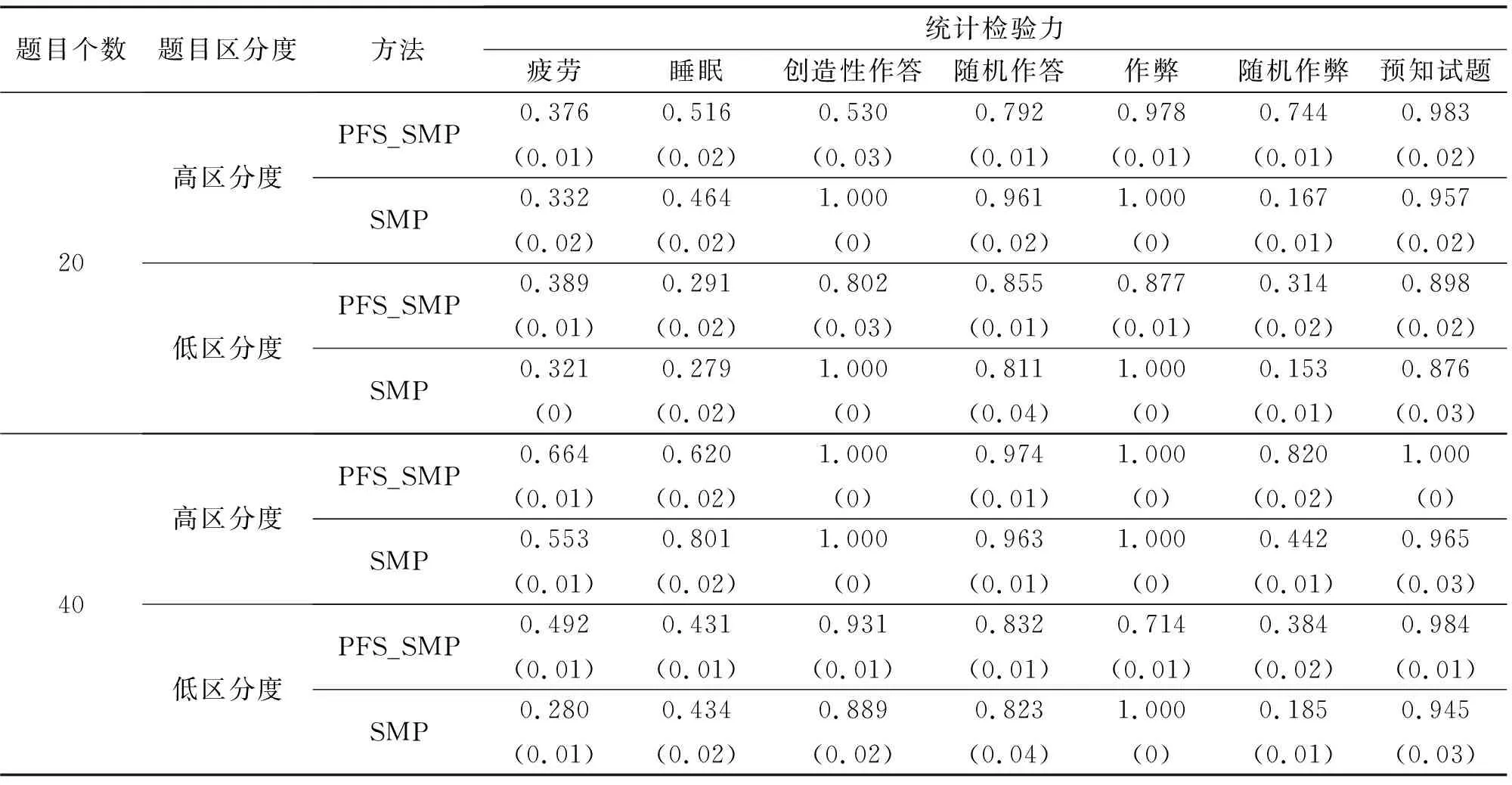
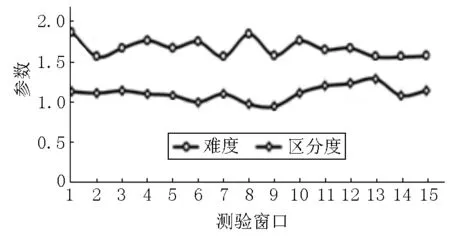
假设被监控试题的泄露点是nk(即在第nk个考生后该题被泄露),而监测结果显示该题是在第n个考生后被泄露,若n 图1 Ⅰ类错误 假设被监控试题的泄露点是nk(即在第nk个考生后该题被泄露),而监测结果显示该试题是在第n个考生后被泄露,若n>nk(即监控程序显示在第n个考生作答时该题被泄露,此时该试题确实泄露了,监控程序给出了正确甄别;但在第nk个考生到第n个考生之间,该试题发生了泄露而监控程序却没有甄别出来),则犯了Ⅱ类错误,[nk,n]是延迟区间(见图2). 图2 Ⅱ类错误 在CAT中每道试题都有它潜在的目标考生子群体,试题难度较大的子群体能力比试题难度较容易的子群体能力更高,因此,定义p是在某一被监控试题的考生目标子群体中某名考生的得分期望值,其计算公式如下: p=E(Un|该试题目标考生子群体)= 其中p是随机从考生目标子群体中选取的一个考生作答该试题的正确概率,f(θ)是该试题的目标子群体的能力密度函数,因此可以用正确作答比例去估计p的值.在测试过程中,若试题没有泄露,则相应的考生作答该试题的p值是一样的;若在第nk个考生后泄露,则前nk个考生p值一样,第nk个考生后的考生的该试题得分期望值为p1,其计算公式如下: 其中P1(θ)由式(1)得到.SMP的监控过程主要由一系列的假设检验构成,假设作答被监控试题的第n个考生指的是当前考生,将到n为止的所有考生的作答分为2个部分:前n-m个考生作答为参考移动样本,第n-m+1个考生到第n个考生的作答为目标移动样本.之所以被称为移动样本是因为监控过程是实时连续的,n会不断往后移,其中m是移动样本量[7].“序贯”的含义就体现在此,在一次次后移的过程中完成监测. 参考移动样本的正确作答概率估计值为 目标移动样本的正确作答概率估计值为 (2) 残差是在回归分析中的重要概念.残差在数理分析统计中是指实际观察值与估计值(拟合值)之间的偏差;给定一个不可观测函数,它将自变量与因变量联系起来.若对某些数据进行回归,则因变量的观测值与拟合函数值之间的偏差为残差.残差在应用中蕴含的逻辑就是:通过对比理想情况(模型预测值)与实际情况(实际观察值)的差异来发现其中的异常情况.预期偏差会使残差统计量膨胀,这与被试拟合检验的思想一致.因此,这里提出基于残差的被试拟合统计量R指标,它主要是检验被试在实际观察作答和期望作答概率之间的差异.第i个被试的拟合指标Ri的计算方法为 (3) 其中J为项目个数.在实际情况下,考生的真实能力无法得到,因此本研究采用能力估计值,借助Matlab语言编程进行估计.已知项目参数及被试作答数据,用期望后验估计(Expected A Posterior)[16]方法得出能力估计值.uij表示被试i在项目j上的作答,uij=1表示被试i正确作答项目j,uij=0表示被试i错误作答项目j,E(Uij|θi,aj,bj,cj)表示能力为θi的被试i在项目j上正确作答的期望概率,P(uij|θi,aj,bj,cj)表示能力为θi的被试i在项目j上的正确作答概率. 在被试进行作答的过程中,并不能一直保持稳定的状态,偶尔会出现异常的状态,因此作答数据也会出现一些异常作答的情况,主要包含以下几种异常作答模式: (i)创造性作答(Creative Responding Behavior).它是指由于被试以独特或具有创造性的方式作答这些试题,而错误地作答了简单的试题. (ii)随机作答(Random Guessing Responses).它是指在测验动机较低下的情况下,被试凭猜测随机反应. (iii)疲劳(Fatigue).J.B. Sympson等[11]讨论的外部因素(如疲劳)可能影响被试的反应,从而导致被试在考试快结束时的异常反应. (iv)睡眠(Sleeping Behavior).根据Zhang Jinming等[9]指出,睡眠是指由于被试对考试形式的混淆而在考试开始时表现不佳. (v)作弊(Cheating).它是指能力较低的被试通过欺骗、抄袭等一系列手段使自己正确作答较难的试题. (vi)随机作弊(Cheating with Randomness).它是指作弊的随机出现. (vii)预知试题 (Item Pre-knowledge).它是指考生在考试之前了解试题的信息,这表明试题发生了泄露. 在了解有关残差应用的逻辑以及R指标的含义和作用后,再构建新的方法:PFS_SMP方法.PFS_SMP方法的基本原理主要为:假设题库共有J个试题,有N个考生,对考生作答过的试题做出相应的标记,分横纵2列记录数据,一列为SMP对试题进行的监控进程,即当试题被作答至一定次数时,可能会发生质量上的变化,用本文所介绍的SMP方法对试题进行检验,这一监测为题目水平的监测[8];另一列为考生作答的试题,通过结合SMP方法计算考生拟合统计量R指标,检验考生实际的观察作答和期望作答概率之间的差异,以判断考生作答数据是否异常,这一监测为考生水平的监测[12].若某个试题被SMP判断为泄露,并且R指标也显示对应考生的作答数据出现了异常,则认为该试题发生了泄露,并将其进行封存,不再用于之后的测试.新构建的PFS_SMP方法是从试题和考生2个方面对题目进行监测,极大地保证了测验的安全性与公平性. 新构建的PFS_SMP方法主要分为以下几个步骤: (i)当试题的曝光次数达到一定数量时,启动SMP对试题的质量进行相应监控,若试题被标记为“泄露”,则继续完成CAT测试; (ii)在测试结束后,统计该考生在作答的所有试题中被SMP标记为泄露的试题个数; (iii)用SMP方法与残差指标R相结合,依据式(3)计算考生的R指标,即PFS值.若PFS值超过预先设定的CPFS(临界值),则把步骤(ii)被标记为“泄露”的试题进行封存,直到所有考生完成测验; (iv)统计被标记为泄露的题目和异常的考生数据,并计算各指标的值,对结果进行评价. 实验研究采用的是Monte Carlo模拟方法,模拟被试的真实能力、测试的题库、作答数据以及泄题情况. Monte Carlo模拟也被称为随机抽样,是一种用随机数来解决计算问题的模拟研究方法.Monte Carlo模拟的基本原理是:当一个问题具有概率特征时,可以通过计算机模拟生成抽样结果,并从抽样中计算统计值或参数;随着模拟次数的增加,可以通过对每个统计量或参数的估计平均值来得出稳定的结论. 为了检验PFS_SMP方法的表现,本文设计了实验进行对比研究:(i)SMP方法,即用原来的序贯检测程序对题目进行监控;(ii)PFS_SMP方法,即用PFS_SMP方法对被SMP标记为“泄露”的试题进行判断后再决定是否封存.通过比较这2种方法的表现来分析PFS_SMP方法的优势或劣势以及其对试题安全监控的效果. 模拟实验数据: (i)模拟被试,假设被试的能力参数服从标准正态分布,即θ~N(0,1)[11],并模拟250个被试. (ii)模拟项目,区分度b和猜测度c分别按b~U(0.5,1.5)和c~U(0,0.25)生成,低区分度题目按a~logN(0,1)模拟,高区分度题目按a~logN(0.5,1)模拟,共模拟100个项目. (iii)模拟作答数据,共包含2种情况, (a)在题目未泄露时的正确作答概率,采用3参数Logistic模型生成,即 P(u=1|θ)=c+(1-c)/(1+e-Da(θ-b)), 其中θ是被试的能力值,P(θ)是能力值为θ的被试的正答概率,a是试题的区分度参数,b是难度参数,c是试题的猜测参数.若正确作答概率大于等于随机数,则u=1,否则u=0.D为量表常数. (b)接触到泄露试题后,用修正的3参数Logistic模型[17]生成数据,即 P(u=1|θ)=c′+(1-c′)/(1+e-Da(θ-b)), 其中c′为修正的猜测参数,且c′=p(m)+c-cp(m),p(m)是在考生事先了解题目信息时的作答概率,本文取p(m)=0.75[18]. (iv)模拟各异常作答模式,包括前面介绍到的疲劳、睡眠、创造性作答、随机作答、作弊、随机作弊、预知试题,这些异常作答模式的生成方式如下. (a)疲劳.测验后期的30%试题作答概率按比例下降50%生成; (b)睡眠.测验后期的30%试题按错误作答生成; (c)创造性作答.当考生的能力参数减去试题难度参数的值超过1时,作答概率按比例下降50%生成; (d)随机作答.测验后期的30%试题随机生成作答; (e)作弊.将测验后期的30%的错误修改成正确作答; (f)随机作弊.随机将测验中的30%的错误试题修改成正确作答; (g)预知试题(试题泄露).设置nk=200,即在试题被作答至第200次时试题发生了泄露,之后启用修正的3参数Logistic模型模拟作答.监控起始点为n0=100,即当试题被作答至第100次时,启用监测程序[13,18-20],移动样本m=50,cα取值为2.5,CPFS取值为2,每个实验条件下重复30次. 在本次模拟研究中,当某道试题被作答次数(即曝光率)达到100次(n0=100)时,就开启SMP来监测试题,在每一次的模拟过程中都将记录好以下数据:被监控试题数量,被错误标记的试题数量(即犯Ⅰ类错误的数量),犯Ⅰ类错误前的考生作答数量,已泄露但认为未泄露的试题数量,实际泄露的试题数量.然后计算犯Ⅰ类错误的概率以及在几种异常作答模式情况下的统计检验力. 本文采用Ⅰ类错误率和统计检验力作为评价指标. (i)Ⅰ类错误率:PⅠ=未泄露但被标为泄露的试题数/(被监控的试题数-实际泄露的试题数); (ii)统计检验力:PT=实际已泄露且被标为泄露的试题数/实际泄露的试题数. 表1和表2分别是被试拟合指标的Ⅰ类错误率和统计检验力的结果. 表1 在相应条件下2种方法的Ⅰ类错误率及其标准差 表2 在几种异常作答模式下2种方法的统计检验力及其标准差 为了显示出PFS_SMP方法的效果,研究中固定cα与CPFS的值分别为2.5和2,然后计算并记录在相应条件下SMP组与PFS_SMP组的Ⅰ类错误率及其标准差.在这里分别记录了当试题数量为20与40时,高低区分度下2种方法的Ⅰ类错误率.由表1可知:随着试题数量的增加,Ⅰ类错误率会逐渐减小;试题的区分度越高,Ⅰ类错误率会越低;属性个数对Ⅰ类错误率没有较大影响.由表2可知:随着试题数量的增加,在各个异常作答模式下的统计检验力会明显增大;试题的区分度越高,统计检验力则越高. 在表1与表2中将SMP组与PFS_SMP组作对比可以发现:在相同的试题数量、区分度与考察属性个数下,PFS_SMP组有着更低的Ⅰ类错误率和更高的统计检验力.这说明:PFS_SMP方法能够在一定程度上降低在相同条件下的Ⅰ类错误率,并且提高统计检验力.在预知试题的情况下,PFS_SMP方法在统计检验力方面比SMP方法更高. 为了进一步考察PFS_SMP方法的应用,将它用于分析一批实际数据,该数据是某省的一次大规模标准化测量,题库中一共有360多项选择题,测验采用CAT机试,自适应地为每位考生选题,整个测验持续15 d,每天的考生是200~950人,一共有8 765名考生参加了测试,对于整个数据集,采用3参数模型进行拟合,量表常数D=1[16],得到所有试题的参数和各考生的能力参数.难度参数和区分度参数的均值分别为0.136、0.998,它们的标准差分别为0.562、0.475.整个考生群体的能力分布呈负偏态分布,能力参数的均值和标准差分别是0.967、1.132.采用如下的步骤对各个测验窗口的数据进行分析: (i)监控每个被选中的试题,若某个试题的使用次数达到100,则启动PFS_SMP程序来监测该试题; (ii)对每个被监测的试题,若SMP程序将它标记为泄露题,则同时标记出施测了这个题目的考生; (iii)对标记的考生计算R统计量的值,判断其是否为异常考生; (iv)根据上述的2个步骤,从试题和考生的水平对题目和考生的异常情况进行判断. 基于上述的过程,一共有18个题目被标记为泄露题,357名考生被标记为异常考生.较低比例的试题被标记的主要原因可能是该测验并不是一个高风险测验,对考试分数特别重视的考生比例可能并不是太高.图3和图4分别显示了被标记出的试题和未被标记出的试题的参数随着测验窗口的增加而变化的情况. 从图3和图4可以看出:一方面,当试题发生泄露时,其参数会有很明显的下降趋势,而对于未泄露试题的参数则在整个测验窗口中保持相对稳定的状态.另一方面,发生泄露试题的参数随着测验窗口的增加而在持续下降.由图3可以看出:第71题是一道区分度较大的题,根据最大信息量选题规则,应该有很多考生选到这道题,几乎可以确定在测验的第2天就发生了泄露,导致该题的参数在逐渐下降,到第15天,它已经变成了一道区分度很低的试题,这是因为此时很多考生都已经提前了解了这道题的信息. 图3 第71题的参数变化趋势(泄露题) 图4 第150题的参数变化趋势(正常题) 题目的安全性一直是在所有大型测试中非常重要的问题,历年来有很多研究者在这方面做了相关的研究,针对题目的曝光提出了很多曝光控制方法.在E. Georgiadou等[18]的研究中,他总结出了5大类曝光控制法:随机化法、分层法、条件选择法、结合前3者的综合方法和多阶段自适应设计.但控制题目的曝光率并不能够有效控制试题泄露,有的试题曝光率达到几百上千次都没有泄露,而有的试题可能只曝光了几次便被泄露了,因此文献[14,20]提出了SMP方法,运用监测程序对试题进行更有效的监控.但SMP方法会发生一定的虚报,即一定的Ⅰ类错误率,相应的统计检验力会降低,因此在试题被SMP方法监测标记为泄露后,还需要其他的统计方法对其进行判断. 为了降低SMP方法的Ⅰ类错误率和提高其统计检验力,本文提出基于残差的R指标[21],并与SMP方法相结合,构建了新的方法:PFS_SMP方法.PFS_SMP方法相较于SMP方法的优势为:使用了被试的作答信息,从试题和被试2个角度出发,核实被SMP监测标记为泄露的试题是否真正泄露,以此降低Ⅰ类错误率.此外,本文采用了修正的3参数Logistic模型模拟作答数据,将考生能力、试题的区分度、难度及猜测度等参数考虑进去,让结果更加符合实际情况[19,22]. 通过一系列的实验验证,得出了以下几个结论: (i)试题数量的增加与区分度的提高能够降低Ⅰ类错误率与提高相应的统计检验力; (ii)PFS_SMP方法能够在一定程度上有效降低在SMP方法中存在的Ⅰ类错误率; (iii)PFS_SMP方法能够在一定程度上提高在SMP方法中的统计检验力. 本文对一些研究条件做了一定的限制,如cα与CPFS的取值固定为2.5和2,后续研究可以取在这2个值附近的其他值,并进行相应的对比观察,以研究随着cα与CPFS的值发生改变实验结果是否会产生相应的变化;若试题的相关参数和考生的能力值发生相应改变,则cα与CPFS又该如何取值来进行更好的研究,这是未来可以研究的方向. 本文主要对SMP方法与PFS_SMP方法中Ⅰ类错误率和统计检验力的变化进行了相应的研究,而对于在SMP方法中的试题泄露位置却未进行详细研究.随着试题数量或区分度等相关参数的变化,泄露位置的探查会发生什么变化以及有什么方法可以提高探查泄露位置的准确性与从统计测量视角来推动考试公平和教育公平[23],这些也是未来可以研究的方向.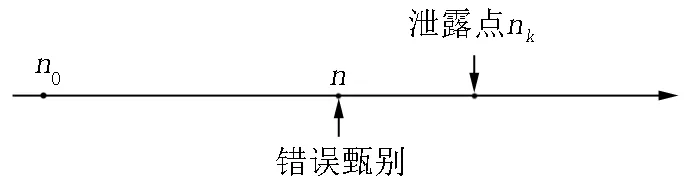
1.2 Ⅱ类错误
1.3 统计量

2 PFS_SMP方法研究
2.1 考生拟合统计量
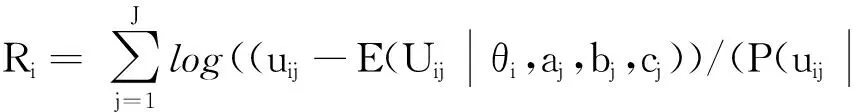
2.2 PFS_SMP方法的基本原理
2.3 PFS_SMP方法的操作步骤
3 研究设计
3.1 模拟设计
3.2 评价指标
3.3 研究结果及讨论
4 实证数据分析

5 总结与展望
5.1 结论
5.2 展望
