基于声发射数据融合与特征提取的起重机故障诊断
2022-06-29陈洪良张一辉许飞云
陈洪良 李 杨 张一辉 许飞云
1江苏省特种设备监督检验研究院南通分院 南通 226011 2东南大学机械工程学院 南京 211189
0 引言
起重机作为现代工程建筑中常见的机械设备,常工作于恶劣和复杂的运行环境,其安全性和稳定性受到严峻的考验[1]。起重机故障的产生不仅会增加停机时间导致生产损失,还会对操作人员的安全带来极高的威胁。因此,为避免灾难性故障并减少生产力损失和停机时间,同时保证人身安全,构建有效的起重机故障诊断和寿命预测模型是必不可少的。
故障诊断能够确定早期故障的发生、故障的位置和故障的严重程度,通过这些方法可以防止机器的故障。故障诊断模型主要依赖于从状态监测数据中提取的故障特征,且预测模型预测机器的退化趋势和机器的剩余使用寿命。数据驱动模型需要状态监测数据来建立预测模型,从而描述缺陷进展和实现剩余使用寿命预测[2]。这些模型独立于物理退化过程,在精度和复杂性方面都有较好的表现。因此,从状态监测数据中提取最大可用信息作为故障特征,构建高效的健康指标是构建故障诊断和数据驱动预测模型的必要条件。近年来,随着计算效率和样本数据存储的不断提高,机器学习技术在故障诊断和预测中的应用越来越广泛。Choudhary等[3]使用卷积神经网络进行故障诊断,并与人工神经网络进行了比较证明了其优越性,其中支持向量机由于其泛化能力强而被用于故障的分类。长短期记忆是分析时间序列数据的一种优势技术,其能够处理时间序列数据中的长期依赖关系。Ding等[4]应用了基于长短期记忆的故障预测方法,并利用模糊C均值技术寻找不同的退化阶段,通过粒子群优化算法调整长短期记忆的超参数来预测设备的剩余使用寿命。
声发射作为一种动态的无损检测技术,由于其明显的优势而被广泛应用于机械系统的故障诊断中,通过提取声发射信号特征能够进行故障的诊断和预测[5]。将从原始声发射信号中提取的多种传统特征融合为单一特征,可以提高故障诊断和预测的准确性。从声发射信号中提取的大量特征可能覆盖了大量的信息,但特征中也可能隐藏了冗余信息,从而降低了算法的准确性并增加了复杂性和计算时间。因此,通过消除冗余信息,从高维特征集中提取有用信息是至关重要的。降维技术通过消除冗余信息和噪声,将高维特征集融合为显著的低维特征,在机械故障诊断和预测中得到了广泛的应用。然而,利用数据融合技术直接融合高维特征集需要较多的时间,容易导致过拟合和维数问题。因此,融合前对相关特征子集的选择是降低融合复杂性和过拟合的关键。
研究人员使用不同的线性和非线性降维技术作为数据融合方法,通过融合高维特征集来提取重要特征。数据融合有利于初始故障检测、不同故障类型的分类以及构建寿命预测的健康指标。主成分分析是一种常用的传统线性降维技术,它表示数据中的最大方差。Zvokelj等[6]通过集成经验模态分解和主成分分析来进行故障诊断,开发了故障诊断框架。Wang等[7]通过融合各种统计特征,使用主成分分析方法计算了一个健康指标来建立一种新的寿命预测模型。此外,独立分量分析可以有效地对数据进行故障诊断和噪声滤波。Li等[8]将压缩感知和独立分量分析相结合,从多源混合数据中提取故障特征来实现故障诊断。线性降维技术可以有效地分析线性数据集,但无法从非线性数据中提取非线性信息。目前,非线性降维技术已被用于分析实际工程中机械的健康状态。局部线性嵌入是一种经典的非线性降维技术,利用线性变换提取非线性信息。Shao等[9]使用局部线性嵌入方法推导出特征指数来量化设备退化趋势。并以制定的指标为输入,构建了一种基于深度信念网络的优化方法,用于设备的故障检测和剩余使用寿命预测。
本文首先采集实际工程中起重机重要部件的故障声发射信号,采用8种降维技术提取所采集的故障声发射信号特征,并计算用于起重机剩余使用寿命预测的8个健康指标。随后,利用随机森林方法从原始特征集中选取特征子集,并将选择的特征子集通过降维技术进行融合,提取二维故障特征来进行单故障和复合故障分类。同时,采用多类支持向量机计算起重机故障的分类精度,通过8个健康指标的单调性、预后性、趋势性和信噪比4个属性的加权来计算适应度值,从而选择最佳健康指标。最后,利用选取的健康指标构建基于长短期记忆的预测模型,对起重机进行剩余使用寿命预测,所提方法流程如图1所示。
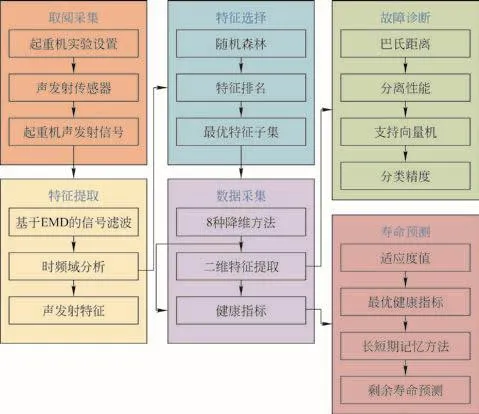
图1 故障诊断流程
1 声发射特征提取基础理论
1.1 信号处理
基于声发射的状态监测方法主要用于故障诊断和预测。从声发射信号中提取的特征包含机器部件的健康状态信息,这对故障诊断和预测具有重要作用。特别的,将时域、频域、时频域的信号处理技术应用于采集的声发射数据中,提取出各种原始声发射特征。时域分析是机械故障诊断早期最简单的方法,它提供了与时间有关的信号幅值信息,然而它忽略了信号中与频率相关的信息。在频域分析中,可以提取与频率相关的部件缺陷信息,从而有利于起重机故障类别的识别,但频域分析忽略了时间信息。因此,利用时频域分析提取特征,在提取特征的同时获取时间和频率信息,在机械故障诊断和预测中更加有效。本文通过采集起重机重要部件的声发射数据来实现状态监测,首先利用经验模态分解(Empirical Mode Decomposition, EMD)对原始声发射信号进行滤波来消除噪声,随后通过连续小波变换和离散小波变换提取时频域中的声发射特征。
1.2 随机森林
上文所述提取的高维特征集可能包含冗余特征,导致过拟合、复杂及计算时间长。从初始特征集中选择低维特征的最佳子集是消除这些问题的关键。在此情况下,使用随机森林方法来确定低维特征的最佳子集。随机森林结合了多棵决策树,每棵决策树都作为分类器从输入特征集中采样,构建一个特征子集[10],其中每棵树由3个节点组成,如根节点、叶节点和决策节点。在决策树中,将根节点分解为决策节点,并将决策节点分支为叶节点。
随机森林方法根据基尼指数或信息增益进行分类,并根据回归问题的方差减少特征进行排序。基尼指数的计算公式为
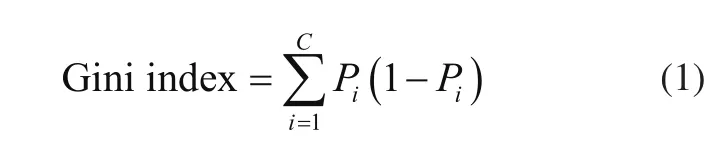
式中:Pi为特定节点属于类i的数据点的比例,C为类的总数。
首先对随机森林进行排序,选择排名靠前的特征作为子集。然后确定子集的随机森林模型精度,并与具有总特征的模型精度进行比较。重复这个过程以选择特征的最佳子集,使其成为具有最大精度的最小子集。
2 故障诊断和预测方法的设计
2.1 巴氏距离
巴氏距离(Bhattacharyya Distance, BD)是一个无量纲数,用于在分类问题[11]中寻找2个概率分布之间的相似性和度量类之间的可分性。当数据簇分离良好时,BD值较高,其可以应用于具有不同标准差的样本。BD值随样本标准差的增大而增大,还被用于特征提取、特征选择和分类误差计算。
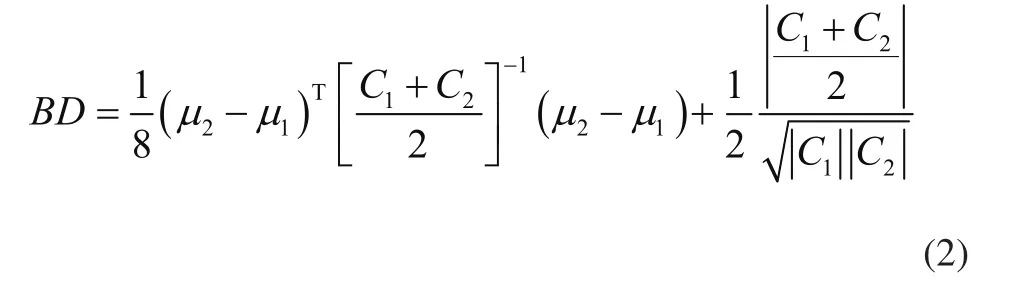
式中:μi和Ci为第i类样本的均值和协方差矩阵。
2.2 支持向量机
支持向量机(Support vector machine,SVM)是由Cores和Vapnik[12]开发的一种监督学习技术,它使用统计学习理论来分析数据进行分类。SVM方法主要用于机械部件的故障检测和分类,由于其泛化能力强,已经取得了许多成功的结果。在SVM中,边界线可以用线性函数ωTx+b表示,式中x为带有分类标签-1和1的特征向量,ω为权重向量,b为分离超平面的位移。SVM的主要目标是通过分离超直线,使类与类之间的距离最大化。其优化问题定义为
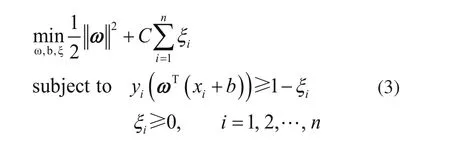
利用拉格朗日乘子法求解约束二次问题,其对偶问题表述为
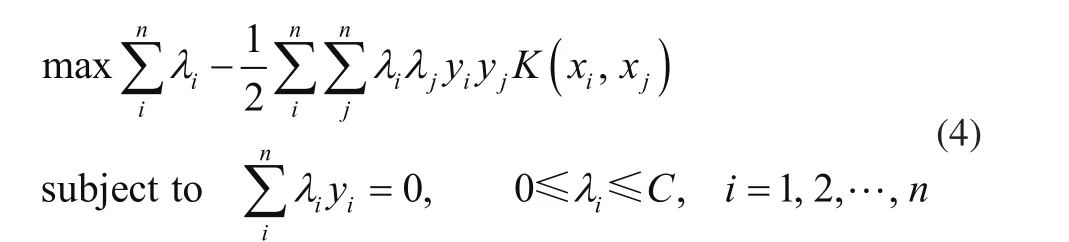
式中:λi为拉格朗日乘子,K(xi,xj)为核函数。对于未知数据,SVM的解为
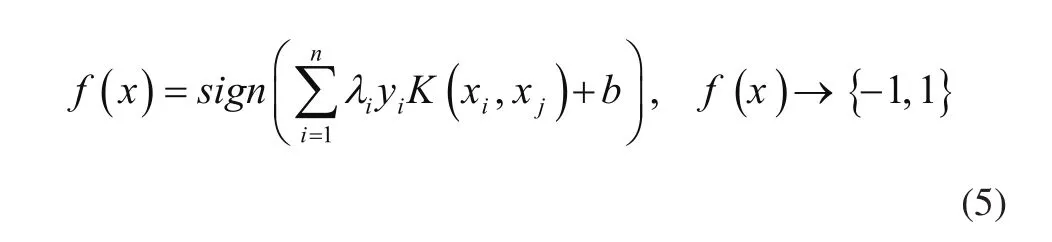
2.3 最佳运行状况指示器选择
选择适当的健康指标是建立有效的预测模型,实现准确的起重机剩余寿命预测的关键。显著的健康指标应具有4个特性,即单调性、预测性、趋势性和信噪比。这4个属性的加权和可以用来确定预测较好的健康指标,从而进行剩余寿命预测。这些参数的范围为从0到1,0表示某一参数得分较低,即该参数不适合用于剩余寿命预测,而取值1表示该参数得分最高,更适合用于剩余寿命预测。
2.4 长短期记忆
长短期记忆(Long Short Term Memory,LSTM)是由Hochreiter和Schmidhuber[14]提出的,用来解决递归神经网络中无法处理时间序列数据中的长期依赖的消失梯度问题。LSTM技术利用了长期依赖优势,是时间序列预测的有效工具。LSTM网络主要包括3个门,即遗忘门、输入门和输出门。这3个门连接在一起决定哪些信息需要存储或忘记。LSTM的关键部分是细胞状态C,采用了sigmoid和tach函数来选择信息。
一个输入xt和先前的隐藏层输出ht-1在时刻t被给予网络。遗忘门首先决定哪些信息可以丢弃或保留,即过滤重要的历史信息,且遗忘门的输出计算为

式中:Uf和Vf为输入权值,bf为遗忘门的偏置。
此外,输入xt和ht-1通过输入门来选择将存储在单元格状态中的信息。输入门将决定状态的更新,中间细胞状态使用tanh函数创建一个添加到细胞的新向量。输入门和中间状态单元给出的方程为
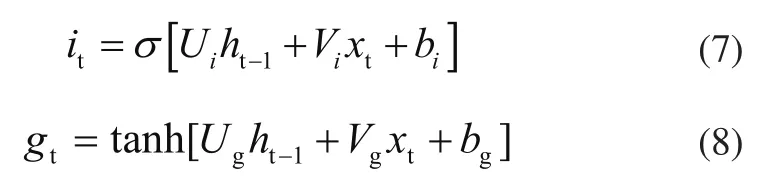
式中:(Ui,Vi)和bi分别为输入门的权值和偏置,(Ug,Vg)和bg分别为输入权值和中间细胞状态的偏置。
新的细胞状态Ct可以由遗忘门、输入门和中间细胞状态的输出来更新。

其中“·”为点积。
LSTM网络ht的输出可以由输出门Ot和tanh函数计算

式中:(Uo,Vo)和bo分别为输出门的权值和偏置。
3 起重机故障声发射数据采集
利用SAMOS声发射采集系统实现实际工程中MQ1260-45型桁架式门座起重机的声发射信号采集,此起重机已被投入使用超过30 a,使用过程中长期承受疲劳载荷及环境腐蚀作用,其钢结构自身出现了多处的开裂现象,如人字架两侧拉杆、臂架根部弦杆、转台大梁局部狭窄区域等。为了验证这些宏观缺陷及潜在埋藏缺陷对整个起重机械结构的稳定性影响,采用声发射检测技术对其进行1.25倍静载荷下的钢结构安全性能检验。因此,选用7个声发射传感器来采集起重机7个重要部件的故障声发射信号,分别位于MQ1260—45门式起重机的旋转柱、A —框架、吊货臂、龙门腿、塔身、旋转平台梁以及配重。在实验中所有的声发射采样频率为1 MHz;阈值为40 dB;采用长度为1 k;前放增益为26 dB;预置触发时间为128 µs;峰值定义时间为200 µs;撞击定义时间为800 µs;撞击锁闭时间为1 000 µs;带通滤波器范围为20 ~400 kHz。起重机不同重要部件采集的原始声发射时域波形如图2所示。

图2 起重机不同重要部件的原始声发射信号
4 故障诊断结果分析
从7个重要部件采集的声发射信号中每一种使用50个样本点进行验证。首先,用基于EMD的滤波器对原始声发射信号进行滤波[15],去除数据中的随机噪声。然后采用基于随机森林的特征选择方法消除冗余特征。以二维特征为输入,计算故障类间的双相空间分布。其中BD值在2个故障集群之间计算,并将得到的BD值取平均值,来计算分离能力指标。BD值越高,表示起重机故障分离越好。本文计算了8种方法的BD指数,其结果如表2所示。从表2可知,LDA法得到的BD值最高,t-SNE所得BD值次之。此外,将从降维技术中提取的二维特征输入到多类SVM中,计算分类精度。支持向量机模型采用了3种类型的核,即线性核、多项式核和径向基函数核。通过对多类SVM进行训练和测试,以发现降维技术的故障分类准确率,其结果如表3所示。从表3中可以看出,LDA方法对故障分类效果最好,3个核的SVM分类准确率均为100%,BD值最高为52.2。PCA、CCA、ISOMAP、LE、DM、LTSA和t-SNE 7种方法的分类准确率均为100%。因此,在选择次优方法时考虑BD值,t-SNE的BD值为45.9。为了比较该方法的有效性,分别使用KNN和朴素贝叶斯分类器对轴承故障进行分类。将8种数据融合技术的二维故障特征输入到KNN和朴素贝叶斯分类器中,结果如表3所示。LDA方法在2种分类器中准确率最高为99.8%。与KNN和朴素贝叶斯方法相比,SVM具有更好的分类精度。
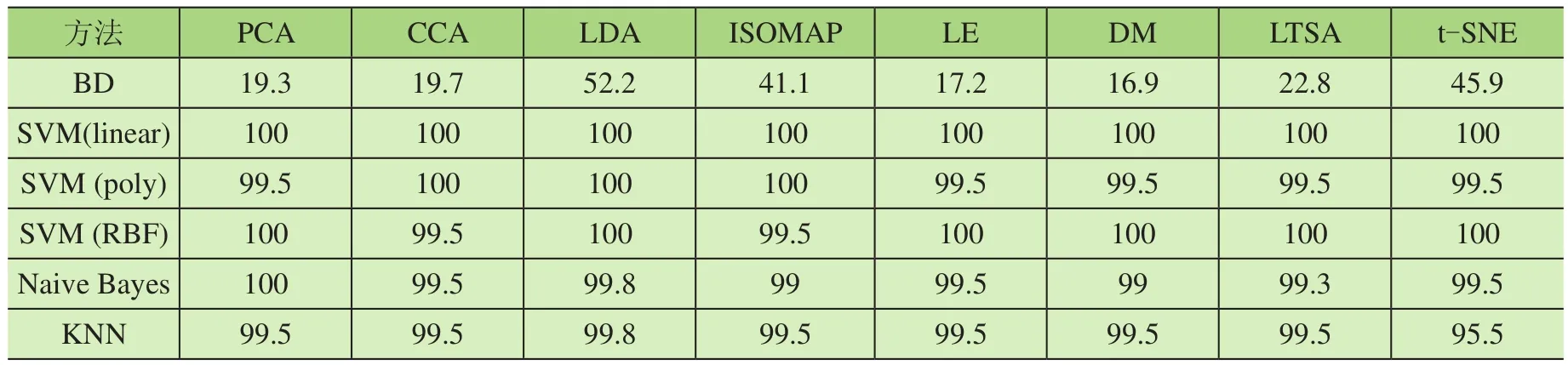
表2 所提方法和其他方法对单一缺陷的分离能力和分类精度
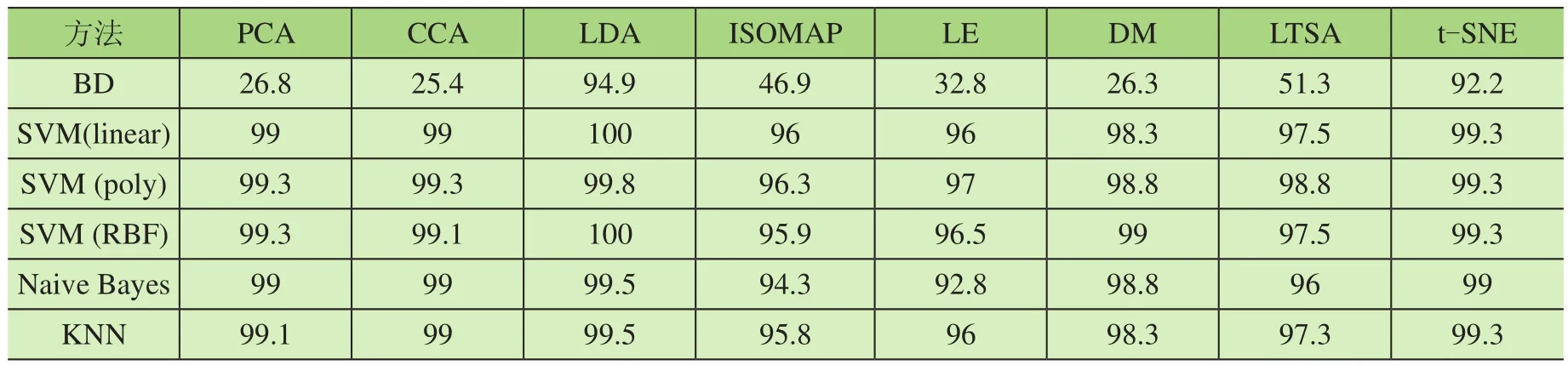
表3 所提方法与其他方法对复合缺陷的分离能力和分类精度
此外,利用数据融合技术对7个通道采集的声发射信号特征进行融合,提取二维故障特征。利用8种数据融合技术所得的二维故障如图3所示。图3所示的2D图显示了对8种故障的比较判别能力。随后根据二维特征来计算8中数据融合技术的BD值,并将所得到的所有BD值取均值,来计算分离能力指标,其结果如表4所示。在这种情况下,LDA技术的BD值最高为94.9,t-SNE方法的结果次之为92.2。将二维特征作为多类支持向量机的输入来计算分类精度。对多类SVM进行训练和测试,以发现降维技术的故障分类准确率,结果如表4所示。从表中可以看出,LDA方法对故障分类效果最好,基于SVM的分类精度为100%,2个核(即:线性核和RBF核)的分类精度最高,其BD值为94.9。与KNN和朴素贝叶斯方法相比,SVM具有更好的分类精度。图4a为融合72个声发射特征得到的健康指标,图4b为融合15个声发射特征得到的健康指标。在图4a中,健康状态和失效阶段由于过拟合而出现严重波动。而图4b中的健康指标在健康状态下是平滑的,在故障后期可以观察到明显的趋势。

图3 不同非线性降维方法的二维故障特征:PCA, CCA, LDA, ISOMAP, LE, DM, LTSA, t-SNE

图4 基于融合的健康指标

表4 采用不同数据融合方法所得到的属性和适应度值
采用8种数据融合技术所得的4个属性值及其适应度值如表4所示。从表中可以看出,PCA、ICA和LTSA具有相同的适应度值,由此表明所计算的4个健康指标对剩余寿命预测的有效性。随后,通过计算均方根误差(Root Mean Square Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)来评估基于数据融合的LSTM方法的寿命预测性能,其结果如表5所示。由表5可知,基于LTSA的寿命预测结果最好,且RMSE和MAE值最小分别为4.05和3.49。为了进一步验证本文所提出的基于LSTM预测方法的有效性,将结果与基于一维CNN方法进行了比较。一维CNN算法中设置的超参数为:隐藏单元个数为100,初始学习率为0.01,最大神经元个数设为100。同时,分别用原始数据的70%和30%来训练和测试数据,并选择RMSE和MAE来比较2种预测方法,比较结果如图5所示。
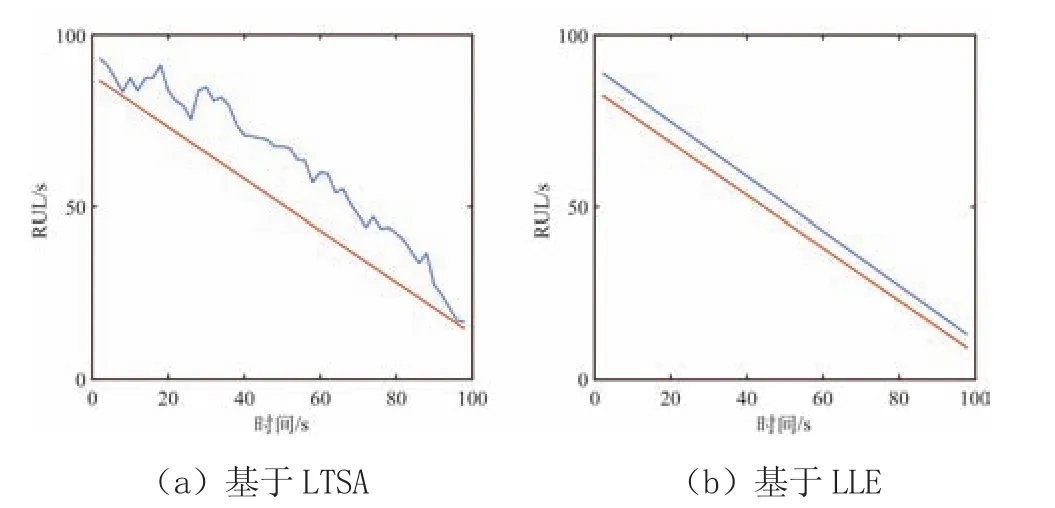
图5 基于LSTM的起重机剩余寿命预测结果

表5 采用所提方法和其他对比方法所得到的剩余寿命预测结果
5 结论
本文提出了一种基于数据融合的起重机故障诊断与预测的整体框架。采用8种数据融合方法对起重机重要部件的故障进行了有效的特征提取,实现了起重机故障的分类和剩余使用寿命预测。通过与8种降维方法的比较,确定了最佳健康指标和二维故障特征。此外,采用8种降维方法对所选特征进行融合,提取出明显的低维特征,并将每种方法的高方差第一维特征作为预测健康指标,且将前二维特征用于故障分类。同时,计算了故障聚类之间的BD值,利用SVM方法对不同故障类型进行分类。最后,通过计算8种降维方法的适应度值,筛选出最优的降维方法。从适应度值结果可以看出,LTSA和LLE是构建起重机预测模型的重要健康指标的最佳技术。结果表明基于LSTM的起重机寿命预测结果与基于LLE的健康指标相结合,能够提供准确的剩余寿命预测结果,从与CNN方法的对比中可以看出,LSTM方法给出了精确的结果。本文所提方法提供了基于数据融合的特征提取方法,提高了起重机故障诊断和预测的准确性。为选择最佳的数据融合技术提取二维故障特征和健康指标提供了一个框架。在现实工业应用中,本文所提的基于数据融合的特征提取可以提高起重机机械部件的故障诊断和预测精度。
