基于铁路客站视频多视角特征图投影融合的人群密度估计模型
2022-06-09代明睿马小宁李国华
李 瑞,李 平,代明睿,马小宁,李国华
(1.中国铁道科学研究院 研究生部,北京 100081;2.中国铁道科学研究院集团有限公司 科技和信息化部,北京 100081;3.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
作为集旅客购票、安检、候车和换乘于一体的大型公共服务空间,铁路客站内人群聚集效应明显,特别是在周末、小长假和春节等节假日以及部分突发情况下,站内人流量会在短时间内急剧攀升,形成高密度人群聚集区。如果此时人群中出现异向客流,很容易在短时间内发展形成高密度对冲,这不仅会造成站内拥挤,使旅客候车乘车的效率和站内服务体验大打折扣,甚至还有可能引发踩踏事件等安全风险。因此,旅客高密度人群聚集对站内运营组织管理和服务管理提出极大考验。
目前应对站内旅客高密度聚集问题时,较为常见的做法是由管理人员现场巡逻监督,一旦观察到旅客人群有高密度聚集趋势,便会通过设置栅栏限行、分流等措施进行疏导,但这种做法本来就存在现场管理难度较大、效率较低等问题,时常会因旅客聚集发现不及时而导致人群疏导工作滞后。而在新型冠状病毒肺炎疫情常态化防控工作中,政府部门对人群密度管理又提出了更为严格的要求。在这种形势下,在人流频繁聚集的铁路客站开展站内人群密度研究,精准掌握站内人群密度数据信息,不仅有助于站内旅客服务组织的科学化管理,更有利于站内疫情常态化防控管理。
近年来,随着深度神经网络在特征提取、识别分类等方面学习能力的不断提升,以深度神经网络模型作为构建基础的人群密度估计算法逐步发展起来并取得了优异的表现[1]。文献[2]创新性地提出多列卷积的神经网络模型(MCNN),实现了同一视角下不同尺度目标的估计,但由于计算参数太大,难以满足当时应用需求。文献[3]在MCNN的基础上增加了卷积神经网络最优化选择器,进一步提升了人群密度估计的准确性。文献[4]使用块状金字塔作为输入来提取多尺寸的特征图,提升了密度估计网络的泛化能力,同时实现了对车流和人流的密度估计。文献[5—6]以MCNN为骨干网络,在人群计数框架中融合图像的全局和局部内容信息,提出了基于图像上下文的金字塔卷积网络CP-CNN,通过生成高质量的密度图提升人群密度估计的准确率,特别是在千人以上的超高密度人群估计中有很好的表现。文献[7—8]对多尺度特征提取模型进一步创新,通过引入注意力机制,提高了模型的自适应性以及人群密度可视化的性能。文献[9—10]主要以目标检测方式对人群图像中不同尺寸的头部进行识别定位,并通过计数的方式估计整体人群数量。文献[11]为获取更多全局信息,采用空洞卷积层来扩大感受野,不仅减少了训练参数,还在保证准确率的情况下提升了训练效率。文献[12]提出一种网格化的编解码网络架构,通过对不同网络层特征图的编码、解码工作,学习特征图与不同人群密度间的映射关系,实现对高密度人群的估计。上述方法虽然都实现了对人群密度的估计,并且模型准确率和效率也都在不断提升,但都是基于单个视觉场景的实现。
单个视觉场景下,多数人群密度估计模型无法覆盖整个场景,例如一般很难在宽阔的站房空间内或狭长的列车站台上,利用单个视觉场景获得准确的全局信息。为解决这种宽广区域下的人群密度估计问题,需要同时配置多路摄像头,通过视野上的重叠即采用多视角融合的方法,尽量减少由环境遮挡造成的估计误差,实现对整个目标场景的覆盖。在这一研究领域,文献[13]在对多视角目标人群特征图提取的基础上,采用贝叶斯估计的方法对行人进行计数,该方法对于稀疏场景(即图像中的行人图像独立完整、无遮挡)有较好的效果,但没有解决行人间遮挡严重情况下的人群计数问题。文献[14]采用特征图投影方法解决人群遮挡问题,在城市十字路口下通过对位于人行道的多路视频图像进行投影融合,实现对整个路口的人群密度估计,但该应用场景下的行人数量较少,尚不知对于高密度人群的密度估计效果。
基于上述各类人群密度研究方法的优点和目前在超大视觉场景下人群密度估计的局限性,本文在归纳铁路客站内人群密度特点的基础上,提出1种多视角特征图投影融合的人群密度估计模型,主要包括多视角特征图提取处理和多视角特征图投影融合处理2个部分。首先,通过特征金字塔网络实现旅客图像的多尺度特征图提取,并引入注意力机制进一步丰富旅客人群特征信息;其次,将二维的多视角旅客人群特征图投影到三维地面坐标系,并进行投影融合,实现铁路客站大视野、复杂场景下旅客人群密度的估计;最后,通过训练选定的公开数据集和自行构建的数据集,完成本文模型与当前同类先进模型在性能上的对比。
1 铁路客站内旅客人群视频图像特点
铁路客站特别是新建的高铁客站普遍具有站房结构庞大、站内场景布置复杂多样的特点,站房内部除了主要的安检区、检票区和候车区,还分布有大量的商铺、巨型广告牌、站内引导牌、列车时刻表大屏等设施设备。由此,实践发现站内旅客人群视频图像处理中存在如下5个特点,这些特点进一步放大了站内旅客的目标识别难度,从技术可行性、模型有效性等方面给人群密度估计工作的开展带来挑战。
(1)旅客人群分布不均。站内旅客人群聚集在时间上的分布是不均匀的,并且人群聚集密度会随着不同检票口发车时刻信息的变化而动态变化[15]。例如,发车前30 min内旅客会在检票口附近区域高度聚集,而其他未检票的候车区域,旅客的人群密度则相对稀疏,如图1所示。

图1 站内旅客不均匀分布场景
(2)旅客人群遮挡明显。视频图像中,旅客人群在站内明显会受到各种类型的遮挡,这种遮挡又可进一步分为静态遮挡和动态遮挡2类。静态遮挡主要指站内设施设备对旅客的遮挡,以及旅客因坐、卧等静态姿态造成的相互遮挡;动态遮挡指旅客进站、排队检票和站内购物等过程中,短时间内旅客被站内设施设备遮挡,以及因走动造成的相互遮挡[16]。典型的站内旅客人群遮挡场景如图2所示。

图2 站内旅客人群遮挡场景
(3)图像中旅客尺寸差异大。摄像头视角下,由于不同旅客与视频监控摄像机的距离远近不一,以及不同旅客的站内行为姿态不一,会造成视频图像获得的旅客尺寸大小相差较大,特别是在利用图像估计人群密度时,长宽均小于50个像素单位的小尺寸旅客往往难以被识别检测,如果不对图像进行处理就直接开展人群密度估计,准确率会受到较大影响。
(4)图像背景复杂。对视频图像进行处理时,通常需根据识别任务目的对图像进行背景与前景人像分离。针对旅客进行人群密度估计时,以站内旅客为前景、以站内容易形成遮挡的设施设备为背景,很容易看出图像背景环境复杂多样,既有立柱等站房自身结构,又有座椅、闸机等固定物,还有广告牌、商铺等可能不定期更换位置的设施,这些遮挡物会在一定程度上影响人群特征提取的准确性,对图像背景识别过程中的泛化能力提出了较高要求。
(5)站内光线影响识别。铁路客站一般站房宽敞宏大,为保证室内采光充足,通常会通过宽大的落地窗和天窗引入自然光。自然光线的变化会导致部分摄像头有时处于逆光状态,有时局部光线过强甚至导致视频图像过曝或死黑,无法进行图像细节的分析与识别。此外,光滑地面产生的反射也会造成类似影响。
2 模型构建
针对上述铁路客站内旅客人群密度场景图像的特点,构建多视角特征图投影融合的人群密度估计模型(以下简称为“MVPFCC模型”),主要包括多视角特征图提取处理和多视角特征图投影融合处理2个部分。在多视角特征图提取处理时,设计图像特征提取器,对多路视频图像分别进行多尺度特征提取;在得到不同尺寸旅客图像信息的基础上,通过特征对齐、融合及注意力机制(Attention)处理后得到注意力密度特征图。在多视角特征图投影融合处理时,先将多路视频图像的注意力密度特征图通过空间投影变化,使其从二维平面特征图转化为三维地面坐标系下的投影特征图,然后再对多路投影特征图进行融合,得到投影融合特征图并在此基础上完成人群密度估计。
2.1 多视角特征图提取处理
2.1.1 旅客视频图像多尺度特征提取
由旅客人群视频图像的特点可知,站内的复杂背景特征对小尺寸的旅客特征提取影响较大。为确保不同尺寸的旅客特征尽可能都被提取到,构建模型时考虑采用多尺度特征提取特性较好的特征金字塔网络(Feature Pyramid Network,FPN)[17]作为预训练网络,这样能够在特征提取时确保对站内摄像头视角下不同位置旅客,特别是镜头远端小尺寸旅客图像信息的有效提取,在此基础上,通过对融合特征图进行注意力机制[18]处理,实现对旅客特征的重定位。
以站内3个不同位置摄像头的多视角视频图像特征提取为例,其具体提取过程如图3所示。首先利用特征金字塔预训练网络,按照256×256,128×128,64×64,32×32,16×16等不同尺寸,对原始图像进行旅客图像特征提取[19];接着通过最邻近上采样操作,将不同尺寸特征图均按照最大尺寸(即256×256)进行上采样特征对齐;然后将对齐后的特征图进行相加得到融合特征图,同时采用3×3大小的卷积核进行处理,消除多层特征融合中带来的重叠效应;最后为提高旅客人群识别效果,对融合特征图进行注意力机制处理,实现基于背景图像和前景人像的语义分割,得到注意力密度特征图(Attention Map,AM)[20]。
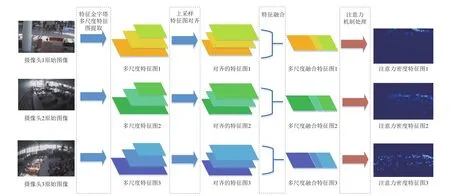
图3 多视角特征图提取处理过程
2.1.2 特征图注意力机制处理
为减少图像特征提取时因站内复杂背景带来的信息干扰,使模型更专注于旅客人群信息的获取,多尺度特征图提取过程中引入了注意力机制处理模块,将融合特征图处理为注意力密度特征图,实现了融合特征中背景环境信息和旅客特征信息的自动分类过滤[21]。在特征金字塔网络预训练过程中,模型学习不同尺寸特征图对应的权重,在后续的站内背景目标和旅客人群目标分类时据此对各局部特征图做出分类判断,并将结果表现为隐藏非重点信息(即环境特征信息)、只显示关键目标特征信息(即前文旅客人群信息)的形式,从而达到对关键信息形成注意力的效果,进一步提高模型准确率[22]。
在对站内旅客人群特征图引入注意力机制的处理时,由于只需对背景和人群特征信息进行提取分离,可通过分类激活函数将其归纳为二分类问题,具体处理流程如图4所示。图中:Fb和Fc分别为用于提取背景和人群的特征层;Wb和Wc分别为特征图在经过全局平均池化后得到对应背景特征图和人群特征层的平均权重矩阵;Pb和Pc分别为Wb和Wc在经过分类激活函数处理后得到的背景和人群的置信度,表示当前该像素点被判别为背景图像或旅客图像的概率大小,Pb,Pc∈[0,1],当Pb取0时表示像素点被判定为背景图像,当Pc取1时表示像素点被判定为旅客图像;⊙和⊕分别为矩阵的乘法和加法运算;蓝色箭头表示背景特征分类分支,由Fc与其置信度Pc相乘得到,同理黄色箭头为人群特征分类分支。在分别完成背景、人群特征提取分离后,2个通道特征层相加得到新的特征图层,即注意力密度特征图。
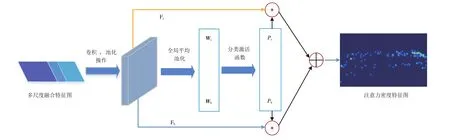
图4 特征图注意力机制处理流程示意图
2.2 多视角特征图投影融合处理
常见的多视角图像投影融合处理方式可分为以下3种:①无特征提取,直接对原始图像先投影再融合;②原始图像进行特征提取后,对特征图先投影再融合;③原始图像进行特征提取后,对特征图先融合再投影。实验表明:采用第1种方式会损失大量的图像信息,对后期的人群密度估计会有很大的影响;采用第3种方式会在融合过程中损失较多特征信息。本文采用能够保留大多数特征信息,对后期的密度估计影响较小[14,23]的第2种方式。经过图3中多视角特征图提取处理后,对得到的特征图源(注意力密度特征图)进行特征图投影融合,具体过程如图5所示。
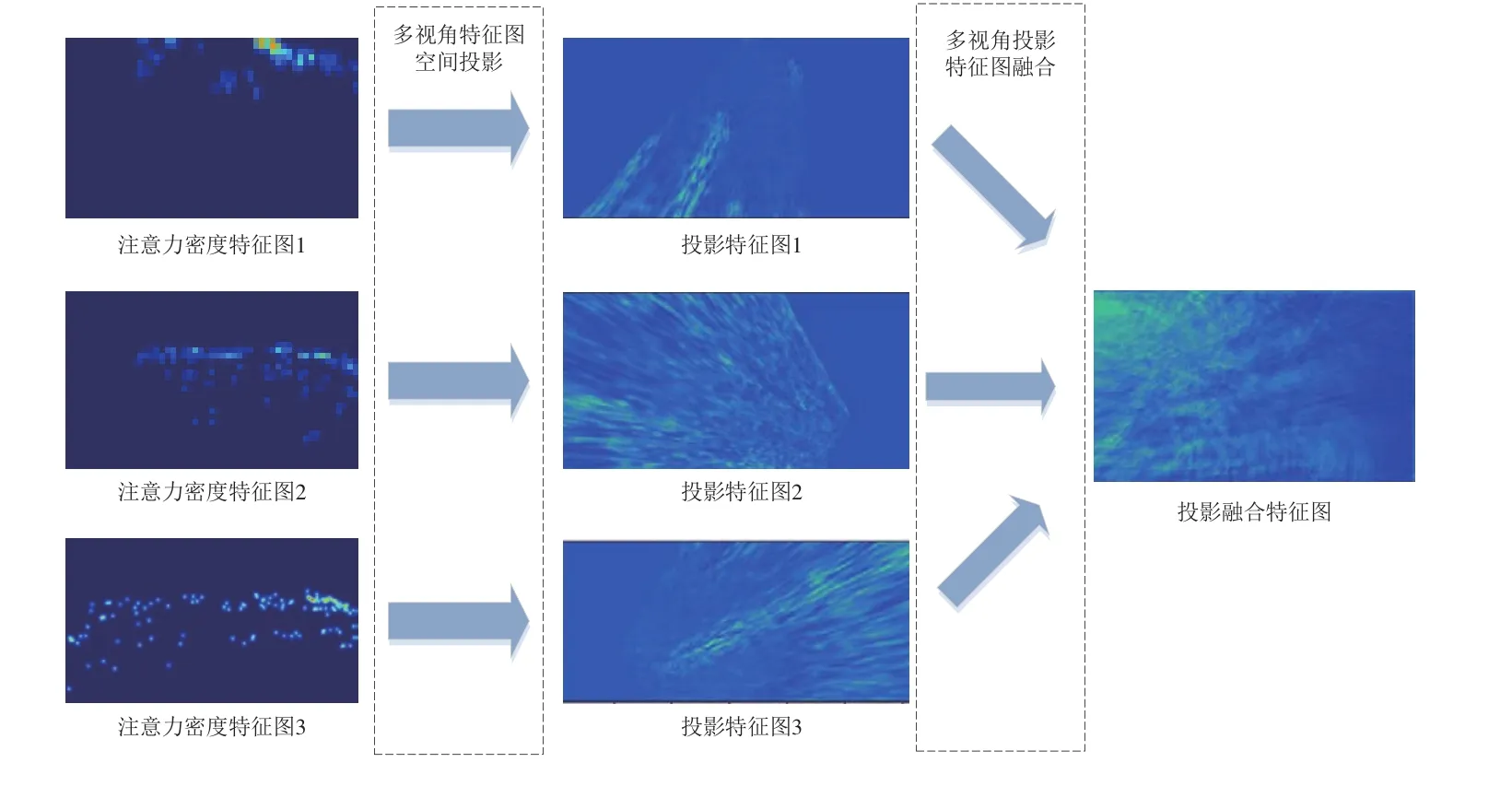
图5 多视角特征图投影融合过程
1)多视角特征图空间投影
特征图的投影过程是将二维的注意力密度特征图投影到三维空间的地面坐标系中。由于视觉投影中的参考坐标系发生变化,在投影变化前,要对各个摄像头进行内参和外参的标定,以此确定二维图像坐标与三维地面坐标系的映射关系。本文采用张氏标定法[24]实现对多个摄像头的内参和外参标定,具体的计算过程略,直接使用标定后的参数。
视觉投影变化过程基于像素点在三维坐标(x,y,z)和二维图像的像素坐标点(u,v)之间进行的仿射变换,通过矩阵的增广运算实现不同维度下的坐标转换[25],即二维坐标向量和三维坐标向量中均增加1行行向量,并全部填充为1。
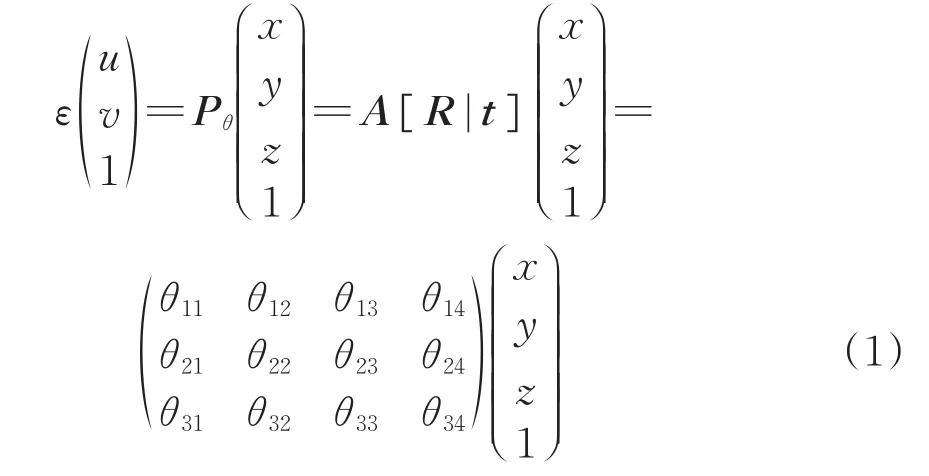
式中:ε为实数比例因子;Pθ为大小为3×4的视角变化参数矩阵;A为3×3的内参矩阵;R为旋转变换矩阵参数;t为平移变换矩阵参数;[R|t]为3×4大小的旋转平移变换矩阵(外参矩阵)。
将旅客人群密度特征图从二维坐标投影到三维地面坐标系的过程中,为最大程度减小因遮挡造成的人群密度估计误差,考虑将坐标系下所有坐标点的z值设为零,即将所有像素投影坐标点变为(x,y,0),得到特征图的投影特征图。具体变化过程由式 (1) 中矩阵Pθ与空间向量(x,y,0,1)通过矩阵乘法运算得到,即
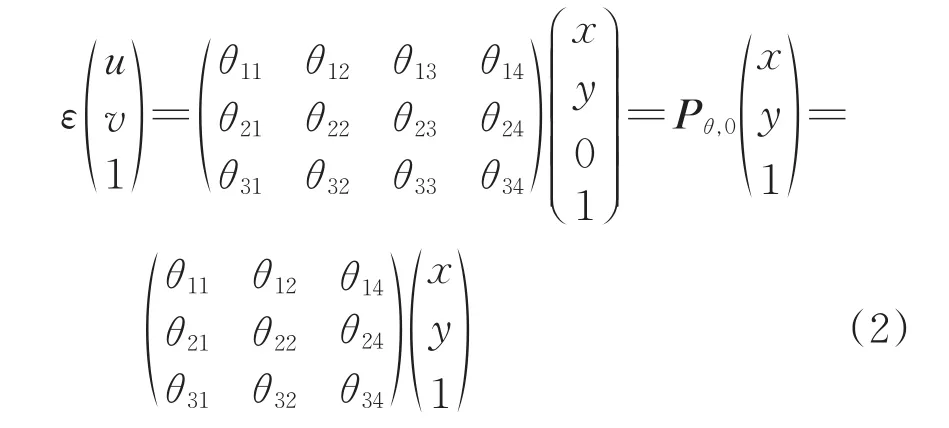
式中:Pθ,0为二维图像投影到地面坐标系下尺寸为3×3大小的视觉变换矩阵。
2)多视角投影特征图融合
投影融合过程比较简单,将不同投影特征图通过矩阵加法运算得到即可。由于在特征图投影过程中,二维坐标下的部分特征图会发生形变,在特征图投影融合后进行密度图估计时会造成一定误差损失,因此融合后的特征图通过大卷积核的空洞卷积减小这一误差,使最后的特征图尽量与标注值接近[23,26],同时,大卷积核处理还可最大限度地保持多视角融合过程中空间信息。
2.3 多视角特征图投影融合密度估算
在模型训练学习时,需要大量的训练数据集样本图像及对应的人群标注信息。训练数据集的原始图像标注文件包含了人群目标个体的位置像素坐标,在标注过程中,多以目标旅客头部的1个点作为对应的1个标注目标。在实际模型训练开始前,首先根据训练数据集中的标注文件信息,将样本图像转化为单视角标注密度图,之后才能参与模型的学习训练过程,然后经过特征提取、注意力密度图生成、多视角的特征图投影以及投影融合等一系列操作,生成最终的投影融合密度估计图。
1)单视角标注密度图生成
对于训练数据集中的样本图像,其对应的标注文件由图像中的旅客头部标注信息构成,其中每条标注信息均由1个稀疏矩阵表示。通过高斯核函数将该稀疏矩阵转换为二维密度图,估计过程为
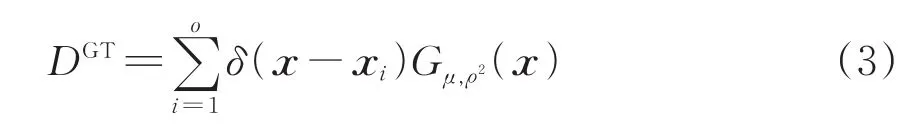
式中:DGT为标注图像生成的人群密度特征图;xi为标注图像中第i个旅客的头部坐标点;δ(x−xi)为表示xi位置的冲击函数,通过自由变量x条件变换确定标注对象是否存在;o为标注图像中人头数;Gμ,ρ2(x)为高斯核函数;μ为确定头部大小的参数;ρ为标准差值。
2)注意力密度特征图生成
完成多尺度特征提取之后会得到多尺度融合特征图,经过注意力机制处理,实现站内背景和人群特征信息的分离,式(4)即为2类特征层二分类实现过程的主要函数。
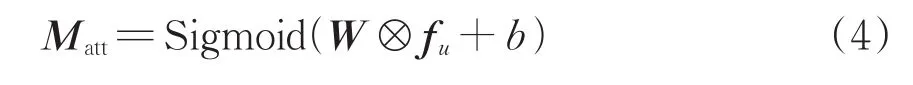
式中:Matt为注意力密度特征图;Sigmoid(·)为激活函数,输出值范围[0,1];W和b分别为注意力模块处理过程中的网络权重和偏差值;fu为多摄像头特征提取后的融合特征图;⊗为卷积过程。
3)多视角特征图投影融合特征图生成
根据式(4)得到不同视角图像的注意力密度特征图,在此基础上分别进行特征图投影变化,即

在完成投影后进行投影特征融合,得到最终的投影融合特征图Rf为

式中:R(·)为最终的投影特征图融合函数。
2.4 模型损失函数设计
在关于人群密度估计模型的诸多研究中,最常见的是采用欧氏距离损失函数作为训练收敛目标的网络训练优化过程。本文在这一传统损失函数的基础上作了进一步优化。
首先,利用欧式距离进行误差反向传播的损失函数设计,即
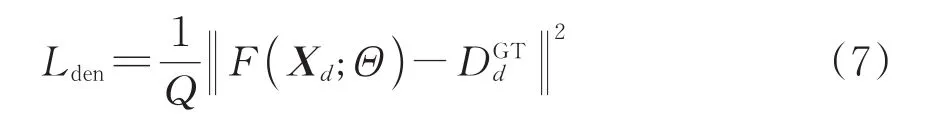
式中:Lden为欧式距离损失目标函数;Q为样本图像个数;F(Xd;Θ)为第d个输入图像通过模型生成的密度估计特征图;Xd为输入的第d个样本图像矩阵;Θ为网络中需要学习的参数集合;为对应样本图像的标注图像的人群密度特征图。
其次,在Lden的基础上考虑到在对特征图进行注意力机制处理时,实际上进行的是背景与人像的像素级语义分割过程,因此用Latt表示该步操作对真实的密度图产生的误差损失,这一损失过程可以通过二分类的交叉熵进行表示,即
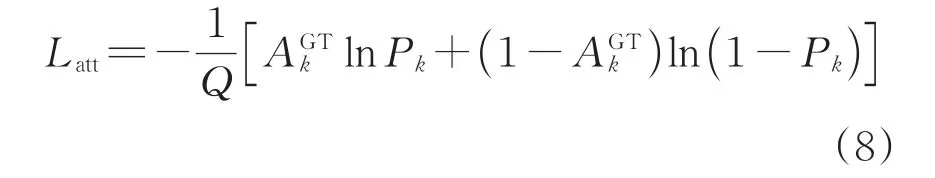
最终,损失目标函数Lcon可由2个损失函数共同决定,其整体即为模型的误差反向传播损失函数

在迭代次数有限的模型训练过程中,当Lcon达到最小值时,模型表现为局部最优。
3 实验与验证
完成模型的算法框架设计后,需要进一步对其效果进行验证。先通过训练选定的公开数据集和自建数据集,对比MVPFCC模型与当前同类先进模型在均值绝对误差上的性能差异,并验证模型中注意力机制模块的应用效果;再通过平均损失值这一指标,考察MVPFCC模型的收敛效果,验证梯度策略设置的合理性;最后依托实际的京张高铁清河站应用场景,验证模型对人群密度估计的有效性。
3.1 数据集
模型训练采用了2个不同数据集,其中1个是公开发布的用于多视角融合密度估计的城市街道数据集[14](CityStreet);考虑到公开的多视角数据集较少,同时也为验证模型对实际应用场景的支持程度,还自行构建了基于客站多摄像头的清河站数据集(QingheStation)。2个数据集的视频图像数据均满足多个视角交叉且能覆盖监控区域的场景要求,同时每个数据集中的训练数据集、验证数据集和测试数据集都按照7∶1∶2的比例从各数据集全样本中随机抽取生成。
1)城市街道数据集
该数据集由香港城市大学计算机视觉团队研究多摄像头行人密度时制作发布,数据来自位于香港市中心某十字街道附近的5个同步摄像头,主要用于对过往的道路和行人状态进行监控。
数据采集时选取其中3个有视野交集的摄像头,在同一时间点进行图像的同步采样,得到各摄像头下的视频图像500帧,分辨率为2 704像素×1 520像素,每帧图像中的人群规模在20~50人左右。为便于后续实验开展,对同一时刻下不同视角图像中的相同目标进行旅客位置和序号标注,以保证同一时刻出现在3个视频中的同一旅客具有相同的序号。
2)清河站数据集
该数据集来自站房结构宽敞高大、站内布设上百个摄像头的清河站,先选取视野有交集的9个摄像头进行同步采样,再筛选出视野交集较多且各路视野恰好可合成1个更大感受野的3个摄像头,以同步采集得到的数据作为样本源。
数据采集时同步截取各摄像头在不同时间段的视频图像500帧,分辨率为1 080像素×1 920像素,每帧图像中的人群规模在20~100人之间。各摄像头下的图像同样进行旅客位置和序号的唯一性标注。
3.2 训练细节
考虑到内存限制要求和数据集的图像分辨率,先对原始图像(1 080像素×1 920像素)进行下采样,将得到的图像按照720像素×1 280像素大小作为输入图像。在特征提取过程中,采用以残差网络ResNet50为骨干的特征金字塔网络,得到特征提取的通道数λ=512;运用空洞卷积代替步长卷积,通过720像素×1 280像素大小的输入图像得到8倍下采样率的特征图。
多视角投影融合过程中,在投影前对多视角注意力密度特征图采用线性插值方法,将其特征图大小调整为270像素×480像素大小。待完成特征图投影融合后,采用卷积核大小为3×3的3个卷积层(空洞卷积率分别为1,2,3),分别对2个数据集生成基于3个摄像头的多视角特征投影融合密度图。模型的总体网络结构如图6所示。图中:J1—J5均为原始图像经过特征提取器卷积操作后得到不同的卷积层;S2—S5均为对应的卷积层经过上采样得到的特征层;箭头表示神经网络参数前向传输过程。
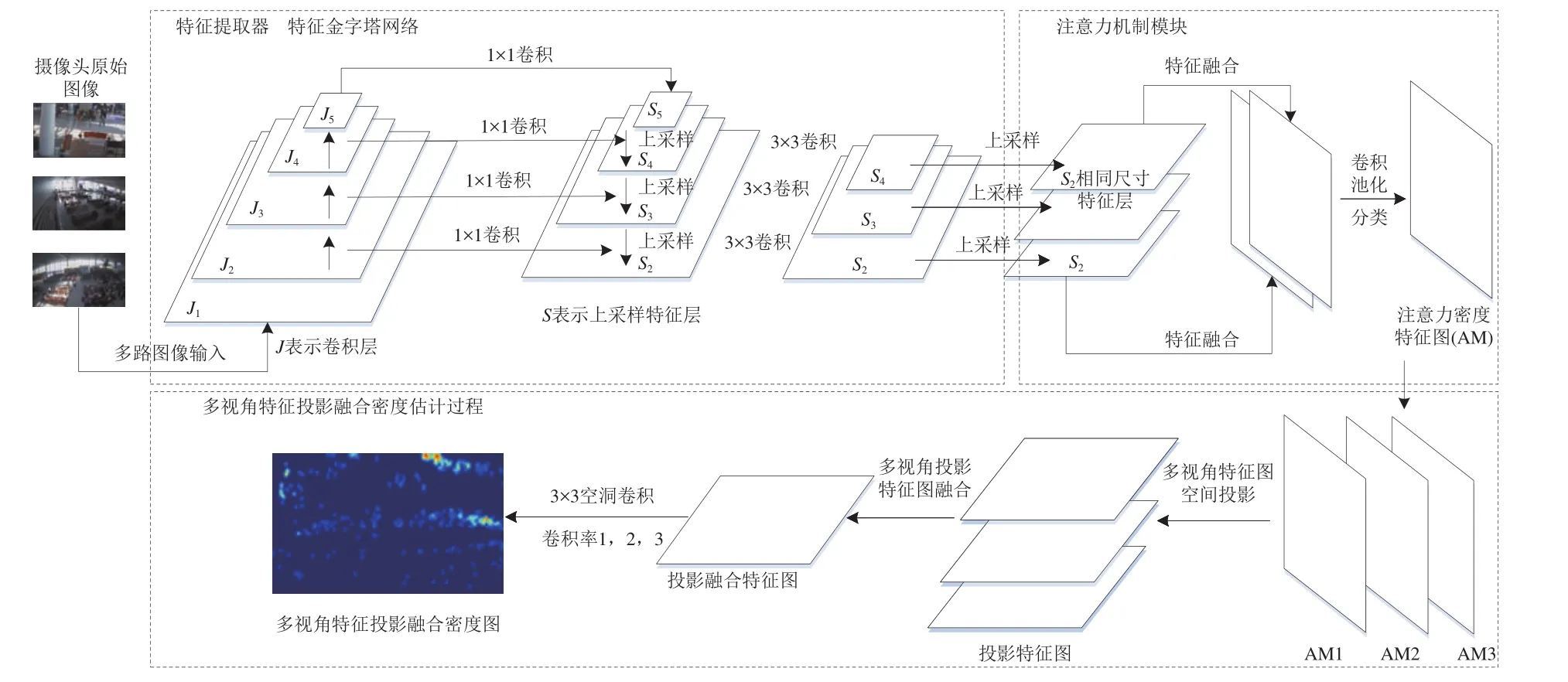
图6 多视角特征图投影融合的人群密度估计(MVPFCC)模型网络结构
模型训练时,采用的实验硬件环境为1台GPU服务器,配有4块型号为GTX-1080TI的GPU加速卡,服务器系统环境为Linux Ubuntu 18.04,深度学习模型框架版本为pytorch 1.4和CUDA 10.1,编译器编译运行环境版本为python 3.7。
考到训练时可能会在随机梯度下降(Stochas⁃tic Gradient Descent,SGD)的优化过程中出现对局部最优的限制,模型采用Adam优化器,根据一般神经网络训练中梯度下降经验,设动量值为0.5,L2正则为5×10−4;考虑模型训练中样本批处理数量会受内存的限制,设最大学习率为0.1,单次迭代的样本量为4,训练迭代循环共900次。
模型训练完成后,采用均值绝对误差Smae和均方差Smse对模型在测试数据集上进行具体评估[22]。Smae通过对样本的预测值与标注值差异的平均值反应预测结果的准确性,Smse通过样本预测值与标注值的差异的波动程度反应模型的鲁棒性,两者的具体定义为
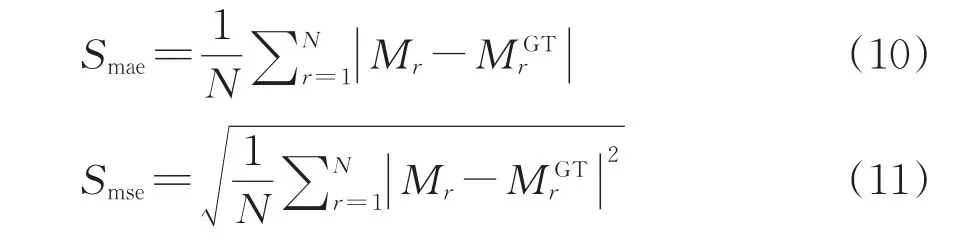
式中:N为测试数据集中的样本图像数量,个;MGTr为第r个样本图像经过标注数据计算而成的人群密度标注值,人;Mr为第r个样本经过模型输出的特征图所计算生成的人群密度估计值,人。
3.3 结果验证
3.3.1 模型效果对比
实验时,为进一步体现本文MVPFCC模型中注意力机制模块的应用效果,先将其分为2种版本进行对比,分别是带有注意力机制模块的MVPF⁃CC(标准)模型,以及去掉注意力机制模块后的MVPFCC(no Attention)模型;再将2种MVPF⁃CC模型与香港城市大学在发布CityStreet数据集时提出的多视角融合密度估计模型[14](MVMS模型)进行对比。以均值绝对误差Smae和均方差Smse作为对比指标,3个模型经过CityStreet和Qingh⁃eStation这2个数据集训练后的结果对比见表1。需要注意的是,因视角融合的数量维度差异,验证MVMS模型性能时仅在CityStreet数据集使用了Smae这1项指标评估样本预测值与标注值的误差结果。
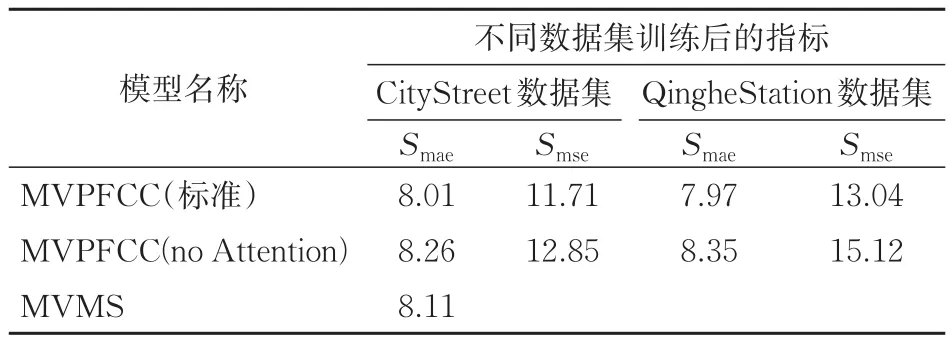
表1 3个模型经过不同数据集训练后的指标对比
由表1可知:经过CityStreet数据集训练后,3个模型在Smae指标下的对比结果为MVPFCC(标准)模型最优、MVMS模型次之、MVPFCC(no At⁃tention)模型最后,2种MVPFCC模型在Smse指标下的对比结果为MVPFCC(标准)模型优于MVPFCC(no Attention)模型;经过QingheSta⁃tion数据集训练后,MVPFCC(标准)模型总体优于MVPFCC(no Attention)模型;对比结果表明在多视角融合的人群密度估计模型设计中,引入注意力机制是有效的。
经过QingheStation数据集训练后,2种MVPF⁃CC模型的Smae和Smse指标随迭代次数变化的曲线分别如图7和图8所示。由图7和图8可知:经过900次迭代训练后,MVPFCC(标准)模型在2种指标下的曲线收敛情况均优于MVPFCC(no At⁃tention)模型,进一步佐证了注意力机制对模型的优化作用。
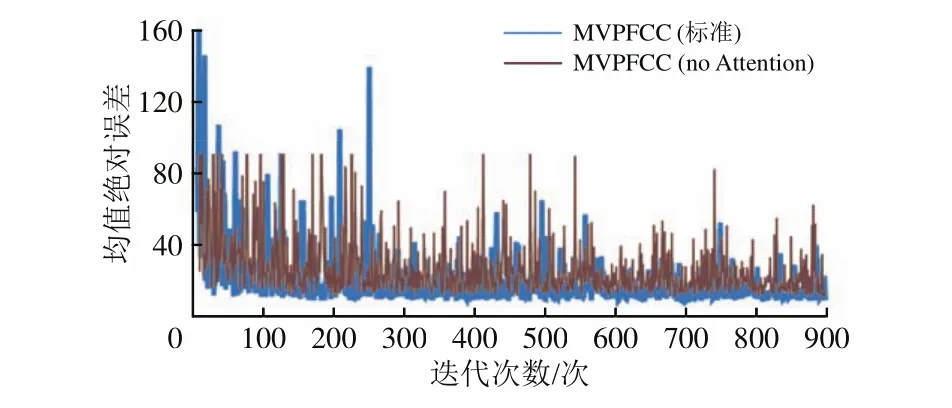
图7 2种MVPFCC模型的训练结果均值绝对误差Smae对比
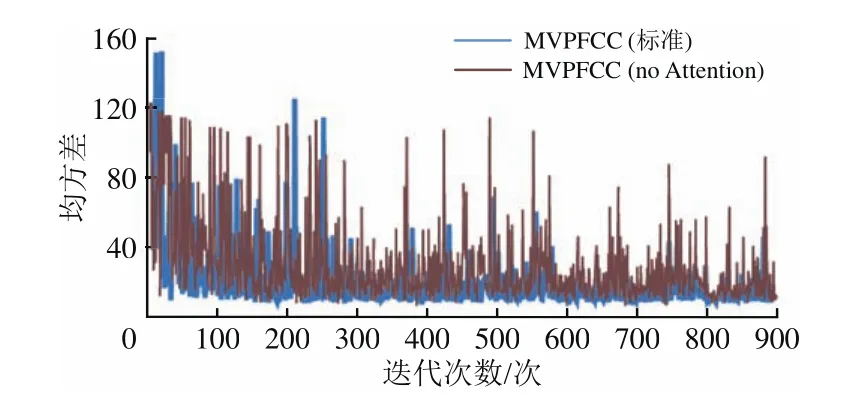
图8 2种MVPFCC模型的训练结果均方差Smse对比
模型在训练过程中,通常还会用到平均损失值这一指标来反映模型的整体收敛情况。MVPFCC(标准)模型平均损失值随迭代次数变化的曲线如图9所示。由图9可知:经过QingheStation数据集训练后,MVPFCC(标准)模型平均损失值随迭代次数的增加整体呈收敛趋势;迭代最初,平均损失值梯度迅速下降,迭代200次左右梯度下降逐步稳定,趋于平缓,说明损失函数、学习率、动量参数等梯度策略设置合理,模型收敛效果较好。
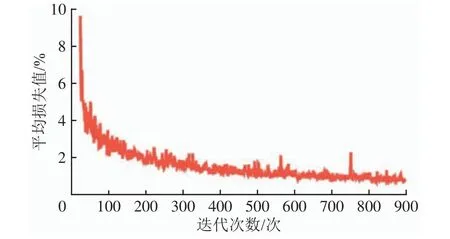
图9 MVPFCC(标准)模型经过QingheStation数据集训练后的平均损失曲线
3.3.2 实际应用场景下的模型有效性验证
MVPFCC(标准)模型经过QingheStation数据集训练后会生成新的网络模型权重,在此基础上,通过测试数据集样本图像进行密度估计可以验证模型在实际应用场景下的性能效果,验证过程中该模型基于3个不同视角视频图像准确估计人群密度。具体估计过程如图10所示。图中:B1−B3为各输入样本标注值,由DGT通过积分计算得到;E1−E3分别为单个注意力密度图的估计值,由Matt通过积分计算得到;T为多视角特征图融合后得到的区域内人群密度估计值,由Rf通过积分计算得到。由图10可知:输入3个不同视角下的视频样本图像后,经过样本标注数据的可视化处理,可得到对应的样本标注密度图,样本再经过多尺度特征提取以及注意力机制处理后,形成对应的注意力密度特征图,3个注意力密度特征图经过投影融合,最终生成多视角投影融合密度图;对单视角样本特征经过注意力机制处理后,得到的注意力密度估计值与对应样本的标注值基本接近。多视角特征图投影融合密度图估计值准确地反映了3个不同视角下的视频样本图像标注值总和,验证了多视角特征图投影融合密度估计模型的有效性。

图10 MVPFCC(标准)模型对多视角融合的旅客人群密度估计过程
4 结语
本文根据归纳得到的实践中铁路客站内旅客人群视频图像特点,基于特征金字塔网络预训练模型,结合计算机视觉领域中的注意力机制、图像特征投影和图像特征融合思想,提出了1种多视角特征图投影融合的人群密度估计模型,可用于铁路客站内旅客的目标识别。该模型能够对站内多路有视觉交叉的旅客视频监控图像进行多尺度特征提取和特征投影融合处理,将多视角下的旅客特征图融合成1个整体特征图并进行密度估计,实现站内更大视野范围内的人群密度感知。通过某公开数据集和基于清河站的自建数据集训练模型,证实模型引入的注意力机制模块是有效的,模型梯度策略设置合理,收敛效果较好,能够在清河站实际应用场景下,基于3个不同视角视频图像准确估计人群密度。然而,模型在多视角投影融合过程中,只考虑了采用大尺度卷积核减少融合误差,没有对具体的误差损失进行定量分析,下一步,考虑以投影融合误差估计为改进方向,重新设计优化损失函数,在误差损失的反向传播过程中,增加投影融合过程中旅客人群图像特征信息损失计算方法,从而在大量的学习训练过程中,以不断降低整体损失为目标,缩小模型预测值与真实值之间的差距,从而实现模型预测准确性的提升。此外,可以对自建数据集样本进一步丰富,扩大样本容量和标注数据,在此基础上不断学习有助于模型泛化能力的提升。
本文模型不仅适用于铁路客站,还可用于其他视频监控有视觉交叉的超大视野场景下的人群密度估计,如机场候机大厅、地铁站台等大型公共场所。
