融合可解释性特征的糖尿病视网膜病变自动诊断
2022-05-31蒋杰伟雷舒陶耿苗苗巩稼民朱泽昊张运生刘芳吴艺杰王育文李中文
蒋杰伟,雷舒陶,耿苗苗,巩稼民,,朱泽昊,张运生,刘芳,吴艺杰,王育文,李中文
1.西安邮电大学电子工程学院,陕西西安 710121;2.西安邮电大学通信与信息工程学院,陕西西安 710121;3.温州医科大学宁波市眼科医院,浙江宁波 315000
前言
据国际糖尿病联盟的统计数据显示2019年全球糖尿病患者数量约为4.63 亿人[1]。2020年中国糖尿病患者数量也已达到1.298亿人[2]。糖尿病患者血液中的高血糖浓度会导致视网膜血管的渗透性发生变化,进而演变为糖尿病视网膜病变(Diabetic Retinopathy, DR),预计1/3 的糖尿病患者会引发DR[3-4]。传统诊断需要经验丰富的眼科医生才能得到可靠的结果,诊断效率较低并且存在主观差异性。使用以深度学习为代表的计算机视觉技术进行DR辅助筛查可以减轻眼科医生的工作量并提高工作效率,缓解眼科医生数量不足的现状。
深度学习技术与医学图像处理的结合已经有了显著的成果,在彩色眼底图像DR 自动诊断方面也有很好的表现,其中集成学习的方法被广泛应用[5-6]。Abidalkareem 等[5]通过限制超参数范围的方式生成多个结构不同的卷积神经网络(Convolutional Neural Networks, CNN),最后集成10 个不同CNN 进行DR病变程度分级诊断,原始数据集经图像增强算法扩大到20 000 张训练图像,该集成方法取得了93.2%的诊断准确率。Gadekallu 等[7]先将DR 数据标准化并使用PCA 减少冗余信息,再通过GWO 算法选择DNN 网络最佳超参数,相对于传统机器学习分类器有更好的诊断表现。Al-Turk 等[8]结合U-Net 和CNN识别DR 病理特征,采用基于特征的方法实现多种分级标准下的DR 诊断任务,训练集共有60 000 张图像,该方法最高Kappa 系数为85.7%。Elswah 等[9]使用线性核函数的支持向量机(Support Vector Machine, SVM)对CNN 网络提取的特征进行分类,数据集共有516 张图像,最终诊断准确率为86.67%。He 等[10]在CABNet 模型中提出类别注意模块解决类别间数据分布不均衡问题和全局注意模块捕获微小DR 病变信息,由此提高模型诊断性能,训练集共包含13 673 张图像,提出的方法在Messidor 数据集上取得了93.1%的诊断准确率。Hemanth 等[11]用直方图均衡和自适应直方图均衡的方法处理彩色眼底图像,有利于模型分类性能的提升。Hemalakshmi等[12]使用MS-DRLBP 方法对预处理后的眼底图像进行边缘特征和纹理特征的提取并融合图像的均值方差等特征,最后使用径向基核函数(Radial Basis Function, RBF)网络分类。Zhou 等[13]公开了文章中使用的数据集FGADR,共包含2 842 张图像,在分类任务中通过多尺度迁移连接MTC的方式整合分割网络中的特征,并使用DSAA模块减小分类网络和分割网络特征的差异,增强分类模型提取特征的能力,最终DR 诊断准确率为86.03%。Holmberg 等[14]使用不同的医学模态图像训练CNN 网络,再将模型参数迁移到DR 分级任务,论证了ResNet50 模型在9 790 张不同模态图像下可达到35 124 张单模态图像的分类性能,其最高Kappa得分为79.1%。
前人对DR 检测所作的大量的工作中,高性能的DR 检测模型均需要依靠足够多且图像质量高的训练数据集,但是在实际中较难得到大量由专业眼科医生标注的高质量DR 眼底图像,针对质量参差不齐的小样本DR 眼底图像,自动诊断算法具有很高的应用价值但也是不小的挑战。
1 方法
本文收集的眼底数据集来自多个社区医院,数据量偏少,由于医生的从业经验和操作规范性有差异,导致获取的眼底图像质量有差别。如图1 所示,部分图像存在着不同程度的模糊或曝光不充分问题。针对这些问题,本文提出一种融合模型可解释性特征的集成学习方法,利用CNN 模型的可解释性技术在原始图像上生成病灶区域(微动脉血管瘤、出血、软渗出、硬渗出)或血管标记的可解释图像,融合生成图像和原始图像的特征,以此提高DR 诊断的准确性。

图1 彩色眼底图像示例Figure 1 Examples of color fundus images
本文提出的融合可解释性特征的DR 自动诊断网络如图2 所示,主要由3 部分组成:可解释性图像生成、特征提取和融合、自动分类。可解释性图像生成:首先使用原始数据集训练基础CNN-Basic 网络,再使用导向梯度加权类激活映射图(Guided Grad-CAM,GC)[15]和显著图(Saliency Map,SM)[16]方法生成具有可解释性特征的SM 数据集和GC 数据集,最后利用这两个生成的数据集训练CNN-SM 和CNNGC 模型,其中3 个CNN 都是带有迁移学习的ResNet50 模型[17]。特征提取和融合:首先去除训练好的CNN-Basic、CNN-SM、CNN-GC 模型的全连接层,提取最后一层卷积的输出特征图,再使用全局平均池化(Global Average Pooling,GAP)将特征图变成特征向量,最后线性串联以融合3个模型提取的特征向量。自动分类:本文使用线性核函数SVM 作为融合特征的DR 分类器[18]。SVM 是一种广泛使用的二分类监督学习模型,求解能以最大几何间隔划分样本类别的超平面。相比于RBF 核函数,线性核函数SVM 不需要寻优、效率高,且能更好地处理高维向量,本文中3 个特征融合后的向量维度为6 144×1,线性核函数更适于融合后的DR 特征,同时本文也对比了线性和RBF核函数的性能差异。
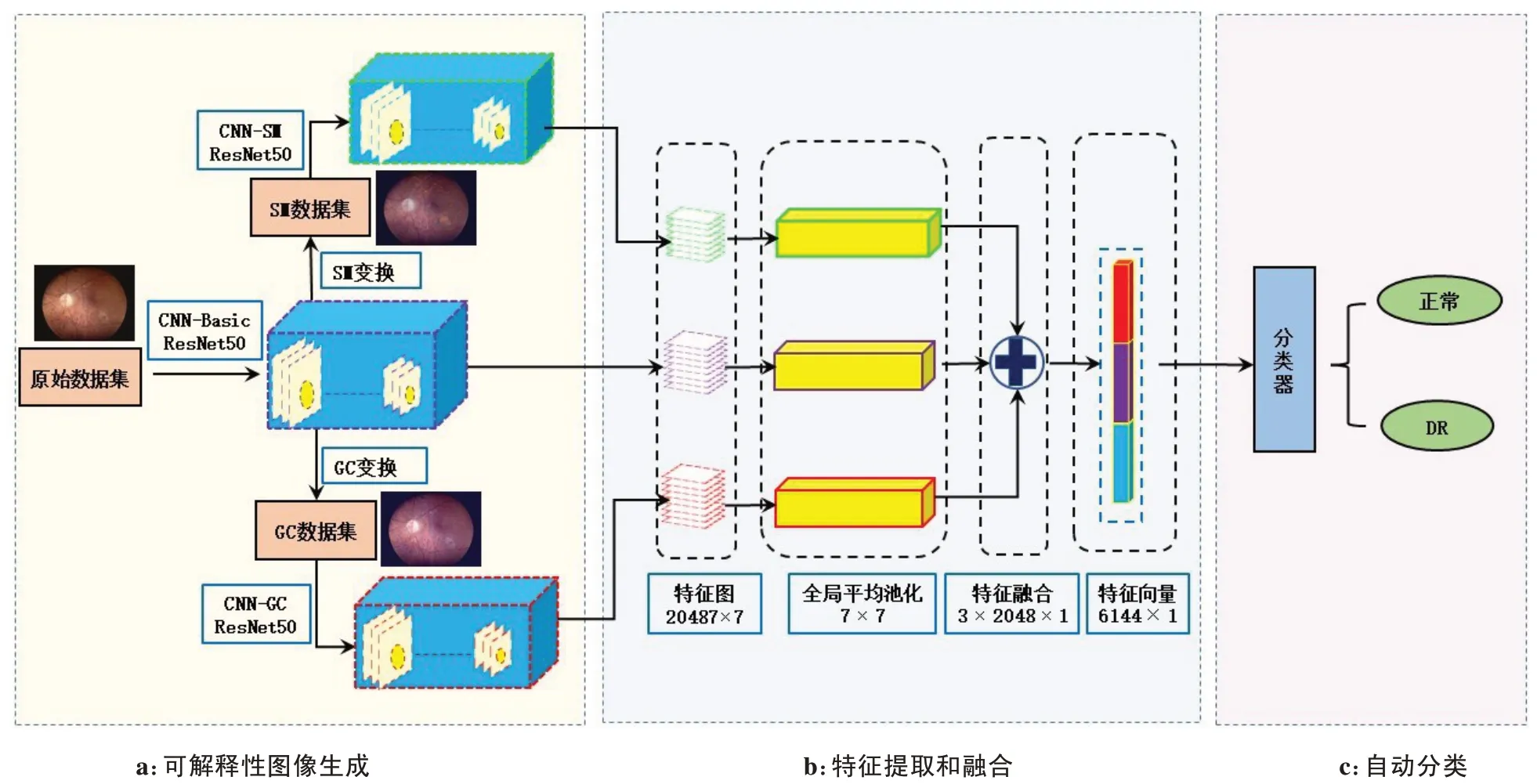
图2 融合可解释性特征的DR自动诊断网络框架图Figure 2 Diabeticretinopathy automatic diagnosis network framework diagram after interpretable features fusion
1.1 DR可解释性图像的生成
基于两种主流的解释性模型GC 和SM,从分类输出回推到输入的图像,在输入图像上标注出与分类结果相关的病灶(微动脉血管瘤、出血、硬渗出、软渗出)区域或血管,即自动标注出模型分类的判别依据,GC和SM均能在像素级别给出合理的解释。
GC是结合梯度加权类激活映射(Gradient-weighted Class Activation Mapping,Grad-CAM)和导向反向传播[19](Guided Backpropagation,GB)优点的一种可解释性生成方法,Grad-CAM的特征映射图是指定类别的特征区域,GB可以在像素级别表示所有类别的判别特征,Grad-CAM和GB从不同侧面给出了诊断相关联的特征区域。GC的核心思想是通过权重叠加CNN网络最后一层卷积的输出特征图生成可解释性图像,第p张特征图Rp的权重rip求解如式(1)所示:

其中,S表示特征图Rp的总像素点个数,vi表示第i个类别得分,Rpxy表示Rp的第xy像素点的值,通过反向传播求得,再使用全局平局池化求得rpi。根据加权系数叠加所有的特征图,计算过程如式(2)所示:

通过修正线性函数(The Rectified Linear Unit,ReLU)仅保留特征图中值为正的分量,小于零的分量对分类判别没有贡献,从而保留对第i类有贡献的像素值,即模型判别的依据。通过插值的方法将gi扩展到与输入图像相同的尺寸,再与GB 图像对应点相乘得到类激活映射图,最后把类激活映射图与原图像叠加生成GC。
SM 方法是根据类别得分通过反向传播得到输入图像的梯度,用输入图像的梯度值表示对应像素点在分类判别中的贡献。具体地,假设在分类任务中第t个分类的得分和输入图像X的映射关系为Pt(X),在复杂的CNN 网络中Pt(X)是非线性的映射关系,为了方便,把Pt(X)作一阶泰勒展开得到式(3):

将图像X变换成一维向量,则权重向量ωT的值表示像素点对分类得分的重要性,对于输入图像X0,将式(3)对X求导可得:

通过式(4)可得图像X0的每个像素点对分类贡献的大小,利用反向传播算法可得到ω。将输入图像的梯度与对应的原始图像叠加即得到SM。
1.2 DR特征融合
CNN 在图像特征提取方面具有较强的性能,它使用多层卷积,每个卷积层由多个不同的卷积核组成,不同的卷积核从不同侧面提取与输入图像相关的特征,通过滑动窗口方式感受输入图像的局部特征。卷积层之后的池化层能有效降低特征冗余和模型计算量,进一步使用非线性激活函数以拟合复杂的规律。经过多层的特征提取将输入图像转化为特征图,有效表达输入图像蕴含的信息,从而CNN把图像抽象特征转化为可供机器计算的数字化特征。特征提取流程如图2b 所示,首先将原始图像、GC 图像和SM图像缩小到224×224,送入ResNet50,去除模型的全连接层,提取输入图像的特征图,ResNet50 输出特征图的尺寸为2 048×7×7,然后使用7×7 的GAP 把输出特征图转化为2 048×1 维的特征向量,最后将3个网络提取的特征向量通过线性融合的方式,得到6 144×1维的特征向量。
2 结果与分析
2.1 数据集
本文使用的彩色眼底图像来自于宁波市鄞州区多个社区医院,由温州医科大学宁波市眼科医院从业6年以上的3 位高年资眼科医生标注。数据集总共包括1 443 张彩色眼底图像,其中正常眼底图像873 张,621 张作为训练图像,252 张作为测试图像,DR 图像570 张,432 张作为训练图像,138 张作为测试图像,训练集总共1 053 张图像,测试集总共390 张图像。在模型训练之前对训练图像作随机水平翻转、垂直翻转和旋转操作,以扩增训练集。
2.2 实验配置
实验环境配置为:Ubuntu16.04 LTS,8 块Nvidia GeForce RTX 2080 Ti GPU,Nvidia Driver 418.87.00,CUDA 10.1,CUDNN 7.6.4,Pytorch 1.6.0,Python 3.7.9。训练过程的参数如下:3 个CNN 网络都基于ImageNet数据集的预训练模型[20],总迭代次数为160次,batch size 为64,动量为0.9,使用动态学习率,初始学习率为0.001,每迭代40 次,学习率降为原来的1/10,优化目标函数为交叉熵损失函数。
2.3 实验结果
实验结果的性能评价指标为精度(Precision)、特异性(Specificity)、灵敏性(Sensitivity)、准确率(Accuracy)和Kappa 系数,计算方法如式(5)~式(10)所示。其中,真阳性(True Positive,TP):表示分类标签为DR 且分类结果是DR 的样本;假阳性(False Positive,FP):分类标签为正常但分类结果为DR的样本;真阴性(True Negative, TN):分类标签为正常且分类结果为正常的样本;假阴性(False Negative,FN):分类标签为DR 但分类结果为正常的样本。N是测试集的总样本数。

经过GC和SM 可解释性方法处理后的眼底图像如图3 所示,对于正常类别的眼底图像,生成了少量轻微的标记,生成图和原始图像的差异性很小,对于DR 眼底图像,在病灶区域生成了表示DR 类别特征的标记,被深色标记的像素区域是模型分类判别的依据,生成图像和原始图像存在部分差异,融合可解释性特征后可为DR诊断提供新的特征。
图3a为原始图像,DR图像右侧的两张小图表示的是两块不同的出血病灶区域,由图3b可以看出,GC方法可以有效地对黄框内的病灶生成标记,而对蓝框内的病灶区域没有生成可解释特征,由图3c可以看出,SM方法对蓝框内的病灶区域做出了有效标记,而黄框内的病灶区域没有生成可解释特征。GC方法和SM方法对图3a中的DR眼底图像生成了互补的可解释性特征。相对于原始图像的特征,3种图像特征融合后,特征向量包含了互补全面的病灶区域信息。
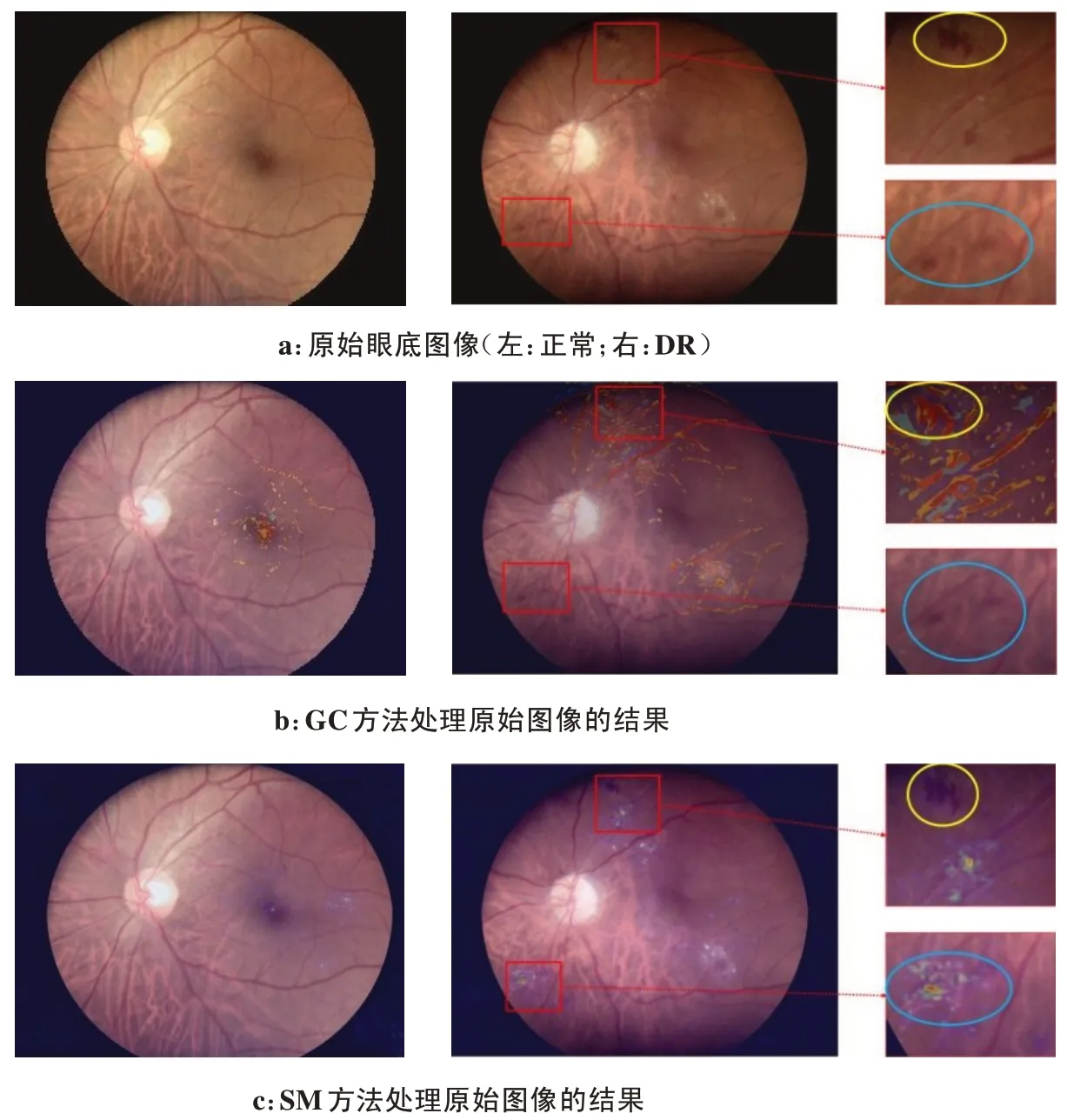
图3 经过GC和SM方法处理的眼底图像示例Figure 3 Examples of fundus images processed by GC or SM
T分布随机邻域嵌入法[21](T-distributed Stochastic Neighbor Embedding,T-SNE)是一种非线性的流形学习法。在特征向量的分布概率保持不变的情况下,可将高维空间中的点映射到低维空间。图4 是提取的正常和DR特征向量在利用T-SNE降维方法后在二维特征空间中的分布图,3个基础网络提取的特征向量在二维空间中的可分性都不强,但它们之间有着不同的分布,结合3 个基础特征向量的差异,融合后的特征向量在二维空间上具有较强的可分性(图4d)。
图5a是4种不同模型(CNN-Basic、CNN-GC、CNN-SM、SVM-Linear)的接受者操作特性曲线[22],其中,CNN-Basic训练集为原始图像,CNN-GC训练集为GC图像,CNN-SM训练集为SM图像,SVM-Linear是融合可解释性特征后的线性核函数SVM分类器。
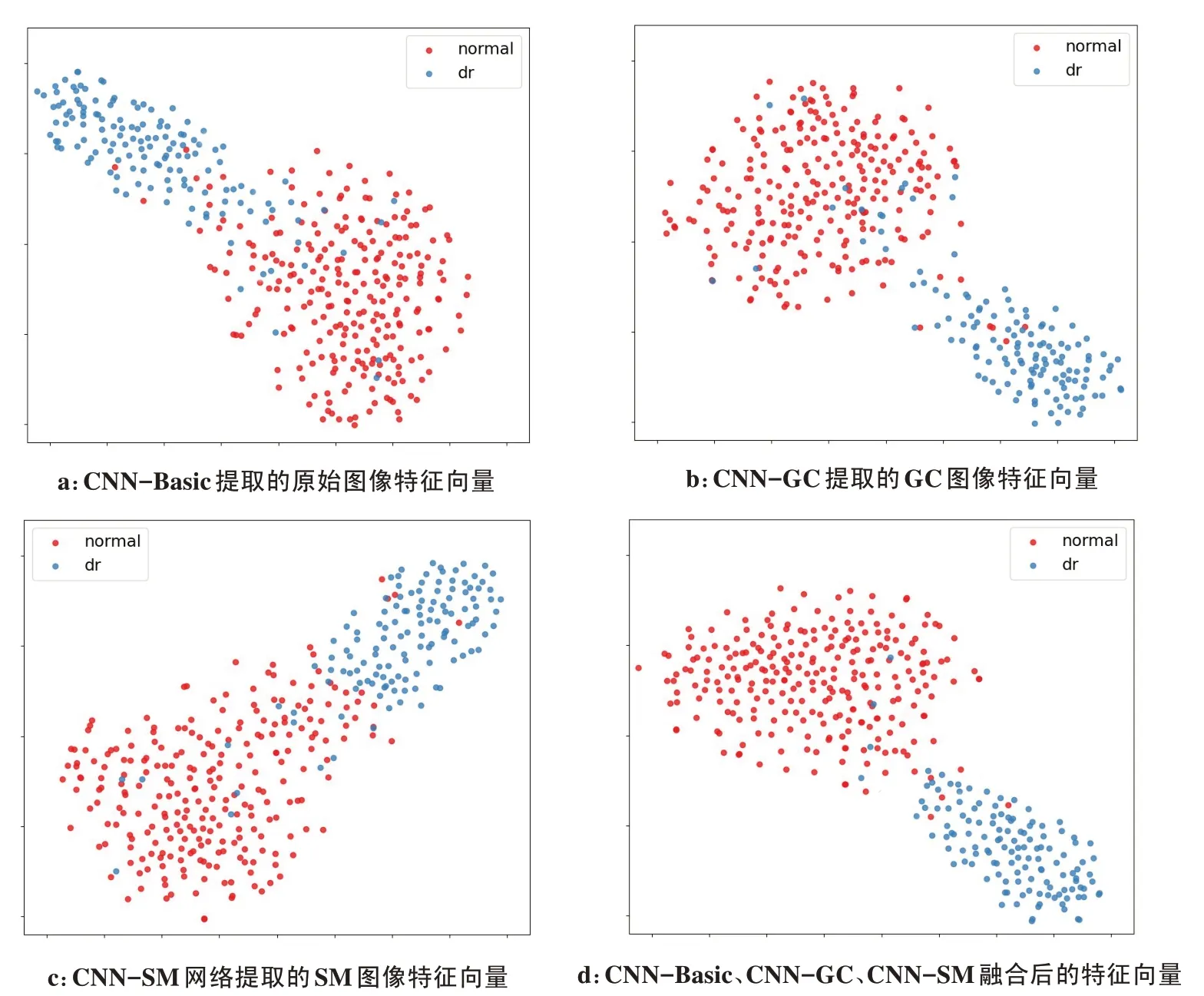
图4 基于T-SNE的特征向量在二维空间上的可分性比较Figure 4 Comparison of the separability of feature vectors based on T-SNE in two-dimensional space
SVM-Linear具有最大的AUC 值为 0.968, 95% 置信区间[23](Confidence Interval, CI)为0.943~0.987。上述4 个模型的PR 曲线如图5b 所示,线性核函数SVM 有最大的PR 曲线下方面积。SVM-Linear 在ROC 曲线和PR 曲线中都有最好的表现,相对基础CNN-Basic 模型,融合可解释性特征后的SVM-Linear可大大提升DR诊断的性能。
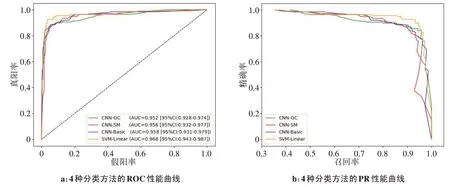
图5 基础模型和特征融合后分类器的性能曲线Figure 5 Performance curve of the classifier in basic model and after features fusion
更详细的实验结果如表1 所示,其中CNN-Basic表示使用原始图像作为训练集的ResNet50 网络,SVM-Linear 表示融合了可解释性特征和线性核函数SVM 的模型,SVM-Linear 在所有的评价指标上都优于CNN-Basic 模型,并且其准确率提高3.6%,精度提高4.6%,特异性提高2.4%,灵敏度提高5.8%,Kappa得分提高7.9%,由此可见融合可解释性特征的方法可有效地提升DR 诊断的性能。Vote-CNNs 是基于CNN-Basic、CNN-GC 和CNN-SM 的投票集成分类模型,利用3个基础模型的分类结果采用少数服从多数的原则。Average-CNNs是使用平均得分的集成分类模型,首先分别取出3个基础模型全连接层特征经过Softmax 后的输出概率,再将正常和DR 类别概率分别累加并求均值,最后利用平均后的概率值进行分类。相较于CNN-Basic方法,两种集成学习方法在正常类别的判定上具有更好的表现,其特异性提高2.0%,在DR 类别的判别中,诊断性能无明显提升。此外,相对于基础CNN-Basic 网络,使用RBF 的支持向量机SVM-RBF 在DR 诊断中特异性提升2.8%、灵敏度提升4.4%。
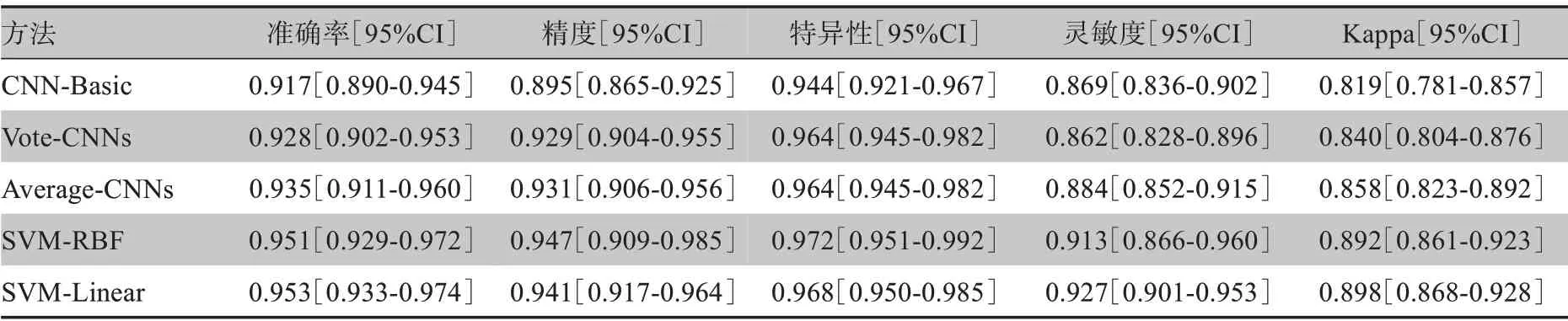
表1 不同集成方式的分类结果Table1 Classification results of different ensemble methods
Vote-CNNs 和Average-CNNs 的集成学习策略仅将分类结果进行线性组合,无法有机结合CNN 提取的特征,而特征对分类结果的影响较大。本文所提融合可解释性特征的方法从两个角度提高了诊断性能:一是生成的可解释性图像提供了病灶的互补信息;二是融合可解释特征后,特征向量在特征空间中形成了更有利于分类器判别的分布。此外,本文对比了两种不同核函数SVM 在糖网诊断上的表现,其中,SVM-RBF 使用网格遍历寻优法确定了最优的参数惩罚因子C值为0.5,核函数系数gamma 值为0.001 953。在融合可解释特征后的高维特征向量(6 144 维)上,线性核函数SVM-Linear 和非线性核函数SVM-RBF 在糖网自动诊断上的性能差异较小,但SVM-RBF 的参数寻优需要消耗大量的时间,SVMLinear 不需要寻优,时间消耗较少,在效率和性能之间进行折中,本文最终选择线性核函数SVM 为最优的模型。
此外进一步对模型性能作了评估,将图2中CNNBasic由ResNet50更改为Densenet121,模型性能参数如表2所示。相对于基础模型Densenet121的诊断性能,本文所提出的特征融合方法结合SVM-Linear和SVMRBF分类器都能提高诊断性能,其中SVM-Linear方法准确率提高3.4%,灵敏度提高8.7%,Kappa 系数提高7.7%,精度和特异性也有小幅度提升。SVM-RBF方法与SVM-Linear方法性能接近,准确率提升3.6%,精度提高2.8%,灵敏度提高8.0%,Kappa系数提高8.2%,精度指标高于SVM-Linear方法。基础模型ResNet50在数据集上的表现优于Densenet121,本文所提出的方法对于两种基础模型都能带来诊断性能的提升。

表2 改变CNN-Basic后的分类结果Table 2 Performance indicators after changing CNN-Basic
3 总结
本文提出一种融合可解释性特征的分类器,可有效提升DR 自动诊断的性能。在基于原始图像训练的ResNet50 基础网络上,使用GC 和SM 可解释性模型生成有类别特征标注的图像,提供互补的病灶信息,然后融合原始图像和生成图像的特征,由分类器实现DR 自动诊断。相比集成学习方法和径向基核函数SVM 方法,融合可解释性特征方法结合线性核函数SVM 在DR 诊断上有更好的性能。下一步,我们将改进可解释性方法,以生成更细致的图像可解释性标注,寻求更优的分类器结合方式,探究其他不同的特征融合方法以进一步提升DR诊断的性能。