基于限制平均生存时间的样本量计算方法比较*
2022-05-28杨紫荆巫宏基黄宝仪张成凤侯雅文
原 皓 杨紫荆 巫宏基 黄宝仪 张成凤 侯雅文 陈 征△
【提 要】 目的 探究Royston-KM、Royston-FP、Luo三种基于RMST方法及log-rank在样本量估计方面的异同。方法 通过模拟符合比例风险假设、前期开口、后期开口及交叉4类8种生存曲线情形,比较样本量估计及对应检验效能的差异,并通过实例说明RMST在样本量计算时的应用。结果 比例风险假设成立时log-rank最优;存在前期差异时,Royston-KM与Luo效果较好;后期开口时,Royston-FP效果最佳;如果出现交叉,则应根据交叉点前后生存曲线间面积差异分类讨论。结论 估计样本量时,如果比例风险假设成立应选择log-rank,反之应根据不同生存曲线类型选择最优方案。
样本量计算是随机临床试验(randomized clinical trial,RCT)中的一个重要环节,特别是对于生存数据,由于其资料的特殊性,如数据参数分布不明、存在删失数据等,该类试验的样本量计算一直为临床试验中样本量计算的难点。生存数据样本量计算最常用方法之一为log-rank法[1]。但该方法在比例风险(proportional hazard,PH)假设不成立时检验效能较低[2-4],样本量估计值不稳定。此时可基于限制平均生存时间(restricted mean survival time,RMST)估计样本量[5-7],该方法无需满足PH假设,在非PH下的样本量估计较为稳健。本文介绍基于风险率的log-rank法、基于RMST的Kaplan-Meier法(Royston-KM)、灵活参数(Flexible parameter)法(Royston-FP)及Luo法等四种样本量估计方法,并对其进行模拟比较,最后通过一个治疗胃部或胃与食管处恶性腺瘤三期临床试验的实例比较其在实际应用中的差异。
方法介绍
1.基于风险率的log-rank样本量估计
比较两组生存数据是否存在差异时常用log-rank检验,Rubinstein等提出对应的两组总样本量估计公式[1]。
(1)
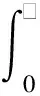
2.基于RMST的Royston-KM、Royston-FP样本量估计
假设生存时间T为右删失数据,选择限制时间点τ,限制平均生存时间RMST[8]为t=0到τ的生存曲线下的积分
假设基于KM估计的试验组和对照组的生存函数分别为SKM1(t)和SKM0(t),那么两组RMST的差值为
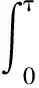
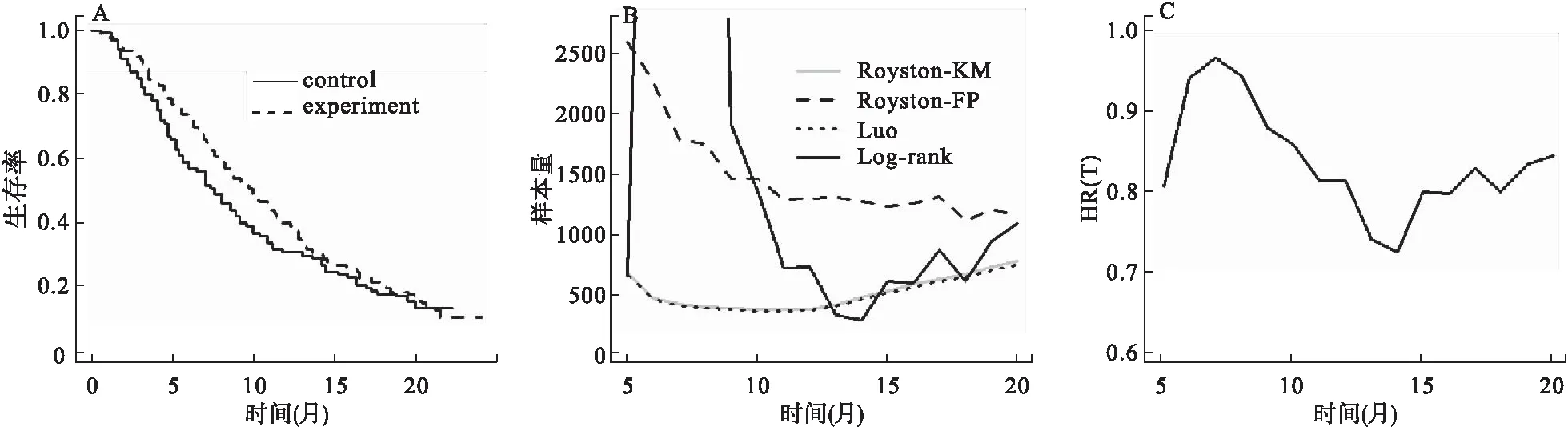
假设t(1)j (2) 该方法记为Royston-KM。此外,Royston等[8-9]提出基于灵活参数的方法,Royston-FP。在对生存函数SFP(t)及时间进行对数转换后,二者呈现较为平滑的线性关系,此时生存函数可表示为 其中lnζ与ψ分别为lnt的位置参数与尺度参数。Royston-FP使用三次样条函数来平滑对数累计风险,由极大似然法估计RMST,通过bootstrap模拟其方差,其样本量计算公式与(2)相似。 3.基于RMST的Luo样本量估计 Luo等根据研究总时长与τ计算RMST与方差[10]。假定事件时间、删失时间均服从分段指数分布,选取时间t′(如总研究时间)与τ并且t′不小于τ,此时第j组RMST估计为 其中,I(·)成立时为1,反之为0;SLj为第j组的生存函数,0=y0,j 其中,rj(u,t′)=SLj(u)CLj(u)GLj(t′-u),SLj、CLj、GLj、λLj分别为第j组的事件函数、删失函数、入组函数、风险率。那么两组所需总样本量为 (3) 为比较不同生存曲线情况下上述四种方法的异同,设定4类8种生存曲线情形(图1):比例风险假设成立、生存曲线前期开口、生存曲线后期开口及生存曲线交叉,每类下分别取两种参数设定情况,具体参数设定如表1所示。 图1 18种生存曲线图像 表1 生存曲线参数设定 设定对照组生存时间服从中位生存时间为10个月的指数分布,试验组生存时间服从分段指数分布。两组人群的删失时间均服从相同的指数分布。模拟设定入组时间为24个月,试验共进行50个月,τ取40个月。选取α为5%,检验效能为80%,两组样本量相等。采用Monte Carlo模拟计算每种情形下4种方法所需样本量及其对应的检验效能,模拟次数设定为5000次。 模拟结果如表2所示。在PH假设成立时,log-rank所需样本量最少,且可达到80%检验效能;基于RMST的三种方法所需样本量基本相当,但Royston-KM检验效能略微低于80%。如果PH假设不成立,基于log-rank估计所得样本量反推的检验效能均未达80%,基于RMST的三种方法反推的检验效能均在80%附近,此时基于RMST估计样本量较为稳健。当前期差异存在时,Royston-KM与Luo所需样本量小于Royston-FP,但Royston-KM反推所得检验效能略低于80%。如果存在后期差异,Royston-FP所需样本量小于Royston-KM与Luo。当生存曲线出现交叉时,不同交叉情形需具体讨论。第7种情形中,交叉点后面积大于交叉点之前,Royston-FP效果较好;第8种情形中恰好相反,此时Royston-KM与Luo效果较好。在所有以上所模拟的情形中,Royston-KM与Luo所需样本量基本相等。 表2 四种方法所需样本量(事件数)及对应检验效能 我们选取一项治疗胃部或胃与食管处的恶性腺瘤三期临床试验[11],试验组使用雷莫芦单抗与紫杉醇、对照组使用安慰剂与紫杉醇。该试验中试验组330人,对照组335人,共516人死亡(77.6%)。生存曲线图像如图2(A)所示。 图2 不同显像结果患者生存曲线、所需样本量及两组HR(τ) 估计生存分析的样本量时,如果两组风险率符合PH假设,可选择经典的log-rank法,其检验效能最高且所需样本量最少;基于RMST的三种方法所需样本量基本一致。如果生存曲线存在前期差异,可选择Royston-KM或Luo,两种方法效果相近且效果较好。存在后期差异时可选择Royston-FP,其效果优于Royston-KM与Luo。当生存曲线出现交叉时,如果交叉点前两条生存曲线面积差值较大,此时可看作“前期差异”,可使用Royston-KM或Luo;若交叉点后两条生存曲线面积差值较大,此时可看作“后期差异”,可使用Royston-FP。 在实例分析中,根据不同τ时间点截断的数据计算的HR(τ)变化较大,此时基于风险率的log-rank估计所得样本量不稳定。基于RMST的Royston-KM与Luo所需样本量呈现明显的先减小后增大的趋势:两条生存曲线属于前期差异,后期两条生存曲线差异逐渐减小,在τ=11月之前,随着τ增加,Royston-KM与Luo所需样本量逐渐减小,但后期由于两条生存曲线逐渐靠近,随着τ的增加,所需样本量逐渐增加。由于Royston-FP首先根据所有生存患者的生存曲线拟合样条函数,而后根据不同τ计算RMST及其对应的方差,因此其所需样本量随着τ的增加而逐渐减小。在实际应用中,τ可选择两组最大随访时间的最小值或根据临床意义来选择[8,12-14]。 在计算样本量时同样可根据event-driven analysis或time-driven analysis[15]进行分类。以上所讨论的方法中,Log-rank及Royston的两种方法均为event-driven analysis,该方法首先设定一定的研究时间,根据所设参数计算所需样本量,当试验纳入计算所得样本量时即可达到预设检验效能;Luo的样本量估计方法为time-driven analysis,即首先纳入一定数量的患者,计算所需研究总时长,随着时间的增加,检验效能提高。当试验进行至计算所得研究时间时即可达到预设检验效能,因此模拟研究中未给出Luo所需事件数。但是,event-driven analysis与time-driven analysis并不是完全独立的,两方法可相互转化。例如,以上log-rank及两种Royston的方法均通过固定研究时间,之后计算所需样本量。为了方便比较,在模拟及实例中Luo法我们同样也固定研究时间,计算所需样本量。此时Luo一定程度上也可看作“event-driven analysis”。 虽然以上每种情形下均可选择最优方法计算样本量,但每种方法仍存在一定不足。Log-rank在PH假设不成立时估计所需样本量偏低,无法达到预设检验效能。Royston的两种方法无法直接获得所需事件数,需通过计算所得样本量与删失率间接获得。如果删失率改变,则所需事件数可能产生波动。Royston-FP首先使用全部生存信息拟合生存曲线的样条函数,而后根据不同计算对应的RMST与方差,此时基于不同τ计算的样本量随着τ的增加而逐渐减小,变化趋势与Royston-KM、Luo不同。由于Luo在计算样本量时未给出所需事件数作为参照,如果随访中删失较多,所获得事件数较少,Luo同样无法达到预设检效能,需延长随访时间以达到预设检验效能。
模拟研究



实例分析
讨 论
