基于多视角图卷积网络的多跳阅读理解模型
2022-05-23贾兆军徐万珺
郑 津,贾兆军,徐万珺,陈 雁,李 平
(西南石油大学 计算机科学学院,四川 成都 610500)
0 引 言
目前研究多跳阅读理解任务的工作中,大多采用流水线式(Pipeline)的求解框架[1],即首先将多跳阅读理解任务进行分解,然后借助问题与文档匹配的检索、命名实体识别、指代消解等自然语言处理技术来逐次解决。例如,Min S等[2]先对问题进行解析,然后利用解析后的问题分阶段进行预测。这类方法对特定的数据集或者任务场景具有不错的效果,但由于模型不够灵活,缺乏通用性,使其难以推广。
本文提出了一种基于多视角和注意力的图卷积网络MV-GCN。在MV-GCN中,主要包括多视角图卷积和多视角注意力两部分。多视角图卷积通过构建多个学习通路,并设置每个通路的参数皆可学习且彼此独立训练,使得在MV-GCN中多通路之间的学习能力形成互补,有利于提取到不同视角的候选实体语义之间的相关关系。多视角注意力利用Squeeze-and-Excitation机制将每个学习通路得到的特征视作基本单位,并通过为其自适应加权的方式来进行多个通路的信息融合。在WikiHop通用问答数据集上的实验结果表明,本文所提的MV-GCN能更有效地学习到多跳实体之间的相关关系,其性能优于当前的主流方法,可为进一步研究提供借鉴。
本文的贡献概括如下:
(1)提出了一个基于多视角和注意力的图卷积网络的多跳推理阅读理解模型MV-GCN,通过实验验证了其性能优于当前的主流方法;
(2)设计了多视角的图卷积通路结构,提高了模型多视角学习多跳实体间语义相关性的表达能力;
(3)构建了自注意力融合结构,可动态地确定不同通路的重要性权重,从而实现多个通路的特征表达的有效融合。
1 研究背景及动机
多跳阅读理解(multi-hop question answering,MQA),也被称为多文档阅读理解(multi-document machine reading comprehension,MMRC),在智能问答[3,4]、多轮对话[5,6]、知识图谱等自然语言处理任务中有着广泛的应用。本文集中研究多跳阅读理解中的答案选择问题,其主要任务是从多篇文档中寻找相关信息,进行线索推理,并从候选实体集合中选择正确的答案。图1展示了WikiHop数据集(Unmasked)中一个真实样本的部分数据,分别为问句以及与问句相关的3个文档、候选实体和答案,任务是从若干候选实体中选出一个正确答案,模型需要在若干不定长的文档中定位相关语句,并在带有干扰的相关语句中找到正确推理信息。多跳阅读理解任务的难点在于如何有效地学习和表达多跳实体间的语义相关关系,因而长期以来是自然语言处理研究领域的热点问题。

图1 WikiHop数据集(Unmasked)的多跳推理示例样本
多跳阅读理解问题的核心是建模和表达多跳实体之间的语义关系,图网络在这方面具有天然的优势。因此,最近的相关工作中提出了基于图神经网络的方法[7,8]。但这类方法仍然面临巨大的挑战,包括:①该类模型大多采用单视角的特征提取方案,即仅采用一个通路来建模多跳实体语义相关关系,使得这类模型学习实体关系表达的角度单一、学习能力有限;②为更好地提取到结点的特征和相关关系,一些工作尝试加深网络深度,但过深的图卷积结构会导致图嵌入表达趋同、过拟合等问题。虽然可以通过引入残差[9]、自注意力[10]等机制缓解,但往往进一步使结构复杂化,出现性能震荡、难以训练,加剧过拟合的风险。
针对现有方法中单视角特征提取通路学习能力不足的问题,受Inception工作的启发,本文提出了基于多视角和注意力的图卷积网络MV-GCN(multi-view graph convolutional network)。值得一提的是,MV-GCN中的多通路结构与原始的Inception有明显区别。首先,原始的Inception主要针对图像识别任务,因而不同通道中卷积核的尺寸设置成不同,以提取和学习不同感受野下的特征。在本文所提出的MV-GCN中,因任务性质不同,每个通路上的图卷积被设置具有相同的结构,但在训练时这些参数并不共享。其次,多个通路所学习到的特征信息需要进行融合。在原始的Inception中是直接将多个通道的特征进行拼接,然后通过1×1的卷积或者pooling来实现融合,其中,默认通道间的权重相同。在本文中,特征提取是在实体图网络上进行,直接套用原始Inception中的融合方法会丢失实体间的拓扑信息。
因此,本文在特征融合处理中引入了Squeeze-and-Excitation(SE)机制[11],设计了一种多视角注意力模块。一方面,通过SE机制可动态地确定不同通路的权重,从而将多个通路的特征表达进行有效融合,另一方面多视角注意力模块是一种自注意力处理结构,这意味着不需要添加繁重的网络结构和太多额外的参数,可有效避免过拟合的风险,易于训练和部署。
2 基于多视角和注意力的图卷积网络
本文所提出的基于多视角和注意力的图卷积网络包含4个模块,包括:①“候选实体-文档”图构建,得到用于表达候选实体与文档之间关联关系的拓扑图,并对候选实体结点的语义特征进行初始化;②候选实体多跳上下文的嵌入表达,基于多个横向通路的图卷积结构来建模结点间的多视角相关关系,并借助SE机制对其进行融合表达,以此学到候选实体的多视角语义特征;③“候选实体-问句”关系映射,利用双向注意力机制,将上一阶段获得的候选实体多视角语义特征与问句特征进行交互,获得候选实体与问句的配对映射关系表达;④答案预测,基于候选实体与问句的配对关系输出最终的答案预测结果。
模型的整体流程如图2所示,接下来对每个模块的具体操作做详细描述。
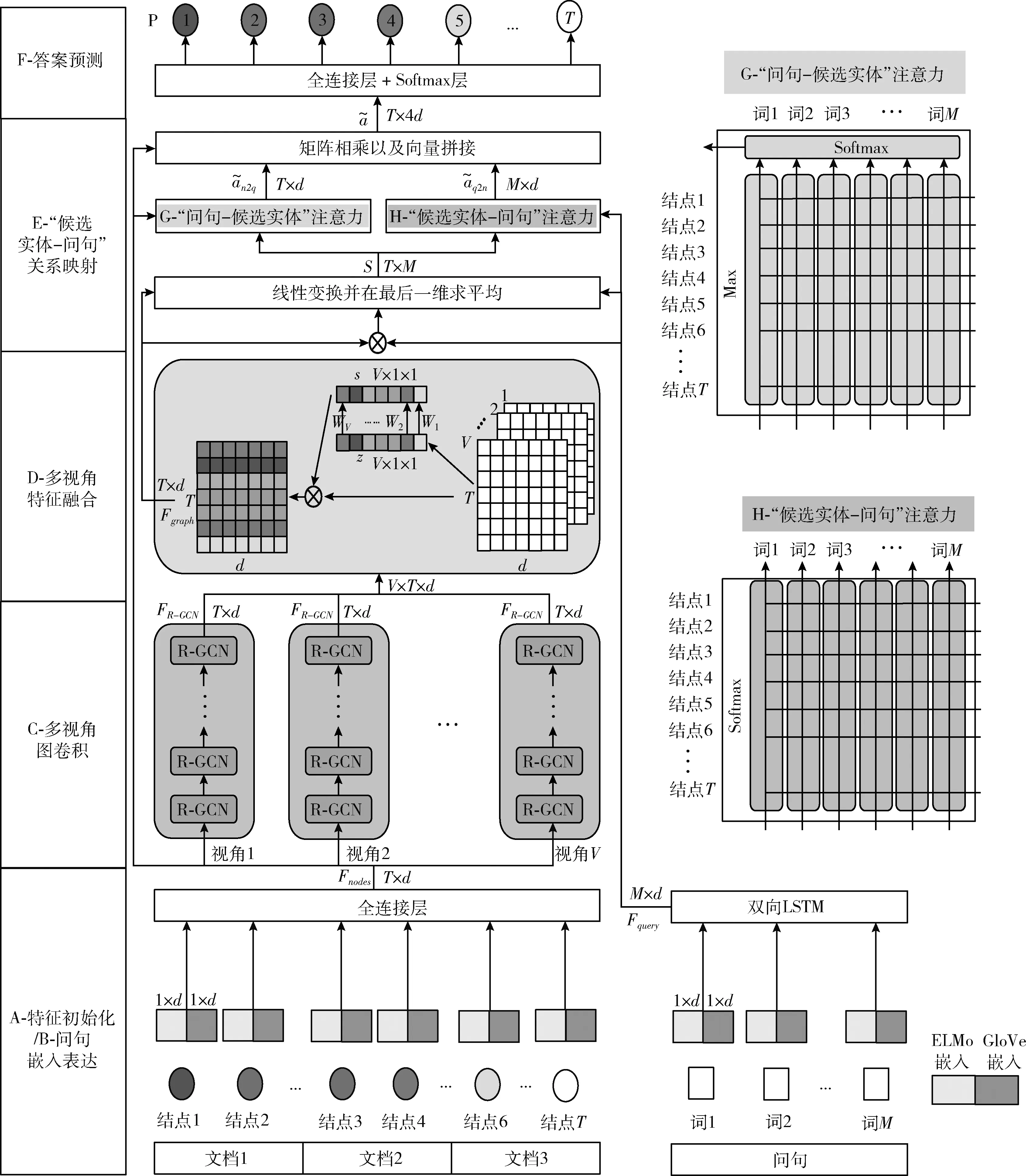
图2 模型整体流程
2.1 “候选实体-文档”图构建
构建表达候选实体与文档之间关联关系的“候选实体-文档”图(以下简称实体图),包括实体图的生成以及结点特征初始化两个方面。
2.1.1 实体图的生成
根据MQA任务的特性,本文选取候选集中的候选实体作为图的结点,结点间用无向边连接,用于表达两种结点间关系[7]。两种结点关系分别为:
(1)一个候选实体多次出现在文档中(包括同一文档或不同文档两种情况),考虑到文档主题和上下文依赖关系的影响,本文中将该候选实体辅以“文档+位置”的索引表示为实体图中的不同结点,并在它们之间设置连边;
(2)两个不同候选实体出现在相同文档中,考虑到同一文档中的语素信息相关,因此在实体图中前述两个不同候选实体间也设置连边。
图3展示了依照图1中示例样本构建的实体图,相同颜色代表了相同候选实体,使用不同的虚线来区分文档内部以及跨文档的结点连边类型,箭头表示推理过程。
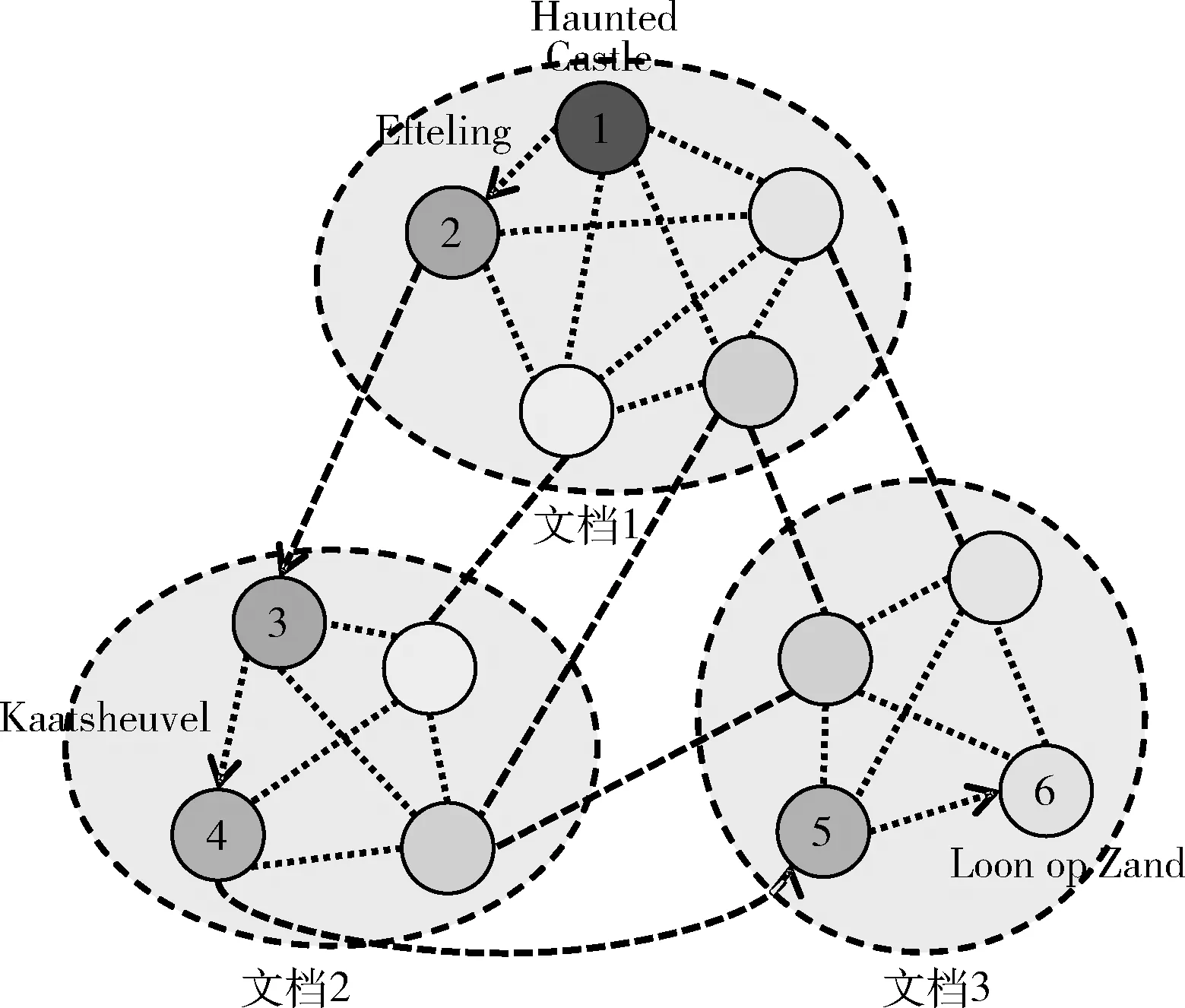
图3 实体图
2.1.2 结点特征初始化
候选实体X一般由一个或多个单词组成,其对应的语义特征可由词嵌入特征和文档上下文特征的组合来表达,即候选实体结点的初始化特征Fnode为
(1)
其中,K是候选实体X所包含的单词个数,GloVe(Xi) 是候选实体X中单词i的GloVe嵌入,ELMo(X) 是候选实体X的ELMo[12]嵌入, [,] 表示拼接操作。将候选实体所包含全部单词的GloVe嵌入平均值作为候选实体的嵌入,并与ELMo嵌入拼接后传入全连接层。使用ELMo嵌入的原因是原始文档中出现的候选实体与其上下文之间的相关性信息对于建模这些候选实体间关系也十分重要。其中,GloVe(Xi)∈Rd,ELMo(X)∈Rd,Fnode∈Rd,d为单词及结点的嵌入维度,实体图初始化特征Fnodes∈RT×d,T为实体图中结点数量。
2.2 候选实体多跳上下文的嵌入表达
在实体图中,候选实体结点与其多跳邻居结点之间具有信息相关性,因此候选实体结点的多跳上下文特征学习需要考虑其邻居结点的影响。在本文中,候选实体特征的多跳上下文特征学习包括多视角图卷积和多视角特征融合两个阶段。其中,在多视角图卷积阶段,借助多个横向通路的图卷积结构来建模候选实体结点间的多视角相关关系,而在多视角特征融合中基于SE机制对前述所提取的多视角特征进行融合,最终学到候选实体的多跳上下文特征的嵌入表达。
2.2.1 多视角图卷积
在本文中,图卷积的基本模块是基于R-GCN[13]的思想来进行构建的。这样做的原因是R-GCN在建模不同结点间的信息相关性时,引入了连边的类型和方向作为特征,十分契合本文所研究的MQA任务。同时,受Inception启发,本文中的图卷积结构设计为多视角的形式,即由多个图卷积通路构成。如图2中“C-多视角图卷积”所示,这些图卷积通路的结构相同但独立训练。
对于V个图卷积通路,每个通路的输入为实体图初始化特征Fnodes和结点间的连边信息e, 信息在结点间的传递可表示为
(2)
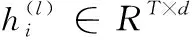
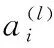
(3)
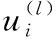
因此,在本文的实体图中,候选实体结点的更新公式为
(4)
其中,⊗代表按位相乘,所有的变换f*都是相似的,经过L层(每个图卷积通路的层数)后产生的关系感知表示特征为FR-GCN∈RT×d,T为实体图中结点数量,d为每个结点的嵌入维度。
2.2.2 多视角特征融合
对于多通路的特征提取结构,特征融合是关键步骤。在适配机器视觉的Inception结构中一般采用1*1卷积或池化操作来对多个通路不同尺寸的特征进行融合。在一些自然语言处理任务中,会对不同通路上的信息进行加权求和来进行融合[14]。但本文中若直接套用这些方式会忽略实体图上多视角特征之间的差异性和重要性特征,从而导致多跳过程中拓扑信息的丢失。
Squeeze-and-Excitation机制是一种轻量级的特征重要性动态重校准结构,参数量少,训练开销小,可有效避免过拟合风险,且易于迁移。因此,本文引入了SE机制,设计了一种多视角注意力模块,来增强特征融合过程中对多视角特征的重要性辨别能力,以实现多视角特征的有效融合,如图2中“D-多视角特征融合”所示。
本文中的多视角注意力模块包含两个全连接层,其中,第一个全连接层起到降维的作用,降维系数r为超参数,然后采用ReLU激活,第二个全连接层恢复原始的维度,然后采用Sigmoid激活的门控机制,得到每个通路产生特征的权重。
具体地,首先,对于V个通路产生的特征集合 [f1,f2,…,fV],fv∈RT×d,v∈[1,2,…,V], 其中fv表示第v个通路产生的关系感知表示特征,它的全局特征zv可表示为
(5)
然后,多视角特征融合的重要性度量s可表示为
s=σ(g(z,W))=σ(W2ReLU(W1z))
(6)
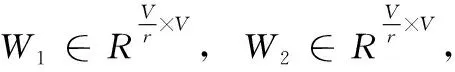
最后,将学习到的各个通路生成特征的权重与它的原始特征加权求和,得到融合后的多视角特征Fgraph
(7)
其中,fv∈RT×d是第v个通路产生的关系感知表示特征,sv为每个通路对应的特征权重,·表示矩阵相乘,Fgraph∈RT×d为融合后的多视角候选实体上下文嵌入表达,T为实体图中结点数量,d为每个结点的嵌入维度。
2.3 “候选实体-问句”关系映射
在MQA任务中,“候选实体-问句”的关联是获得最终答案的关键步骤。在本文中,借鉴BiDAF[15]、BAG[8]等相关工作的思路,“候选实体-问句”的关系映射也是采用双向注意力的机制获得的。双向注意力操作的输入为式(7)候选实体上下文嵌入表达Fgraph和问句嵌入表达Fquery, 处理过程如下所述。
2.3.1 问句嵌入表达Fquery
Fquery由问句词嵌入特征和问句上下文特征的组合来表达,可表示为
Fquery=LSTM([GloVe(Qi),ELMo(Qi)])
(8)
其中,GloVe(Qi) 表示问句Q中第i个单词的GloVe嵌入,ELMo(Qi) 表示问句Q中第i个单词的ELMo嵌入, [,] 表示拼接操作。问句嵌入表达Fquery的初始化方法与实体图中候选实体结点特征的初始化方法类似,唯一不同的是,由于问句包含的单词数量比候选实体的多,所以问句中单词的GloVe特征和ELMo特征不进行平均的操作,而是直接拼接后通过一个双向LSTM得到相应的嵌入编码。其中,GloVe(Qi)∈RM×d,ELMo(Qi)∈RM×d,Fquery∈RM×d,M为问句中的单词数量,d为问句嵌入的维度。
2.3.2 “候选实体-问句”关联度矩阵
“候选实体-问句”关联度矩阵用于表达每个候选实体与每个问句单词之间的关联程度,可表示为
S=avg-1fa([Fgraph,Fquery,(Fgraph⊗Fquery)])
(9)
其中, fa表示线性变换操作, avg-1表示在最后一个维度上求均值, [,] 表示拼接操作,⊗表示按位乘法,S∈RT×M,T为实体图中的结点数量,M为问句中的单词数量,Fgraph∈RT×d为候选实体上下文嵌入表达,Fquery∈RM×d为问句嵌入表达。由此得出的关联度矩阵也可以看作是候选实体与问句单词间的Attention。
2.3.3 双向注意力计算
本文中的双向注意力包括“候选实体→问句”以及“问句→候选实体”两种。
(10)
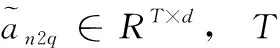
(11)
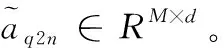
2.3.4 “候选实体-问句”关系映射
(12)
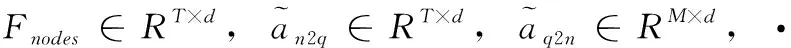
2.4 答案预测
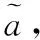
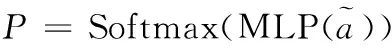
(13)

3 实验和评估
3.1 数据集
本文在WikiHop数据集上对提出的模型进行实验分析,WikiHop是基于维基百科开放域的文章数据集,其中每一个样本包含一个问题、多个支撑文档和多个候选实体。为了能进一步验证模型的推理能力,该数据集在Unmasked版本的基础上构建了Masked版本,唯一的区别是在Masked版本中,所有候选实体均用“__MASK__”标记来进行替换,这样模型在进行推理时无法利用候选实体本身的语义信息,只能借助上下文信息,对模型的推理能力提出了更高的要求。WikiHop数据集目前只公开了训练集Train和验证集Dev两部分,为了方便测试,本文在实验中将验证集Dev中的部分数据作为测试集Test-1,相关统计见表1。

表1 数据集指标统计
在实验中,将准确率作为评价指标
(14)
其中, Max()i表示第i个样本中概率最大的实体,即预测结果,labeli表示第i个样本的标签, I(,) 为指示函数,如果两者相同就返回1,否则返回0,N表示数据集中样本数量。
3.2 实验设置
在预处理中,模型采用840B 300 d的GloVe预训练嵌入作为词语级别的初始特征,使用1024维的标准ELMo表示作为上下文级别的语义信息,用于结点编码的1层线性映射网络维度为512,并且使用Tanh作为激活函数;用于问句编码的2层双向LSTM网络维度为256。多视角图卷积的通路数量C设置为4,多视角注意力模块中Squeeze-and-Excitation操作的降维系数r设置为4。参照R-GCN[13],每个图卷积通路的层数L设为5。此外,对于每个样本,最大结点数量和最大问题长度分别设置为500、25。
每个图卷积通路中的Dropout率设置为0.2,在显存为16 G的Tesla T4上进行实验,batch size设为32,使用初始学习率为0.0002的Adam优化器,并且每2个epoch后学习率减半,损失函数选用交叉熵,损失计算如下
(15)
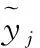
3.3 实验结果与分析
3.3.1 多跳问答任务测试
为了验证本文所提出的MV-GCN模型的有效性,此处将其与两类基线模型进行对比,分别在WikiHop数据集的Unmasked、Masked两个版本上进行实验。两类基线模型是:①基于RNN的模型,包括FastQA、BiDAF、Coref-GRU[16];②基于图网络的模型,包括MHQA-GRN、Entity-GCN[7]、BAG[8]。其中基线模型Entity-GCN、BAG展示了与本模型相同环境下的运行结果,其它基线模型的设置皆参照其原始论文进行。
对比结果如表2所示,“MV-GCN”即本文提出的模型,表中报告的结果是在多视角图卷积参数C为4,降维系数r为4设置下的结果。从表2的实验结果可以看出,本文提出的模型整体上优于目前所有的基线模型,并且在Unmasked版本测试集上达到了68.6%的准确率。说明通过设计多视角图卷积来提取结点间的传递信息,以及多视角信息融合的方法能很大程度上提高模型的特征表征和推理能力;并且在多次实验过程中发现相较于基线模型,本文提出的模型在稳定性上表现更好,这是因为神经网络本身具有不稳定性,再加上随机初始化等因素,单视角的网络稳定性较差,而多个视角之间可以形成互补与增强,从而在提高性能的同时达到一个动态平衡。
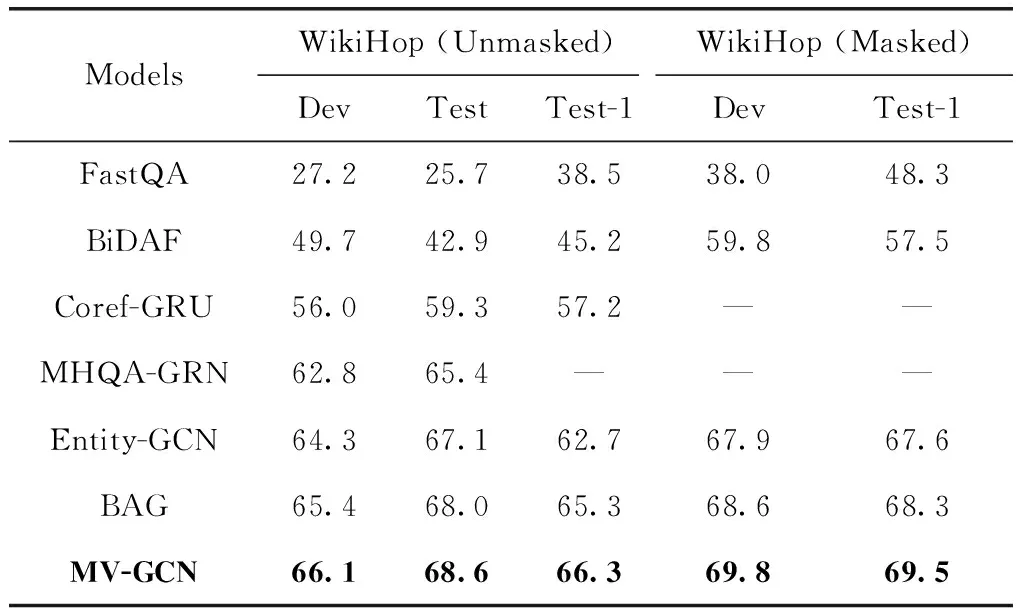
表2 多跳问答任务下不同模型的准确率对比/%
3.3.2 对多视角图卷积参数C的分析
图4展示了关于多视角图卷积参数的实验,验证不同多视角图卷积参数对模型性能的影响。由于Inception中每层的通道数量较大,所以对应的Squeeze-and-Excitation机制中降维系数r也设置的很大,比如16、32;但在本文的模型中多视角图卷积数量并不是很大,所以将降维系数为r设为4,其它设置相同。从图4可以看出,当多视角图卷积参数设为4时准确率达到最高,这是因为图网络本身具有较强的特征抽取及推理能力,当视角参数过大时,反而会形成信息冗余及视角间的互相干扰,而视角数量过少则会出现信息抽取角度不够的问题。
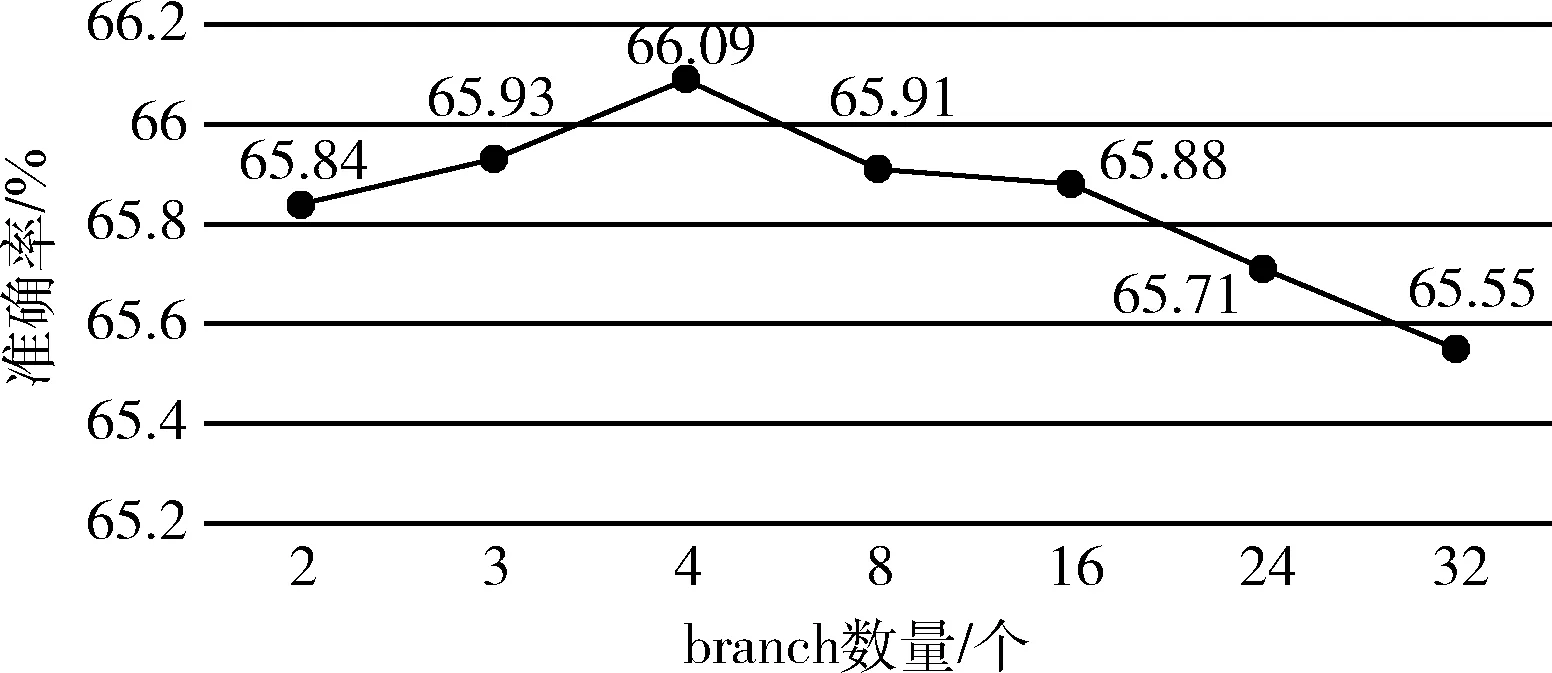
图4 关于多视角图卷积参数C的实验
3.3.3 对多视角融合中降维系数r的分析
图5展示了关于多视角融合中降维系数r的实验,验证降维系数r对模型性能的影响,实验时将多视角图卷积参数C设置为24,这样可以尽可能多地测试多组r值,其它设置相同;为了提高实验效率,分别随机选取了5000条训练样本和1000条验证样本进行实验。从折线图可以看出,当r值为4时,准确率最高,此时降维后的维度为6,能对多个视角进行最大程度的权重筛选,但又不影响信息的融合,最终使整个模型的性能达到最优。
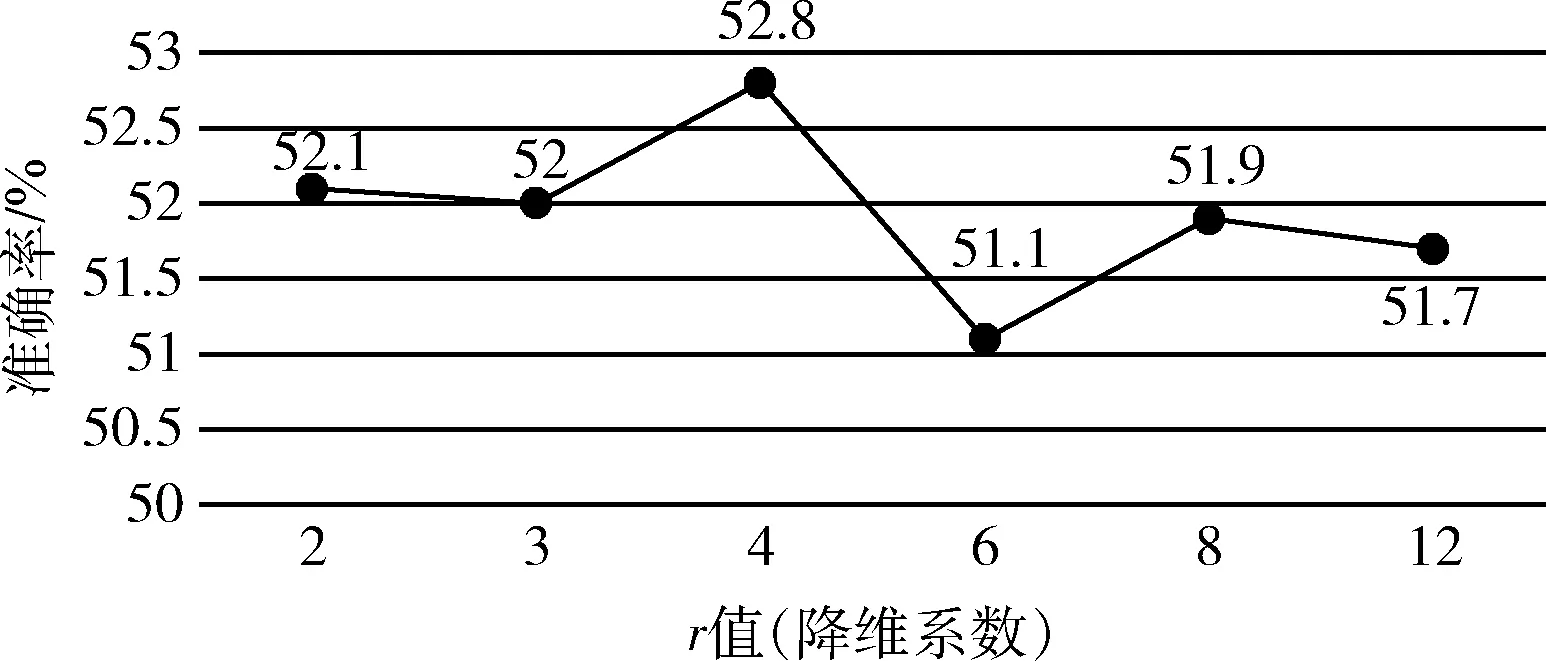
图5 关于降维系数r的实验
3.3.4 对MV-GCN模型训练稳定性的分析
在基线模型中,目前BAG的综合性能最好,图6为MV-GCN与BAG在稳定性方面的性能对比,展示了从训练开始5个epoch(215 000步)内的损失变化情况。从图中可以看出,训练开始阶段,MV-GCN的损失快速且平滑下降;在训练中后期的每个epoch内,BAG的损失会略有上升,而MV-GCN的损失变化平缓,波动幅度小,且在整个训练过程中MV-GCN的损失都略低于BAG,表明相较于BAG有更好的稳定性。
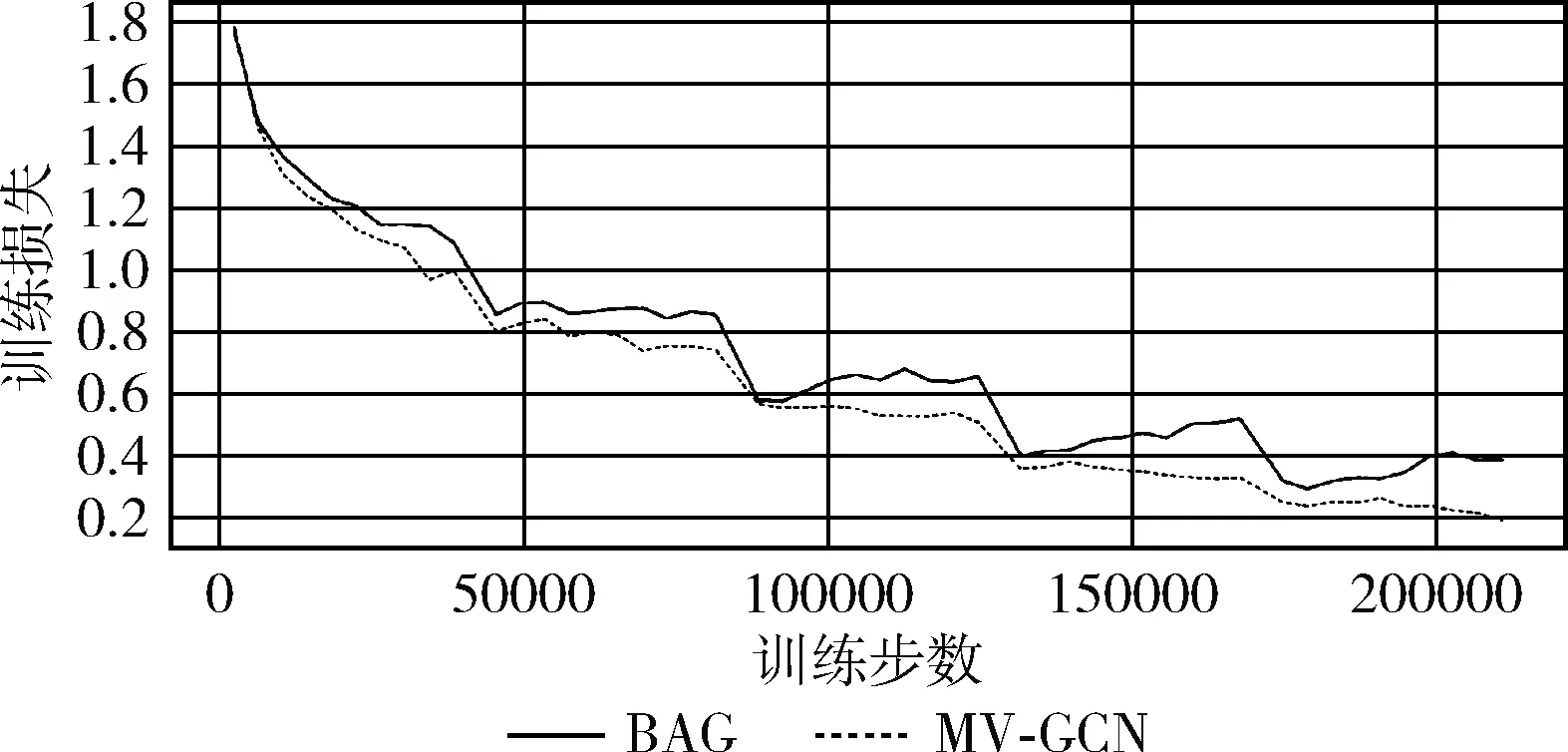
图6 训练过程中损失变化
4 结束语
本文针对多文档多跳推理阅读理解问题,提出了基于多视角图卷积的MV-GCN模型,摒弃了传统加深网络的思路,而是采用在横向设计多个图网络通路的思路来加宽网络,引入更加丰富的特征信息,并通过SE机制对多个图卷积通路的全局信息进行动态重校准的方式实现信息融合。经过验证,整个模型拥有较好的性能,但在实际应用场景中还存在着一些问题,比如针对不同的问句需要不同的跳转次数,这就需要模型能够动态进行答案推理。为应对这些问题,在下一步研究工作中,将通过引入更加灵活有效的注意力机制[10]的方式,并结合门控图网络等方法来进一步提高多跳推理阅读理解模型的推理能力。
