基于离线模型预训练学习的改进DDPG算法
2022-05-23王洪格
张 茜,王洪格,倪 亮
(中原工学院 计算机学院,河南 郑州 450007)
0 引 言
强化学习[1,2]是机器学习的一个重要分支,智能体通过执行某些操作并观察从这些操作中获得的奖励或结果来学习在环境中行为。
强化学习的控制决策功能与深度神经网络的感知功能相结合产生深度强化学习(deep reinforcement learning,DRL)。DRL中经典算法DDPG及双延迟DDPG(TDDD twin delayed deep deterministic policy gradient,TD3)是神经网络拟合值函数和策略函数的典型案例。
DDPG算法训练过程较稳定,但其学习过程比较缓慢且存在Q值高估偏差,导致次优策略和发散行为,使最终算法模型有很大的偏差[3]。TD3算法在DDQN基础上抑制Q值高估,却没有考虑价值估计的动态性,导致出现策略恶化。
另外,在线强化学习需要在线地处理环境中每个时刻的状态数据和反馈奖励,施加动作后必须等待环境的下个反馈奖励,故造成时间成本代价过高。不仅如此,在训练初期时,其中的动作网络和评估网络泛化能力较弱,产生大量冗余的试错动作和无效数据,一定程度上浪费在线的计算资源。
为了解决上述问题,本文首先利用已有离线数据,训练数据生成对象状态模型和价值奖励模型,通过基于模型的强化学习方法离线预训练DDPG中动作网络和评估网络,离线提升网络的决策能力,从而加快之后在线学习效率,提高算法的性能和收敛速度。同时利用DDQN算法中双Q价值网络的结构[4],避免Q值在训练过程中被过高估计,产生最优策略。
1 相关工作
目前深度强化学习已经在机器人的仿真控制[5]、运动控制[6]、室内室外导航[7]、同步定位[8]等方向产生重要的影响,广泛应用于机器人操作任务上[9],促使机器人能够在仿真环境甚至现实世界中通过经验和环境交互进行自主学习,以达成回报最大化或实现特定目标。
JIN Hai-Dong等[10]提出一种带自适应学习率的综合随机梯度下降方法,将其与Q-Learning算法结合,解决优化震荡,但仍存在算法收敛性能对历史梯度折扣率λ敏感。Todd Hester等[11]将深度Q网络(deep Q-Learning network,DQN)与专家示例数据相结合,对智能体进行预训练,利用小数据集来大幅加快学习过程,但缺少在现实任务场景中的验证。CHEN Song等[12]提出一种基于线性动态跳帧和改进的优先级经验重放的深度双Q网络,使智能体将根据当前状态和动作来动态地确定一个动作被重复执行的次数,但评价标准只考虑到样本的时间差分误差,可能还存在其它影响样本优先级的因素。Hasselt等[3]将Double Q-Learning应用到DQN上提出了DDQN,将TD目标的动作选择和动作评估分别用不用的值函数来实现,改进了max操作去解决Q值高估。Timothy P等[13]提出了DDPG,解决了DQN无法处理大量的连续动作空间问题,广泛用于解决避障、路径规划[14,15]等问题。但与大多数无模型强化方法一样,DDPG需要大量的训练来找到解决方案,而且样本数据采集受到实时操作的限制,一般来说,基于模型的算法在样本复杂度方面优于无模型学习者[16]。Scott Fujimoto等[17]提出了TD3算法,在DDQN基础上通过选取两个估值函数中的较小值并使用延迟学习,但存在收敛速度过慢。Pieiffer M等[18]提出一个模型,能够学习避免碰撞的策略,安全地引导机器人通过障碍物环境到达指定目标,但是从完美的模拟数据中训练出来的模型,存在导航性能的不足。
基于以上分析,本文提出了基于离线模型预训练改进的DDPG算法,利用离线真实训练数据构造了对象状态模型网络和价值奖励网络,并通过新构造的两个网络对DDPG中的动作网络和价值网络进行预训练,加快智能体从已知环境中学习的效率以便高效地完成指定任务。同时,DDPG算法存在噪声和函数逼近不够灵活,导致对已知的Q-action值估计过高,不能产生最优策略,因此本文将DDQN的结构应用到算法中,通过将目标中的最大操作分解为动作选择和动作评价,使用目标网络来评估其价值,得到更精准的Q值,以便产生最优策略。实验结果表明本文提出的基于离线模型预训练改进的DDPG算法比原始DDPG算法效率更高效,平均奖励值更高,学习策略更加稳定可靠。
2 DDPG算法介绍
Deepmind提出DDPG[13],是Actor-Critic框架[19]和DQN算法的结合体,是针对连续动作空间的off-policy[20]、Model-Free深度强化学习算法。从整体上来说,DDPG网络应用基于Actor-Critic方法,故具备策略Policy的神经网络和基于价值Value的神经网络,包含一个策略网络用来生成动作,一个价值网络用来评判动作的好坏,并吸取DQN的优秀特性[21],同时使用了样本经验回放池和固定目标网络。
DDPG结构中包含一个参数为θπ的动作网络和一个参数为θQ的价值评估网络来分别计算确定性策略a=π(s|θπ) 和动作价值函数Q(s,a|θQ), 由于单个网络学习过程并不稳定,因此借鉴了DQN固定目标网络的成功经验,将动作网络和评估网络各自细分为一个现实网络和一个估计网络。
现实网络和估计网络两者结构相同,估计网络参数以一定频率由现实网络参数进行软更新。动作估计网络用于输出实时动作,供智能体在现实环境中执行动作,而动作现实网络用于更新价值网络系统。同时价值评估网络也细分为现实网络和估计网络,用于输出每个状态的价值奖励,而输入端却有不同,状态现实网络根据动作现实网络输入的动作及状态的观测值分析,而状态估计网络根据此时智能体施加的动作作为输入。
该算法的流程描述如下:
算法1:DDPG算法
步骤1 初始化参数设置动作网络和评估网络的在线神经网络参数:θQ和θμ,将在线网络的参数拷贝给对应的目标网络:θQ′和θμ′;
步骤2 初始化存储缓冲器R;
步骤3 智能体根据行为策略选择一个动作,下达给环境执行;
步骤4 智能体执行动作后,环境返回奖励值和新的状态st+1,智能体将这个状态的转换过程 (st,at,rt,st+1) 存入存储缓冲器R中,作为训练在线网络的数据集;
步骤5 从存储缓冲器R中,随机采样N个转换数据,作为在线策略网络和在线Q网络的一个小批量训练数据,用 (si,ai,ri,si+1) 表示小批量数据中的单个转换数据;
步骤6 计算在线Q网络的梯度,求得损失函数中针对θQ的梯度;
步骤7 采用Adam优化器在线更新Q网络中的参数θQ,计算在线策略网络的策略梯度更新θμ;
步骤8 通过软更新去更新动作网络和评估网络分别对应的目标网络参数θQ′和θμ′。
3 改进DDPG算法
3.1 介 绍
在实际训练过程中,智能体与环境进行交互训练成本代价昂贵,在线强化学习时间成本高且前期训练神经网络过程会进行大量的尝试,会产生大量试错动作和无效数据,效率低下。
因此,本文提出基于离线模型预训练学习改进的DDPG算法,在原始DDPG网络结构上新构建了两个结构相似的全连接神经网络,分别为对象状态模型网络和价值奖励网络,每层网络的人工神经元个数基本相近。对象状态模型网络和价值奖励网络可以通过从已有离线数据中学习智能体之前与环境交互得到的观察和动作的组合到所预期的新的观察与回报之间的迁移动态去调参和训练优化,最终分别生成相应模型后,用模型环境来训练智能体的策略,去模拟在线学习过程以此去提前预训练动作网络和价值网络,大大减低智能体与环境交互产生的工作量,促使智能体前期就可以选出较好的动作去产生高评分的价值奖励值,可以愈发高效地完成任务。
任何类型的估计误差都会导致向上偏差,不管这些误差是由环境噪声、函数逼近、非平稳性还是任何其它来源引起的。在DDQN之前,基本上所有的目标Q值都是通过贪婪法直接得到的,计算如下式
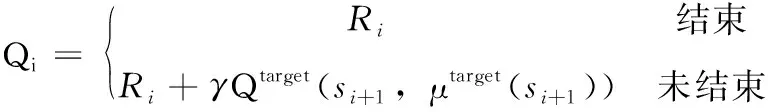
(1)
式中:γ∈[0,1] 是衰减因子,权衡即时和未来奖励的重要性; Qtarget(si+1,μtarget(si+1)) 表示由目标Q网络获得si+1状态下选取ai+1动作所能达到的Q值。
使用max操作虽然可以快速让Q值向可能的优化目标靠拢,但是由于损失函数中每次求得的目标Q值都是取max操作得到,会存在
E(max(x,y))≥max(E(x),E(y))
(2)
即将N个目标Q值先取max操作再求平均总是会比先计算N个目标Q值取平均后再max操作要大,最终导致过度估计。
所谓过度估计就是最终估计的值函数比真实值函数要大,使得到的算法模型有很大的偏差。为了解决这个问题,DDQN通过解耦目标Q值动作的选择和目标Q值的计算,使用目标网络来评估其价值,对目标网络的更新与DQN保持不变,并保持在线网络的定期副本,促使DQN朝着双Q学习的最小可能的改变,尽可能得到更加准确的Q值,产生更好的策略。
本文为了解决DDPG中的Q值过度估计问题,在Q值的处理上增加了DDQN的结构,具体设计思路如下:
通常在非终止状态下,其Q值的计算为
Qi=Ri+γQtarget(si+1,μtarget(si+1))
(3)
在本文提出的方案中,为了避免Q值过大估计,不再是仅仅直接在目标Q网络里面找出动作决策网络对应Q值,而是在目标Q网络中先找出当前动作决策网络对应的Q值,如下所示
(4)
(5)
式(4)表示在状态si+1下,在当前Q网络中先找最大Q值对应的动作,再在目标网络里面去计算目标Q值。
然后利用这两个值中的最小值在目标网络里面去计算目标Q值
(6)
综合写起来为
(7)
除了目标Q值的计算方式以外,本文所提出的算法在在线训练的方式与DDPG一致。
3.2 训练评价网络和动作网络
收集训练数据:本文通过智能体根据行为策略选择一个行动,下达给环境执行该行动,环境执行后返回奖励和新的状态。智能体将这个状态转换为 (st,at,rt,st+1) 来收集训练数据。
数据预处理:许多数据因其不完整性和前后不统一等特点会造成所谓“脏”数据的产生,如果直接使用这些数据进行模型预训练而不考虑数据内在特征,会使得最终结果误差较大,影响整体效果。因此使用数据之前需要进行相应的去除空值和异常值的处理,对数据的格式进行归一化转换,能降低干扰,从而提高预测精度[22]。另外本文将零均值高斯噪声加入到训练数据中,以提高模型的鲁棒性。最后将处理后的数据存储在数据集N中。
离线预训练评估网络和动作网络:从预处理后的数据集N中提取N个样本数据,离线训练对象状态模型网络和价值奖励网络后生成模型,再利用这两个模型提前对DDPG中的动作网络和价值网络进行预训练学习,减少前期的大量试错工作,提升在线学习的效率和品质。
离线预训练过程描述如下:
(1)离线环境下:从系统历史数据表格中收集环境样本数据或产生随机动作,得到对应的奖励值和反馈奖励数据,其数据格式为 (st,at,rt,st+1)。
(2)从数据集N中随机选取N个样本,更新对象状态模型网络P(s,a|θp) 和价值奖励网络r(s,a|θr):
方式如下最小化,对象状态模型的损失函数
(8)
其中,si+1表示下一时刻的状态,N表示随机从数据集中抽取的N个样本, P(si,ai|θp) 表示在si状态下执行动作ai后的状态值。
方式如下最小化,价值奖励模型的损失函数
(9)
其中,ri表示从当前状态直到将来某个状态中间所有行为所获得奖励值的之和, r(si,at|θr) 表示当前状态和行为所获得的奖励值。
(3)基于训练好后的对象状态模型和价值奖励模型对评估网络Q(s,a|θQ)、 动作网络μ(s|θμ) 进行预训练,从数据集中选取N个样本 (st,at), 对价值网络进行训练,通过价值奖励函数预测当前状态执行动作后的反馈奖励
Ri=r(si,at|θr)
(10)
(4)通过对象状态模型预测下一步状态
si+1=P(si,ai|θp)
(11)
(5)根据目标动作网络预测下一步的动作
ai=μ′(s|θμ′)
(12)
(6)通过目标价值网络得到下一步的Q值
Qi+1=Q′(si+1,ai|θQ′)
(13)
(7)运用式(7)DDQN算法结构训练和更新Q网络:
方式如下最小化,Q网络的损失函数
(14)
(8)继续训练更新动作网络μ(s|θμ)
ai=μ(si|θμ)
(15)
方式如下最小化,动作网络的损失函数
(16)
(9)最后进行软更新,更新目标网络里面的参数θQ′和θμ′,离线预训练结束。
3.3 算法流程设计
算法2:基于模型预训练学习的改进DDPG算法
步骤1 构建并初始化人工神经网络评估网络Q(s,a|θQ)、 动作网络μ(s|θμ)、 对象状态模型网络P(s,a|θp) 和价值奖励网络r(s,a|θr) 并初始化各自参数,收集并预处理数据,训练对象状态模型网络和价值奖励网络;
步骤2 训练好后的两个模型对评估网络Q(s,a|θQ) 和动作网络μ(s|θμ) 进行预训练;
步骤3 初始化上述两个网络对应目标网络,初始化存储缓冲器R中;
步骤4 随机初始化分布N用作动作探索,初始化st为当前的第一个状态;
步骤5 智能体根据行为策略选择一个行动,下达给环境执行该行动;
步骤6 智能体执行动作后,环境返回当前状态执行后的奖励和新的状态st+1;
步骤7 智能体将这个状态转换过程 (st,at,rt,st+1) 存入存储缓存器R中,作为训练在线网络的数据集;
步骤8 从存储缓存器R中,随机采样N个转换数据,作为在线策略网络和在线Q网络的一个小批量训练数据。本文用 (si,ai,ri,si+1) 表示小批量中的单个转换数据;
步骤9 通过目标动作网络预测下一步的动作ai=μ′(s|θμ′), 利用DDQN算法结构Qi=ri+γQi+1比较Q值
Q′i+1=Q′(si+1,ai|θQ′)
(17)
Qi+1=min(Qi+1,Q′i+1)
(18)
步骤10 计算在线Q网络的策略梯度,Q网络的损失函数定义如式(14)所示。
步骤11 更新在线策略网络:采用Adam优化器更新θμ和动作网络μ(s|θμ)
ai=μ(si|θμ)
(19)
(20)
步骤12 最后进行软更新,更新目标网络里面的参数θQ′和θμ′
θμ′←τθμ+(1-τ)θμ′
θQ′←τθQ+(1-τ)θQ′
其中,τ为更新系数,为避免参数变化幅度过大,范围取0.01~0.1。
改进DDPG算法的结构如图1所示。
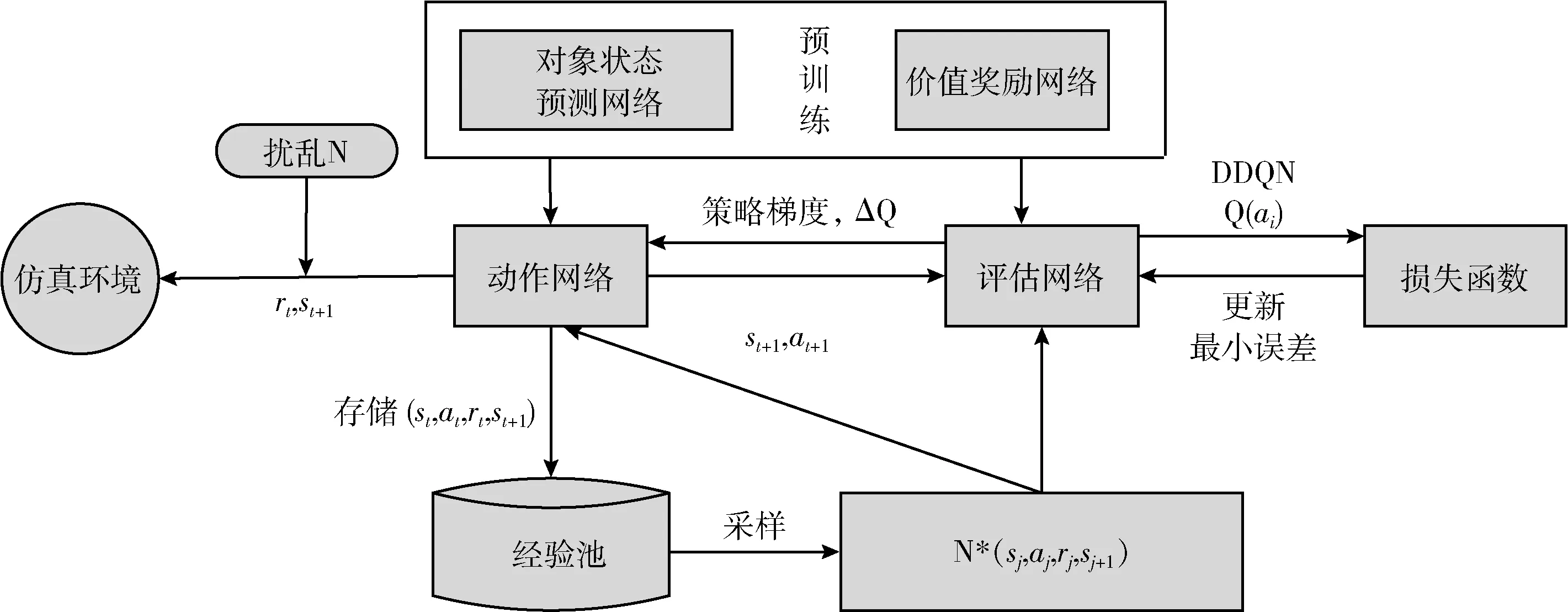
图1 改进算法结构
4 实 验
实验环境为windows 10+paddle 1.7+par l1.3.1+cuda 10.0。硬件为core i8-8300+显卡GTX1060。仿真平台为BipedalWalker-v2。本文的离线数据获取是在环境状态和动作范围内,随机产生状态数据、动作和其对应的价值奖励及下个状态,将最终数据以 (sj,aj,rj,sj+1) 格式存入数据库。本文利用DDPG算法、TD3算法和基于离线模型预训练学习的改进DDPG算法分别训练4000回合,分析2D假人从起点到达终点的反馈奖励值与训练回合数的关系,进行了训练奖励曲线对比实验和评估奖励对比实验。
4.1 BipedalWalker-v2仿真平台
BipedalWalker-v2[23,24]是一个开源模拟器,其环境特点为地形的生成是完全随机的,它的任务是让2D假人从起点走到终点,机器人有4个关节可以控制,分别是左腿根部连接,右腿根部连接,左腿膝部连接和右腿膝部连接,这个技能是在模仿双足动物向前行走的过程。往前走的越远,分数越多,如果机器人摔倒则扣分,训练的模型必须非常稳健才能拿到高平均分。
假人行走过程如图2所示。
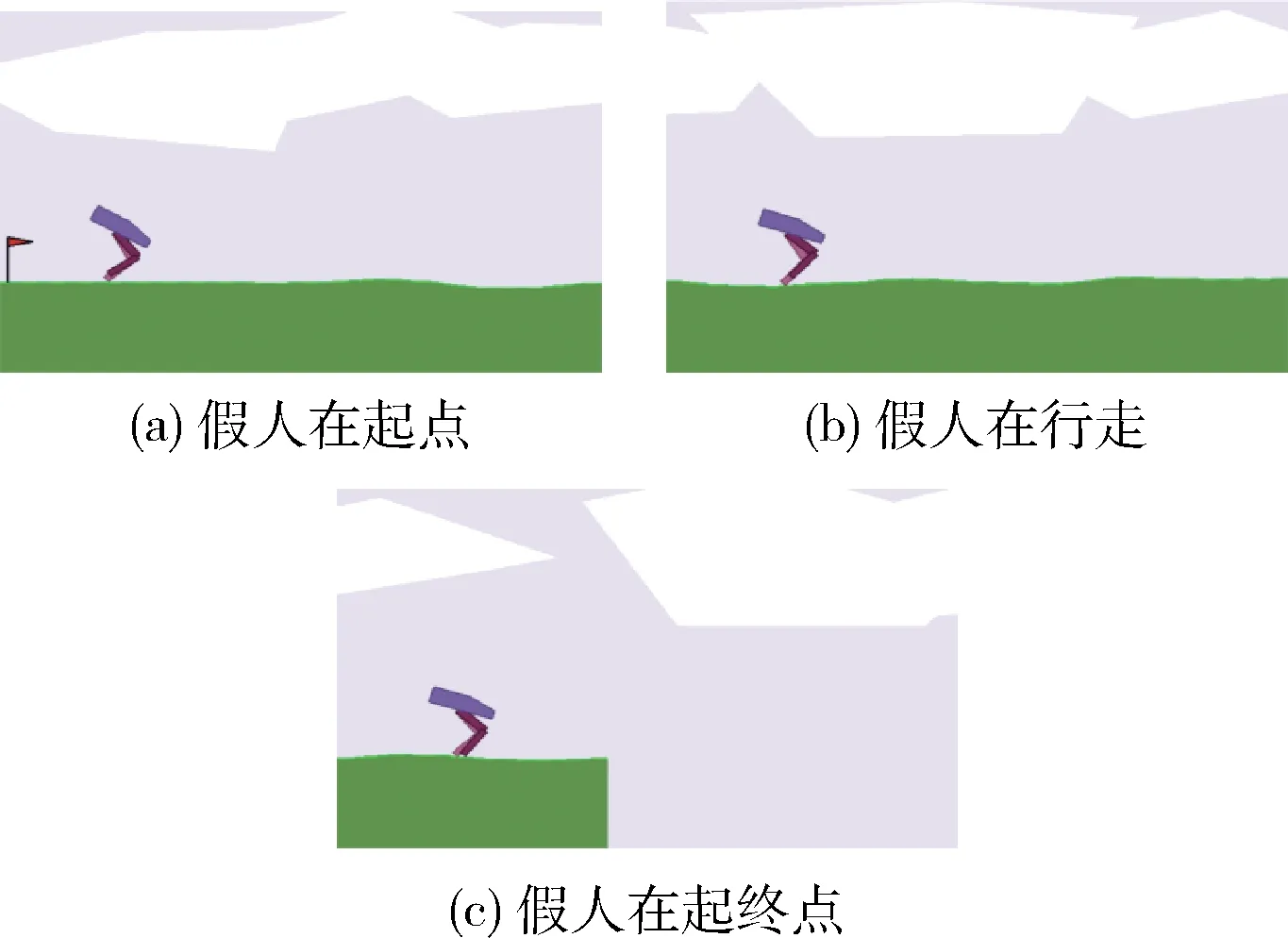
图2 假人行进过程
4.2 实验参数设置
为了保证实验的有效性,本文使用的所有算法均使用相同的参数。实验中参数取值如下:动作网络的学习率为5e-3,评估网络的学习率为5e-3,对象状态模型网络的学习率为6e-5,价值奖励网络的学习率为9e-6,价值奖励的衰减因子γ取值0.995,软更新的系数取值0.008,经验池大小为200 000,奖励缩放系数为1,动作噪声方差为1,训练过程中逐渐会衰减到0.5,训练的总回合数为4000。
本文在原来DDPG的动作网络和评估网络结构上新构建了两个结构相似的全连接人工神经网络,每层网络的人工神经元个数基本相近。网络的具体设计如下:

4.3 预训练模型的损失函数
新构建的对象状态模型网络和价值奖励网络有着不同的功能和结构,相应的训练方式也不同,使用不同的损失函数进行训练,其目的都是为了从训练数据中获取最优权重参数。
对象状态模型网络训练的损失函数曲线如图3所示。

图3 对象状态模型网络训练的损失函数曲线
价值奖励网络训练的损失函数曲线如图4所示。
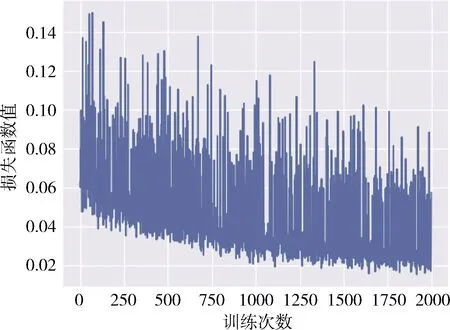
图4 价值奖励网络训练的损失函数曲线
从图3和图4上可以直观看出训练损失函数曲线总体呈现下降趋势,相邻之间的损失值有较小的波动,收敛速度较快,数据的变化程度越小,说明预测模型描述实验数据具有更好的精确度,使最终的模型达到收敛状态,减少模型预测值的误差。
4.4 训练奖励曲线对比
图5(a)为传统DDPG训练奖励曲线[13],图5(b)为TD3训练奖励曲线[17],图5(c)为离线模型预训练后的改进DDPG训练奖励曲线。纵坐标为训练的回合次数,横坐标每次训练的价值奖励。Q值是神经网络训练时用于评估动态规划的价值,Q值越小,价值函数曲线的网络越保守,则Q值增长慢,曲线越平滑;而Q值大一点就会激进一点,则Q值增长快,曲线产生振荡幅度大。
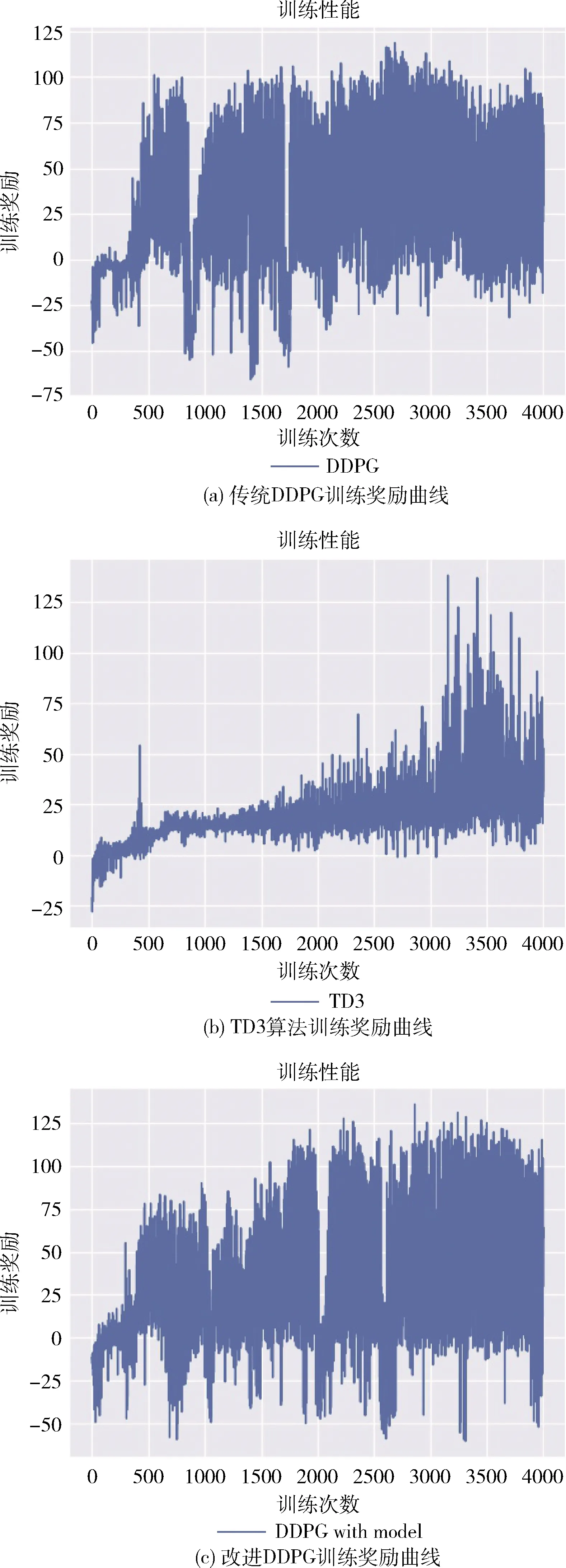
图5 训练奖励曲线对比实验结果
从图5(a)上明显看出TD3算法抑制Q值增加,稳定性较好,但前期获得的价值奖励值低,收敛速度慢。而改进DDPG算法可以明显看出前期的训练奖励曲线获得的奖励值整体高于DDPG算法和TD3算法,说明了基于离线模型预训练学习的改进DDPG算法可以有效提升算法的性能。因为通过对象状态模型网络和价值奖励模型网络对评估网络Q(s,a|θQ)、 动作网络μ(s|θμ) 进行预训练可以更好地确定每个状态下每个动作需要重复执行的次数,早期便可获得高评分奖励值,进一步节省智能体在大部分时间里重复执行多次的动作次数和提升智能体自身的决策能力。
4.5 评估奖励对比
从图6(a)上看来,训练初期时算法评估奖励TD3稳定性较好,但是奖励值增长较DDPG和改进DDPG算法弱很多。从图6(b)上看来,训练结束时改进DDPG算法稳定性较好且震荡少、评分高。图6(c)为3种算法在4000回合中累积奖励曲线对比,累积奖励越高,代表机器人按照期待的目标选出来更优的动作。
从图6(c)上直观可以看出3条曲线都呈递增趋势,且当训练回合超过某一定值后,图中显示改进DDPG算法在2600回合左右平均累积奖励已经趋于整体稳定,数值在300左右,而原始DDPG则是在3600回合左右开始趋于稳定状态,TD3算法稳定性较好,但前期增长速度一直很慢,明显看出前者优于后两者先趋于稳定,算法收敛速度优于后两者而且累积奖励值评分高。
数据显示本文所提出的改进DDPG算法在0-4000回合的平均奖励为82.3,最大奖励为142,最小为-58;DDPG算法平均奖励为75.4,最大奖励为118,最小为-66;TD3算法平均奖励为62,最大奖励为132,最小为-27;
在测试环境下改进DDPG算法的平均奖励为198.2,最高奖励为302,最低为-198;DDPG算法平均奖励为189.6,最高奖励为281,最低为-186.4;TD3算法平均奖励为98.7,最高奖励为294,最低为-101。
从数据可以更加直观看出改进DDPG算法的累积奖励值最高且从图像上可看出整体算法收敛速度快,稳定性较好。
5 结束语
本文提出了一种基于离线模型预训练学习的改进DDPG算法。该算法从离线样本数据学习训练生成对象状态模型和价值奖励模型,通过模型预训练DDPG中的动作网络和价值网络,节省在线学习的成本并提升在线学习质量和效率。另外,改进算法加入DDQN网络结构,将目标中的最大动作分解为动作评估和动作选择来减少Q值的高估,根据在线网络来评估贪婪策略,同时使用目标网络来评估其价值,使智能体尽可能去达到最优策略,达到更稳定可靠的学习过程。
从BipedalWalker-v2平台的仿真实验结果显示,改进DDPG算法获得的最大累积奖励可以达到更高的水平,获取的平均累积奖励值较DDPG提升了9.15%,而且能够更快达到稳定的状态,在操作2D假人过程中可以通过最优策略快速地到达目的地。
