基于GA优化SVM参数的白酒分类识别方法应用研究
2022-05-23周永帅庹先国
刘 鑫 ,韩 强 ,周永帅 ,庹先国
(1.四川轻化工大学 自动化与信息工程学院,四川自贡 643000;2.人工智能四川省重点实验室,四川自贡 643000)
0 引言
白酒的分类识别技术主要可实现品牌鉴别、成品酒品质检测、基酒等级划分等操作,在白酒生产过程中扮演着重要的角色。传统的白酒分类识别方法主要依靠品酒师的感官品评经验[1],存在稳定性差、效率低等缺陷,无法满足实时、快捷、准确提供分类识别信息的需求。近年来,电子鼻、电子舌等仿生传感器的诞生对白酒分类识别的促进意义极大[2];神经网络、模式识别等人工智能技术与白酒分类识别的结合在实验环境下效果显著,但到目前为止其普适性不佳,无法广泛推广。现阶段主成分分析(PCA)、线性判别分析(LDA)、最小二乘(GLS)以及支持向量机(SVM)、聚类(HCA)等在白酒分类中应用最为频繁[3],其中SVM的效果最佳,但仍然存在准确率低、耗时长等问题。
支持向量机算法是一种基于小样本和结构风险最小化的统计理论机器学习方法,因其良好的泛化能力与便捷的操作方式,在各个领域的分类识别操作中被广泛应用。在常规的运用场景中,基于小样本数据集的SVM分类预测模型在信息熵要求过高、核函数参数与惩罚参数欠优化等方面存在局限[4],然而SVM中的核函数参数与惩罚参数是决定其分类精度的重要因素,其选择尤为关键。遗传算法(Genetic Algorithm,GA)是一种通过模拟自然进化过程搜索最优解的方法。参数编码、初始群体设定、适应度函数设计、遗传操作设计和控制参数设定5个环节组成遗传算法的核心内容,因其优异的全局寻优能力被广泛应用于组合优化、机器学习和自适应控制等领域[5]。因此,本文提出基于GA优化SVM参数的算法,结合电子舌对白酒的实时检测,实现白酒品牌的快速分类识别,适应性较强、准确性较高。
1 分类预测模型的建立
1.1 SVM算法原理
SVM算法的核心思想是升维与线性化,即通过非线性映射的方式,把样本空间从低维映射到高维空间,并将其分类或回归问题转化为一个凸规划问题,再结合线性学习机在其特征空间内部实现求解过程。基于SVM建立的分类识别预测模型需先结合样本数据集进行训练,训练结束后方可对待测数据的类别进行预测,其中SVM算法的决策方程如下:

其中,αi是实变量,xi为对应训练对象的特征变量,向量αi和常数b为模型训练过程中的被优化对象,K(x,xi)是核函数[6]。SVM 算法中的核函数可以在非线性映射表达未知的情况下进行使用,能够有效规避计算过程中因复杂度、维度过高而产生的问题。在实际的应用过程中,线性核函数(Linear Kernel)、多项式核函数(Polynomial Kernel)、径向基核函数(也称高斯核函数,Radial Basis Function)以及两层感知机核函数(Sigmoid Kernel)等最为常见[7],其中径向基核函数在分类识别的运用中性能更优,其原理方程式如下:
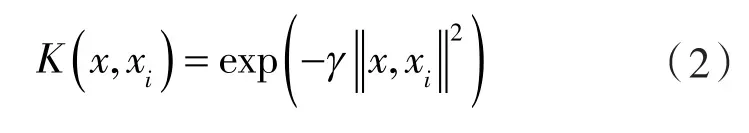
其中,参数 γ 定义为核函数参数,需要提前设定;xi是空间中的任意一点,x表示为空间中心点[8]。参数 γ 和参数 C(惩罚参数,通用于 SVM核函数)对所建分类预测模型的性能存在重要影响,须重点考虑与调整。γ 可看作是被模型选中作为支持向量样本的影响半径的倒数,值越小对单个训练样本的影响越大,反之越小;惩罚参数C主要对误分类样本与分界面简单性进行权衡,高的C值通过增加模型自由度,以选择更多支持向量来确保所有样本都被正确分类,反之使分界面更加平滑。
在基于SVM的分类预测模型的设计中,模型性能评估方法的选取不容忽视。交叉验证法在模型的精度与效率上表现优异,使用极为频繁,其具体可分为留出法(Hold-out)、K折交叉验证法(K-fold Cross Validation,K-CV)以及留一交叉验证法(Leave-One-Out Cross Validation)3种。以上检验方法在实际应用中的效果较好,但受限于惩罚参数C和核函数参数 γ 的选取与调整。C与 γ作为优化对象,且2者间的相关性较强,因此采用混合策略对2类参数同时进行优化调整,以确保模型的整体性能,其具有的有效性与全局性能够实现全局最优且耗时最短。
1.2 遗传算法优化SVM参数
GA是一种适合复杂系统优化的自适应概率优化算法,其核心原理是通过随机选择、交叉及变异等遗传操作,在局部区域内使种群繁衍、进化,最后产生一群适应环境的个体。使用GA对SVM算法的参数进行调整、寻优,其中GA编码规则的设定、初始种群的建立以及自适应函数的设计最为关键[9-10]。选取二进制编码作为样本数据的编码方式;SVM算法的惩罚参数与核函数参数分别代表不同的染色体,且每个染色体被编码为特定的序列,其数学表示如下:

其中,ωi表示染色体优化参数的二进制基因位数;[l1,l2]作为优化参数区间;k为单基因二进制编码的长度。试验中通过K-CV检测下的准确率设计确认自适应函数,以分类预测模型预测值与真实值间的误差来验证模型的性能。因此,自适应函数值越小,代表模型的分类性能越强,预测的准确率也越高。
为使GA对SVM的参数进行快速寻优,得到最优解。采用随机选择作为GA种群的操作方式,以此保证种群的多样性,并且将最小适应度函数值所对应的个体(最优个体)直接带入下一个种群中,进而通过单点交叉法执行交叉操作和多点变异法执行离散、变异操作,以实现整个种群的遗传进化。最终通过判断是否满足遗传运算的终止进化代数来确定SVM分类预测模型的最优参数。GA中种群数量的多少对优化过程的时耗存在直接影响,初始种群的设定需参照样本数据集的量级与维度。因此,试验中将k值设为20,二进制编码位数定为60。具体的GA优化SVM参数的白酒分类预测模型流程如图1所示。
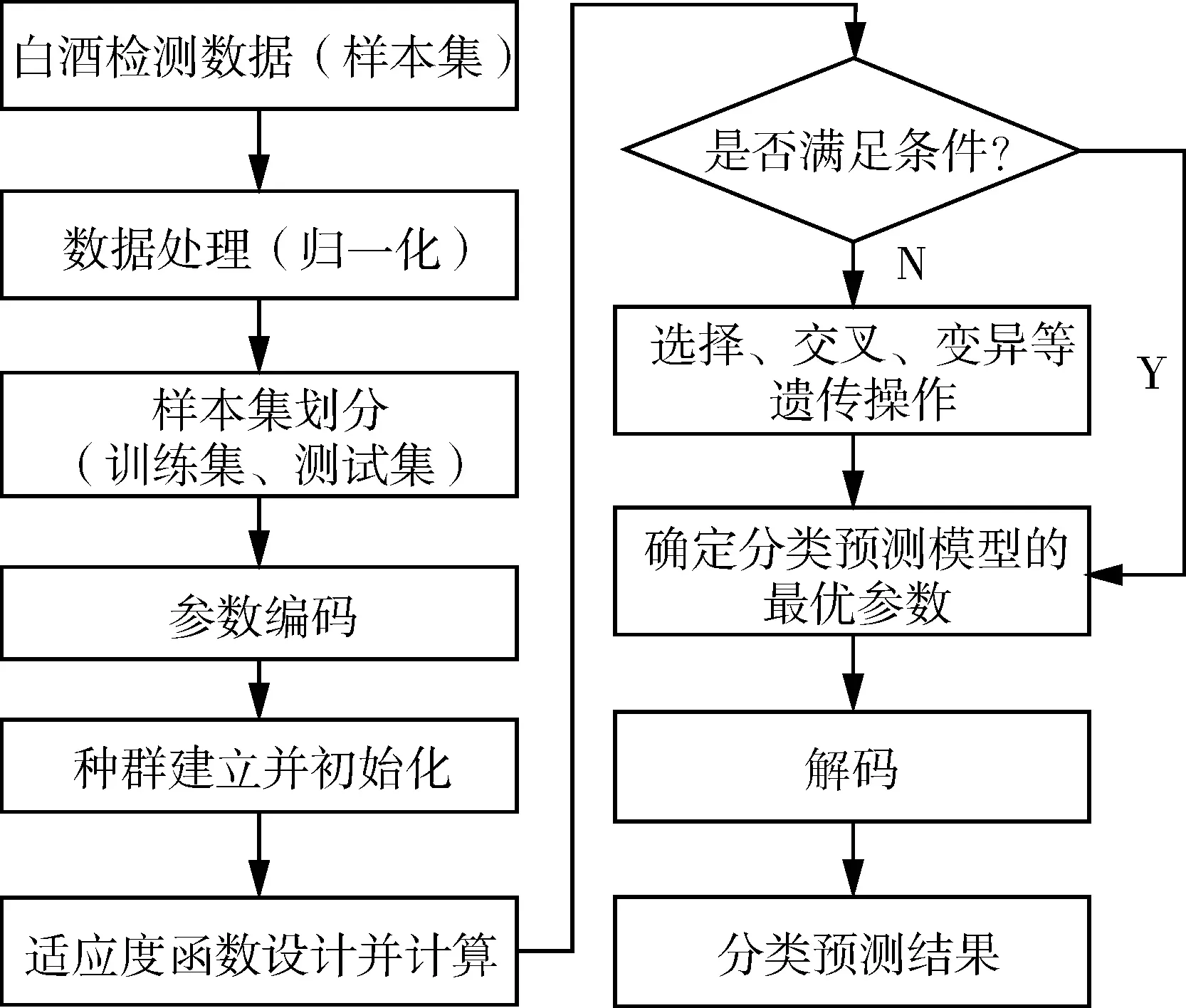
图1 GA-SVM参数优化流程图Fig.1 Flow chart of GA-SVM parameter optimization
2 试验验证
2.1 试验装置
电子舌具有操作简单、稳定性强、效率较高等优势,近年来被广泛应用于食品生产与检测、生物医药、环境(空气、水、土壤)健康检测和化工检测等领域[11]。试验使用电子舌作为白酒数据的采集装置,为分类识别模型的建立提供数据支撑。本文采用伏安型三级阵列式传感器。为更加准确、稳定地测得白酒内部的详细信息,工作电极采用贵金属组合(铂、银、钨、钛、钯、金等6个工作电极),辅助电极(铂柱电极)联合工作电极组成独立的单元结构,再结合参比电极(铂柱电极)共同组成1个完整的传感器阵列。
伏安法是电子舌检测的基本方法,本文将常规的大振幅脉冲伏安法进行优化,提出多频大振幅脉冲的测试方法,即把脉冲间隔缩短(时间和频率为反比例关系),加大振幅脉冲的频率(次数)。将脉冲时间间隔以10的指数规律减小,组合成不同频段的大振幅脉冲,最终采取1,10,100 Hz 3个频率段的大振幅脉冲,把脉冲时间间隔设为1,0.1,0.01 s。
在电子舌阵列式传感器中,每个工作电极采用环形结构设计,使得工作电极之间的距离保持一样,6个工作电极围绕辅助电极呈环形排列。每个工作电极的直径为2 mm,辅助电极的外径和内径分别为40 mm和14 mm,辅助电极与工作电极的面积比非常大(351倍),2者面积的悬殊可以保证在极化电流中辅助电极的极化现象,同时可以保证辅助电极的电势值能够保持稳定,对电流信号的测量起到稳定作用。整个设备工作的工作温度15~35 ℃,工作湿度0%~80%RH。设备开机后在0.01 mol/L氯化钾溶液中对传感器预热30 min,分别设置系统的起始电压、结束电压和步降降压值为 1.0,-1.0,0.2 V。
2.2 数据获取
乙醇与水是白酒的主要成分,含量达98%左右,其他的成分如有机酸、甲醇、多元醇、醛类、羧酸等微量成分所占的比重仅为1%~2%。微量成分的种类与含量是决定白酒品质的关键因素,到目前为止,能够检测出的已达300余种。传统的白酒检测方法如气相(GC)、液相(HPLC)等能够对白酒进行分类,但耗时较长,无法实现快速分类。品酒师依据自身的感官经验能够分辨不同的白酒,但由于生理、心理等主客观因素的影响,使得结果稳定性较差,并且训练成本较大。
使用电子舌阵列式传感器对不同品牌和不同产地的白酒进行检测。为保证待测样品数据采集的随机性,分别对每类酒进行若干次采集而非固定采集次数,形成N*6维的样品数据集。随机选取4类白酒数据建立GA优化SVM参数的分类预测模型,分别用数字1,2,3,4对选取的样品数据进行类别标识,具体信息如表1所示。从每个类别的测试数据中,随机、均匀地选取总计150*6维的数据作为分类预测模型的测试样本集,部分数据如表2所示。传感器采集的所有数据的属性分布如图2所示。

表1 待测不同品牌样品酒Tab.1 Sample liquors of different brands to be tested
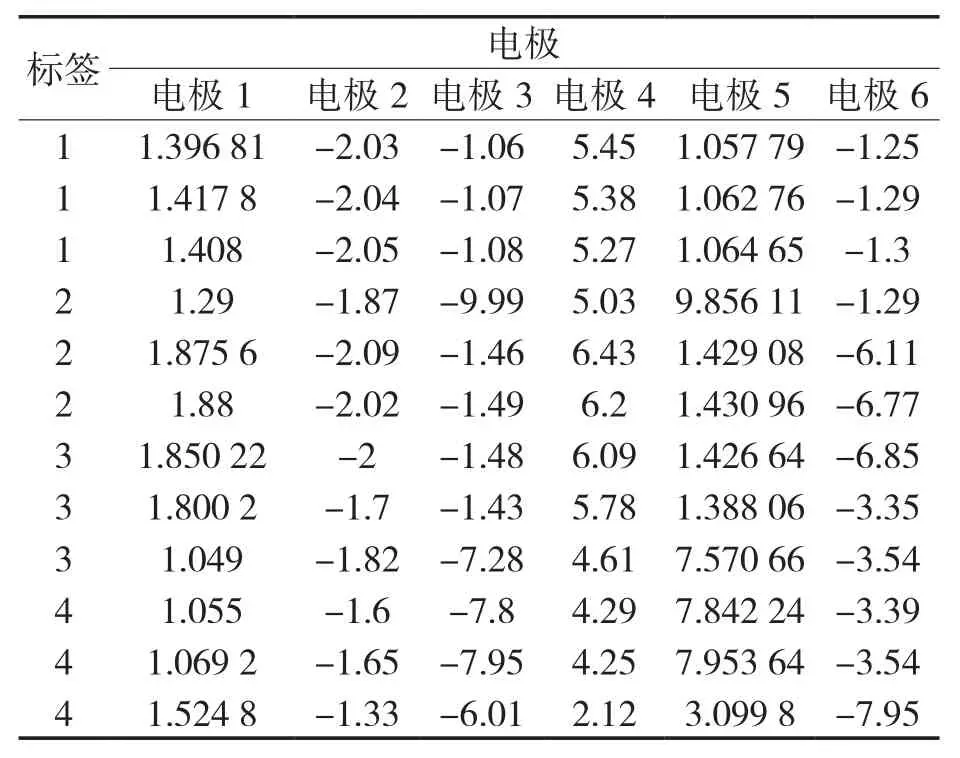
表2 部分样品测试数据Tab.2 Test data for selected samples
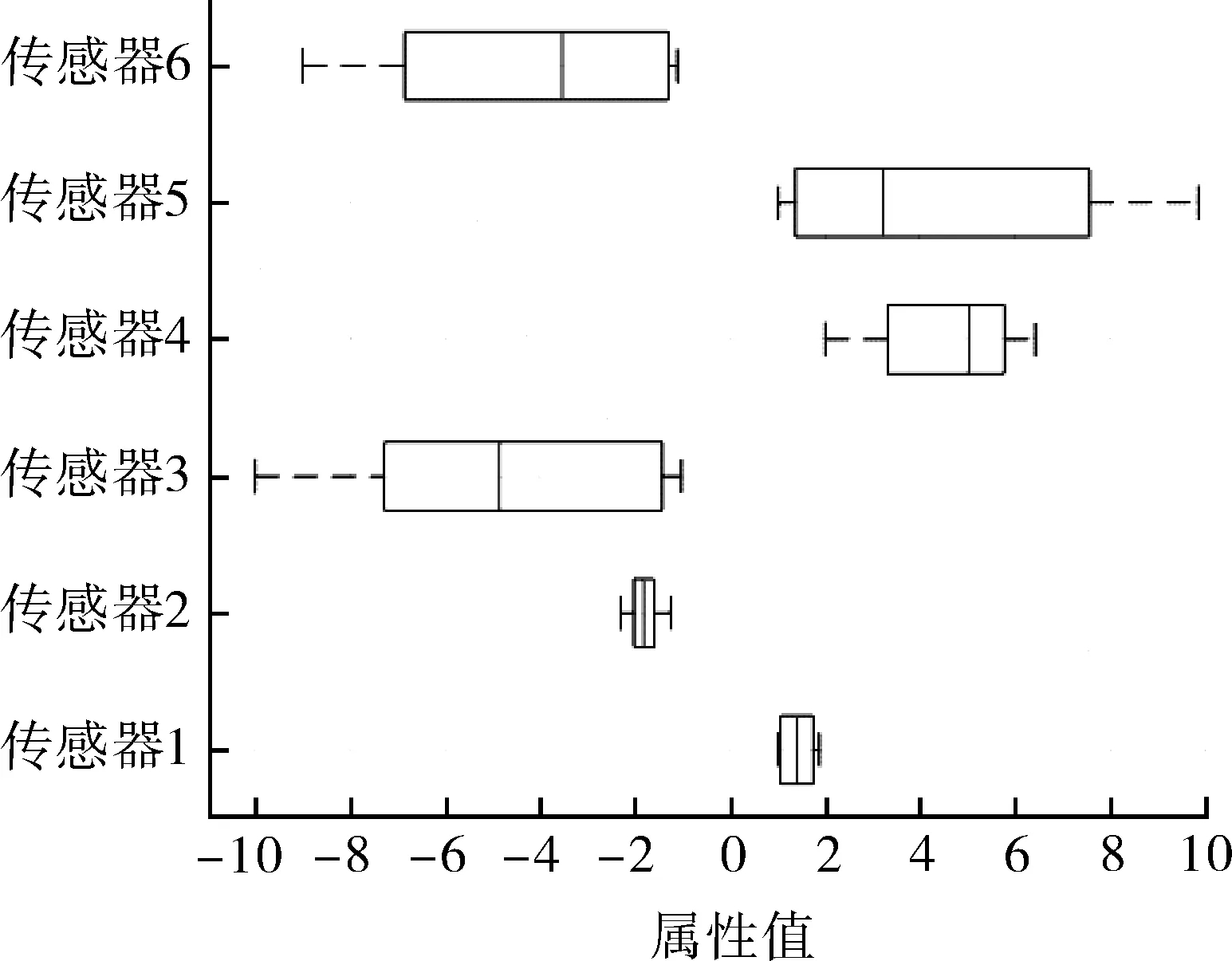
图2 样品各个属性分布图Fig.2 Distribution of individual properties of the sample
2.3 数据分析与处理
在测试数据中,不同维度对应值的范围不同。为消除数据量级带来的影响,将所测数据进行归一化处理,范围设置为[0,1]。由于分类预测模型的性能检验方法采用的是交叉验证法,所以将测试样本集进行类别均匀划分,其中1~30;61~90;121~150为训练集,31~60;91~120;151~184为测试集,并对训练集和测试集进行标签设定。在模型中,GA的参数设定对模型的性能影响较大,经调整,设定初始化种群数目为100;最大迭代次数为200;交叉验证参数为0.7;变异概率为0.05。经模型训练后可确定最优的分类预测模型中惩罚参数C=2.061 8,核函数γ=1.715 7。经交叉验证法验证,训练集的准确率可达100%,测试集经模型预测,识别率为97.872 3%。
2.4 效果对比分析
在基于SVM算法的分类预测模型中,不同的SVM内核函数呈现的分类预测效果也各不相同。基于不同内核函数的白酒分类预测模型的效果对比如表3所示。

表3 不同核函数识别率比较Tab.3 Comparison of recognition rates of different kernel functions
由表3可知,以RBF为内核函数的分类预测模型效果最佳。与此同时,把GA优化SVM参数的分类预测模型与基于K-CV算法、粒子群优化支持向量机算法(POS-SVM)建立的分类预测模型进行效果对比[12-13],具体如表4所示。

表4 不同方法识别率比较Tab.4 Comparison of recognition rates of different methods
由表4所知,基于K-CV算法的分类预测模型在时效性与准确性方面表现较差;POS-SVM算法与GA-SVM算法在时效性方面表现相当,但GA-SVM算法的分类预测模型具有更高的准确性。
3 结语
采用多脉冲阵列式传感器(电子舌)对白酒的内部信息进行采集,通过提取各个传感器的电脉冲信号作为模型训练的数据样本,建立基于GA优化SVM参数的白酒分类预测模型,对样本数据进行训练,从而实现对未知的白酒样本数据进行分类识别预测。通过与不同方法建立的分类模型进行效果对比可知,基于GA优化SVM参数的白酒分类预测模型拥有较高的准确性与高效性,能够较好地满足当前的生产所需。
随着检测技术的快速发展,白酒的测试数据以量级的方式陡增。与此同时,在白酒市场不断扩大的背景下,白酒的生产过程对白酒的分类识别的要求越发苛刻。实现智能、快速、准确的白酒自动化分类是未来的发展趋势。把人工智能技术与白酒分类识别进行深度融合,给在白酒测试大数据背景下快速且准确地实现不同品牌、不同产地、不同年份以及不同等级的酒液识别带来可能。
