基于天际线算法的主题排序方法研究
2022-05-19万校基李海林龚燕燕林海龙
万校基,李海林,龚燕燕,林海龙
(1. 华侨大学工商管理学院,泉州 362021;2. 华侨大学东方企业管理研究中心,泉州 362021)
1 引 言
信息爆炸时代,面对海量科技文献,科研人员难以高效地获取学科研究热点和发展趋势。与此同时,相关期刊也面临如何甄选符合时代特色和学科发展趋势文献的困境。为全面深入了解相关学科发展态势,迫切地需要对科技文献的主题进行深层次挖掘、梳理与分析。
近年来,国内外研究者对科技文献主题进行了大量研究,主要集中于主题识别和主题排序等方面。①主题识别方面:较多研究者通过词频分析[1]、共词分析[2]、共引分析[3]等文献计量统计法来开展研究,其中词频分析法主要是通过关键词频数来识别相关文献主题,缺乏对关键词之间相关性的考虑;共词分析法是结合关键词共现次数和Jaccard、余弦指数等相似性度量方法来构建关键词相似性矩阵,再通过层次聚类、多维尺度分析和社会网络分析等方法来进行主题划分和提取,缺乏对关键词在不同文献中重要性的考虑,同时也面临着提前设置聚类个数和尺度大小等人为主观因素的影响;共引分析法是通过分析文献之间的引用和被引用关系,以及多维尺度分析和聚类等方法获取相似主题,需要花费大量时间对共引文献开展分析。随着数据挖掘技术的进一步发展,部分研究者在共词分析的基础上,借助相关聚类算法来开展主题分析研究。如传统经典聚类算法k-means[4],由于原理简单,可解释度较强,其在文本聚类[5]和机器学习[6]等方面得到了广泛的应用。然而该方法对噪音和异常点数据比较敏感,易获得局部最优,同时聚类效果严重依赖于初始中心点。为此,Frey 等[7]基于图论提出了近邻传播(affinity propagation,AP)聚类算法,相比于其他聚类算法,该算法将每个数据点作为初始代表点,不需要设置初始中心点和聚类个数,可自适应对文献主题进行识别。鉴于其重要作用,AP聚类算法在计算机[8]、图书情报学[9]和工程学[10]等多个领域获得了广泛应用,然而,大部分研究仅是对首次聚类后的初始核心主题簇开展分析,未细粒度地揭示相关文献主题,缺乏对学科研究的深入了解。因此,如何科学度量关键词重要性,并细粒度地揭示科技文献主题已成为当前主题识别研究中的重要问题。②主题排序方面:部分研究者基于相关机器学习算法如TF-IDF(term frequency-inverse doc‐ument frequency) 加权技术[11]和概率主题模型[12-13]等对相关学科研究主题进行了排序研究,然而他们在计算过程中的时间代价和资源消耗相对过高;与此同时,他们的研究缺乏对用户需求因素的考虑。为此,李秀霞等[14]基于文献计量和主题挖掘方法,从读者和研究人员两个视角,通过发文趋势和引文趋势对学科研究主题进行了合理排序,但美中不足的是,他们需要结合数据不同分布特点自定义发文趋势和引文趋势的运算关系。考虑到文献计量统计方法更容易理解,便于操作,且效率较高,有一部分研究者借助文献计量学参量开展科技文献主题排序。如蒋卓人等[15]采用了主题出现频率、被引用次数和PageRank 值三种排序方式对中英文科技主题进行了排序,并且以此为基础,对中英文科技主题在各自数据集中的排序相关性进行了对比分析。然而,他们在表征科技文献主题热度时,仅用到一维度量指标,未能准确和全面地揭示科技文献主题热度。因此,如何降低数据高维复杂特征,并快速准确地获取科技文献主题热度已成为主题排序研究中最具有挑战性的难点之一。
针对当前研究存在的一些不足,本文提出了一种将主题识别与主题排序相融合的新方法。通过共词分析法和近邻传播(AP)聚类算法自适应获取初始学科研究主题[16],对低于总体平均相似性的主题簇进行二次AP 聚类,进而自动实现学科研究主题精确细划分。与此同时,为进一步分析同类各主题热度,以主题簇内中心代表关键词的篇均被引量和篇均下载量为特征指标[17],借助天际线算法(skyline algorithm)[18]和主成分分析法(principal component analysis,PCA)[19]获取各主题热度,最后以供应链相关期刊文献为例开展实验分析,为相关科研人员和期刊的重要决策提供技术支持。
本研究的主要贡献体现在:①通过共词分析法、加权Ochiia 系数和AP 聚类算法自适应识别了相关领域研究主题,量化了关键词在文献不同位置的重要性,减少了传统主题提取方法如层次聚类、多维尺度分析和社会网络分析等提前设置聚类个数和尺度大小等人为主观操作的影响。②有别于传统一次聚类划分主题,基于平均相似性系数精准筛选待细划分主题簇,并对筛选后的主题簇进行二次聚类,确保了细粒度研究主题的精准识别。③借助天际线算法和主成分分析法分析二次主题聚类结果,不仅降低了算法复杂度,而且细粒度地揭示了相关领域研究主题热度。④新方法的运用,不仅可为相关领域研究者的科学选题提供指导意见,也可为相关期刊的精准选稿提供决策支持。
2 理论基础
2.1 相似性度量
传统共词分析法在利用Ochiia 系数、Jaccard、余弦指数和TF-IDF 等度量关键词相似性时,会忽视同一关键词在不同文献中的不同重要性程度,一定程度上影响了相关领域研究主题的准确识别。鉴于关键词的重要性在一定程度上与作者给出的关键词顺序有关,排序越靠前的关键词,其对主题的描述力越强,重要性也越大。为度量关键词的重要性,李海林等[20]根据关键词在文献中出现的顺序计算了对应权重wKeypk,并以wKeypk为基础度量了关键词两两之间相似性Sw(i,j),其定义的公式为

其中,Kp代表第p篇文献中的关键词个数;k代表第p篇文献中的第k个关键词。
2.2 近邻传播(AP)聚类算法
近邻传播(AP)聚类算法是基于数据点间的“信息传递”的一种聚类算法,根据n个数据点之间的相似度进行聚类。在数据点间迭代传递归属度(availability) 和吸引度 (responsibility) 这两种消息,直到迭代过程收敛,类代表也随之固定,同时将其余的数据点分配到相应的聚类中[20-21]。与k-均值(k-means)算法或k中心点(k-medoids)算法不同,AP 算法不需要在运行算法之前确定聚类的个数。AP 算法寻找的“examplars”即聚类中心点是数据集合中实际存在的点,作为每类的代表。在AP 聚类的运算过程中,核心的两点是对代表程度r(i,k)和合适程度a(i,k)的迭代和更新。代表程度r(i,k)是表示xk的积累信息,说明了xk对所划分簇中xi的代表程度;合适程度a(i,k)代表xi的累积程度,说明了对于xi所在的簇,选择xk作为代表点的合适程度有多大。
代表程度r(i,k)和合适程度a(i,k)的计算公式为

在更新信息时,为了降低可能的振荡影响,引入衰减系数∂(0 <∂<1)来迭代代表程度和合适程度,具体迭代过程为

其中,k为簇中心;i为簇中某一个点;t为迭代次数;∂为衰减系数。
公式(5)和公式(6)说明第t+1 次迭代过程中,每条信息被设置为前次(第t次)信息更新值的∂倍加上本次(第t+1 次)迭代更新值的1-∂倍。显然,迭代后的代表程度r(i,k)和合适程度a(i,k)越大,说明k点越适合作为i点的簇中心,对i点的代表程度越大。重复以上迭代过程,直到聚类结果趋于稳定或者达到预设迭代次数,算法结束。

2.3 天际线(skyline)算法
skyline 计算求解的是一个典型的多目标优化问题,早期研究可追溯到20 世纪70 年代,其问题可以定义如下。
给定一组多维空间数据点G{p1,p2,…,pn},sky‐line 计算并返回所有不被其他点“支配(domi‐nate)”的数据点,即skyline 点;对于多维空间中的两个数据点pi和pj,如果其同时满足如下两个条件,则称pi被pj支配:
(1)在一个维度上,pj的值小于pi的值;
(2)在剩余维度上,pj的值不大于pi的值。
显然,skyline 计算的目的是查找数据集合中所有不被支配的对象所构成的集合[22],其广泛应用于多目标决策、用户偏好查询和市场分析等。
为详细论述skyline 原理,以图1 为例展开说明。假设点a、b、i、k为酒店,显然,a酒店比b酒店更便宜,而且离景区更近,我们说a点在受欢迎程度上大于b点;再比较a点和i点,a点因为离景区更近,而i点更便宜,因此,a点和i点在受欢迎程度上是相同的。

图1 skyline示例
最优skyline 包含了一系列最受欢迎酒店的集合。在图1 例子中,最优skyline={a,i,k},显然,不在最优skyline 集合内的酒店在大多数情况下不会被用户考虑。因此,折线上的点就是skyline 选出的数据点,更能满足人们的需求。

由于本文涉及的表征主题热度的指标不止一个,主题排序的任务可以看成是一个多维排序问题。天际线算法能够从多维空间中查找到不被支配的对象集合,并且能够对科学家进行排名[23],因此,本文将借助天际线算法来开展主题排序。
3 主题排序
3.1 研究思路
如图2 所示,通过词频分析法识别相关学科领域高频关键词,结合关键词重要性公式[20]和关键词相似性度量方法Ochiia 系数构建加权高频关键词相似性矩阵,利用AP 聚类算法自适应获取初始主题簇。鉴于部分初始主题簇内的关键词成员相似性不强的情形,对低于总体平均相似性的初始主题簇进行二次AP 自适应聚类。以最终主题簇内中心代表关键词的篇均被引量和篇均下载量为主题热度表征指标,利用天际线算法获取主题天际线集合,最后对其进行主成分降维,从而实现主题热度排序。

图2 本研究思路
3.2 主题排序方法
基于AP 聚类算法、skyline 算法和主成分分析法(PCA),本文构建主题排序方法,命名为ASP算法。

通过关键词权重公式(1)和相似性公式(2)构建加权关键词相似性矩阵,利用AP 聚类算法对其进行自适应聚类。针对某些主题簇中关键词成员之间的相似性偏低、中心代表关键词涵盖不全等问题,再次通过AP 聚类算法实现主题再聚类。统计相关主题簇中心代表关键词的篇均被引量和篇均下载量,对每个核心主题簇用天际线算法得到核心主题天际线集合,选取每个主题簇中最外层的核心主题作为天际线集合,对筛选后的天际线集合进行PCA 降维处理,进而获取到最终主题排序结果。
4 实验分析
为验证本文提出的主题排序方法(ASP)的有效性和可行性,本节将以供应链相关文献为例开展实验分析。
4.1 数据来源与处理
选取中国知网(China National Knowledge Infra‐structure,CNKI) 中收录于SCI(Science Citation In‐dex)、EI(Engineering Index)、CSSCI(Chinese So‐cial Sciences Citation Index)、 CSCD (Chinese Sci‐ence Citation Database) 中与供应链相关的期刊文献,检索的主题词为“供应链”,来源时间为2010—2020 年,数据收集时间为2020 年12 月21 日。为排除不相关文献的干扰,保证研究的可信度,剔除通知、征稿文件、专访和会议等文献,最终获得6329 篇有效文献,其中关键词26735 个,篇均关键词4.22 个,不重复的关键词7114 个。图3 为供应链相关期刊文献的每年发表情况。

图3 供应链相关期刊文献的每年发表情况
由图3 可知,2010—2020 年,供应链领域发表论文的数量波动不大。2010 年和2013 年的发文量略微高于其他年份,从2015 年起,每年的发文量呈小幅度的下降趋势,这似乎表明,学术界对供应链相关研究的热度有下降趋势。
4.2 初始主题识别
关键词是期刊文献核心内容的浓缩和提炼,具有较强的主题代表性[24]。通过统计关键词在标题或摘要中的概率,李海林等[20]发现,不同顺序的关键词对相关主题的描述力不同,排位越靠前的关键词,其对主题描述力越强。此外,蒋卓人等[15]也阐述了关键词作为学术主题的优势,即关键词不仅可以更为准确和全面地概括文献主题,也可以让主题在语义表现层面上更有解释性。鉴于关键词的较强主题代表性,本文将用其来表示期刊文献主题。
为便于后续初始主题识别,选取频数超过10 的336 个高频关键词来开展分析。
根据公式(1)和公式(2)可计算得到336 阶加权关键词相似性方阵:

对矩阵(7)进行AP 自适应聚类,最终可得到如图4 所示的11 个初始主题簇。
由图4 可知,颜色相同的小圈属于同一个主题簇,每个簇中间的关键词与邻近的关键词成员联系密切,是该主题簇的核心主题。通过AP 聚类获得的11 个初始核心主题分别为“供应链”“外包”“供应链整合”“供应链能力”“随机需求”“供应链金融”“知识共享”“信息共享”“STACKELBERG博弈”“博弈论”和“供应链协调”。以初始核心主题“供应链金融”为例,其包含的关键词成员有区块链、中小企业融资、商业银行、资金约束等,从概念上可以看出这些关键词之间联系较为紧密。白燕飞等[25]提到,“未来区块链SCF(供应链金融,supply chain finance)平台要从更广阔的发展视角出发,重在助力供应链产业链的补链、强链,以综合性金融服务基础设施的方式在产业网络中推广和应用,能够更好地发挥市场激励机制,规范供应链的运营”,其清晰地揭示了“供应链金融”“中小企业融资”“区块链”这几个关键词的密切关系。对于以“供应链”为核心的主题簇,可以看到簇内含有“非对称信息”“应急管理”等关键词,从概念上来看,联系并不太紧密,但崔玉泉等[26]研究了非对称信息下供应链在突发事件下的应急管理和信息价值问题,刚好说明一些新理论概念的提出,有可能会将传统看来关系不紧密的主题联系起来。

图4 初始主题簇(彩图请见https://qbxb.istic.ac.cn/CN/volumn/home.shtml)
量化主题簇内各关键词成员之间的紧密程度,需要计算核心主题簇中各个成员之间的平均相似性Savg。假设某个核心主题簇所对应的关键词相似性矩阵为

则该主题簇对应的平均相似性Savg为
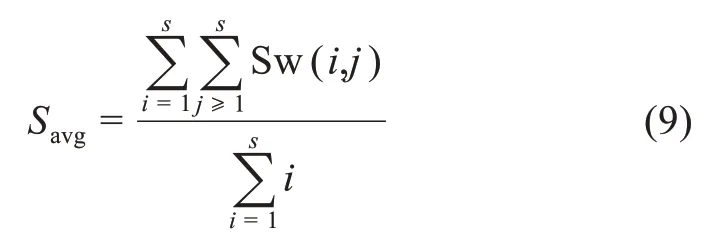
其中,关键词i和j之间的相似性Sw(i,j)由公式(2)计算得出。
对首次AP 聚类的11 个初始主题簇进行平均相似性计算,最终得到的结果如表1 所示。

表1 初始主题簇的平均相似性
为衡量首次AP 聚类效果,计算所有初始主题簇的平均相似性AVG(Savg)=0.136。显然,针对平均相似性小于AVG(Savg)的主题簇,我们可以认为其簇内关键词成员之间的相似性较低,即该主题簇的中心代表关键词未能更好地反映成员关键词所蕴含的主题,因此,有必要对其进行再次聚类。
4.3 最终主题识别
鉴于首次聚类效果不理想,有必要对平均相似性较低的主题簇进行二次聚类。考虑到中心代表关键词“供应链”所在簇的关键词成员平均相似性最小(Savg=0.021),下面将以其为例开展主题分析。
类似首次AP 聚类过程,对以“供应链”为核心的主题簇进行二次AP 聚类,最终可得到如图5所示的聚类结果。
由图5 可知,对以“供应链”为核心的主题簇进行二次AP 聚类,最终可得到27 个主题簇。其中“网络设计”“农产品”“供应商选择”等中心代表关键词被分在了不同的主题簇中,而在同一个簇中的关键词往往具有较高的相关性,如在以“契约”为核心的主题簇中,含有“竞争”“协同机制”和“博弈”三个关键词成员,这些关键词之间的紧密关系在赵青松等[27]的研究中得到了很好地体现,其构建并分析了价值网络模式下各参与主体间的协同竞争博弈模型。

图5 二次AP聚类结果
此外,我们也发现,二次聚类后的大部分主题都由3 个或4 个关键词所刻画,说明了在海量数据文献中,往往是特定几个关键词之间联系较为紧密,因此,可以选取每个主题簇的中心代表关键词作为该主题簇的代表。
4.4 主题天际线集合构建
以二次聚类后的各主题簇中心代表关键词的篇均被引量和篇均下载量为主题热度表征指标,并以其为基础来构建主题天际线集合。图6 展示了频数排名前15 位的关键词篇均被引量和篇均下载量。
如图6 所示,频数最高的关键词不一定具有最高的篇均被引量和篇均下载量,例如,“供应链”为频数最高的关键词,但其篇均被引量和篇均下载量却低于“供应链金融”和“协调”等关键词。而篇均下载量少的主题,也不一定拥有较少的篇均被引量,例如,“再制造”对应的篇均下载量为736,虽然其比“供应链金融”对应的篇均下载量少了80,但是“再制造”的篇均被引量却比“供应链金融”对应的篇均被引量高出了15。

图6 频数排名前15位的关键词篇均被引量和篇均下载量
显然,以上结论充分说明了单个关键词的篇均被引量或篇均下载量难以客观揭示相关主题热度。因此,有必要结合两者来表征相关主题热度。
由于聚类后每个主题簇含有的关键词成员个数不同,有可能会导致含有较多关键词成员的主题簇的整体被引量和下载量高于其他主题簇。为消除此因素影响,本文将以主题簇中心代表关键词的篇均被引量和篇均下载量来度量所在簇的主题热度。通过天际线算法的应用,可得到如图7所示的主题天际线集合。
图7 说明了在二次聚类得到的27 个主题簇中,存在12 条天际线,其中右上角最外围的天际线只有一个主题“合作伙伴”,该主题的篇均被引量和篇均下载量均高于其他主题,显然,我们可以认为“合作伙伴”是“供应链”这个主题簇下热度最高的主题。而除去“合作伙伴”这个主题后,可以看到“SHAPLEY 值法”和“质量控制”所在的天际线集合区域在剩余的主题中拥有最高的热度,因此将“SHAPLEY 值法”和“质量控制”作为第二条天际线集合,其热度低于第一条天际线集合。同理,图7 显示的单个主题“供应商选择”所在的天际线集合区域位于所有集合的最低处,可以认为在篇均被引量和篇均下载量这两个控制因素下,该主题的研究热度最低。

图7 主题天际线集合(彩图请见https://qbxb.istic.ac.cn/CN/volumn/home.shtml)
4.5 主题热度排序
通过天际线算法得到的主题天际线集合,只是找出了在被引量和下载量两个维度下的各主题集合热度,还需要进一步通过主成分分析法进行降维,从而进一步客观揭示主题热度。
结合主题天际线集合和主成分分析法,可计算得到如表2 所示的主题排序结果。
如表2 所示,“合作伙伴”在“供应链”主题下拥有最高的热度,在CNKI 上将其与“供应链”一起搜索,结果显示,“合作伙伴”在“供应链”领域下仅有12 篇期刊文献,但其篇均被引量和篇均下载量均位居所有主题首位;显然,肖静华等[28]的论文《从面向合作伙伴到面向消费者的供应链转型——电商企业供应链双案例研究》在很大程度上提升了该主题热度,当前该文献被引量已经接近250 次,同时下载量已超过2.2 万次。此外,主题“SHAPLEY 值法”的热度也高于“质量控制”,从其所在聚类簇的关键词成员来看,相比于研究“契约设计”和“网络均衡”,科研人员可能更热衷于研究“碳交易”和“利益分配”。再如,“零售商”的热度高于“复杂网络”的热度,在CNKI 上将这两个词与“供应链”一起搜索,结果显示,“零售商”在“供应链”领域下的期刊文献篇数更多(“零售商”1001 篇,“复杂网络”20 篇),且“零售商”比“复杂网络”在供应链领域下的讨论范围更广。类似地,其他主题在篇均被引量和篇均下载量上也存在一定差异,以至于它们呈现出不同的排序结果。

表2 主题排序结果
4.6 排序结果的可靠性分析
为验证ASP 算法的排序结果可靠性,有必要将其与既往典型主题排序方法进行对比。
通过文献梳理可知,当前主题排序方法主要有机器学习算法[11]、概率主题模型[12-13]、文献计量统计方法[14-15]等,虽然各类排序方法均有各自的优势,但没有统一的评价标准来说明它们的优劣。从现有主题热度的度量指标来看,大部分指标是一维指标,如主题出现频率[15,29]、被引量[15,30]、下载量[30]、PageRank 值[15]等,有少量研究涉及二维度量指标[14],但其构建的主题排序公式有较大主观性。本文将以初始核心主题“供应链”的二次聚类结果为例,重点对比分析由主题出现频率、篇均被引量、篇均下载量、PageRank 值和ASP 等排序方法决定的前10 位主题。
根据相关主题排序公式计算,可得到如表3 所示的排序结果。
如表3 所示,在不同排序方法下,排名前10 位的主题存在一定重叠,为度量不同排序方法之间的主题重叠程度,定义某排序方法的主题重叠率为该排序方法与其他排序方法比较时,重复的主题总数与被比较的主题总数的比值。

表3 不同方法的主题排序结果
通过计算,我们发现,篇均被引量排序的主题重叠率最高,达到(6+7+6+8)/40=67.5%,ASP 算法排序次之(65%),而出现频率排序、篇均下载量排序、PageRank 值排序的主题重叠率最低,均为57.5%。显然,主题重叠率体现了各排序方法之间的相似性,一定程度上也反映了相关排序方法的可靠性。一般来说,主题重叠率越高,排序方法之间的相似性就越大,对应排序方法也越可靠。虽然ASP 算法排序的主题重叠率比篇均被引量排序低2.5 个百分点,但是相比于出现频率排序、篇均下载量排序和PageRank 值排序,该算法的主题重叠率不仅高出7.5 个百分点,而且同时兼顾了主题的篇均被引量和篇均下载量两个热度指标。鉴于ASP 排序算法不仅有较高的主题重叠率,而且能够多维度全面地评估主题热度,我们推断,由该算法得到的主题排序结果是可靠的。
下文将继续借助ASP 算法对图4 中其他相似性较低的初始主题簇开展二次聚类和热度排序。
4.7 结果分析
由上文分析可知,主题排序算法ASP 是可靠的。类似地,利用该算法对图4 中平均相似性Savg小于总体平均相似性AVG(Savg)的所有初始主题簇进行二次聚类和热度排序,最终得到如表4所示的结果。

表4 初始主题簇内热度排名前2位的主题
从初始核心主题来看,7 个主题均来自原始数据的第一次聚类,但其所在主题簇的平均相似性相对较低,部分主题之间存在一定重复性,例如,“STACKELBERG 博弈”和“博弈论”在概念上存在一定包含关系,但从各自所属聚类簇的关键词成员来看,“STACKELBERG 博弈”可能更倾向于说明STACKELBERG 博弈模型在低碳供应链、旅游供应链、双渠道供应链等研究领域中的应用,而“博弈论”可能更倾向于说明要以博弈论为基础来分析再制造、政府补贴、回收渠道、定价决策、供应链协同、逆向物流等问题中的博弈关系。此外,初始核心主题“知识共享”和“信息共享”也具有一定重叠性,然而从自适应AP 聚类结果来看,两者之间的差异并不小。为描述两者之间具体的联系与差异,以“知识共享”和“信息共享”所在聚类簇的关键词成员为节点,将与核心代表关键词有相似性的关键词成员连边,线越粗,代表它们之间的相似性越大,反之,则相似性越小。如图8 所示,同一聚类簇内,“知识共享”与“知识创新”相似性最大(相似度0.105),与“绿色供应链管理”相似性最小(相似度0.010);“信息共享”与“需求预测”相似性最大(相似度0.119),与“大数据”相似性最小(相似度0.006)。从横跨两个聚类簇的连线来看,“知识共享”和“信息共享”又存在一定联系:“知识共享”与“信息共享”所在簇的关键词成员“演化博弈”“价值创造”“激励机制”“本体”存在相似性,“信息共享”与“知识共享”所在簇的关键词成员“博弈分析”“大数据”“供应链绩效”“绿色供应链”“农产品供应链”“集群供应链”存在相似性。实际上,以上主题之所以会存在这种差异,可能是由于作者对这些概念存在不同的模糊认知和理解倾向,而通过自适应AP 聚类算法进行硬划分能够比较客观地揭示它们之间的差异。

图8 知识共享与信息共享的联系与差异
从主题的排序结果来看,7 个平均相似性较低的初始主题簇被进一步细分,细分后的各主题之间相似性较小,如“博弈论”下的主题“模型”和“知识共享”下的主题“结构方程模型”,虽然它们看起来存在一定联系,但是由于代表的聚类簇不同,其反映的主题也不同。从同簇内的关键词成员来看,主题“模型”更倾向于描述“协同”问题中用到的一些模型,而主题“结构方程模型”可能更倾向于说明该模型在“绿色供应链管理”和“供应链风险管理”等研究领域中的应用。同理,其他细分后的主题也可以结合同簇内的关键词成员给出合理的语义解释。
此外,在核心主题为“供应链”的初始主题簇中,“合作伙伴”和“SHAPLEY 值法”均有较高的研究热度,具有较高的研究价值。类似地,在“供应链协调”主题下,“收益共享”和“理性预期均衡”的研究热度也较高,如刁心薇等[31]在论文《混合碳政策下两产品供应链的协同研究》中重点提出收益共享契约是协调供应链的常见契约。对于“STACKELBERG 博弈”这一初始核心主题,由于其一般用于企业间的不对称竞争,伴随着“生鲜农产品供应链”被不断关注,STACKELBERG 博弈模型也常被应用于该领域,相关研究者可对此重点关注。
显然,对于相关科研人员来说,如果想在未来获得高科研绩效,可以根据本文研究方法快速找到自己学科领域下热度较高的主题,并以此作为自己主攻的研究方向;反之,如果其重点关注自身研究领域下热度较低但有一定研究前景的主题,未来有可能取得一些科研突破。另外,对于相关学术期刊来说,可以根据本研究成果重点关注和选取相关主题文章,提高选文的科学性和效率。
5 结 论
本文结合近邻传播聚类和天际线算法构建了一种主题排序方法ASP。该方法首先通过共词分析法、加权Ochiia 系数和近邻传播聚类算法自适应获取文献初始核心主题;然后基于平均相似性系数筛选待细化分主题簇,并对筛选后的主题簇进行二次近邻传播聚类,从而细粒度识别文献主题;最后借助天际线算法和主成分分析法对二次主题聚类结果进行热度排序。本文的创新性主要体现在:①通过对加权高频关键词相似性矩阵进行多次聚类,细粒度地识别了相关研究文献主题,解决了传统文献主题划分不够精细等问题。②以簇内中心关键词的篇均被引量和篇均下载量为表征指标,创新性地结合天际线算法和主成分分析法科学实现了相关主题的热度排序,克服了传统的对主题热度单一维度度量存在的缺陷。同时,由于在排序前先进行了天际线划分,较好地解决了直接使用主成分分析法排序的误差问题。本文提出的主题排序方法可以有效地识别相关研究文献主题,并且能够客观揭示它们的主题热度,不仅能为相关领域科研人员的研究方向选择提供了指导意见,也为相关期刊的精准选稿提供了决策支持。
本文在计算研究主题热度时,仅将簇内中心代表关键词的篇均被引量和篇均下载量作为表征指标,忽略了其他特征变量和时间因素可能带来的影响;同时,在具体生成主题天际线集合和降维时,缺乏对关键词重要性的进一步考虑。未来我们将进一步优化主题排序算法,例如,尝试再加入主题出现频率来表征主题热度,全面考虑关键词重要性影响,对由天际线算法和主成分分析法得到的前沿主题进行演化趋势分析。
