基于深度迁移学习的地方志多模态命名实体识别研究
2022-05-19陈玥彤
范 涛,王 昊,陈玥彤
(南京大学信息管理学院,南京 210023)
1 引 言
党的十九届五中全会通过的《中共中央关于制定国民经济和社会发展第十四个五年规划和二〇三五年远景目标的建议》中明确提出了到2035 年建成文化强国的远景目标,并强调在“十四五”时期推进社会主义文化强国建设,这标志着我国文化强国建设进入了一个新的历史阶段[1]。作为中华文化的载体和组成部分,地方志是建设文化强国的重要一环,对其进行挖掘和研究,有利于传播中华文化和增强文化自信[2]。
命名实体识别作为文本挖掘中的一项基础任务,旨在识别文本中的专有词,如人名、地名、时间、组织等,其对后续的文本知识组织和知识图谱的构建都具有重要影响[3]。目前,已有学者利用相关研究方法对地方志等文化资源进行了实体抽取。例如,李娜[4]以《方志物产》山西分卷作为语料,基于条件随机场模型实现了对物产别名实体的自动抽取。黄水清等[5]将部分人工标注的先秦古汉语语料库作为条件随机场的训练数据,利用训练生成的最优模型,对语料库中的地名实体进行自动识别。从上述工作可以看出:①当前对于地方志等文化资源命名实体识别任务的研究对象均基于文本,缺乏对多模态内容(即文本结合图片)的探究;②自动识别文本实体的模型依赖于大规模人工标注的语料,需要耗费大量的人力资源和时间。然而,随着地方志数字化进程的加快,地方志数据库提供的内容并不仅局限于文本这一单模态内容,与文本相关联的图片资源同样以结构化的方式呈现,这为地方志多模态内容的研究提供了契机。在文本命名实体识别任务中,当实体边界模糊时,仅依靠上下文难以辨别其实体类型。例如,在图1 中,倘若仅考虑文本,难以确定句子中所包含实体的边界,“江大桥”可以被视作人名,而“长江大桥”又可以被视作地名,但是当结合文本对应的图片时,则可以确定文本中提及的实体为“长江大桥”,从而准确地识别出实体。当面向某一具体领域展开实体识别研究时,通常会面临标注语料匮乏的问题。常用的解决方法是利用人工去标注数据集,但是会耗费大量的人力、物力,同时,在面向新领域时,还需标注新的语料,并不能较好地解决面向特定领域的实体识别问题。然而,通过深度迁移学习方法,利用深度神经网络预学习相关领域知识后,再对目标语料进行实体抽取,则可以有效避免对训练语料的标注。目前,已有学者利用基于深度迁移学习的方法抽取文本中的实体,应用公开数据集训练模型,结合微调的方法提升实体抽取模型的性能[6-7]。但是,目前的相关研究多集中于文本,利用深度迁移方法对多模态内容进行命名实体识别鲜有探索。基于此,为了解决目标领域标注数据匮乏的问题以及提升实体识别性能,本文提出利用深度迁移学习并结合文本和图片内容展开地方志多模态命名实体识别的研究。

图1 南京市长江大桥
多模态命名实体识别是一项新兴的任务,旨在利用多模态内容挖掘文本和图片中存在的相关语义关系,增强文本语义信息,提升模型识别实体的性能。该任务最早由Zhang 等[8]提出,其利用基于自适应多模态联合注意力机制(adaptive co-attention)的命名实体识别模型,对推特中网民所发布的包含多模态内容的帖子进行实体识别,并获得了最优结果;同时作者公开了文中所用的多模态数据集。目前,中文领域尚未有应用于多模态命名实体识别的公开数据集,因此,本文以文献[8]的数据集为基础,制作了用于深度迁移学习的平行语料。尽管图片内容能够在一定程度上提升命名实体识别任务的性能,但是文本中的语义信息依旧是实体抽取中的核心。基于此,本文提出基于深度迁移学习的多模态命名实体识别模型(multimodal named entity rec‐ognition model,MNERM)。该模型主要由四个部分组成,分别是BiLSTM-attention module(BAM)模块、adaptive co-attention module(ACAM)模块、过滤门及CRF(conditional random fields)层。为使得BAM 模块和ACAM 模块分别获取预训练权重,本文分别引入了面向人民日报语料库的BiLSTM-atten‐tion-CRF(BAC)模型和面向中文平行推特多模态语料库的adaptive co-attention CRF(ACAC) 模型,BAM 模块和ACAM 模块同样也是BAC 模型和ACAC模型的组成部分。通过在对应语料库预训练模型,将权重参数分别迁移至BAM 模块和ACAM 模块,使MNERM 模型拥有提取多模态特征的能力。尽管应用多模态特征能够提升模型性能,但依旧包含噪声,本文提出利用过滤门对ACAM 模块输出的多模态特征进行去噪,再同BAM 模块输出的文本特征进行融合,最后以微调的方式将融合后的多模态特征输入至CRF 层进行解码。
本文的主要贡献为:从多模态视角出发,提出结合地方志中的文本和图片进行命名实体的识别研究;针对目标领域标注语料匮乏的问题,提出利用深度迁移学习方法进行地方志多模态命名实体识别,并构建了MNERM 模型,该模型能够充分获取不同模态的信息表示,并能有效捕捉不同模态间的相关关系,增强文本的特征表示能力。
本文将提出的模型在地方志多模态数据集中进行了实证研究,并与相关基线模型进行对比。研究结果表明,本文提出的模型具有一定的优越性。
2 相关研究
2.1 地方志命名实体识别研究
伴随着数字化进程的加快,沉睡的人文资源逐步成为可计算的数据,这为数字人文计算打下坚实的基础。而命名实体识别作为自然语言处理中的基础性任务,其对文本的知识组织及实体间的关系抽取都有着重要的影响。为了探究古籍方志中的实体自动识别,徐晨飞等[9]采用BiLSTM-CRF、BERT 等模型对物产别名、人物、产地及引书等实体进行识别,实验结果表明,采用基于深度学习的实体识别方法能够取得较好的效果。崔竞烽等[10]基于深度学习方法,构建BiLSTM-CRF 模型对菊花古典诗词中的菊花花名、花色等实体进行识别,并同CRF 等基线模型作对比,实验结果表明,该文献提出的方法能够取得较好的效果。史书中的历史事件名是历史文本知识库的重要组成部分,唐慧慧等[11]提出以字作为最小语义单元,利用CRF 模型对魏晋南北朝史书文中的历史事件名实体进行识别,并取得良好效果。在人民日报语料库中,殷章志等[12]利用基于BiLSTM-CRF 的序列标注模型抽取文本序列的中间特征,并将其输入支持向量机中进行实体识别,并取得一定的效果。石春丹等[13]提出利用双向门控循环网络与CRF 结合的模型对文本中人名、地名和机构名等实体进行识别,该模型能够有效学习序列的时序信息,并能捕捉长距离依赖。
从上述研究可以看出,目前面向地方志等人文资源的命名实体识别研究多基于文本,并利用基于BiLSTM-CRF 架构的深度学习模型进行实体识别。与之不同的是,本文在BAC 模型中引入了自注意力机制,其能够有效增强文本的特征表示,减少序列信息中的噪声,并获得实体识别性能上的提升。除此之外,人文资源的数字化带来的并不止是单一的文本,同时有着大量可获取的对应图片资源。已有研究表明,图片的加入能在一定程度上增强和补充对应的文本语义信息[14]。基于此,本文提出结合地方志中的文本和图片,进行命名实体识别研究。
2.2 多模态命名实体识别研究
用户在网络中产生内容的多模态化,为多模态自然语言处理任务提供了丰富资源。多模态命名实体识别作为其中的一项任务,已受到学界和工业界的广泛关注。在以文本为主要处理对象的命名实体任务中,当实体存在多义性或实体边界难以区分时,仅依靠上下文对实体类别做出准确判断存在一定困难。但是当文本有着与之对应的图片时,通过观察图片内容出现的实体,则能对歧义实体做出准确预测。
在多模态命名实体识别中,文本和图片存在语义相关关系。在图片内容中,与文本中提及实体存在相关关系的仅局限于图片的部分区域。因此,Zhang 等[8]提出基于自适应联合注意力机制(adap‐tive co-attention)的多模态命名实体模型,利用词引导和图引导的注意力机制充分学习文本和图片的语义相关关系及模态交互,应用门机制进行多模态特征融合和噪声过滤,之后将多模态特征与经过BiLSTM 编码后的文本特征再次拼接,获得最终多模态融合特征,并将其输入CRF 层中进行解码,F1值达到70.69%。同样地,为了充分学习图片中与文本实体相对应的语义特征,Yu 等[14]提出基于Trans‐former 架构的多模态命名实体模型,该模型主要由单模态特征表示、多模态Transformer 及辅助实体边界检测组成,通过这些构件,模型能够较好地学习文本和图片上下文敏感特征,并能够关注到聚合多模态信息时未被充分关注的实体。为充分理解图片中的视觉内容,Lu 等[15]提出基于视觉注意力机制的多模态命名实体模型,该模型能够自动忽略与文本内容无关的视觉信息并重点关注与文本内容最相关的视觉信息,其在多个数据集中取得较好结果。
上述研究主要通过挖掘图片与文本之间的相关语义关系及不同模态间的交互,并结合注意力机制,在公开英文数据集中取得一定性能。然而,在中文领域中,多模态命名实体识别任务尚未有研究涉及,并且缺乏相关的中文多模态命名实体识别语料。因此,本文探索将公开的英文多模态命名实体识别语料库制作成可学习的平行中文多模态命名识别语料库,并将词作为句子的划分粒度,利用深度迁移学习的方法对地方志多模态数据集进行实体识别研究。
2.3 深度迁移学习研究
深度迁移学习常用的方法包括基于实例的深度迁移学习(instance-based deep transfer learning)、基于映射的深度迁移学习(mapping-based deep transfer learning)、基于神经网络的深度迁移学习(networkbased deep transfer learning)以及基于对抗的深度迁移学习 (adversarial-based deep transfer learning)[16]。其基本思想是利用在源域(source domain)训练的深度神经网络中的知识解决目标域(target domain)中的问题。
目前,已有相关文献利用深度迁移学习方法进行命名实体识别研究。武惠等[17]提出利用基于实例的深度迁移方法学习样本特征,构建BiLSTM-CRF模型对人民日报语料库中的实体进行识别,并取得一定效果。王瑞银等[7]在源域中训练语言模型预测模型,将源域模型知识迁移至目标域模型中,从而对实体进行识别,其在法律文书数据集中性能良好。为了缓解可利用标注语料的不足,Lee 等[6]提出在大型源数据集中训练BiLSTM-CRF 实体识别模型,结合微调的方法对目标域的实体进行识别,并取得了一定的效果。
为了有效获取文本的语义知识和文本结合图片的多模态知识,本文应用基于神经网络的深度迁移学习思想,提出在两个源域数据集中训练与目标模型对应部分有着相似结构的深度学习模型,然后将预训练模型中的权重迁移至目标模型的对应结构中,最后结合微调的方法对地方志多模态数据进行实体识别。
3 模型设计
为了提升地方志中模型识别实体的性能并探索解决目标领域标注语料匮乏问题,本文提出基于深度迁移学习的多模态命名实体模型MNERM,结构具体如图2 所示,其分别由BAM 模块、ACAM 模块、过滤门及CRF 层组成。本文首先分别在人民日报语料库和中文推特多模态数据集这两个源域预训练BAC 模型和ACAC 模型。然后,利用基于神经网络的深度迁移学习方法,将BAC 模型和ACAC 模型中的对应权重分别迁移至BAM 模块和ACAM 模块中,使得MNERM 具备抽取文本和图片的多模态特征能力。接着,将文本特征和经过过滤门过滤的多模态特征进行中间层融合,输入CRF 层中进行解码生成标签,并进行微调。下文将详述MNERM 模型及建模方法。

图2 基于深度迁移学习的多模态命名实体识别模型
3.1 特征提取
1)文本特征提取
文本的特征表示对下游任务的表现有着重要影响。本文利用在百度百科大规模语料中预训练的中文词向量模型[18],对文本进行特征表示。MNERM模型以Skip-Gram 模型为基础,并结合负采样技术进行优化,其在中文类比推理任务中取得最优结果。本文利用MNERM 模型分别对人民日报语料库、中文推特多模态语料及地方志多模态语料库中的句子进行文本表示。
2)图片特征提取
以卷积神经网络(convolutional neural network,CNN)[19]为基础构建的模型,如VGG16、VGG19等[20],在多个计算机视觉任务中均获得了最优结果。这一方面得益于CNN 强大的特征学习建模能力,另一方面则受益于大规模的图片训练集,如Ima‐geNet[21]。目前常用的图片提取方法是利用ImageNet数据集中预训练的CNN 模型,提取最后一层全连接层的输出作为图片的特征表示。但为了获取图片的空间特征表示,本文遵循文献[8]中的方法,以预训练于ImageNet 数据集的VGG19 模型中的最后一层池化层的输出作为图片的特征表示。本文利用MNERM 模型分别提取中文推特多模态语料及地方志多模态语料中的图片特征。
3.2 BiLSTM-attention-CRF模型
文本的语义信息是识别实体类别的核心,已有研究表明,将人民日报语料库(1988)作为迁移学习的学习语料,并利用基于深度迁移学习的方法对其他语料库中的相同实体进行识别,有着良好的效果[17]。为了使MNERM 模型中的BAM 模块拥有先验知识,本文设计了用于权重迁移的BAC 模型。目前常用的命名实体模型多基于BiLSTM-CRF 架构[7-8],与之不同的是,本文引入了自注意力机制(self-attention),而利用自注意力机制能够有效增强文本的语义表示。BAC 模型主要由BiLSTM 网络、自注意力层及CRF 层。BAM 模块由BAC 模型中的BiLSTM 网络和自注意力层组成。BiLSTM 作为循环神经网络(recurrent neural network,RNN)的变体,能够较好地学习句子中的上下文关系,具有捕捉长距离依赖的能力,并能够克服因序列长度过长所带来的梯度消失和梯度爆炸的问题。给定人民日报语料库中的句子S={s1,s2,…,si,…,sn},进行特征表示后 的 句 子 为其 中 ,n表示句子长度,dw表示向量维度,大小为300。BiLSTM 获得的隐藏层状态hi∈Rd由前向的LSTM输出和反向的LSTM 输出拼接而成,d表示隐藏层单元数,具体公式为

注意力机制起源于人类视觉,当人观察物体或阅读书本时,会对其中的某一区域投入大量注意力,获取富含价值的信息,并抑制对其他区域的注意力投入。目前已有工作利用注意力机制进行自然语言处理任务,如机器翻译、情感分析等;而有关利用自注意力机制进行命名实体识别任务的研究相对较少。通过利用注意力机制,能够确定在决定词的标签时,有多少词的信息被利用,从而提升模型性能。自注意力机制关注句子内部的特征相关性,并能够减少对外部特征的依赖。在自注意力机制中,句子中的每个语义单元同其他语义单元进行注意力权重计算,可以有效捕捉词间的相互关系,获取句子结构信息,增强特征表示。自注意力机制本质上是输入Query(Q) 到一系列键值对(Key(K),Value(V))的映射函数,对BiLSTM 生成的句子表示H={hi|hi∈ Rd,i= 1,2,…,n},应用自注意力机制获得的编码表示为E={ei|ei∈Rd,i= 1,2,…,n},具体公式为

其中,Q、K、V为隐藏层状态hi的特征;Softmax 为归一化函数。将编码后的文本表示输入CRF 层进行解码,获得文本中词对应的预测标签Y={y1,y2,…,yi,…,yn},

其中,W、b表示全权重矩阵。本文利用经典的最大条件似然估计对CRF 层进行训练,具体公式为

3.3 自适应联合注意力机制模型
鉴于当前尚未有中文多模态命名实体识别公开数据集,仅有英文推特多模态命名实体识别公开数据集,目前已有研究涉及利用英译汉平行语料来进行深度迁移学习,并在公开数据集中取得了较好的性能[22]。因此,本文制作了推特多模态数据集的中文平行语料作为ACAC 模型的训练语料,将ACAC模型中自适应联合注意力网络的权重灌入ACAM 模块中,其主要由自适应联合注意力机制网络和CRF层组成。不同于自适应联合注意力机制结构[8],在ACAC 模型中,本文将VGG-16 图片特征提取模型替换成性能更佳的VGG-19[23],其余部分保持一致。
自适应联合注意力机制由词引导的注意力机制(word-guided attention,WGA)、图引导的注意力机制(image-guided attention,IGA)和门机制组成。由图1 可以看出,图片中仅包含长江大桥的区域与文本中的“长江大桥”有关,如果考虑图片中的全部区域,那么会带来噪声和信息冗余。词引导的注意力机制核心思想是给序列中的一个词,利用Softmax函数计算图片中的各个区域同该词的相关程度,过滤掉与其不相关的区域和信息,减少计算复杂度,以达到最优结果。应用词引导的注意力机制,则能让模型过滤掉噪音并找出与当前词最为相关的图片区域。给定文本序列X={x1,x2,…,xt,…,xn},利用BiLSTM 编码后的输出表示为M={mt|mt∈Rd,t=1,2,…,n},利用VGG19 模型提取与文本相对应的图片特征为T={ti|ti∈ R512,i= 1,2,…,49},其中特征图的数量为49,512 表示特征图的维度。应用词引导的注意力机制得到与词mt相关的图片特征向量

其中,θw为词引导的注意力机制中的参数。利用WGA 能够获得与词mt相关的图片特征向量但是并不知道序列中的哪个词与mt相关。因此,需要利用图引导的注意力机制去寻找与图片特征的最相关的词。图引导的注意力机制的核心思想是在给定新的图片特征向量下,计算序列中的词同图片特征向量的相关程度,从而提升序列的特征表达能力。因此,利用IGA 可以计算出与图片特征表示相关的词
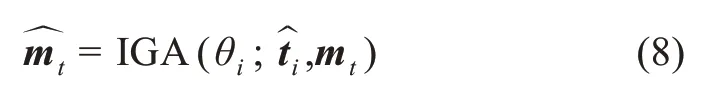
其中,θi为图引导的注意力机制中的参数。门机制主要由融合门和过滤门组成。为获得文本和图片的多模态特征表示,利用门机制中的融合门对新获得的依赖于IGA 的词特征和依赖于WGA 的图片特征向量进行拼接,获得多模态融合后的中间特征表示。尽管利用WGA 和IGA 能够生成富含多模态语义特征的中间表示,但是依然存在噪声。例如,当预测文本中实体所包含的副词或形容词标签时,与之对应的图片特征并不能提供语义表示的增强,反而会引入噪声。因此,应用门机制中的过滤门,采用Sigmoid 函数对融合后的多模态中间表示特征进行噪声过滤,获得高质量多模态中间特征表示gt。尽管融合后的多模态中间特征能够在一定程度上完成对文本和图片语义的联合表达,但是命名实体识别的核心语义依旧在于文本。因此,通过将BiLSTM 编码后序列特征与多模态中间表示特征相拼接,获得最终多模态表示特征ut,具体过程为

其中,gt,ut∈Rd;θg为门机制中的全部参数。将编码的多模态特征ut表示输入CRF 层中进行标签解码,并利用最大似然估计对CRF 层进行训练,获得解码标签。
3.4 深度迁移学习
为了缓解当前可利用标注语料匮乏的现状,本文提出利用深度迁移学习方法探索解决这一问题,并设计了基于深度迁移学习的MNERM 模型。利用预训练完成的BAC 模型和ACAC 模型,将相应的权重分别迁移至BAM 模块和ACAM 模块中,使得MNERM 模型具备对目标域(地方志多模态数据集)抽取文本和多模态特征的能力。
给定用于进行实体识别的地方志文本图片对(C,P),C经过加载权重后的BAM 模块得到的编码输 出 为C'={ci|ci∈ Rd,i= 1,2,…,n},(C,P) 经 过 加载权重后的ACAM 模块得到的多模态特征表示K={ki|ki∈Rd,i= 1,2,…,n}。尽管利用迁移学习后的多模态特征能够在一定程度上增强文本语义信息,但是其仍包含一定的噪声,并且模型学习的语料并不是原始中文语料,而是英译汉平行语料,经过翻译后会部分丢失原意,引入噪声。因此,本文提出应用过滤门对提取的多模态特征进行噪声过滤,得到过滤后的多模态特征V={vi|vi∈Rd,i= 1,2,…,n},之后将文本语义特征表示C'与多模态特征表示V进行融合输入至一层全连接层中进行非线性激活,获得最终的多模态特征表示Z={zi|zi∈R2d,i=1,2,…,n},具体过程为

其中,Wk和Wz为权重矩阵;bk和bz为偏置项;tanh 为非线性激活函数。本文将多模态特征Z输入CRF 层中,微调后获得最终的预测标签。
4 实证研究
4.1 实验数据集
1)人民日报语料库
本文使用的是1998 年1 月的人民日报语料库,该语料库由北京大学计算语言学研究所和富士通公司联合制作并发布,被广泛应用在命名实体识别研究中。语料库中包含人名、地名及机构名实体,本文以行对语料进行切分,共获得19484 条句子,将语料库的80%作为训练集,剩余的20%作为测试集。
2)中文推特多模态数据集
本文使用的是Zhang 等[8]用于多模态命名实体任务的英文推特数据集。该数据集共包含8257 个句子和图片对,标注实体类别为人名、地名、机构名及其他实体,利用BIO(begin,inside,outside)规则[24]进行实体标注。该数据集经双人标注完成,包含的实体数量为12784,训练集句子数量为4000,验证集数量为1000,测试集数量为3257。为了制作平行语料,本文首先利用科大讯飞翻译API(appli‐cation programming interface) 对数据集进行翻译,并召集5 位研究生对平行语料进行检查,使其通顺并保持原意;然后利用jieba 包对语料进行分词,并使用相同标注规则对照原英文语料进行实体标注;最后得到中文推特多模态数据集。在英文推特中,语料中常包含缩写词及非中文对应实体词,同时考虑到迁移应用的语料,本文在中文平行数据集中去除了其他实体类别。该平行数据集中的训练集、验证集及测试集数量均与原数据集保持一致,在实体对照的标注过程中,当中文出现了英文中未标注的实体,本文则加以补充,最后得到的实体数量为10636。
3)地方志多模态数据集
利用本课题组编写的爬虫对《南京简志》①江苏古籍出版社,1986年出版。《南京人物志》②学林出版社,2001年出版。《南京园林志》③方志出版社,1997年出版。《南京城墙志》④凤凰出版社,2008年出版。、百度中的南京地方志等资源进行爬取,获取志书中的图片及相应文本描述,文本均为现代文。搜集到的文本及图片对数量为2885,经过过滤及去重,共获得1659 个文本图片对。之后对数据进行实体标注,标注由组内的两位研究生完成,标注规则为BIO[24],标注实体类别分别为人名、地名及机构名,实体总量为2908。标注后的地方志多模态数据集作为检验本文提出的MNERM 模型的性能测试语料。本文同时标注了500 个用于微调的文本图片对。
4.2 实验设置
本文所用编程语言为Python 3.6,使用的深度学习框架为tensorflow2.3.0,本文的实验均在两块GPU型号为NVIDIA GeForce RTX 2080ti、内存为16G 的服务器中完成。
4.3 基线模型
基于深度迁移学习的MNERM 模型主要由BAM模块、ACAM 模块、过滤门及CRF 层构成,组成模块的性能影响着整体模型的表现。因此,本文按照使用的数据集,分别是人民日报语料库和中文推特数据集,将组成模块对应的模型(BAC 和ACAC)与不同的基线模型进行对比,以验证其性能。最后,本文将MNERM 模型在地方志多模态数据集进行性能验证,并与基线模型作对比。
1)人民日报语料库
本文选择了几种具有优异性能的文本实体识别模型,将其与BAC 模型作对比,具体如下。
BiLSTM-Att[25]:该模型使用的注意力机制同BAC 模型相同,解码层使用Softmax 函数作为标签解码层。
BiLSTM-CRF[26]:该模型结合了BiLSTM 模型和CRF 模型,具有良好的实体识别效果,并被广泛应用在命名实体识别任务中。
BiLSTM[27]:相较于BiLSTM-CRF 模型,该模型利用Softmax 函数作为序列解码层,具有一定的实体识别性能。
CRF[28]:该模型为命名实体识别任务中的经典模型,能够较好地考虑到序列特征并避免标签偏置问题。
1.1 研究对象 本研究以上海市某地区失去独生子女的父母作为研究对象。纳入标准:(1)没有领养意愿及行为,已经丧失再生育能力的夫妇;(2)年龄≥50 岁;(3)失去独生子女 1年以上;(4)能独立完成问卷调查。排除认知障碍及患有重大精神疾病者。
2)中文推特多模态数据集
ACAM 模块主要由WGA、IGA 和门机制组成,为验证组成部分的优越性,本文对基于ACAM 的ACAC 模型进行了消融实验,分别去除了WGA、IGA 和门机制,形成Without-WGA、Without-IGA 和Without-Gate 等模型。同时,为了验证多模态融合的性能,本文将其与仅基于文本的BiLSTM-CRF 作对比,具体如下。
Without-WGA:该模型去除了词引导的注意力机制,仅保留了图引导的注意力机制。
Without-IGA:该模型去除了图引导的注意力机制,仅保留了词引导的注意力机制。
Without-Gate:该模型在自适应联合注意力网络中去除了门机制。
BiLSTM-CRF[27]:该模型对文本序列进行命名实体识别,参数与ACAC 保持一致。
3)地方志多模态测试数据集
为了验证MNERM 模型的性能,本文将仅在人民日报语料库和中文推特数据集中进行预训练的BAC 和ACAC 作为对比模型,微调方式均保持一致。同时,为了验证过滤门的性能,本文设计了去除过滤门的模型Without-FGate 作为对比。本文还将哈尔滨工业大学提供的Language Technology Plat‐form(LTP)[29]中的命名实体工具作为对比模型。
4.4 实验结果及分析
1)人民日报语料库
表1 呈现的是BAC 模型与其他模型的对比结果。从表1 可以看出,本文提出的模型在各个指标中均表现最优。在同BiLSTM-CRF 的比较中可以发现,当模型的解码层均保持相同时,引入自注意力机制能够使模型更为关注那些能够决定序列标签的信息,生成富含语义特征的序列特征,从而提升模型识别实体的性能,这也是BAC 模型具有一定优势的原因。在同BiLSTM-Att 的对比中,当模型的编码层保持一致时,利用Softmax 层作为识别实体的解码层,尽管能够取得一定的性能,但依旧劣于BAC 模型。相较于Softmax 层,CRF 能够对隐藏层的各个时间步进行有效建模,学习并观察序列中的标签特点,从而提升模型的解码性能。这样的优势同样体现在BiLSTM 和BiLSTM-CRF 的对比中。当忽略文本的上下文关系,仅用词向量对文本进行表示时,将其输入CRF 层进行解码,从结果可以发现,CRF 模型均劣于使用BiLSTM 或结合自注意力机制的模型作为上下文建模的模型,这充分说明了文本上下文在命名实体识别任务中的重要作用,同时也表明利用BiLSTM 等时间序列模型能够较好地学习文本上下文关系,并能生成富含上下文关系及语义信息的序列特征。

表1 模型在人民日报语料库中的测试结果
通过比较分析发现,本文引入的BAC 模型具有较好的实体识别性能,而模型包含的BiLSTM 和自注意力网络在其中发挥了充分抽取语义特征的重要作用,这也是本文将BiLSTM 和自注意力网络(BAM 模块)作为MNERM 模型组成部分的原因。
2)中文推特数据集
自适应联合注意力机制由图引导的注意力机制、词引导的注意力机制及门机制组成。每个组成部分均能对ACAC 模型性能产生影响,为了探究不同组成成分的作用及整体组合的性能,本文对此进行了探究。
表2 呈现的是各对比模型在中文推特多模态数据集中的结果,可以看出,ACAC 模型在F1 这一指标上表现最优。当去除图引导的注意力机制后,Without-IGA 模型在精确率(P) 这一指标上优于ACAC 模型,但是在召回率(R)和F1 指标上均劣于ACAC。尽管ACAC 模型在预测序列正标签样本中并没有表现出最优性能,但是在序列中的各实体类别真实标签样本识别中效果最佳,并在召回率这一指标上超出With-IGA 模型近7%。当去除词引导的注意力机制后,仅利用图引导的注意力机制并不能较好地学习到文本和图片之间的模态交互和关联关系,这也是Without-WGA 劣于ACAC 的原因。在同Without-FGate 模型的对比中,可以发现门机制在模型中的重要作用,引入门机制能够较好地聚合多模态融合特征,同时有效过滤来自模态融合中的噪声。当不考虑文本对应的图片时,通过对比BiLSTMCRF,可以发现图片信息在增强文本语义特征中的作用,这也是ACAC 模型表现良好的原因。因此,本文将去除了CRF 层的ACAC 模型作为MNERM 模型中的ACAM 模块,用于提取地方志数据中的多模态特征。

表2 模型在中文推特数据集的测试结果
3)地方志多模态数据集
表3 呈现的是经过微调后的不同对比模型对地方志多模态数据集进行实体识别的结果,各模型所用的微调数据均一致。利用通用模型LTP 对地方志语料进行实体识别并没有取得较好的效果。与BAC模型比较可以发现,当MNERM 模型联合多模态语料库知识后,模型性能有了较大提升。这表明在多模态语料库中预训练实体识别模型后,利用基于神经网络的深度迁移学习方法,将权重灌入MNERM模型对应模块中,能够使得MNERM 具备捕捉不同模态间的语义相关关系及动态交互的能力,从而获得更优的性能。在与ACAC 的比较中可以发现,尽管利用在中文推特多模态语料库中的预训练模型ACAC 能够取得一定优势,但是劣于含有人民日报语料库知识的BAC 模型以及MNERM 模型。一方面是因为在制作平行语料的过程中,会伴随着部分英文原意信息的丢失;另一方面是因为源域英文推特数据集大多由推特平台上用户的发帖组成,内容大多关于用户生活的分享,而目标域则是地方志多模态内容,目标域与源域之间存在着部分不相关的知识。当本文引入过滤门后可以看出,采用过滤门的MNERM 模型在精确率和F1 指标上均优于Without-FGate 模型。尽管应用过滤门机制使得召回率轻微下降,但是F1 值提升了1.042%。这表明,应用过滤门能够对深度迁移学习得到的多模态融合特征噪声进行有效过滤,同时能够弥补因源域和目标域之间存在不匹配知识所造成的性能损失。

表3 地方志多模态数据集深度迁移学习结果
4)深度迁移学习有效性分析
为了探究深度迁移学习在地方志多模态命名实体任务中的有效性以及模型对目标领域的适配性,本文通过调节预训练模型中训练集大小进行验证[6]。图3 展示的是当人民日报语料库训练集大小成比例增加时,BAC 模型在人民语料库中的测试性能及在地方志多模态数据集中的文本进行深度迁移学习的结果。从图3 可以看出,随着预训练模型中训练集数量的增加,经过微调后的权重迁移模型对地方志文本进行实体识别的性能呈上升趋势。该趋势同样呈现在ACAC 模型对地方志多模态数据的实体识别中。
从图4 可以看出,当人民日报语料库及中文推特多模态数据集中的训练集同步成比例上升时,应用深度迁移学习的MNERM 模型在对地方志多模态数据集中的实体进行预测时,性能总体呈上升趋势。综合图3、图4 中的结果可以发现,预训练模型中训练集的大小影响着后续应用深度迁移学习的效果,这表明本文提出的深度迁移方法具有一定的有效性,并且显示出本文提出的MNERM 模型对目标领域具有较强的适配性。

图3 训练集比例对BAC模型和ACAC模型性能及应用深度迁移学习的影响

图4 预训练模型中的训练集比例对MNERM模型性能的影响
4.5 误差分析
表4 呈现的是利用不同模型对地方志多模态数据集中的部分数据进行预测的结果。在例1 中,MNERM 模型和ACAC 模型均对地名实体做出了准确的预测,而BAC 模型则做出了错误判断。例1 图片中的大楼为文本的地名实体提供了语义增强作用,通过多模态融合则可以产生更富含语义的表示,从而提升实体识别的性能。在多模态命名实体中,文本的语义信息依旧是实体识别的核心信息。在例2 中,尽管利用ACAC 模型未能对人名实体进行有效识别,但仅依靠文本语义信息,BAC 模型做出了准确判断,而作为ACAC 模型和BAC 模型两者的结合,依靠捕捉文本语义信息的BAM 模块,MNERM 模型同样预测成功。在例3 中,MNERM模型和BAC 模型均对人名和组织实体做出了准确判断,而ACAC 模型仅识别出了人名实体,未能识别出组织实体。例3 图片中的人像为人名实体的识别提供了语义增强作用,但是在组织实体识别中,与文本相对应的图片未提供相应的补充特征,ACAC模型未能对组织实体进行识别。尽管MNERM 模型在利用深度迁移学习的多模态命名实体识别任务中能够取得一定效果,但其未能够有效利用文本中的字级特征,而联合字级的特征则可以增强文本的表示能力,能够进一步改善多模态特征融合后的语义表示特征,从而提升迁移学习后实体识别的性能。

表4 不同模型对地方志多模态数据进行实体识别的结果
5 总结与展望
当前,面向地方志等文化资源的命名实体识别研究主要基于文本,忽略了文本对应的图片信息,同时还面临着在领域内训练实体识别模型缺乏已标注数据集的困境。为了解决该问题,本文从多模态视角出发,结合地方志对应的图片信息,并提出基于深度迁移学习的MNERM 模型。该模型由四个部分组成,分别是BAM 模块、ACAM 模块、过滤门及CRF 层。为了验证模型组成部分的有效性,本文将包含对应模块的模型(BAC 和ACAC)与不同基线模型进行对比,实验结果表明,模型各组成部分均包含一定的优势。利用经过权重迁移后的BAM模块和ACAM 模块,MNERM 模型能够有效获取文本语义特征及多模态特征,应用过滤门对ACAM 模块输出的多模态特征进行去噪,最后将BAM 模块输出的文本语义特征及过滤后的多模态特征进行融合,输入至CRF 层进行解码。实验结果表明,本文提出的模型在同基线模型的比对中具有一定优势。同时,为了验证深度迁移学习的有效性和对目标领域的适配性,本文将预训练模型中的训练集比例作为参数进行调节,发现当源域训练集越大,经过深度迁移学习后的模型表现越佳。
本文提出的模型和方法不仅适用于地方志多模态命名实体识别,也适用于数字人文领域中标注数据集匮乏的文化资源,如非遗等。在未来的研究中,本课题组将进一步提升模型的领域泛化能力,提升模型利用深度迁移学习进行多模态实体识别的性能以及中文多模态命名实体识别数据集的构建。
