学科交叉视角下的学科区分能力测度方法及分析研究
2022-05-19张宝隆
张宝隆 ,王 昊 ,张 卫
(1. 南京大学信息管理学院,南京 210023;2. 江苏省数据工程与知识服务重点实验室,南京 210023;3. 郑州航空工业管理学院信息管理学院,郑州 450046)
1 引 言
随着学科间交流联系的日益紧密,学科交叉融合已经成为促进学科发展创新的重要因素之一,关于学科交叉的研究已成为学科研究的重要发展趋势[1]。但学科之间的交流融合正逐渐模糊学科边界,学科自身的研究特色也随之被弱化。而以新工科、新文科等为主要内容的新学科建设要求各门学科要在发展中寻求自身特色,形成既独立发展又融合新生的新学科[2]。因此,各个学科能否在融合发展的趋势中保留学科特色,凸显出学科个体的独特性和差异性特征是需要密切关注的问题,这对于学科持续健康发展至关重要。
当前,学科交叉研究是学科研究的主要方向之一,多采用引文的多样性、作者合著、机构合作等来对学科的交叉程度进行测度和分析[3]。该方面研究主要聚焦于学科之间的交叉融合特征,对学科之个体的独特性或差异性则较少关注;所采用的研究数据多是引文数据,只有较少研究采用研究内容对学科进行直接测度。区分能力最初用于索引术语质量的评价,通过度量术语个体在群体中的区分性来判定其质量[4-6]。张宝隆等[7]将其算法进行改进,并应用于学术期刊的同质性测度以探讨学术期刊个体的异质性特征,研究结果表明,该方法能够很好地探测期刊对象的差异性特征。因此,在已有研究的基础上,本文提出学科区分能力(discipline discrim‐inative capacity,DDC)指标,并将其定义为:学科个体与给定学科群体中其他所有学科在内容层面的总体差异程度,即学科个体区别于其他学科总体的能力。区分能力越强,说明该学科的独特性越强,反之则说明该学科与群体中的其他学科的交叉越密切。利用该指标可以从研究内容层面对学科在群体中的差异程度进行测度,进而可以从一个新的视角——区分性,来对学科的独特性和交叉性特征进行定量分析,从而为探索学科个体的独特性、把握学科交叉融合的发展动向提供一种新的方法和思路。
本文旨在利用学科的研究内容对其区分能力进行测度和分析,探讨学科交叉融合发展中学科个体的差异性特征及其一般规律。为此,本文以中国人文社会学科为例,采用2019 年各个学科的论文题录作为研究数据,对学科的区分能力进行测度和分析,并分别采用基于PCA(principal component analy‐sis)和基于ADV (angle-distance based visualization)方法对学科空间可视化,以辅助分析学科的差异性。同时,采用常用的学科交叉测度指标如布里渊指数、Rao-Stirling 指数等作为参照,对比分析DDC 与学科交叉指标之间的相关性。在此基础上,利用学科互引网络对学科区分能力进行分析,以验证学科交叉与其区分能力之间的关系,探查学科交叉的强度、广度对于学科区分能力的影响,从而为学科的健康有序发展、研究方向的妥善调整提供参考和借鉴。
2 相关研究概述
目前,国内外对于学科对象的研究主要集中在学科交叉领域,其中大部分研究聚焦于利用基于学科间的引文关系和基于学科间的引文内容[8]来进行学科交叉测度和探讨。
基于引文关系的学科交叉测度是国内外学者较常采用的方法[1]。利用学科之间的引文关系能够有效反映学科间的交叉融合,由此学界涌现出了大量的基于引文的学科交叉测度指标,其中引用学科多样性指标研究最为广泛[9-10]。最早有学者将信息熵[11]用于学科交叉测度,但该指标仅考虑了引用学科的均衡性。随后,Brillouin[12]在信息熵的基础上提出了布里渊指数来对学科多样性进行测度,该指标综合反映了引用学科的丰富性和均匀性,但没有考虑引用学科之间的异质性。而后,Stirling 指出多样性测度应综合考虑引用学科的丰富性、均衡性和异质性3 个属性特征[13],并提出一般性计量公式[14],与Rao[15]所提出的公式共称之为Rao-Stirling 指标。该指标综合考虑了上述3 个属性特征,成为学科交叉测度的一项重要指标,对推进学科交叉测度具有重要作用。但同时也有研究提出该指标的区分性并不高[16]。在该指标的基础上,有许多学者对其进行了泛化和改进[17-19],其中Zhang 等[20]所提出的改进型2DS指数得到了广泛认可和应用[21]。也有学者将Gini 系数[22-23]用于学科交叉测度[24],但该指标侧重于引用学科的均衡性而不是丰富性[25]。Leydesdorff 等[26-27]将Gini 系数作为均衡性属性提出了DIV(diversity)指标,其中的上述3 个属性均能够独立计算,具有一定的优势和应用潜力。此外,还有很多学者从引文角度对学科交叉测度指标进行了探索[28-30],这些指标也各有优劣。总的来看,在基于引文的学科交叉测度研究方面已经取得了丰硕的成果,但这些指标仅能依据引文特征来刻画学科交叉性,无法有效揭示学科自身的独特性或差异性特征。
基于内容的学科交叉研究逐渐受到国内外学者的关注。章成志等[31]和徐庶睿等[32-34]结合引用术语和引文内容,通过计算引文内容中引用术语的频次和重复率实现了学科交叉测度。但该方法仅能对两两学科间的交叉程度进行度量,无法实现学科个体与总体的交叉测度,难以全面反映学科交叉性特征。陈红丽等[35]在其研究基础上,用标题术语表征学科内容,通过计算两两学科间重叠词序列在术语集中的词频分布相似程度来对两学科间的交叉程度进行测度。马瑞敏等[36]利用Jaccard 相似度分别对学科间的文献直引、文献耦合和共关键词的相似度进行了计算,并在此基础上对这三者进行加权平均实现学科交叉的直接测度。该研究融合了引文和内容,但仍局限于两两学科之间。曹嘉君等[37]采用关键词描述学科研究内容,通过共现分析和相似度计算对人工智能领域与其他学科的交叉特征进行分析探讨。总的来看,基于内容的学科交叉研究成果不够丰富,仍有继续探索的空间,并且已有的这些研究多采用标题词、关键词、引用术语等,不能全面表征学科内容。
此外,有学者利用作者合著来对学科交叉进行测度和分析[38-40],但这类研究从合作角度来探讨学科交叉是一种更为间接的方式,并且不同领域学者的合作是否能产生知识交叉融合也值得商榷。
综上所述,当前对于学科对象的研究在学科交叉方面成果非常丰富,但总体来看绝大多数研究均是对学科交叉性特征的探索,很少有研究涉及学科自身的独特性或差异性特征。当然,学科多样性指标中也有将学科差异性(或异质性)考虑在内,但这仅是反映引用学科在引文方面的差异,并不能有效测度学科自身的差异性特征。同时,多数研究都是采用引文数据进行测度,利用研究内容来探测学科交叉性的研究略显不足。实际上,论文自身的研究内容能够很好地体现学科涵盖的内容,利用其进行学科交叉测度会更有优势。因此,本研究提出学科区分能力指标,利用学科论文的标题、关键词、摘要表征研究内容来对不同学科在内容方面的差异性进行测度,借此探讨学科独特性和交叉性特征,以弥补当前研究在此方面的不足。
3 数据和方法
3.1 数据来源和预处理
1)学科数据源确定
学科是本文的主要研究对象,因此采用何种标准来确定学科对象是本研究的关键。《中华人民共和国国家标准学科分类与代码》(GB/T 13745-2009)[41]和中文社会科学引文索引(Chinese Social Sciences Citation Index,CSSCI) 中均对中文社会学科进行了规范划分,因此,本研究结合两者确定23 个人文社会科学一级学科作为研究对象。为了从内容视角对学科对象进行测度,本研究将各个学科的CSSCI期刊发表的研究论文作为数据源。学科类目及其期刊数量如表1 所示。

表1 学科类目及期刊数量
2)数据预处理
CSSCI 和中国知网(China National Knowledge Infrastructure,CNKI)是中文领域规范且常用的学术资源数据库,两者均提供规范的论文题录数据下载。但CSSCI 数据库所提供的题录中摘要字段缺失,CNKI 数据库提供的题录中参考文献数据不完整。而标题、摘要、关键词、参考文献等关键字段是本研究所需的核心数据,因此需要分别从两个数据库中获取题录数据,然后将标题和关键词作为匹配项对题录数据进行合并,最终构建本研究所需的基础数据集。
针对基础数据集的预处理主要包括:①数据清洗。原始题录中摘要、关键词等字段空缺的不完整数据,将其视作无效数据进行剔除。②数据抽样。由于每个学科的题录数据量较大且存在较大差异,为了节省算力和计算过程的简便性,采用随机抽样方法对有效数据进行抽样。③文本处理。首先提取题录数据中的标题、摘要、关键词字段,采用pynl‐pir 包进行分词,并根据词性对分词结果进行停用词过滤,将获得的字或者词视作术语。④参考文献处理。由于参考文献涉及较多外文、图书等非中文学术论文,需要进行剔除,从而为后续实验分析做准备。
3.2 学科区分能力测度方法
DDC 算法的核心思想是通过剔除所构建的学科空间中某一学科后的空间密度(discipline space den‐sity,DSD)的变化来衡量该学科的区分能力,其中空间密度由空间中所有学科个体与空间中心的平均相似度来表示。某个学科被剔除后,如果新形成的空间密度增大,即说明该学科与其他学科相似度较小,具有显著区分性;反之,如果空间密度减小,则说明该学科与其他学科相似度较大,学科之间存在一定的交叉。因此,基于该算法可以有效测度学科个体与群体的差异程度,进而度量其区分能力。
根据DDC 算法思想,需要先采用基于TF-IDF的文本表示方法对学科对象进行向量表示,从而构建学科-术语矩阵(discipline-term matrix,DTM),并在此基础上,采用Cosine 相似度把DTM 转换为相似矩阵(discipline-discipline matrix,DDM),将其作为学科空间,即

其中,Si表示学科相似向量;sij表示学科i与学科j的Cosine 相似度;m为学科数量。
进而,DSD 可由学科向量Si与空间中心的平均相似度来表示,即

其中,DS(Si)表示学科向量Si与空间中心的相似度,采用基于距离的相似度来计算,即

其中,Centroid 表示空间中心,由所有学科向量Si的均值计算所得;Dist 表示学科向量Si与Centroid之间的距离,采用欧几里得距离进行计算,公式为

最终,DDC 可由剔除某一学科后DSD 的变化计算得出,即

其中,DSDSk为剔除学科Sk后新形成的学科空间密度;AVG_DSD 表示所有空间密度变化差值的平均值,计算公式为

根据DDC 算法,学科区分能力具有以下属性:
(1) DDCSk>0,说明学科k具有较好的区分能力,呈现出一定的独特性特征;
(2)DDCSk=0,说明学科k没有区分能力;
(3)DDCSk<0,说明学科k没有区分能力,呈现出一定的交叉性特征。
3.3 基于角度和距离的空间可视化方法
基于术语特征所构建的学科对象空间均为维度大于3 的不可视环境,这阻碍了学术对象空间分布特征及其规律的分析和探讨。传统的做法主要是采用MDS(multi-dimensional scaling)、PCA、t-SNE(tdistributed stochastic neighbor embedding)等方法将高维空间降至2 或3 维来实现空间的可视化分析,但其不足之处在于降维操作带来的信息损失会导致相对位置的失真,不利于精确刻画学术对象之间的差异。Zhang 等[42-44]提出了一种基于角度和距离的信息检索可视化方法,本研究沿用其思想提出一种新的用于描述多维空间中学术对象相对位置的可视化方法——基于角度和距离的空间可视化方法(ADV)。
ADV 方法的思想是以中心对象为原点,同时采用距离和角度两个参数来描述对象之间的相对位置,进而实现多维空间到2 维平面的映射。距离是指空间中两点间的直线距离,角度用夹角余弦表示。因此,ADV 方法的具体实现过程为:基于所构建的学术对象空间DS,将其空间中心Centroid 作为坐标原点,分别将学术对象Si与空间中心Cen‐troid 的余弦距离和欧几里得距离作为横纵坐标轴,如图1 所示。学术对象距离原点越远,表明其区分能力越强;与群体的距离越大,说明其与其他个体之间的差异程度越大。

图1 基于角度(angle)和距离(distance)的可视化示意图
本研究所提出的区分能力是从差异角度来描述学科对象的总体特征和个体差别的,利用该可视化方法可以有效地从差异性视角观测学科对象在空间中的相对位置,从而实现学术对象间的相似关系分布在二维平面上的可视化展示。同时,该种方法既不同于SNA(social network analysis)中以连线表示关系的关联分析(角度不同),也不同于MDS 的仅以距离表示相似的降维拟合分析(失真程度不同),为学科对象的差异(相似)可视化分析提供了一种新的方法和思路。
3.4 学科交叉测度方法
目前国内外学者多采用学科多样性指标来进行学科交叉测度,常用的指标有布里渊(Brillouin)指数[12,45]、 Rao-Stiling 指 数[13-15]、2DS指 数[20]、 Gini 系数[22-24]。其中,布里渊指数侧重于引用学科的丰富性,Rao-Stiling 和2DS均综合考虑了引用学科丰富性(variety,number of disciplines)、均匀性 (balance,evenness of distribution) 和差异性 (disparity,degree of difference),但2DS指数提高了丰富性的权重[46],Gini 系数则侧重于引用学科强度的均匀性。这几个指标均已得到学界的广泛认可和使用,因此,本研究将其作为参照指标,与学科区分能力指标进行对比分析。各个指标的计算方法如表2 所示。

表2 学科交叉测度指标及其说明
4 实验结果与分析
4.1 数据处理结果及分析
本研究分别从CNKI 和CSSCI 数据库中获取23个学科所有期刊的题录数据并进行匹配,构建完整的数据集合,然后按照预处理方法对数据集合进行清洗、分词等操作,最终形成实验所需的基础数据集以进行后续实验分析。
4.1.1 数据预处理结果
数据清洗之后,每个学科所收录的有效题录数据量差别较大,最少的是宗教学,仅有490 条有效数据。因此,采用随机抽样方式从每个学科中抽取400 条作为实验数据,然后提取其中的标题、关键词、摘要,进行分词、去停用词等处理。数据预处理结果如表3 所示。
通过表3 可以发现,不同学科的有效数据量及其术语量均存在较大差距,这主要是由每个学科所收录的期刊数量和载文量决定的;并且,通过随机抽样所获取的样本术语量也存在较大差异,最小的是统计学,有3705 个术语,最大的是历史学,有7718 个术语,是统计学的2 倍之多。因此,需要首先进行分析探讨的是,数据规模差异是否会对DDC产生影响。

表3 23个学科数据预处理结果
4.1.2 随机抽样及数据集对DDC的影响分析
为了验证随机抽样方式在本实验中的合理性,分别采用随机样本量和全样本量进行DDC 测度,并对两者结果进行相关性分析,从而判定随机抽样对DDC 结果的影响。由于不同抽样规模也可能会对结果造成影响,故分别以50 和400 为最小和最大抽样规模,以50 为步长进行递增。同时,按照最大抽样规模进行5 次随机抽样,以分析随机抽样结果的稳定性。
1)基于随机样本和全样本的DDC 结果相关性分析
根据抽样规模对每个学科的有效数据进行随机抽样,经过数据处理后计算每个学科的DDC 值,然后采用SPSS 软件对基于抽样和全样本的DDC 结果进行皮尔逊相关性分析,将所有的相关性系数绘制成折线图。如图2 所示,随着抽样规模的逐渐增大,两者之间的相关性也随之增大,当样本量达到250 以后,相关性系数稳定在0.95(P<0.01)以上。由此可以说明,采用随机抽样方式会对DDC 结果产生一定的影响,但当抽样数据量达到一定规模后,这种影响会降至很低,几乎可以忽略不计。因此,本研究根据最小有效数据量,确定以400 作为抽样规模具备科学性和合理性,这也充分说明基于随机抽样的结果具有很好的代表性和很强的稳定性。

图2 基于不同样本量的DDC与全样本DDC的相关性系数
2)数据集与DDC 的相关性分析
为了进一步分析实验数据特征是否会对DDC 结果产生影响,对每个学科的有效数据量、全样本术语量、随机样本术语量以及基于随机样本的DDC_s400 值进行了相关性分析,两两之间的皮尔逊相关系数如表4 所示。

表4 数据集与DDC结果的相关性分析
从表4 可以看到,有效数据量和全样本术语量、全样本术语量和随机样本术语量两两之间均具有一定的相关性,但相关程度不高,这表明不同学科有效数据的差距并没有对其术语量产生较大影响,并且对抽样数据术语量的影响也比较微弱。同时,有效数据量、全样本术语量以及随机样本术语量均没有对DDC_s400 产生显著影响,这表明DDC 算法对数据集特征不敏感,表现出较好的鲁棒性。因此,本研究采用随机样本来对各个学科进行区分能力测度和分析是可行且科学合理的,这有助于提升计算效率。
4.2 人文社会学科区分能力分析
4.2.1 DDC结果分析
通过上述分析,基于随机抽样的DDC 结果可以很好地替代全样本数据,因此,采用4.1.1 节中的随机样本数据对23 个学科DDC 进行计算,结果降序排列如图3 所示。
观察图3 发现,23 个学科的区分能力具有显著差异且呈现出明显分层。从整体上看,绝大部分学科的DDC 都为正值且部分学科处于较高水平,表明在人文社会科学领域多数学科都具有较好的区分性,学科之间的知识流动和交融并没有掩盖其学科差异特征。

图3 人文社会学科的DDC结果
(1)DDC 处在第①层次的学科为经济学、统计学和管理学。它们之间的差异明显且与其他学科的DDC 也存在显著差距,说明这3 个经管类学科的研究内容特色鲜明,在人文社科领域具有显著的差异性,可能与其他学科之间的知识交叉程度很低。
(2)2 个人文地理环境类(自然资源与环境、人文经济地理)和两个文学类(中国文学、外国文学)学科处于第②层次。前者由于其学科特性与其他学科差异显著,区分性明显;而中国文学和外国文学也同样具有较高的区分度,说明这两个学科独特性较强,与其他人文类学科存在较大差异,学科之间的交叉融合程度可能较低。
(3)接近半数的学科都集中在第③层次。这些学科的DDC 整体处于中低水平,并且学科之间的差异不大,说明这些学科的研究内容具有较好的区分性,但同时与其他学科之间存在一定程度的交叉融合,没有呈现出鲜明的学科特色。如考古学、体育学、宗教学等学科虽较为独特,但在学科群体中并没有呈现出较高的区分性,表明这些学科可能与其他学科知识出现了不同程度的交叉融合。
(4) 处于第④层次的主要是社会类学科,其DDC 多为负值。其中历史学和教育学的DDC 接近于0,其区分性特征与负值无异,因此将其划分至第④层次。这类学科在群体中的区分度为负值,说明它们的研究内容与其他学科存在很大程度上的互动,在知识层面的交叉融合程度较深,从而掩盖了自身学科特色。尤其是民族学与文化学,其DDC在所有学科中最低,说明其研究内容可能与其他学科存在广泛交叉,且学科知识融合程度较深,因此没有呈现出差异性。
总的来说,人文社会科学领域的学科之间的差异性非常显著。经管类学科的区分能力处于最高层次,其学科差异性特征明显,研究特色显著;人文类学科的区分能力总体上处于中等层次,表现出了较好的学科独特性;而部分社会类学科没有表现出区分性,其学科交叉融合的特征较为显著。此外,通过分析可以发现,区分能力越高的学科,与其他学科知识的交叉融合程度可能就越低;而区分度较低的学科,其学科间知识交融的范围可能更为广泛,程度更深。
4.2.2 学科差异性可视化分析
本研究分别采用基于PCA 和基于ADV 方法来对学科空间分布进行可视化分析,并对比两种方法的优劣性,从而可以通过观测学科对象的相对位置、聚集离散程度等分布状况来直观判断学科个体的差异性特征。
1)基于PCA 的可视化分析
PCA 是较为常用的降维方法,利用该方法对学科空间进行降维,可以通过观察学科分布的亲疏关系来对学科差异性特征进行辅助分析,结果如图4所示。

图4 基于PCA的学科空间的二维可视化
从图4 可以看出,23 个学科大致分布在3 个区域,不同学科群体之间的界限明显,学科个体分布的离散程度也基本和其DDC 相对应。
(1)不同学科群体的聚集程度与其DDC 呈现负相关,群体聚集程度越高,其DDC 相对越小。①经管类和人文地理环境类学科分布在第一象限,学科之间分布较为离散,且整体距离空间中心较远,其DDC 在学科群体中均处于较高水平。②分布在第二象限的主要为人文类学科,学科群体聚集程度和与空间中心的距离均次于第一象限的学科;这几个学科的DDC 多分布在中间层次。③第三象限的学科主要为社会类学科,这些学科分布较为密集,且整体上较为靠近学科空间中心,它们的DDC多处于较低水平。
(2)学科个体的分布位置与其DDC 基本对应,分布位置越靠近中心,区分能力就越小。①经济学、统计学等学科离散分布在学科群体的边缘(虚线圆外),与空间中心以及其他学科之间的距离均较大,而它们的DDC 在学科群体也是最大的。②分布在圆环部分的学科个体与学科空间中心距离较远,它们的DDC 也基本处于中间层次。③处于圆心区域的几个学科(如政治学、民族学与文化学等)是距离空间中心最近的,其DDC 在整个学科群体中也是最小的。
因此,借助学科空间的二维分布可以通过观察学科群体及个体的聚集程度和分布位置来大致判断其区分性。学科群体的聚集程度越高,其DDC 就越小;学科个体分布距离空间中心越远,它们的DDC 就越大。但该方法的不足在于降维操作所带来的信息损失会导致相对位置的失真,并且从空间分布中也难以准确判断学科个体的区分能力。
2)基于ADV 的可视化分析
鉴于基于PCA 可视化分析的弊端,本文提出基于ADV 方法对学科空间进行可视化,分别计算学科向量与空间中心的余弦距离和欧几里得距离作为横纵坐标,结果如图5 所示。
从图5 可以看出,学科群体整体上离散分布在3 个区域,不同区域间层次分明,与其DDC 所处层次基本保持一致;并且,学科个体的分布位置与其DDC 也基本对应。第一,分布在区域①的经管类学科距离学科群体最远,且3 个学科之间也存在一定距离,这与其DDC 的数值分布高度一致。第二,文学类和人文地理环境类学科分布在区域②,其整体分布的区域位置反映了其DDC 所处的层次;同时,两类学科的相对位置也反映了学科间的亲疏关系。第三,大多数学科离散分布于区域③(即学科群体的核心区域),整体从右上至左下排列分布,其中③_1 区域是DDC 为正值的学科,③_2 区域是DDC 为负值(或接近于零)的学科。对比图2 中的DDC 排序,区域③的学科分布位置与DDC排序基本上保持一致,很好地呈现出了学科的区分性特征。
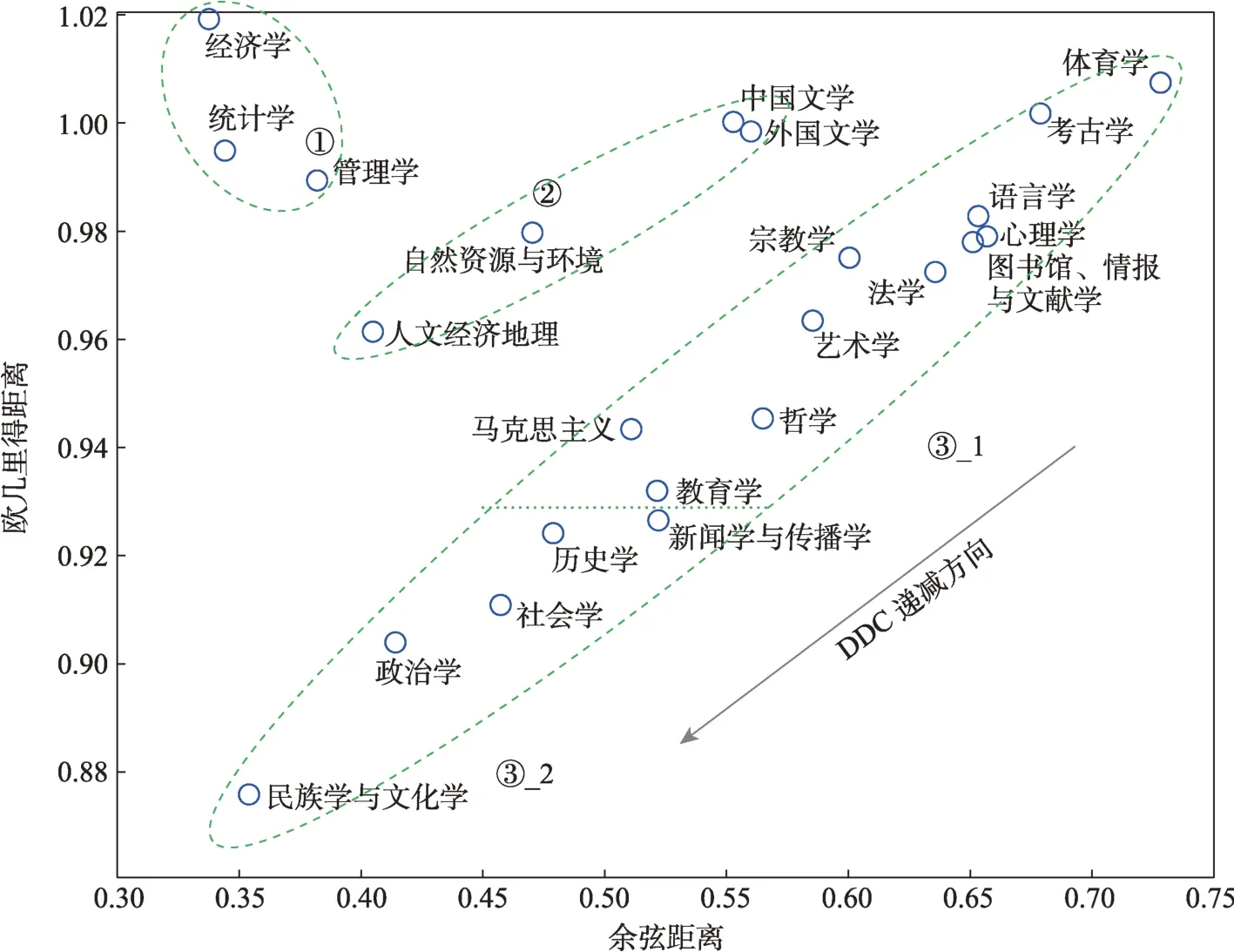
图5 基于角度和距离的学科空间可视化
通过分析发现,基于ADV 方法能够更加准确地刻画学科区分能力。距离学科群体越远的学科,其DDC 就会越大;在学科群体的核心区域中,学科个体的DDC 自右上至左下递减。由此,个体的分布规律可以泛化为距离群体越远其与群体的差异程度就越大,其DDC 也越大;距离原点(空间中心)越远,其DDC 越大,反之,则DDC 越小。此外,个体之间的相对距离也能够很好地呈现它们的差异性,距离越大,两者之间的差异就越明显。
4.3 DDC与学科交叉指标对比分析
上述分析表明基于抽样数据的DDC 与基于全文本的DDC 结果高度相关,但如果仅使用随机样本的引文数据进行学科交叉测度,则可能丢失较多的引证关系,进而导致学科交叉测度严重失真。因此,本研究采用学科中所有的有效参考文献进行测度和分析。
4.3.1 DDC与学科交叉测度结果对比分析
1)DDC 与学科交叉指标的对比分析
按照文献-期刊-学科的模式将每个学科中每篇论文的参考文献映射到各个学科,最终统计所有学科间的互引频次。基于此,按照3.4 节中的公式进行指标测算,结果如表5 所示。
由于不同指标的量纲不同,难以直接进行比较,因此,通过其排名来对不同指标进行对比分析。在表5 中,①从整体的数值分布来看,DDC 的数值区分性更强。DDC 的标准差最大,其数值分布最为离散;而B、Gini、RS 和2DS这4 个指数的标准差均在0.5 以下,数值分布较为集中,表明数值之间的差异较小,指标区分性不强。②从各指标的排名来看,DDC 与其他指标之间存在一定的相关性。B指数和Gini 系数大致呈现负相关;RS 和2DS指数表现为强正相关,这是其计算原理所导致的;DDC与B、RS、2DS指数存在一定程度的负相关,区分能力较大(较小)的几个学科其B、RS、2DS指数均处于较低(较高)水平;而多数学科的DDC 值与其Gini 系数呈现出一定的正相关性。③从学科个体来看,DDC 与其他指标具有明显的差异。对比B、Gini、RS 和2DS值可以发现,经济学和民族学与文化学在23 个学科中分别是交叉程度最小(较小)和最大(较大)的,这与其区分能力保持一致。而艺术学的RS 和2DS值是最大的,说明其具有较强的学科交叉性,但其DDC 处于中等水平,这两者不完全一致;同时,从RS 和2DS值来看,中国文学和外国文学的学科交叉性较强,但实际上其区分能力处在较高水平,这两者也不一致。由此可以说明,学科交叉指标虽然和区分能力指标存在一定的相关性,但两者并不能完全相互替代。

表5 DDC与学科交叉指标测度结果
2)DDC 与学科交叉指标的相关性分析
为了进一步探讨DDC 与其他学科交叉指标之间的相关性,本文采用SPSS 对其进行皮尔逊相关性分析,结果如表6 所示。
从表6 可以发现,DDC 与其他4 个指标之间均具有较强的相关关系。①DDC 与Gini 呈现出较强的正相关关系,说明学科间交叉的均匀性对其区分能力具有显著积极影响,不均匀性越强,学科的区分能力就越强。②DDC 与B、RS、2DS具有显著的负相关关系,说明引用学科丰富性、多样性对于其区分能力具有一定的消极影响,即学科间知识的交叉程度越深,其学科区分能力就越弱。

表6 DDC与学科交叉指标的相关系数
通过对比分析发现,DDC 与其他学科交叉指标具有显著不同。DDC 能够精确地刻画不同学科个体在群体中的区分程度,而其他学科交叉指标并不能完全反映其这一特征。但同时,学科交叉指标又与DDC 具有较为显著的相关性,说明学科间的知识交叉融合是形成学科区分性的一个重要因素,因此,通过学科区分能力可以大致判断不同学科的交叉程度,两者可以在一定程度上互补。此外,DDC 与学科交叉指标的相关关系也反映了学科交叉仅是形成学科区分性的因素之一,其他特征如学科创新性、影响力等也可能是其影响因素,这需要后续进一步探讨。
4.3.2 基于学科互引网络的学科区分能力分析
学科引文网络是利用学科之间的引证关系来探测学科知识流动的重要方式,通过知识流动的强度和广度可以有效分析学科间的交叉程度。因此,为了深入探讨学科区分能力与学科交叉之间的关系,本文采用23 个学科之间的互引网络来对其学科交叉性进行分析。先将上述实验中所统计的学科互引频次转换为学科互引矩阵(23×23 维),然后采用VOSviewer 软件对其进行可视化。为了使互引网络结构更加清晰,设置最小引证强度阈值为50,结果如图6 所示。图中节点直径越大,学科间的知识流动强度就越大;边越粗,引证强度就越大。

图6 人文社会学科互引网络
在图6 中,23 个学科被划分为四类。类别一为经济学、管理学、统计学等经管类学科,类别二为人文经济地理、自然资源与环境等人文地理环境类学科,类别三为社会学、法学、政治学等11 个社会类学科,类别四为民族学与文化学、历史学、考古学、宗教学、艺术学、中国文学、外国文学等人文类学科。对比这些学科的DDC 发现,DDC 的层次划分与该引文网络中学科划分高度相关,这进一步验证了学科间知识流动所造成的学科交叉是影响学科区分能力的重要因素。
为了进一步分析学科间知识交叉对学科区分能力的影响,分别以DDC 最小、最大以及中间层次的民族学与文化学、经济学,以及图书馆、情报与文献学为例(如图7 所示),对不同学科交叉特征进行微观分析。
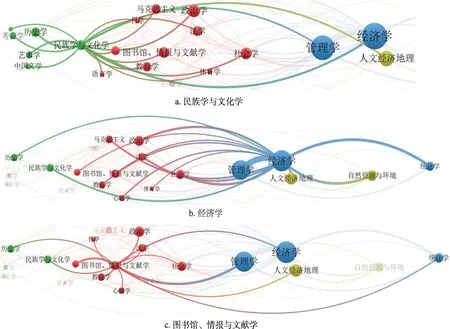
图7 DDC最小、最大及中间层次学科的互引网络图
观察图7 可以发现,图7a 中,民族学与文化学共与18 个学科存在广泛的知识流动,且与各个学科间的知识流动强度比较均匀,表明该学科与其他学科间的知识交叉范围广,与学科群体交叉程度较深;图7b 中,经济学共与16 个学科存在知识流动,范围较广,但与不同学科间的知识流动强度极不均匀,其中与管理学的知识流动强度最大,次之是统计学、人文经济地理、自然资源与环境,而与其他学科的知识流动则相对微弱,表明该学科仅与4 个学科具有较强的交叉融合,知识交叉范围较小;图7c 中,图书馆、情报与文献学共与13 个学科存在知识流动,与管理学、新闻学与传播学知识流动强度相对较大,但与其他学科的知识流动在整体上没有表现出较大差异,表明该学科与较多学科存在知识流动,广度和强度均处于一般水平。
对比3 个学科与其他学科的知识流动发现,民族学与文化学的知识流动范围最广,学科交叉程度最深;经济学虽与较多学科存在知识流动,但仅与小部分学科存在较强的交叉,其他学科并未对其产生较大影响;而图书馆、情报与文献学则介于两者之间。由此可以说明,学科间的知识流动广度、强度以及均衡性对学科间的交叉融合具有重要影响,反映在研究内容方面则会影响学科的区分能力,即某学科与其他学科间的交叉融合程度越深,其学科区分能力就越弱,反之越强。
5 结 语
区分能力作为学术对象的内在属性,对研究学术对象个体与群体之间的差异程度具有重要作用。本研究在已有研究的基础上,提出学科区分能力来对学科个体和总体的差异特征进行分析。本研究采用标题、关键词、摘要等内容数据对学科对象进行区分能力测度和分析,并分别采用了基于PCA 和ADV 方法对学科的空间分布进行了辅助分析。在此基础上,将学科区分能力指标与布里渊指数、Rao-Stirling 指数、Gini 系数等学科交叉指标进行了对比分析,探讨指标间的相关关系及其优劣性。同时借助学科互引网络来对学科交叉和学科区分能力的内在联系进行分析和验证。结果表明,①利用学科区分能力指标能够很好地测度学科个体与群体的差异性特征。23 个学科个体区分能力差异显著,经管类学科区分能力最强,人文类、社科类学科区分能力普遍偏弱,部分学科如民族学与文化学、政治学等区分能力最弱,呈现出显著的学科交叉特性。②本研究提出的基于ADV 可视化方法能够准确刻画学科个体的差异性特征,相较于基于PCA 的可视化方法,能够更好地适用于学术对象差异性分析。根据其分布的相对位置可以判断其区分能力:距离原点越远,其区分能力越强;距离学科群体越远,其与群体的差异程度越大。③学科区分能力指标与布里渊指数、Rao-Stirling 指数、Gini 系数等学科交叉度量指标具有一定的相关性,但两者并不完全一致,可以在一定程度上相互补充;同时两者之间的相关关系这也反映了学科间的交叉融合会对学科区分能力产生一定影响。④学科区分能力测度和学科互引分析结果具有高度的一致性,这验证了学科交叉和学科区分能力之间的相关关系以及学科间知识交叉融合对于其区分能力的影响程度;并且通过学科区分能力测度和学科互引分析填补了学科差异性特征和交叉性特征之间的缝隙,实现了学科对象内容测度和引文分析相统一。
本研究基于所提出的方法对学科对象的区分能力进行了测度与分析,但仍有不足之处。本研究仅与学科交叉指标进行了对比分析,讨论了两者之间的相关关系,但对于学科其他特征如学科影响力、学科创新性等并未涉及;同时,在利用引文网络分析时,未对引证强度、出入度等网络指标与学科区分能力之间的关系做深入分析,后续将在这些方面进行更加深入的研究。
