基于先精确后召回策略的作者名消歧模型研究
2022-05-19鞠秀芳
沈 喆,王 毅,鞠秀芳,成 颖
(1. 南京大学信息管理学院,南京 210023;2. 南京大学中国社会科学研究评价中心,南京 210093)
1 引 言
目前,作者名歧义已经对科学计量与评价研究的可靠性、信息检索的查全与查准率等产生了较大的负面影响[1]。为此,在作者个体层面建立完整且准确的学术成果集,即实现作者名消歧(author name disambiguation,AND) 已成为学界的迫切需求。鉴于AND 提供的重要数据支撑作用,学界已经对其开展了相当丰富的研究,研究成果的概貌可见之于 Smalheiser 等[2]、Elliott[3]、Hussain 等[4]、San‐yal 等[5]学者的综述。不过,现有研究与实践尚难以支撑后继应用的需要,比如,ORCID、ResearchID等作者身份标识码存在普及率不高的问题;个人或研究团队主页等外源性数据普遍存在数据不完整、更新不及时以及网页的异构造成的可用性低等问题;基于机器学习的消歧模型的F1 值普遍差强人意且泛化能力弱[6],以AMiner 数据库为例,其研究团队利用网络表示学习等方法建构的消歧模型的F1值仅达到了0.68[7]。
高层次科研人才作为国家科技核心竞争力和科学事业发展的领军人物,现有的计量以及科技人才评价等研究多聚焦于此,如诺贝尔奖获得者[8-10]、中国科学院院士[11]、长江学者[12-13]、国家杰出青年科学基金获得者(下文简称“杰青”)[14]等。相关研究重点探讨了人才的产出规律、成长轨迹以及影响因素等。显然,高AND 精确率和召回率的数据集是相关研究得到可靠结论的重要前提。目前,有关诺贝尔奖获得者的成果已经有开放的数据集,具体到院士、长江学者以及杰青等我国的高层次科研人才尚未见类似的成果,现有研究主要通过人工核验等方式收集少量样本数据[11-14]。诺贝尔奖获得者等他山之石虽可攻玉,但以我国的高层次科研人才为对象的研究对国家的人才及团队的评价、潜在优秀人才的发现和培养、学科建设与发展等方面均会有更直接的价值。因此,有必要构建以院士、长江学者以及杰青等为代表的高层次科研人才学术成果的开放数据集。
目前,采用机器学习、图模型等的消歧方法在AND 上的表现均没有达到实用的要求[6],而基于规则方法具有高效率和高精确率等优点;从实用性的角度出发,本研究拟采用基于规则的方法开展研究工作。拥有较强影响力和知名度的高层次科研人才的履历、研究方向和学术成果等外部数据对于提高消歧模型的精确率和召回率有重要作用,且相关信息易于从网络搜集,可以保证本研究的顺利开展。考虑到不同类型高层次科研人才的成长性,本研究拟以杰青为例开展研究工作。据此,本研究拟采用上述外部数据并结合文献元数据,采用“先面向精确率,后面向召回率”的逐步优化策略,构建基于规则的“两步法”消歧模型,为解决高层次科研人才的学术文献AND 提供一条可行的路径。
2 文献综述
2.1 AND研究概况
Ferreira 等[15]提出,一人多名(synonyms)和一名多人(homonyms)是引发作者名歧义的两个主要原因。前者多源于拼写变体或错误,随婚姻、宗教、性别等因素改名以及使用多个笔名等;后者则主要源于少数姓氏的流行和名字的常见性等[2],在亚洲国家尤为突出,并且,期刊常使用姓氏+名首字母的方式表示作者信息,进一步加剧了一名多人的情况[5]。值得注意的是,随着我国科研实力和国际地位的提升,我国学者发表的外文文献数量高速增长,但同音不同字、拼写不规范、复姓、多音字等姓名翻译问题使得国内学者外文文献中的姓名存在歧义的程度更为严重[16]。同时,元数据缺失或不完整、多作者、多学科以及跨机构的合作等也为AND 带来了更大的挑战[2]。目前,常见的AND 系统框架通常包括特征提取、特征表示以及模型训练与预测等模块。
(1)特征提取。AND 的特征主要来源于文献数据库中的元数据和外源性数据。元数据提供了消歧的常用特征,如作者层面的合作关系、地址以及邮箱等,文献层面的标题、出版物名、摘要以及关键词等。外源性数据包括从科研机构、ResearchGate、ORCID 等平台的个人主页中提取的成果列表、学者ID,以及从搜索引擎的检索结果中挖掘出的网页共现关系等。由于元数据不同程度的缺失、个体学习或工作单位的变动、跨学科研究的增多等原因,外部数据有助于解决元数据特征明显不同时的合并问题。
(2)特征表示。Huang 等[17]根据表示模型的数学理论基础,将特征表示分为基于集合论、代数、概率、图结构以及混合方法等5种。具体到AND,常见的集合论模型方法包括Jaccard 系数[18]、N-gram[19]、Jaro-Winkler 相似度[20]以及 Hamming 距离[21]等,代数模 型 方 法 则 包 括 One-Hot 编 码[22]、 TF-IDF[23]、word2vec[7,24]、doc2vec[25-26]和语义指纹[27]等,概率模型主要使用特征共现的频率刻画对象间的关联强度[28-33],图结构模型常见的有多特征网络[34]以及异构网络[25-26,35],混合模型的主流方法包括成对似然排序[25,36-39]、 DeepWalk[40-41]、 node2vec[42]以 及 图 卷积[7,26,43]等。
(3)模型训练与预测。模型训练与预测模块将识别待消歧文献所归属的作者实体。Ferreira 等[15]归纳了两种实现思路,一是分组(grouping),依据共性特征归并事先未知的作者实体文献集;二是指派(assignment),根据特征相似度将文献指派给已知的实体,该方法所需人工标注工作量较大。现有AND 研究多集中于分组方法,可划分成基于机器学习、基于图和基于启发式规则三类。
基于机器学习的模型在AND 中应用广泛,不过鉴于有监督的分类方法存在较多缺陷,如过度依赖标注数据的规模和质量、训练数据分布不均等[44],现有研究中无监督的聚类方法更为多见,包括层次聚类[25,36,41-43]、谱聚类[24]、AP 聚类[37]、K-means[45]等。聚类方法的难点在于确定聚类数或者聚类结束的条件,多数研究仅设定了一个相似度阈值,即当簇间距离均低于阈值时停止。部分研究提出了更多的思路,例如,根据标注数据训练神经网络模型估计不同数据规模的合适聚类数[7];在特征网络图中,簇间没有边相连则停止聚类[26]等。此外,使用多特征聚类时需要判断不同特征的重要性,有研究在少量标注数据中训练逻辑回归分类器,以确定不同特征的区分能力[29,46];Xu 等[47]基于每个特征都完成一次聚类,计算F1 值占比赋予权重。代表性的相关研究如表1 所示。

表1 基于机器学习模型的AND研究
基于图的模型依据路径识别同一作者实体,具体采用的判断条件包括有效路径强度之和高于阈值[35]、最短路径的距离低于阈值[50]等。此外,采用连通分量方法将有边相连的节点归并成同一类的思路对网络图的构建提出了更高的要求,文献[19,51]结合了机器学习方法用于决定网络中边的连接。代表性的相关研究如表2 所示。
基于规则的模型相较于时间复杂度高的机器学习和图模型,拥有高效准确的优势。该模型的关键在于确定处理顺序的优先级以及合理的特征组合。例如,刘林[52]认为同一作者实体在不同机构的发文时间窗应该不同。Hazra 等[53]则认为不同机构的同一实体,其研究高峰年以及活跃区间可以相似,即存在研究者同时就职于多个单位的情况。Sun 等[54]认为在细分领域下作者重名的可能性很小,使用两次聚类细化研究领域的描述,将其作为区分不同作者的主要依据。Cota 等[55]基于合作者姓名、论文题名以及期刊名提出了两步法消歧策略,第一步通过合著者将同名作者进行链接并据此聚类,第二步通过论文题名以及期刊名的相似度迭代归并第一步中生成的聚簇。Schulz 等[56]基于合作者、参考文献以及被引文献的相似度提出了三步法消歧策略。第一步,相似度超过阈值的作者生成作者对簇;第二步,基于聚簇的相似度对第一步生成的作者对簇进行归并;第三步,归并独著作者。Backes[29]的模型首先计算了论文题名、摘要以及作者机构等特征的相似度,其次根据TF-IDF 的思想对特征进行加权,最后归并得分高于阈值的作者。Caron 等[57]提出的消歧模型计算了各特征的相似度,并根据特征对消歧的重要性进行赋权,并将超过阈值的作者进行归并。代表性的相关研究如表3 所示。
2.2 述 评
学界围绕AND 已积累了较为丰富的研究成果,现有研究主要涉及特定学科、综合学科以及特定机构的学者,较少有研究针对高层次科研人才这一特定群体。相关实证研究显示,外源性数据在面向所有类型学者的姓名消歧时作用有限[23,34],主要原因在于采集难度大[52]、数据缺失严重[45],同时可靠性也难以保证[19]。鉴于高层次科研人才辨识度比较高的优势,其AND 研究中所需的相关外源性数据更易于获得,且更加全面、可靠,在消歧中能够发挥更重要的作用。由表1 可见,基于机器学习的AND研究的F1 多在0.7 以下,新近的一项较优的研究[49]也仅0.78;表2 显示的结果让人欣喜,比如,其中一项研究[35]的F1 达到了0.96,不过,阅读该项工作的实验数据描述表发现,作者为“李强”的文献量仅为44,与万方数据的实际检索结果有较大差距,提示该数据应是在受限语境下的检索结果,因此,该项工作在非受限的场景下是否依然有如此优异的表现尚需要进一步研究的证实。表3 提示,基于规则的F1 多优于基于机器学习,其中一项工作的F1达到了接近实用要求的0.90。

表2 基于图模型的AND研究
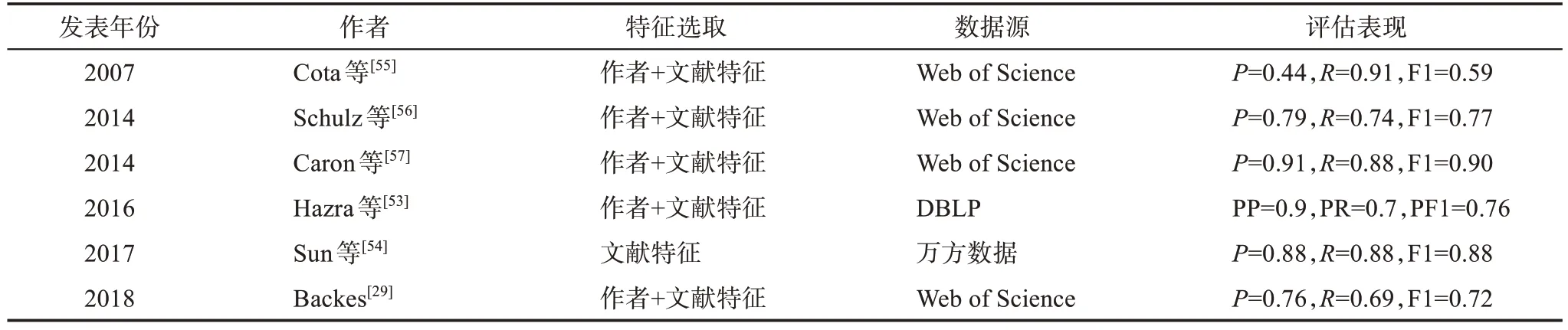
表3 基于规则的AND研究
综上,鉴于基于机器学习算法AND 研究的F1值普遍难以满足应用需要的现状,以及科学计量与人才评价等研究对数据质量的高要求,本研究拟充分发挥基于规则模型在精确率方面的优势。目前,基于规则的现有实证研究多基于计算机、物理或医学等单一领域的数据库,而应用于大型综合数据集(如Web of Science)时表现难以保证,并且华人学者外文文献消歧的相关研究较少。由于Web of Sci‐ence(WoS)等综合性数据库姓名歧义程度大幅提高的现状,如基于合著关系的消歧策略的有效性难以充分彰显[18,36]等,本研究拟采用多特征融合的策略首先面向精确率展开研究工作。同时,针对基于规则的方法在召回率上表现欠佳的问题,如针对跨学科研究、单位变动等引发的姓名歧义问题,本研究拟综合采用现有研究中广泛使用的基于元数据的多特征组合方法,并结合外源性数据以提高模型的召回率,建构“先面向精确率,后面向召回率”的“两步法”消歧模型。
3 数据与方法
3.1 总体思路
目前,基于规则的AND 研究中存在一步法(Backes[29]、 Caron 等[57])、 两 步 法 (Cota 等[55]) 以及三步法(Schulz 等[56])等不同的策略。其中,一步法难以同时满足AND 对高精确率与召回率的要求,虽然 Caron 等[57]研究中的 F1 高于 Schulz 等[56],宜考虑是后者采用的特征集较小所致;而两步法以及三步法提供的柔性机制更符合AND 的需要,能更好地兼顾精确率与召回率。需要说明的是,Schulz 等[56]虽比Cota 等[55]增加了独著作者的消歧环节,不过该环节也可在第一和第二步完成,并非必需。就精确率以及召回率两个指标而言,未消歧数据集的召回率可达100%,因此召回率在AND 研究中非首选目标;这样,精确率必然成为AND 研究的首要着眼点,即在保证高精确率的前提下兼顾召回率,也就自然地形成了本研究的两步法消歧模型。
据此,本研究提出的方法总体思路如图1 所示。第一步,面向精确率。①本研究首先根据履历信息排除与目标作者经历不同的学者,降低待消歧文献量;②利用邮箱、基金号、合著关系、出版物名和所属学科类别等特征,对同一机构内的重名作者消歧;③将相关联的文献划分成不同实体的文献集;④为了从重名的不同实体中识别出目标作者文献集,进一步引入基金名、外部数据中的代表作和研究方向特征进行优化。

图1 高层次科研人才两步法姓名消歧模型
第二步,面向召回率。本研究依据第一步已确认作者身份的文献集,对误检漏检的文献做进一步处理。①邮箱可以快速准确地识别出同一作者的文献;②与初步扩充的文献集进行比对,采用合著关系、地址、基金号等元数据特征,以及履历机构、研究方向等外部特征的合理组合进行判断;③形成目标作者的完整消歧文献集。
3.2 数据预处理
3.2.1 文献数据库
根据作者名对文献数据进行分区(blocking)通常是消歧的第一步,旨在降低后续消歧任务的复杂度以及非同名数据的干扰,现有研究多采用姓全拼+名首字母(last name-first initial,LNFI)的方式进行划分。对华人学者的外文文献进行消歧时,需要注意的是,WoS 数据库自2006 年11 月开始提供作者姓氏+名全拼(last name-first name,LNFN)的信息[58],即数据集中存在LNFI 和LNFN 格式并存的现象。根据作者名是否完整可以将数据集分成LNFN 数据集与LNFI 数据集,即可以从LNFN 数据集中直接剔除缩写一致但全拼不一致的数据。为避免不同拼写形式导致的误删,本研究保留了先姓后名、先名后姓以及包含常用连字符的拼写变体。经预处理后,原始文献数据集被一拆为三:第一部分,姓名全拼和目标作者姓名相同的数据集Dfull,用于消歧的第一阶段以保证精确率,并在第二阶段进行二次判断;第二部分,仅提供了姓名缩写的数据集Dabbr,用于第二阶段以提高召回率;第三部分,姓名全拼和目标作者姓名不一致的数据集Ddiff,可直接剔除。另外,Ddiff可用于识别Dabbr中与Ddiff为同一作者的数据Ddiff_rel,在第二阶段中将Ddiff_rel数据也直接剔除。
3.2.2 外源性数据
百度百科是目前最大的中文网络百科全书,截止到2021 年2 月,已收录22791094 个词条[59]。得益于百度百科词条的质量保障机制,如关键信息需要权威参考资料支持,多主体的编辑、审核与完善团队等[60],词条内容的可信度较高,可用于获取拥有一定学术成就的学者的履历、代表作和研究方向信息。对于百科词条这一外源性数据的预处理过程为:
(1)收集并解析百科人物词条数据:为避免姓名歧义问题,在爬取词条时根据其内容是否同时包含依托单位和所获荣誉进行筛选。
(2)机构名提取:基于履历信息提取出学者学习或工作过的机构名称,目前较为成熟的命名实体识别技术(named entity recognition,NER)可以实现从文本中提取机构名,同时辅以自定义的语料库以达到更高的精确率。本研究采用百度LAC(lexi‐cal analysis of Chinese)中文词法分析工具对履历文本进行机构实体的识别,并采集我国教育部发布的国内外大学名单、丁香医生网站提供的国内医院名单生成自定义词典对模型进行优化。未直接采用字典法匹配的原因在于国外大学名有多种译法,如加利福尼亚大学又称“加州大学”,字典法不能一一列举;此外,各研究中心、实验室、海外医院等机构名均难以获得完整的名单。
(3)机构名翻译:面向外文文献数据消歧时,需要将中文履历中包含的机构名翻译成英文,鉴于现有翻译软件的准确率难以保证,本研究采用从机构的百科词条中获取其对应英文名的方式进行中英文转换。
3.3 “两步法”消歧模型
3.3.1 特征区分能力
从元数据和外部数据中提取出的特征,其区分不同实体的能力不同。其中,邮箱与代表作本身不存在歧义,前者可以准确归并同一作者的成果,后者可以识别出目标作者的文献;合著关系是AND中广泛使用的特征,有学者[18,36,50,53]直接将具有共同合著者的文献归并为同一作者实体;部分研究利用了机构对作者加以区分[29,39,45],履历的机构信息能够排除经历不同的学者,有助于解决人员流动问题,而WoS 提供的地址信息大部分详细到二级机构及邮编,使得完整地址的相似度以及提取出的邮编也具有较强的消歧作用;资助基金号可以反映同一基金资助的文献间紧密的关联,基金名则可以识别出受特定基金资助的文献,可用于确认作者身份。本研究将上述特征设定为强特征。
考虑到同一研究领域存在同名作者的可能性较高,本研究将与研究方向相关的特征设定为弱特征,包括文献元数据中的标题、出版物名以及WoS提供的出版物所属的二级学科类别列表;外源性数据中的学者研究方向,可用于排除不同领域的同名学者。
各特征的区分能力如表4 所示,除邮箱和代表作外,仅依据单一特征难以完全消解歧义。本研究拟根据消歧过程中需解决主要问题的不同,进行强弱特征的合理组合。

表4 各特征区分不同实体的能力
3.3.2 第一步消歧
1)不同机构间的重名消歧
为排除与目标作者经历不同的同名作者,本研究采用发文机构与履历信息中的机构进行匹配。为保证后续处理的准确性,首先基于Dfull进行筛选,以缩小待消歧文献量。具体匹配过程中,WoS 提供的地址信息对常用词进行了一定程度的缩写,如“univ”“coll”“hosp”分别表示“university”“col‐lege”“hospital”。由于数据量庞大,穷举所有缩写规则的可行性很低,不过,WoS 提供了部分文献一级机构的全称,可用于构建机构英文名全称和缩写的映射表。对于存在全称的数据,进行完全匹配;对于全称缺失的情况,采用编辑距离大于阈值的条件判断是否为同一机构。本研究选取了中位数、众数以及均值等多个阈值进行测试,最终发现将阈值设定为机构名全称和缩写映射表中编辑距离的均值(0.783),可以保证第一步所得结果的高精确率。

2)同一机构内的重名消歧
考虑到从履历中提取的是一级机构,仅能和WoS 地址信息中的一级机构进行匹配,且华人学者中广泛存在的同音不同字现象提高了重名概率,因而,履历中包含的几个机构内的重名问题是消歧需要解决的重点之一。通过邮箱可以准确地识别出同一作者的文献,不过,作者邮箱也会随单位变动而发生改变,且当目标不是第一作者或通信作者时数据缺失严重。
鉴于上述问题,模型通过强弱特征的组合识别出同一实体,即在合著关系这一强特征基础上,为避免可能存在的合著者重名的影响,本研究结合地址、基金号和研究方向三个特征进行限制;具体地,拥有相同合著者,并且地址、基金号或研究方向三者其一相同的文献归并为同一作者实体的成果。


3)消歧结果优化
经过上述两步的处理,每个作者的全拼数据集可以划分出多个不同的同名作者实体文献集。在此基础上,需要从中识别出目标作者实体,可用于判断的条件包括:①文献集是否包含了从百科词条中收集到的该学者成果题名;②文献基金信息中是否含有标注了所获荣誉名的文献;③在上述特征缺失的情况下,基于同一机构中存在相同研究方向的同名作者的概率极低这一消歧研究中常见的假设[28,54,61],模型根据文献内容特征与研究方向信息进行判断,具体采用文献的题名、出版物名和出版物所属学科类别与外部数据中目标作者的研究方向信息进行文本余弦相似度的计算,其相似度之和最高的文献集合则为目标作者所著,得到的初步消歧结果记为Dconfirm。

3.3.3 第二步消歧
1)召回数据集
为提高模型召回率,消歧模型的第二阶段根据已识别出的文献集Dconfirm及相关特征数据在Dabbr中进行筛选与增补,同时,鉴于履历信息存在更新不及时、机构识别和翻译的遗漏和错误等,未通过履历筛选的Dfull同样需要二次判断。为了压缩Dabbr的规模,本研究首先在Dabbr中剔除与Ddiff存在相同邮箱或基金号的数据Ddiff_rel。

最终待消歧数据Dremain范围包括Dfull-Dconfirm以及Dabbr-Ddiff_rel两个部分。
2)召回算法
首先,依据已识别数据Dconfirm的作者邮箱在Dremain中快速召回同一作者的文献,并汇总入Dcon‐firm。考虑到在缩写数据中,合著者与同名实体合作的概率增加,本研究仅采用标注了目标作者的邮箱信息作为判据。
其次,对于邮箱特征缺失的数据,本研究依据已识别数据Dconfirm采用更多特征组合判断Dremain剩余文献的归属。使用的强特征包括是否有共同合著者、基金号、完整地址的相似性,以及发文机构是否为履历中的机构等;弱特征涉及出版物名及其所属学科领域是否相同,以及标题、出版物及所属领域和外源性数据中的研究方向是否相似等。
最后,鉴于大规模数据中华人学者的外文名存在更高的重名风险以及完整地址和基金号等特征的不同程度缺失,为避免存疑单个特征造成的误检漏检,本研究发现将满足任意两个强特征或一强一弱特征作为判断条件,既没有降低精确率,同时也提高了召回率。


最终,目标作者的消歧文献集合为Dcomplete。
4 实验与结果
4.1 实验数据
本研究采用杰青数据验证两步法模型的有效性。依据1997—2019 年4107 位杰青的姓名,采集了WoS 数据库收录的文献题录共计5017168 条,其中仅提供缩写作者名(Dabbr)的数据占27%,提供姓名全拼(LNFN)的数据集中,与目标杰青姓名一致的数据(Dfull)占23%,不一致的数据(Ddiff)占50%。除作者列表、标题、出版物名外,各特征的缺失比例不同,在Dabbr中缺失最为严重(图2)。

图2 不同数据集中各特征的缺失情况
4.2 模型评估
本节将对消歧模型中的主要步骤逐步进行评估,并根据结果不断调整模型以实现最优。
(1)依据履历机构缩小消歧范围。根据学者工作或学习过的机构信息进行初筛后,筛选结果中少量学者的文献量极低,甚至为零,其主要原因在于:①中文姓名存在多音字以及非常规笔名的情况,如“单”“仇”“伯”“乐”等字的读音以及“Rau, P. L. P.”“Chan, R. C. K”“W Hsu”等个性化的笔名,在WoS 中使用姓名检索文献时未将上述问题考虑在内,导致39 人的姓名和机构无法匹配;②共有7 名学者的数据中提供姓名全拼的文献小于5 篇;③部分机构的简写和全称差距过大或有多种英译名,例如,“中国人民解放军总医院”中的People's Liberation Army,其简写为“PLA”,“中国气象科学研究院”既有“Chinese Academy of Meteo‐rological Sciences”,也有“China Meteorological Ad‐ministration”。对此,更新履历机构信息和全称简写映射表,重新进行机构筛选,最终待消歧文献量从人均2635 篇降至132 篇左右(图3)。
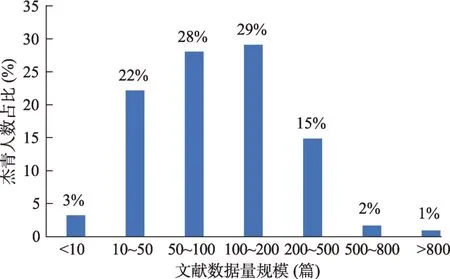
图3 履历机构筛选后的待消歧文献量
(2) 同机构内不同实体的划分及目标实体识别。采用邮箱、基金号以及合著关系辅以研究方向的判断条件可以较为准确地划分同名的不同实体。这一过程中,有73%的杰青其确认的文献量约占机构筛选后文献量的70%。
(3)基于初步筛选结果进一步增补。鉴于初步筛选后的数据较为准确,提供的目标作者的邮箱可以准确快速地补充遗漏文献,为后续过程提供更多可依据的信息;不过邮箱特征缺失严重,对提高召回率的贡献有限,因而采用多特征组合条件对剩余数据进行再次补充。本研究针对的是高层次科研人才,这类学者为科研事业做出了较大的贡献,通常学术成果丰硕;本研究结果统计可得,90%的杰青成果数大于30 篇,54%的杰青成果数超过100 篇。需要指出的是,3 个强特征均缺失,即仅有一个作者且无机构和基金信息的5 万余条文献数据无法判断其所属的作者实体。
(4)性能评估。Caron 等[57]提出的消歧模型在Tekles 等[62]的AND 比较实验中表现最优,本研究将其作为基线方法(简称为Caron 法),以验证本研究模型的消歧性能。除了表4(两步法,表4 特征集)列出的特征外,Caron 法还采用了引用关系特征,故本研究将引用关系特征补充至表4 作为两步法的另一种实现(两步法,表4 特征集+引用关系特征),具体做法借鉴Caron 的权重思想,将自引、4篇(含)以上的引文耦合和共被引设置为强特征,4 篇以下的引文耦合和共被引设置为弱特征,本研究将对3 种方法的性能进行比较。
本研究使用精确率(P)、召回率(R)与调和平均值(F1)评价消歧模型的性能,通过随机选取的10 名杰青的文献数据进行人工消歧,可得两步法(表4 特征集)的模型表现,如表5 所示。由表5可以发现,在待消歧规模以及特征缺失程度不同的情况下,第一步消歧的结果均能实现近100%的精确率;第二步消歧过程使召回率也得到了较大幅度的提升,达到了0.883,最终的消歧模型的精确率稳定在0.991,平均F1 值为0.933。

表5 基于规则的两步法(表4特征集)作者名消歧模型表现结果评估
基线方法与采用两个不同特征集的两步法实验结果如表6 所示。总体上,两步法的F1 值均高于Caron 等[57]的方法。整体而言,两步法(表4 特征集)与Caron 法的召回率差异甚微,从两者采用的特征来看,前者采用了作者履历特征,后者采用了引用关系特征,其他基本相同;而当两步法同时采用了履历特征+引用关系特征后,其召回率已明显优于Caron 法。该结果表明,两步法采用作者履历信息+引用关系特征与其他特征结合的方式提高了对跨学科研究、单位变动等作者的识别能力。从精确率来看,Caron 法的表现不够稳定,比如,最低的P值仅为0.335,其原因在于低引文耦合与其他弱特征匹配的得分高于阈值会使非目标作者文献被纳入。由此可见,特征的消歧能力与阈值同时影响着模型的性能。Tekles 等[62]的研究给出了不同待消歧文献数量下的最佳阈值,但当文献量较少即阈值较低,且同时匹配的弱特征较多时,Caron 法无法准确识别同一作者的文献。而两步法由于需要弱特征和强特征的同时满足,且补充了引用关系特征,其精确率较基线方法有很大提升且性能稳定。由表6 可见,两种两步法实现的F1 值均优于Caron 法,从而显示了两步法在AND 方面的优势。

表6 基线方法与采用两个不同特征集的两步法实验结果对比
5 讨 论
5.1 消歧策略
本研究设计的两步法消歧模型符合计算机科学“自顶向下,逐步精化”以致问题解决的基本原则。第一步面向精确率的消歧包括基于履历机构的初步筛选,以及使用多特征限制的合著关系进行实体的划分。不同于现有研究选取的特征集较小,本研究采用多特征组合的条件判断降低了同名合著者的干扰,保证了划分不同同名实体的准确性。不过,难以避免的是过度分裂的问题,例如,难以识别人才流动造成的合著网络没有交集的文献,对此,引用关系特征的引入从一定程度上进行了弥补。
第二步面向召回率的消歧旨在依据高精确度的结果,使用多特征组合找到更多目标作者的文献,其中若地址信息包含了履历中的机构并且有共同合著者或相同研究方向,则可判断为该学者的成果,充分利用了履历信息。未将这一条件直接应用于第一步的原因在于,划分不同实体是一个“滚雪球”过程,在网络中寻找连通分量,若在节点间建立了错误的边,则会导致大量的错误数据被导入,进而使后续操作建立于错误的基础之上。相比之下,在最后补充阶段使用强弱特征结合的条件提高了模型的召回率,同时避免了因极少量数据的误判而引起错误的连锁反应。另外,强弱特征的结合是模型的另一个特点,同名的不同实体多个弱特征相似易带来错误的结果,该问题可以通过提高阈值来解决,不过,在歧义程度不同的情况下阈值如何设定仍需进一步研究。
5.2 模型优势
近年来,学界围绕AND 仍在持续不断地改进原有方法或提出新思路,通过对前人研究成果的梳理发现,研究改进主要集中于特征表示方法和机器学习模型。诸多学者采用了网络表示学习方法[36-43]将合著网络、引文网络或者文本相似度网络中的特征表示从高维转变为低维向量以便于计算,不过该类方法对AND 性能的提升作用并不明显,模型精确率最高仅0.8 左右。鉴于这类方法尚不成熟,本研究采用多特征融合的方式避免了单特征本身存在的歧义问题,并利用基于规则的策略保证了模型的精确率和效率。
另外,机器学习模型在AND 中应用广泛,有监督的分类算法通过对训练数据的学习,避免了人为地、依靠经验确定不同特征权重的不足,能够达到较高的精确率。不过,模型性能很大程度上依赖于学习数据的质量,在缺乏来自各学科的学者成果黄金标准数据集(golden standard dataset) 的情况下,现有研究的标注数据多源于ORCID、谷歌学术主页等外部数据或人工标注的少量数据,这些收集方法存在数据缺失以及耗时费力等缺点,且训练数据还存在分布不均的问题,如负例数据量常远大于正例,其结果只是增加了计算量却没有显著提升消歧性能[44]。不依靠训练数据的无监督聚类算法更为常用,部分学者对于如何确定聚类数或停止聚类的阈值条件这一难点做出了有价值的探索,但F1 值仅0.7 左右[7,26],在大量常用名和同音名的华人学者外文文献数据集中,估计同名的不同实体数难度更大。此外,聚类算法的时间复杂度高,不断增长的文献数据对计算性能提出了越来越高的要求。面向高精确率和高召回率的消歧需求,机器学习模型仍难以达到实用的要求。本研究针对高层次科研人才这一已知身份的作者名进行消歧,避免了聚类算法中确定聚类数的难点,且采用基于规则的方法能够大幅度提高处理速度。基于两步法的多特征融合的规则模型更重要的优势体现在,在部分特征缺失的情况下可根据不同的特征组合进行判断,避免了机器学习模型学习不充分导致的欠拟合问题。
5.3 履历数据的收集与处理
履历数据在现有AND 研究中受到的关注较少,在面向所有层次科研人才的消歧研究中,全面收集学者履历信息的可行性较低,也有研究[63]仅对某一机构内的学者进行消歧,均未能发挥履历信息降低待消歧数据规模和识别机构变动的作用。有研究[14,64]通过人工收集学者的履历信息,保障了信息的完整性和准确性,但规模非常有限且不易于推广应用。针对高层次科研人才这一研究价值更高的群体,履历信息更易于获得,比如,以本研究的实验数据为例,90%的杰青都可以从百度百科词条中获取教育或工作经历信息。需要指出的是,百科人物词条存在着更新不及时、信息不全面的问题,数据质量相比于问卷调查和学者主页较差,不过后者大规模收集的可行性低,而易于爬取、结构相近且便于信息抽取的百科词条是更为完善的解决方案。
另外,NER 技术的限制和翻译不准确的问题造成了部分机构信息的丢失,例如。“Bascom Palmer眼科研究所”“John Innes 研究中心”等词典法难以列举出的机构和中英文混杂的写法,对NER 识别的准确率有细微的影响;外文文献的消歧需要将中文机构名进行翻译,中译英的多种形式也使得匹配过程中存在误差。本研究主要通过邮箱、合著者、基金号和研究方向等多特征组合进行判断,以弥补履历信息缺失造成的遗漏。
6 结 论
本研究针对高层次科研人才,在已知学者履历和研究方向的前提下,建立了一个基于规则的“两步法”消歧模型;两组不同特征集的实验显示,模型的F1 值分别达到了0.93 和0.95,较现有研究有较大提升。鉴于百度百科数据易于获取,模型的推广和易用性也体现了一定的优势,为研究高层次科研人才所需的消歧数据提供了可操作性和准确性兼具的解决方案。
需要指出的是,本研究以杰青作为研究案例,仅仅是因为杰青等高层次科研人才的辨识度比较高,能够方便地从百度百科等途径获得其履历等相关信息而已;就原理而言,本研究的模型可以推广到所有类型科技人才的消歧研究与实践,待他日其他类型科技人才的履历便于获得后即可使用本研究的模型。
另外,本研究也存在一些有待改进之处,包括NER 技术的查全查准率、中译英的翻译准确性、摘要关键词等可以更准确提供研究方向的特征缺失等,对面向所有学者消歧研究的借鉴价值尚需进一步探索,AND 任务的全面解决仍需要科研人员、管理部门以及文献数据库的共同努力。
