基于半监督集成学习的词义消歧
2020-11-13张春祥熊经钊高雪瑶
张春祥, 熊经钊, 高雪瑶
(1.哈尔滨理工大学 软件与微电子学院,黑龙江 哈尔滨 150080;2.哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨 150080)
词义消歧的目的是确定歧义词汇在特定上下文环境中的具体含义。词义消歧对机器翻译、话题关联检测、语音识别、文本分类、信息检索和主题挖掘等应用有很大的影响[1-2]。钱涛等[3]、SONAKSHI等[4]和EDILSON等[5]使用图来描述词义消歧问题。ROCCO等[6]根据分布信息来计算语义的相似性,提出了一种新的基于进化博弈理论的词义消歧模型。SALLAM等[7]将蜂群优化元启发式算法应用于词义消歧过程,利用多个人工蜂代理来协同处理该问题。SULEMA等[8]利用Alpha-Beta联想记忆对歧义词及其上下文之间的关联性进行计算,提出了一种基于简化LESK算法的词义消歧方法。与其他基于LESK的方法相比,该方法具有一定的优越性。MYUNG等[9]提出了一种基于词嵌入的消歧方法,使消歧特征向量具有可加性和组合性,消歧特征向量更加紧凑和高效。OSMAN等[10]和CLAUDIO等[11]以少量带有语义注释的语料为基础,挖掘大量无标注语料中的语言学知识来进行半监督词义消歧。杨陟卓[12]和孟禹光等[13]分别利用上下文的译文和词性来确定歧义词汇的含义。WANG等[14]以共现知识和训练文档的类知识为基础,利用语义扩散核来解决词汇的歧义问题。郭瑛媚等[15]以话题信息、位置关系和互信息为消歧特征,提出了一种无监督的跨语言词义消歧算法。利用在线词典和Web搜索引擎,使用上下文信息来确定评论句中多义评论词的具体含义。杨安等[16]和鹿文鹏等[17]利用领域知识来进行词义消歧。HUNG等[18]和唐共波等[19]分别利用情感词汇网络词典与知网中的义原来进行词义消歧。许坤利等[20]用启发式信息从语料中挖掘实体和关系,对谓词进行消歧。WANG等[21]和ANTONIO等[22]以生物医学中的专业知识为基础来建立词义消歧模型,解决了文本中词语的歧义问题。
本文以歧义词汇为中心,从其左右4个邻接词汇单元中抽取词形、词性和语义类作为消歧特征,统计其出现的频率。以逻辑回归模型、梯度提升决策树和支持向量机为基础,采用软投票策略来构造集成词义消歧模型。同时,使用半监督学习方法来优化集成词义消歧模型。
1 词义消歧特征的选择
本文利用词法知识和语义知识来确定歧义词的含义。以歧义词为中心,选择左右4个邻接词汇单元。从每个词汇单元中,抽取词形、词性和语义类作为消歧特征。
对于包含歧义词“中医”的汉语句子,其消歧特征的提取过程如下所示:
汉语句子:一位当中医的亲戚。
分词结果:一 位 当 中医 的 亲戚。
词性标注:一/m 位/q 当/v 中医/n 的/u 亲戚/n。/w
语义标注:一/m/Eb02 位/q/Di15 当/v/Hj24 中医/n/Dk03 的/u/Ed01 亲戚/n/Ah01。/w/-1
消歧特征的提取过程如图1所示。

图1 消歧特征的提取Fig.1 Extract disambiguation features
从汉语句子中,提取歧义词“中医”左右4个邻接词汇单元,分别为:“位/q/Di15”、“当/v/Hj24”、“的/u/Ed01”和“亲戚/n/Ah01”。词形用W来表示;词性用P来表示;语义类用S来表示。歧义词左侧的2个邻接词汇单元的词形分别用WL1、WL2来表示;右侧的2个邻接词汇单元的词形分别用WR1、WR2来表示。左侧2个邻接词汇单元的词性分别用PL1、PL2来表示;右侧2个邻接词汇单元的词性分别用PR1、PR2来表示。左侧2个邻接词汇单元的语义类分别用SL1、SL2来表示;右侧2个邻接词汇单元的语义类分别用SR1、SR2来表示。从4个邻接词汇单元中,共抽取了12种消歧特征。
在哈尔滨工业大学人工语义标注语料中,每个汉语句子都进行了词汇切分。每个单词都标注了词性。以《同义词词林》为基础,按照上下文信息标注了每个词汇的语义类别。以该人工语义标注语料为基础,统计消歧特征的频率F,如表1所示。

表1 消歧特征的频率Table 1 Frequency of disambiguation features
本文利用词义消歧特征的频率来判别歧义词的真实含义。统计12个消歧特征的频率,F(WL2)、F(PL2)、F(SL2)、F(WL1)、F(PL1)、F(SL1)、F(WR1)、F(PR1)、F(SR1)、F(WR2)、F(PR2)、F(SR2),得到词义消歧特征向量Efeature=(F(WL2),F(PL2),F(SL2),F(WL1),F(PL1),F(SL1),F(WR1),F(PR1),F(SR1),F(WR2),F(PR2),F(SR2))。
2 基本词义消歧模型
歧义词w具有m个语义类sk=k(k=1, 2,…,m)。其消歧特征向量为Efeature。本文使用逻辑回归(logistic regression,LR)模型、梯度提升决策树(gradient boosting decision tree,GBDT)和支持向量机(support vector machine,SVM)来确定歧义词w的语义类别。
2.1 基于逻辑回归模型的词义消歧

(1)
从语义标注语料中,抽取包含歧义词w的汉语句子。从每一个汉语句子中,抽取歧义词w的特征向量。歧义词w的特征向量和标注的语义类别构成二元组。将歧义词w的所有二元组搜集起来形成集合L。利用L来计算交叉熵代价函数J(θk):
(1-u)lb(1-FLR(Efeature))]
(2)
式中:Lk=L,(Efeature,u)∈Lk,u∈{0, 1}。当歧义词w的语义类为sk时,u的值为1;w的语义类不为sk时,u的值为0。

(3)
歧义词w不属于语义类sk的概率:
(4)
逻辑回归词义消歧模型为FLR(Efeature),选择具有最大概率的语义类作为歧义词w的预测语义类别:
(5)
2.2 基于梯度提升决策树的词义消歧

(6)

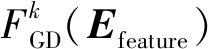
1)初始化梯度提升决策树。
(7)
2)采用向前分布算法,得到第n步的模型:
(8)

(9)
其中,(Efeature,u)∈Lk,u∈{0, 1}。当歧义词w的语义类为sk时,u的值为1;w的语义类不为sk时,u的值为0。Loss为损失函数,采用平方差误差损失函数来进行计算:
(10)
使用softmax函数来计算w属于语义类sk的概率,选择具有最大概率的语义类作为歧义词w的预测语义类别。基于梯度提升决策树的词义消歧模型FGD(Efeature)为:
(11)
2.3 基于支持向量机的词义消歧
对于歧义词w而言,设计m个二类SVM模型FSVM1(Efeature、FSVM2(Efeature)、…、FSVMm(Efeature)来进行消歧。其中,FSVMk(Efeature)用于判别歧义词w是否属于语义类别sk:
(12)
式中:wk为分类超平面的法向量;bk为分类超平面截距;sgn为符号函数。

(13)

使用softmax函数来计算w属于语义类sk的概率,选择具有最大概率的语义类作为歧义词w的预测语义类别。SVM词义消歧模型FSVM(Efeature):
(14)
3 半监督集成词义消歧
分类模型会根据自己学习到的知识来对未标记数据进行预测。本文运用软投票策略来融合FLR(Efeature)、FGD(Efeature)和FSVM(Efeature),获取集成词义消歧模型FEN(Efeature)。在确定歧义词w的语义类别时,不但考虑了少数服从多数的原则,而且考虑了模型对语义类别的概率分布。基于软投票集成的词义消歧过程如下:
输入:歧义词w的特征向量Efeature,
输出:歧义词w的语义类别S。

(15)

(16)

P=(P(sk|w,FLR)+P(sk|w,FGD)+
P(sk|w,FSVM))/3。
(17)
5)集成分类器为:
P(sk|w,FGD)+P(sk|w,FSVM))/3
(18)
选择具有最大概率的语义类作为歧义词w的预测语义类别。
从语义标注语料中,抽取包含歧义词w的汉语句子。从每一个汉语句子中,抽取歧义词w的特征向量。歧义词w的特征向量和标注的语义类别构成二元组。将歧义词w的所有二元组搜集起来形成集合L。从无标注语料中,抽取包含歧义词w的汉语句子。从每一个汉语句子中,抽取歧义词w的特征向量。将歧义词w的所有特征向量搜集起来形成集合U。基于半监督集成学习的词义消歧分类器的训练过程:
输入:语义标注集合L和无语义标注集合U。
输出:词义消歧分类器FEN(Efeature)。

3)L=L∪{(t,FEN(t))},U=U-{t}。
4)若U不为空集,则重复执行步骤1到步骤4);否则,执行步骤5)。
5)输出优化后的词义消歧分类器FEN(Efeature)。
4 实验结果与分析
采用SemEval-2007: Task#5的训练语料和测试语料来度量本文所提出方法的性能。从SemEval-2007: Task#5中,选取28个常用的歧义词。其中,具有2种语义类的歧义词共有16个,分别为“表面”、“菜”、“单位”、“动摇”、“儿女”、“机组”、“镜头”、“开通”、“气息”、“气象”、“使”、“推翻”、“望”、“眼光”、“震惊”、“中医”。具有3种语义类的歧义词共有9个,分别为“补”、“本”、“成立”、“队伍”、“旗帜”、“日子”、“天地”、“挑”、“长城”。具有4种语义类的歧义词共有3个,分别为“吃”、“动”、“叫”。共进行了8组实验来度量本文所提出方法的性能。在这8组实验中,都选择了歧义词左右邻接的4个词汇单元的词形、词性和语义类作为消歧特征。
实验1采用FLR(Efeature)作为词义消歧分类模型。实验2利用FGD(Efeature)进行词义消歧。实验3采用FSVM(Efeature)作为词义消歧分类模型。实验4利用FEN(Efeature)进行词义消歧。使用SemEval-2007: Task#5的训练语料来优化这4组实验的词义消歧模型。实验1到实验4采用有监督学习方法来训练词义消歧分类器。利用优化后的FLR(Efeature)、FGD(Efeature)、FSVM(Efeature)和FEN(Efeature)对SemEval-2007: Task#5的测试语料进行语义分类。
采用SemEval-2007提供的评测指标来进行评测,计算过程为:
(19)
式中:N为所有目标歧义词汇数目;mi是第i个歧义词汇正确分类的测试句子数;ni是包含第i个歧义词的所有测试句子数;pi为第i个歧义词的消歧准确率;pavg为词义消歧的平均准确率。
实验1~4的消歧准确率如表2所示。

表2 实验1~4的消歧准确率Table 2 Disambiguation accuracy from experiment 1~4 %
实验4的消歧平均准确率达到了70.80%,比实验1提高了13.20%,比实验2提高了4.40%,比实验3提高了15.40%。其原因在于:实验4采用软投票对逻辑回归模型、梯度提升决策树和SVM模型进行集成,综合了各种分类模型的优点,取长补短,其消歧效果要比单一分类模型好。
实验5~8利用本文所提出的方法来进行词义消歧。以SemEval-2007: Task#5的训练语料为基础,结合哈尔滨工业大学无标注语料使用本文所提出的方法来优化集成分类器FEN(Efeature)。在训练结束后,获得了优化的集成分类器FEN(Efeature)。同时,也得到了半监督学习下的优化的FLR(Efeature)、FGD(Efeature)和FSVM(Efeature)。实验5利用半监督学习获得的FLR(Efeature)作为词义消歧分类器。实验6使用半监督学习获得的FGD(Efeature)进行词义消歧。实验7利用半监督学习获得的FSVM(Efeature)作为词义消歧分类器。实验8使用半监督学习获得的FEN(Efeature)进行词义消歧。在实验5~8中,分别对SemEval-2007: Task#5的测试语料进行语义分类。实验5~8的消歧准确率如表3所示。
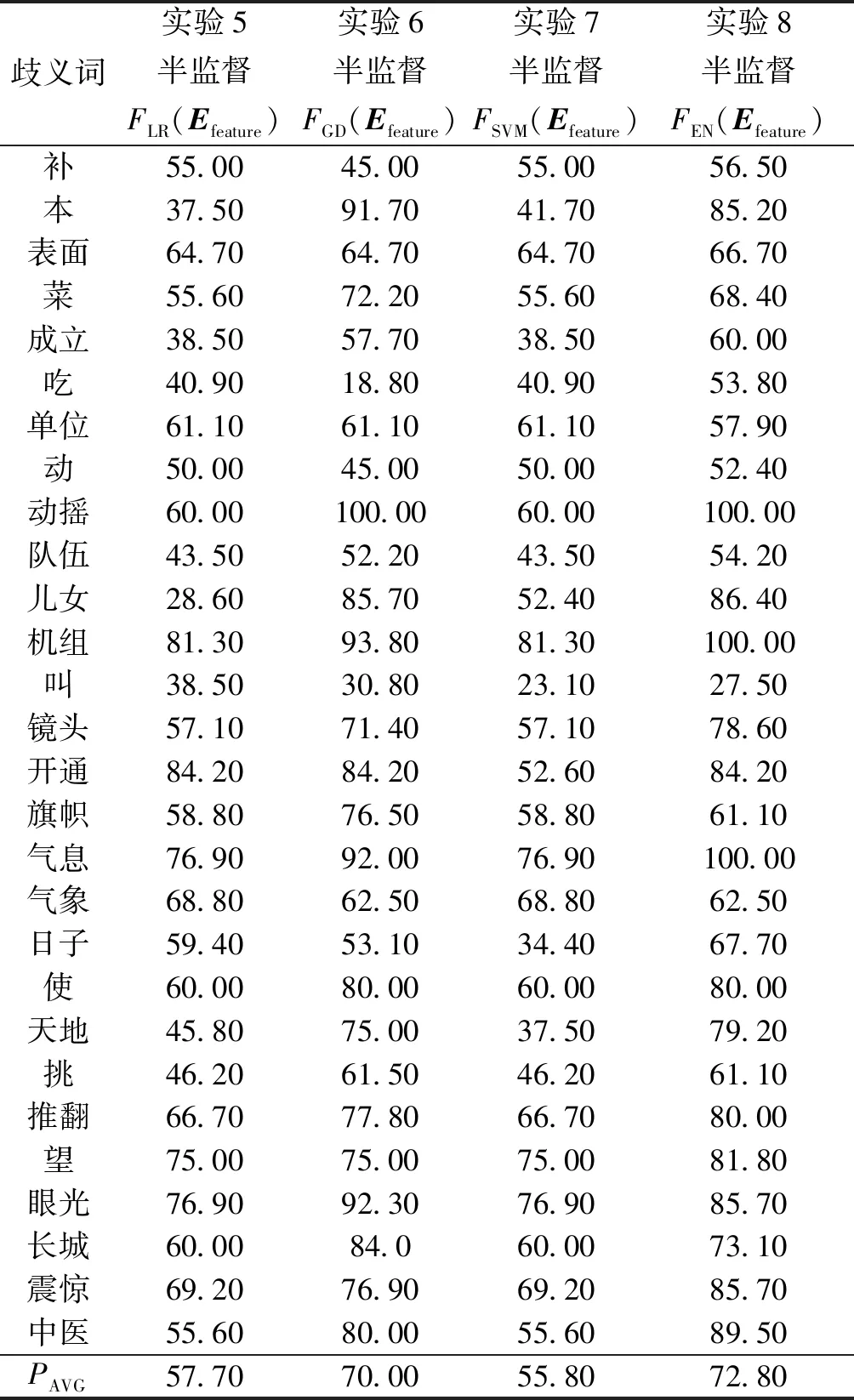
表3 实验5~8的消歧准确率Table 3 Disambiguation accuracy from experiment 5~8 %
对比表2和表3可以看出:实验5的平均消歧准确率比实验1提高了0.10%;实验6的平均消歧准确率比实验2提高了3.60%;实验7的平均消歧准确率比实验3提高了0.40%;实验8的平均消歧准确率比实验4提高了2.0%。其原因为:实验1到实验4是以人工语义标注语料为基础,采用有监督学习方法来优化词义消歧模型。大规模人工标注语料的语义类别是极其困难的,因此,实验1~4所获取的语言学知识将是有限的。实验5~8是以人工语义标注语料为基础,结合大量无标注语料采用半监督学习方法来优化词义消歧模型。大量无标注语料是比较容易获得的,其中蕴含了丰富的语言学知识,能够为词义消歧过程提供指导信息。因此,实验5的平均消歧准确率要高于实验1,实验6的平均消歧准确率要高于实验2,实验7的平均消歧准确率要高于实验3,实验8的平均消歧准确率要高于实验4。
在实验5~8中,分别统计具有2种、3种和4种语义类的词汇的平均消歧准确率,如图2所示。
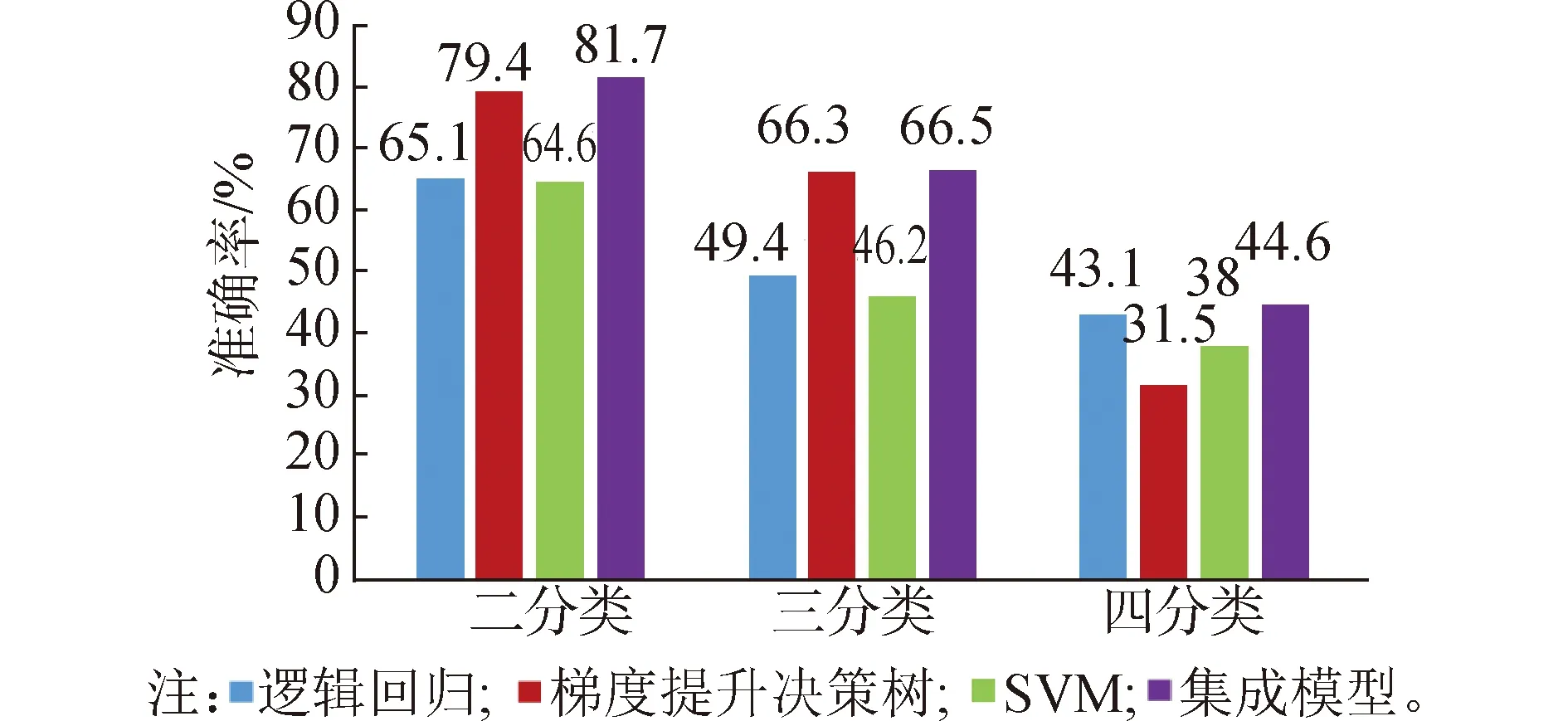
图2 在不同语义类别数下实验5~8的平均消歧准确率Fig.2 Average disambiguation accuracy under different number of sense categories from experiment 5~8
从图2中可以看出:在2种、3种和4种语义类下,FEN(Efeature)的平均消歧准确率要好于FLR(Efeature)、FGD(Efeature)和FSVM(Efeature)。
5 结论
1)本文所提出方法的消歧性能要优于逻辑回归模型、梯度提升决策树和支持向量机,能够更准确地确定歧义词汇的语义类别。
2)根据实验论证能够证明本文提出的方法具有一定的优势,能够更加准确地确定中文歧义词的具体含义,可以应用到中文消歧的实践中。
