政务服务中群众留言答复意见评价模型
2022-05-18李卓轩赵璇曹进德储越
李卓轩 赵璇 曹进德 储越
0 引言
“互联网+”及Web2.0时代的到来,不仅影响着公众的日常生活方式,而且还对政府与民众之间的交互模式带来了一场变革[1].当前,我国地方政府为推动电子政务建设,将互联网技术引入政务服务.为进一步提高公民参与水平及积极性、增强政府回应及时性与透明度,各地政府陆续打造并推出“智慧政务”平台以提高服务效率、增强服务质量.截至2020年6月,我国网民规模达9.40亿,相较上一年度,增加了8 500余万[2].越来越多的民众选择互联网作为其公共诉求、反映现实问题的重要载体[3].因此,政府与民众之间在互联网上的交流互动日益成为人们表达诉求、政府获悉民意的重要方式.
学术界与地方政府重视“智慧政务”和政府与民众在网络环境下的交互行文.习近平总书记曾指出:“各级党政机关和领导干部要学会通过网络走群众路线……了解群众所思所愿,收集好想法好建议,积极回应网民关切、解疑释惑.”[4]2020年1月,江苏省人民政府办公厅积极履行法定主管部门职责,研究制定了《江苏省政府信息公开申请办理答复规范》[5],对答复文本从文本上作规定.然而,至今未有一个全国范围完整、统一的答复评价标准.
鉴于此背景,为答复意见做质量评价对提升政务服务水平具有重要意义,有助于规范答复文本格式,促进答复内容更完整、更全面,也更利于民众理解.同时,对答复文本作分析也有助挖掘如今政务答复普遍存在的问题,促进政务服务优化,构建数字政府,打造“智慧政务”.孙宗锋等[6]以青岛市市长信箱数据为例,进行了网络情境下地方政府政民互动研究分析,探究了其中公民诉求表达与政府回应.姚水琼等[7]针对美国数字政府建设发展过程,研究其构建数据驱动战略体系,分析了我国构建数字政府的切入点.段哲哲等[8]采用德尔菲法建构领导信箱回应绩效指标体系,设计了针对66个政府网站领导信箱的实验,探究了互联网下的政府回应逻辑.王李[9]结合公共服务导向、信息公平公开、信息回复质量等一级指标建立了市长电子信箱回应性评估指标体系.王思迪等[10]运用多层神经网络算法分析市长信箱的文本分类,并对比朴素贝叶斯算法、随机森林算法以及决策树算法,建立了政府网站信箱自动传递方法.
本文利用某市的群众问政留言记录,及相关部门对部分群众留言的答复意见,结合《2020年中国政府网站绩效评估报告》[11]中的内容,总结出5个答复意见特征,设计并定义了特征指标和评价指标,通过回归分析方法对答复意见类型进行分析.采用K-means聚类[12]、DBSCAN聚类算法[13]、Meanshift聚类算法[14]、HC聚类算法[15]4种聚类算法对答复意见等级进行分析,根据4种聚类算法效果对比结果,选用K-means聚类算法和回归分析的结果结合,对答复意见进行评价,将评价等级分为6类.本文通过对群众留言的答复意见数据进行挖掘,建立留言回复的评价模型.本文模型建立了政府答复意见数据与答复意见评价分析的有效关联,具有更高的准确性与科学性.
1 政府答复意见特征提取
本文所利用某市的群众问政留言记录,及相关部门对部分群众留言的答复意见,共2 816条,包括留言编号、留言用户、留言主题、留言时间、留言详情、答复意见、答复时间,具体数据(部分)如表1所示.
本文根据所给数据,设计并提取出以下政府答复意见特征参数.
1.1 答复意见相似性
为描述答复意见与留言的相关程度,即主题的契合程度,要求答复意见描述内容与留言所描述的必须是同样一个事件,引入答复意见相似度概念.相似性用于描述答复与留言的文本相似程度,刻画答复内容的准确度.例如,答复主题与留言主题相去甚远,认为这是相似度低的、不可靠的答复.
留言与回复属于长文本特性,通过TF-IDF算法[16]生成文本向量,依据关键词计算余弦相似度[17],通过式(1)计算文本相似程度:

(1)
留言包括正文、标题,标题在一定程度上反映了留言主题,正文是留言的主要部分.故用留言标题与留言正文分别与答复计算文本进行相似度计算,根据计算公式:
Stotal=Stitle+Scontent
(2)
其中Stitle为留言标题与答复计算文本的相似度,Scontent为留言正文与答复计算文本的相似度,得到最终的相似度数值Stotal.
留言有重述标题的情况存在,如“市民同志:你好!您反映的‘请加快提高民营幼儿园教师的待遇’的来信已收悉.现答复如下:”,之后才是正式的答复,因此,计算相似度时将此类不属于正式答复的内容去掉,否则影响相似度结果.
1.2 答复意见完整性
为提高可读性和可理解性,便于发帖人阅读,答复意见不能是毫无章程的、混乱的,如同书信、网络电子邮件,答复意见应该满足一套格式标准,这个标准使得答复意见清晰可阅.为评价答复文本格式的规范性,建立标准答复格式,引入答复意见完整性概念,完整性用于描述答复文本的规范程度.
如同书信,答复文本格式应该尽可能规范.一般书信的完整格式应该有5个部分,包括称呼、正文、结尾、署名和日期.完整的群众意见答复应有:起首语、问候语、祝颂语、表示已收到市民留言的语句、署名、日期.
综合考虑书信、网络回帖、政务答复特征,建立规范答复格式如图1示.
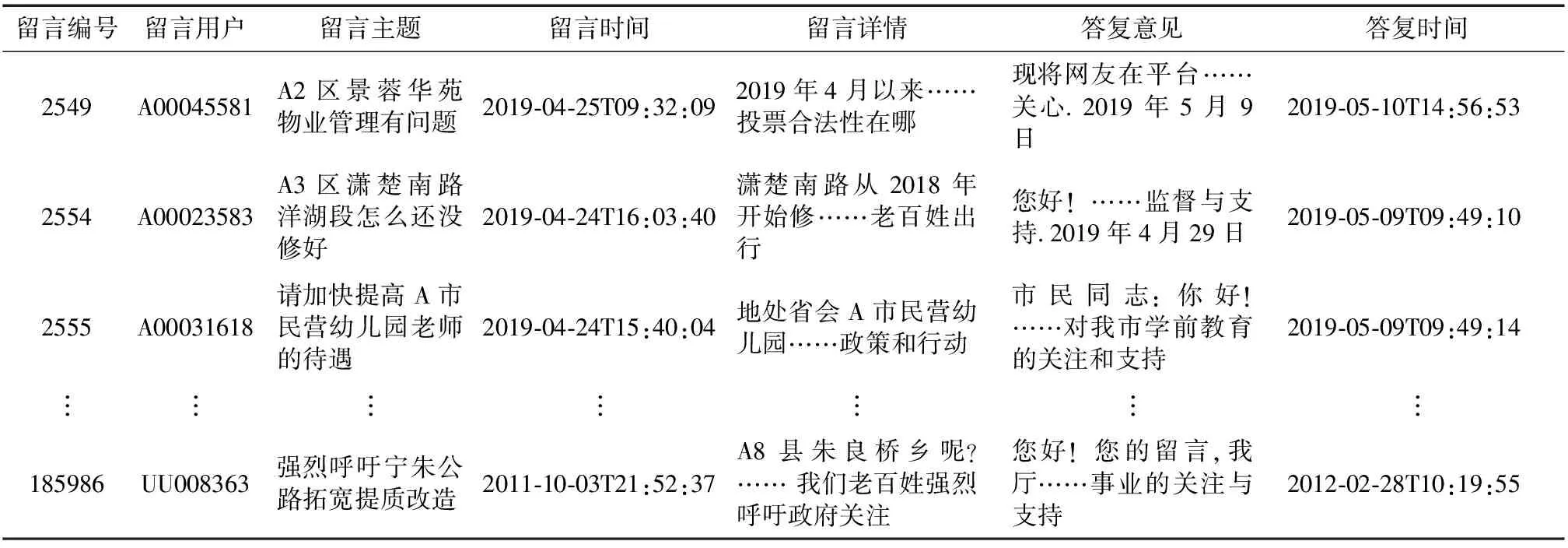
表1 群众留言原始数据

图1 规范答复格式Fig.1 A standardized reply format
答复意见完整性计算流程如下:
1) 计算起首语得分.将疑似起首语与标准起首语语料库比较,计算得到编辑操作次数,取单字符编辑操作次数最小值为n.因起首语语料文本长度均为5,若最小编辑次数大于3,改动过大,即认为不存在起首语,起首语分数置0.当最小编辑次数≤3时,如起首语为“同志”、“网友ASX000”,这是正常的情况,可计算该文本起首语与标准起首语料库相似度分数.起始语分数:
(3)
2) 计算问候语得分.采用疑似问候语句搜索匹配,若存在标准问候语给1分,不存在记为0分.
3) 计算祝颂语得分.疑似祝颂语中若存在“感谢”、“祝愿”等词语,则认为存在祝颂语,给1分,否则记为0分.
4) 计算署名得分.设定署名长度阈值为3,记署名语句长度为l,对疑似署名语句进行长度检查,若长度大于等于署名长度阈值,则给1分.署名分数计算方法如下:
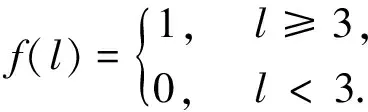
(4)
5) 计算日期得分.针对疑似日期语句,若表达日期则给1分,无则0分.
6) 对表示已收到市民信件,并明确分割出具体答复正文的答复进行评分.以最长公共子序列(Longest Common Subsequence,LCS)算法[18]将疑似语句与“已收到”标准语料库及答复内容作对比,即可得到此项分数:
f(Lmax)=Lmax/Ls,
(5)
其中Lmax为各语料最长子序列长度最大值,Ls为标准语句长度.
7) 计算总分.上述每项评分标准满分1分,总分为6分,进行求和并求得平均分记为该答复完整性分数.
1.3 答复意见可解释性
给出的答复意见必须可信度高、说服力强,在一定程度上符合常理,满足法律条例规范要求,这样的答复意见才能使发帖者信服、使大众满意,才能解决民众问题、满足大众诉求.为此,在评价体系中引入可解释性概念.可解释性用于描述答复的合理程度、说服力度.严密而合理的答复内容,可解释性强,使发帖者信服.
本文对答复意见文本引用法律条文数情况进行了统计分析.答复中引用法律条文的情况有两种情况.第一种情况:用书名号括起文献名称.第二种情况:未出现书名,但引用了法律条例,如 “根据省厅文件精神”、“让学校根据调档函要求将档案寄至人力资源服务中心”.根据政务答复文本书面性较强的特点,引用文献时一般使用如下句式:“根据……规定”、“按照……原则”.构建“根据”的同义语料库,构建“规定”的同义语料库,对答复内容进行匹配,得到文献名序列,即为第二种情况的引用法律条文.两种情况的法律条文序列合并去重统计,即得到引用法律条文数.统计数据中的各答复引用的法律条文数统计如图2所示.
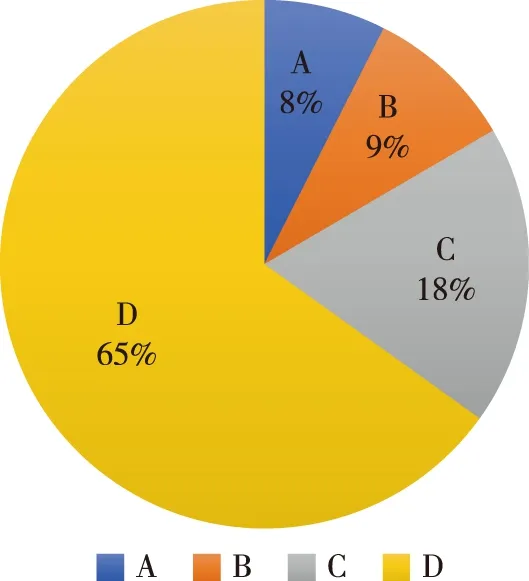
图2 引用法律条文数统计Fig.2 Statistics on the number of legal provisions cited
其中,A类:法律条文数大于等于3部;
B类:法律条文数为2部;
C类:法律条文数为1部;
D类:未引用法律条文.
可知,17%的答复引用了2部及2部以上法律条文,18%的答复引用了1部法律条文,其余65%未引用法律条文.
针对政务服务特点,需要理论支撑或实地调查的情况有:所给信息有错误;所给信息不全导致无法回答;所提出的问题与实际情况不符.以上情况都应给出合理的解释.若无解释则认为此文本可解释性低.答复意见可解释性计算流程如下:
1) 每条答复给基准分0.4分.
2) 根据答复引用法律条文数目分布情况,制定给分规则如下,其中n为引用法律条文数目:
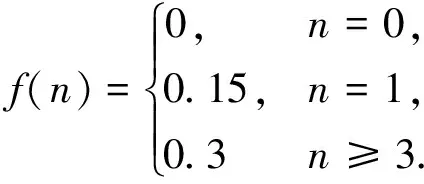
(6)
3) 判断是否存在实地勘察行为,存在实地调查行为,给0.3分,否则此项给0分.
4) 该答复是否无法解决问题,若属于“无法解决发帖者问题”情况,且此时并未识别出理论支撑或给出存在实地调查行为,则认为此答复可解释性低,总分置0.
1.4 答复意见及时性
为及时解决民众问题,满足大众诉求,应在一定时间范围内及时答复发帖者,若拖延时间过长,民众心声得不到回复,则认为这是不好的情况.故在评价体系中引入及时性概念.及时性用于描述答复的时效,若答复时间与发帖时间的时间间隔较小,则认为此答复是及时的,在时间上是优秀的.以小时为单位,统计所有帖子的提问时间与答复时间的间隔时间差(不包括双休日).求时间差最大值tmax、最小值tmin.答复意见及时性评分计算方法如下:
(7)
其中qi是第i条答复意见的及时性评分,ti是第i条答复意见的答复时长,tmax是样本中答复意见的最大答复时长,tmin是样本中答复意见的最小答复时长.
2 群众留言答复意见评价模型
2.1 数据处理
群众留言答复共有约2 816条原始数据,根据上节介绍的提取特征的方法,对原始文本数据的处理结果如表2所示.
2.2 技术路线
首先,提出并详细定义群众留言答复意见的评价指标,包括答复长度、相似性、完整性、可解释性和及时性.答复长度及相似性用于分析答复意见的类型;完整性、可解释性和及时性用于描述答复意见等级.
接着,对答复意见类型进行分析,将答复长度与答复意见相似性作回归分析,回归线的下方为简洁可靠型,上方为繁杂离题型.采用K-means聚类、DBSCAN聚类算法、Meanshift聚类算法、HC聚类算法将答复意见分为3个等级,并进行对比.
最后,将聚类算法和回归分析的结果结合,对答复意见进行评价,将评价等级分为6类,建立起完整的答复意见评价模型.
2.3 答复意见类型的回归分析
答复长度在一定程度上可以与答复相似性产生联系.单从文本长度而言,长文本相似度高的概率大于短文本的相似度,因为内容更丰富、匹配的概率更高.若答复文本短,而相似度高,则此答复是简明扼要的,可靠性高;答复文本长,而相似度低,那么答复是繁杂冗长的,可靠性低.因此,将答复意见风格分为两种,一类是“简洁可靠型”,另一类记为“繁杂离题型”.
回归分析是通过建立模型来研究变量之间相互关系的密切程度、结构状态及进行模型预测的一种有效工具,通常用于定量地分析两个变量之间的相关性[19].因此,本文采用回归估计来定量分析答复长度与答复意见相似度之间的关系,以此判断答复意见类型.其公式为
(8)
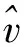

表2 群众留言答复意见特征参数数据(部分)
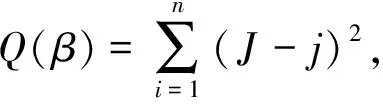
(9)
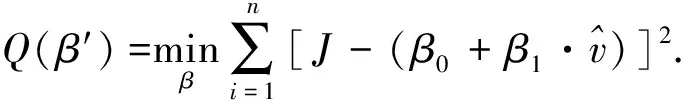
(10)
为了使式(10)得到的结果最小,求解偏微分方程组:
(11)
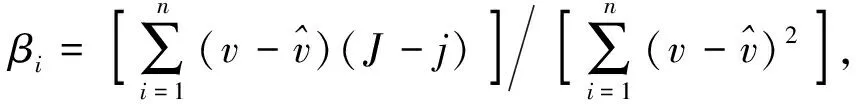
(12)
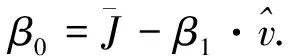
(13)
根据表3中的数据,使用最小二乘法进行分析,得到回归直线,进而得到群众留言答复意见的两种答复类型.
利用表3中的数据,运行结果如图3所示.其中纵截距为0.502,斜率为1.432,即得到的回归直线为
y=1.423x+0.502.
(14)
根据答复意见相似性与文本长度的关系可知,位于回归直线上方的答复意见风格是简洁可靠型,位于回归直线下方的是繁杂离题型.

表3 归一化文本长度和答复意见相似性(部分)
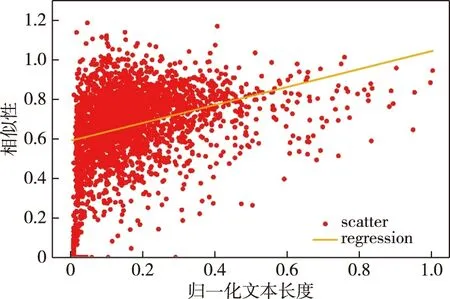
图3 回归分析结果Fig.3 Regression analysis result
2.4 答复意见等级的聚类分析
由于训练样本是无标签的数据,答复意见的等级分类结果未知,且答复意见复杂性很高,如果使用手动标注分类则具有太强的主观性,故选用聚类这种无监督学习的方式来对数据进行分类.本文将答复意见等级分为3类,所以将聚类数目确定为3.
聚类算法的种类有很多,为了确定哪种聚类算法更适合本次研究的数据,采用基于划分的K-means算法进行聚类,并与DBSCAN聚类算法、Meanshift聚类算法、HC聚类算法进行对比.
1) K-means 聚类算法
K-means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.具体算法过程如下:
1) 从N个答复意见特征数据中随机选取K个样本作为初始的聚类中心;
2) 分别计算每个样本到各聚类中心的距离,将对象分配到最近的类簇中;
3) 所有对象分配到所属类簇后,重新计算K个类簇的聚类中心;
4) 与3)中计算得到的K个聚类中心比较,如果聚类中心发生变化,转2),否则转5);
5) 当聚类中心不发生变化时停止计算,并输出聚类结果.
根据表2中提取的答复意见特征,包括答复意见完整性、答复意见可解释性、答复意见及时性,将这3个特征进行K-means聚类分析,得到3个等级,给出的K-means聚类分布如图4所示.其中定义3个等级,等级1、2、3分别对应优良中,则图中蓝色为等级1,绿色为等级2,红色为等级3.
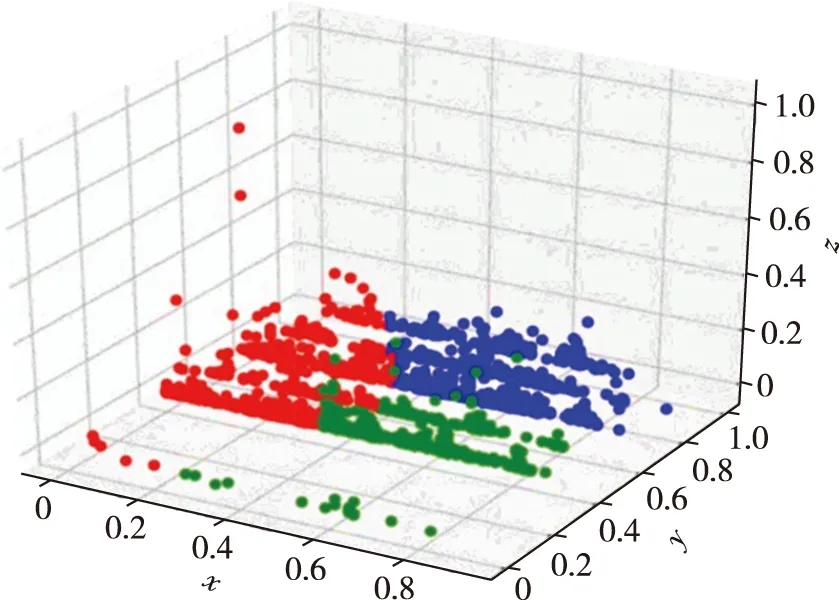
图4 K-means 聚类分析结果Fig.4 K-means clustering analysis result
2) 聚类效果对比
由于无明确的类别指标,所以采用 Calinski-Harabaz 指数和轮廓指数这两种指标来对聚类效果进行评价.
a) Calinski-Harabaz指数
这个评价指标计算简单直接,得到的分数值越大则说明聚类效果越好.其公式如下:
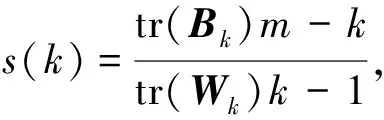
(15)
其中,m为训练样本数,k为类别数,Bk为类别之间的协方差矩阵,Wk为类别内部数据的协方差矩阵,tr(·)为矩阵的迹.换言之,类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数越高.
b) 轮廓系数
轮廓系数(Silhouette Coefficient)适用于实际类别信息未知的情况.对于单个样本,设a是与它同类别中其他样本的平均距离,b是与它距离最近的不同类别中样本的平均距离,则对于这个样本,它的轮廓系数为
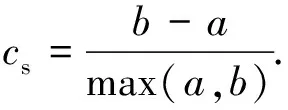
(16)
对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值.轮廓系数的取值范围是[-1,1],同类别样本距离越近且不同类别样本距离越远,轮廓系数的数值越大.对比结果如表4所示.
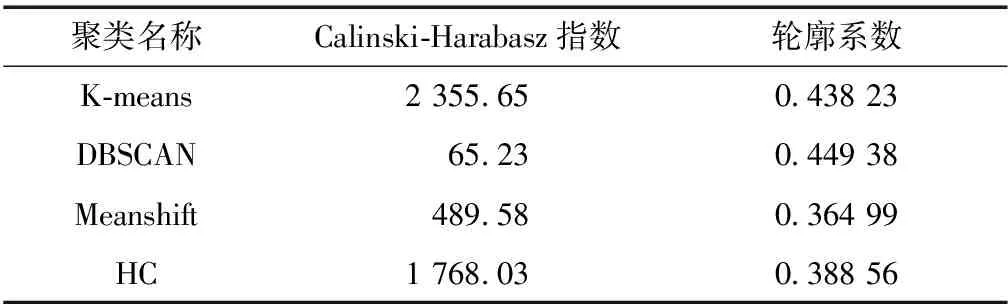
表4 聚类效果评价
从Calinski-Harabasz指数来看,K-means聚类明显大于其余聚类算法,说明其类别内部数据的协方差更小,且类别之间协方差更大,使得答复优良程度的分类更加清晰.另外,从轮廓系数来说,虽然DBCAN算法比K-means算法稍大,但DBSCAN的Calinski-Harabasz指数过低,这算是不理想且不符合预期的.除DBSCAN聚类算法以外,K-means算法的轮廓系数大于其他聚类算法,说明其同类别样本距离更近且不同类别样本距离更远,聚类结果更为准确.因此,由这两个指数的对比可知,对于答复意见,K-means聚类算法较为理想.
2.5 结果分析
综合考虑答复意等级与答复意见类型2个指标,将答复优良等级分为6个等级.如表5所示.

表5 答复意见评价等级
对2 816则答复进行数据预处理,进行答复意见特征提取,再采用回归分析得到答复风格,得到答复风格回归直线.其中:回归直线上的为简洁可靠型,有1 456则,占总文本的52%;回归直线下方的为繁杂离题型,有1 360则,占总文本的48%.
由图5可知,繁杂离题型答复几乎占据了总文本数的一半,政务工作者答复时应尽量简洁凝练,为民众给出较为核心的解决办法.

图5 答复风格统计Fig.5 Reply style statistics
采用K-means算法进行分析,得到答复意见优良程度的3个等级.其中:等级1有答复1 066则,占总答复的37.855%;等级2有答复915则,占总答复的32.493%;等级3有答复833则,占总答复的29.581%.
由图6可知,答复意见等级分布均匀,但仍有近1/3的答复文本是较不规范的,政务工作人员应重视此问题,对答复质量做出改进.
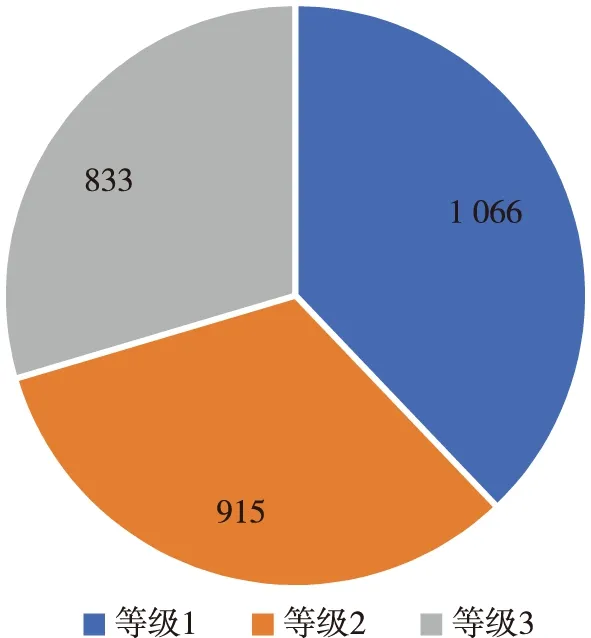
图6 K-means划分等级结果统计Fig.6 Reply grades according to K-means clustering
综合分析以上2个评级指标,分析2 816则答复的优良程度.将“简洁可靠型+等级1”评价为优秀;“简洁可靠型+等级2”评价为较优秀;“简洁可靠型+等级3”评价为良好;“繁杂离题型+等级1”评价为较良好;“繁杂离题型+等级2”评价为较一般;“繁杂离题型+等级3”评价为一般.评价结果如图7所示.
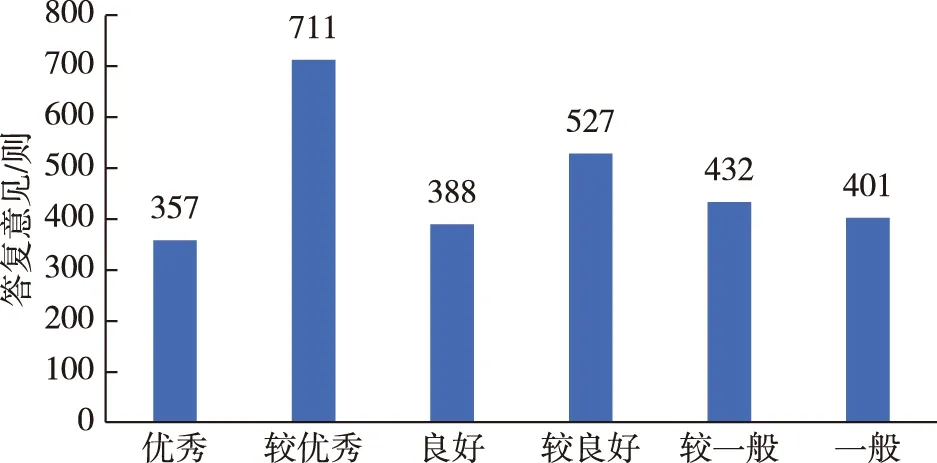
图7 评价结果统计Fig.7 Reply evaluation result
由图7可知:优秀答复有357则,占总文本数12.677%;较优秀答复有711则,占总文本数25.249%;良好答复有388则,占总文本数13.778%;较良好答复有527则,占总文本数18.714%;较一般答复有432则,占总文本数15.34%;一般答复有401则,占总文本数14.24%.综上,可见评价结果是均匀的、良好的,故评价体系是可靠的.政务工作人员应加强对答复质量的重视程度,给出更行之有效、更规范、更优秀的答复意见,完善政务服务工作.
3 结论
本文利用数据挖掘技术提取并量化了群众答复意见的特征参数,并对2 816条群众答复意见,186万字文本数据进行处理,得到能够初步表征群众答复意见的数据.用回归分析分析群众答复意见类型,结合聚类分析对群众答复意见进行等级划分,建立了群众答复意见评价模型.根据模型的评价结果,地方政府可以有针对性地提高政府的服务水平.进一步可以通过分析海量数据,提取出更多有效的群众答复意见特征,从而建立更加实时高效的检测模型,完善评估群众答复意见的完整体系.
