基于U-Net++的人体脊椎MRI图像识别
2022-05-18吴相远蒙玉洪王子民
吴相远, 申 诺, 蒙玉洪, 王子民
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
目前国内外广泛应用的医学图像分割方法有多种,根据分割特点的不同可分为传统的医学图像分割[17-20]和基于深度学习的医学图像分割。对于传统医学图像分割方法,常见的有基于边缘的分割方法、基于区域的分割方法等[1]。但这2类方法仅对图像中对比度较明显的区域有较好的分割效果。
近年来,深度学习在医学图像分割领域大放异彩,基于编码器的医学图像分割中最著名的框架U-Net[2],是在FCN的结构上改进而来。U-Net架构的主要的新颖之处是跳接结构、相等数量的上采样模块以及下采样模块的组合。这使U-Net结构可以有效地考虑整个图像的信息,与基于区块的 CNN相比有一定的优势。此外,Cicek等[3]通过向U-Net反送来自相同体积的几个带有2D注释的切片,实现了完整的3D分割。2016年Milletari等[4]提出了一种V-Net的体系结构,其为U-Net的3D变体,训练过程中将Dice系数作为目标函数,并用3D卷积层对3D医学图像分割。Drozdzal等[5]在常规U-Net中,除了用长跳接之外,还用类似于ResNet的短跳接。加上短跳接结构,不仅可以缓和深层网络的梯度消失,还能增加收敛速度,且得到结果与U-Net结果相似,该方法还可以训练更深的网络。Brosch等[6]使用了另一个类似U-Net的体系结构,使用了3D卷积并在第一个卷积层与最后一个反卷积层之间的单个跳接,在脑MRI中分割病变白质很有效果。Zhou等[7]对U-Net中使用的长连接进行重排,该网络将传统的U-Net结构进行剪枝和叠加,可以提取不同层次的特征,并通过级联的方式整合不同层次的特征。2019年Gu等[8]提出一种用膨胀卷积块来保存上下文信息的网络CENet。与U-Net相比,CENet用密集膨胀卷积块和多核残差池化层集成来修改 U-Net结构,并在特征编码器中采用了预训练好的残差模块,以捕获更高层的特征并保留更多的空间信息。Wang等[9]使用的架构与U-Net类似,但不使用跳接结构,以减少网络参数量,提高分割效率。
目标检测在医学手术目标定位上取得了显著成功,基于深度学习[15-16]的目标检测方法最著名的是YOLO算法。Redmon等[10]提出了YOLOv1算法,将图像分割成S×S个网格,基于每个网格对应的包围框直接预测类别概率和回归位置信息。Liu等[11]提出SSD算法,借鉴YOLO算法的思想,并利用多尺度特征图进行预测。2017年,Redmon等[12]提出YOLOv2算法,用DarkNet-19对YOLOv1的网络结构进行了修改。2018年,Redmon等[13]提出YOLOv3算法,改进之处是:YOLOv3借鉴FPN结构进行了多尺度预测,借鉴ResNet[14]网络结构将DarkNet-19改进为DarkNet-53。
1 人体脊椎椎骨分割
图像分割是把原图像分割成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术,更确切地讲是对图像的每个像素进行分类或聚类。图像分割是医学图像处理领域常见的需求,自动化的图像分割能够帮助医生确定诊断对象的形状、大小,定量评价治疗前后的变化。传统的图像分割算法主要有基于边缘的分割方法、基于灰度阈值的分割方法、基于区域的分割方法、基于图论的方法和基于特定理论的分割方法[1,17-20]。近年来,深度学习的大繁荣泛及到图像分割方面,全卷积神经网络[21](FCN)是深度神经网络对于图像分割的第一个成功应用。FCN先用若干卷积层对输入图像进行特征提取,再接上若干采样层和卷积层,最后输出的特征图即为分割结果,实现了对图像端到端的高效分割。
1.1 U-Net++
U-Nnet是常用于生物医学图像分割的经典网络,它代表着U型结构在医学图像分割上的成功,在小数据集上也表现良好。U-Net++[18]是基于U-Net的改进模型,是一种巢状结构的密集连接网络,在训练时可选择在L1、L2、L3和L4都加一个输出卷积层,使网络成为一个单输入四输出的网络。U-Net++结构如图1所示。
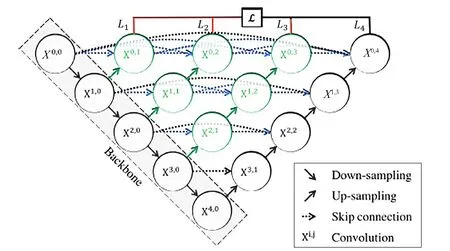
图1 U-Net++结构
1.2 数据准备和训练
使用的原始数据来自桂林市人民医院,用PhotoShop对其中6张进行标注后得到对应的6张椎骨图像。由于标注成本大,得到的训练数据不多,因此先对数据进行了合理的增强,所用的方法包括左右翻转、上下翻转、适当弹性变换、适当位移和放缩。以上操作是对训练集中的输入图像和标签图像同节奏进行的,增强后得到180张图像作为训练集。数据增强完毕后,将这些训练数据按照9∶1划分成训练集和验证集,并另备一份测试集。
本分割任务是要将椎骨部分准确分割下来,其他部分忽略,因此是一个针对像素的二分类问题,采用0.5倍的二值交叉熵L(a,y)减去Dice系数∝作为损失函数L,即
L=0.5L(a,y)- ∝。
(1)
二值交叉熵常用于二分类问题,可反映预测概率的分布与真实概率分布之间的相似程度,其表达式为
L(a,y)=-[ylna+(1-y)ln(1-a)],
(2)
其中:a为预测值;y为真实值。Dice系数是一种集合相似度度量函数,其也能反映模板图像与分割样本图像的相似度,是另一种流行的用于图像分割的损失函数,该度量值在[0,1]区间,其中值为1表示2个样本完全重叠。计算式为
(3)
U-Net++的训练分为深监督和无深监督2种,如图2和图3所示,前者在X0,1、X0,2、X0,3、X0,4后都分别接一个卷积核为1×1的卷积,并将其作为输出层,训练期间分别计算各自的损失并各自反向传播梯度;后者是仅在X0,4后接一个卷积层,并将其作为输出。

图2 深监督下的训练框图

图3 无深监督下的训练框图
1.3 训练结果
用Adam优化器先对无深监督下(no DS)的网络进行训练,然后在有深监督(DS)情况下进行训练。
由图4的训练过程中的损失变化可见,采用深监督时模型收敛得更好,网络中密集的跳级连接既能使梯度传播得完整,也能将相对底层的特征和高层的特征融合,4个梯度可以通过各自路径反向传播,高效调节了各层神经元的权重,而不用深监督时只有一个梯度在网络中起作用,且传播到浅层时已经很微小了。对36张验证图像测量的指标有Dice系数、IOU、正确率和二值交叉熵,其中正确率是针对每个像素的分类正确率,IOU度量2个区域的重合长度(值介于0到1之间),这里用于衡量分割结果和标签图像的重合程度,其计算式为

图4 深监督训练100epochs后验证集的各项指标
(4)
U-Net++是一种结构灵活的网络,训练期间可以用深监督使得L1、L2、L3和L4都趋于真实值,训练完成后,对比四者的效果。由图4可知,使用深监督的情况下,针对脊椎图像集的训练得到L3和L4的综合效果在验证集上最好且相差无几,L2次之,L1最差。最理想的情况是L1得到了与L4同等的效果,不过这几乎是不可能的。基于此,在使用模型时可将仅属于L4的部分去掉,用L3即可。这个实验说明,针对本文的图像分割数据集,用具有4层卷积层的BackBone即可达到很好的效果,而不用一味追求“深度”。这样的好处是使网络规模更小,模型参数从L4的900多万下降到L3的200多万,这意味着分割速度更快,甚至可高效应用于嵌入式设备。在测试集上进行测试,得到的分割结果如图5所示,L3与L4的结果非常接近,这进一步说明模型可剪枝。

图5 模型的使用阶段(L3)
2 人体脊椎间盘检测
2.1 任务方案分析
一般地,医生除了询问病人病情外,还通过观察人体脊椎MRI图像中各椎间盘部分来更进一步分析确认是否有病变及哪个部位病变,也就是目标检测。目标检测是计算机视觉领域的核心问题之一,旨在找出图像中所有感兴趣的目标,确定它们的位置和类别。由于各类物体有难以处理的类内差距和类间相似,如相同或不同的外观、形状、姿态等,加上成像时光照、遮挡等因素的干扰,使得目标检测长久以来是计算机视觉领域最具有挑战性的问题之一。近年来,基于深度学习的方法在目标检测上取得了巨大进步。这就为椎间盘检测带来了解决方案,即采用深度卷积网络对脊椎MRI图像进行端到端的检测。
2.2 YOLOv3目标检测模型
YOLO[10]是一系列先进的One-State目标检测模型,它的v1、v2和v3版本的基本思想都是将整张图像作为网络的输入,直接回归出目标的边界框(BoundingBox)及其所属的类别。在训练时网络的输出张量和输入图像有形式上的对应,即输出张量分为多少个Cell,相应地会把输入图像隐式地分为多少个网格(实际上未对图像进行任何分块,YOLO是用整个图像信息进行检测),使得训练后某个Cell会对中心坐标落在这个Cell对应的输入图像中某个网格上的目标具有最好的响应。YOLOv3[13]针对先前的1、2版本做了改进,使用一个包含众多残差块的Darnet53特征提取骨干网(BackBone),整个检测模型融合了目标检测领域的众多优点,包括锚方案、粗细粒度特征融合和多尺度预测。
2.2.1 网络的结构
YOLOv3网络(图6)主要基于骨干网络Darknet-53,是一个有75个卷积层的全卷积网络,主要组成单元包括以下几个模块:
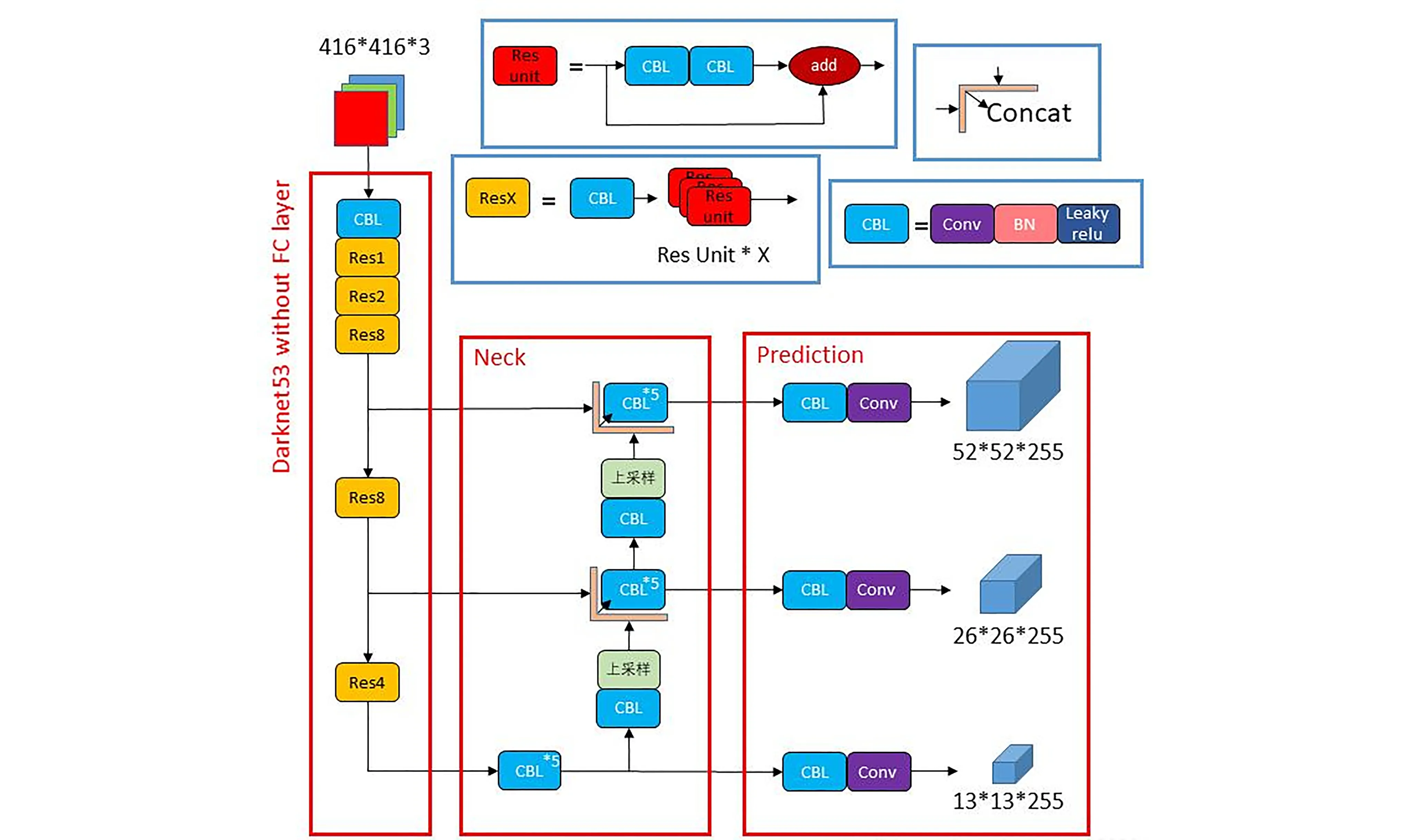
图6 YOLOv3结构
1)DBL模块,主要包括卷积、批规范化以及LeakyReLU激活函数,未用任何形式的池化,网络的下采样全由卷积步幅控制,这可以避免池化引起的细粒度特征损失。
2)Upsample模块,利用上采样可以提供高层部分更多的细粒度特征。
3)Res模块,有效减少了梯度消失的影响,使训练更深的网络成为可能。
4)Route模块,将图像进行拼接,扩充张量第三维度。
YOLOv3全程将BN作为加速收敛、正则化和避免过拟合的手段,将BN和LeakyReLU接到每一卷积层后三者合成的模块作为标准单元使用。LeakyReLU函数是对ReLU的改进,避免对小于0的输入全部抑制,其表达式为
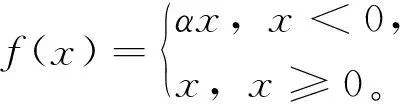
(5)
2.2.2 网络的输入和输出
YOLOv3在训练阶段接收416×416×3的图像,经过骨干网并路由到不同的支路后得到一组尺寸为13×13的特征图y1,一组尺寸为26×26的特征图y2和一组尺寸为52×52的特征图y3,如图7所示。这3个不同尺寸的特征图体现了多尺度预测的特点——适应输入图像中不同尺寸的目标。y1尺寸最小,卷积过程中经过了32倍下采样,具有最大的感受野,适合检测图像中尺寸较大的目标;y2经过了16倍下采样,适合检测图像中的中等尺寸目标;y3则经过了8倍下采样,具有较小的感受野,适合检测图像中较小尺寸的目标。YOLOv3在每个Cell上做3个预测,每个预测包含一个bounding box(tx,ty,tw,wh),一个confidence和一组类别概率(class_probs)。其中:(tx,ty)是相对于单元格的归一化目标中心坐标,(tw,th)是相对于单元格归一化边界框尺寸;Lcon代表了所预测的box中含有object的概率和这个box预测的准确性这两重信息,其计算式为
Lcon=Pr(object)×IOU。
(6)
网络共产生(13×13+26×26+52×52)×3=10 647个预测,这是一个很大的数字,后期会经过score阈值和非极大抑制进行筛选,绝大部分无效预测会被去掉。

图7 YOLOv3修剪后的输入输出
2.2.3 损失函数
YOLOv3模型的输出包含多层信息,设计一个合理的损失函数至关重要,这决定了反馈信号是否能以更有效的形式往正确的方向调整网络的巨量参数。YOLOv3损失函数由3部分组成:预测框位置的误差;框的自信度误差;类别误差。其中,每个组成部分对整体贡献度的误差不同,需要乘上一个权重进行调和。相对来说,目标检测的任务主要是位置误差,故位置误差的权重一般为0.5。
2.2.4 小结
人体脊椎MRI图像是高度规范化的图像,其灰度分布比较有规则,如果仅考虑椎间盘突出这个病症,那么椎间盘检测是一个目标稀疏、目标尺寸单一且目标种类极少的轻量级检测问题,因此有必要对模型做适当剪裁,改造成一个比较小型的,更适合于本任务的椎间盘检测模型。于是对YOLOv3原型除去了一部分残差块和y1、y3两个子检测器。
2.3 训练和测试
使用的原始数据来自桂林市人民医院,包含470张人体脊椎MRI图像。首先使用图像标注工具LabelImg进行图像标注,将图像中能够判断椎间盘突出还是正常的部分标注下来,标注块的坐标信息和类别信息保存在XML文件中。针对椎间盘检测将目标分为对立的两类,即正常和椎间盘突出。标注完成后按9∶1分成训练集和测试集,在训练集中按9∶1分成训练集和测试集。现有的MRI图像是灰度图像,而YOLOv3要求输入的是RGB图像,将每张MRI图像在第三维度上进行2次堆叠,变成特殊的RGB图像,目的是为了训练前在HSV颜色空间上进行数据增强。分别对YOLOv3原型和修剪后的模型在数据增强后共3 800个训练样本上训练。模型训练情况如表1所示。YOLOv3原型和修剪后模型的训练损失如图8所示。

表1 模型训练情况(在Quadro M4000图形处理器上)
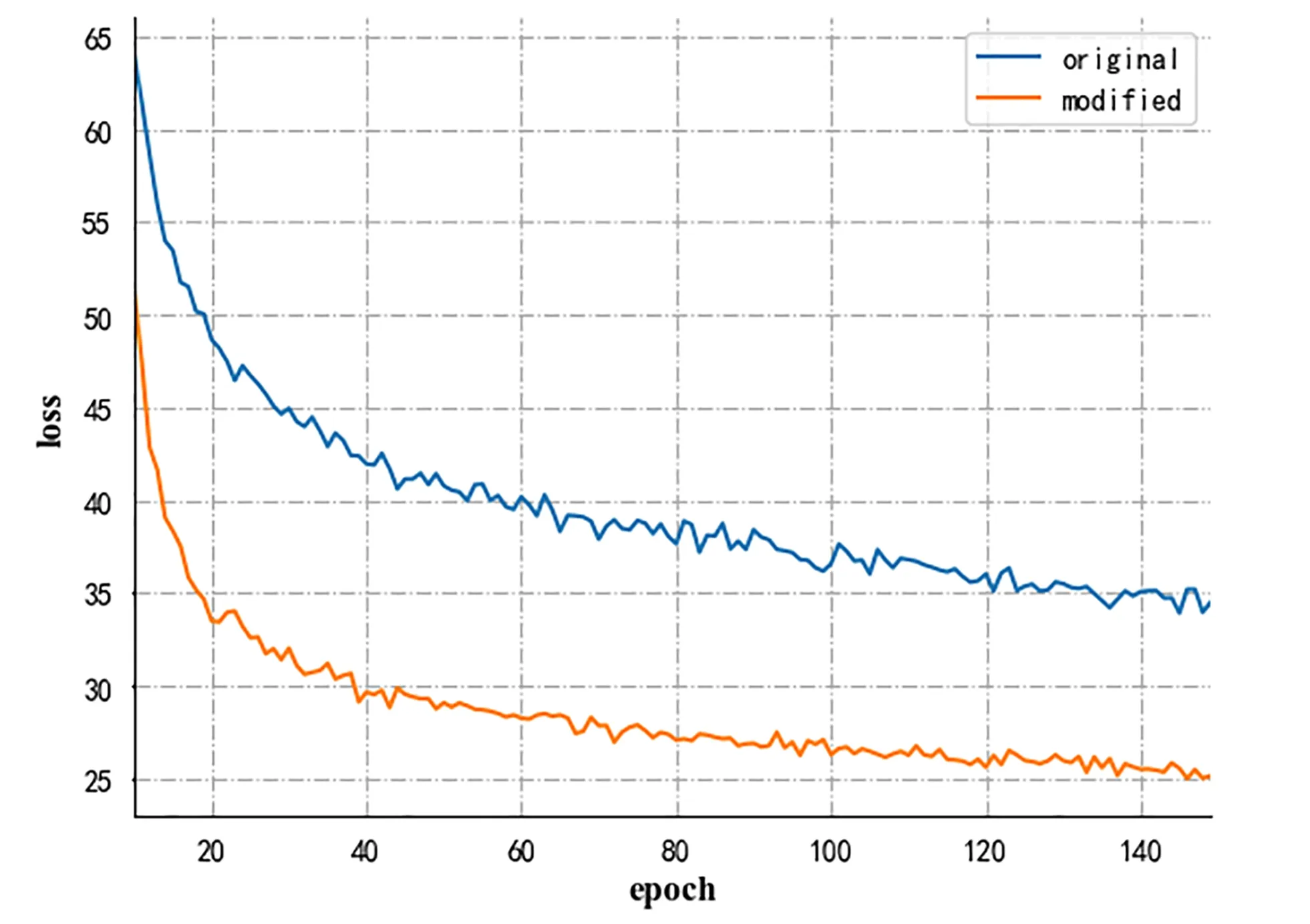
图8 YOLOv3原型和修剪后模型的训练损失
从图8可看出,修剪后的模型比原型收敛更好。分别用YOLOv3原型和修剪后模型对图像进行测试,两者都能正确地定位椎间盘位置,且给出了各个椎间盘正常与否的识别结果。网络的深度取决于特征的复杂度,人体脊椎图像的椎间盘突出特征较简单,用一个较浅的卷积网络即可。
对模型的输出特征图进行可视化分析(特征图皆经过颜色映射处理)。修剪后模型的最后层输出32×32×(7×3)的特征图,图中荧光效果越好,说明该响应值越大。观察输入图像和输出特征图的关系,可见图像中椎间盘落在哪个图像网格,特征图中哪个对应的Cell就负责预测这个椎间盘——这符合YOLO的基本思想。从特征图的第5列可看出,3个anchor对应的confidence特征图的明暗分布有致,说明只在有椎间盘的部位才有大的confidence值。
对比图6 YOLOv3原型的conv2d_67和conv2d_75两个卷积层的输出(y2、y3),可以看到它们非常相似,这是因为脊椎图像的目标尺寸都比较接近,使得K均值生成9个anchor中有相当部分的值很接近,由此产生了检测冗余,即在图像的同一部位进行了多次结果非常接近的检测,这会给后阶段的非极大抑制环节带来更大负担。对47张图像的测试结果指标如表2所示。

表2 对47张图像的测试结果指标
3 结束语
本研究将深度卷积网络应用于人体脊椎MRI图像分割和椎间盘突出检测,并取得了良好的效果,表明深度卷积网络具有优秀的特征自适应能力和特征表达能力,可以使用大量只经过少量预处理的图像数据进行全局端到端训练,从而自动学习到图像中针对任务稳健的特征,这类特征不受位置、光照等类内差异的影响,同时对类间差异敏感。所用的卷积网络从监督数据中学到了稳健的从底层到抽象的椎骨特征和椎间盘特征,学习到了原始脊椎图像和椎骨分割图像和椎间盘突出与否之间的一般规律,能够胜任分割和检测任务。
