大中型煤炭企业信用风险评估体系研究
2022-05-16宋思远王洛锋张新生暴子旗
宋思远,王洛锋,张新生,暴子旗
(1.西安建筑科技大学资源工程学院,陕西 西安 710055; 2.洛阳栾川钼业集团股份有限公司,河南 洛阳 471500; 3.西安建筑科技大学管理学院,陕西 西安 710055)
0 引 言
目前煤炭仍然是中国的主体能源[1],近年来,全球煤炭产量呈现震荡走势,2017—2019年全球煤炭产量保持连续增长,2020年受新冠肺炎疫情影响,全球煤炭产量增势未能延续,导致需求下滑、产量下降、国际煤炭贸易萎缩,煤炭价格在上半年大幅下降,且煤炭销售价格易受到煤炭市场价波动影响,从而易出现产业亏损等问题。在这种情况下,煤炭企业如何在金融市场上进行有效的融资成为其发展的原动力,而能否有效融资与企业自身的信用风险密切相关,信用风险是借款人因各种原因未能及时、足额偿还债务或银行贷款而违约的可能性,其高低直接决定了融资力度的强弱。大中型煤炭企业不同于小微企业,其风险特点和表现形式均不同,具体表现为宏观市场经济关联度高、隐蔽性较高、风险损失大等,因此大中型煤炭企业一旦出现经营状况,对于银行、投资者以及企业本身来说都损失巨大。
随着人工智能、大数据技术不断深入各行各业,对企业进行信用风险的标准化评估显得尤为重要,信用评价是一个开放式评价过程,指标的选择往往决定评价结果的准确性,因此信用风险评价分为指标体系建立与指标筛选两个方面。在指标体系建立方面,业界流行的“5C原则”[2]是企业信用评价指标体系的主要标准之一,“5C原则”通过资本(capital)、品德(character)、担保(collateral)、能力(capacity)、环境(condition)五个方面对借款人如期偿还本息的意愿和能力进行评价。在煤炭企业的信用风险评估方面,张涛等[3]使用签约合同金额履约率作为评价指标来构建风险预警指标体系;唐海伟[4]选取矿产资源储量、生产能力、产品方案、采选技术指标和生产成本作为评估参数;HUANG等[5]通过供应链、行业状况、企业创新能力、盈利能力、偿债能力和宏观经济环境等建立了企业信用评级体系;林军[6]从矿产资源型企业风险入手,从宏观环境风险、行业市场风险、勘查风险、开采风险、经营风险、资源枯竭风险等六大方面进行模型构建。在指标筛选方面,HUI等[7]利用T检验方法降低指标体系信息冗余度,使用Logistic回归方法与多目标规划模型构建评分模型;孟斌等[8]采用方差齐性检验和R聚类对指标进行筛选,建立能显著区分违约状态与否的债信评级指标体系;林宇等[9]使用偏相关分析以及Twin-SVR模型构建信用风险预测模型;LABORDA等[10]分别使用Filter和两种Wrapper方法降低信用风险评估中出现的维数灾难问题,实验表明前向搜索方法在使用的分类器性能中表现最佳;ELSSIED等[11]针对特征空间数据维数高等问题,基于单项方差分析F检验进行特征选择。
综上所述,现有研究在上市企业的信用风险评价方面已经取得了一定的进展,但也存在两个问题:一是大部分指标体系仍是遵循着金融类企业的指标体系原则所建立,不能很好地表现煤炭企业的特点;二是在指标的筛选上,现有方法存在删除变量过多、不能很好预测违约状态等问题。基于此,首先在通用指标选择上结合煤炭企业风险因素提出两个新指标:抗风险能力、煤炭及加工产品业务销售毛利率,然后构建Filter-Wrapper两阶段特征选择算法对信用风险指标体系进行筛选并预测,建立大中型煤炭企业信用风险评估模型。
1 信用风险评价指标体系建立方法
1.1 指标体系建立
通过广泛梳理国内外经典文献,基于业界普遍认可“5C原则”,在大部分企业构建的信用风险要素的基础上,多方面考虑大中型煤炭企业的风险特点,最终从煤炭企业外部环境、企业财富创造能力、偿债来源三大类别进行分析。一方面,针对现有煤炭企业指标体系较少涉及信用风险因素的问题,提出了两个新指标:抗风险能力、煤炭及加工产品业务销售毛利率,以适用于大中型煤炭企业;另一方面,全面将定性指标与定量指标相结合,使指标体系更加完整。基于此,选择煤炭企业外部环境等3个一级指标,行业风险、企业状况等6个二级指标,抗风险能力、司法诉讼等22个三级指标开展评价,建立如图1所示的大中型煤炭企业信用风险评价指标体系。
1.1.1 抗风险能力(ARA)
为了对煤炭行业经济进行整体把握,同时可以分析煤炭行业变动状况,并反应煤炭企业的抗风险能力,在此引入了煤炭行业景气指数与企业的净利润增长率。
行业景气指数又称为景气度,它是对企业景气调查中的各种指标进行加权编制,综合反映某一特定调查群体或某一社会经济现象所处的状态或发展趋势的指标;净利润增长率是一个企业经营的最终成果,净利润增长率的多少代表着企业经营效益的优劣,它是衡量一个企业经营效益的主要指标。由此,通过式(1)可得出抗风险能力指标。
ARAi=

(1)
式中:ARAi为企业第i年抗风险能力;Ni为第i年净利润;Ni-1为第i-1年净利润;CPi为第i年煤炭行业景气指数;CPi-1为第i-1年煤炭行业景气指数。
抗风险能力表示煤炭企业在每年行业景气变化情况下稳定和发展的能力,是评判企业信用风险的重要指标。
1.1.2 煤炭及加工产品业务销售毛利率(CPPM)
大中型煤炭企业大多以煤炭开采及加工产品为主营业务,主营业务销售毛利率反映了主营业务的获利能力,也体现了企业的财富创造能力,而利润率却不能完全体现企业的生产经营状况,因此考虑将煤炭及加工产品业务销售毛利率作为企业财富创造能力的指标,计算见式(2)。

(2)
式中:CPPMi为企业第i年煤炭及加工产品业务销售毛利率;CPPRi为第i年煤炭及加工产品业务收入;CPPCi为第i年煤炭及加工产品业务成本。
煤炭及加工产品业务销售毛利率体现了大中型煤炭企业的财富创造能力,获利能力强弱与信用风险有着直接的关系。
1.2 两阶段特征选择方法
1.2.1 特征选择方法框架
构建大中型煤炭企业信用风险评价模型的最大挑战是判断哪些指标与违约状态密切相关,不相关或冗余的数据特征都可能使得评价模型出现判断失误等情况。当数据空间随着维度或特征数量的增长而以非常快的速度增长时,就会出现维数灾难。休斯现象指出,在同等条件下,分类器或回归器的预测能力随着特征数量的增加而增加,但在数量达到临界点后下降[12]。多特征的模型往往很复杂,复杂的模型也需要更多的时间来拟合数据,易造成过拟合。因此在数据量相对较小的情况下,可以通过减少特征数量来缓解这种情况,主要包括Filter、Wrapper、Embedded三种方法。
本文采用的是结合Filter方法与Wrapper方法的两阶段特征选择方法,首先以Filter法——假设检验的算法(互信息和方差齐性检验)完成特征变量的预筛选,筛选出对违约样本与非违约样本的非显著性特征,从而降低数据维度,保证后续Wrapper方法运算量能够控制在合理的程度;然后在Wrapper阶段,结合使用序列前向选择算法(sequential forward selection,SFS)进行特征最优子集的搜索,进一步筛选变量。算法流程图如图2所示。

图2 两阶段特征选择算法流程Fig.2 Two-stage feature selection algorithm flow
1.2.2 阶段一:Filter方法
Filter方法也称为过滤式方法,一般依据评价准则来增强特征与类的相关性,弱化特征之间的相关性。特征属性分为两种类型:连续性和离散型,而目标属性为离散型。根据属性类型的不同,可以分为两种情况:①X和Y都是离散型属性;②X是连续型属性,Y是离散型属性。针对以上情况,使用互信息和F检验来实现,互信息主要用于筛选离散值属性,方差分析用于筛选连续型属性。
1) 针对X和Y都是离散型的情况,通过互信息检验X和Y的独立性,评价自变量对因变量的相关性。互信息是衡量不同变量之间相关性的有效标准,描述两个变量之间的共享信息。设X有s种可能取值,x为随机变量X的具体取值,Y有t种可能取值,则Pi=P(X=xi)(i=1…s),p(x,y)为X和Y的联合分布,通过互信息式(3)计算得出每个变量与Y之间的互信息。
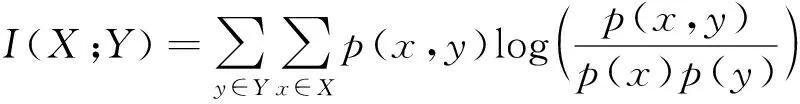
(3)
由互信息的定义得知,当随机变量X和Y没有共享信息时,互信息为最小值0;当随机变量X和Y间的共享信息越多或者说两变量依赖程度越强,他们之间互信息的值越大。通过设置阈值来筛掉互信息值较小的特征。
2) 针对连续型属性特征进行F检验,F检验又称为ANOVA、方差齐性检验,是用来捕捉标签与每个特征之间线性关系的过滤方法,通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。F检验的计算如下所述。
令X={x1,x2,…,xn}和Y={y1,y2,…,yn}为两个服从正态分布的独立时间序列,则有两个序列的均值表示为式(4)。

(4)
两个序列的方差为式(5)和式(6)。

(5)
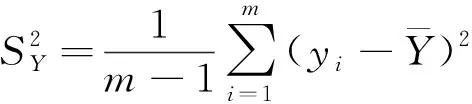
(6)
由此可计算出F(n-1,m-1),见式(7)。
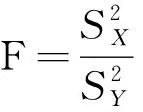
(7)
F检验会返回F值与P值两个统计量,在进行F检验时,可以根据样本的某个特征的F值判断特征对预测类别的帮助,F值越大,预测能力也就越强,相关性就越大。而P值是结果可信水平的一个递减指标,样本中变量的关联可以认为是总体中个变量关联的可靠指标,P值越小,特征的预测能力就越强。
1.2.3 阶段二:Wrapper方法
Wrapper方法也称为包裹式方法,其评价的策略是使用后续学习算法的分类性能来评价特征子集的优势,该方法需要回归器或分类器来进行特征选择,尝试不同的特征组合,并通过在验证集上测试模型来对每个子集进行评分。
阶段一的Filter方法虽然能够过滤数据集中无关的特征,但无法去除一些冗余特征,因此本阶段利用Filter阶段所选出的共有特征子集作为Wrapper阶段的原始特征子集,采用序列前向选择进一步对特征进行过滤,并以AUC值作为衡量指标构建特征评价值,以RF(random forest)作为分类器检测分类的效果,从而获得最终特征子集。SFS选择步骤如所述。
Step1:根据评估标准,选择返回最佳性能的特征作为初始特征。
Step2:将初始特征与剩余所有特征进行双特征组合,选择最佳性能的一对。
Step3:通过前向选择继续添加新的特征,并选择最佳性能的组合。
Step4:到达设定特征个数条件即停止,输出所选择的特征组合。
2 大中型煤炭企业实证研究
2.1 数据来源与样本处理
2.1.1 数据来源
考虑到数据的可获取性、真实性和有效性,选取的相关财务数据来自于Choice金融终端,非财务数据来自于天眼查与中国执行信息公开网。其中,选取38家煤炭行业上市公司2000—2018年的相关数据对大中型煤炭企业信用风险进行实证研究,数据中违约是指公司被沪深证券交易所标记为ST(special treatment)的情况,未被标记的则认定为非违约。
由于ST状态是指上市公司经审计两个会计年度出现财务状况或其他异常状况,导致其股票存在上市风险,从而在下一年实行风险警示。因此以在t年某公司被标记为ST为例,意味着公司在t-1年、t-2年连续两年亏损,若是以这两年的x来预测t年的违约风险变量y,则不符合实际预测情形,不具有说服力和时效性。因此,当构建样本过程中出现此种情形时,以t-3年的x来预测t年的ST状态。
2.1.2 样本处理
1) 违约样本的选取。由于单个年份的煤炭类上市公司违约样本数量太少,不利于建模,为了充分利用每一年的违约样本,本文包括了煤炭企业从2000—2020年所有被标记为ST的年份,共选取了40个被标记为ST的违约样本,并使用t-3年的数据进行预测。
2) 非违约样本的选取。选取2000—2020年未被标为ST的年份作为非违约样本,由于违约状态的年份均为2018年以前,则对于非违约样本也采用2018年之前的指标数据进行建模。
3) 样本预处理。首先将违约样本与非违约样本合并为一个数据集,然后对数据完整度低于90%的年份进行删除,由于煤炭企业信用风险指标量纲不统一,最后进行指标数据归一化。
正向指标是指数值越大、企业经营状况越好、信用状况越好的指标,如利润总额等指标;负向指标是指数值越小、企业偿还能力越强、信用状况越好的指标,如偿债保障比率等指标。设xij为第i个指标第j个企业的标准化值;vij为第i个指标第j个企业的原始数值;n为样本总数。根据正向指标和负向指标的标准化公式见式(8)和式(9)。

(8)

(9)
2.2 实验分析
2.2.1 指标集
根据数据类型情况,将大中型煤炭企业数据年份划分为ST与非ST两种情况,被标为ST的标签为1,非ST的标签为0,具体指标情况见表1。

表1 指标集Table 1 Index set
2.2.2 分类指标选择
实验所选指标为准确率(Accuracy)、AUC(Area under curve)、F1分数(F1-score)、精确率(Precision)、召回率(Recall)以及特异度(Specificity),从各个方面表现对违约样本的识别效果以及模型的稳健程度,计算公式见式(10)~式(14),TP、TN、FP、FN见表2。

(10)

(11)

(12)

(13)

(14)

表2 混淆矩阵Table 2 Confusion matrix
2.2.3 预选学习算法
表3为六个预选算法在大中型煤炭企业信用风险原始数据集中的表现。由表3可知,RF相较于其他5个模型而言,6个指标表现均较好,可以有效识别违约非违约样本,因此选用RF作为阶段二特征筛选的学习算法,算法均采用5折交叉验证进行实验,实验结果为10次实验的平均值。
2.2.4 阶段一选择结果
图3为互信息筛选离散型特征结果,图3(a)为互信息值,互信息用于衡量离散型变量与标签的信息相关程度,互信息值越大,依赖程度越大,因此借助图3(a)可得到图3(b)的学习曲线,表现为删除特征个数对应的模型准确率结果。图3(b)最高点为删除x19(失信被执行记录)与x22(大股东性质3)这两个特征,模型准确率可达到最高,为0.942 8,说明筛选出的特征对煤炭企业是否违约的分类准确率较好,因此在互信息这一步骤中,删去这两个特征作为结果。
图4和表4为方差齐性检验结果,用于判断连续型变量对因变量是否有显著影响, 所得F统计量越大、P统计量越小,预测能力越强,而在许多研究领域,0.05的P值通常被认为是可接受错误的边界水平,因此在16个连续型变量的分析中,保留P≤0.05的9个变量(即x1、x2、x7、x8、x9、x10、x11、x15、x16)作为预选连续型特征集。另一方面,由图4和表4可以看出,指标x1(ARA)与x2(CPPM)处于相对靠前的位置,证明了这两个指标与是否是违约状态具有强相关性,验证了指标的有效性。

表3 六个预选算法在初始数据集中的表现Table 3 The performance of six preselection algorithms on the initial data set

图3 互信息筛选Fig.3 Mutual information screening

图4 F检验筛选Fig.4 F-test screening

表4 方差齐性检验Table 4 Test for homogeneity of variance
2.2.5 阶段二选择结果
在阶段一Filter方法筛选出来的13个候选特征的基础上,阶段二Wrapper使用基于RF的序列前向搜索方法选择最优特征子集。根据1.2.3部分的描述,使用AUC值作为特征集效果评价指标,采用序列前向选择算法从空集逐步增加特征,直至达到最优,经过多轮的迭代最终选择出了10个优选特征。由图5可以看出,当指标为10个时,AUC值表现最好,即保留x1、x2、x7、x8、x9、x11、x17、x18、x20、x21作为最终优化特征集。
2.2.6 实验结果说明
表5为原始数据、阶段一筛选之后的特征、阶段二筛选之后的特征分别使用分类器预测之后的实验结果。由表5可知,经历两个阶段的特征筛选之后,各类指标均得到了增长,模型具有较高的Specificity与Recall,说明对正负样本可以有针对性地进行识别,对煤炭企业信用风险的分类预测效果较好且稳健,指标由22个删减到10个,大大增加了模型计算效率。本文使用最后选择出的特征子集进行模型训练既可以保证良好的预测效果,又可以保证没有冗余变量干扰分类,这在大中型煤炭企业信用风险预测中具有较大的现实意义。

图5 特征个数与AUC值的关系Fig.5 The relationship between the feature number and AUC value
表6为无x1(ARA)、x2(CPPM)特征的情况下,原始数据、阶段一筛选之后的特征、阶段二筛选之后的特征使用分类器的预测结果,图6~图8为有无x1、x2特征的情况下的实验对比结果。实验结果表明,x1、x2对于模型的分类精度以及稳健程度具有重要作用,各类指标均优于无x1、x2的指标,证明了所提出的两个指标的有效性。

表5 实验结果对比Table 5 Comparison of experimental results

表6 无x1、x2特征实验结果对比Table 6 Comparison of experimental results without x1 and x2 features
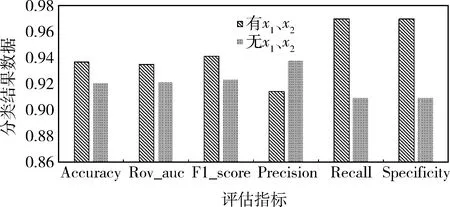
图6 原始数据对比Fig.6 Raw data comparison

图7 阶段一之后数据对比Fig.7 Data comparison after stage one

图8 阶段二之后数据对比Fig.8 Data comparison after stage two
3 结 语
本文建立了基于Filter-Wrapper两阶段特征选择方法的大中型煤炭企业信用风险评估模型,根据大中型煤炭企业的特点,在通用指标选择上结合煤炭企业风险因素提出两个新指标:抗风险能力、煤炭及加工产品业务销售毛利率;构建的Filter-Wrapper两阶段特征选择方法通过实验证明对ST状态的分类准确率高、对煤炭企业信用风险违约样本识别率较高且提高了预测效率,准确率高达95%,对违约样本识别率高达96%;实验结果将特征选择前后的数据集进行预测对比,验证了煤炭企业信用风险评估指标的有效性以及特征选择方法的可行性,说明该模型能够很好地对煤炭企业信用风险进行预测,从而合理防范风险、调控市场、减少银行、投资者以及企业本身的损失。
