社交媒体平台中健康报道标题对公众情绪影响研究
——以人民日报微信公众号为例
2022-05-12张学波
张学波 王 卿
当前,社交媒体平台中表达的情绪对国内主流媒体、舆情生态和和谐社会倡导的主流文化具有重要影响作用。研究民众的情绪可以揭示人们的生活状态、生活诉求以及对民生健康的看法与意见,为政府拟定卫生、健康等方面的相关政策提供实际建议。本研究致力于收集分析人民日报微信客户端健康专栏的标题情绪,可有效获知公众对于这些健康议题信息的需求情况,挖掘出受众对哪些健康议题关切,有利于为人民日报微信公众号或者是其他健康类微信公众号提供议题方面的借鉴。也有利于满足公众对健康报道、医疗卫生信息的需求,消除有关健康问题公开的不确定性,提高公众的安全和满足感,有助于丰富大众传媒对健康传播的报道、受众和效果方面的研究,有助于重新审视媒体对于公众情绪的影响。
一、问题缘起及文献综述
情绪表现为对外部刺激的各种心理和生理反应,例如恐慌,兴奋和愤怒。情感分析是通过编写代码自动确定文本中包含的情绪状态,对于掌握公众的舆情状态和人们的诉求的实际意义十分关键。
在此方面,国外相关的研究起步较早,范围较广泛,它主要涉及初步的情感倾向分析、更进一步的文本提取和多种情感的分类、情感分析相关的字典和语料库建设等,其中情绪词典和语料库构建是基础。情感词典和机器学习是文本情感分析的两种主要的操作方法。最早出现的是基于情绪词典的方法,主要是指在已经经过人工构建的情绪词典的基础上,利用词典中每个词语的情绪标签对待分类文本的情绪类别进行标注。Paltoglou(2012)以LIWC情绪词典做参照,扒取了推特、我的空间和Digg等网络平台的文本,制订出了一系列的计算规则来处理句子中的情绪词,当情绪词被不同的词修饰时或者情绪词本身的样式发生变化时,那么相应的计算规则也会发生变化[1]。结果表明,他们提出的公式和规则得出的情感分析的效果皆比单纯靠机器学习分析出的效果好。此种方法的效果缺点在于人工构建的情绪词典无法完全覆盖所研究的文本,并且当文本中出现的情绪词较为隐晦时,研究者也不易标注。Mohammad(2011)通过Word Net、Affective Norms 和NRC 三个词典,进一步设计计算规则,进行情绪分析,结果表明,相比于n-gram,情感词库对多个不同专业和领域的文本分析效果更佳[2]。
国内许多文献对微博中的微内容进行文本情感分析,对本研究内容的划分具有重要的借鉴意义。封丽(2018)主要对微博中有关柴静《穹顶之下》纪录片的评论进行了情感计算,以正负中性三种对微博主体中的表情和文本情感极性计分,正向表情表示为1,负向表情表示为-1,中立向表情表示为0。她还注意到与表情、文本不同的是微博情感词通常有“十分”“稍微”“没有”等程度副词,这些词语也对情感表达具有特殊作用。最后得出对柴静及其纪录片存在的负面情感倾向主要有以下几类:①纯粹不安好心凑热闹;②只从个人好恶出发,不喜欢柴静则不认同《穹顶之下》;③从柴静立场、经历等各方面对其动机进行挖掘,然后从阴谋论等方面认为柴静纪录片需要得到质疑;④《穹顶之下》这部纪录片的话语表达以及拍摄所存在一些问题,这篇论文计算情感极性的方法值得本研究借鉴[3]。在文本情感分析方法刚刚兴盛之时,就已有学者将其与社会网络分析法相结合对雾霾舆情进行了研究,四川大学何跃、朱婷婷(2018)通过对新浪微博进行扒取以及聚类,进一步找出具有代表性的微博绘制网络图,展示出整个情感传播网络的子群、中心度等指标[4],这说明情感分析可以和社会网络分析进行结合,对本研究指明了方向。
情感词典和机器学习是目前文本情感分析所涉及的两种主要的方法,其中构建情感词典的作用最为基础。目前通过人工构建的中文情感词典主要有谭松波酒店评论、台湾大学情感语料库、Hownet情感词袋、BoSon语义情感词库等。本研究采用情感词典的方法进行分析,主要借鉴BoSon语义情感词库和Hownet情感词袋,目的是分析人民日报微信公众号健康专栏的总体情感倾向,计算出标题和评论的情绪值,并探讨标题情绪值、评论情绪值、点赞量以及评论量两两间的数据关系。
二、文本分词及情感词典选用构建
本研究选用Python3.6环境,统一使用“utf-8”格式编码。“分词”即将一个整句按照词性分成不同的部分,要想进行自然语言处理,就必须得使用较为精确的分词工具对文本中的语句进行切割。目前学界也出现了一些比较成功的有效分词系统,例如庖丁分词系统、ICTCLAS中文分词系统以及基于HMM模型的结巴分词系统等等,本研究使用结巴中文分词系统。情感词典方面,国内已存在着一些具有针对性的情感词典,例如台湾大学语料库、HowNet语料库、BoSon语义情感词典等。由于波森情感词典主要在Twitter、微博、微信等社交媒体品平台的基础上爬取其文本,整合出词典。故本研究以波森情感语料库为主体,HowNet及其余词典为辅,构建出本研究所采用的情感词典。
三、混淆矩阵构建及分类器验证
本研究数据来自2018年4月至12月的人民日报微信公众号“健康”专栏的标题以及评论,经清洗后得到标题共822条,评论共8843条。为测试实验结果的准确率,选用4名志愿者对标题以及评论进行正面和负面倾向的人工标注。经人工标注后,标题共359条为积极情感倾向,463条为消极情感倾向;评论共4907条为积极情感倾向,3936条为消极情感倾向。而机器标注结果为:标题共390条为积极情感倾向,432条为消极情感倾向;评论共4936条为积极情感倾向,3907条为消极情感倾向。标注后统计结果如下:
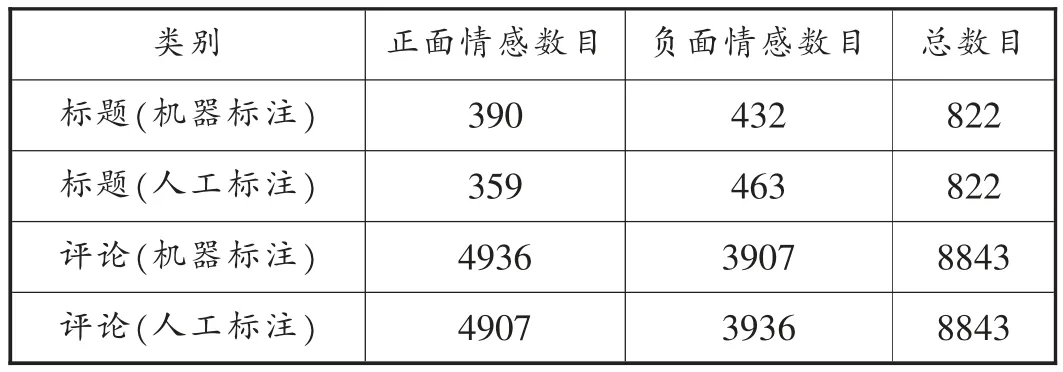
表1 机器标注与人工标注对比表
对情感计算结果的评估即是指对自然语言处理的结果进行评估,是计算过程中非常重要的一环。学界在近几年评估自然语言处理的结果时,通常以召回率(R)、精确率(P)、准确度(A)以及F-measure值(综合评估指标)作为评估指标,而这三项指标的计算往往是以人工标注的结果为参照[5]。
准确度(A)是指分类器情感分类的准确度,是正确分类的样本数除以样本总数,分类效果和准确度成正比。准确率(P),也称为“查准率”,是指分类器的情绪分类的准确性,分类器正确分类的样本的数量与所有正确样本总量的比率。召回率(R)是指被分类器分类过的数量可以涵盖到多少原本的分类数量。F-measure值是综合评价指标,是指当P和R指标出现矛盾情况时,综合两者而得出的指标。在计算四个指标之前,首先要构建混淆矩阵。混淆矩阵包含四个数值:True Positive (TP)—将正面情感倾向句判断为正面情感倾向句;True Negative(TN)—将负面情感倾向句判断为负面情感倾向句;False Positive(FP)—将负面情感倾向句判断为正面情感倾向句;False Negative (FN)—将正面情感倾向句判断为负面情感倾向句。笔者假定人工参照结果全部正确,以人工标注为参照,分别对标题和评论分类的正确以及错误数目进行统计并构建混淆矩阵:

表2 标题混淆矩阵
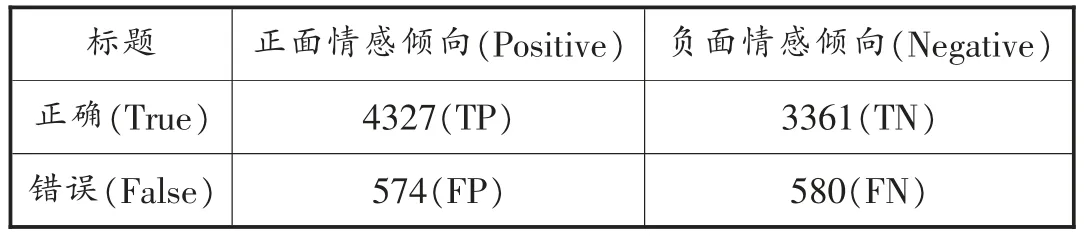
表3 评论混淆矩阵
根据准确率(A)计算公式:
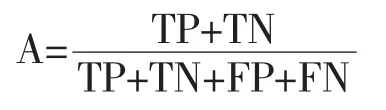
精确率(P)计算公式:Ppositive=

召回率(R)计算公式:

以及F-measure计算公式:

其中λ是一个可以自行设定的系数,当λ大于1时,精确率对F-measure值影响较大,当λ小于1时,召回率对Fmeasure值影响较大;当λ等于1时,二者对F-measure值具有同样影响。在本研究中,取λ等于1,则此时F-measure值为F1值。F1值越大,则分类器越好。公式为:
由表4,可得出结论:分类器在分析评论时较分析标题时更为准确,尤其是在分析正面情感评论时的精确率比分析正面情感标题的精确率高出9.5个百分点,究其原因,是二者表达方式不同。评论大多为短句,分析较为简便,而标题糅合悬疑、设问、反问、感叹等多种表达方式,不易把握其情感倾向,反观评论,其正面情感表达方式大多比较单一,多数为“感谢小编”“感谢科普”“实用,收藏”云云。综观各项数据,该分类器性能良好,分类较为准确,分类结果较为可信。

表4 情绪值分类器各项评估指标
四、假设检验
(一)相关分析
相关分析是指分析两个或多个具有相关性的元素或变量之间的关系,以探讨二者的密切相关程度。本研究将标题情绪值与评论情绪均值、点赞量以及评论量进行相关分析,以探求其中的显著性。
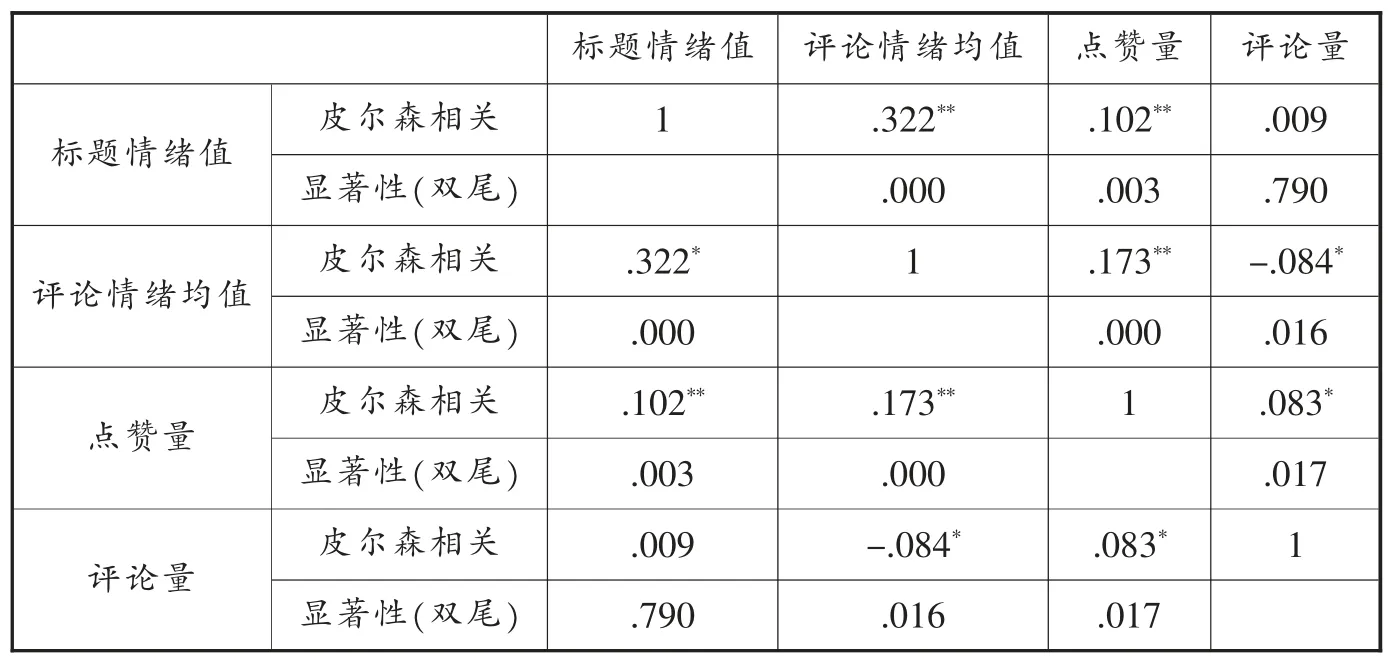
表5 相关分析结果表
由上表可以看到,标题情绪值与评论情绪均值之间的相关系数为0.322,呈现为中等相关,P值接近于零,表明相关性在0.01层上显著。而在标题情绪值与点赞量之间,虽然P值等于0.003,表明相关性是显著的,但二者皮尔森相关系数仅为0.102,呈现为弱相关关系。此外,标题情绪值与文章评论量之间无显著相关关系。
(二)回归分析
由相关分析可知,标题情绪值与评论情绪均值之间的相关关系具有显著性,故探讨二者是否存在显著的线性回归方程具备一定的研究意义。本研究采用的是一元线性回归分析,经由SPSS分析之后,结果如下表。

表6 Anova表
由Anova表可看到,模型F统计量为94.846,表明显著性水平的p值接近为零,说明因变量与自变量的线性关系明显。
表7给出了回归标准系数以及显著性检验的P值,可以看到回归系数为0.322,P值接近于零,故模型达到了显著性水平。由共线性诊断表,可看到特征值VIF不为零,说明不存在多重共线性现象。

表7 系数表
五、研究结论:
(一)社交媒体平台中健康报道的标题呈现通俗化、情感化趋势
微信是一种即时性社交媒体平台,由于其具有的及时传递、隐秘性的特点,被许多亲朋好友所青睐,本研究在对表达情绪倾向的词语进行分析时发现,恐吓词、人称词以及数词的使用占比较多。其中例如“后果很严重”这类恐吓词的使用,会让人们不得不联想到自己的身体状况,产生杞人忧天的恐惧心理,从而利用此种心理转发文章,吸引人们的注意力;第一人称、第二人称这种人称词的使用频率增多,将会凸显出标题内容的口语化、亲民性,从而消除文章与读者的隔阂,更利于情感的传递;而例如“万万”“千万”这种数词的使用也夸张了原本标题的表达情感,凸显出一种惊慌之意。总体上说,通过对标题中各类词语使用情况的内容分析,可以得出人民日报微信公众号标题呈现通俗化、情感化趋势这一结论。
(二)社交媒体平台中健康报道的标题中蕴含的情感会显著地转移至评论者
本研究通过文本情感分析的方法,主要以波森语义情感词典和Hownet语料库为基础,构建情感词典库。以Python3.6为编程环境,jieba分词为分词工具包,编写分类器,计算出2018年月到12月人民日报微信公众号健康专栏的标题及其相对应评论的情绪值。进一步构建混淆矩阵,经过实验的评估,该分类器达到的最高准确率为86.9%,平均准确率为85.05%,最高召回率为88.2%,平均召回率为85.05%,分类效果较好。此处分类器的分类结果表明计算所得的情绪值较为可信,可为下一步探讨标题情绪值和评论情绪值之间的关系奠定坚实基础。
随后,将标题情绪值和评论情绪均值做假设检验,探讨二者的相关性,结果表明,二者具有显著的相关性,并进一步探讨其中的因果关系,可初步得出结论:在人民日报健康专栏中,文章标题情绪可影响文章评论情绪,并且新闻标题蕴含的情绪越强烈,评论所蕴含的情绪也越强烈,二者成正相关关系。议程设置理论的第一层是指新闻事件由编辑部转移到公众之中,第二层是新闻事件的属性转移到公众中,通过对标题情绪值和评论情绪值之间关系的假设检验,可以创新性地验证“属性议程设置”理论。
