基于量子进化算法的包装式特征选择方法①
2022-05-10雷华军
雷华军,蒋 强
(乐山师范学院 电子与材料工程学院,乐山 614000)
随着信息技术的飞速发展,高维数据的监督分类问题在生产、生活和科研活动中大量涌现.理论上讲,增加特征的个数可以提供更多的分辨能力,但研究表明:数据维数的线性增加将使得问题的假设空间成指数增长,特征每增加一维,为确保学习算法的性能不变,样本量亦需成倍增加.另一方面,在样本量一定的情况下,由于无关或冗余特征的存在,过多的特征不仅降低学习算法的效率,还可能导致过拟合,致使模型的泛化能力下降[1].特征选择是解决前述问题的有效手段之一,它根据某种评价标准,从原始特征集中挑选一些最有效的特征以达到降低特征空间维数的目的,并取得与原始特征集相似甚至更好的分类性能.特征选择已成功应用在文本分类[2]、癌症识别[3]、设备故障检测[4]、贷款风险预测[5]等领域.
纵观现有特征选择方法,均包含特征子集生成和子集评价两个构成要素[6].前者采用一定的策略搜索特征空间中的全部或部分子集,常用的方法有穷举搜索、启发式搜索和随机搜索.后者使用某一标准评价搜索到的子集,依据该标准是否独立于后续的学习算法,可将特征选择方法分为过滤式(filter)、包装式(wrapper)和嵌入式(embedded)三类.相比过滤式,包装式选择的子集通常拥有更优的分类性能,因其直接使用特征子集的分类精度作为评价标准[7].
近年来,国内外学者对基于随机搜索策略的包装式特征选择开展了广泛的研究,大量新颖的群智能优化算法被用于特征选择[8],其中较为典型的方法有粒子群优化[9]、蜻蜓算法[10]、灰狼优化[11]、鲸鱼优化[12]、引力搜索算法[13]等.这些方法大多从搜索策略的角度对原算法进行了有益的改进,而有关子集评价的研究则较少.
量子进化算法(quantum-inspired evolutionary algorithm,QEA)是一种基于量子计算原理的概率进化算法,具有种群规模小、收敛速度快和全局寻优能力强等优点[14].目前,仅检索到一篇与本文主题密切相关的文献[15],该文将QEA 作为特征子集的搜索策略,并使用Fisher 比评价其性能,因而它属于一种过滤式的特征选择方法.综上所述,将QEA 与包装式特征选择结合的相关研究尚处于空白,本文将从子集评价和搜索策略两个方面开展工作,力图提出一种具有竞争力的包装式特征选择方法.
1 问题描述
为结构完整性,给出特征选择的形式化描述.假定D={(s1,y1),(s2,y2),···,(sm,ym)}为原始数据集,S=(s1,s2,···,sm)T为样本矩阵,行和列分别代表不同的样本和特征,Y=(y1,y2,···,ym)T为各样本对应的真实类别.si=(si1,si2,···,sin)是n维特征空间 χ的一个向量,即si∈χ ,χ=span{f1,f2,···,fn},其中fj表示第j个特征,元素sij(1 ≤i≤m,1 ≤j≤n)为样本si在特征fj上的取值.类别yi∈C,C={c1,c2,···,ck}为类别集合.m、n和k分别为样本、特征和类别的个数.
基于上述定义,监督分类的任务是:利用给定的学习算法从D中学习一个分类模型h:χ →C,它对采样自 χ的新样本具有良好的泛化能力.然而,并不是所有特征都对分类有贡献,为提高模型的训练效率和泛化能力,特征选择从原始特征集F={f1,f2,···,fn}中找出一个子集X,X⊆F,它使得评价函数J(X)尽量大,X包含的特征数尽量少.J(X)量化了X分类性能的好坏,不失一般性,假定J(X)值越大,X越优.不难看出,分类性能和特征个数是该问题最重要的两个优化目标.
基于现有研究,归纳出包装式特征选择的一般框架如图1所示.
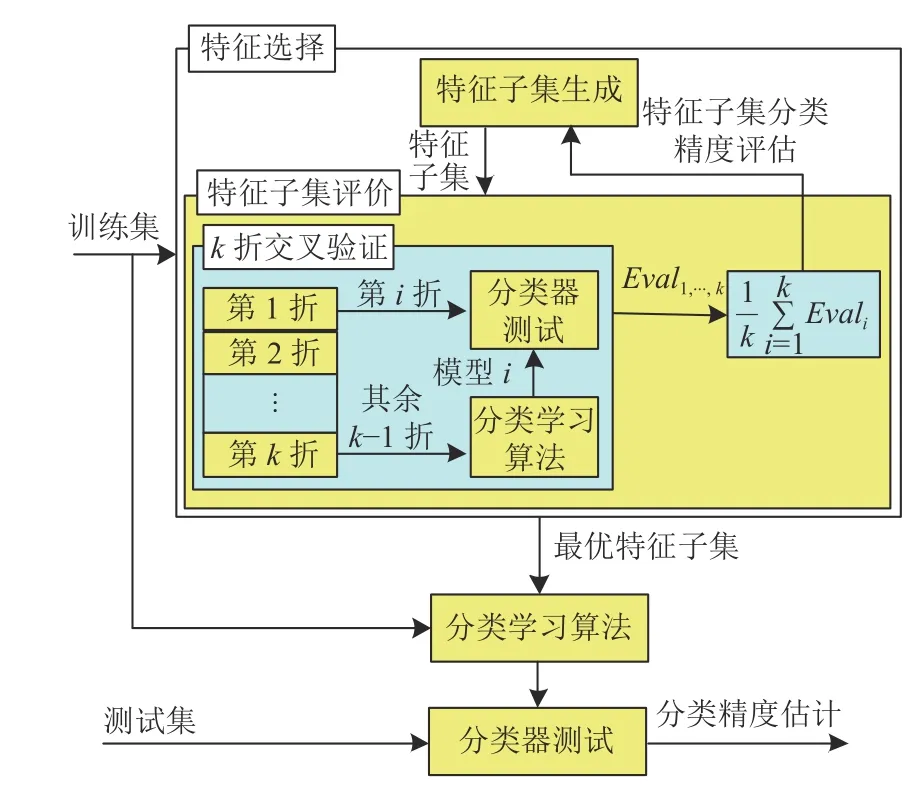
图1 包装式特征选择的一般框架
由图1 可以看出,数据集被分为训练集和测试集,特征选择在训练集上进行,测试集不参与该过程.特征选择结束,需验证最优子集在测试集上的分类精度.在特征选择过程中,子集的分类性能通过K 折平均分类精度来衡量,分类器被视为一个封闭的黑盒.
2 量子进化算法
基本量子进化算法包含种群初始化、随机观测、种群进化等3 个主要步骤[14,16].它采用量子比特编码,一个量子比特可表示为:

其中,|0〉和|1〉表示两个不同的量子态,α 和 β分别表示状态 |0〉和| 1〉的概率幅.一个量子比特可能处于| 0〉或|1〉两个基态,或者两基态的任意叠加态,|α|2和 |β|2表示该量子比特处于| 0〉和| 1〉的概率大小.


3 特征选择方法
3.1 种群初始化


3.2 特征子集评价和性能比较



3.3 种群进化策略


3.4 整个算法流程
综合第3.2 节和第3.3 节的改进措施和图1,得到整个特征选择方法的流程如图2所示.
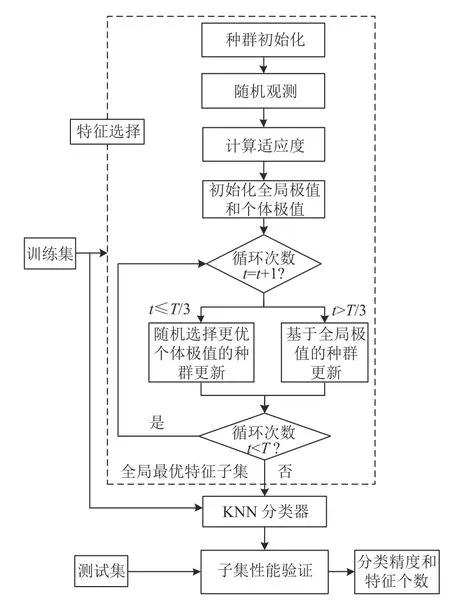
图2 特征选择方法的流程
由图2 可知,实验中利用分层采样将数据集分为训练集和测试集.在特征选择过程中,两种进化策略分别执行T/3 和2T/3 代.
4 实验与结果分析
4.1 实验方案
选取UCI[19]中的15 个数据集作为实验数据,其中大多已被用于验证各种特征选择方法,关于这些数据集的详细信息如表1所示.注意,前11 个数据集以一个整体的形式提供,实验中利用分层采样将其分为70%的训练集和30%的测试集;后4 个加“*”号的数据集以训练集和测试集的形式提供,实验中直接使用训练集做特征选择,测试集用于验证,不再进行划分.
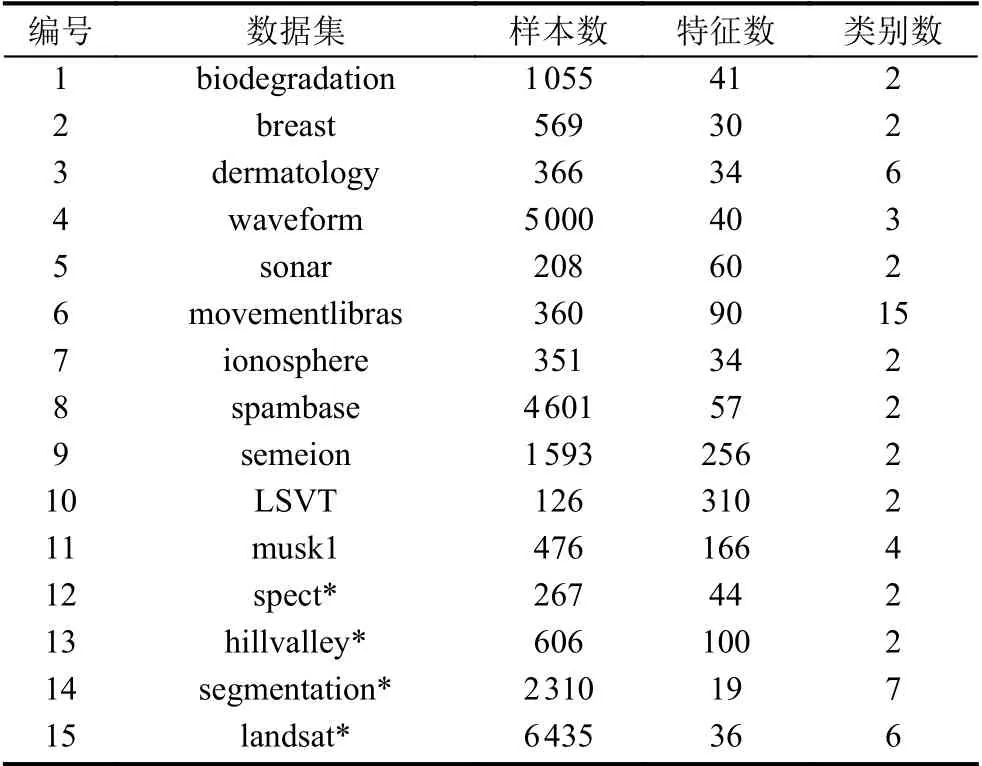
表1 实验数据集
包装式特征选择方法使用分类器来评价特征子集,后续实验均使用K 近邻(K-nearest neighbor,KNN)学习算法,这有利于算法之间公平的比较[9-13];KNN 的距离度量使用欧氏距离,近邻个数为5.所有实验均在同一台PC 机上进行,配置为:Intel(R)Core(TM)i7-9700 CPU@ 3.00 GHz,8 GB 内存,Win10 64 位操作系统,编程环境为Matlab 9.9(R2020b).为了结果的客观性,若无特别说明,对于每个数据集,算法均独立运行20 次,以便评估算法的性能,表中所示分类精度和特征个数是20 次独立试验后的平均值.
4.2 重要参数的选择
子集评价方法4 和5 分别依赖于参数ε和delta的取值,它们直接影响显著性的判定.选取表1 中的前5 个数据集进行参数的讨论,假定 ε的可能取值为{0.001,0.005,0.010,0.050,0.100,0.500},delta的可能取值为{0.05,0.10,0.15,0.20}.为选择一组合适的参数,进化策略采用基本QEA,将其分别与子集评价方法4 和5 相结合构成2 种特征选择算法.其它的算法参数为:种群规模G=10,最大进化代数T=50,交叉验证次数K=10,旋转角幅值θ=0.01 π.不同参数取值对应的平均分类精度和特征个数如图3所示.
从图3(a)可以看出,除了waveform,在其它数据集上平均特征个数随ε增大而减小,ε的值越小越好;考察分类精度,其值亦呈现相同的趋势,但前3 种ε值对应的分类精度在5 个数据集上均无显著差异,后3 种ε值对应的分类精度则显著下降.综合考虑,选取 ε的值为0.010.同理分析图3(b),平均特征个数随delta增大而增大,delta的值越小越好;从分类精度的角度,仅有delta=0.10 时对应的分类精度在5 个数据集上与delta的其余4 种取值的最优分类精度均无显著差异,故选取delta值为0.10.
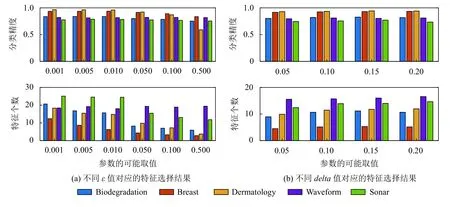
图3 重要参数的结果对比
4.3 子集评价方法对比
为对比不同的子集评价方法,搜索策略采用基本QEA,将其分别与5 种子集评价方法相结合构成5 种特征选择算法,算法参数同第4.2 节.表2 为5 种特征选择方法的运行结果,其中Pij表示对方法i(i=1,2,3)和方法j(j=4,5)的20 次分类精度进行威尔科克森秩和检验的P 值,显著性水平为0.05.“+”和“-”分别表示前者的分类精度显著好于和差于后者,而“=”则表示两者的分类精度相似,没有显著差异,表中最后一行统计了对应列“+”“-”和“=”的个数.
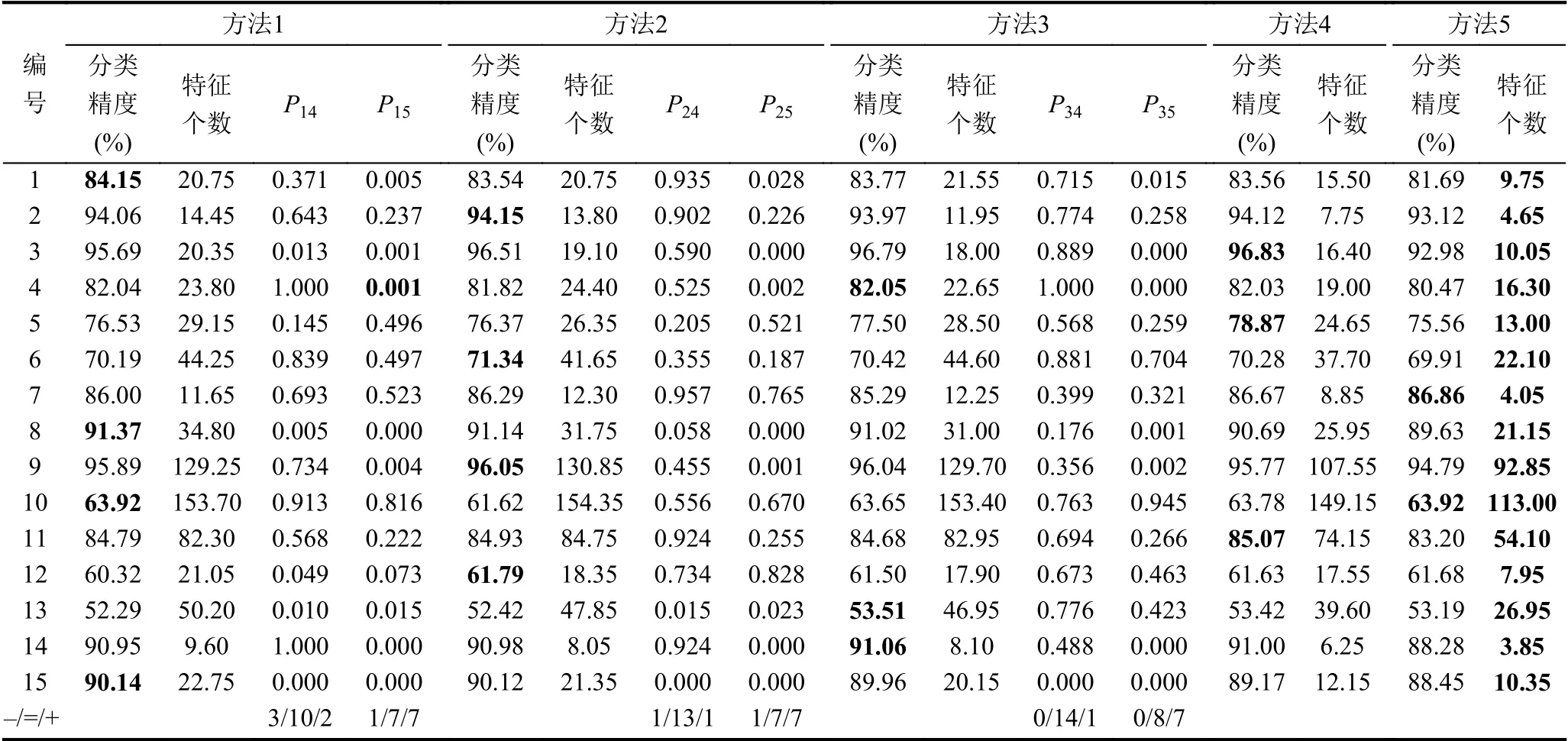
表2 5 种子集评价方法的分类精度和特征个数
由表2 可知,相比子集评价方法1、方法2 和方法3,方法4 至少在13 个数据集上取得相似甚至更好的分类精度;而方法5 仅在8 个数据集上表现出同样的性能,在其余7 个数据集上分类精度要显著的差于方法1、方法2 和方法3.从特征个数的角度,不难看出方法5 总是取得最优的结果,其次是方法4.为更具体的说明,以breast 数据集为例,给出其20 次实验中的分类精度和特征个数的箱线图,如图4所示.

图4 子集评价方法在breast 数据集上的对比结果
从图4(a)可以看出,前4 种方法对应分类精度的中位值和平均值大致相当,难以直观判断哪种方法更优,但均优于方法5 的分类精度;从图4(b)可以很容易看出方法5 选择的特征个数最少,其次是方法4.综合两者,方法4 能在确保分类精度无显著差异的情况下,选择特征个数更小的子集,表明针对子集评价方法的改进是有效的,后续实验均采用方法4 作为子集评价方法.
4.4 进化策略的有效性验证
采用子集评价方法4,将其分别与基本QEA 和改进QEA 相结合构成2 种特征选择方法,算法参数同第4.2 节.为叙述方便,分别简记为BQEA 和IQEA,其运行结果如表3所示,其中P为针对分类精度的威尔科克森秩和检验的P 值,“+”和“-”分别表示BQEA 的分类精度显著的好于和差于IQEA,而“=”则表示两者的分类精度相似.
由表3 可以看出,在Semeion 和Landsat 数据集上,BQEA 的分类精度显著优于IQEA,在Ionosphere 和Hillvalley 数据集上的结论正好相反,在其余数据集上两者的分类精度均相似.从特征个数来看,IQEA 的结果总是优于BQEA 对应的结果.同样以Breast 数据集为例,其分类精度和特征个数的箱线图如图5所示.
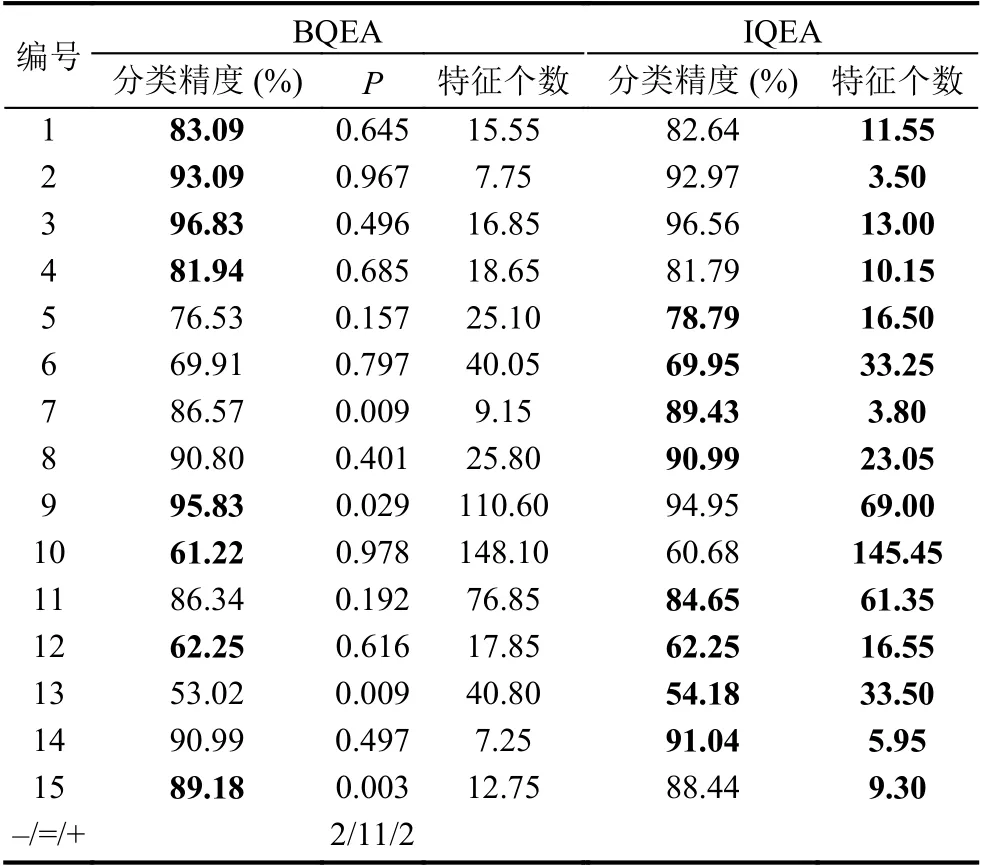
表3 BQEA 和IQEA 的运行结果
由图5(a)可以看出,BQEA 和IQEA 的分类精度大致相当,无法直观判断哪种方法更优;从图5(b)却可以直观的看出IQEA 选择的特征个数小于BQEA 对应的结果.由实验的设置可知,BQEA 和IQEA 的差异仅在于进化策略的不同,表明针对进化策略的改进措施是有效的.
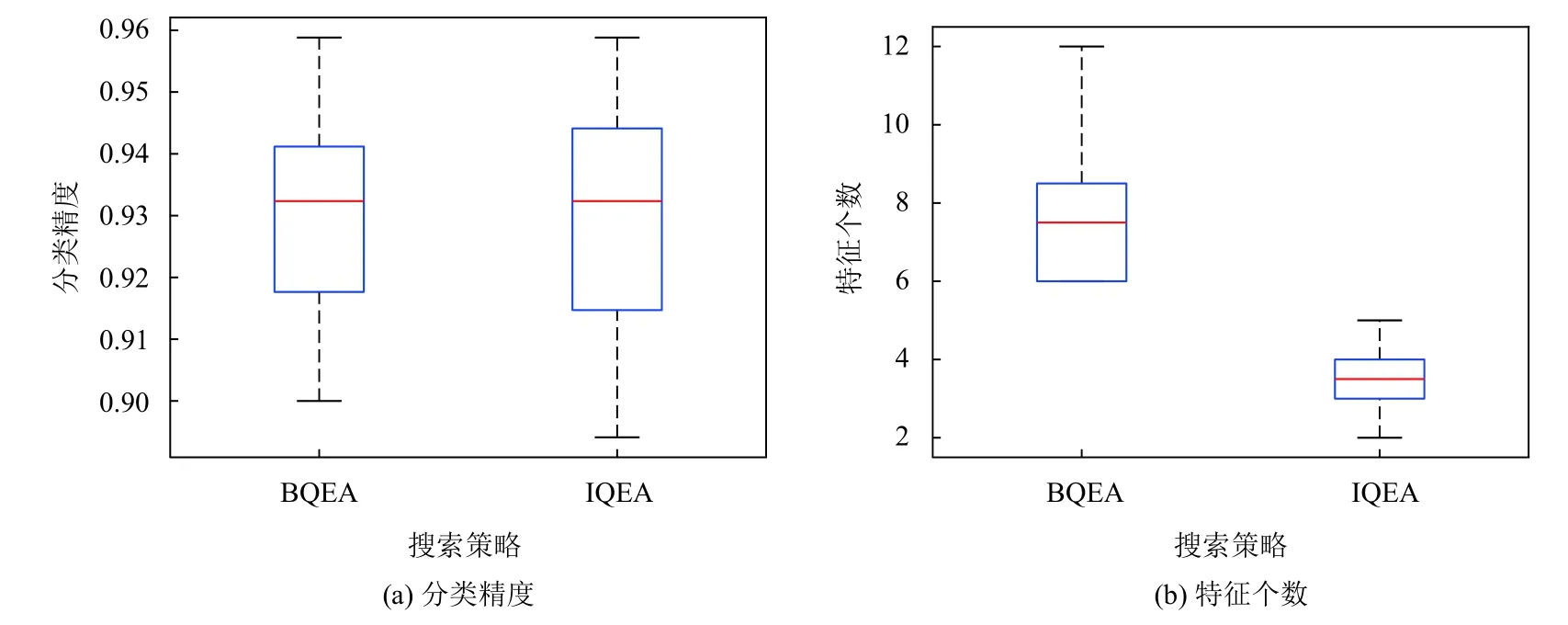
图5 BQEA 和IQEA 在breast 数据集上的对比结果
4.5 特征选择方法的对比
选取近年来新提出的包装式和过滤式特征选择方法作为对比,包括HPSOSSM[9]、SBDA[10]、ABGWO[11]、HMNWOA[12]、HGSA[13]和FS-IQEA[15],其中前5 种方法属于包装式,后1 种方法为过滤式.为比较的公平性,设置所有算法的种群规模G=20、进化代数T=60,交叉验证次数K=10,每种方法其余的参数按照对应文献给定的值设置.这些方法连同IQEA 的运行结果如表4所示,其中Pi(i=1,2,3,4,5,6)分别表示6 种对比方法和IQEA 的分类精度做威尔科克森秩和检验的P 值,“+”“-”和“=”的含义同前.
由表4 可知,分类精度方面,IQEA 显著优于HPSOSSM 、SBDA、ABGWO、HMNWOA、HGSA和FS-IQEA 的数据集占比分别为26.67%、20.00%、26.67%、13.33%、20.00%和66.67%;取得相似分类精度的数据集占比分别为53.33%、66.67%、60.00%、73.33%、66.67%和33.33%.综合两者,IQEA 与比较方法取得相似甚至更好分类性能的数据集占比分别为80.00%、86.67%、86.67%、86.67%、86.67% 和100%.

表4 IQEA 与其它方法的对比结果
从特征个数来看,除了Semeion 数据集,FS-IQEA选择的子集总是包含最少的特征,但其对应的平均分类精度亦小于包装式方法对应的结果,从而证实了“相比过滤式,包装式选择的子集通常拥有更优的分类性能”的一般结论.若仅考察包装式方法,不难看出,除了LSVT 和hillvalley 数据集 ,IQEA 在其余数据集上选择的特征个数均最少,占总数据集的86.67%.
综合考虑分类精度和特征个数,相比现有包装式特征选择方法,可以看出IQEA 在大多数情况下能取得相似甚至更好的分类性能,并且选择的特征个数更少,降维效果更加明显.
5 结论与展望
子集评价和搜索策略是构成包装式特征选择方法的两个关键要素,论文从这两个角度出发,分别提出了改进的子集评价方法和搜索策略,进而设计了一种
基于量子进化算法的包装式特征选择方法.大量的实验结果表明,相比现有特征选择方法,本文方法在大多数情况下能搜索到更小的特征子集,并能取得相似甚至更好的分类精度,降维效果突出.同时表明,要提高包装式特征选择方法的性能,除了现有文献广泛关注的搜索策略,子集评价方法也应重点关注.
需要指出,随着样本量和特征个数的增加,包装式特征选择方法的计算量将显著增加,甚至根本不适用.实验中所用数据集的特征个数均不超过1 000,因此如何进一步提高算法的性能,使其适用于更高维(特征个数>1000)数据的场合,例如基因选择,将是下一步要研究的内容.
