网格化局部自适应DBSCAN聚类算法
2022-05-03代少升刘小兵赖智颖
代少升,刘小兵,赖智颖,任 忠
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
随着大数据时代的到来,众多改进聚类方法[1-2]应用于数据分析。基于密度的噪声应用空间聚类(density based spatial clustering of applications with noise, DBSCAN)算法作为基于密度的聚类算法典型代表,能够有效地标记噪声点,并且能够发现任意形状的数据簇。与基于划分的聚类算法相比,DBSCAN算法不需要预先指定聚类簇数便能标记不同的数据簇。DBSCAN通过给定邻域半径来遍历所有点的邻居点,并通过点数阈值控制邻域点个数来完成聚集区域的标记。但是,DBSCAN算法对参数敏感。其一,参数一般为手动指定,如果参数设置不当将会导致聚类效果不佳;其二,对于多密度的数据集[3],如果使用统一的全局参数将无法保证局部的聚类质量。针对DBSCAN算法的改进[4-5]及局部自适应聚类算法,国内外学者展开了一系列的研究。文献[6]利用“分治”思想提出改进的DBSCAN聚类算法,该算法利用网格分配以及归并思想自适应局部邻域半径(epsilon, Eps),从而实现非均匀数据集的局部聚类分析,但仍需要输入参数。文献[7]提出基于K-平均最近邻算法的DBSCAN聚类算法(K average nearest neighbor DBSCAN, KANN-DBSCAN),该算法根据距离矩阵求得Eps候选列表,并根据不同的Eps确定最小点数(minimum number of points, Minpts)列表,最后使用2列表对应参数聚类,取聚类簇数超过3次相同,且选取K值最大时对应的Eps和Minpts作为最优参数。该方法精度较高,但是非常耗时,且使用的仍是全局参数。文献[8]提出了增量并行化DBSCAN(incremental parallel DBSCAN,IP-DBSCAN)聚类方法,该算法通过二分法划分网格,并使用R*-tree来加快聚类合并速度。在采取二分法划分网格时,需要输入网格边长阈值,该阈值直接关系到聚类结果的好坏。文献[9]提出自适应选择局部半径的密度聚类算法(self adaptive local eps DBSCAN , SALE-DBSCAN),其运用密度峰值点自适应局部Eps,然后通过密度峰值点邻域合并聚类结果,复杂度较高。文献[10]提出基于高阶差分和网格划分的DBSCAN参数选择算法 (higher order difference and grid partition DBSCAN parameter setting ,HODG-DBSCAN),其方法要求数据集分布均匀。
本文从多密度数据集出发,基于DBSCAN聚类算法思想,提出了一种自适应局部参数DBSCAN (grid based local adaptive DBSCAN, GBLA-DBSCAN) 聚类算法,该算法利用非等分网格划分[11]数据集,将数据集根据各维度大小映射到网格空间,并使用高斯核函数计算每个网格的局部密度,然后根据每个维度的密度分布曲线确定最佳 Eps和Minpts参数,最终实现局部参数的自适应选择。该算法运算简单,聚类效果较好,能有效地标记非均匀与均匀分布的数据集。
1 DBSCAN聚类算法
文献[12]提出的DBSCAN聚类算法是一种基于空间密度的聚类算法,可以用于发现任意形状的数据集合。该算法的核心思想是对于每个目标簇,在给定邻域半径范围内包含有指定点数阈值的一系列集合。于是,DBSCAN中定义了2个关键参数:Eps-邻域搜索半径以及Minpts-搜索邻域内包含的最小对象数。设D为R2空间上的点集合,则DBSCAN会根据给定的2个参数将D中的点划分为3种类型:核心点、边界点和噪声点,具体定义如下。
核心点:假设∃a∈D,a为核心点,即a周围的点分布密度较大。则核心点必满足
NEps(a)≥Minpts,a∈D
(1)
(1)式中,NEps(a)为a的Eps-搜索邻域点个数。令b是a搜索邻域内的一点,b与a之间的距离关系可根据闵可夫斯基距离公式确定。
(2)
(2)式中,p为数据集的维度。由于本文研究的是二维数据集合,即p=2。由此可知b满足
dist(a,b)≤Eps,b∈D
(3)
边界点:∃a∈D,a为边界点,即a处于一个点簇。则边界点满足
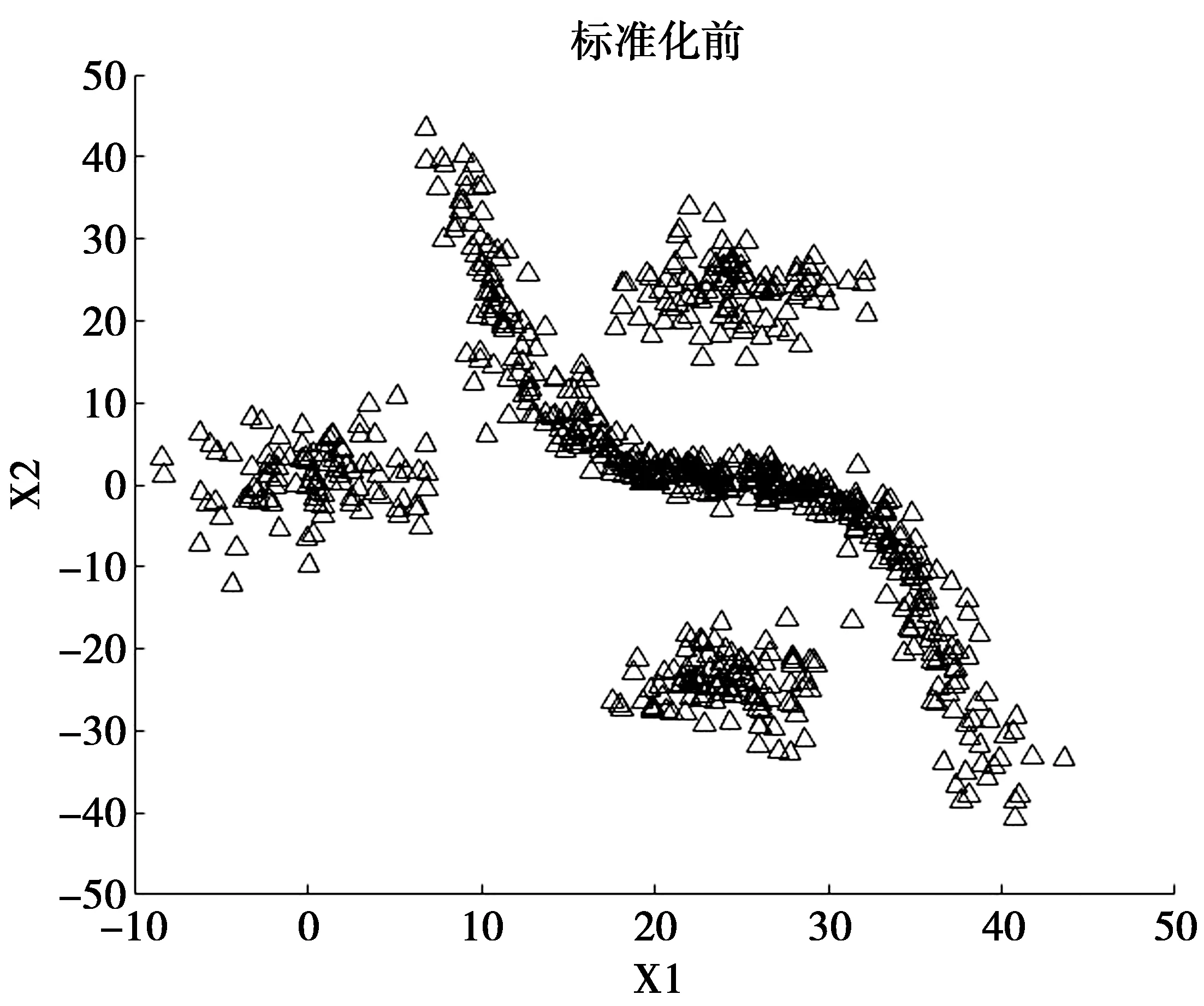
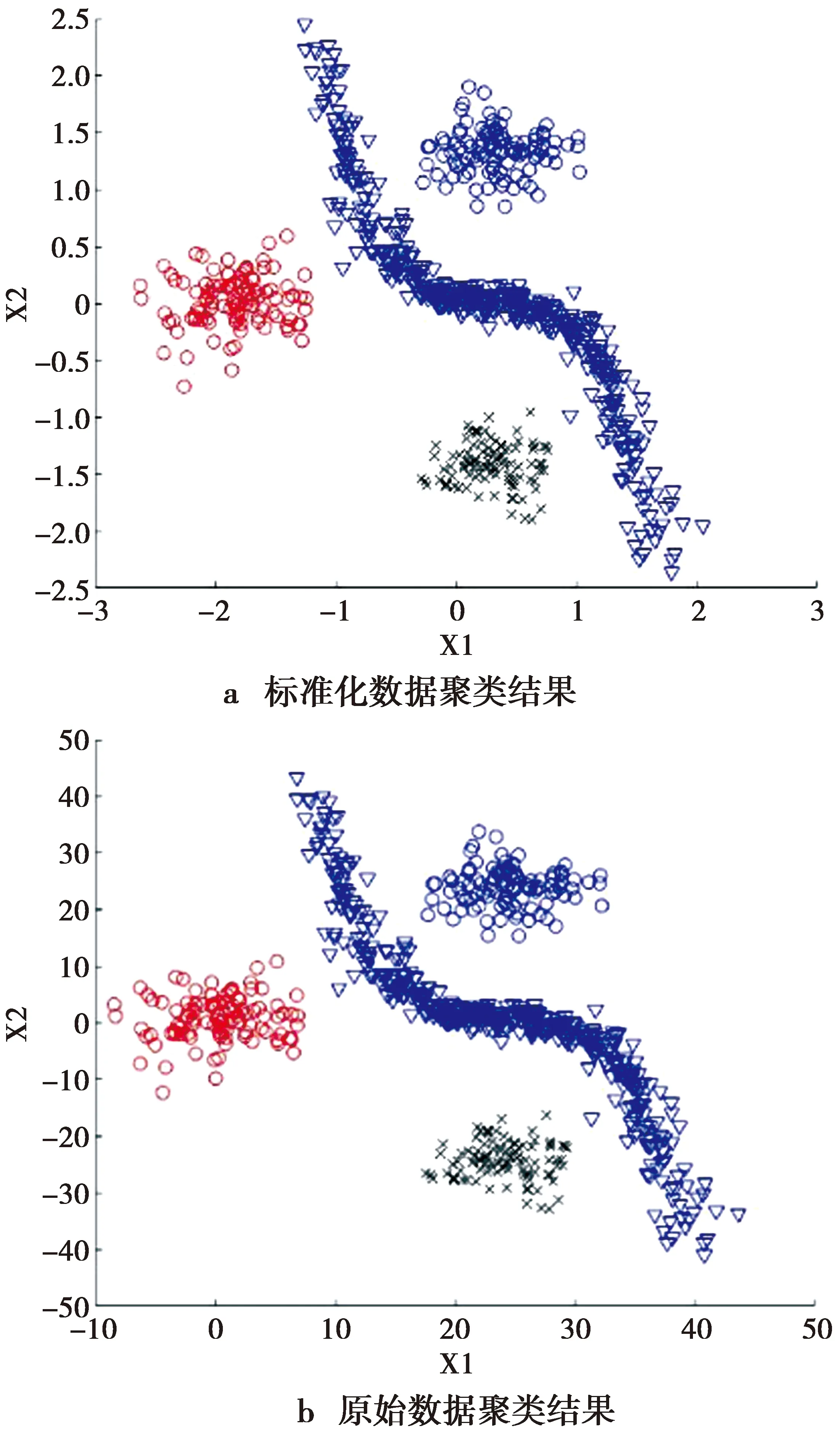
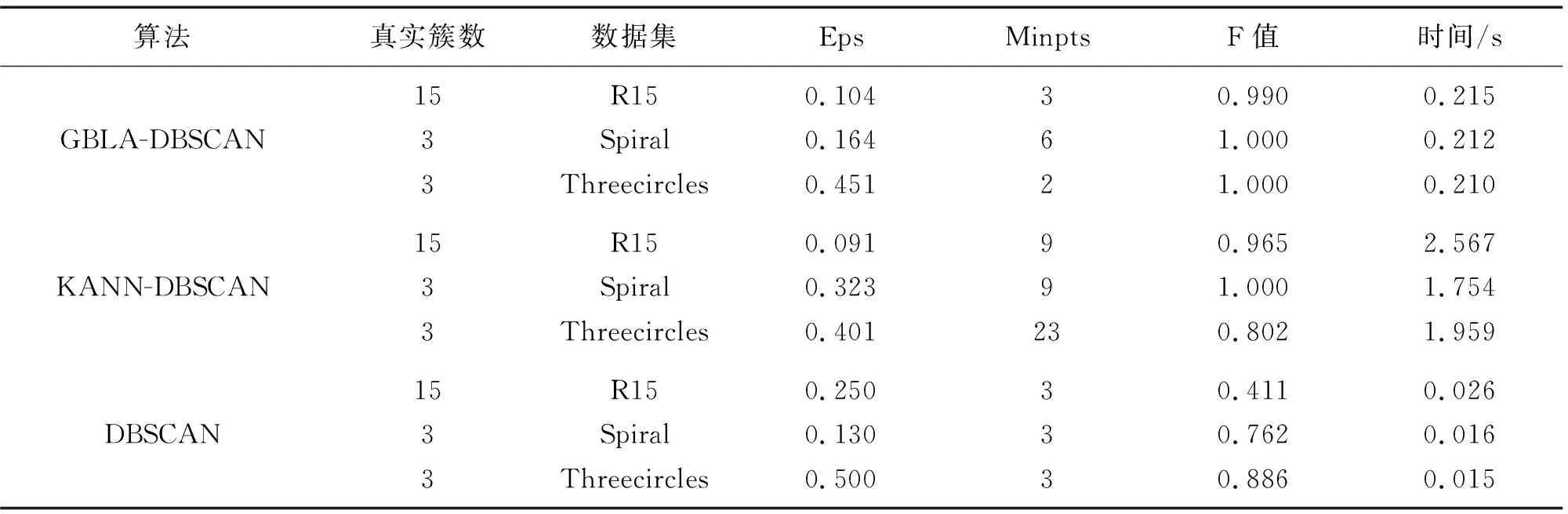
NEps(a) (4) 即边界点的Eps-搜索邻域点个数小于Minpts,则边界点无法继续搜索。边界点作为一个点簇的边界,它和簇内的某些核心点在Eps-搜索邻域内是相互包含的。 噪声点:既不满足核心点条件,也不满足边界点条件的一类点,例如某些孤立点。 由于DBSCAN算法通过逐渐搜索查找来标记3种类型的点,故在查找过程中有3种关于点与点之间密度关系的定义,描述如下。 直接密度可达:设a,b∈D,如果b在a的Eps搜索邻域内并且a为核心点,则认为b从a是直接密度可达。 密度可达:设一系列点c1,c2,c3,…,cn∈D,另外设a=c1,b=cn,如果ci从ci+1直接密度可达,则b从a密度可达。 密度相连:∃c∈D,c到点a和点b都是密度可达,那么a和b密度相连。 经典DBSCAN算法需要预设2个参数,然后计算每个点到其他所有点的距离,并统计距离小于Eps的点个数,如果满足Minpts,则归为核心点,剩下的点如果在核心点的Eps邻域内则归为边界点,否则为噪声点。然而参数的设置具有主观性,对聚类的结果具有较大的影响。并且对于非均匀分布的数据集合,难以确定合适的邻域半径Eps和点数阈值Minpts来保证聚类质量。 通过DBSCAN算法的聚类实验发现,针对子区域存在不同“间隔”的数据集合进行聚类分析时,无法在保证聚类质量的情况下设置合理的参数。于是考虑可以根据各子区域间的距离设置不同的Eps参数和Minpts参数,从而以一种保证局部效果最优的方式来逐渐实现整体聚类。 针对一个对象进行聚类分析时,往往需要使用多维特征进行数据分析。但不同特征的数据数值范围和量纲均不同,使得特征数据相互之间不具有可比性,且会增加误差,因此,不能直接用作聚类分析。为了避免不同量纲带来的数量级差别,并增加不同特征数据的可比性,需要对特征数据进行标准化[12]。一般情况下,不能保证数据完全干净,即可能存在超出范围的离群点,此时可以利用数据的均值以及标准差来消除不同量纲带来的误差。故本文采用z-score标准化(zero mean normalization),给定数据个数为n的数据集X={xi},则标准化后的数值为xi′。 (5) Clouds是一种含有4类共705个对象的二维数据集,如图1所示。后续利用该数据集做分析。 图1 Clouds数据分布Fig.1 Clouds data distribution 假定数据集合X={xi}为d维数据集,且每一维度的数据存在上下界。将该数据集合的每一维数据分成同维等间距且不相交区间,然后联合其他维度的划分区间就形成了网格。网格可能为正方形,亦可能是长方形区域。为了保证网格个数的合理性且保证其受数据的上下界及数据量的控制,经实验发现,如果不做开方处理,受离群点影响,划分的网格数目会剧增,过多的空白网格会影响算法的执行时间,而开放处理折中地削弱了这一影响。故本文定义第i维中的网格边长为 (6) (6)式中,Ubi和Lbi分别为第i维数据的上界限和下界。对应第i维的网格数量为 (7) 建立网格空间之后,将数据映射到网格空间的过程中,不能打乱数据原有的分布,故通过索引的方式将每一个数据映射到对应的网格中。则对于X={xi},对应元素在每个维度具有单独的网格索引,其索引值为 (8) (8)式中,Labeli表示在第i维的特征数据上,从0开始的网格序号。 利用非参数方法的核密度估计方式来计算局部网格的密度,能够更加细致地反映数据的局部分布情况。利用高斯核函数估计单个网格中的局部密度,第i个网格的密度为 (9) (9)式中:d(x-ci)为对应网格中的数据到该网格中心的欧拉距离;lj表示第j维的网格边长。网格分布密度如图2所示。网格越“亮”,代表该网格的局部密度越大。 图2 Clouds网格密度分布Fig.2 Clouds grid density distribution 图3 局部密度分布曲线Fig.3 Local density distribution curve 为了自适应局部Eps,以横向密度分布图为例。可以看出图中a、b、c点位于同一密度波形上,而d点位于另一波形上,可知a、b、c属于同一类别A,而d属于另一类别B。可以发现,通过寻找这种局部“平坦”区域,就可以很好地将不同的类别分割开。根据这种局部现象,定义flag为不同类别的“平坦”段长度。定义A的右半径阈值为 (10) 定义B的左半径阈值为 (11) 根据相同的方式得到B的右半径阈值,则A,B的局部自适应半径参数分别为 (12) (13) 定义A的点数阈值为A区域中的波峰数量,即对图3中a、b、c类型的点有 MinptsA=numpeakA (14) 确定每个子区域的Eps和Minpts之后,从每个子区域的最大密度网格开始使用DBSCAN进行聚类分析。聚类结果如图4所示。将聚类标记结果通过行标对应关系映射到原数据空间,即得到图4b所示的原始数据聚类结果。其中,共生成4个簇,与数据集合原始标记的类别基本相同。这表明GBLA-DBSCAN算法可以根据数据的局部密度自适应Eps参数及Minpts参数[14-17]有效地标记不同区域。 图4 聚类结果Fig.4 Clustering results 本文使用Matlab 2018a实现GBLA-DBSCAN算法。电脑配置如下:Windows 10 Intel(R) Core(TM) i5-9500;CPU@3.0GHz;内存8G。为了验证GBLA-DBSCAN算法的聚类效果,实验中使用分布均匀与不均匀的人工数据集以及合作项目中的放电信号数据集进行聚类分析,并将GBLA-DBSCAN的聚类结果与KANN-DBSCAN、经典DBSCAN算法的聚类结果进行对比分析。 为了验证GBLA-DBSCAN的聚类效果,使用3种人工数据集进行测试,3种数据集的分布如图5所示。R15含有600个数据对象,共分为15个簇;Spiral含有312个数据对象,共3个簇;Threecircles含有299个数据对象,共3个簇。通过GBLA-DBSCAN与其他对比算法的聚类结果进行对比,结果见表1、图6。可以看出,GBLA-DBSCAN能有效地将各子区域划分为一簇,聚类结果与实际类别相差无几。从聚类结果中的F值[18]来看,GBLA-DBSCAN算法使用局部参数使得局部聚类效果最优,从而保证了整体的聚类效果,这使得其F值均优于对比算法,说明GBLA-DBSCAN具有较高的准确性。从算法执行时间来看,在数据量一般的情况下,GBLA-DBSCAN较KANN-DBSCAN低1个数量级。这是由于GBLA-DBSCAN使用了网格划分技术,对数据进行预处理,将其划分为多个数据块,降低了算法的运行时间。 图5 人工数据集分布Fig.5 Distribution of artificial data sets 由图6可见,GBLA-DBSCAN以及KANN-DBSCAN通过各自的自适应策略确定了参数;而经典DBSCAN算法没有参数自适应能力,需通过人为观察设置参数。图6中,Cluster代表聚类后发现的实际簇数。 R15的聚类结果中,数据集本身有15个聚类簇,但是经典DBSCAN的聚类结果仅发现了8个簇。从直观的聚类效果以及聚类结果簇数来看,对R15和Spiral,GBLA-DBSCAN和KANN-DBSCAN算法的聚类效果比较准确。在数据集Threecircles的聚类分析中,KANN-DBSCAN算法最终使用的是全局Eps及Minpts参数,聚类时兼顾了内层数据的标记,效果较好,但是无法兼顾最外层数据,这就是使用全局参数存在的缺陷。而GBLA-DBSCAN使用自适应的局部Eps及Minpts参数,能较好地弥补使用全局参数的缺陷。 表1 人工数据集聚类结果对比 图6 人工数据集聚类结果对比Fig.6 Comparison of clustering results of artificial data sets 基于前文对局部自适应算法的研究,为验证GBLA-DBSCAN算法在真实数据集上的聚类效果,通过真实的UCI数据集,以及校企合作项目中于高压放电场景下采集得到混合放电信号进行了实验,真实数据集聚类结果如图7—图8所示。图7—图8中,Iris是包含150个数据的4维数据集,Wine是包含178个数据的13维数据集,而混合放电信号维度为2且数据对象为126个。 图7 真实数据集聚类结果F值对比Fig.7 Comparison of F-values of clustering results of real data sets 图8 真实数据集聚类结果时间对比Fig.8 Time comparison of clustering results of real data sets 可以看出,本文提出的GBLA-DBSCAN算法在克服了人为选择参数主观性的基础上,其聚类时间介于KANN-DBSCAN和DBSCAN之间,聚类性能较稳定。对于Iris数据集,由于数据集具有多维特征,导致局部聚类时效果一般,但仍不会低于经典DBSCAN算法。 针对二维特征空间而言,经典DBSCAN算法的时间复杂度为O(n2)[8]。本文提出的GBLA-DBSCAN算法,首先划分网格并映射数据,时间复杂度为O(n);然后估计每个网格的局部密度,需要遍历每个点的网格标记,其时间复杂度为O(n);最后,选择局部半径阈值和点数阈值,时间复杂度为O(kn2),k为密度分布的峰值个数。因此,总的时间复杂度为O(2n+kn2)(k≤n)。 经典DBSCAN的空间复杂度为O(n2),GBLA-DBSCAN需要创建网格索引,空间复杂度为O(n)。可以求得GBLA-DBSCAN的空间复杂度为O(n2)+O(n)。 综上所述,GBLA-DBSCAN算法的复杂度较经典DBSCAN算法略高,但是提升了聚类效果,适用于对复杂度要求不高的应用场景。 经典DBSCAN算法使用全局参数,参数选择较主观,本文利用网格划分技术,将二维特征数据映射到划分的网格中,提出了基于网格划分的局部参数自适应DBSCAN聚类算法。该算法有效细致地计算出局部密度,并通过局部密度分布曲线图,自动获取局部Eps及Minpts参数。在保证局部聚类效果的前提下提升了整体的聚类效果。实验证明本文所提方法能够较好地标记各种数据集,虽然聚类所需时间有所增加,但得益于网格划分技术,增加的聚类时间能够控制在可接受范围内。2 GBLA-DBSCAN算法
2.1 数据标准化
2.2 网格划分
2.3 数据映射
2.4 网格密度计算

2.5 局部自适应参数
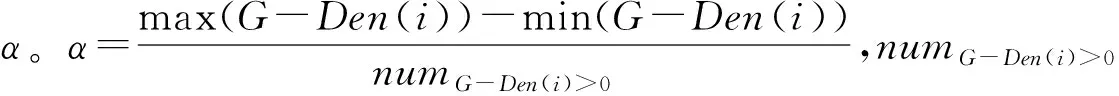

3 实验及分析
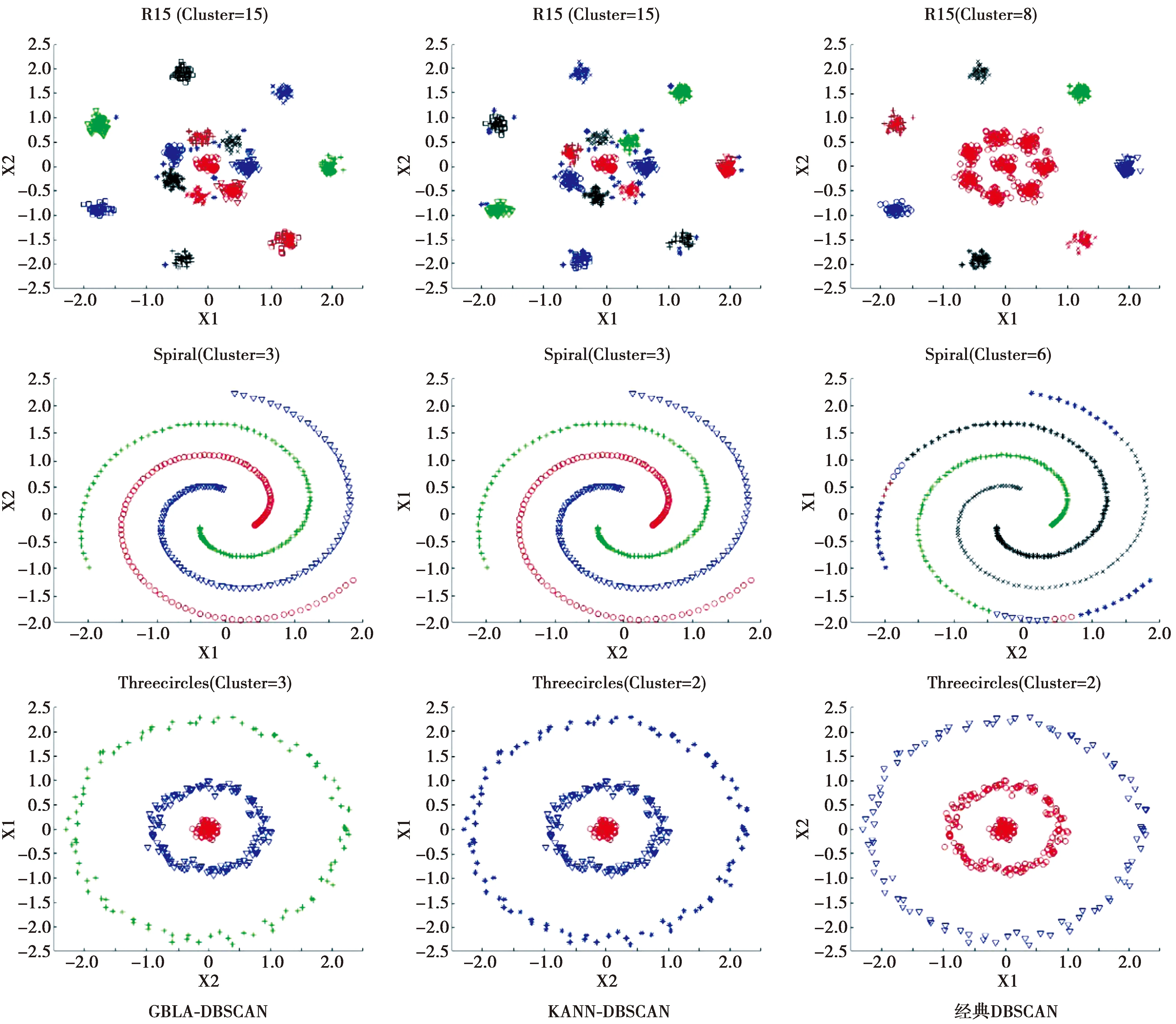
3.1 人工数据集实验结果与分析

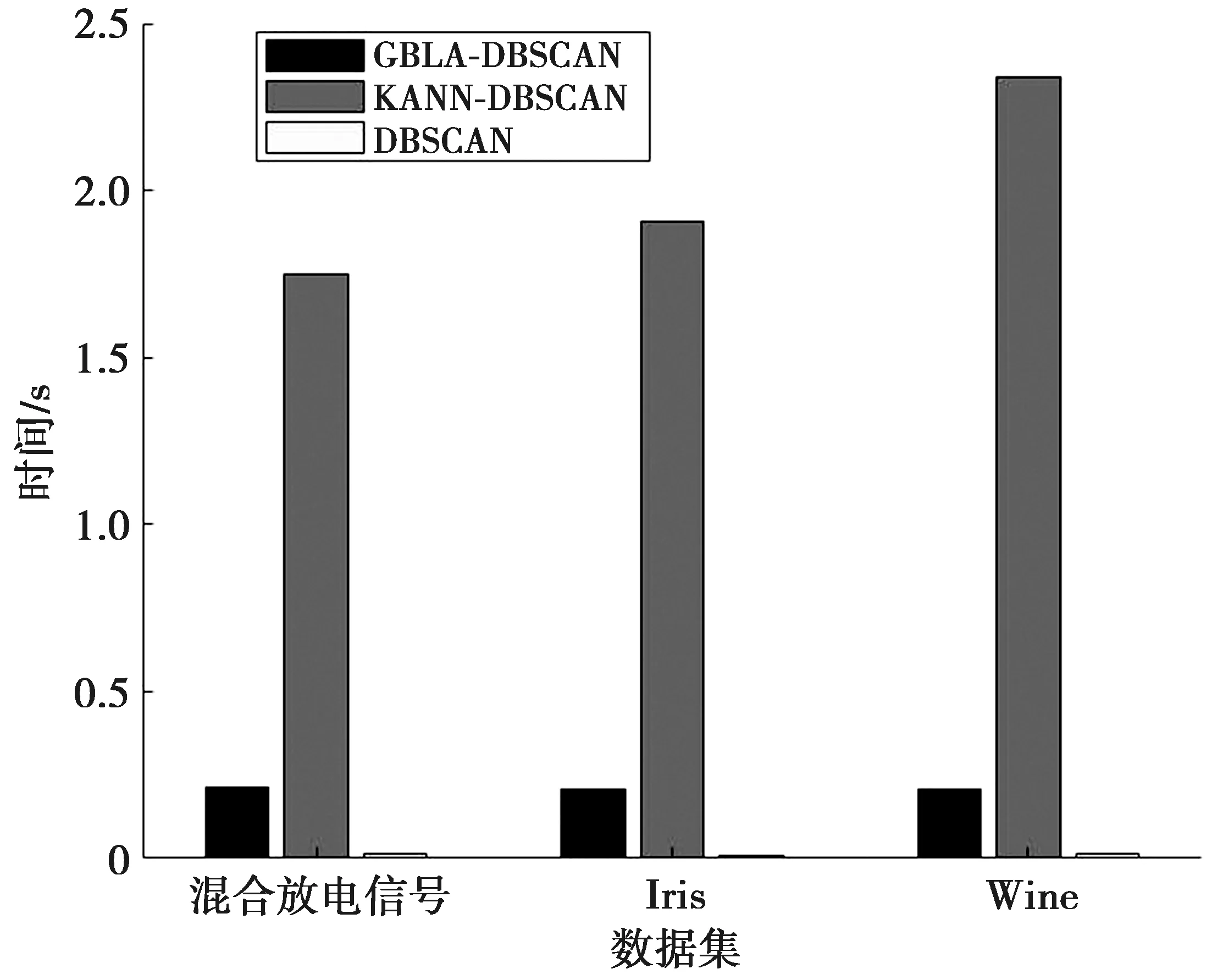
3.2 真实数据集结果与分析

3.3 算法复杂度分析
4 结束语
