基于多种特征融合的微博突发事件检测方法
2022-05-03陈开鑫
夏 英,陈开鑫
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
随着互联网技术发展,微博这种以用户交互关系为核心的社交媒体成为了人们传播及获取信息的重要渠道[1]。文献[2]表明,Twitter能够比其他社交媒体更快地报道事件,而国内的微博与Twitter拥有相似的特点,这使得微博逐渐成为了主要的网络媒体之一。
突发事件是指突然发生,造成或者可能造成严重社会危害,需采取应急处置措施予以应对的事件。及时准确地检测突发事件并采取相应的措施,对于公共安全、文化传播、社会治理等领域具有重要意义。微博平台用户规模大、信息传播快、传播范围广,能够为突发事件检测提供有力的数据支撑。但同时,微博数据具有数据量大、噪声多、以短文本为主、表达方式多样等特点,也给突发事件检测带来了挑战。如何从微博数据中准确地检测出突发事件是近年来的一个研究热点,也是话题检测与追踪的重要分支。
1 相关研究分析
近年来,国内外研究学者在社交网络媒体的突发事件检测中投入了大量研究。现有的突发事件检测算法主要可以分为基于主题建模的方法、以文档为中心的方法和以特征为中心的方法[3-4]。
基于主题建模的方法通过建立概率主题模型来识别信息流中潜在事件,将文本与事件相关联。文献[5]提出TopicSketch模型,当检测到推特流、单词和单词对加速时,模型就会触发主题检测。文献[6]提出Bursty Event dEtection(BEE+)增量主题模型,通过对事件的时间信息建模来发现突发事件。文献[7]提出STMTwitterLDA(Spatio-Temporal Multimodal TwitterLDA)模型,通过文本、图像、位置、时间戳和标签的联合概率分布来检测事件。这类方法能够及时有效地检测出微博中发生的事件,并直接将文本与事件相关联,但计算成本较高,且不能高效处理同时发生的事件。
以文档为中心的方法是计算时间片中的文本相似度,并对文本进行聚类,满足突发规则的簇则为突发事件。文献[8]引入LDA[9](latent dirichlet allocation)主题模型以缓解数据稀疏问题。文献[10]在文献[8]的基础上,对LDA主题模型进行了改进,提出TC-LDA模型去除微博文本中的背景噪声。文献[11]以LDA为基础模型解决了数据稀疏问题,并提取文中潜藏的主题信息。这类方法对于传统媒体的长文本效果较好,但不太适合处理微博短文本,在构建文本特征向量时容易出现数据稀疏问题,且难以消除微博中的广告、链接、网络用语等噪声信息。
以特征为中心的方法通过提取微博特征分布,并根据突发事件周期性来挖掘突发事件。文献[12]将突发事件生命周期按照时序构建“三阶段五点”模型,存在从萌发到高峰最后走向衰弱的过程,如图1所示。文献[13]提出的burst算法,根据文档到达时间将特征分为正常和突发两种状态,在捕获突发特征的基础上检测突发事件。文献[14]计算词的基础权重和突发权重提取突发词并根据聚类算法检测突发事件。文献[15]利用词频、用户关联、地域分布及社交行为,提出微博网络突发值计算模型检测突发事件。文献[16]根据词频、话题标签和词频增长率计算词权重,并利用D-S证据理论和层次分析法检测突发事件。文献[17]通过用户影响力、评论数、点赞数、转发数识别出重点微博然后提取突发词,解决了突发词数难以确定的问题。这类方法是目前比较主流的方法,其核心在于特征选取以及通过突发特征来挖掘突发事件,但依然存在选取何种特征、特征如何应用以及准确率有待进一步提高等问题。
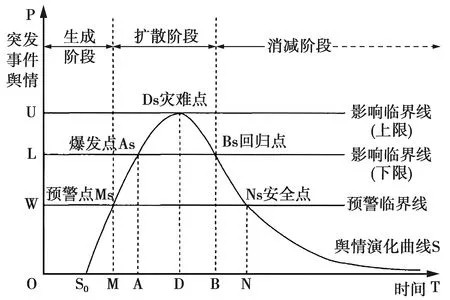
图1 突发事件的舆情生命周期“三阶段五点”模型Fig.1 Three-stage five-point model of public opinion life cycle ofbursty event
大量研究工作将情感作为突发事件检测的特征。文献[18]分析了Twitter上事件与情感间的关系,发现事件的发生与负情绪的增加有关。文献[19]在检测到突发事件后,对情感词分布进行了分析,发现随着事件的爆发与消亡,对应情感也呈相同趋势。文献[20]通过噪声过滤和情感过滤得到包含负面情感的博文,并提出用户活跃度结合突发词检测突发事件。文献[21]利用情感符号来检测突发事件,使用启发式的近邻传播聚类算法对微博文本聚类检测突发事件。文献[22]提出情感结合微博话题标签的突发事件检测模型,从而进一步提高了检测的准确率。以上研究表明,利用情感特征与突发事件之间的关系能够有效地检测到突发事件。
目前的研究成果中,以特征为中心的方法主要通过计算时间段内的文本特征来挖掘突发事件,在计算效率和准确率上有待提升;对于特征的选择大多只考虑了词频与词频增长率,尚不能完全提取突发特征;在检测到突发事件后分析其情感,对于情感的应用还不够充分。本文为了提高突发事件检测的准确率,在现有以特征为中心的方法基础上,提出融合情感特征与微博文本特征的微博突发事件检测方法,并通过实验检验其有效性。
2 多种特征融合的突发事件检测模型
基于多种特征融合的微博突发事件检测模型框架如图2所示,包含情感特征模型的构建、突发期的检测、多种文本特征融合的突发词提取和基于突发词的事件提取4个模块。

图2 基于多种特征融合的微博突发事件检测模型框架Fig.2 Model framework of micro-blog bursty event detection method based on multi-feature fusion
2.1 情感特征模型的构建
突发事件的发展大多与情感相关。基于这一考虑,本文首先以情感特征来检测微博中的突发期,构建情感特征模型。为保证情感分类的准确性,提高检测效率,情感特征模型采用预先构建方式,并随着语料库的增加定期更新。该情感特征模型构建的初始化语料库为NLPIR(1)http://www.nlpir.org/wordpress平台提供的微博数据集。通常微博中的情感符号通过特殊标识“[]”进行文本表示,通过正则表达式抽取数据集中的情感符号,如表1所示。由于许多情感符号表达相同情感,因此采用统计和互信息方法对相似情感进行合并构建情感特征模型。
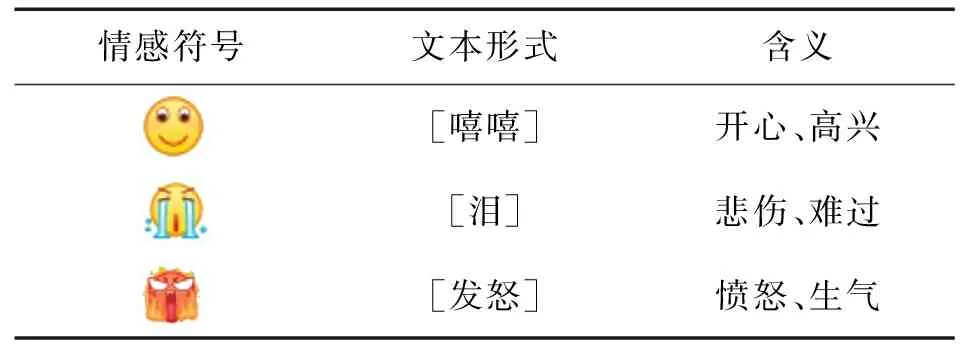
表1 部分情感符号文本转换
互信息是计算语言学模型分析的常用方法,用来度量两个对象间的相似性。互信息越大,相似性越大。这里使用互信息度量情感符号间的相似性,两个情感符emoi和emoj之间的互信息MI(emoi,emoj)可表示为
(1)
(1)式中:p(emoi)、p(emoj)分别表示包含emoi、emoj的微博在语料库中独立出现概率;p(emoi,emoj)表示同时包含emoi和emoj的微博在语料库出现概率。
将相似情感符号进行合并,并选取出现次数大于阈值θ1的情感符号作为情感特征模型。定义情感序列E={ei|i=1,2,3,…},其中ei表示第i种情感,包含一种或多种相似的情感符号。
2.2 突发期的检测
为方便后续讨论,定义时间窗口T,Tn表示第n个时间窗口,时间窗口T对应的微博数据集DT={dti|ti∈T,i=1,2,3,…},其中dti表示微博文本。经分词处理后可表示为dti={wj|j=1,2,3,…},wj为第j个词,ti为微博发布时间。
1)基于情感特征模型的微博情感分类

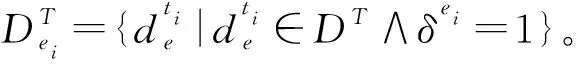
2)基于情感特征的突发期检测
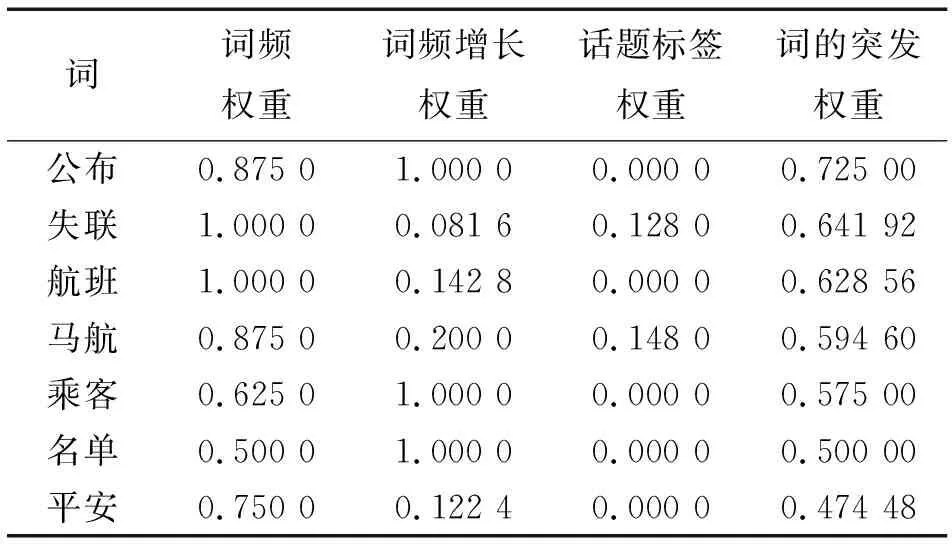
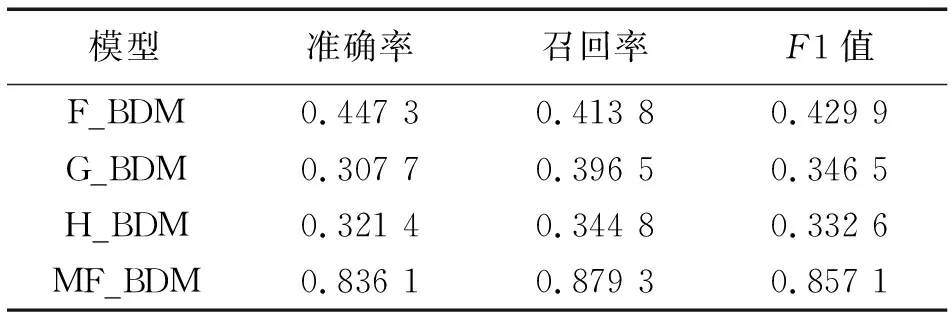
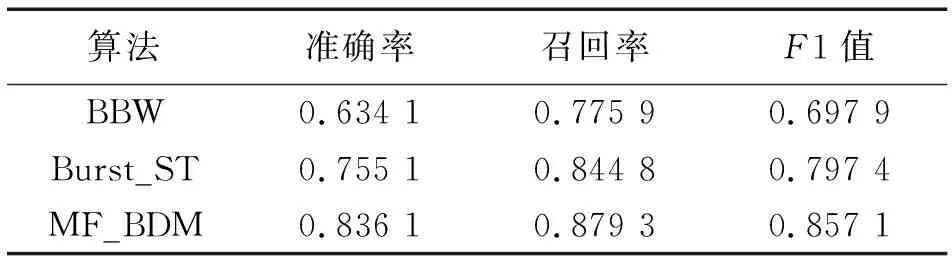
当突发事件发生时,相关文本之间的发布时间间隔变短,Kleinberg[13]算法正是根据文本发布时间将文本分为正常状态和突发状态。因此本文采用Kleinberg算法进行情感特征的突发期检测。该算法通过二元状态机模型对信息流进行建模,普通状态为q0,相关微博发布时间间隔长,对应密度函数f0(x)=a0e-a0x;突发状态为q1,相关微博发布时间间隔短,对应密度函数f1(x)=a1e-a1x,且0 (2) (2)式中,Q为将时间窗口T平均划分的时刻数。 根据突发事件舆情周期相关研究,当突发事件发生时往往会产生相应特征的变化。例如,当突发事件发生时,它在对应时间内被广泛讨论,用户对此进行大量转发、评论,与之相关的微博、词语、话题会快速增长。因此本文考虑从词频、词频增长率、话题标签3个特征来提取突发词。 1)突发词的词频权重计算 词频最能直观地反映词在时间窗口中的重要程度,如果某词频繁地出现在时间窗口中,且频率比其他词更大,在一定程度上说明该词很可能与某突发事件相关联。所以引入词频特征作为提取突发词的特征之一。传统的词频特征计算,通常采用经典的TF-IDF算法,该算法倾向于赋予出现频率高且区分度大的词较大的权重。然而在面向微博这种数量大、文本短的数据时,TF-IDF算法会把多次出现在不同微博中的词赋予较低的权值,从而导致无法检测到正确的突发词。因此对TF-IDF计算方法进行改进,在突发期内,某个词w的词频权重为 (3) 2)突发词的词频增长权重计算 只考虑词频特征来提取突发词还不够全面,还应考虑词频变化趋势。比如运动、娱乐这类热度一直很高的话题,相关词的词频会很高,只考虑词频会将该类词误判为突发词。所以引入词频增长特征作为提取突发词的特征之一。在突发期内,某个词w的词频增长权重为 (4) 3)突发词的话题标签权重计算 话题标签是一种无层次结构的关键词,通常由用户创建,用“#”作为标识符,能够直接反映文本内容,所以与突发事件相关的突发词可能出现在话题标签中,如“#雅安地震#”。因此为了提高突发词提取准确率,引入话题标签特征作为提取突发词的特征之一。以下从两个方面计算话题标签权重。 在突发期内对提取到的话题标签进行分词,分词结果中词w的话题标签权重为 (5) 某些微博没有话题标签,而在微博文本中出现了话题标签中的词,这也对话题标签权重产生了影响。词w的话题标签权重为 (6) 词w的话题标签权重为 H(w)=ε×H(w)1+(1-ε)×H(w)2 (7) (7)式中,ε为权重因子,且ε∈(0,1)。 将词频权重、词频增长权重和话题标签权重加 权计算词的突发权重I(w),计算公式为 I(w)=α×F(w)+β×G(w)+γ×H(w) (8) 微博中突发事件个数难以确定,而聚类算法可以将相似对象放在一起,所以采用聚类算法将相关突发词聚为一类得到突发事件描述。在文本聚类领域,层次聚类算法经常被使用,它不用指定簇的个数,并且能够发现任意形状的簇。因此,采用自底向上的层次聚类算法对突发词进行聚类。该算法初始将每个数据都看成一个簇,然后计算任意两个簇之间的相似度并将最相似的两个簇进行合并,可以适当调整聚合阈值防止过度合并和确定最佳聚类效果。 利用共词分析法计算突发词之间的相似性。共词分析法基于这样一个假设,在语料库中,如果两个词经常共现在同一文本中,则认为这两个词是相互关联的,共现频率越高,相似性越大。如“飞机失联”事件中,“飞机”和“失联”在语义上没有任何相似性,但根据共词分析,它们经常出现在同一微博文本,则认为它们有关联。因此引入词共现矩阵,表示两两突发词之间的相似度,在突发期内如果有N个突发词,则形成N×N的词共现矩阵,突发词之间的共现度越大,则相似度越大、距离越小,越有可能描述同一事件。突发词之间的共现度为 (9) 计算得到突发词之间的相似度后,使用自底向上的凝聚式层次聚类算法对突发词进行聚类实现突发事件的检测,具体算法见算法1。 算法1 自底向上的凝聚式层次聚类算法 输入:突发期内的突发词集W,由突发词构成的词共现矩阵M。 输出:由突发词构成簇的聚类结果clustern。 步骤1:将突发词集内的所有突发词都看成一个簇clusteri; 步骤2:计算任意两个簇之间的平均距离average_distance; 步骤3:找到最小平均距离min_average_distance的两个簇cluster1和cluster2; 步骤4:若min_average_distance小于阈值σ,则合并cluster1和cluster2为一个簇,并返回步骤2,否则输出聚类结果并结束该算法。 用户往往对同一突发事件拥有多元化情感,从而不同情感的事件簇中可能会存在相同事件,因此采用事件相似性度量方法对事件进行合并。对于时间窗口Tn中的情感ei和ej及其对应的突发事件qei和qej,当且仅当满足(10)式时,认为是同一事件。 (10) (10)式中:|qei∩qej|为两个事件相交突发词的个数;|qei∪qej|为两个事件相并突发词的总数。 (11) (11)式中:|qei∩dti|表示突发事件和微博相交词的个数;|qei|表示突发事件中突发词个数。Sim越大,表示突发事件和微博文本间相似性越大。 实验采用由“自然语言处理与信息检索共享平台NLPIR”提供的500万条微博作为实验数据集(2)http://www.nlpir.org/wordpress/category/corpus语料库/。数据集包含微博ID、用户ID、发布时间、正文内容、转发数、点赞数和评论数等必要信息。采用2014年3月1日—31日期间的所有数据作为测试数据集。部分文本数据实例见图3。 图3 微博实例数据Fig.3 Instance of micro-blog data 本文对情感符号进行了统计分析,图4展示了以天为单位包含情感符号的微博文本分布和占有百分比情况。由图4可见,含有情感符号的微博数会随着每天的微博文本总数进行变化,平均值约占总数的36%。这也反映了利用情感符号构建情感特征检测突发事件的可行性。 图4 包含情感符号的微博文本分布情况Fig.4 Distribution of micro-blogs containing emoticons 图5展示了微博数据集中情感符号的出现频数分布。由图5可见,情感符号的分布具有长尾现象,只有少数情感符号出现频数高,大多数情感符号用得比较少。因此选取出现次数大于阈值θ1=200的情感符号构建情感特征模型。 图5 情感符号出现频数分布图Fig.5 Frequency distribution of emoticons 测试数据集中的情感符号也具有长尾现象,如图6所示。由图6可见,大多数情感特征在时间窗口中没有包含微博文本或只包含了极少数的文本,所使用的情感只有少数几个。因此,根据情感文本集包含的文本数量,抽取时间窗口中的主流情感进行突发期检测,可以降低数据规模,提高检测效率。 图6 2014年3月份情感符号出现频数分布图Fig.6 Frequency distribution of emoticons in March 2014 本文按小时进行时间窗口的划分,并将对应时间窗中的数据输入到模型中。经多次实验验证,α=0.6、β=0.2、γ=0.2时提取突发词效果最好。 以3月8日11:00—12:00为例,期间检测到的部分词突发权重见表2。由表2可见,“公布”“失联”“航班”“马航”“乘客”的突发权重高于其他词。上述词在3月1日—20日期间的分布见图7。从图7可以判断,8日当天发生了突发事件。 表2 话题标签权重检测部分结果 本文采用准确率(precision)、召回率(recall)和F1值作为模型评价指标。准确率表示正确检测事件个数占模型检测事件个数的比例,召回率表示正确检测事件个数占数据集中实际事件个数的比例,F1值是对准确率和召回率的综合评价指标,这3个参数取值范围都为[0, 1],值越大表示方法效果越好。计算公式如下。 (12) (13) (14) 图7 突发词词频分布图Fig.7 Word frequency distribution of bursty words 突发词聚类时,簇间相似度阈值σ是事件划分的核心参数。经多次实验验证,阈值σ取13.7到14.5之间的值时聚类效果比其他值更好,对该区间的值进行分析,实验结果见表3。 表3 簇间阈值σ对评价指标的影响 可见,当阈值σ取值14.1时,准确率、召回率和F1值分别到达最高值。分析其原因:随着阈值的减小,虽然检测到的事件更多,但是容易把同一事件的突发词分到多个簇,导致簇中信息过少无法提取到对应的突发事件;而随着阈值的增大,检测到的事件变少,会把多个事件的突发词聚类到同一簇中,导致无法提取出正确的突发事件。簇间相似度阈值σ取14.1,然后对突发词进行聚类检测突发事件,其中正确检测到的突发事件部分结果见表4。 表4 突发事件检测部分结果 可见,本文提出的方法能够比较准确地检测微博中的突发事件。如以“[蜡烛]”“ [泪]”情感特征在2014年3月1日检测到突发词“火车站”“昆明”“暴力”“死亡”“恐怖”,对应的突发事件为“昆明火车站暴力事件”。 图8是2014年3月份“[蜡烛]”“[泪]”情感符号的总频数分布,可以发现出现3个数据峰值,分别对应了1日晚的“昆明火车站暴力事件”、8日的“马航失事”和24日的“马来西亚总理宣布马航飞机坠毁”事件。当突发事件发生时,与之对应的情感特征也会呈突发状态,这也表明了利用情感特征检测突发期的有效性。 以下从两个方面对模型进行实验对比分析。 对比实验一:为了验证每个特征的影响,对以下模型进行实验。 1)F_BDM:该模型仅考虑用词频特征提取突发词。 2)G_BDM:该模型仅考虑用词频增长特征提取突发词。 3)H_BDM:该模型仅考虑用话题标签特征提取突发词。 4)MF_BDM(本文提出的模型):综合考虑词频、词频增长率、话题标签多个特征提取突发词。 图8 “[蜡烛]”“[泪]”情感符号总频数每日分布Fig.8 Total frequency distribution of emoticons for “[candle]” and “[tear]” 实验对比结果见表5。 表5 不同模型实验结果对比 由表5可见,MF_BDM模型的准确率、召回率和F1值最高。分析其原因:F_BDM仅考虑词频,会提取到词频高但没有实际价值的词;G_BDM仅考虑词频增长,会将无意义的新词认为是突发词;H_BDM仅考虑话题标签,而很多突发事件相关微博没有使用标签,还有一些话题标签是无用的标签;而MF_BDM从多种微博文本特征融合提取突发词,较大程度上弥补了其他模型的缺陷,因而取得更好的结果。 对比实验二:为了进一步验证本文方法的有效性,与文献[14]提出的BBW算法及文献[22]提出的Burst_ST算法进行对比。BBW算法根据改进的TF-IDF计算每个时间窗中的基础权重和突发权重提取突发词,再根据获得的突发词聚类检测突发事件,是比较经典的算法; Burst_ST算法是目前以特征为中心的方法中效率较高的算法,它将情感特征与微博话题标签相结合检测突发事件,具有一定的可比性。实验对比结果见表6。 由表6可见,本文提出的方法准确率和F1值都有较大的提升,召回率有较小的提升。分析其原因:BBW算法需在每个时间窗内计算基础和突发权重后提取突发词,并不能完全提取到突发词,而本文算法只需在突发期内提取突发词,不但能提高效率同时还能更加准确地识别突发词;Burst_ST算法根据微博中的话题标签和新闻标题检测突发事件,但很多微博文本没有话题标签,或者包含一些无用的话题标签,而本文算法引入了词频和词频增长率,提高了检测准确率。 表6 不同算法实验结果对比 突发事件的检测普遍应用于公共安全、舆情监测、社会治理等领域,从微博中准确检测突发事件对社会稳定和公众利益具有重要意义。针对微博文本数据量大、噪声多、以短文本为主等特点,结合突发事件发生时对应的情感特征同样呈突发状态这一判断,本文提出了基于多种特征融合的微博突发事件检测方法。该方法在解决了微博数据稀疏性问题的同时,融入情感特征及微博文本特征,从而提高事件检测准确率。实验表明,该方法能够准确地检测到微博中的突发事件,相对于其他方法,准确率和召回率都有所提升。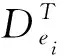
2.3 多种文本特征融合的突发词提取

2.4 基于突发词的事件提取
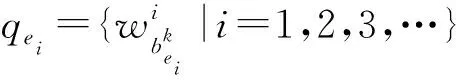
3 实验及分析
3.1 数据集
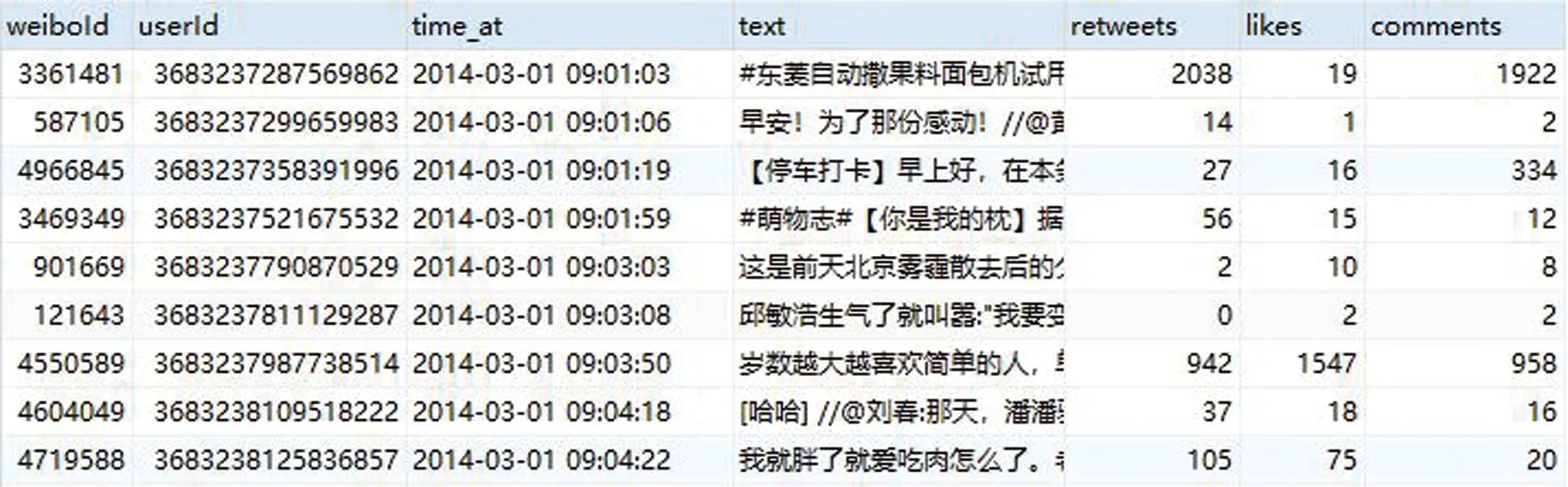
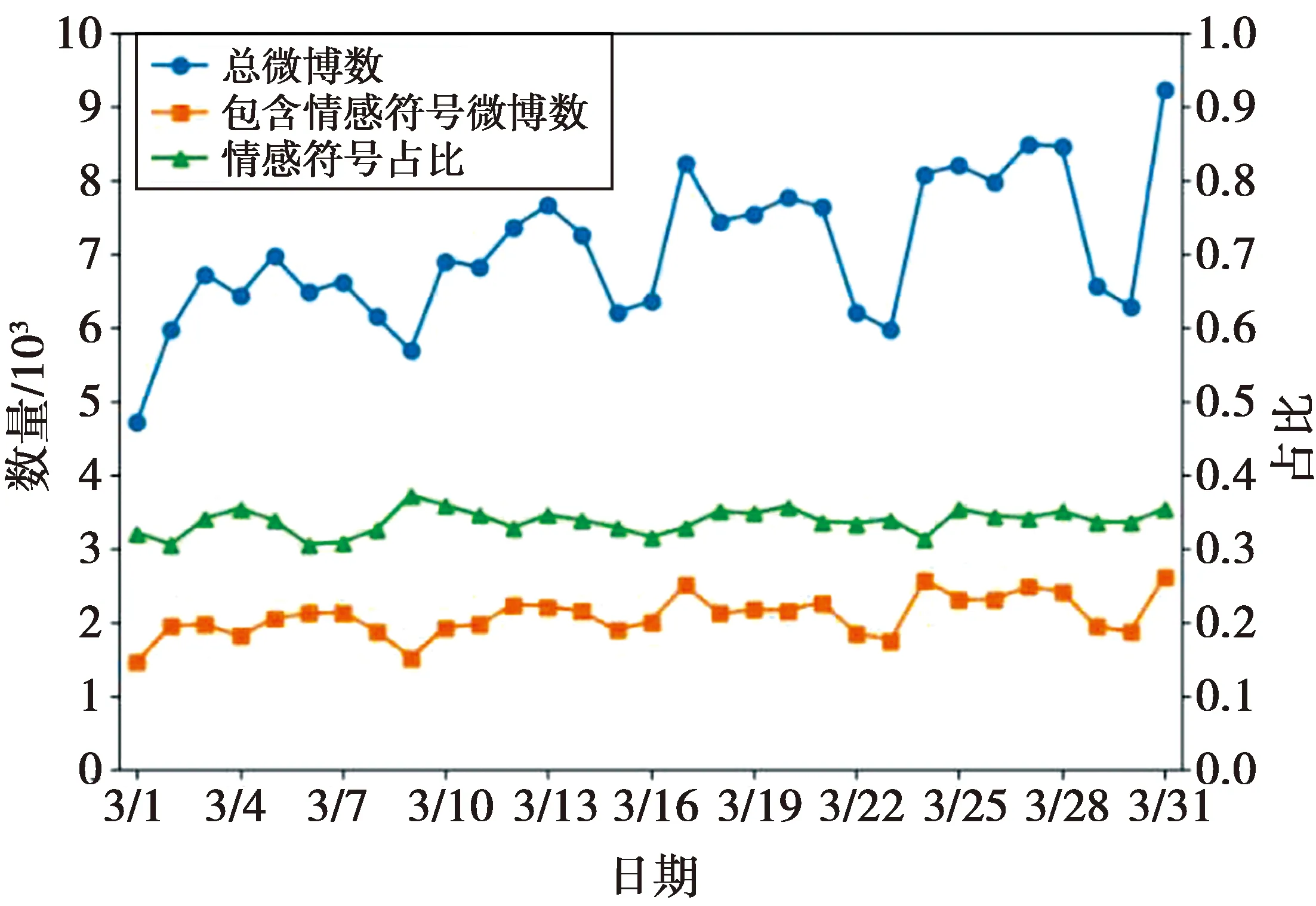
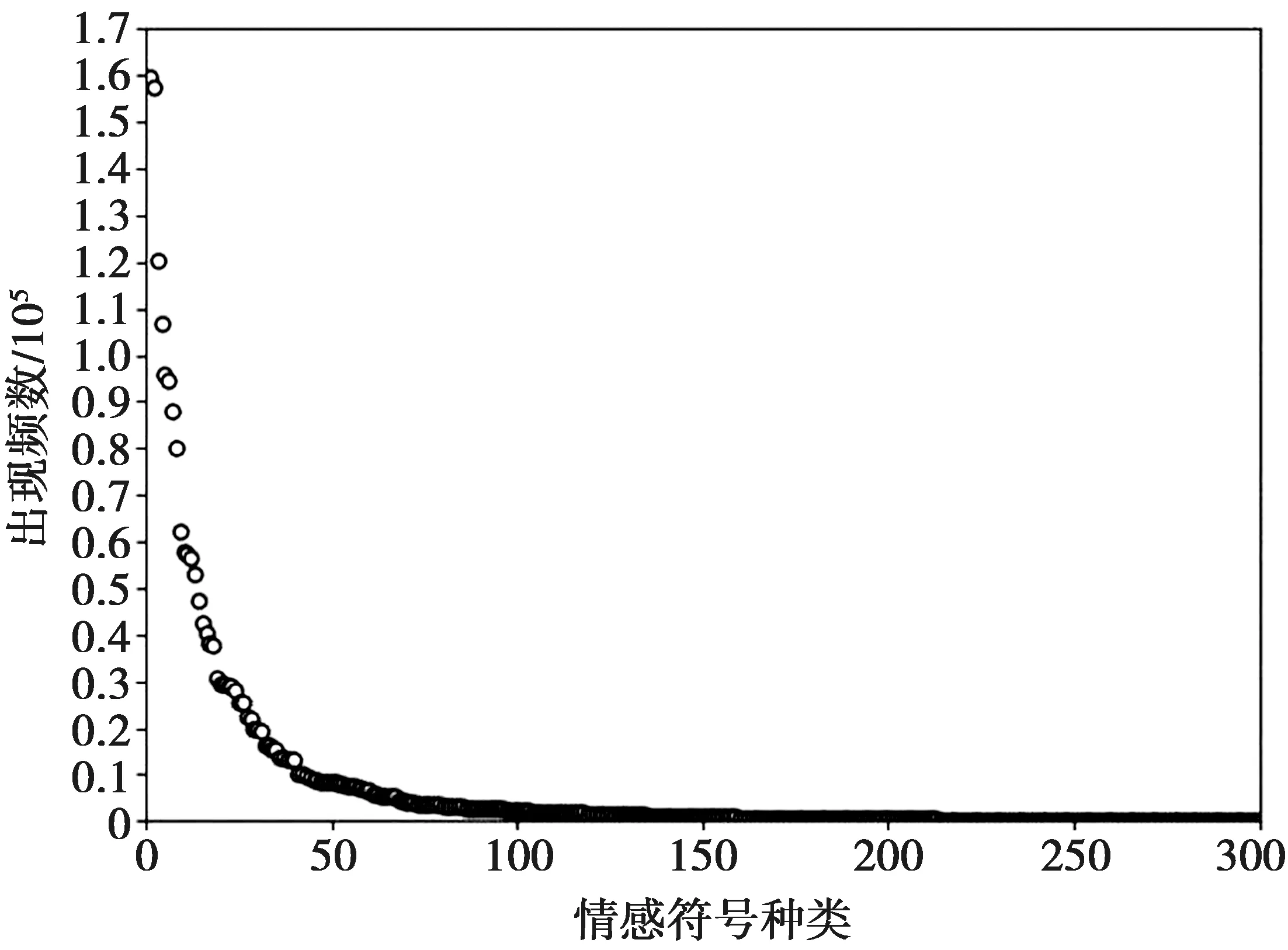

3.2 实验结果及分析





3.3 实验对比分析

4 总 结
