一种基于特征融合与评分反馈的CQA专家推荐方法
2022-04-27司恩鹏王鲁豫李浩杰杜军威
司恩鹏,王鲁豫,李浩杰*,杜军威
(1.青岛科技大学 信息科学技术学院,山东 青岛 266061;2.山东省实验中学,山东 济南 250001)
基于社区问答服务(CQA,community-based question answering)通过用户之间的问答交互打破了传统的基于关键词的在线信息搜索模式。随着CQA热度的不断上升,社区中收录的问题也在飞速增长[1],然而一方面,存在海量用户提问的问题未得到解答,另一方面,具备问题解答能力的用户也无法有效的发现自己感兴趣的问题,这极大地影响了用户解决问题的效率和对社区的忠诚度。因此,面向问答社区的专家推荐成为近十几年研究的热点。
面向问答社区的推荐任务主要分为两类,其一是为问题推荐已有的答案,其二是为问题推荐能够回答的专家。前者主要通过发现历史中相似且已解决的问题进行答案推荐[2-3],但由于多数问题文本较短,问题编码难以准确表达问题语义信息,导致问题匹配准确率较低。同时,随着历史没有解答的新问题逐渐增多,基于问题匹配的检索推荐模式已经无法满足CQA快速发展的需求,因此急需为新问题推荐合适的专家回答者[1]。
目前主流的CQA专家推荐方法仅从局部视角如问题和答案的文本特征[4]、社交网络特征[5]、答案反馈信息等进行特征提取。例如,LIU和RIAHI等[3]分别利用LDA和STM生成主题向量来构建用户和问题的文本特征,融合了语言模型和LDA主题向量模型来对潜在回答者兴趣进行建模,解决了无法利用更高级语义的缺陷,一定程度上提高了推荐准确性。但是,基于文本的研究方法,忽略了除文本之外建模问题与用户的其他重要异构信息。
利用专家推荐的方法旨在由用户的问答关系推荐最具权威性的用户作为新问题的回答专家,专家推荐主要分为基于社交网络或基于协同过滤或基于分类。ZHANG和JURCZYK等[5-6]基于社交网络分别通过Indegree、Pagerank、HITS表征用户影响力和权威性,构建问答社交网络特征,并为问题推荐最具权威性的专家;基于协同过滤的专家推荐主要使用矩阵分解算法,例如,YANG等[7]采用概率矩阵分解(PMF)方法结合生成概率模型和矩阵分解的方法来推荐问题。但是,协同过滤算法存在数据稀疏和冷启动问题,限制了该类方法的应用场景,相较于上述角度,基于分类的推荐方法能够综合考虑用户、问题、答案或用户间交互等特征组合进行灵活建模,因此具有更好的鲁棒性。WANG等[8]除了从问题和用户的角度构造特征,还引入了文本相似性作为特征,证明了文本相似性对实验结果具有积极作用。诸如此类的专家推荐方法,没有充分考虑不同特征的融合对推荐的影响,而本研究结合用户、问题、答案或用户之间交互关系综合构造特征,相较于其他方法能更全面地评估回答者和问题间的偏好关系[1,8],同时验证了不同特征组合对最终推荐效果的影响。
然而,从多角度提取特征的传统分类方法,在正负样本划分时存在不合理性,其主要采用如下方式:构造形如〈Question,User〉的二元组,当User为该问题的回答者时,该样本为正样本,当User为该问题的提问者时,该样本为负样本[9-11]。这种样本构造模式,忽视了提问者本身也可能是回答者的情况,同时也没有考虑答案质量;WANG和TIAN等[12]将具有Best Answer标签的回答者作为问题的正样本,一定程度上考虑了回答者答案的质量,但由于每个问题只能有一个Best Answer,其他答案质量接近Best Answer的回答者也被作为负样本,因此无法细粒度地评价每位回答者的能力。除此之外,由社区投票机制产生的得分信息也可以作为一种评估问题和答案质量的有效方法,并且相比于传统的样本划分标准,细粒度的投票评分更为客观合理。因此,本工作采用投票得分这种细粒度的反馈评价作为用户回答能力的量化指标。
本工作利用用户对答案的反馈评价作为答案质量细粒度评分,从问题、答案、回答者、社交网络等多个角度提取特征,设计了一种考虑特征组合和交互的FM回归模型进行专家推荐,在爬取的Stack Overflow有关java领域的数据集上按真实时间序列进行专家推荐[3],与主流基准算法进行对比,验证本工作方法的有效性。
1 特征融合的CQA专家回答者推荐方法
1.1 方法概述
本工作旨在从多角度提取特征并对不同特征进行组合,设置消融实验探索各特征组合对推荐效果的影响,并利用用户对答案的反馈评价对答案质量进行细粒度量化。最终设计一种结合最佳特征组合与细粒度评价反馈的FM预测模型完成专家推荐任务。基于特征融合与评分反馈的专家回答者推荐方法框架见图1。

图1 基于特征融合与评分反馈的专家回答者推荐方法框架Fig.1 Framework of expert responder recommendation method based on feature fusion and rating feedback
如图1所示,本工作研究框架主要包含如下几个部分:
1)在Stack overflow社区问答平台中抽取并建立结构化数据,将其存储为〈问题,提问者,回答者〉三元组形式。2)从问题、用户、文本匹配、社交关系等角度提取特征,建立问题(Q)、回答者(A)、问题-回答者文本(QA)、提问者-回答者社交关系(AA)特征集合并对特征进行编码。3)设置消融实验结合FM算法探索不同特征组合的重要性,训练模型确定最佳特征组合。4)针对粗细两种反馈评价在MRR与S@N上对比推荐效果,选取细粒度反馈作为最终评价标准。5)用FM模型结合最佳特征组合与细粒度反馈评价来生成专家推荐列表,完成推荐任务。
假设将数据集划分成4个特征集合,分别为问题特征集QuestionQ=〈q1,q2,…,qn〉,回答者用户特征集AnswerersA=〈a1,a2,…,am〉,问题-回答者文本特征集Question-AnswererQA=〈qa1,qa2,…,qak〉以及提问者-回答者社交关系特征集Asker-AnswererAA=〈aa1,aa2,…,aal〉。本工作的任务是为新问题推荐合适的回答者。将每一个实验样本表示为〈q,a,qa,aa,score〉,其中q∈Q,a∈A,qa∈QA,aa∈AA,score∈[0,1]。研究目标是学习一个映射关系,使得f:(q,a,qa,aa)→R。其中,在f(q,a,qa,aa)中获得最高分的用户a∈Answerer将被预测为问题q的最佳回答者。
1.2 特征选取
考虑到本工作是为新问题推荐回答者,在构造样本特征时,选取问题样本格式为〈q,a,qa,aa,score〉五元组,其中分别包含问题特征集(Q)、回答者用户特征集(A)、问题-回答者文本特征集(QA)、以及提问者-回答者社交关系特征集(AA)4个部分。样本构造中丢弃了历史问题的答案信息,这是因为新问题的回答者推荐是一个冷启动任务,新问题不存在答案信息。因此本工作构建样本的主要特征如表1所示。

表1 模型主要特征Table 1 Main features of model
1.2.1 问题特征集Q(1~7)
问题标题长度可以被认为是衡量问题质量的重要特征,换句话说,高质量问题较容易被回答[13];问题文本中网站内部链接数量(特征Q_5)也被认为是反应问题质量的重要因素[14]。其中,对问题ID(Q_1)和问题标签(Q_7)类别特征分别采用one-hot编码和multi-hot编码。对于连续特征Q_2~Q_6,考虑到Q_2~Q_6特征均呈现长尾分布特点,为了提升特征表达能力并更适合本工作设计推荐模型,采用等频分箱进行离散化,并生成one-hot编码。
1.2.2 用户特征集A(1~12)
考虑采用用户发布问题数量(特征A_7)和答案数量(特征A_4),来建模用户的社区参与度。如果用户提供了较多的问题或答案,则认为该用户在社区中是活跃的,乐意与其他用户分享知识和探讨问题,相较于不活跃用户,其为其他用户解答问题的可能性更高。另外,考虑采用用户荣誉值(A_2)、获得徽章的评分(A_3)、发布答案平均得分(A_10)和发布最佳答案比例(A_6),来建模用户的知识专业性。如果用户有较高的发布最佳答案的比例(特征A_6),那么认为他将在社区中提供的答案也更大概率是“Best Answer”。同时,用户的注册年龄(特征A_12)也是衡量问题质量和回答质量的重要特征,注册时间短的用户相较于注册时间长的用户,产出优质答案的概率要小。其中,除回答者ID(特征A_1)为类别特征之外,其余均为连续特征。因此分别采用与问题特征集Q相同的处理方法。
1.2.3 问题回答者文本特征集QA(QA_1)
在问题回答者特征构造方面,传统的CQA服务多基于用户历史回答过的问题文本表征回答者知识特征,基于LDA算法探索新问题和用户个人资料在主题分布上的相似关系,从而为新问题生成最佳回答者用户列表[3]。本工作采用特征QA_1表示问题和回答者之间的文本相似程度,因其为连续特征,所以采用同问题特征集Q一样的处理方法。
1.2.4 提问者回答者社交关系特征集AA(1~3)
在以回答者为起点、提问者为终点的有向用户社交网络中,PageRank算法通过估计节点在网络中随机游走(以及偶尔的随机跳跃)访问其他节点的可能性,来表示用户可能回答其他用户提出问题的概率[15]。不同于PageRank,HITS将网络中的节点分为两种类型,每个节点对应两个得分,分别是表示节点用户回答质量的hub分数和表示节点用户专业知识程度的authority分数[5],从而可以对用户进行更加全面的评估建模。因此,本文用连续特征AA_1~AA_3表征用户之间的社交关系,同样采用等频分箱进行离散化,并生成one-hot编码。
1.3 算法描述
1.3.1 因子分解机FM
FM借鉴了矩阵分解隐向量的思想,为每一个交互特征学习一个隐权重向量(latent vector),在特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重。这样不仅可以自动地交叉得到二阶特征,还克服了数据稀疏性问题。其表达式为

其中,ω0为全局偏置,ωi是模型第i个变量的权重,ωij=〈vi,vj〉是特征i和j的交叉权重,vi是第i维特征的隐向量,n代表特征数,k(k≪n)为隐向量的长度,包含k个描述特征的因子。
〈..,〉代表两个k维隐向量的点积:

为训练FM模型,求解如下优化问题:

其中S表示训练集,λω0、λω、λV分别表示三类模型参数对应的正则化系数,避免噪音样本带来的扰动。
对于优化问题(3),本工作利用随机梯度下降法求解权重参数,迭代公式如下:

其中η为学习率。式,由于与变量i相互独立,因此可以预先计算得到,且vi,f的训练只需要样本xi特征非0即可,适合于稀疏特征。每个梯度的计算时间复杂度都为Ο(1),模型的参数总数量为nk+n+1,在数据稀疏条件下,参数更新所需要的所有时间为Ο(kn)。
1.3.2 基于特征融合与评分反馈的FM
本工作中的特征向量<q,a,qa,ua>非常稀疏且为新问题推荐的冷启动问题,不适合采用传统基于协同过滤的推荐方法。FM算法能够降低交互向量特征维数,且能够自动学习任意二维交叉特征,减少了大量的特征选择工作。本工作构造的特征为稀疏特征空间样本集合,因此,设计使用FM算法来完成推荐任下:
如1.2.2小节中介绍,对整理后的结构化数据进行特征提取,构造4类特征集合,在其基础上设置6组特征组合并采用FM算法进行消融实验,研究不同特征组合的选取对评分预测精度的影响从而确定最佳特征组合。设置对比实验进一步研究将投票得分作为细粒度反馈评价与仅区分Best Answer与否的粗粒度反馈评价对专家推荐效果的影响。最终采用结合最佳特征组合与细粒度反馈评价的FM推荐方法与其他基准方法进行实验对比,验证本工作模型在社区问答领域专家推荐效果的有效性与优越性。
2 实验及结果分析
2.1 数据集
Stack Overflow 2018年年度开发人员调查报告显示,在2018年java是该社区中广受欢迎的开发语言,因此本工作收集了2018年Stack Overflow网站中所有有关java主题的问题。
首先将爬取到的数据以〈question,asker,answerer〉三元组形式存储,共计样本17万余条。随后,剔除含有部分不规则或无效的样本记录,选择至少有4个答案以上、拥有Best Answer且提问者和回答者均为已注册用户的问题作为最终实验数据。最终合计共20 236条实验样本,其中包含问题4 450个,回答者10 444人。经数据处理后的实验数据集详细统计信息如表2所示。

表2 Stack overflow数据集统计Table 2 Statistics of stack overflow dataset
2.2 投票得分与Best Answer相关性研究
为了验证由社区投票机制产生的得分信息对提供更加细粒度的评价标准的合理性,采用VoteRank对答案的投票得分与Best Answer之间的相关性进行分析,即在问题q中根据评分大小选择Top N回答者作为其“Best Answerer”,然后统计Top N回答者(N=1,3,5)包含Best Answerer答案的比例。如图2所示,约68%的Top1是Best Answer,Top3中87%是Best Answerer,Top5中93%是Best Answerer。这表明Best Answerer与答案反馈评价具有强相关,因此采用答案的投票得分来量化答案质量具有充分的合理性。
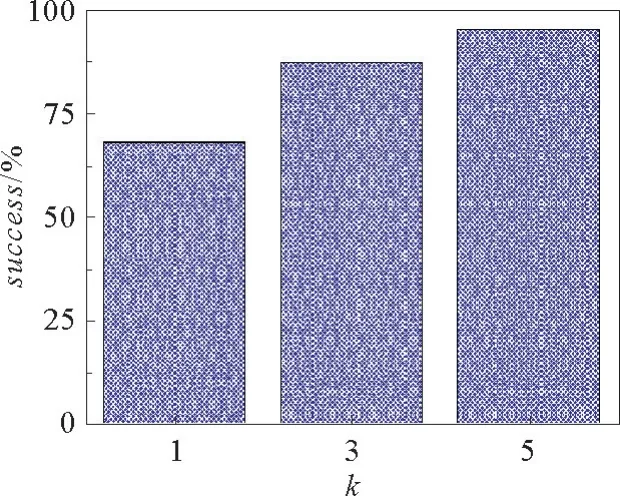
图2 在数据集上VoteRank的S@N(N=1,3,5)Fig.2 S@N of voterank on dataset(N=1,3,5)
此外,为了保证标签取值在统一范围,本工作将每个问题的答案反馈评价采用归一化方法归至[0,1]区间。
2.3 按时间序列划分数据集
本工作根据问题发布时间进行训练集和测试集的划分[3,16]。为了保证不同数据在划分方法上的一致性,对共计12个月的所有问题进行迭代划分,并记录不同数据划分结果的平均水平,具体划分结果如表3所示。
由于本工作实验分为两个阶段:评分预测和专家推荐。第一阶段是探索不同特征组合对评分预测精度的影响,第二阶段是结合最佳特征组合为新问题推荐回答专家。因此,针对不同的任务,测试集构造有所不同。评分预测阶段测试集构造如表3所示;在专家推荐阶段,每个问题仅保留一个正样本(即问题的最高分回答者),并在训练集中随机负采样,和正样本一同作为候选用户集。另外,为了验证在不同大小候选集上的推荐效果,本工作随机负采样生成长度分别为5、10、15、20、25、30、35、40、45、50的候选集。
值得注意的是,得益于本工作的特征设置,该方法不仅可以为新问题推荐老用户(训练集中出现),也可以推荐新用户(训练集中未出现),使得该方法能够完全克服CQA领域中棘手的冷启动问题。
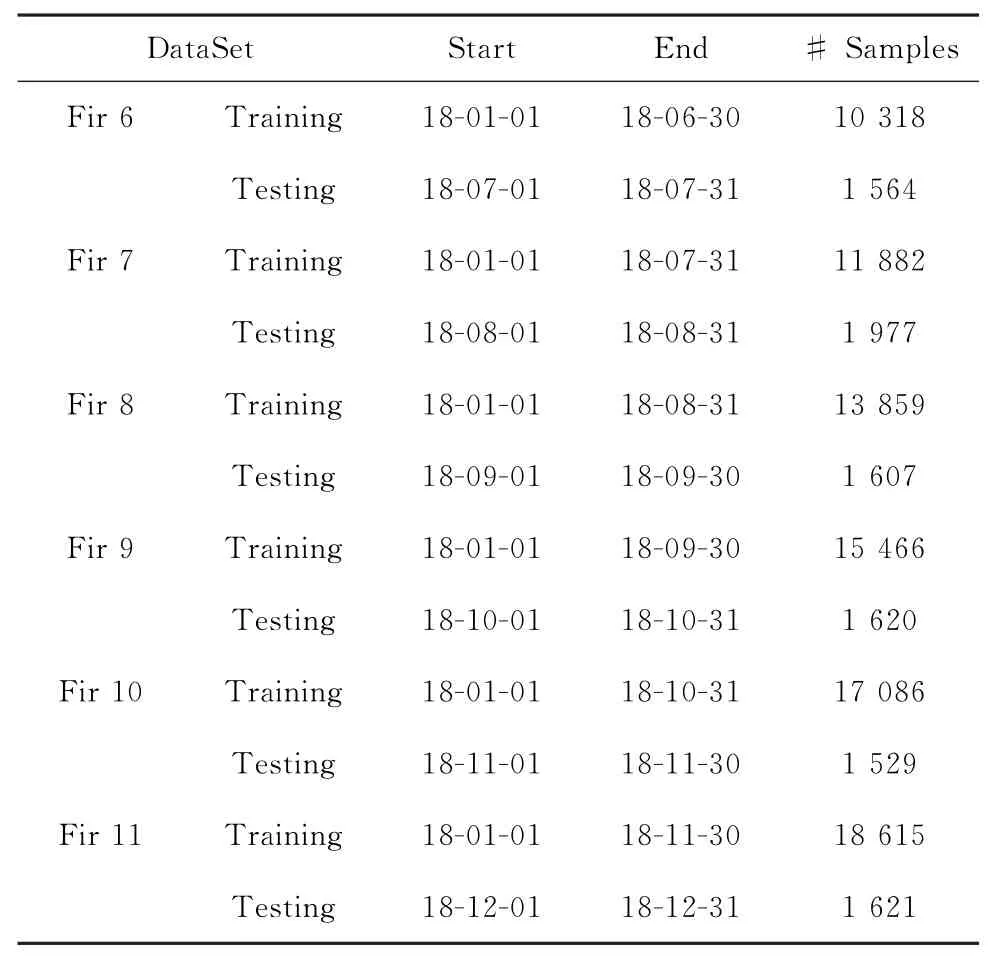
表3 数据集划分Table 3 Division of dataset
2.4 对比方法
2.4.1 LDA
根据问题文本和回答者历史回答问题的文本集合,采用主题数为30的LDA模型,采用余弦相似度计算相似度,由高到低对候选用户排名,并生成推荐列表[3]。
2.4.2 MF
针对为新问题推荐回答专家的冷启动问题,通过计算文本相似度,采样与新问题最相似的3个历史问题,并将其拟合训练阶段得到的问题隐向量加权平均作为待推荐问题的隐向量表示,与用户隐向量作点积获得用户在新问题上的预测评分,从而生成推荐列表。
2.4.3 SVM
采用与FM实验相同的特征,只是采用传统的CQA专家推荐分类标签,将“Best Answer”标记为正样本,将非“Best Answer”标记为负样本,采用SVM方法实现分类预测[1,16]。
2.4.4 LR(linear regression)
采用LR方法,对每一个新问题的候选回答者用户集预测评分,依据分数高低返回回答者推荐列表,探索引入细粒度评分是否能提升推荐的准确性。
2.4.5 FM
通过消融实验确定最佳特征组合,设计FM方法,对每一个新问题的候选回答者用户集预测评分,依据分数高低返回回答者推荐列表,探索引入特征交互和细粒度评分是否能显著提升推荐的准确性。
2.5 评价指标
在评分预测阶段,本工作采用MAE(平均绝对误差)、MSE(均方误差)来评价预测结果。在用户推荐阶段,本工作基于CQA中的专家推荐的几种流行的评估标准,评估本工作提出方法的性能。分别为MRR(mean reciprocal rank)[11]、S@N(success@top N)[9]。定义如下:

其中,Q表示测试集,Q表示测试样本的数量,q表示测试集中的每一个样本,N表示生成的推荐列表的长度,表示第i个问题中Best Answer用户在推荐列表中的顺序,ranki同,特殊地,当ranki未出现在推荐列表中时,定义ranki=0。对S@N,当时,表示该样本预测成功。
2.6 实验结果及分析
2.6.1 消融实验
在评分预测阶段,为了验证特征组合的的预测效果,采用消融实验,迭代地将不同组特征引入到FM算法中,来探求不同特征组合的重要性。
本工作设计5个方面的Basic、Question(Q)、Answerer(A)、Question-Answerer(QA)、Asker-Answerer(UA)特征组,分别设置了以下6组对照组合Basic、Basic+Q、Basic+A、Basic+Q+A、Basic+Q+A+QA、Basic+Q+A+QA+UA进行对比。
实验结果如图3所示,可以得出:
Basic+Q和Basic在2个评价指标上的表现大致相同,表明加入问题特征Q仅仅丰富了对问题建模的复杂性,对评分拟和效果没有太大提升。
Basic+A相比于Basic,在2个评价指标上略有提升,表明加入用户特征A只是提高了用户建模的精确度,对评分拟合效果有一定提升但不明显。
Basic+Q+A相较于Basic、Basic+Q和Basic+A,在2个评价指标上有显著提升,表明问题特征Q和用户特征A的同时加入,能够使得问题和回答者建模更精准,同时问题和回答者之间的特征交互也可以挖掘出两者之间的潜在关系,明显提高了模型的评分拟合能力。
Basic+Q+A+QA相较于Basic+Q+A,拟合效果进一步提升,表明QA特征的融入可以帮助模型从语义匹配的角度,更好地丰富问题和回答者两者间的内在关系。

图3 消融实验结果Fig.3 Results of ablation experiments
Basic+Q+A+QA+UA相较于Basic+Q+A+QA,拟合效果非但没有提升,反而有一定程度的下降,表明UA特征的加入扰动了原有模型的稳定性,说明用户社交关系并不能完全体现用户之间问答的意愿,较为活跃的用户并不是在所有问题上都有较强意愿予以回答,而仅仅倾向于个别知识领域的问题。因此,确定Basic+Q+A+QA为最佳特征组合。
2.6.2 专家推荐
本工作通过消融实验确定了模型所需的最佳特征组合。进一步探索细粒度评分反馈评价和粗粒度0、1分类(Best Answer--1,非Best Answer--0)对推荐结果的影响。
粗粒度反馈评价,即将Best Answer作为预测正标签,其余作为负标签;细粒度反馈评价,即将Best Answer作为预测真实标签,保持其余用户分数不变。显然,前者仅关注Best Answer,而后者通过分数来量化不同用户的回答能力。为探索两种反馈评价对推荐结果的影响,采用FM就相同数据集和相同特征做对比实验,前者预测候选用户为Best Answer的可能性,然后依此降序生成推荐列表;后者预测候选用户在待推荐问题上的得分,并依此降序生产推荐列表。其中,采用专家推荐阶段数据集和特征组合(Basic+Q+A+QA),在长度分别为5、10、15、20、25、30、35、40、45、50的候选集上实验结果如图4所示。

图4 粗细粒度反馈评价对推荐结果的影响Fig.4 Impact of coarse and fine-grained feedback evaluation on recommendation results
根据实验结果,在不同长度的候选集上细粒度反馈评价实验的S@3和MRR始终优于粗粒度反馈评价,其中关注推荐结果位序的MRR效果更为明显。这是由于粗粒度反馈评价将用户粗略地划分为两类标签,忽视了大量接近最高分用户的优质回答者;而细粒度反馈评价保留了用户原有评分,不仅能识别Best Answer用户,还能细致量化其他用户的回答能力。所以本工作FM模型结合细粒度反馈评价完成专家推荐任务。
上一个实验说明了针对FM算法,采用细粒度反馈评价有助于提升推荐性能。在长度为5、10、15、20、25、30、35、40、45、50的测试候选集上,分别采用前文介绍的基准方法:LDA、SVM、LR、FM预测推荐用户列表,然后计算相应的Success@N、MRR值。在长度为5的测试候选集上,按时间序列进行训练和测试,实验结果如表4所示。
在长度分别为5、10、15、20、25、30、35、40、45、50的测试候选集上,按时间序列进行训练和测试,图5按照每种方法在不同的长度测试候选集的平均实验结果,这里S@N(N=3)。
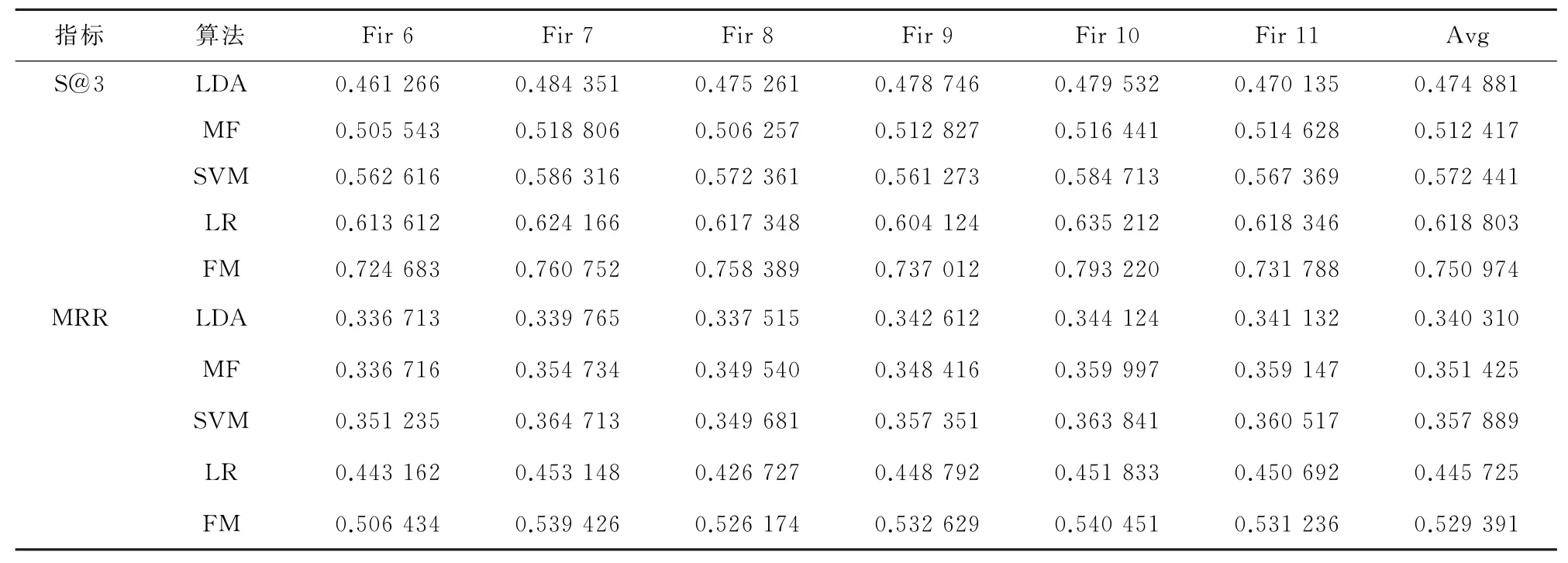
表4 推荐结果对比(T=5)Table 4 Comparison of recommended results(T=5)

图5 在不同长度推荐列表上的推荐结果Fig.5 Recommendation results on recommendation lists of different lengths
根据实验结果,可以得出如下结论:
1)LDA方法仅考虑提出的问题与专家历史回答的问题文本相似度,而MF方法仅关注问题与回答者之间的评分反馈信息,这两种推荐方法相对于其它方法效果是最差的;
2)SVM、LR和FM采用相同的特征组合(Basic+Q+A+QA),SVM采用Best Answer,和非Best Answer粗粒度反馈评价,LR和FM都是采用反馈评分细粒度评价,SVM的推荐效果要弱于LR和FM,也进一步说明了细粒度评价能够提升推荐效果;
3)相对于LR和FM两种算法,由于FM引入二阶特征交互,与LR相比,能够提升推荐效果;
4)S@3指标仅考虑推荐列表前3位中是否包含Best Answer,而不考虑Best Answer的位置,MRR指标考虑了Best Answer在推荐列表的位置,从图6可以看出,本工作考虑的特征交互与细粒度评价的FM算法,都优于基准方法,在考虑推荐位置的MRR指标上表现更突出。
3 结 语
面对传统CQA专家推荐或仅考虑问题文本特征、或考虑更多特征但没有分析特征不同组合对推荐效果的影响、或仅考虑Best Answer和非Best Answer粗粒度评价等,造成CQA专家推荐精度不高问题。本工作将特征划分为5类,并通过消融实验考虑类别组合对推荐性能的影响而确定了其4类组合对推荐的价值;同时考虑反馈评分细粒度评价和特征交互,设计FM算法在实际爬取的Stack Overflow 1年的问答数据进行实验对比,结果表明本工作设计的方案能够较基准方法能够较显著提升专家推荐性能。在日后的工作中考虑将特征融合与深度学习模型相结合,提高模型的表达能力的同时探索对专家推荐效果的影响。
