基于加权网络的专利技术主题分析
2022-04-25刘玉林刘超高蕾
刘玉林 刘超 高蕾






【摘 要】 在专利网络研究中,通过设定阈值构建无权无向网络并将其用于专利内容分析的方法得到广泛研究,但其中阈值设定随意性大、主观性强,最优阈值的选择和阈值优化往往是非常困难的事情。鉴于此,提出一种基于加权网络分析专利技术主题的方法,该方法将专利文本相似度设定为边的权重,从而构建专利加权网络,通过网络特性分析技术主题的发展。以中国电商发明专利为例,研究表明:(1)通过专利加权网络节点单位权重及其分布,发现电商专利技术主题凝聚性不强;(2)通过节点强度指标,发现电商数据分析类专利已经成为研究热点;(3)通过权重筛选,发现一个风筝型聚集社团,该社团特性显示电商专利发展有一个局部突出的技术点。案例研究进一步表明专利加权网络的优势在于将文本相似度引入专利网络构建中,以权重角度分析专利之间的确定关系,从而发现更多的网络特性,揭示专利技术主题的发展。
【关键词】 阈值;专利加权网络;权重;技术主题
Analysis of Patent Technology Themes Based on Weighted Network
Liu Yulin 1,2 , Liu Chao2, Gao Lei2
(1. Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China;
2. Anhui Business College, Wuhu 241002, China)
【Abstract】 The method of constructing unauthorized and undirected networks by setting thresholds has been widely studied in the research of patent networks. However, the threshold setting is arbitrary and subjective, both the selection of the optimal threshold and threshold optimization are very difficult to carry out. In view of this, a method of analyzing patent technology themes based on weighted network is proposed. This method sets the patent text similarity as the weight of edges, thereby constructing a patent weighted network and analyzing the development of patent technology themes through network characteristics. Taking Chinese e-commerce invention patents as the study case, the research shows that: (1) the cohesion of e-commerce patent technology themes is not strong from the research of unit weights and their distributions of patent weighted network nodes; (2)the e-commerce data analysis patents have become a research hotspot from the study of node strength indicators; (3)through weight screening, the research finds a kite-type agglomeration community whose characteristics show that there is a local outstanding technical point in the development of e-commerce patents. The case study further shows that the advantage of the patent weighted network is to introduce text similarity into the construction of the patent network, and to analyze the definite relationship between patents from the perspective of weight, so as to discover more network characteristics and reveal the development of patent technology themes.
【Key words】 threshold; patent weighted network; weight; technology themes
〔中圖分类号〕 G203 〔文献标识码〕 A 〔文章编号〕 1674 - 3229(2022)01- 0014 - 06
0 引言
在技术挖掘、技术机会发现、技术空缺识别等领域,专利分析一直以来都是最有用的工具[1-3]。在专利分析中,对技术主题进行分析能够把握技术发展前沿和动态,提供技术研发投资管理等方面的有效建议。对技术主题分析而言,基于专利名称、摘要、权利要求、描述等文本数据,结合文本挖掘和复杂网络等进行专利网络构建与分析,成为当前专利分析和技术主题挖掘研究的热点。
当然,在专利网络的构建中,通常将专利作为节点,将专利之间确定的相似性关系作为边,从而构建一种用于专利内容分析的无权无向网络。在衡量专利之间确定的相似性关系时,往往设定一个相似度阈值,当专利文献之间的相似性值大于或等于阈值时,认为专利之间存在连接关系,当专利之间的相似性值小于阈值时,认为专利之间不存在连接关系。但阈值的设定是一个主观的、反复试验的任务[3],阈值没有固定值,会根据专利技术领域不同发生变化,最优阈值的选择和阈值优化往往是非常困难的事情[4]。因此,本文通过将专利之间的相似性值设为权重,以此构建专利加权网络,并基于专利加权网络对技术主题进行挖掘,从而为技术主题分析提供一种新的分析方法,为专利分析拓展新的研究思路。
1 文献回顾
在专利网络分析中,通过设定阈值,对专利内容之间的相似度值二元化,从而构建专利无权网络进行技术分析,是当前学者常用的研究方法[3-5]。因为一旦确定了阈值,就可以很容易地将相似矩阵转换为邻接矩阵,从而构建专利无权网络 [6]。Lee P C等學者认为专利无权网络的形成,关键在于阈值的选取,不同的阈值会导致不同的网络结构和网络属性[6]。Yoon J等学者认为尽管阈值的测定是一个试错的过程,甚至不同专利数据集可能给定不同的截止值,但专家们必须选择一个合理的阈值才能更好地利用网络可视化[7]。菅利荣等学者认为阈值的设定考虑两方面因素,一是国家、行业或者企业在专利机会开发和比较时的研究需要,二是网络节点关系规律性和图形规模适度性的需要[8]。Yoon B等学者认为分析人员必须选择一个合理的值,使网络的结构变得清晰可见[3]。但在现有研究中最佳阈值的确定是一件非常困难的事情。Yoon B等学者认为阈值的确定本质上是一个主观的、反复试验的任务[3]。Lee P C等学者认为传统的确定阈值的方法需要反复多次,并且过于任意和主观[6]。Niemann H等学者认为由于专利的语言因技术领域的不同而不同,而且相似度值也因技术领域的不同而不同,因此阈值没有绝对值[9]。Zanin M等学者尝试使用多个阈值来生成不同级别的专利无权网络[5]。Lee P C等学者认为作为表示整体网络行为的最优阈值,该阈值是通过选择不同阈值生成的知识网络之间的最大匹配,认为在文献计量学分析中,阈值可以是一个任意值[6]。Lee P C、Yoon B和Park Y等学者通常建议使用多个值进行敏感性分析,然后考虑网络结构是否能够合理可视化,从而选择任意的阈值[3,6]。Lee P C等学者认为不同的数据源和代表研究兴趣的关键字集会导致不同的阈值,阈值应该是基于任务和案例的因变量,没有可以普遍应用的阈值,最好的阈值总是未知的[6]。
综上所述,阈值设定存在着主观性和任意性,在此基础上构建的专利无权网络往往以偏概全,甚至可能产生错误的分析结果。将专利之间文本相似度值作为权重、从而构建专利加权网络是一种有效的避免阈值主观设定,挖掘更多专利分析价值和开展专利主题分析的方法。因此,本文提出一种专利加权网络的构建方法,将专利文本相似度值作为权重构建专利加权网络,并根据网络特性分析专利技术主题,能够为专利分析学者和企业专利决策人员提供更多参考建议。
2 研究方法
2.1 专利加权网络
加权网络是指网络中节点之间连接的边是有权重的。对于专利加权网络而言,首先要确定权重的赋予方式,即通过相似权和相异权赋予权重值。在专利分析中,相似权通常可以是结构相似性、路径相似性和内容相似性,相异权可以是距离相异性等[10]。在本文中,将专利文本相似度值作为权重,是一种基于相似权而构建专利加权网络的方法[11]。专利加权网络的可视化形式如图1(a)中所示,专利节点边上的数值为专利之间的权重,该权重为根据专利文本计算出来的相似度值。
专利加权网络和专利无权网络之间可以相互转化,其中通过设定阈值,专利加权网络可以直接方便地转化为专利无权网络,该过程称为阈值化[11]。在图1(a)中,将阈值设定为0.6,就变为图1(b)的专利无权网络。但是,将专利无权网络变为专利加权网络的过程更复杂,需要对专利之间的边进行含义分析、量化和计算权重值等过程,甚至在某些信息不足的情况下,无法完成转化工作。
2.2 加权网络特性
2.2.1 节点强度S
对于专利加权网络[G]及其权值矩阵[W=wij]而言,节点度[kij]的概念可以延伸为节点强度[Si][11],计算公式如(1)所示:
[Si=j=1Nwij] (1)
其中,[N]为网络中节点数,当某两个节点没有边相连时,定义[wij]为[0]。节点强度[Si]蕴含节点度[ki]和边权值[wij]综合特征,是节点局部信息的有效表达方式[10]。
2.2.2 单位权重及其分布
单位权重[Ui]是指该节点所有边的平均权重值,计算公式如(2)所示:
[Ui=siki] (2)
其中,单位权重刻画的是节点连边的平均权重情况。
在专利加权网络[G]中,权重分布是衡量权重分布程度的重要指标,权重分布差异性可以用[Yi]来刻画,计算公式如(3)所示:
[Yi=j=1Nwijsi2] (3)
2.3 余弦相似度
计算专利文本相似性的方法有很多,比如Dice系数、Jaccard系数和余弦相似度,前两个度量针对关键字进行计算,余弦相似度对术语向量(文档)之间的夹角进行计算[6]。目前,基于余弦相似度的计算方法是比较常用的方法,Song K等学者在研究3D汽车行业技术挖掘时,认为余弦相似度是一种测量两个向量余弦角相似度的方法。可以使用这种方法计算技术间的相似度,技术间相似度的结果取值范围为0-1[12]。
常见的余弦相似度是通过求两个向量的余弦角来计算的,常见公式如(4)所示:
[A=wPA1,wPA2,wPA3,…,wPAn]
[B=wPB1,wPB2,wPB3,…,wPBn]
[cosA,B=∑wPAi×wPBiwPAi2×wPBi2] (4)
其中,[A]、[B]分别为权重所组成的一维向量,向量中权重来源于专利文本特征在专利中的权值[6]。
3 实证分析
选择中国电子商务发明专利作为实证案例,通过构建中国电商专利加权网络,基于加权网络的特性分析中国电商专利技术主题发展现状,以此揭示专利加权网络在专利技术主题分析中的应用。
3.1 数据源
在中国国家知识产权局网站,采用关键词查找方式,关键词为“电子商务”或“电商”,将时间跨度定为1996-2018年,共采集到已有授权的发明专利101条数据,数据特征维度包括专利号、专利名称、发明人、代理人、文件下发时间、摘要等,其中专利号、专利名称、摘要等特征经过人工核实校对,数据无误且无缺失。需要说明的是,时间跨度中1996年为电子商务发明专利首次出现的时间,截止时间定为2018年,主要考虑发明专利的授权时间比较长,存在发明专利申请超过3年尚未获得授权的情况。
3.2 专利加权网络构建
3.2.1 专利文本相似度计算
在专利中,专利名称、摘要、权利要求书和描述等含有大量的技术知识和信息,是专利文本内容的主要表现形式,利用文本挖掘技术从专利文本中提取特征、衡量专利相似性,成为学者专利挖掘的有效分析方法。Madani F等学者对专利分析方法的时间演化分析表明专利内容分析已经成为新的专利分析研究热点方法[4]。
在本文中,选择专利摘要作为专利文本特征提取对象,从专利摘要中提取属性-功能关键词组合作为专利内容特征,构建专利文献与属性-功能向量空间,并基于余弦相似度(见公式4)计算专利文献之间的相似度,得到专利相似度值,见表1,其中专利文本特征的选取和文本相似度计算方法借鉴相关文献[8, 13]。
3.2.2 专利加权网络生成
将专利作为节点,文本相似度值设置为边的权重,构建专利加权网络,并将相关数据导入gephi中制作专利加权网络图,如图2所示。
在图2中,专利节点之间通过边连接,边中间数值为专利文本相似度值,即权重值。如果专利相似度值为0,则专利节点之间没有边连接,此时定义权重值为0。在图2中没有边连接的专利节点对数量为191。
3.3 專利技术主题分析
3.3.1 技术主题凝聚性分析
在Python中根据公式(2)对专利加权网络的节点单位权重进行统计,并将单位权重绘制成散点图,如图3所示,其中横坐标为节点序号,纵坐标为节点对应的单位权重值。由图3可见,专利节点的单位权重基本介于0-0.3之间,总体上数值偏小,说明在已授权的中国电商发明专利上,专利文本相似度较低,表现出较大差异性。同时,根据公式(3)进一步统计权重分布差异性Yi值,Yi值中最大值为0.028,最小值为0.012,表明在所有专利节点上均表现出权重分布较小的差异性。上述专利加权网络单位权重分布的特性说明我国电商专利发展“各有特色,百花齐放”,呈现与众不同的特色。同时,也说明在已授权的中国电商发明专利中尚未凝聚出特别突出的集中主题,因此,中国电商发明专利技术主题凝聚性不强[14]。
3.3.2 技术主题热点性分析
通过中心性识别关键节点从而发现技术主题的热点,一直是专利网络中的常用方法。其中无权网络通常使用度中心性、介数中心性、接近中心性和特征向量中心性等方法识别关键节点,但在加权网络中,边的权重成为衡量节点连接关系的重要指标,关键节点的识别要充分考虑边的权重因素。通过公式(1)计算图3中节点强度,排序后将节点强度在前10位的节点制作柱状图,如图4所示。
图4显示排名前两位的节点为CH15、CH6,该节点分别为雅虎公司和泰康亚洲(北京)科技有限公司所有,两家公司均为美国企业,并且两项专利均为G06F17类。经过IPC查询G06F17类专利为电数字数据处理,其中特别强调适用于特定功能的数字计算设备、数据处理设备或数据处理方法,该发现进一步说明数据处理成为发明专利申请领域的热点。同时需要强调的是该热点专利均为美国公司在中国申报,是一种跨国专利行为。Moussa B等学者研究表明随着全球化的到来和各国间金融经济的互动,国际专利行为已经变为普遍现象[15]。因此,美国企业在中国申请电商专利表现出较高的节点强度,值得引起我国电商企业和研究者对该领域知识产权的重视。
中国电商企业阿里巴巴集团控股有限公司在电商发明专利中的成绩也不甘示弱,在前10的关键节点中有3项发明专利,分别为节点强度排序第4、5、7的节点CH38、CH41和CH43,专利领域均为G06Q30类,经过IPC查询G06Q30类专利为电商购物类计算、推算和计数等,均属于电商数据分析类。该发现进一步佐证和增强了电商数据分析类发明专利是目前电商发明专利研究的热点。其中特别强调的是,节点CH41的专利名称为“一种基于用户行为的电子商务信息推荐方法与装置”,说明阿里巴巴集团不但在数据分析上开展了研究,也同步推进了数据分析结果的应用与顾客选择研究。
在排名前10的节点中仅有第10位节点CH50是非G06类专利,节点CH50为方正国际软件(北京)有限公司2013年申请的H04电通信技术类发明专利,说明非电商数据分析类专利也是一些企业的研究范畴和申报意向,但已经退出技术主题的热点研究领域。
3.3.3 技术主题局部趋势性分析
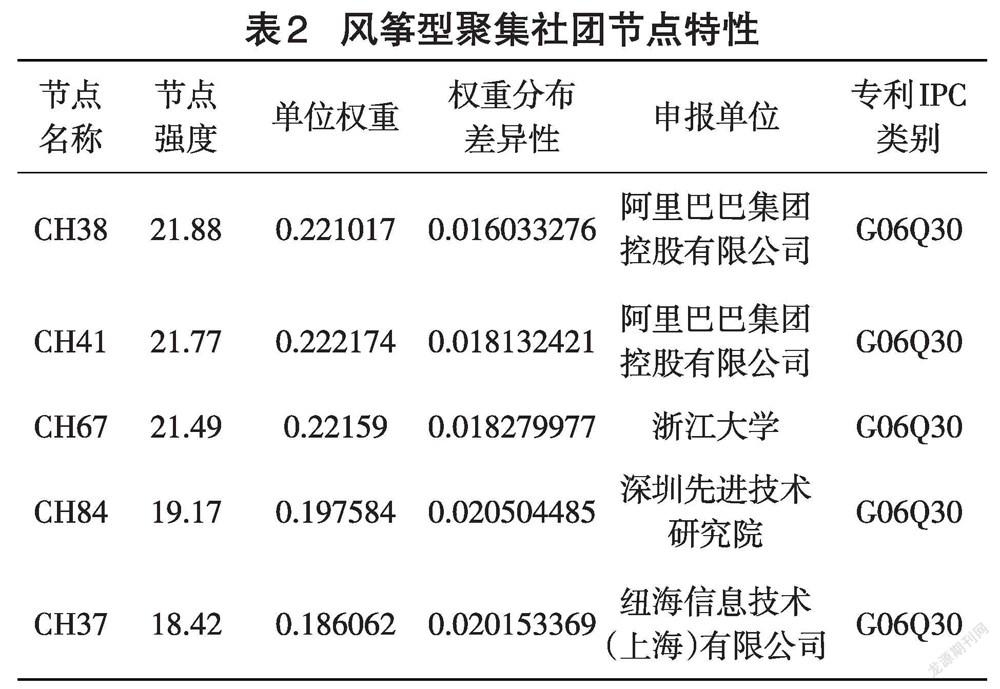
在专利加权网络中,设定一个权重阈值,筛选出高权重连接,从而发现高度相似的局部技术社团,并剖析该社团的拓扑性质,有利于深度分析局部技术趋势的发展。在图3的专利加权网络中,为了识别高度相似的局部聚集社团,将权阈值设定为0.7,设定完成后,计算节点度,筛选度高的节点,发现一个风筝型聚集社团,如图5所示。
图5显示,在风筝型聚集社团的头部结构中,形成一个全局耦合网络,网络密度为1,节点之间两两连接,边的权重均超过0.7,说明在头部结构的节点专利高文本相似,主题突出。在“风筝”型聚集社团的尾部结构中,仅有1个节点CH38,该节点仅与头部节点CH41相连,形成权重为0.71的高文本相似性,但未与头部其他三个节点专利相连[16]。
通过IPC专利分类号分析发现,头部结构中节点CH37、CH41、CH67和CH84和尾部结构中节点CH38,IPC专利分类号均为G06Q30类,即为电商购物类计算、推算和计数等,均属于电商数据分析类。此时进一步通过专利文本分析,CH38比较侧重于电商买家数据的分析,而CH37、CH67和CH84则侧重于电商网页数据的分析,其中CH41为电商网页数据和买家数据的交叉研究,因此,CH41节点与CH38节点在文本上有高相似性,也同时与CH37、CH67和CH84在文本上有高相似性,但CH38节点与CH37、CH67和CH84未出现高文本相似性。
通过专利申报单位分析,风筝型聚集社团中5个节点专利均为中国企事业单位申报。但申报的类型不同,CH37节点为纽海信息技术(上海)有限公司申报,该公司的主营范围为计算机软硬件的研发和设计;CH38和CH41节点专利为阿里巴巴集团控股有限公司申报,该公司的主营范围为网络购物和数据分析等;CH67为浙江大学申报,浙江大学为我国著名且世界一流大学;CH84节点为深圳先进技术研究院申报,该研究院隶属中国科学院,是研究超算和信息技术的专业研究院。从申报单位属性看,包括研究性企业、实践性公司、著名大学和专业研究院,虽然申报单位属性不同,但在电商专利申报类型上趋向一致,均聚焦在G06Q30电商数据分析类,说明电商数据分析类专利已经成为技术发展趋势,符合社会广泛需求。
在风筝型聚集社团中,5个节点的节点强度均处于前列,其中CH38、CH41和CH67都位列节点强度前10,CH37和CH84也都大于18,高节点强度进一步说明风筝型聚集社团不仅结构紧密、主题突出、凝聚性强,而且在整个专利加权网络中也处于热点位置,对其他节点有着重要的影响力。
4 结论与讨论
本文以1996-2018年我国电商发明专利数据为样本,通过将专利文本相似度设定为权重,從而构建专利加权网络,并对其进行网络特性分析,具体包括单位权重、节点强度和关键社团等。通过分析发现专利技术主题的凝聚性、热点和趋势,从而有以下结论:首先,我国电商专利发展呈现“各有特色,百花齐放”,整体技术主题凝聚性不强;其次,美国公司在中国专利申报的跨国性专利行为已经形成突出影响,中国阿里巴巴集团在电商专利热点的影响力紧随其后,综合分析发现电商数据分析类专利已经成为专利研究和申报的热点;最后,中国电商专利有一个局部社团,即风筝型聚集社团。在风筝型网络社团的头部中,专利高度相似,两两连接呈现全局耦合网络,尾部也表现出技术主题的尾随性,整个社团专利均为电商数据分析类,说明中国电商专利的发展呈现数据分析趋势。
本研究中专利加权网络的优势在于将文本相似度作为权重引入专利网络构建中,以权重角度分析专利之间的确定关系,从而发现更多的网络特性,揭示专利技术主题的发展。同时,案例研究表明通过对专利加权网络中单位权重及其分布、节点强度、关键社团等网络特性分析,对揭示专利技术主题发展有着重要的帮助。当然,本研究也有不足之处,对专利加权网络中的技术主题凝聚性没有数量指标性的算法,以致主题凝聚性强度难于量化;专利属性中时间没有纳入分析维度,致使技术主题发展的时序性难以把握等。因此,专利加权网络未来的发展在于进一步深化专利加权网络的网络特性分析和量化,综合考虑时间维度,深度挖掘基于专利加权网络的技术主题分析优势。
[参考文献]
[1] Abbas A , Zhang L, Khan S U. A literature review on the state-of-the-art in patent analysis[J]. World Patent Information, 2014, 37:3-13.
[2] Sun H, Geng Y, Hu L, et al. Measuring China's new energy vehicle patents: A social network analysis approach[J]. Energy, 2018, 153:685-693.
[3] Yoon B, Park Y. A text-mining-based patent network: Analytical tool for high-technology trend[J]. The Journal of High Technology Management Research, 2004, 15(1):37-50.
[4] Madani F, Weber C. The evolution of patent mining: Applying bibliometrics analysis and keyword network analysis[J]. World Patent Information, 2016, 46:32-48.
[5] Zanin M, Papo D, Sousa P A , et al. Combining complex networks and data mining: Why and how[J]. Physics Reports, 2016,635 :1-44.
[6] Lee P C, Su H N, Chan T Y. Assessment of ontology-based knowledge network formation by Vector-Space Model[J]. Scientometrics, 2010, 85(3):689-703.
[7] Yoon J, Kim K. An analysis of property-function based patent networks for strategic R&D planning in fast-moving industries: The case of silicon-based thin film solar cells[J]. Expert Systems with Applications, 2012, 39(9):7709-7717.
[8] 劉玉林,菅利荣. 基于文本挖掘和复杂网络的中美电商专利比较研究[J]. 情报杂志,2019,38(6):72-79.
[9] Niemann H, Moehrle M G, Frischkorn J. Use of a new patent text-mining and visualization method for identifying patenting patterns over time: Concept, method and test application[J].Technological Forecasting and Social Change,2017, 115:210-220.
[10] 姚尊强,尚可可,许小可.加权网络的常用统计量[J].上海理工大学学报, 2012,34(1):18-26.
[11] 汪小帆,李翔,陈关荣.网络科学导论[M].北京: 高等教育出版社, 2012:38-43.
[12] Song K, Kim K S, Lee S . Discovering new technology opportunities based on patents: Text-mining and F-term analysis[J]. Technovation, 2017, 60-61:1-14.
[13] 荀雪莲,王晓宁.基于中文摘要关键词的毕业论文质量评价系统[J]. 廊坊师范学院学报(自然科学版),2019,19(4):30-32.
[14] 田柳,狄增如,姚虹.权重分布对加权网络效率的影响[J].物理学报, 2011,60(2):807-812.
[15] Moussa B, Varsakelis N C. International patenting: An application of network analysis[J]. The Journal of Economic Asymmetries, 2017,15:48-55.
[16] 周莉,刘苗,周蕊格,等. 基于专利文本挖掘的科技文化产业技术发展趋势研究[J].科技进步与对策,2019,36(23):69-75.
