基于机器学习的移动代理应用流量识别方法*
2022-04-21张广胜苏金树
崔 弘,赵 双,张广胜,苏金树
(1.烽火通信科技股份有限公司,湖北 武汉 430074;2.国防科技大学计算机学院,湖南 长沙 410073;3.中央军委政法委员会,北京 100080)
1 引言
移动应用已成为人们开展日常活动的主要途径之一,如社交、购物和娱乐等[1]。在海量移动应用中,代理应用是一类常见的工具应用。这类应用通过配置一台或多台代理服务器,将用户对网络资源的直接访问转换为借助代理服务器对网络资源的间接访问。如图1所示,当用户通过代理应用访问网络资源时,代理应用客户端会首先与代理服务器建立连接。基于代理协议,客户端将用户的访问请求发送至代理服务器,代理服务器访问应用服务器,获取网络资源并转发至代理应用客户端。最后代理应用客户端将响应内容展示给用户。对应用服务器而言,访问者是代理服务器,而非背后的用户,从而访问资源的用户真实身份得以隐藏。基于代理应用,用户能够保护个人网络隐私或绕开网络限制,例如使用被防火墙禁止的网络服务。此外,攻击者也可以利用其发起恶意攻击[2,3]。若应用服务器不能识别有效的访问请求,这类攻击将更难以识别与防范。因此,代理应用流量识别不仅有助于网络流量审计与管理,也能帮助入侵检测系统或防火墙发现更多可疑行为。

Figure 1 Working process of proxy application
目前,仅有少数研究人员针对代理应用流量识别展开了研究[2 - 7]。代理应用采用的随机端口号、加密和混淆等技术,给已有的流量识别方法带来了极大的挑战,即传统的基于端口的流量识别方法和基于深度包检测的流量识别方法的有效性大大降低。针对不具有明显负载特征的流量,如加密流量,基于机器学习的流量识别方法近年表现出优秀的识别能力。按照提取特征方式的不同,这一方法可分为2类:一类基于专家经验设计流量特征[8 - 10];另一类则在方法的训练过程中实现特征的自动学习[11 - 13]。近期基于神经网络的加密流量识别方法广受关注,该方法通过自动学习流量特征,可避免繁琐的人工特征设计过程,并且可以提取高维抽象特征,因此具有优秀的分类能力。但是,已有方法并不能良好地解决本文提出的移动代理应用流量识别问题,主要原因包括:
(1)已有方法仅关注区分加密流量和非加密流量[14,15],或同类加密协议下的应用识别[11 - 13,16,17],未涉及识别不同的代理应用。
(2)多数方法利用安全套接层/传输层安全SSL/TLS(Secure Socket Layer/Transport Layer Security)协议握手前期的明文信息对加密流量进行识别[11 - 13,16,17],但一些移动代理应用具有透明传输的特点[5],其产生的流量不具有明文握手信息,因此相关方法可能会失效。个别代理应用采用TLS协议进行流量混淆时,会模拟TLS协议握手过程,如Shadowsocks[18]。
(3)已有方法提出的分类器多采用卷积神经网络、长短期记忆LSTM (Long Short-Term Memory) 网络、AutoEncoder和胶囊网络等学习算法进行训练,预测过程复杂,对计算环境要求高,难以满足实际应用中的高速网络实时分类需求。
基于人工设计的特征的流量识别方法通常采用随机森林RF(Random Forest)、决策树等学习算法实现[4,5,19],计算简单快速。这类方法虽然会不可避免地遗漏高维特征,但当流量具备有效的低维特征时,依靠人工提出的简单特征集也可满足其识别需求。例如,Deng等人[4]针对Shadowsocks提出3 000余种统计特征,包括报文大小、报文个数等,并基于随机森林分类器识别其流量。但是,已有相关工作均针对一种特定的代理应用展开分析,如Shadowsocks和V2Ray等,并未对多种代理应用间流量区分的问题进行进一步研究。
通过分析多种代理应用流量,本文发现其与非代理移动应用流量在一些特征上存在明显差异,例如广泛使用的报文长度特征、突发特征及其他未被关注到的特征,如options字段。此外,不同代理应用间也表现出不同的流量传输模式。为满足快速甚至实时的流量识别需求,本文基于第一类方法,提出一组新的统计特征,并结合机器学习算法识别代理应用流量,首次对不同移动代理应用间的流量分类展开研究。
本文主要工作包括:提出一组与负载无关的流量特征用于识别移动代理应用流量和分类不同移动代理应用流量。4种机器学习算法XGBoost[20]、随机森林RF、支持向量机SVM(Support Vector Machine)、朴素贝叶斯NB(Naive Bayes)用于训练分类器并验证提出的特征的有效性。由于代理应用与代理服务器间存在不同的交互方式,包括长连接交互和短连接交互,本文将进一步分析通过不同的报文分组方式构建的流和服务突发2种识别对象对分类器识别结果的影响。最后验证分类器的鲁棒性并基于公开数据集与其他方法进行比较。
2 相关工作
流量识别方法虽已受到广泛的关注和研究,但其中涉及代理应用流量识别的研究较少,尤其是移动代理应用流量识别。本节首先介绍最为相关的代理应用流量识别工作,然后介绍基于ISCX VPN-nonVPN流量数据集[8]展开的加密流量识别研究。
2.1 代理流量识别
Miller等人[3]提出一组统计特征,例如报文个数、报文长度和报文持续时间等,并基于多层感知机MLP(MultiLayer Perceptron)训练分类器,以识别网页访问流量是否来自OpenVPN服务器,该分类器准确率约为93.71%。Foroushani等人[21]利用39种统计特征识别网络流量是否来自代理IP。基于C4.5分类器,该工作识别准确率约为97%。Deng等人[4]针对Shadowsocks提出一种基于随机森林的分类器,可实现85%以上的识别准确率。Zeng等人[5]提出12种流量特征识别Shadowsocks流量,包括流上下文特征、主机流行为特征和主机DNS行为特征。基于随机森林,以上特征用于训练分类器时,分类器的识别准确率可达93.43%。Cheng等人[6]通过伪装客户端主动向疑似Shadowsocks代理服务器发起连接,提取服务器的响应报文特征,例如时间相关统计特征及报文长度等,并基于XGBoost训练分类器识别Shadowsocks代理服务器,准确率约为94.63%。唐舒烨等人[7]提出一种基于分段熵的V2Ray代理应用流量识别方法。该方法通过划分滑动窗口下的报文高熵、低熵区域,基于胶囊神经网络训练分类器实现V2Ray流量的识别,识别准确率为96.34%。
2.2 加密流量识别
Draper-Gil等人[8]公开ISCX VPN-nonVPN数据集,并使用时间相关特征对加密流量进行识别,识别准确率约为84%。该数据集包括7类服务的普通加密流量和相应的经VPN封装后的加密流量。本节后述加密流量识别工作均是基于该数据集的。Bagui等人[14]利用24种时间特征训练6种分类器,以识别流量是否属于VPN加密流量,研究表明梯度提升树和随机森林具有最好的分类性能,可实现约94%的平均准确率。Deep packet[11]采用IP报文前1 500字节训练一维卷积神经网络及栈式自编码器对流量进行分类。类似地,Guo等人[12]采用卷积自编码器和卷积神经网络分类加密流量,识别准确率约为92.92%。Dong等人[17]采用卷积神经网络和GRU(Gated Recurrent Unit)自动学习报文负载特征,并融合人工设计的统计特征基于MLP训练分类器,准确率约为96.08%。Wang等人[22]采用对抗生成网络补充训练样本,以缓解数据集不均衡问题。利用平衡后的数据集训练的基于MLP 的分类器可实现99.1%的识别准确率。Cui等人[13]采用胶囊神经网络学习流的前784个负载字节特征并对加密流量进行分类,识别准确率为99.3%。Vu等人[23]提取报文序列中的端口、协议、报文长度和报文负载字节作为特征,并基于LSTM训练分类器识别加密流量。Zou等人[16]对流中任意位置的3个连续报文进行识别,其首先使用卷积神经网络提取报文负载特征,然后基于LSTM的分类器提取报文的序列特征,识别精度为91%。王琳等人[24]基于遗传算法和随机森林训练分类器对加密流量进行分类,可实现92.2%的识别准确率。
3 移动代理应用流量识别方法
基于人工设计的统计特征的流量识别方法包括数据预处理、特征提取及筛选、分类器训练及分类等步骤。在数据预处理阶段,本文采用2种报文分组方法构建2种识别对象。特征提取阶段给出一组流量特征用于训练分类器。根据分类器训练结果进一步筛选冗余特征,提高特征集有效性。最后,验证分类器的有效性。
3.1 数据预处理
数据预处理包括报文分组和异常报文处理。报文分组用于划分识别对象,异常报文处理包括消除重传报文、ACK报文等操作。
按五元组划分的流是流量识别中最常用的一种识别对象。流的划分方法如下:定义F=〈Pi0,Pi1,…,Pim〉是一条流,其中,Pij(0≤j≤m)为报文并具有相同的五元组(〈源IP,目的IP,源端口,目的端口,协议〉),Pi0的SYN标志位置1,Pim的FIN标志位置1。此外,若2个具有相同五元组的相邻报文的间隔时间超过T(T为超时时间阈值),则从后一个报文起将构成一条新流。
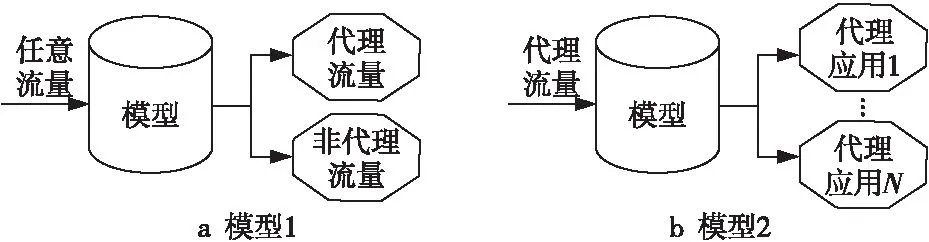
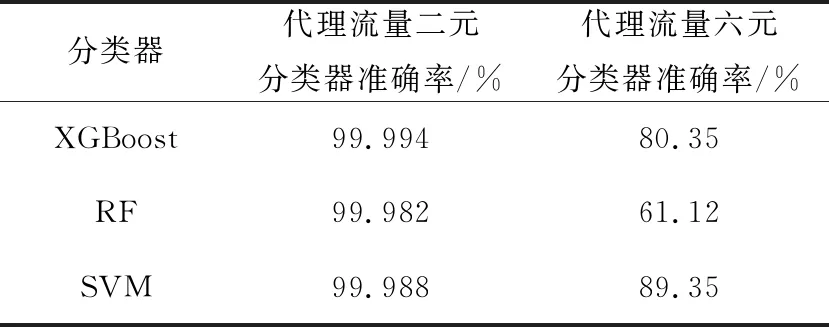
服务突发SB(Service Burst)是另一种常用的识别对象。其划分方式如下:定义B=〈Pk0,Pk1,…,Pks〉是一个突发,其中,Pkl(0≤l≤s-1)为报文,tkl为第l个报文的时间戳,tk(l+1)-tkl 代理应用转发流量时会对流量进行封装,不同代理应用具有不同的封装机制。例如,一些代理应用将每一条流封装为一个短连接,因此封装后的连接数与用户原本产生的流个数基本一致。另一些代理应用则将多条流封装于一个长连接中,因此经代理应用封装后的连接个数远远少于用户原本产生的流个数。不同的封装方式下,不同的识别对象能更好地表示代理应用行为。本文采用流和服务突发2种识别对象,并比较了其给分类器带来的影响。为实现快速的识别,本文仅利用每条流或每个服务突发的前几个报文信息。考虑到3个握手报文,各方向传输的第1个数据报文及响应报文,一个完整的流包含的最小报文数通常为7。因此,本文保留每个样本的前7个报文,并去除报文数小于4的样本。此外,Aceto等人[25]指出去除重传报文对分类器准确率影响较小。考虑到去除重传报文会带来额外的计算开销,因此本文不进行相关处理。 代理应用流量通常经过加密或混淆处理,因此不再具有明文负载特征。通过分析代理应用流量,本文发现其报文长度、报文标志位和应用层头部字段等取值与非代理流量具有一定的差异。基于此,本文提出41种与负载无关的统计特征,如表1所示。表2列出了表1中涉及的options字段的详细信息。 Table 1 41 statistical features 如表1所示,特征集包含3类特征:基本特征、options字段特征和标志位特征。基本特征在相关方法中已表现出优秀的区别能力[19,25],PSH标志位也表现出一定的有效性[21]。此外,在TCP层的options字段方面,代理应用流量和非代理应用流量在字段长度、字段选项分布等方面均表现出一定的差异,本文提出options相关字段特征共22种。options相关字段特征尚未在相关识别方法中使用。 Table 2 Description of options 3.3.1 模型设置 本文提出2种不同识别粒度的模型,如图2所示。这2种模型适用于不同的分类场景:模型1实现粗粒度的代理应用流量二元分类,即区分流量是否由代理应用转发;模型2实现细粒度的代理应用流量识别,即识别流量来自哪种代理应用。 基于多种机器学习算法训练的分类器在相关研究中已表现出良好的分类能力。本文选择XGBoost、RF、SVM和NB训练分类器,验证特征集的有效性并比较不同分类器的分类能力。 Figure 2 Two models with different recognition granularity 3.3.2 评价指标 本文采用整体准确率OA、精度Precision和召回率Recall对分类器的性能进行评估。对于类别A,真正数TP(True Positive)指类别为A的样本被识别为类别A的个数;假正数FP(False Positive)指类别非A被判定为类别A的样本个数;真负数TN(True Negative)指类别非A被判定为非A的样本个数;假负数FN(False Negative)指类别为A但漏判为非A的样本个数。基于以上4个变量,3种评估指标的计算方法分别如式(1)~式(3)所示: (1) 其中,n为分类类别数。 (2) (3) 由于移动应用流量不易被标记且涉及隐私等原因,当前没有公开可用的移动代理应用流量数据集。为验证所提特征集的有效性,本文采用安卓模拟器及wireshark[26]捕获代理应用流量构建本地数据集。首先,在安卓模拟器上安装代理应用,将其设置为全局代理模式,即安卓模拟器产生的全部流量都经由代理服务器转发。然后在模拟器中运行其他应用并使用wireshark捕获模拟器产生的所有流量作为该代理应用的流量样本。另一方面,关闭代理应用并运行其他移动应用,捕获的流量组成非代理应用流量样本。 本文选择6款国内常用或谷歌商店下载量较高的代理应用作为待识别的代理应用,即Shadowsocks(SS)、ShadowsocksR(SSR)、256、Fish、Thunder和WindScribe。其中,SS和SSR需配置代理服务器,其他4种代理应用提供代理服务器。在3台安卓模拟器上捕获的流量组成的数据集如表3所示。 Table 3 Local dataset 此外,ISCX VPN-nonVPN公开数据集提供的数据与本文所需数据最为接近,但仍不能完全满足本文需求,主要原因包括:(1)数据集非移动应用流量;(2)所有VPN流量均来自同一种VPN软件,无法应用于本文提出的模型2分类场景。因此,本文仅使用该数据集验证模型1 分类场景中的分类方法的有效性,并与其他工作提出的分类方法进行比较。预处理后的数据集构成如表4所示。 Table 4 ISCX VPN-nonVPN dataset 对本地数据集按流分组后,流样本个数分布如表3所示。样本以7∶3的比例随机划分为训练集与测试集,用于训练和测试分类器。测试结果为运行10次获得的平均值。 4.2.1 代理应用流量二元分类 二元分类器的目标是识别流量是否由代理应用转发。分类器基于scikit-learn[27]实现。其中,XGBoost最大深度设为5,迭代次数设为6;RF中树设为10棵,最大深度设为7。SVM学习率设为1e-6;NB保持默认参数。表5给出基于4种机器学习算法训练的分类器的识别结果。 Table 5 Classification results of proxy traffic binary classifiers 使用41种特征训练分类器时,RF和XGBoost表现出最优的性能,达到99.98%的整体准确率。SVM的整体准确率略低于RF的,但具有最快的识别速度。虽然NB的训练时间最短,但其整体准确率低于90%。XGBoost的训练时间高于RF的,但在相同的整体准确率下,XGBoost具有更快的识别速度。 XGBoost训练完成后,可以获得特征的重要性,本文基于此对特征集进行筛选。表6给出了XGBoost分类器选用的27种特征的重要性排序(重要性从大到小排序)。其中,报文长度和options字段具有较高的重要性。本文选取前70%的特征(18种特征)作为新的特征集。由表5可知,基于18种特征训练的分类器,除NB外,另外3种分类器的整体准确率均未下降,或表现出微小的上升。同时训练时间和测试时间也有相应的缩短,因此可通过特征筛选去除冗余特征,提高分类器效率。 Table 6 Importance ranking of features used in XGBoost 为进一步验证提出的3类特征的有效性,本文去除其中1类或2类特征并重新训练XGBoost分类器,实验结果如表7所示,其中,+表示仅使用该类特征,*表示仅去除该类特征。 Table 7 XGBoost classification results with different combination of features 由表7可知,在识别代理应用流量/非代理应用流量时,基本特征具有最优的识别效果,单独用于分类时可达到99.93%的整体准确率。options字段特征单独用于分类时整体准确率为98.83%,有效性略低于基本特征的。标志位特征有效性最低,单独应用时的分类整体准确率仅为74.04%。 4.2.2 代理应用流量多元分类 多元分类器的分类目标是识别不同代理应用间的流量。各分类器参数设置如下:XGBoost最大深度设为10,迭代次数设为6;RF树设为20棵,最大深度设为20;SVM学习率设为1e-6;NB保持默认参数。各分类器识别结果如表8所示。 Table 8 Classification results of proxy traffic 6-class 类似地,XGBoost分类器训练所得的前70%重要性最高的特征(28种特征)同样用于构建新的特征集。 由表8知,RF分类能力最优,整体准确率达94.1%,XGBoost的分类能力略低于RF的。在细粒度的代理应用流量识别中,XGBoost分类器复杂度增加,其训练速度和分类速度均低于RF的。虽然SVM和NB具有最快的分类速度或训练速度,但两者的整体准确率均低于60%。各类别识别精度和召回率分布如图3所示。 Figure 3 Precision and Recall of 6-classe proxy traffic classifiers 对于SS,4种分类器的识别精度均较高,但SVM和NB不能有效区分另外5种代理应用。召回率上,WindScribe和Fish的召回率低于另外4种代理应用的,RF和XGBoost在其上的召回率仅略高于60%。识别精度上,前3种代理应用的识别精度较高,代理应用256的识别精度可达98%,后3类代理应用的识别精度仅约75%。 表9给出了不同特征组合下训练的XGBoost分类器的识别结果。识别不同的代理应用流量时,基本特征仍具有最优的区分能力,options字段特征区分能力优于标志位特征的区分能力。基本特征与options字段特征共同训练的分类器的识别性能优于仅使用基本特征训练的分类器,并与完整特征集训练的分类器识别性能非常接近。 Table 9 XGBoost classification results with different combination of features 从表3可知,各代理应用的流样本分布极度不均衡,其中Thunder和WindScribe样本数远小于其他代理应用的。经检查报文发现,除SS和SSR外,其他4种代理应用与代理服务器采用长连接的交互方式,即一段时间内采用同一个端口转发设备产生的所有流量,因此超时阈值设置较大时,按流的划分方法只能得到少量流样本。对于这种情况,服务突发更适合表示应用行为,因此本节重新处理数据集并获得服务突发样本,然后训练分类器。 不同时间间隔下服务突发样本分布如表10所示。基于服务突发分组方法,Thunder和256的样本数大幅度增加,WindScribe和Fish的样本数量增加相对较少。由4.2节知特征筛选可有效减少特征数量,且对整体准确率影响较小。本节实验使用全部特征训练分类器。 4.3.1 代理应用流量二元分类 基于服务突发识别对象的分类器参数设置与4.2节的保持一致。不同时间间隔下的样本训练的分类器的分类整体准确率如图4所示。4种分类器分别在8 s,10 s,15 s和4 s时取得最高的整体准确率99.95%,99.95%,94.99%和87.77%。其中,基于决策树的分类器的整体准确率受时间阈值影响较小,而SVM则在大的时间阈值时表现出更优秀的识别能力。除NB外,另外3种分类器的整体准确率均略低于基于流的识别分类器的。由于不同类型特征有效性与4.2节的类似,限于篇幅限制,不再详细介绍。 Table 10 Service burst sample distribution with different time thresholds Figure 4 OA of binary classifiers with different burst time thresholds 4.3.2 代理应用流量多元分类 不同时间阈值下的服务突发样本训练的4种六元分类器在不同应用上的分类精度和召回率分布如图5所示。由图5知,时间阈值越大,基于决策树的分类器在SS、SSR和256这3种代理应用上的识别精度和召回率越高。另外3种代理应用则具有相反的趋势,即在时间阈值较小时获得最高的精度和召回率。SVM和NB的性能与时间阈值的取值无明显的关系,并且稳定性较差。XGBoost和RF依然表现出最优的分类能力。其中,RF能更有效地识别SS、SSR和256这3种代理应用,而XGBoost在另外3种代理应用上具有更优的分类能力。总体上,基于流的分类器能够更好地识别SS、SSR和256,基于服务突发的分类器则能更有效地识别Fish、Thunder和WindScribe。对于Thunder,基于服务突发的分类器的识别精度提高约16%,召回率提高约7%。一个可能的原因是基于服务突发的Thunder样本数量远远多于基于流的样本数量。 4.4.1 代理应用混淆加强 与另5款代理应用不同,SSR提供2种参数用于加密和混淆流量,即协议参数和混淆方式。其中,协议参数定义加密前的协议,用于长度混淆,增强安全性和隐蔽性。混淆方式用于协议伪装。在初始数据集收集过程中,SSR的配置为最简单的协议和混淆方式(origin/plain)。为验证当代理应用混淆加强时分类器的鲁棒性,本文使用新的参数组合捕获SSR流量(共采用10组新的参数组合,涉及5种协议和3种混淆方式),收集新样本16 488条流,并使用基于流的分类方法(分类器训练过程不包含新类型流量)对新捕获的流量进行分类。分类结果如表11所示。 Figure 5 Precision and recall of 6-classes classifiers on different proxy apps 由表11可知,即使代理应用增强其流量的隐蔽性,本文提出的分类器也能有效区分代理流量和非代理流量,但细粒度分类的有效性有所降低,其中,XGBoost、RF和SVM分别将18.52%,38.38%,6.22%的流样本误识别为SS,将1.13%,0.5%,4.42%的流样本误识别为其他4类代理应用。XGBoost和RF能将SSR与其他4类无关的代理应用区分开,但不能有效区分SS与SSR。SVM具有最高的整体准确率,但其将SSR误识别为其他4类无关代理应用的比例最高。需注意的是,SSR是SS的升级版代理应用,且兼容SS。 4.4.2 新代理应用 为分析分类器处理未知的代理应用流量的能力,本节收集新代理应用V2Ray[28]的流量共1.67 GB,10 650条TCP流样本,并验证提出的二 Table 11 Classification results on new SSR dataset 元分类器(训练样本不包含V2Ray流量)能否将V2Ray流量识别为代理应用流量。实验结果表明,XGBoost、RF和SVM识别V2Ray流量的整体准确率分别为67.63%,92.10%和95.65%。因此,本文提出的特征训练的分类器能有效识别训练中未学习过的代理应用流量,特征鲁棒性强。此外,相比XGBoost,RF和SVM在对代理应用流量进行粗粒度识别时具有更强的鲁棒性。 本节在ISCX VPN-nonVPN公开数据集上对模型1中的二元分类器与已有工作提出的分类器进行比较。Zeng等人[5]提出的分类器要求主机使用VPN应用时开启局部代理模式。另外,该分类器采用的特征包含DNS访问的敏感域名分布情况,不适合应用于该公开数据集。唐舒烨等人[7]提出的分类器未给出必要的实现细节。因此,本文选择MLP[3]和Deng等人[4]的分类器进行比较。其中,本文分类器与Deng等人提出的分类器均基于随机森林训练得到,参数设置一致,包含100棵树,最大深度为15。MLP采用10种统计特征训练多层感知机分类器,参数设置与原分类器一致。此外,MLP及Deng等人提出的分类器均使用完整流的统计特征。本文的分类器则在完整流和前7个报文上提出的特征训练得到。实验平台参数如下:Intel i7-6800K CPU 3.40 GHz,12核,32 GB内存,GPU包含3个NVIDIA GTX TITAN X。实验结果如表12所示。其中,*表示使用完整流的统计特征,#表示使用流前7个报文的统计特征。 Table 12 Comparison of identification classifiers from different methods 由表12可知,本文分类器的整体准确率优于另外2种分类器的。相比文献[4]提出的3 000余种特征,本文分类器仅采用40余种特征,因此本文的分类器具有更快的分类速度。虽然MLP仅采用10种统计特征,并且训练的多层感知机分类器非常简单(包含1个含有6个神经元的隐藏层),但其分类速度仍然低于本文提出的随机森林分类器。鉴于目前其他加密流量识别神经网络分类器通常采用更加复杂的计算算法,因此若应用于快速、实时的分类场景则对计算环境有更高的需求。相比之下,本文采用的随机森林分类器更适合实时分类场景。 本文根据代理应用流量的特点,提出一组与负载无关的统计特征,并验证4种机器学习分类器对流和服务突发2种不同识别对象的分类性能。结果表明,本文提出的特征可有效识别代理应用流量,提出的分类器更适合实际应用。基于流的识别方法整体准确率优于基于服务突发的识别方法。但是,当一个代理应用长时间采用固定的五元组转发应用流量时,基于服务突发的识别方法能更好地识别此类代理应用流量。在4种分类器中,基于决策树的分类器,包括XGBoost和随机森林的识别能力及稳定性均优于SVM和朴素贝叶斯的。随机森林在识别代理应用流量时可达到99%以上的整体准确率,细粒度识别代理应用的整体准确率高于94%。 未来工作的开展方向包括: (1)更细粒度的代理应用流量识别,即识别代理应用流量承载哪些移动应用。这一工作要求更复杂的流量收集过程。直观的方法是在收集代理应用流量时,每次只运行一个移动应用,收集的流量的标签默认为该移动应用。但是,移动设备本身会产生背景流量,导致数据集标签不准确。其次在这种识别粒度下,一些统计特征会失效,如本文使用的options字段和PSH标志位相关特征很有可能不再有效,人工提取有效的特征变得更加困难。深度学习模型能够自动学习流量特征的特点,使其在此类应用场景中更有优势。 (2)本文未验证样本不均衡对分类器性能的影响,对于基于服务突发的识别分类器,Thunder应用的识别精度和召回率获得极大的提升,而其服务突发样本量也远远多于流样本数目,因此可进一步分析样本不均衡问题给分类器带来的影响。3.2 特征设计


3.3 模型设计
4 实验与结果分析
4.1 数据集


4.2 基于流的分类方法






4.3 基于突发的分类方法


4.4 分类器鲁棒性

4.5 与其他方法比较

5 结束语
