基于字段过滤和伸缩窗口的SNM算法优化*
2022-04-21周世杰娄渊胜
周世杰,娄渊胜
(河海大学计算机与信息学院,江苏 南京 211100)
1 引言
随着社会工业化和信息化水平的不断提高,存储在数据仓库中的数据迅速增加。通过数据挖掘可在这些海量的数据中找出蕴含的重要信息,这些信息往往对信息决策支持系统有重要作用,但挖掘的前提是有高质量的数据。高质量的数据是充分发挥其蕴含的效能的前提和基础,而低质量的数据可能对决策产生不利的影响[1,2]。数据清洗可以对存储在数据仓库中的“问题”数据进行剔除或改正[3],从而提高数据质量,为决策分析提供数据支撑。数据清洗的主要清洗对象是不完整数据、冲突数据和重复数据[4],其中需要解决的主要问题是对相似重复数据的查找与去除。相似重复数据是指对于现实世界的同一或类似实体,由于在各数据源存储时可能出现的格式或拼写错误、结构或表述不同等问题,数据库管理系统DBMS(Database Management System)不能准确识别而存储的多条不完全相同的记录[5]。在信息管理系统中,重复数据的存在会影响存储效率,造成数据冗余,识别和消除无用数据可以提高数据质量,保证决策数据的可靠性。
清除相似重复记录常用“排序-合并”的方式,其思想是将待检测的数据集按照某个或某些属性排序,使得数据集中的相似重复记录彼此靠近,然后通过比对邻近位置的记录判断是否为相似重复记录。常见的排序-合并算法包括邻近排序算法SNM(Sorted-Neighborhood Method)[6]、多趟邻近排序算法MPN (Multi-Pass Sorted Neighborhood)[7]和优先队列算法[8]等。其中,邻近排序算法SNM是一种比较流行的排序-合并算法,因其思想简单、效果明显和易于实现的优点而被人们广泛使用。SNM算法在排序后的数据集上设置一个固定大小的窗口,每次只比对窗口内的数据,窗口内的数据比对完毕后向下移动窗口再次进行比对,这种方式极大地减少了比对次数,从而加快了检测的速度。
虽然SNM算法加快了检测的速度,但依然存在一些缺点:(1)对排序关键字依赖程度大;(2)字段权重多为单一用户或领域专家设定,主观程度大;(3)窗口的大小难以确定;(4)记录匹配过程采用笛卡尔乘积的方式,比对时间较长。许多研究人员针对上述缺点提出了一些改进方案。文献[7]采用的方式是多次独立地执行SNM算法,每次选用不同的关键字对数据集排序,然后在小窗口中进行比对,此方法可以减少关键字选取不当所带来的影响,但该方式需要频繁计算传递闭包,降低了查准率。文献[9,10]使用的属性确定方法结合了客观数理统计方法和主观经验,虽然可以较为客观地确定属性权值,但此方法需要多用户的参与,在实际运用中耗时过长且不易实现。文献[11,12]依据窗口内重复记录的总数与窗口大小的比例动态调整滑动窗口的大小,但此种方式将SNM归并过程的时间复杂度从O(WN)提高到O(N2)(N为数据集总记录数,W为窗口的大小),时间效率不高。文献[13,14]提出了长度过滤算法,在识别重复记录前根据字符串的长度比例去除不相似的数据集,减少记录比较次数,提高检测效率,但如果属性值采用简写的方式或属性是非必填项,采用此方式可能会将重复记录排除,致使算法精度降低。
综上,本文提出了一种SNM的改进算法ISNM(Improved Sorted-Neighborhood Method)。该算法采用属性区分法客观地计算权值,提高了检测精度;采用字段过滤算法计算记录相似度,减少了比对次数;采用可变窗口来防止漏配,减少了无用的记录比对。实验结果表明,ISNM算法提高了检测精度,加快了记录比对速度。
2 SNM算法介绍
基本的SNM算法主要包括以下3步:
(1) 选取排序关键字。抽取记录的重要属性作为记录排序关键字。
(2) 排序。根据(1)中选取的关键字排序数据集。排序后重复记录会彼此靠近,从而将比对限定到一定范围内。
(3) 相似重复记录检测。设置一个大小为W的窗口,在第(2)步的基础上向下移动窗口。窗口的末尾记录与其余的W-1条记录比对,比对完成后将首条记录移出,将第W+1条记录移入,重复上述步骤直到所有记录都完成比对。
图1为SNM算法滑动窗口示意图。
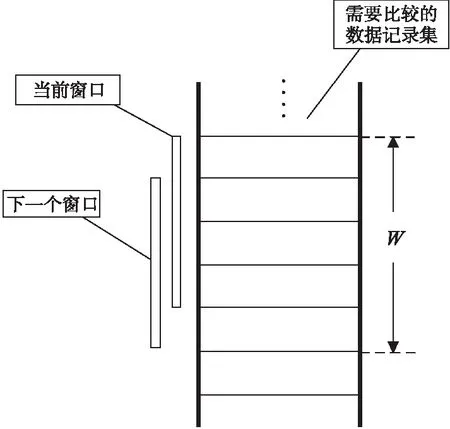
Figure 1 Sliding window in SNM algorithm
由上述描述可知,SNM算法将记录的比对限定在大小为W的固定窗口中,总比对次数为N(W-1)次;而传统的方法是将每一条记录与剩余的N-1条记录进行比对,总比对次数为N(N-1)/2。由此可见,SNM算法极大地减少了比对次数,因此极大地加快了检测速度,提高了运行效率。但是,SNM算法也存在以下不足:
(1) 对选取的排序关键字依赖性较大。选用不合适的关键字对数据集排序,会使相似重复记录不能同时出现在同一个窗口中,因无法比对而造成漏配。例如表1的2条记录,无论是按照Name属性排序,还是按照Address属性排序,或者2个属性组合排序,都存在因它们存储的位置不相邻而产生漏配的可能。

Table1 Example of similar duplicate records
(2)难以确定滑动窗口的大小W。如果W较大会增加无用的比对,降低检测效率;如果W较小又可能导致漏配,降低检测精度。
(3)确定属性权值的主观性大。属性权值大多是采用单一用户或者专家打分的方法来确定,因此主观性大。
(4)在重复相似度检测过程中,相似记录的判别基本上都是采用笛卡尔积的方式,采用该种方式会导致记录的匹配时间较长,检测效率不高。
3 ISNM算法
本文针对SNM算法的缺点提出了改进的ISNM算法,其思想是:首先通过属性区分法计算各属性权值,并通过权值来确定排序关键字;其次采用字段过滤算法进行判重,提高检测效率;最后使用可变窗口进行比对。ISNM算法流程图如图2所示。
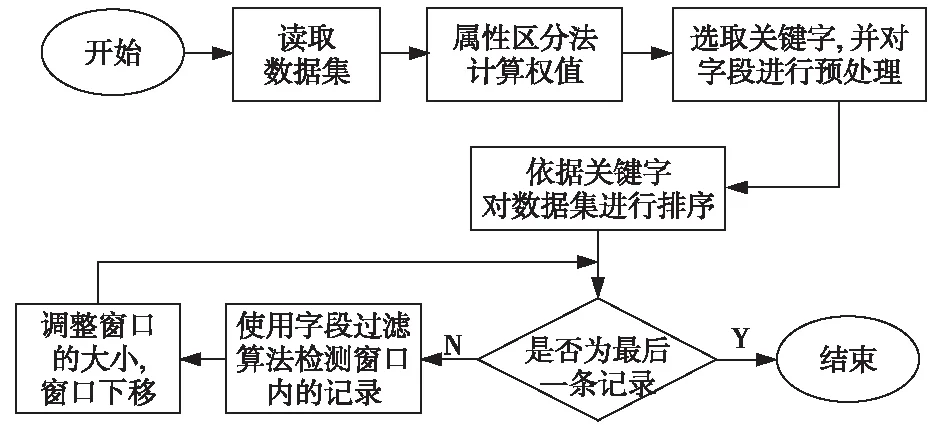
Figure 2 Flow of ISNM algorithm
3.1 属性区分法计算权值
记录的属性体现了现实实体的某个特性,属性的权值又代表了该特性对实体的重要性,属性权值越大,则该属性对其所表示的现实实体的重要程度就越大,因此权值的设定不应该有较强的主观性。本文提出使用“属性区分度”来确定属性权值,一方面避免了权值设定的主观性,另一方面不需要多用户参与,在实际应用中容易实现。
属性区分度是指属性区分数据集中不同记录的能力,某个属性取值种类越多,则该属性的属性区分度就越大。属性的区分度代表了该属性记录的差异性,因此属性区分度越大,该属性的权值就越大。将计算得到的属性区分度值归一化处理后得各属性权值。
为方便描述,假设待检测的数据集D={D1,D2,…,DN},N为记录总数,每条记录有p个属性,即Di={Attr1,Attr2,…,Arrtp},则每个属性的区分度计算公式为:
(1)
其中,YAttri表示属性Attri的取值种类数,也就是说如果按照属性Attri的不同取值进行聚类,会有YAttri个簇。将各个属性的区分度值进行归一化处理后,得到属性的权值向量W={W1,W2,…,Wp}。属性区分算法如算法1所示。
算法1属性区分算法
输入:数据集D={D1,D2,…,DN}。
输出:字段权值(W1,W2,…,Wp)(p表示记录的属性个数)。
1.Fori=1 topDo
2. 计算属性i的取值种类数YAttri;
3.Endfor
4.Fori=1 topDo
5. 根据式(1)计算属性i的属性区分度Attrdisi;
6.Endfor
7.对Attrdisi进行归一化处理;
8.ReturnWi
3.2 关键字的选取与预处理
由3.1节可知,属性的区分度代表了该属性记录的差异性,选择区分度大的属性对数据集进行排序,可以最大程度保证相似重复记录位置靠近,并将非相似重复记录分隔开。对数据集中每条数据的各个属性利用算法1计算其属性权值,并按由大到小顺序排序,根据实际情况选取排名靠前的属性作为排序关键属性,并从每个关键属性中提取一部分组成排序关键字对数据集进行排序。如针对滁河流域水文数据集,经过上述方法处理后,最终选取“站点名称”“地区”“获取数据时间”和“传感器编号”作为排序关键属性,取每个关键属性的前4个字符作为排序关键字对数据集进行排序。
对数据集进行排序之前,首先把字段中标点符号、不能辨别的或有标示性含义的符号删除,例如银行系统的“¥”“$”等;其次将字段中的单词按照字典序排列;最后再按照排序关键字对整个数据集进行排序。假设选择表1中Name和Address属性的组合作为排序关键字,按照上述方法对记录进行排序后的结果如表2所示。由此可见,经过预处理之后,可以使这2条记录存储位置相距较近,确保它们在同一个窗口中。

Table 2 Record sorting results table after preprocessing
3.3 字段过滤算法
SNM算法检测相似重复记录常用的方法是求出2条记录各属性值的相似度,并加权求和得到记录相似度,然后将该值与相似度阈值对比来判定记录是否相似重复。然而字段比对大多采用的是笛卡尔乘积的方式[15],采用这种方式的问题是记录匹配时间过长,效率不高。本节针对该问题提出使用字段过滤算法来提高检测效率。
字段过滤算法的核心思想是:记录的不同属性值可以区分不同的记录,且关键属性的属性值对记录的区分度更高。若对关键属性的相似度进行加权求和后可以确定2条记录为相似重复记录,则无需计算剩余属性的相似度;否则需要计算所有属性的相似度,加权求和后判断2条记录是否为相似重复记录。因此,在进行相似度检测时,首先选择关键属性进行比较,将关键属性的相似度与权值相乘并求和得到记录相似度,然后将其与相似度阈值相对比,若前者大于后者,则断定这2条记录相似重复,同时完成属性比对,否则,继续比对剩余属性。
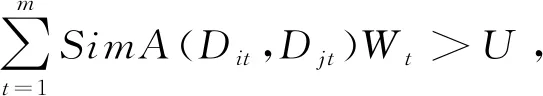
(2)
否则有:
(3)
字段过滤算法如算法2所示。
算法2字段过滤算法
输入:待比较的记录Di和Dj,相似度阈值U。
输出:SimR(Di,Dj)。
1.Fort=1 tomDo
2.SimR(Di,Dj)=SimA(Dit,Djt)Wt;
3.Endfor
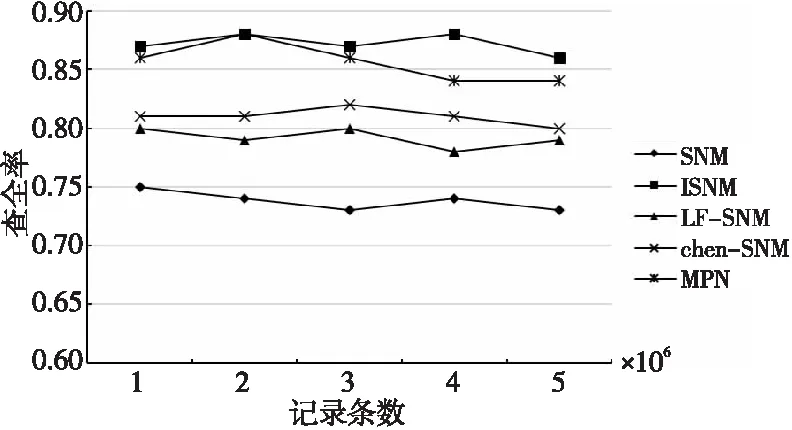
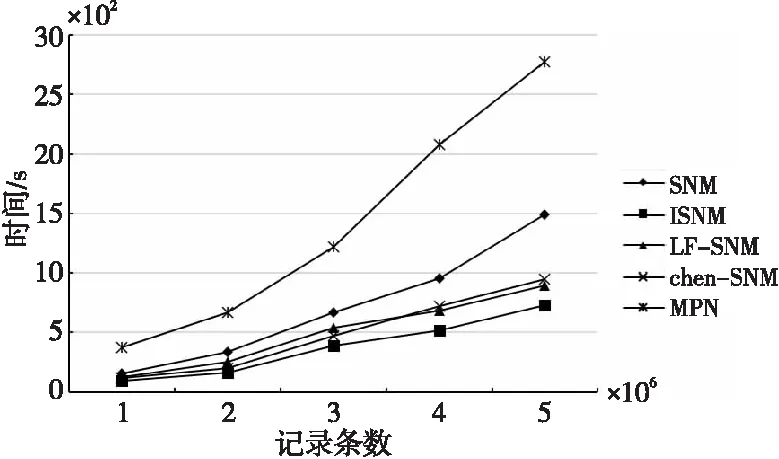
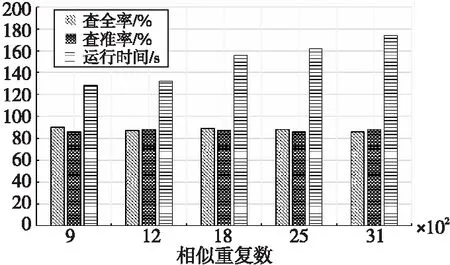
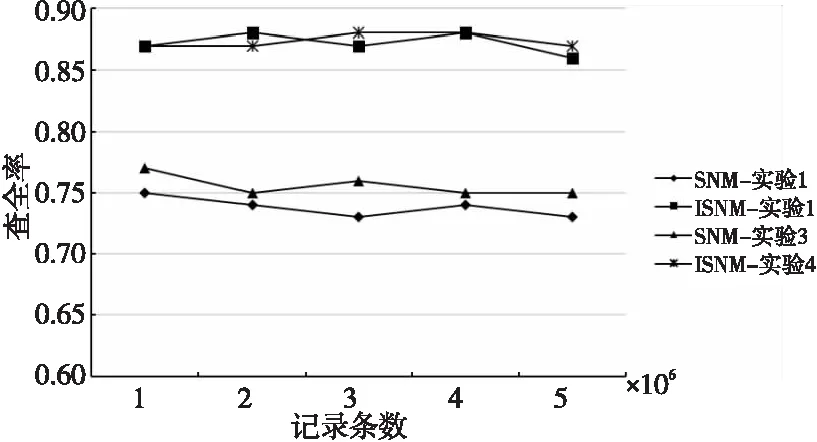
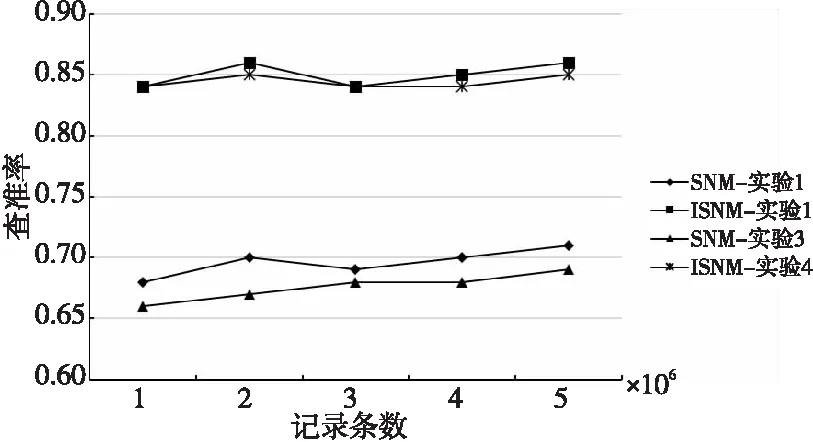
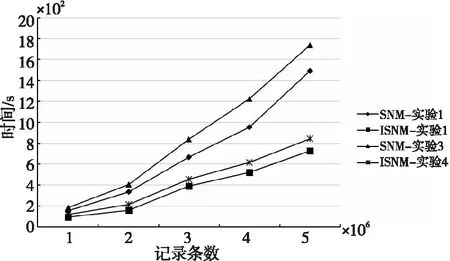
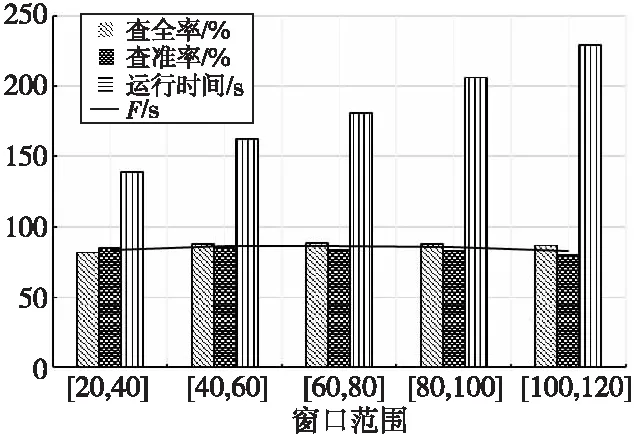
4.If(SimR(Di,Dj) 5.Fort=m+1 topDo 6.SimR(Di,Dj)+=SimA(Dit,Djt)Wt; 7.Endfor 8.Endif 字段过滤算法极大地减少了字段比对的次数,从而加快了检测速度。 原SNM算法滑动窗口的大小不易确定,窗口设置得太大会增加很多无用的记录比对,降低检测效率;窗口设置得太小又可能导致重复记录的漏配,降低检测精度。使用可变窗口可以在检测过程中动态调整窗口的大小,从而减小固定窗口给检测结果带来的影响。本文根据相似重复记录的位置动态调整滑动窗口的大小,其基本思想是:假设窗口C的开始大小为W,若新移入C的记录Rw与即将移出C的记录R1是相似重复记录,则Rw+1与R1相似的概率较高,此时应当增大窗口的大小,避免相似重复记录的漏配;若与Rw互为相似重复的记录Ri(1≤i≤w)距离Rw较近,则应该缩小窗口大小,减少无用的比对。设窗口C大小的最大最小值分别为Wmax和Wmin,窗口C大小的初始值Wn设定为Wmin。C中记录的位置为[1,w],位置为1的记录为C内的首条记录,位置为w的记录为新移入C中的记录,则动态计算滑动窗口大小的方法如式(4)所示: (4) 其中,Bi表示第i条记录是否与末尾记录Rw互为相似重复记录,若是,则Bi=1,否则,Bi=0。由式(4)不难看出,若C内的所有记录都相似重复,则下一轮C的大小从Wn变成Wmax,若C内的所有记录都不相似重复,则下一轮C的大小从Wn变成Wmin,距离末尾纪录Rw越远的相似重复记录对C的取值作用越大。 ISNM算法的基本流程是:使用属性区分法计算各属性权值,并在权值的基础上选择排序关键字,对字段预处理后,再按照排序关键字排列数据集中的记录,在窗口内对数据子集进行判重,在判重的过程中使用字段过滤算法提高检测效率,然后调整窗口大小并向下移动窗口,重复进行判重。ISNM算法流程如算法3所示。 算法3ISNM算法 输入:数据记录集D,相似度阈值U,窗口最大值Wmax与最小值Wmin。 输出:去重后的数据集。 步骤1计算属性权值。 使用算法1计算记录各属性的权值Wi。 步骤2关键字的选取与数据记录预处理。 根据3.2节描述的方法选取排序关键字 Fori=1 toNDo/*N表示数据总量。去除字段中的无用符号,并将字段中的单词按照字典序排列*/ Endfor 步骤3按照排列关键字对数据集进行排列。 步骤4在滑动窗口中使用字段过滤算法进行重复记录检测,并动态调整窗口的大小。 While(滑动窗口没有滑到数据集的尾部) 使用算法2计算相似度值; If(SimR(Di,Dj)≥U) D=D-Ri;∥Ri表示第i条记录 Endif 根据式(4)计算下一个滑动窗口大小; 向下滑动窗口; Endwhile 本次实验数据来自滁河流域近3年各站点所观测的水位记录,记录了站点名称、数据获取时间、地区、传感器编号和水位等内容。由于记录过程中传感器异常导致同一时间重复记录水位信息,因此采集到的数据存在大量的重复数据。 实验环境为Intel(R) Core(TM) i5-1035G1 CPU @ 2.2 GHz,16 GB内存,Windows 10操作系统。数据存储在MySQL 5.6中,采用IntelliJ IDEA编程工具和Java语言实现优化算法,jdk版本为1.8。 4.2.1 性能实验 实验1为了更好地分析ISNM算法带来的性能提升,本次实验把ISNM算法与传统的SNM算法、文献[14]的LF-SNM(SNM based on Length Filtering and Dynamic Fault-tolerance)算法、文献[16]的SNM改进方法(在本文中称为chen-SNM算法)、MPN(Multi-Pass Sorted Neighborhood)算法进行对比实验。实验每一次从数据集中随机抽出10万,20万,30万,40万和50万条记录,分别用上述5种算法进行检测。为了便于统计实验结果,将上述各数据集处理成包含0.12万,0.25万,0.43万,0.56万和0.71万条相似重复记录的数据集,用人工统计的方式判断实验得出的相似重复数据集是否正确。实验中设定相似度阈值为0.75,可变窗口的最小值为40,最大值为60,固定大小的窗口值为40。 实验2为了检验ISNM算法在相同数据规模、不同相似重复记录条数下的有效性,设置如下实验:从数据集中随机抽取20万条记录,并将此数据集处理成包含0.09万,0.12万,0.18万,0.25万和0.31万条相似重复记录的数据集,仍采用人工统计的方式处理实验结果。此次实验设定相似度阈值为0.75,可变窗口的最小值为40,最大值为60。 4.2.2 不同窗口大小对消除结果的影响 实验3为了看出不同窗口对实验结果的影响,设置可变窗口的最小值为60,最大值为80,可变窗口与固定窗口的初始值为80,在与实验1同样的实验环境中进行实验,并将实验结果与实验1的结果进行比较分析。 实验4为了检验ISNM算法在相同数据规模和相似重复记录条数下,不同窗口范围对实验结果的影响,设置如下实验:从数据集中随机抽取20万条记录,并将此数据集处理成包含0.25万条相似重复记录的数据集,将可变窗口的最小最大值分别设置成[20,40],[40,60],[60,80],[80,100]和[100,120],设定窗口的初始值取窗口的最小值,相似度阈值为0.75。 4.2.3 评价指标 实验性能评价指标采用查准率(precision) 、查全率(recall)[17]和运行时间开销。查全率和查准率定义如式(5)和式(6)所示: (5) (6) 其中,tp表示检测出来的相似重复记录是正确的数量,fp表示检测出来的相似重复记录是错误的数量,fn表示没有检测出来的相似重复记录的数量[17]。故tp+fp表示检测出来的相似重复记录的总量,tp+fn表示数据集中原本存在的重复记录总量。 4.3.1 性能实验 基于上述实验方案,使用各算法在相同的实验环境下对待检测的数据集进行重复记录检测,实验结果如图3~图5所示。 Figure 3 Comparison of precision of each algorithm 由图3可以看出,ISNM算法的查全率优于其他各算法的。ISNM算法采用属性区分法确定字段权值,解决了权值主观性过强的问题,在排序之前对排序关键字进行预处理,使相似重复记录存储在靠近的位置以避免漏配,并使用大小可变的窗口进行检测,避免了因窗口过小而引起的漏配,从而提高了查全率。MPN算法多次独立地执行SNM算法,每次选用不同的关键字对数据集进行排序,故查全率较高,但MPN算法固定移动窗口大小,窗口设置得太大或太小对查全率都有比较大的影响,因此MPN算法的查全率低于ISNM算法的。LF-SNM算法与chen-SNM算法采用的字段权值调整方法需先人为设定再进行调整,仍具有一定的主观性,故查全率较低。 Figure 4 Comparison of recall of each algorithm 由图4可以看出,ISNM算法的查准率要优于其他算法的。ISNM采用了伸缩滑动窗口的方式,当窗口较大时可以动态缩小窗口,避免了因不必要的记录比对导致检测出来的记录是错误的情况,并且使用字段过滤算法减少了比较次数,而不使用传递闭包的方式,降低了误识别率,故查准率高。而chen-SNM算法、LF-SNM算法和MPN算法均采用传递闭包的方式整合重复记录,会产生很多的误识别,因此这3种算法的查全率不如ISNM算法的。 Figure 5 Comparison of running time of each algorithm 由图5可以看出,在同样的实验环境中ISNM算法的时间效率优于其他算法的。ISNM算法使用了可变窗口的方式,避免了无用的记录比对,并同时使用字段过滤算法计算记录的相似度,提高了记录的比对效率,因此ISNM算法的时间开销小。chen-SNM算法与LF-SNM算法分别采用了伸缩窗口和长度过滤的方式来提高效率,但这2个算法需要计算传递闭包,因此这2个算法的时间开销与ISNM算法的相近但低于ISNM算法的。MPN算法需要多次独立执行SNM算法,每次选择不同的关键字排列数据集,并且合并数据集合时需要计算传递闭包,因此时间开销较大。 4.2.1节中的实验2的实验结果如图6所示。 Figure 6 Comparison results under different similar repeat scales 由图6可以看出,ISNM算法在相同数据规模、不同相似重复记录条数下,查全率与查准率一直处于相对稳定的状态,并同时保持了较高水准。其次运行时间随着相似重复数的增加而逐渐增大,但是仍在可接受的范围内,由此可进一步证明本文所提算法的优越性。 4.3.2 不同窗口大小对消除结果的影响 基于4.2.2节中的实验3的实验结果如图7~图9所示。 Figure 7 Comparison of precision between ISNM algorithm and SNM algorithm Figure 8 Comparison of recall between ISNM algorithm and SNM algorithm Figure 9 Comparison of running time between ISNM algorithm and SNM algorithm 由图7和图8可以看出,ISNM算法的查全率和查准率明显优于SNM算法的。随着窗口的增大,窗口内覆盖的重复记录变多,避免了目标记录的漏配,故SNM算法的查全率会提高,但查准率会下降,这是因为固定窗口不能调节大小,增加了无用的记录比对导致误识别增多。初始值为80的窗口几乎包括了所有目标记录,故ISNM算法的查全率变化不大,但查准率会稍微下降,这也是由于窗口增大造成误识别增多导致的,但可变窗口会及时缩小窗口大小来避免这种情况的发生。 由图9可以看出,ISNM算法的时间开销要优于SNM算法的。随着窗口的增大,增加了窗口内的记录比对次数,故ISNM算法与SNM算法的时间开销都会变大,其中SNM算法的时间开销变化较大,而ISNM算法由于采用了可变窗口,可以及时调整窗口的大小,所以时间开销变化的幅度不大。 基于4.2.2节中的实验4的实验结果如图10所示。 Figure 10 Comparison results of different window ranges 由图10可以看出,随着窗口范围的增大,查全率先增大,然后趋于平稳;而查准率先增大,然后减小。在此使用查全率和查准率的调和均值F值来反映ISNM算法的性能。从图10中的折线可以看出,窗口大小在[60,80]和[80,100]时F值达到最大,再结合2个范围的运行时间可以得出,针对本文的实验数据,最优的窗口为[60,80]。 数据清洗可以有效地提高数据源的数据质量,消除数据中的重复记录是其中的一个热门课题。本文分析了传统SNM算法,并指出了传统SNM算法的缺陷,针对原算法的缺陷提出了基于SNM的改进算法——ISNM算法。主要提出了4点改进:(1)采用属性区分法确定属性权值,解决了单一用户设定固定权值的不足,提高了算法检测的精度;(2)根据权值选取排序关键字,避免了关键字选取不当对SNM算法精度的影响,并对关键字进行预处理,使得相似重复记录位置彼此靠近以避免漏配;(3)使用字段过滤算法计算相似度,减少了窗口内记录属性的比对次数,加快了算法的检测速度;(4)使用可变窗口的方式进行检测,既防止了记录的漏配,也减少了无用的匹配。通过对实际系统中的数据进行实验,采用查全率、查准率和运行时间评价标准验证了ISNM算法的可行性与优势。然而改进算法无法识别文字不同但语义相同的相似重复记录,另外相似度阈值的取值范围也是一个亟需解决的问题,过大或过小的阈值都会对查重精度产生影响,下一步将针对这些问题进行研究。3.4 可伸缩滑动窗口
3.5 相似重复记录检测改进方法
4 实验与结果分析
4.1 实验环境及数据
4.2 实验方案及评价指标
4.3 实验结果分析
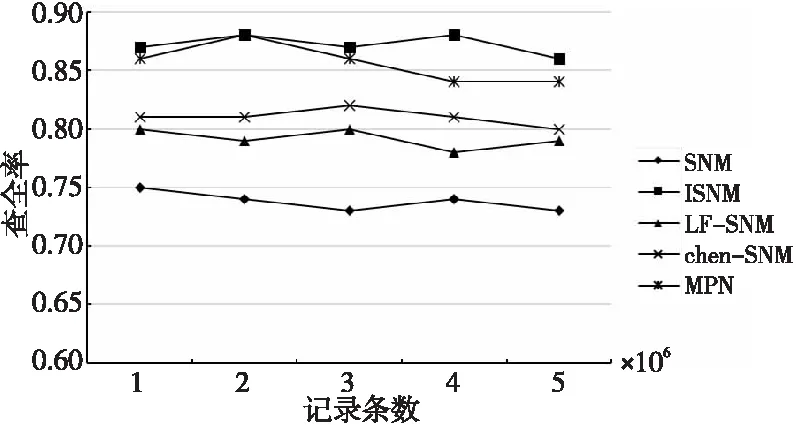
5 结束语
