改进条件生成对抗网络的文本生成图像方法*
2022-04-20侯丽君倪建成张素素
侯丽君, 倪建成, 张素素
(曲阜师范大学网络空间安全学院,273165,山东省曲阜市)
0 引 言
文本生成图像是指以关键词或句子的形式将人类的书面文本描述转化为与文本具有相似语义图像的方法,业已成为图像生成领域的热点研究方向,在艺术生成、计算机视觉和计算机辅助设计等领域具有广泛的应用需求,对文本生成图像任务的研究推动了跨视觉和语言的多模态学习与推理的研究进展. 最近提出的文本生成图像方法大多基于生成对抗网络(GAN)[1]模型,主要结构包含生成器和判别器. 从本质上而言,生成器和判别器之间是一种极大极小的博弈游戏,当判别器试图区分真实数据和生成器生成的数据时,生成器则试图欺骗判别器,GAN通过两者间的这种对抗性训练实现图像的生成.
伴随GAN的研究进展,基于GAN的文本生成图像研究已经取得了较为丰硕的成果. 2016年,GAN-INT-CLS[2]模型首次将条件GAN[3]应用于文本生成图像任务,同时在输入数据中增加文本特征作为生成器和判别器的约束,最终生成64×64分辨率的图像. 从此,大部分文本到图像生成任务采用GAN作为基础模型. 随后,StackGAN[4]模型首次提出多阶段图像生成机制,实现了由粗粒度到细粒度的图像生成,能够生成256×256高分辨率的图像. 2017年,AttnGAN[5]网络模型将注意力机制引入GAN,使其能够利用多层次(例如词级和句子级)条件生成细粒度的高质量图像. 自此以后,文本生成图像方法多采用注意力和多阶段相结合的模式生成高分辨率图像. 多阶段生成方式即将多个GAN进行堆叠,通过应用多对生成器和判别器逐渐增加图像分辨率,最终能生成256×256分辨率的图像. 这种生成方式的弊端在于:(1)需要训练多个GAN,占用较多服务器和GPU资源,对于一些小成本实验室来说计算成本较高.(2)文本句向量仅在初始阶段与噪声进行连接作为输入,在后续生成阶段没有额外引入文本句向量,会导致文本信息在生成过程中逐渐丢失,影响生成图像的语义一致性.
为了解决多阶段生成方式的问题,提高生成图像的质量,本文提出了改进的条件生成对抗网络(TxtGAN)实现文本到图像生成. 相比训练多个GAN进行堆叠,TxtGAN只需训练单个GAN,即一对生成器和判别器,减少了计算成本,并且同样可以生成256×256分辨率图像. 另外,TxtGAN在每个生成模块中应用条件批量归一化方法,使得文本信息在生成过程中得以保留,加强了文本与图像的融合,最终生成的图像能够与文本描述语义一致.
1 模型架构
本文提出了一种改进的条件生成对抗网络(TxtGAN)模型,该模型由文本编码器、条件增强模块、生成器和判别器等模块组成,整体架构如图1所示. 文本编码器对输入的文本描述进行处理,获得富含文本语义信息的词向量与句向量,词向量用作判别器的输入数据之一,而经过条件增强(CANET)之后的句向量,则作为文本条件信息添加到生成器的每个生成模块中. 生成器设计6个隐藏图像特征生成模块(RUPBlock)和一个图像生成模块(ImgBlock),以实现256×256分辨率图像的生成. 随后,生成图像与相应的句向量、词向量一起作为判别器的输入,得到对抗性损失,该损失作为生成器的“信号”引导生成器的图像合成过程. 以下将详细介绍模型中各模块的功能.
1.1 文本编码器
采用预训练的双向LSTM[6]作为文本编码器来处理文本描述. 双向LSTM包含前向LSTM和反向LSTM,前向LSTM接收正向文本描述序列数据,反向LSTM接收该序列数据的反向副本,结构如图2所示. 图中xi表示文本描述的第i个单词,每个单词分别对应正向与反向2个隐藏状态,连接这两个隐藏状态作为该词的语义信息表示yi. 双向LSTM的最后一个词的语义信息yn表示为全局句向量. 假设词向量表示为w∈D×L,其中D为词向量的维数,L为单词的数目;全局句向量用s∈D表示.
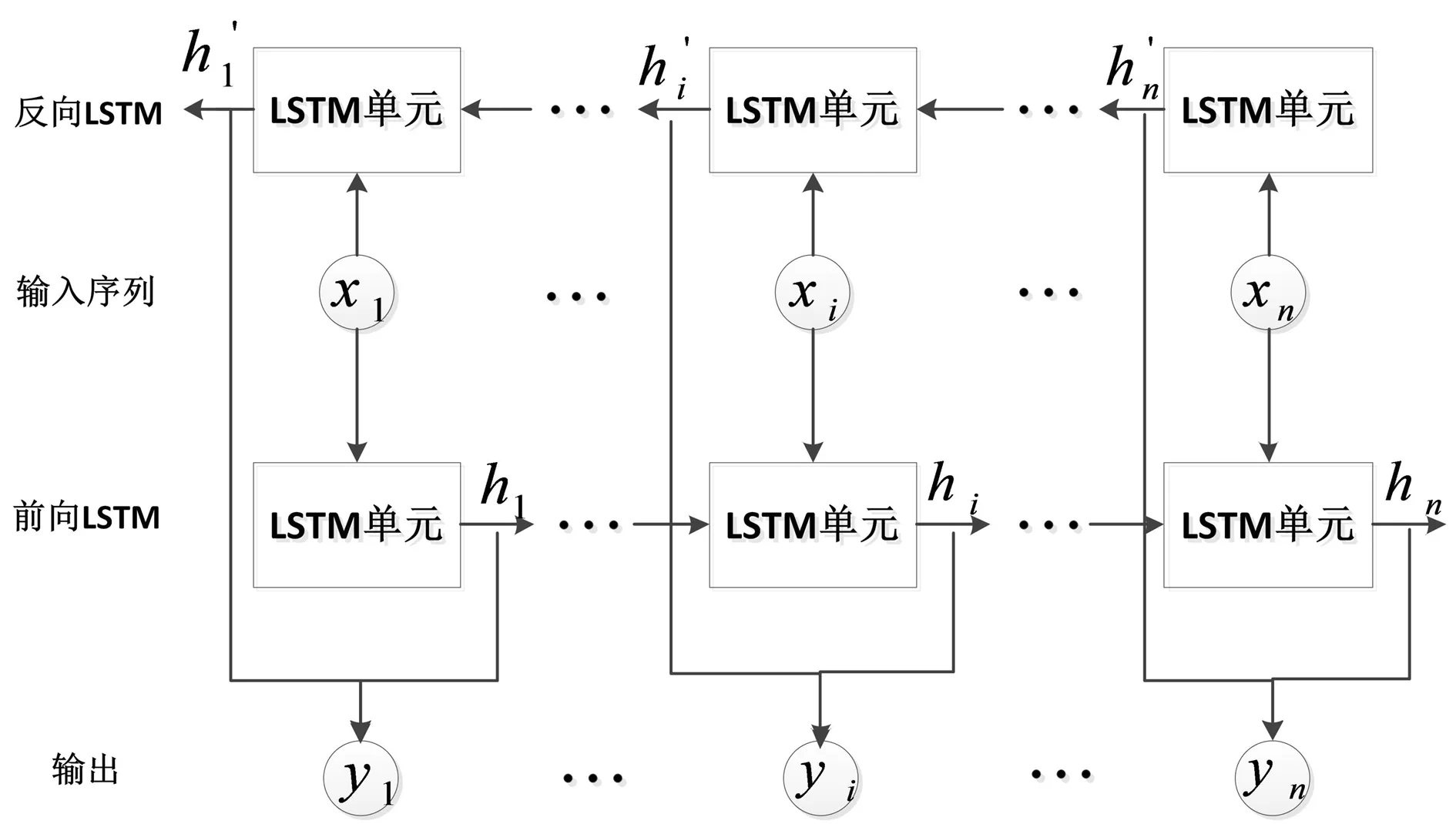
图2 双向LSTM结构
1.2 条件增强网络
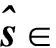
1.3 生成器模型
现阶段生成高分辨率(256×256分辨率)图像的GAN多延续StackGAN[4]及其后续改进版本[7]的多阶段生成模式,即堆叠多个GAN,从粗粒度到细粒度实现图像生成. 在StackGAN++[7]中,第一阶段的GAN生成64×64分辨率图像,生成256×256分辨率图像需要堆叠3个GAN. GAN自推出以来,因其训练不稳定、难以达到纳什平衡而饱受诟病,训练多个GAN,势必会加剧训练不稳定的问题.
为了解决多GAN堆叠方式带来的弊端,本文利用单个GAN,即一对生成器判别器来实现文本到图像生成. 在生成器中设计6个隐藏图像特征生成模块(RUPBlock)和一个图像生成模块(ImgBlock),生成256×256分辨率图像. 生成器生成过程可用下列公式表示
(1)
(2)
x=Img(hn),
(3)
其中,hi表示隐藏图像特征,z表示取样自高斯分布的噪声向量z~N(0,1),x表示最终生成的256×256分辨率图像.FC代表全连接层,Ri表示每个RUPBlock,Img表示生成图像的ImgBlock模块.
1.3.1 生成模块设计
RUPBlock包含改进的残差模块和上采样模块,结构如图3所示.
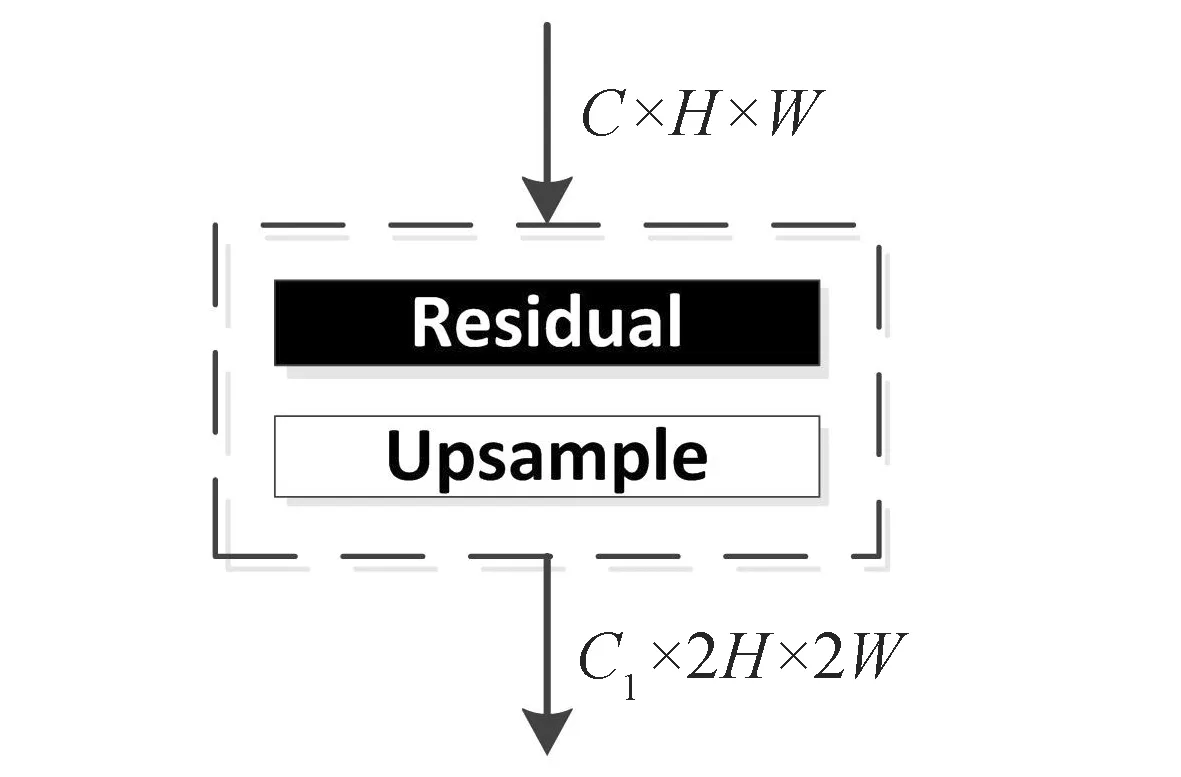
图3 RUPBlock结构
图3中,Residual表示残差模块,Upsample表示上采样层.C、H、W分别代表隐藏图像特征的通道数、高和宽,C1表示RUPBlock生成的新的图像特征的通道数. 上采样模块选择最近邻插值方法,将隐藏层图像特征空间维度扩大为原先的2倍. 另外,在残差模块中额外引入了条件句向量,使用条件批量归一化代替原始批量归一化方法,从而能在图像生成过程中充分学习文本条件语义信息,有助于提高生成图像的质量. 残差模块设计如图4所示.
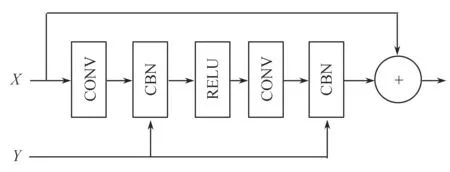
图4 使用CBN的残差块
图4中,X代表图像特征,Y表示文本条件信息,CONV、CBN、RELU分别表示卷积层、条件批量归一化和相应的激活函数.
生成最终图像的ImgBlock模块由残差模块与卷积层组成,通过Tanh激活函数生成256×256分辨率图像.
1.3.2 条件批量归一化
(4)
其中,xn,c,h,w是一个小批量(mini-batch)内的数据,n,c,h,w分别对应批量的大小、通道数、高和宽,μx和σx表示该数据在特征通道上的均值和方差. ò是为了保证数值稳定性的小的正常数.
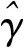
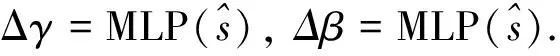
(5)
使用增量更新CBN的仿射参数,如公式(6)所示
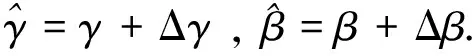
(6)
1.4 判别器模型
在文本生成图像任务中,判别器需要判别生成图像的真实性和语义一致性,即判断输入的图像属于真实数据还是生成图像以及判断生成图像的内容是否符合文本描述. TxtGAN模型的判别器共有2个分支,其一,句向量与处理后的图像特征作为输入,计算文本-图像对条件损失,确保图像与文本语义统一;其二是探索词与图像区域之间的相关性[12],提供细粒度的监督反馈,从而促进生成器的有效训练.
句向量分支中,首先生成的图像x经过连续下采样,获得空间维度为4×4的特征映射. 连接该特征映射与条件信息,经过2个卷积层之后,输出条件对损失.
(7)
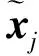
最后,相关系数权重以及第i个单词的词感知特征由公式(8)和公式(9)计算
(8)
(9)
其中,αi,j表示词向量第i个单词和生成图像的第j个子区域的相关性.ci表示对生成图像特征进行加权之后,获得的图像子区域感知的词特征,维度为c∈D×L. 图像子区域感知的词特征计算过程如图5所示.
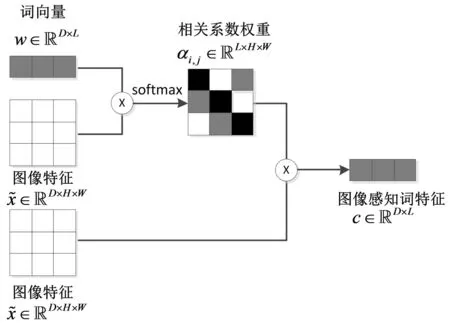
图5 图像子区域感知的词特征计算
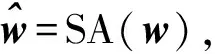
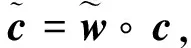
(10)
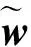
(11)
其中r表示单词与图像之间的相关性,σ表示sigmoid函数,相关性计算过程如图6所示.
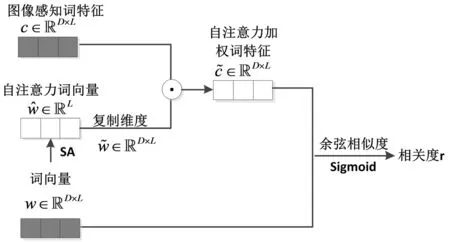
图6 单词与图像特征相关性计算
2 损失函数
相比原始GAN[1]中的损失函数,本文采用更容易收敛、训练过程更稳定的hinge损失函数[15],以文本为条件的hinge损失函数如公式(12)所示.
LD=-Εx~pdata[min(0,-1+D(x,s))]-
(12)
其中,s表示句向量,w表示词向量,z表示服从高斯分布的噪声向量,pdata,pz,pmis分别代表真实的数据分布、高斯分布、与文本描述不匹配的真实图像分布.
生成器的损失函数如公式(13)所示
LG=-Εz~pz,D(G(z),s).
(13)
3 实验结果及分析
3.1 数据集
为了验证提出方法的有效性,在经常用于评估文本生成图像模型效果的CUB鸟类数据集[16]和COCO数据集[17]两个数据集上进行了实验,并基于StackGAN++[6]进行了预处理.
CUB数据集包含11 788张鸟类图像,一共200个类别,每张图像对应10个文本描述. 将CUB鸟类数据集划分为类别互斥的训练集与测试集,其中训练集包含8 855张图像,共计150类,测试集包含2933张图像,共计50类.
COCO数据集相比鸟类数据集而言包含的图像更加复杂,图像共包含80个对象类,其中每个图像与面向对象的注释(即边框和形状)和5个文本描述相关联. 使用2014年官方训练集(超过8万张图像)和验证集(超过4万张图像)进行训练和测试.
3.2 实验环境与参数设置
实验平台为Ubuntu 16.04.7操作系统,处理器为Intel Xeon Gold 6130十六核CPU,内存共256 G,使用显存为16 G的Tesla P100显卡加速图形运算. 实验环境为python3.7.9,采用基于pytorch的深度学习框架,版本为1.4.0. 实验在CUB数据集和COCO数据集上分别训练了600和120 epoch,2个数据集上批次大小均设置为24. 整个实验在CUB数据集上运行了约6天,COCO数据集则需要12天.
实验使用Adam[18]优化器训练网络,其中2个超参数设置为β1=0.0,β2=0.9. 遵循2次尺度更新规则(TTUR)[19]并将生成器和判别器的学习率设置为0.0004和0.0001.
3.3 定量结果分析
Inception Score(以下简称IS)[20]是评价GAN模型生成图像常用的指标,IS使用ImageNet分类模型来评价生成图像的多样性和真实性,较高的IS意味着生成的图像的质量更好. FID[19]使用预先训练的Inception-v3[13]网络中提取真实数据与生成图像的特征,来衡量两者之间的分布距离. FID越小,代表生成图像的分布与真实数据分布更接近,生成的图像更真实. 相比IS而言,FID是一个鲁棒性更强的指标,并且与人类的定性评估一致[20]. 本文沿用StackGAN++[7]的方法对CUB数据集上生成的图像进行IS评估,对COCO数据集则采用DM-GAN[21]的IS评估方法,同时按DM-GAN所述方法对2个数据集进行FID分数的测量. 选用2个基线模型StackGAN++和HDGAN[22],前者是StackGAN的改进版本,利用多GAN堆叠方式进行图像生成,而HDGAN则使用层级生成方式. 与TxtGAN不同的是,HDGAN保留从64到256所有隐藏层生成图像的结果,并且使用3个判别器,而TxtGAN只保留了256×256输出图像,因此仅对基线模型生成的256×256图像进行IS和FID评估. IS和FID结果分别如表1和表2所示.
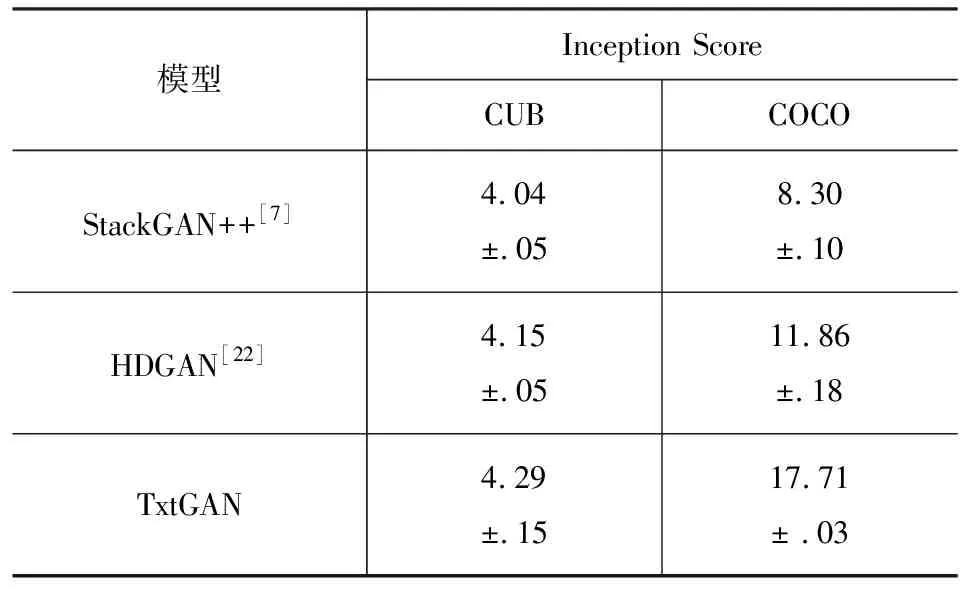
表1 CUB和COCO数据集上不同模型IS对比
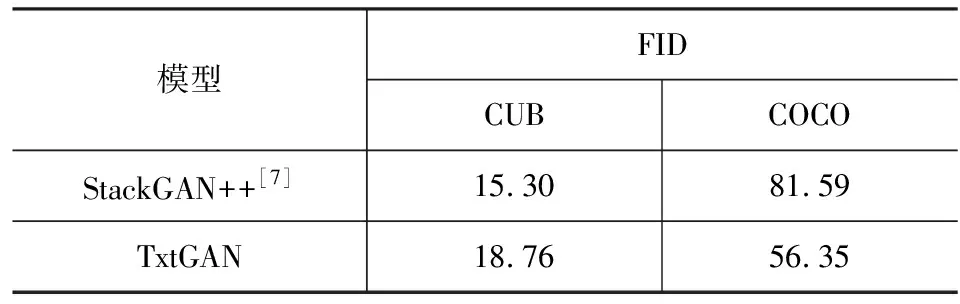
表2 CUB和COCO数据集上不同模型FID对比
从表1中可以看出相比StackGAN++和HDGAN,TxtGAN在CUB数据集上IS分别提高了0.25和0.14,在COCO数据集上,IS分别提高了9.41和5.85. 关于FID分数,TxtGAN相比StackGAN++而言,在COCO数据集上下降了25.24,在CUB数据集上FID分数有所增加,因此本文将进一步进行定性结果分析. 由于HDGAN论文中未涉及FID分数测量,因此仅使用StackGAN++作为对比方法.
3.4 定性结果分析
为了从人类视觉角度直观比较生成图像的质量,对StackGAN++[7]、HDGAN[22]和TxtGAN生成的图像进行了比较.
首先,在CUB数据集上比较生成图像的质量和图像与文本的语义一致性,然后比较在复杂场景下,也就是COCO数据集上的生成结果. CUB数据集上3种GAN模型的生成结果如表3所示. 从表3中可以看出,StackGAN++生成的图像相比TxtGAN生成图像而言更高清一些,但其轮廓较为模糊,生成细节不足,例如第1和第2个文本描述生成的图像中,StackGAN++无法生成清晰的鸟类眼睛,而TxtGAN可以做到. 而HDGAN生成的图像背景较为单一,并且出现了树枝悬在空中的不符合常理的图像.

表3 3种GAN模型在CUB数据集上的生成结果
对于COCO数据集而言,本文选择从基线方法的预训练模型生成的测试集中挑选图像与TxtGAN进行比较,为了使图像具有普遍性,挑选了建筑物、人体、交通工具、动物类别的图像,结果如表4所示. 从表4中可以看出,TxtGAN方法能够生成与文本描述相一致的人群,尽管在人脸等细节方面仍然生成能力不足,但相比StackGAN++和HDGAN而言,TxtGAN可以生成完整的人体图像,StackGAN++生成的人体支离破碎、背景一片混乱,HDGAN则出现了多个人体重叠的现象. 在生成交通工具类图像方面,表4第2个文本描述生成结果表明,TxtGAN不仅能生成飞机,而且能表现出多云的天气,StackGAN++没有做到这一点,HDGAN生成飞机失败. 在生成动物方面,TxtGAN可以生成羊群,但没有成功地生成建筑物,而StackGAN++和HDGAN两者均生成失败,经过对测试集的取样分析,本文认为在StackGAN++生成羊群过程中产生了模式崩溃,生成的羊群与表4第6行第2列单元格中的不明组织物图像类似.

表4 3种GAN模型在COCO数据集上的生成结果
4 结束语
针对传统文本生成图像方法中多阶段生成方式堆叠多个GAN带来的计算成本高以及文本信息在生成过程中逐渐丢失等问题,本文提出了改进条件生成对抗网络的文本生成图像模型(TxtGAN). 模型使用一对生成器判别器实现文本到图像生成,相对于训练多个GAN来说节省了计算资源. 生成器设计多个生成模块来增加生成图像的分辨率,同时通过条件批量归一化方法在每个生成模块中引入文本句向量信息加强条件融合,最大限度地保留了文本信息. 判别器中除句向量以外,增加词向量输入,引导生成器更有效训练. 经过在CUB数据集和COCO数据集上的定量结果和定性结果分析,相比StackGAN等堆叠GAN的生成方法,TxtGAN有效改善了生成图像的质量. 但在实验中可以观察到,TxtGAN还存在不足之处,例如在人脸等细节方面和交通工具类物体的完整性方面生成能力依然较弱,未来将对如何在生成高分辨率图像的情况下保持图像细节进行下一步的研究.
