Trans_isA:一种基于实体属性和语义层次的表示学习方法*
2022-04-20李天宇王艳娜周子力赵晓函
李天宇, 王艳娜, 周子力, 赵晓函
(曲阜师范大学网络空间安全学院,273165,山东省曲阜市)
0 引 言
知识图谱本质上是一个大规模的语义网络,旨在通过实体间的关系描述客观世界中的事实,其中将实体(如人名、地名、机构名、概念等)表示为网络中的节点,将相邻实体间关系表示为网络中的连边[1]. 因此,大多数的知识图谱都是以(h,r,t)这种三元组的形式存储和表示数据,不同的三元组描述不同的客观事实. 表示学习是指将知识图谱中的中文词语或英文单词以及用来链接词语或单词的关系在统一的向量空间中进行表示,使知识图谱由离散的符号化表示转变为连续的向量,便于后续任务的完成.
近年来,研究学者提出了很多关于面向知识图谱的表示学习算法. 本文主要针对翻译模型展开研究,这类模型简单且高效,如TransE[2]、TransH[3]、TransR/CTransR[4]、TransM[5]、TransG[6]等. 这些模型从向量空间、模型复杂度、复杂关系等几个角度对之前的模型优化,但它们在学习过程中仍是将三元组作为独立个体进行向量表示,忽略了实体本身就是一个具有综合属性的个体. 此外,独立学习三元组及进行向量表示破坏了知识图谱中原有的语义层次结构,不利于后续的推理工作. 如图1中三元组(Hedge,isA,Fence)和(Fence,isA,Barrier),在进行知识推理时如果将这两个三元组看作独立的个体,则不会产生新的三元组,构不成足够多的推理路径. 实际上依据二元关系的传递性可以从图1这两个三元组中得到一个新的三元组,即(Hedge,isA,Barrier). 因此,如果在对知识图谱进行表示学习时保留了其中原有的语义层次结构,那么就会由此产生新的、正确的知识,最终提高知识图谱推理的质量. 针对这个问题,本文提出了基于实体属性和语义层次的表示学习模型——Trans_isA.
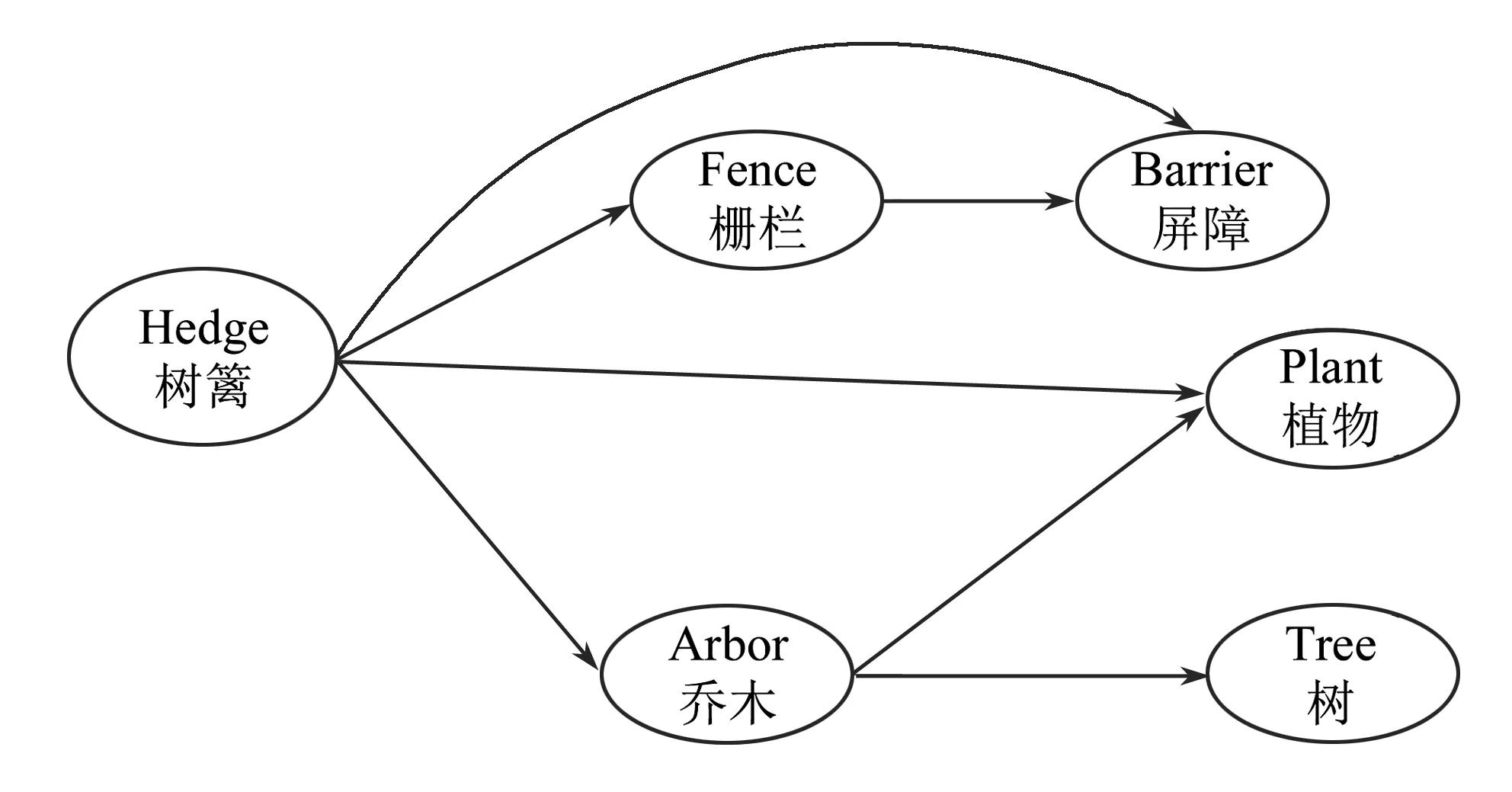
图1 一个关于知识图谱推理的示例
1 相关工作
目前的研究可以分为两类:一类是基于翻译的表示学习方法,另一类是其他的表示学习方法.

TransH[3]用于解决TransE在对具有自反性、1-N、N-1、N-N这些关系建模时存在的一些问题. 它的基本思想为:对于一个三元组(h,r,t),首先将头实体h和尾实体t投影到以wr为法向量的超平面dr上,表示为h⊥和t⊥,然后通过dr连接起来. 因此,TransH的得分函数为
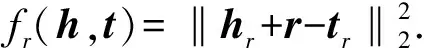

2 Trans_isA模型
2.1 问题描述
TransC[12]、JECI++[13]等方法通过区分实体中的概念和实例来改进现有的基于翻译的表示学习方法,但它们在进行表示学习时仍忽略了实体的属性信息,主要体现在PartOf关系中. 通过对PartOf关系三元组中头实体及尾实体的分析,可知同一关系链接的2个实体可能具有不同的语义类型,并且头实体与尾实体中含有的语义类型数量存在差异. 现有的大多数模型忽视了这种差异,将同一关系中的头尾实体不加区分地表示为相同空间的特征向量,这样则会导致有些实体的语义信息表示较少,从而降低语义表示的准确性.
此外,许多现有的表示学习方法无法在知识图谱中对语义层次进行建模,而语义层次结构是知识图谱中普遍存在的属性[14]. 语义层次结构中最重要的关系就是层级关系,它主要描述的是知识图谱中两个不同实体间的隶属关系. 图2描述了知识图谱中一个关于语义层次的示例. 其中,图2(a)展示了现有模型的表示学习形式,三元组在TransE或者TransH中训练时是独立且统一的,忽略了实体自身含义的表示范畴以及isA关系的传递性. 图2(b)则展示了Trans_isA模型的训练形式,在训练过程中将头、尾实体的范畴大小作为训练依据,即分别训练上位实体和下位实体,并且保留头、尾实体间isA关系的传递性.
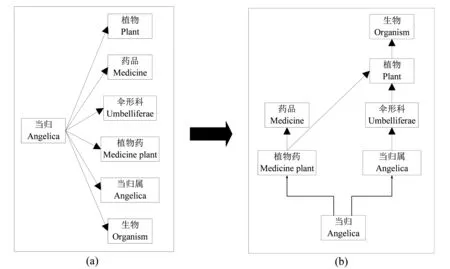
图2 一个关于语义层次的示例
针对以上分析的问题,将实体属性和语义层次进行融合,进而提出一个新的模型——Trans_isA. 该模型既可以保留TransE简单高效这一特点,又可以通过学习层级关系保留实体间的语义层次.
这里给出一些常用的符号表示:知识图谱由实体集合、关系集合以及三元组集合构成,用符号表示为:KG={E,R,S}.其中E=H∪P∪C、R=RH∪RP∪RC、S=SH∪SP∪SC,H表示具有语义层次关系的实体,P表示具有整体、部分属性的实体,C表示其它实体;RH表示isA关系,RP表示PartOf关系,RC表示其它关系;SH表示isA关系三元组,SP表示PartOf关系三元组,SC表示其他关系三元组.
Trans_isA模型对于给定知识图谱KG,进行如下表示学习:e→e∈RK,∀e∈E,同时r→r∈RK,∀r∈R. 对于每个e∈E,建模为球体Q1(ε,μ)、Q2(p,σ),其中ε,p∈RK表示球心,μ,σ为半径.
2.2 模型设计
图3中展示了模型的整体架构.
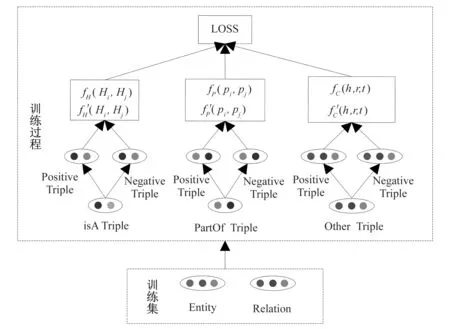
图3 Trans_isA模型架构图
isA关系类:对于任意给定的实体对(x,y),如果y的语义范畴比x的语义范畴更广,就称y是x的上位词,x是y的下位词,称这个实体对(x,y)为isA关系元组. 传递性关系的定义为:令R是A上的二元关系,对于A中任意的x,y,z,若〈x,y〉∈R,且〈y,z〉∈R,则〈x,z〉∈R,则称R具有传递性. 根据isA关系这一特性,设计了新的得分函数. 对于每个实体εi∈H,学习一个球体Q(ε,μ),ε∈RK表示球心,μ表示半径. 则isA关系的传递性为
(3)虚拟水战略对社会环境的影响。通过实行虚拟水战略,增加棉花进口相当于减少人工数33. 25万人、41. 56万人,但是不一定会带来失业问题。同时对于农户增收来说是一个不错的机遇。
(ε1,rh,ε2)∈SH∧(ε2,rh,ε3)∈SH→(ε1,rh,ε3)∈SH.
PartOf关系类:对于任意给定的实体对(a,b),如果a的语义表示的是部分属性,b的语义表示的是整体属性,就称a是b的组成部分,b是由a组成的整体,称这个实体对(a,b)为PartOf关系元组. 图4展示了PartOf关系下两个实体对应的球体之间的相对位置关系,模型将头、尾实体分别编码为球体Si(pi,σi)和球体Sj(pj,σj),其中pi、pj表示球心,σi、σj表示半径.Si和Sj之间的相对位置关系表示PartOf关系,模型的目标就是图4(a)所示的球体相对位置关系.
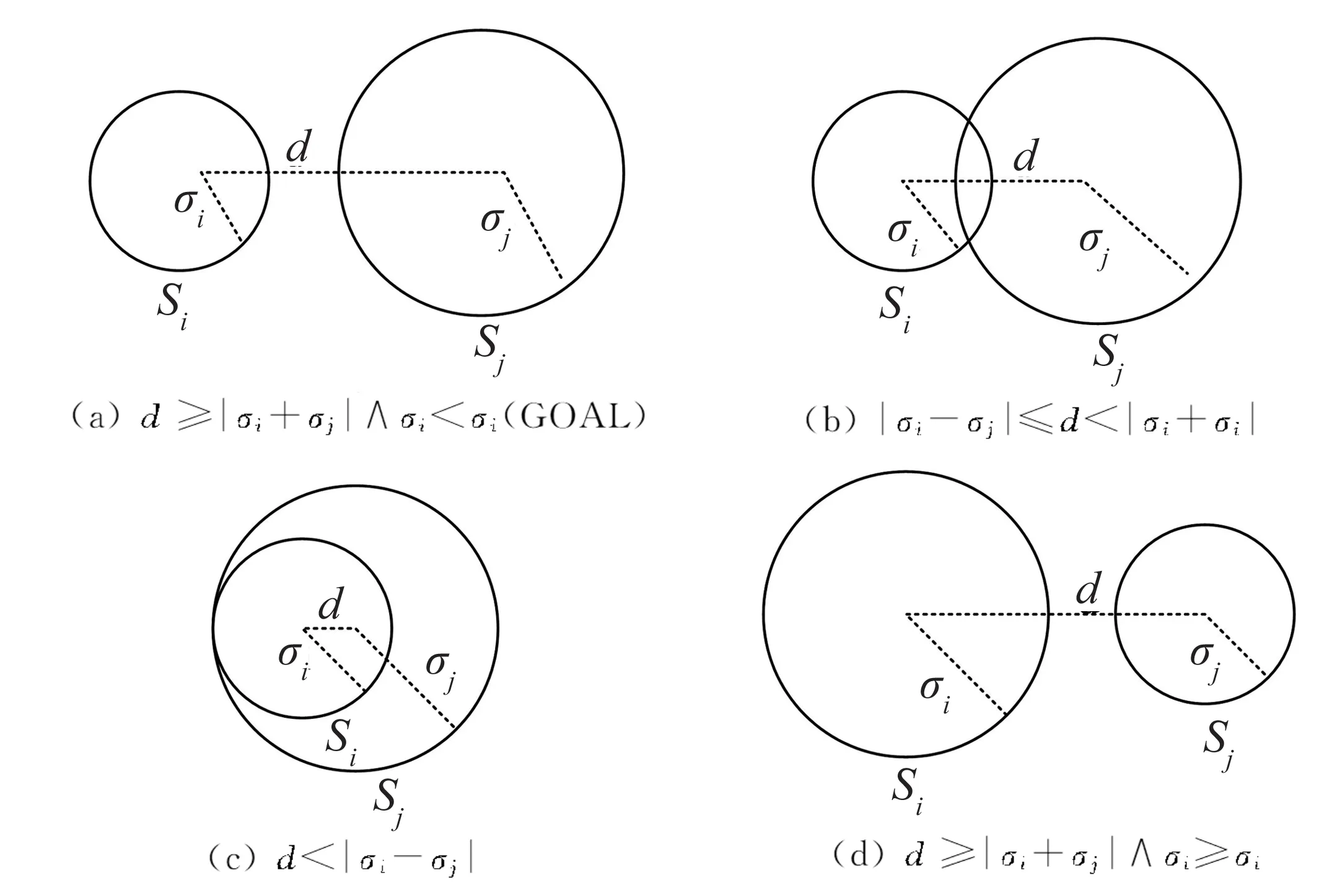
图4 PartOf 关系类相对位置关系示意图
根据不同关系类型的特征属性定义不同的得分函数对知识图谱KG中的实体(entity)和关系(relation)进行训练,具体如下:
isA关系类型的得分函数为
PartOf关系类型的得分函数为
其它关系类型的得分函数为
损失函数中的得分函数与上述3类关系类型相对应.
2.3 训练过程及目标

表1 Trans_isA算法

续表1 Trans_isA算法
基于翻译的表示学习模型通常是最小化基于边际的成对损失函数,所以Trans_isA模型也沿用此方法,具体定义为
(1)
Trans_isA的训练目标为:通过随机梯度下降方法,不断更新优化相关参数及向量,从而使式(1)中的LC、LH、LP均取得最小值.
在训练过程中,将同时获得正三元组和负三元组的得分函数值. 得分函数f表示的是三元组的语义相似性,即三元组为真的概率. 为了使训练目标最小化,首先要使正确三元组的得分函数值低于对应的错误三元组得分函数值,其次还要使两者之间的差值至少高于一个正常数,即边际参数γC、γH、γP. 通过随机替换正确三元组的头实体或尾实体对生成的错误三元组进行采样. 替换规则为
S′={(h′,r,t)|h′∈E,(h′,r,t)∉S}∪{(h,r,t′)|t′∈E,(h,r,t′)∉S}.
3 实验及结果分析
本节使用了最新提出的公开数据集WN18RR,分别在链接预测和三元组分类任务上进行了实验验证.
3.1 数据集
大多数先前的研究使用两个基准数据集WN18和FB15K评估表示学习模型的性能,这些数据集中的语义重复性、语义相关性或者数据不完整性,导致数据集中此类关系表现出很高的数据冗余性,这就使得数据集存在过度数据泄露的情况[15]. 因此Dettmers等人通过删除WN18中反向三元组创建了WN18RR. 本文中的链接预测任务以及三元组分类任务将在WN18RR这一基准数据集上进行,WN18RR数据集的基本统计信息如表2所示.

表2 WN18RR数据集
3.2 链接预测实验分析
链接预测任务是知识图谱表示学习的标准评估任务,其目的是预测三元组中缺失的头实体、尾实体或者关系. 根据现有的表示学习模型的评估标准,选用以下3个标准评估模型在链接预测任务上的性能:(1)MRR(正确实体的平均排序的倒数);(2)Hits@10(正确实体排在前10的百分比);(3)Hits@1(正确实体排名第一的百分比),这3个标准的值越大,模型的性能越好.
Trans_isA模型的实验参数设置为:从{0.1,0.3,0.6,1,2}中选择边际参数γH、γP、γC的值,从{20,50,100}中选择向量表示维度K的值,从{0.1,0.01,0.001}中选择梯度下降学习率λ的值. 根据验证集中链接预测的结果,得到了最优的参数配置:γH=0.1、γP=0.3、γC=2,K=100,λ=0.001,最大迭代次数为1000,同时采用L1范式.
表3展示了Trans_isA模型在WN18RR上的链接预测结果,可以看出:(1)表中所列模型的链接预测结果普遍较低,这是因为WN18RR数据集中去除了冗余数据,训练集中的数据重复率降低,使链接预测的结果更接近现实情况. (2)在Hits@1指标上,模型取得了最优结果,而在MRR和Hits@10这两个指标上,TransR和TransE分别取得了比较高的结果. 这是因为模型的重心放在了实体的层次结构以及实体属性表示中,在对其它关系类数据集训练时沿用了TransE的目标函数,使得本模型在处理复杂关系时没有表现出较为明显的性能提升.

表3 WN18RR数据集上链接预测结果
3.3 三元组分类实验分析
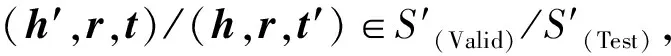
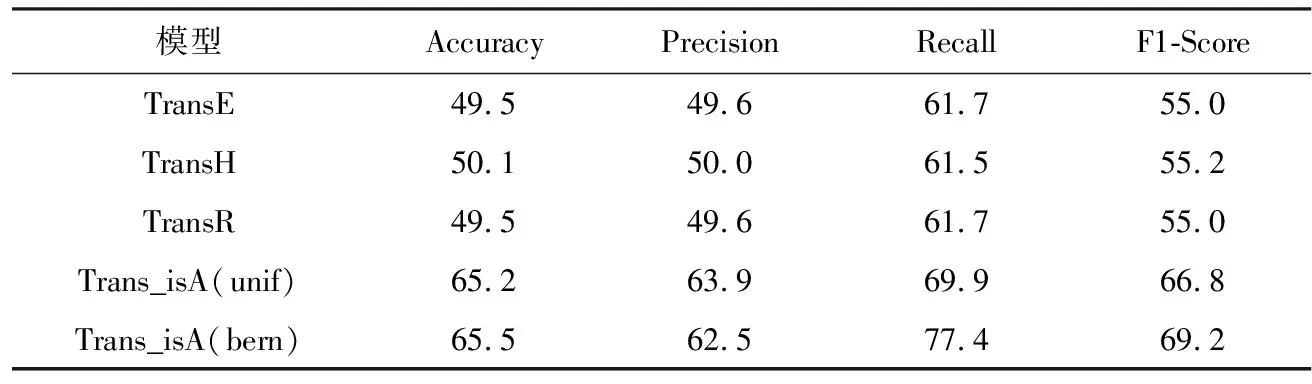
表4 WN18RR数据集上isA关系三元组的分类实验结果 单位:%
表4展示了Trans_isA模型在isA关系三元组分类任务中的结果,可以得出:Trans_isA的4个指标数值均达到了60% 以上,模型的召回率(Recall)达到了77.4%,高出其他3个基准模型10个百分点左右,这充分说明了Trans_isA模型训练之后的实体和关系向量带有明显的语义层次信息,符合模型的预期.
表5展示了Trans_isA模型在其它关系三元组分类任务中的结果,可得出如下结论:(1)在数据集WN18RR上,Trans_isA在Accuracy、Recall和F1-Score这3个指标上都高于TransE、TransH和TransR,这说明模型整体的三元组分类能力是比较强的. 但是在Precision这一指标上略低于TransR,这是因为Trans_isA模型在进行知识表示学习时虽然考虑了实体间的语义层次,但还是将实体和关系放在同一空间中学习,这样就导致部分实体属性单一,从而使得模型精确率(Precision)略低于TransR. (2)Trans_isA使用bern采样方法时,模型的准确率(Accuracy)高于使用unif采样方法时的准确率,这说明bern采样方法在本模型上的有效性.
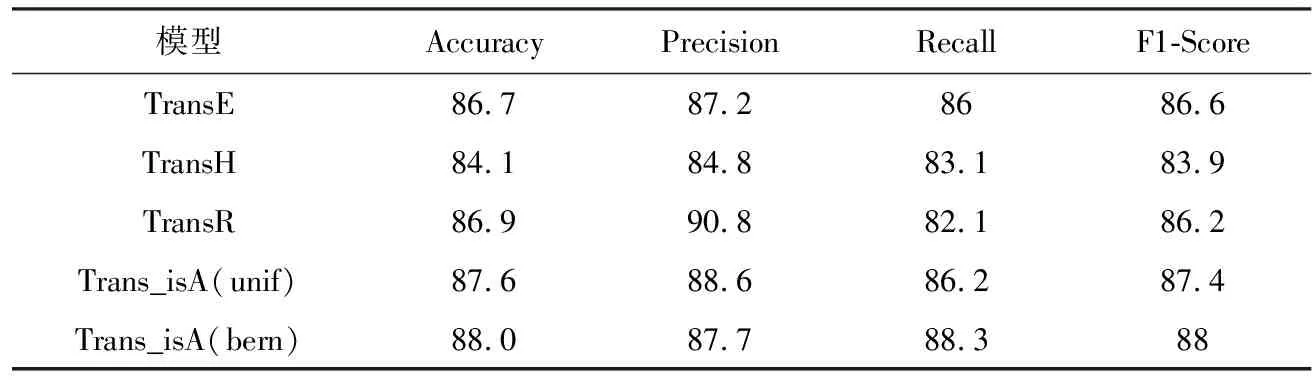
表5 WN18RR数据集上其他关系三元组的分类实验结果 单位:%
4 结束语
本文提出了一种基于实体属性和语义层次的表示学习算法,并将其命名为Trans_isA. 首先介绍了该方法的研究问题及思路,利用知识图谱中实体本身的属性特征和实体间的语义层次对其进行表示学习. 然后,详细的介绍了如何利用实体属性以及语义层次中的层级关系特性建模. 在对知识图谱中三元组建模时,充分考虑了头、尾实体的语义范畴,以及实体自身属性信息. 再根据不同类型的关系和不同属性的实体分别设计其得分函数. 最后,在链接预测和三元组分类这两个经典任务中验证了模型的有效性.
根据实体在不同的三元组中具有不同的表示,下一步考虑在不同的向量空间中对实体间关系建模,利用更加灵活的度量标准来设计损失函数,提高表示学习算法的性能.
