我国医药行业国企与民企间的风险传染分析*
——基于国企混改后的实证研究
2022-04-20闫海波
闫海波, 安 璐
(新疆财经大学统计与数据科学学院,830012,新疆维吾尔自治区乌鲁木齐市)
0 引 言
国有企业和民营企业是我国主要的两大企业类型,二者之间的风险溢出效应能直接反映我国经济发展的状况.现阶段,我国经济着重向高质量方向发展,经济发展速度有所减慢,出现投资增长额、政府财政收入、国有资本投入等不足现象[1].为改善这一现象,国务院颁布了混合所有制改革政策[2].混改的实施使得国企民企间的依赖关系更加紧密,相对的,发生风险传染的概率也随之增大.目前对金融市场相依性的研究多采用Copula模型、向量自回归VAR、Granger因果检验、DCC模型等[3].由于金融市场存在非线性,非正态等特性,上述传统分析相关性的方法并不适用,所以Copula函数才是研究金融市场间相依关系的主流方法.Bouye et al.(2000)将Copula理论应用在金融领域[4].考虑到单一Copula刻画金融市场相依结构的局限性,Hu L(2002)在金融市场相依结构的研究中,提出通过线性组合单一Copula构造新的混合Copula函数[5].随后大量学者用混合Copula模型来分析金融市场之间的相依性,张艾莲和靳雨佳将Gumbel和Clayton Copula函数混合考察股票外汇市场相依性[6].徐赐文等用混合Copula和Garch模型分析工业、商业和地产指数之间的相关结构[7].量化金融风险,清楚知道资产的得失概率,把不确定的金融风险转化为一个具体数值,是人们日前最关心的问题,VaR便是解决此问题最常用的办法.
本文利用Granger因果检验和混合Copula相结合方法描述我国医药行业混改前后的国企和民企间的相关性,并利用蒙特卡洛模拟计算不同置信水平下的风险值,为投资者提供有效规避风险的决策依据,为监管者管理风险提供理论支持.
1 模型介绍
1.1 Granger因果检验
20世纪60年代Granger C W J提出Granger因果检验,用来分析两变量之间在时间上的引导关系,常用于判断金融市场里的联动效应.
时间序列x=(x1,x2,…,xn),y=(y1,y2,…,yn),用x的过去值预测未来值,得到预测值xn+1,误差c;用x,y的过去值预测c未来值,得到预测值xn+2,误差d;若c>d说明x、y的联合预测误差小于x自身的预测误差,认为y对x的预测有帮助,y是x的格兰杰原因.
1.2 Copula模型
Copula函数是以Sklar定理为依据,用来描述变量间依赖关系的多元分布函数[8].
一个n元Copula函数C是定义在Id=[0,1]d上的边缘均匀分布函数,其中
C(u1,…,ud)=Pr (u1≤u1,…,ud≤ud).
由联合分布和其边缘分布函数间的联系有,对给定的边缘分布F1(x1),…,Fd(xd)和合适的Copula函数C有
C(F1(x1),…,Fd(xd))=F(x1,…,xd).
上述方程微分得到Copula函数的密度函数c
本文试图考察在混改发生前后我国医药行业股票市场国有企业和民营企业之间的关系,仅用二元Copula函数即可,最常用的二元Copula函数当属椭圆Copula和阿基米德Copula,其中Gauss Copula,T-Copula隶属于椭圆Copula函数,其密度函数是对称的,无法捕捉到非对称相依结构金融市场的特征;Gumbel Copula,Cayton Copula和Frank Copula是最常用的阿基米德Copula函数,其中Gumbel和Clayton Copula密度分布分别是“J”形和“L”形,均非对称,用来描述上,下尾相依系数;Frank Copula的密度函数有对称性,用来描述随机变量间对称的相依关系[9].
1.3 混合Copula
不同Copula函数有不同的特点,在描述相关结构的利弊也各有特点.混合Copula函数就是将单一的Copula函数根据一定的权重线性组合从而形成一个更灵活的Copula函数,并通过改变权重系数来刻画金融资产之间复杂的相依结构[10].
混合Copula函数的表达式
CM=wGCGu+wCCCl+wFCFr,
CCl(u,v,θ)表示Clayton Copula 函数,生成元φ(t)=t-θ-1,θ∈(0,∞),密度函数为
CGu(u,v,θ)表示Gumbel Copula 函数,生成元φ(t)=(-lnt)θ,θ∈(0,1],密度函数为
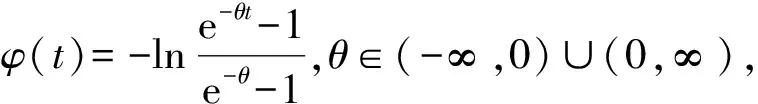
其中CM表示混合Copula,wG,wC,wF∈(0,1)是权重系数代表着两资产间的相依程度,wC值越大说明两资产间的下尾相依程度越高;wG越大,说明两资产间的上尾相依程度越高[11].
本文设国企、民企的股票收益率分别是X,Y,样本特征(如均值,标准差)用边际分布函数是F(X),F(Y)描述,相关关系用Copula连接函数,即C(F(X),F(Y))描述,国企、民企面临金融风险时的联合分布函数是F(x,y)=C(F(X),F(Y)).
1.4 蒙特卡洛方法计算VaR/CVaR
VaR定义市场正常波动下,在一定持有期,一定置信水平c下,金融资产所面临的最大可能损失.用数学公式表示,即
prob(Δp≤-VaR)=c,Δp=pt+Δt-pt,
其中pt是t时刻资产价值;Δp是未来持有期Δt内的损失;c是置信水平;因为VaR不满足次可加性,不考虑超过在险价值的损失,所以存在低估风险的可能,风险越大,低估程度就越明显,于是Artzner学者就提出了一致性风险度量CVaR概念,完美避开了VaR的缺点[12].
CVaR定义市场正常波动下,在一定持有期,一定置信水平β=100(1-c)下,损失超过在险价值VaR的条件均值.用数学公式表示,即
CVaR=-E{Δp|Δp≤-VaR}.
为能准确量化现实生活中的金融风险,方便投资者更好的规避风险,本文基于Copula模型视角利用蒙特卡洛方法来度量VaR和CVaR,计算步骤如下[13]:
(1)生成两个服从[0,1]均匀分布的随机数u,v构造二元随机序列(x,y);
(6)用模拟产生的随机数计算不同置信度下的VaR和CVaR.
2 实证分析
2.1 数据选取与统计描述
我国医药行业大致可以分为化学药、中药、生物药和医药商业四大类,其中恒瑞医药在我国化学制药上占据绝对的龙头地位;爱尔眼科在我国眼科上有很大的成就,在医疗商业中有一席之地;哈药集团是大型综合性制药企业,位列全国医药“百强”企业之首;国药集团制药板块综合全面,包括中药、化药、生物药、医疗器械等各板块.因此将哈药股份和国药股份两只国企股票为我国医药行业混改国企的代表,以爱尔眼科和恒瑞医药这两只民企股票为我国医药行业民企代表.
文章以4只医药行业股票的日收盘价为样本数据,样本区间选用2010年1月4日到2020年12月31日,共计2495个样本数据,根据国有企业混改时间将2016年3月以前的样本数据定义为混改前,2016年3月之后的为混改后.为保证样本数据量一致,将时间不一致的收盘价做删除处理,数据来源于同花顺.对数据的统计性描述见表1.
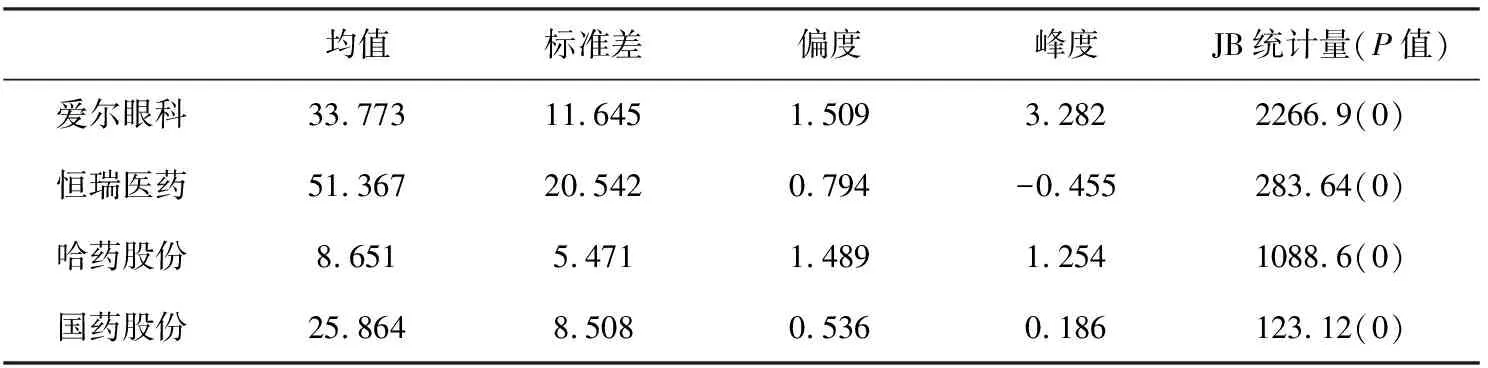
表1 收盘价的统计性描述
表1中,民企标准差的数值相较于国企都较大,符合国企发展更稳健的实际,各股票收盘价的偏度值均大于0,有右偏趋势;收盘价序列峰度值都不等于3,不服从正态分布;JB统计的检验结果再次表明,序列在5%显著性水平下,不服从正态分布,所以传统的皮尔逊相关系数法在这里不适用;从均值可知民营企业的收益要远好于国有企业,所以私有资本注入国有企业,带动国有企业发展就很有必要.
分析我国医药行业国企在混改前后与民企间的风险特征时为避免受政策影响,将四组收盘价序列分为两类,其中两只国企股票日收盘价取均值统称为国企,两只民企股票日收盘价取均值称为民企.接着对两组序列进行对数化处理,rt=lnpt-lnpt-1,其中pt-1为第t-1天的股票指数收盘价,pt为第t天股票指数收盘价.国企、民企的对数收益率取均值的时序图如下:
如图1所示,混改政策的实施,国企的股票价格立即出现剧烈波动,大波动之后紧跟着较大的波动,显示出明显的波动聚集性.民企股票价格也随之出现波动.总的来看国企民企之间的波动趋势具有一定程度的相似性,初步认为国企民企之间存在一定的相关性.
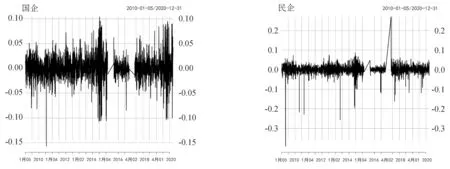
图1 国企、民企对数收益率时序图
2.2 风险传染方向的判别
本文拟用格兰杰因果关系检验来对国企、民企收益率序列之间的风险传染方向进行定性研究.金融领域大量的时间序列具有非平稳的特征,对非平稳时间序列进行建模时容易产生“伪回归”问题.所以本文用包含截距项的ADF单位根检验对4只股票收益率做平稳性检验.为避免ADF出现“纳伪”错误,再用PP检验对一阶差分后的4只股票收益率序列进行平稳性检验,均以AIC为滞后项检验标准,检验结果见表2.
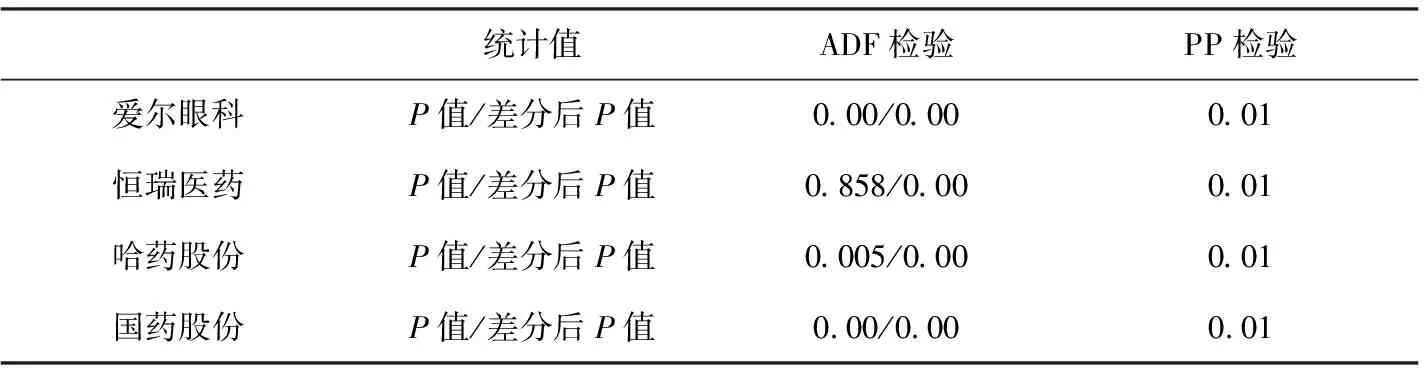
表2 平稳性检验
表2中,ADF检验结果知,除恒瑞医药指数序列外,其余3只股票指数序列均拒绝原假设,认为3只股票指数序列均不存在单位根,为平稳序列.为确保序列的平稳性对收益率序列都进行一阶差分处理后再作ADF检验,发现序列平稳.PP检验结果在1%显著性水平下拒绝原假设,再次证明序列是平稳的.接着对平稳序列用E-G两步法判断序列之间是否存在协整关系,结果显示,序列之间存在单向协整,有存在因果关系的可能,因果关系检验结果见表3.
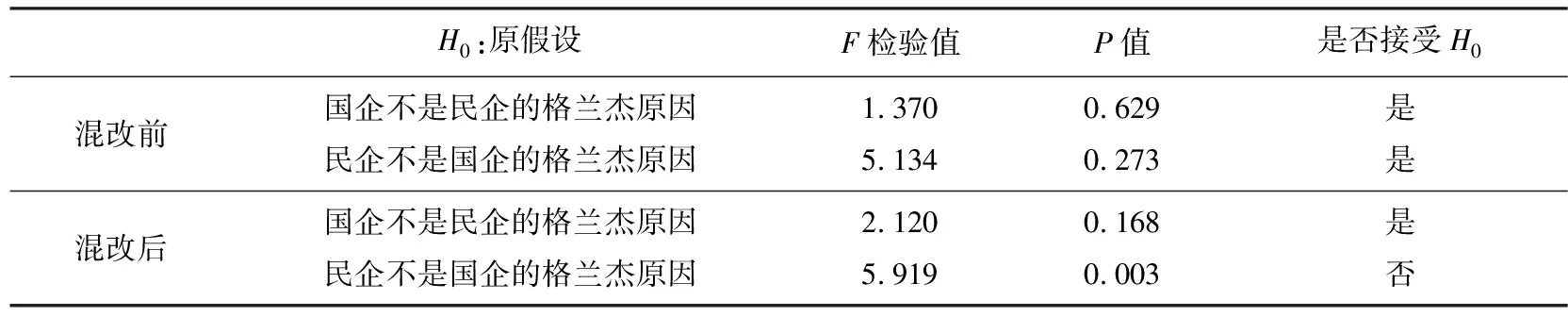
表3 格兰杰因果关系检验
由表3的检验结果可以知道,混改实施前后国企和民企的指数收益率之间的格兰杰因果关系发生了变化,混改之前民企和国企不存在格兰杰因果关系,混改以后,民企是国企的格兰杰原因,在5%显著性水平下,民企股价变动会引起国企股价的变动.
2.3 确定Copula模型
相较于传统的相关性建模,Copula方法在边缘分布的选择上没有任何特殊要求即其适用于任何给定的边际分布.选择一个合适的边缘分布模型又是构建合适Copula模型的重要前提.同时文献[13-15]表明相较于正态分布,t分布尾部厚,对变量尾部间变化较为敏感,可以较好捕捉收益率的尾部极端值.因此本文选用t分布作为边缘分布,接着用R软件来估计混合Copula模型的参数.图2可以看出t分布与收益率序列的拟合程度较好.
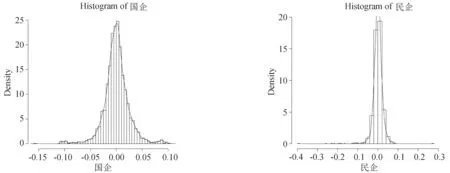
图2 国企、民企收益率序列t分布拟合
由于混改前后国企,民企遇到风险时的相依结构有所变化,所以它们之间的Copula函数也有所变动.本文以极大对数似然值,AIC值为依据,拟合得到表4中国企,民企之间的最优Copula函数.
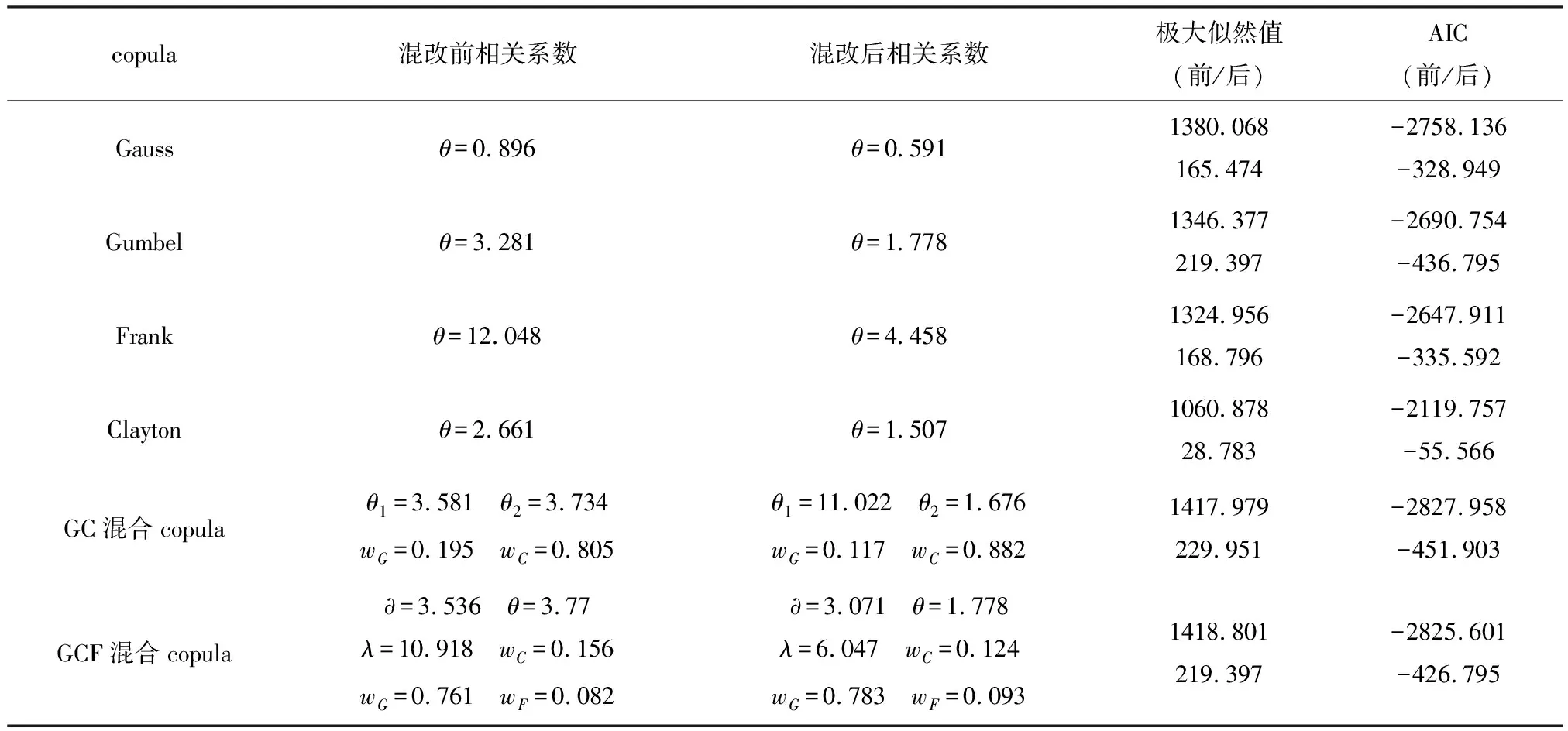
表4 Copula函数选择
由上述表4可知,以极大对数似然值,AIC值为判别标准可以发现,相较于单一Copula函数的拟合效果来说,由单一Copula按照一定权重线性组合构成的混合Copula函数拟合效果较好.通过观察GC混合Copula和GCF混合Copula函数的极大似然值,AIC值可知,这两个函数拟合效果差别不大,但由3个单一Copula构成的混合Copula函数存在待求参数多,计算复杂,容易出现模型误差大等问题,因此选定Clayton Copula、Gumbel Copula函数构成的GC混合Copula来刻画国企和民企间的相依结构,在避免失真的同时也为准确度量风险打下基础.
2.4 风险度量
为更好的对金融资产进行监管,本文在边缘t分布和混合Copula模型的基础上,遵照上述蒙特卡洛的模拟方法反复进行3000次实验,求得在混改前后在置信水平90%、95%、99%的VaR和CVaR值,如表5所示.
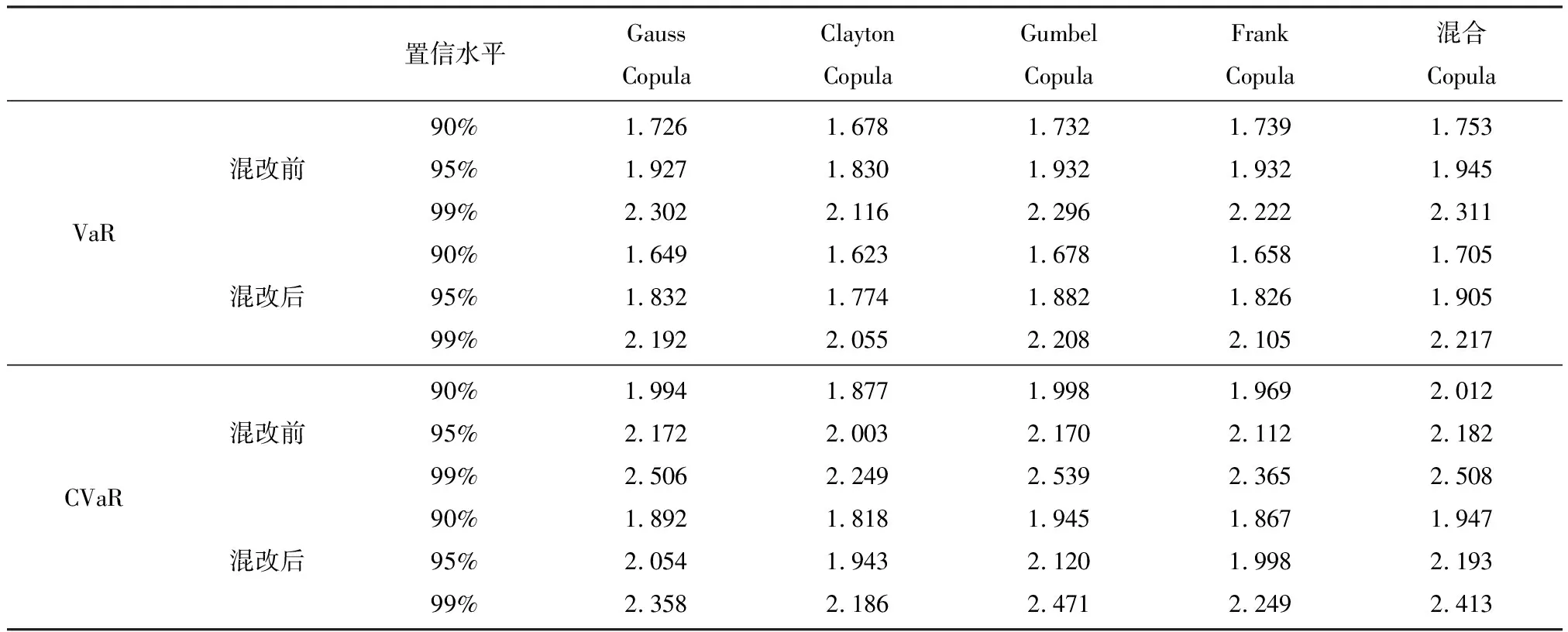
表5 不同置信度下风险值、条件风险值
对比表5同一置信水平下的VaR和CVaR值,可以发现,CVaR值总是比VaR值大,CVaR值估计了超出VaR值的损失,结果更为保守,为投资者很大程度上降低损失的可能.又通过观察表5发现,采用混合Copula模型估计的VaR和CVaR值是最大的,印证了用混合Copula刻画的国企和民企间的相依结构是最优的,单一Copula模型只能反映国企和民企间相关性的某一侧面,在一定程度上低估了风险,用混合Copula模型能给投资者提供更为稳健和可靠的决策依据.相较于混改以前,在同一置信水平下,混改政策执行后的VaR和CVaR值都有所减小,从金融风险角度显示出混改能改善企业的经营状况,激发企业的活力,提升企业的抗风险能力.另外,随着置信水平的提高,VaR和CVaR值都有所增加.
3 总 结
本文基于混合Copula函数刻画企业间的相依关系 ,利用蒙特卡洛方法度量不同置信水平下的风险值,对我国医药行业国企混改前后和民企间的风险特征进行分析研究,混改前后国企和民企之间的格兰杰因果关系发生了改变,混改后的国企与民企之间关系更加紧密,联动性增强,在国资民资优势的双重加持下,面临的风险也有所降低.随着我国经济步入新常态时期,混改也进入到关键时期,多数国企都进行了混改,通过引进非公有制资本,来降低自身杠杆,提升经营效率,最终达到防范化解金融风险的目的.因此在确认企业间相依关系的基础上度量风险值就是防范金融风险的第一步也是核心一步,对捍卫国家金融安全也有重大意义.
