模拟“what”通路前端视觉机制的边缘检测网络
2022-04-12潘盛辉王蕤兴林川
潘盛辉 王蕤兴 林川





摘 要: 边缘检测是图像处理工作的关键步骤之一,目前边缘检测模型基于卷积神经网络(CNNs)搭建编码-解码网络。由于现有编码网络提取特征能力有限,且忽视了神经元之间复杂的信息流向,本文模拟视网膜、外侧膝状体(LGN)和腹侧通路(“what”通路)前端V1区、V2区、V4区的生物视觉机制,搭建全新的编码网络和解码网络。编码网络模拟视网膜-LGN-V1-V2的信息传递机制,充分提取图像中的特征信息;解码网络模拟V4区的信息整合功能,设计邻近融合网络以整合编码网络的特征预测,实现特征的充分融合。该神经网络模型在BSDS500数据集和NYUD-V2数据集上进行了实验。结果表明,本文搭建的编码-解码方法的F值(ODS)为0.820,相比于LRCNet提高了0.49%。
关键词:边缘检测;生物视觉;编码-解码网络;特征提取;卷积神经网络(CNNs)
中图分类号:TP317.4;TP391.41 DOI:10.16375/j.cnki.cn45-1395/t.2022.02.009
0 引言
边缘检测作为轮廓检测的基础工作,旨在标记数字图像中目标与背景的交界[1-2],其作为图像处理与计算机视觉的关键步骤之一,用于图像分类[3]、目标检测[4-5]、语义分割[6-7]等诸多领域。
近年来,卷积神经网络(CNNs)在边缘检测任务中取得了很好的效果。以经过裁剪后的VGGNet、ResNet等学习架构作为网络的编码结构,通过构造不同的解码结构对编码结构中不同卷积层的输出特征进行整合,获得最终的边缘输出[8]。以VGG16为编码网络构造的边缘检测模型都取得了很好的成绩。如Xie等[9]提出了一种端到端的整体嵌套的轮廓检测算法(HED),通过上采样的方法融合VGGNet[10]五大层的侧边输出,证明了深度学习模型在边缘检测的高效性。为了增加信息的利用率,Liu等[11]在HED 的基础上提出了RCF网络,该算法将VGG16的13 层的侧面输出融合,在不增加计算成本的基础上,减少了信息丢失,得到了优于HED的效果。但是,侧面输出图直接上采样会导致图片纹理大量增加,且轮廓粗糙,缺少细节信息。因此,Xu等[12]引入了一个分层深度模型(AMH-Net),它产生了更丰富和互补的纹理。此外,为了更好地融合从不同尺度上得到的特征图像,提出了一种新的注意门控条件随机场(AG-CRFs)。Wang等[13]提出了一种CED网络,该网络使用逐层组合的方式融合VGG16的每一阶段输出,使用亚像素卷积的方法进行上采样。可见,信息逐层连接可大大提高轮廓的精度,得到清晰的边缘。Lin等[14]提出了一种新型的水平细化网络(LRCNet),通过融合不同级别的细化模块来获得越来越有效的轮廓信息,提高了图像间的预测性能。Cao等[15]提出一种深度精化网络(DRNet),通过堆叠多个精化模块,设计一种邻近结合方式。从视觉神经机制来看,视觉系统的分析过程表现为分层化、复杂化,而特征信息的提取则逐渐细节化。视觉任务中的CNNs 通过分层次特征学习实现特征提取和整合,完整地模拟了整体视觉的功能。因此,将生物视觉神经机制与深度学习相结合,模拟视觉皮层对信息的提取,并将所得信息有效结合,可取得更加优化的效果。
本文从生物视觉出发,模拟来自视网膜的视觉信号,经丘脑外侧膝状体处理后,参与与物体识别相关的“what”视觉通路,这一过程在目标识别中起着关键作用[16]。本文模拟了 “what”通路中视网膜-LGN-V1-V2-V4的处理过程,搭建编码-解码网络,构建基于仿生的深度学习模型;在BSDS500数据集和NYUD-V2数据集上对本文模型进行定性和定量测评,并与其他CNNs模型进行对比。结果表明,本文模型优于其他模型,有较好的检测效果。
1 模型搭建
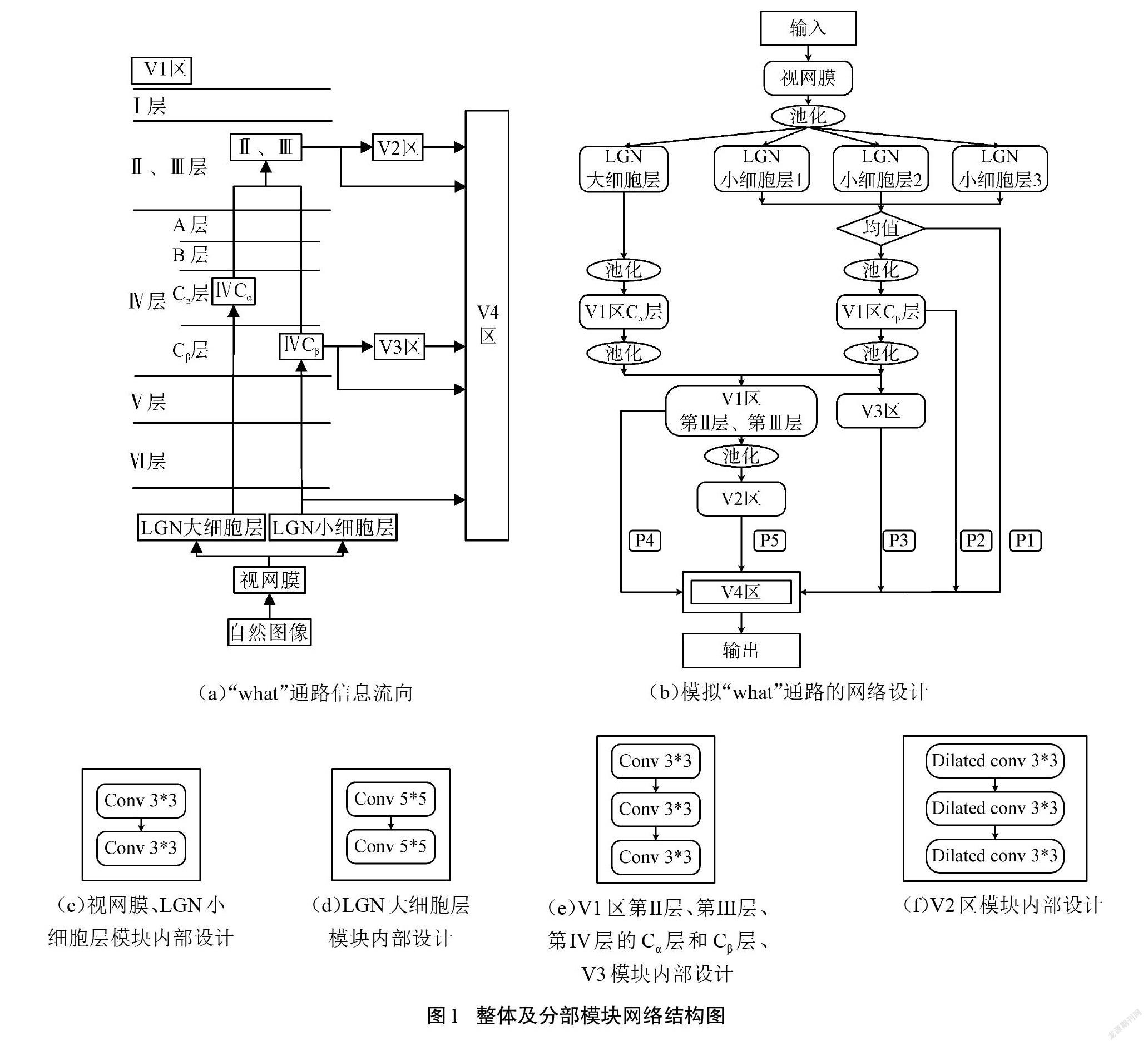
生物视觉系统按照特定的规则处理图像信息。功能性磁共振成像(fMRI)[17]研究表明,外膝体(LGN)在处理视网膜传递的图像信息之后分为腹侧(“what” 通路) 和背侧 (“where”通路)2条视觉通路进行分流处理。“what”通路参与物体识别,起始于初级视皮层V1区,依次通过V2区和V4区,进入高级视皮层(IT区)[18]。本文模拟“what”通路前端视觉处理机制搭建编码-解码网络,即:视网膜-LGN-V1-V2-V4。
图1(a)为“what”通路信息流向,在“what”通路中,视网膜接收图像进行简单的信息提取后向LGN传递,LGN根据细胞感受野大小分为大细胞层和小细胞层。大细胞层对运动、方向、速度等信息敏感,而小细胞层对物体的形状、颜色等信息敏感。大、小细胞层接收视网膜提取的信息后分别向视觉机制中初级视皮层(V1区)的不同层分流传递。其中,V1区共分为6层,分别标记为Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ、Ⅵ,信息流通方向为Ⅵ→Ⅴ→Ⅳ→Ⅲ→Ⅱ→Ⅰ。Ⅳ层内部又细分为A、B、Cα、Cβ等4个小层,信息流通方向为Cβ→Cα→B→A,每层处理任务各不相同。LGN大細胞层神经元将信息传递至V1区Ⅳ层的Cα层,再传递到V1区的第Ⅱ层、第Ⅲ层;小细胞层神经元将信息传递到V1区的Ⅳ层的Cβ层,再传递到V1区的第Ⅱ层、第Ⅲ层和V2区。在第Ⅱ层、第Ⅲ层时对图像的颜色及形状等信息进行重点提取。之后,经过第Ⅱ层、第Ⅲ层处理的视觉信号离开V1区,到达V2区。V3区接收V1区第Ⅳ层中Cβ层的信息,由于V3区主要对视野中的运动特征进行提取,故在腹侧流中仅起到增强轮廓的作用。视觉联络区(V2区、V3区、V4区)不局限于某种功能,而是对各信息进行加工整合。V2区注重对形状、颜色、立体视觉等信息的处理,起到调制复杂信息的作用。V4区和V1区相似,提取形状、颜色等信息,用来接收来自V1区、V2区、V3区及部分LGN的前馈信息,拥有强大的注意力调节功能,可分离出更加复杂精确的轮廓。本文根据上述视觉机制搭建网络,整体结构如图1(b)所示。
编码网络分别模拟了视网膜、LGN、V1区、V2区的视觉传递机制。为了模拟视网膜提取初级特征的能力,设计了由2个连续的3*3卷积核组成的模块,对输入图像的轮廓特征进行提取,如图1(c)所示。将所提取的特征经过最大值池化后传递至模拟LGN的模块中。视神经学中根据LGN细胞感受野大小分为大细胞层和小细胞层,基于这一特性本文设计了大细胞层和小细胞层2个通道。对于大细胞层而言,其细胞感受野相对较大且数量较少,因此,使用一组卷积操作来模拟大细胞层的特征获取能力。它由连续2个5*5卷积核组成,所得特征作为LGN大细胞层的侧面输出,如图1(d)所示。对于小细胞层而言,其细胞感受野较小且数量较多,因此,设计了3组平行卷积操作,每一组都由2个3*3卷积核组成,如图1(c)所示,将3组处理后的特征信息求取算数平均值并作为LGN小细胞层的侧面输出。 LGN接收视网膜的信息后向V1区传递,而V1区内部Ⅳ层中Cα 、Cβ 2个小层分别接收来自LGN的信息。其中,V1区Ⅳ层中的Cα层接收LGN大细胞层神经元投射的信息,V1区Ⅳ层中的Cβ层接收LGN小细胞层神经元投射的信息。从V1区Cα 、Cβ层输出的信息经过池化相加后,向模拟V1区中第Ⅱ层和第Ⅲ层的模块传递,经其处理后的轮廓信息分别向V2区和V4区传递。此外, 经fMRI研究发现,V1区Cβ层经V3区的处理后再向V4区传递,V4区对所有接收到的特征信息进行统一处理。其中,V1区第Ⅳ层的Cα层和Cβ层、V1区第Ⅱ层和第Ⅲ层和V3模块的模型结构均采用3个连续的3*3卷积操作来模拟,如图1(e)所示。对于V2区的功能,选择3个连续的空洞卷积来模拟,空洞率设置为1,有效地加强了网络的泛化能力,提取到了更加清晰的特征信息,如图1(f)所示。
解码网络模拟“what”通路中V4区的功能及作用。在V4区之前,通路中各部分已基本完成了视觉机制中简单的轮廓提取任务,且V4区位于整个腹侧流的中高层,是视觉处理机制的中继站,也是多种信息的汇聚点[16]。本文解码网络模拟V4区的功能作用,接收并融合来自LGN、V1、V2等机制处理所得的丰富信息,合成最终轮廓。模拟V4区网络结构如图2(a)所示。选取编码网络中的5幅侧面输出图进行解码,即:LGN小细胞层、V1区的Cβ层、V3区、V1区的第Ⅱ层和第Ⅲ层、V2区的侧面输出信息,标注为如图2(a)所示的P1、P2、P3、P4、P5。
将P1、P2、P3、P4、P5这5幅侧面输出图视为“what”通路前期提取的特征信息。使用一种邻近结合的方式将高分辨率与相邻的低分辨率通过精炼模块R两两结合,如图2(a)所示。其中,精炼模块R包含2个输入和1个输出,每个输入通过1个大小为3*3的卷积核来改变图片通道,使输出特征图与2个输入特征图中通道数少的一方相同。设置Relu激活函数与BN层加快训练速度,随后与经过sigmoid函数归一化的权重系数相乘,解决输出边缘在不同分辨率下的特征比率不平衡的问题。将低分辨率特征信息经双线性上采样操作至與高分辨率特征相同并相加,如图2(b)所示。由于P3与P4的图片分辨率相同,在此处省略精炼模块R中上采样的处理过程,将两者权重卷积过后的结果直接相加,输出至下一阶段。解码网络的最后1个精炼模块通过1个1*1的卷积核处理后得到的预测结果为最终边缘检测结果。
2 实验结果与分析
2.1 网络设置
本文将非极大值抑制处理方法应用于所有的输出结果。使用BSDS500数据集[19] 及NYUD-V2数据集[20]对所提出的检测方法进行定性和定量的实验验证,并与其他深度学习的神经网络进行对比。
为了改善边缘质量,创建了图像金字塔[21]以检测多尺度轮廓。单尺度检测器是以图像原始大小进行采样。多尺度模型首先将放大或缩小的图像输入单尺度检测器中,再用双线性邻近插值将所得边缘图调整为原始图像尺寸,最后通过求取每个像素点的平均值作为最终的预测图。本文使用0.5倍图像、1倍图像、2倍图像进行融合。
使用精确-回归(precision-recall,P-R)曲线和调和平均数[F]值来评判轮廓检测模型的性能。[F]值的定义如下:
[F=2PR/(P+R)], (1)
其中:[P]和[R]分别代表精确度和回归度,[P=NTP/(NTP+NFP)],[R=NTP/(NTP+NFN)];[NTP]、[NFP]和[NFN]分别代表轮廓像素的正确个数、错误检测个数和漏检测个数。
轮廓检测模型一般使用以下3个指标来评价性能:1)固定阈值下整个数据集得到一个最优[F]值,被称作最优的数据集尺度(ODS);2)每一幅图像在一个固定阈值得到一个最优[F]值,被称作最优的图像尺度(OIS);3)数据集的平均精度(AP)。
2.2 整体结构对比分析
2.2.1 BSDS500
BSDS500数据集为BSDS300的扩展版,包含200幅测试图像和300幅训练图像,其中每幅图像都对应着5~10个由人工标注的真实轮廓。由于训练数据有限,将这300幅训练图像旋转、缩放和裁剪为24 880幅图像,从而扩展了BSDS500训练集。将BSDS500增强训练集与Pascal VOC训练集(即表1中的VOC)[22]混合作为训练数据。在评估过程中,采用标准非最大抑制(NMS)对检测到的边缘进行细化。将该算法与传统的边缘检测算法、机器学习、仿生学习及近几年的深度学习算法作比较,包括:Canny[23]、SCO[24]、Pb[25]、gPb[19]、DeepContour[26]、DeepEdge[27]、HED[28]、CED[13]、RCF[29]、DRNet[15]、LRCNet[14]。在本文中,SS 表示单尺度,MS 表示多尺度。
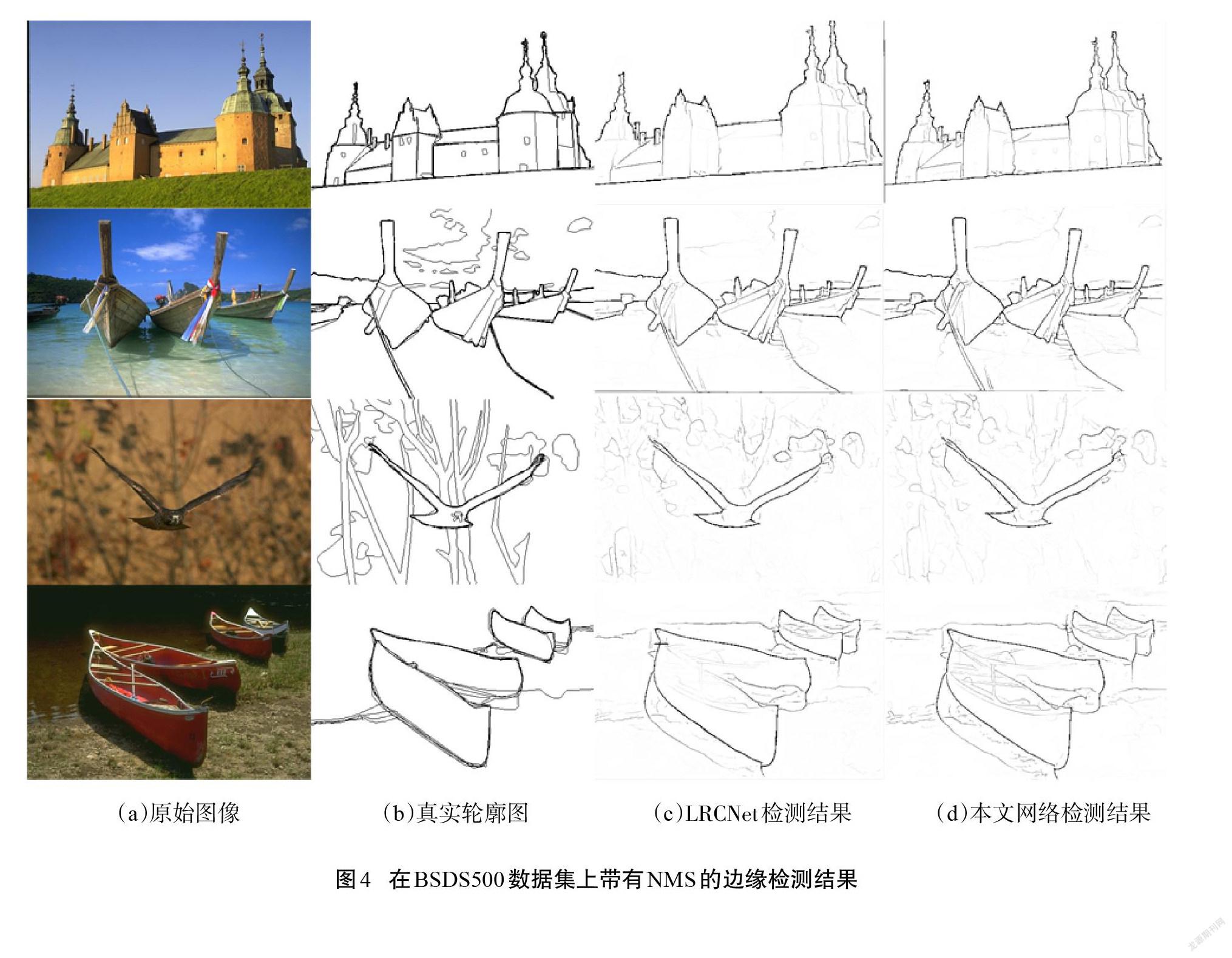
表1为BSDS500数据集上ODS、OIS和AP的定量评价结果,由表1可知,无论是单尺度还是多尺度,本文方法均优于所列文献中的方法。本文模型的ODS为0.820,OIS为0.840,AP为0.852,其网络结果在BSDS500数据集上超过了人类基准(ODS=0.803),相较于其他仿生学及深度学习网络都有较好的检测结果;单尺度和多尺度ODS值相比于LRCNet[14]在BSDS500和VOC混合数据集中分别提高了0.12%和0.49%。本文为了加快计算速度,缩减了网络内存,只对最终输出结果求损失函数与真实轮廓图进行对比,因而AP值并没有优于其他所有网络。图3为算法的P-R曲线,图4展示了一些模型在BSDS500测试集上的定性结果。由图4可以看出,本文模型在预测出更多边缘细节的同时,含有更少的背景纹理。
2.2.2 NYUD-V2
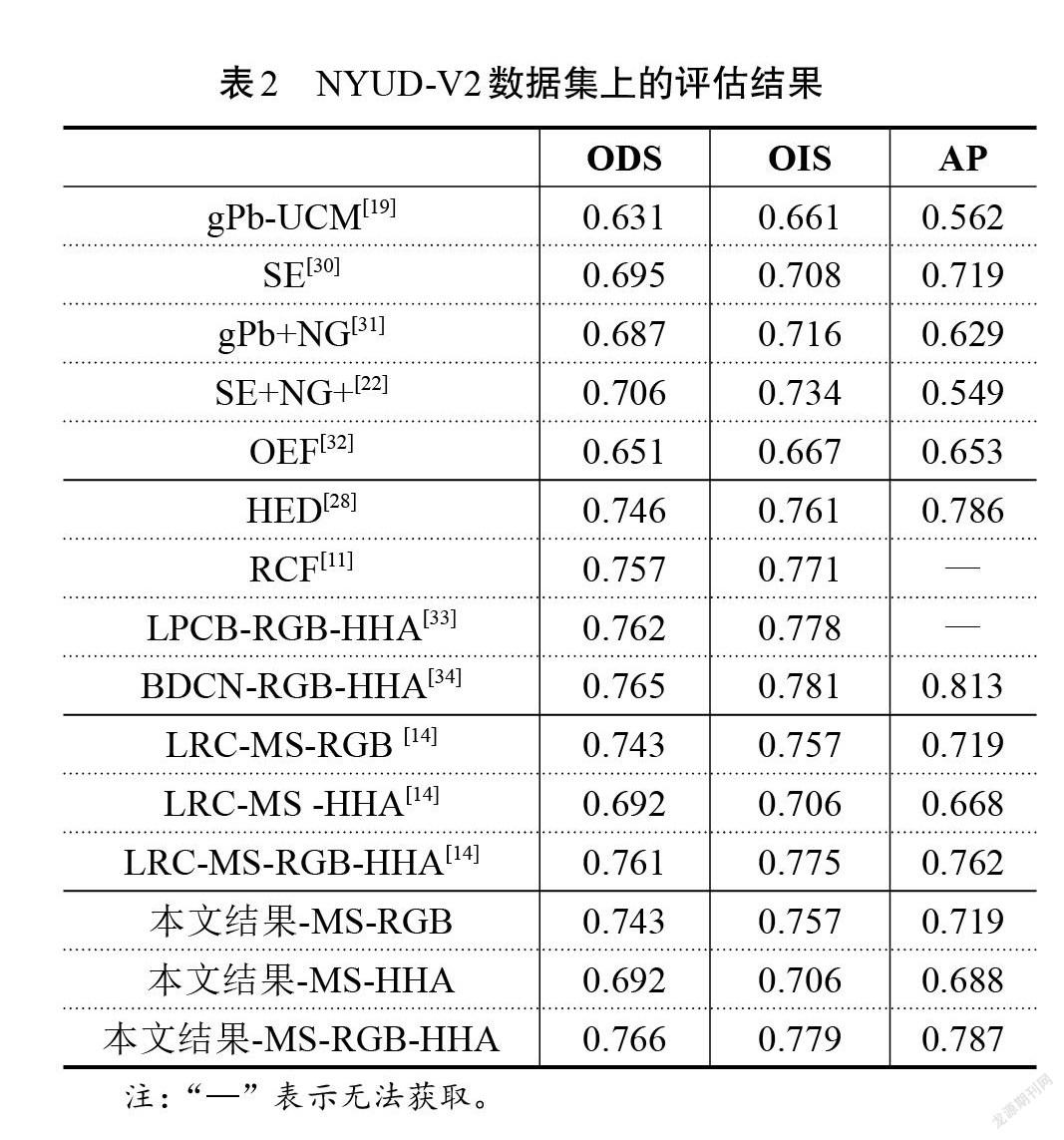
该数据集一共由1 449幅自然图像组成(381幅训练图像,414幅验证图像和654幅测试图像),每幅图像都对应着由人工标注的真实轮廓,由654幅测试图像得到NYUD-V2的定量实验。该数据集共分为2种类型图片:HHA与RGB图像。本文在检测这2种图片的基础上将两者结合,对HHA-RGB进行测试,并将提出的模型与机器学习及其他深度学习的网络进行了比较,包括gPb-UCM[19]、SE[30]、gPb+NG[31]、OEF[32]、HED[28]、RCF[11]、LPCB[33]、LRC[14]、BDCN[34]。表2为NYUD-V2数据集上ODS、OIS和AP的定量评价结果,图5为算法在NYUD-V2测试集上的P-R曲线,图6展示了一些模型在测试集上的定性结果。
由表2、图5可知,本文网络用于HHA图像的ODS达到了0.689,用于RGB图像的ODS达到了0.743,RGB和HHA平均融合结果的ODS为0.766,OIS为0.779,AP为0.787。以LRCNet为例,本文网络在RGB上的ODS值可与其持平,在HHA上的结果却相差甚远,但RGB和HHA平均融合结果优于LRCNet的结果。说明本文网络虽可过滤大量的纹理背景,且突出了轮廓特征,但提升效果并不明显。其主要原因分析图6可知,RGB和HHA的融合结果中包含了来自HHA预测图的绝大部分边缘和背景纹理,影响了最终的检测结果。
由图6可以看出,本文模型的预测结果过滤了大量的背景纹理,边缘更加清晰。
3 结论
提取清晰的底层特征是边缘检测的难点之一。近几年的边缘检测模型通常以VGG16为编码网络并在此基础上搭建解码网络,忽略了神经元之间复杂的信息流向,且编码网络的侧面输出图边缘粗糙、携带大量的纹理与噪声。本文从生物视觉出发,摒弃了经典VGG16结构,模拟视觉神经机制中“what”通路的信息传递方向,搭建全新的編码网络结构,并模拟V4区的特征整合功能设计解码网络。经过对比分析,所提出的编码网络适用于大部分解码网络,并可以表现出良好的成绩。整体模型结构在BSDS500数据集和NYUD-V2数据集上进行定性和定量实验,结果表明,与多个网络的检测效果相比,均表现出明显的优势。其中,本网络在BSDS500数据集上,获得了ODS为0.820的效果,相较于LRCNet提升了0.49%。本文提出的方法为后续轮廓检测研究提出了一个新的思路,为将生物视觉机制融入视觉任务中拓展了新的方向。
参考文献
[1] 林川,曹以隽.基于深度学习的轮廓检测算法:综述[J].广西科技大学学报,2019,30(2): 1-12.
[2] CHAPELLE O,HAFFNER P,VAPNIK V N.Support vector machines for histogram-based image classification[J].IEEE Transactions on Neural Networks,1999,10(5):1055-1064.
[3] BOSCH A,ZISSERMAN A,MUÑOZ X.Image classification using random forests and ferns[C]//2007 IEEE 11th International Conference on Computer Vision,2007.
[4] VIOLA P,JONES M.Rapid object detection using a boosted cascade of simple features[C]//2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2001.
[5] FELZENSZWALB P F,GIRSHICK R B,MCALLESTER D,et al.Object detection with discriminatively trained part-based models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(9):1627-1645.
[6] PINHEIRO P O,LIN T Y,COLLOBERT R,et al.Learning to refine object segments[C]//14th European Conference on Computer Vision,ECCV,2016:75-91.
[7] NOH H,HONG S,HAN B.Learning deconvolution network for semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition,2015:1520-1528.
[8] 張晓,林川,王蕤兴.轮廓检测深度学习模型的多尺度特征解码网络[J].广西科技大学学报,2021,32(3):60-66.
[9] XIE S,TU Z.Holistically-nested edge detection[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV),2015 :1395-1403
[10] SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[J].Computer Vision and Pattern Recognition,2014.arXiv:1409.1556.
[11] LIU Y,CHENG M M,HU X W,et al.Richer convolutional features for edge detection[C]//IEEE Conference on Computer Vision and Pattern Recognition,2017:5872-5881.
[12] XU D,OUYANG W L,ALAMEDA-PINEDA X,et al.Learning deep structured multi-scale features using attention-gated CRFs for contour prediction[C]//31st Annual Conference on Neural Information Processing Systems,2017.
[13] WANG Y P,ZHAO X H,HUANG K Q.Deep crisp boundaries[C]//IEEE Conference on Computer Vision and Pattern Recognition,2017:3892-3900.
[14] LIN C,CUI L H,LI F Z,et al.Lateral refinement network for contour detection[J].Neurocomputing,2020,409:361-371.
[15] CAO Y J,LIN C,LI Y J.Learning crisp boundaries using deep refinement network and adaptive weighting loss[J]. IEEE Transactions on Multimedia,2021,23:761-771.
[16] DESIMONE R,SCHEIN S J,MORAN J,et al.Contour,color and shape analysis beyond the striate cortex[J].Vision Research,1985,25(3):441-452.
[17] ENGEL S A,RUMELHART D E,WANDELL B A,et al.fMRI of human visual cortex[J].Nature,1994,369:525-525.
[18] KANDEL E R,SCHWARTZ J H,JESSELL T M,et al.Principles of neural science[M].5th ed.New York:McGraw-Hill Medical,2012.
[19] ARBELAEZ P,MAIRE M,FOWLKES C,et al.Contour detection and hierarchical image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(5):898-916.
[20] SILBERMAN N,HOIEM D,KOHLI P,et al.Indoor segmentation and support inference from RGBD images[C]//12th European Conference on Computer Vision,2012 :746-760.
[21] LIN T Y,DOLLÁR P,GIRSHICK R,et al.Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:2117-2125.
[22] GUPTA S,GIRSHICK R,ARBELÁEZ P,et al.Learning rich features from RGB-D images for object detection and segmentation[C]//Proceedings of 13th European Conference on Computer Vision,2014.
[23] CANNY J.A computational approach to edge detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1986,8(6):679-698.
[24] YANG K F,GAO S B,GUO C F,et al.Boundary detection using double-opponency and spatial sparseness constraint[J].IEEE Transactions on Image Processing,2015,24(8):2565-2578.
[25] MARTIN D R,FOWLKES C C,MALIK J.Learning to detect natural image boundaries using local brightness,color,and texture cues[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(5):530-549.
[26] SHEN W,WANG X G,WANG Y,et al.DeepContour:a deep convolutional feature learned by positive-sharing loss for contour detection[C]//IEEE Conference on Computer Vision and Pattern Recognition,2015:3982-3991.
[27] BERTASIUS G,SHI J B,TORRESANI L. DeepEdge:a multi-scale bifurcated deep network for top-down contour detection[C]//IEEE Conference on Computer Vision and Pattern Recognition,2015:4380-4389.
[28] XIE S N,TU Z W.Holistically-nested edge detection[J].International Journal of Computer Vision,2017,125:3-18.
[29] LIU Y,CHENG M M,HU X W,et al.Richer convolutional features for edge detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,41(8):1939-1946.
[30] DOLLÁR P,ZITNICK C L.Fast edge detection using structured forests[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(8):1558-1570.
[31] KOKKINOS I.Pushing the boundaries of boundary detection using deep learning[C]//International Conference on Learning Representations,2016.
[32] HALLMAN S,FOWLKES C C.Oriented edge forests for boundary detection[C]//IEEE Conference on Computer Vision and Pattern Recognition,2015:1732-1740.
[33] DENG R X,SHEN C H,LIU S J,et al.Learning to predict crisp boundaries[C]//Proceedings of the European Conference on Computer Vision,2018:562-578.
[34] HE J Z,ZHANG S L,YANG M,et al.Bi-directional cascade network for perceptual edge detection[C]//32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019.
An edge detection network simulating the front-end vision mechanism of "what" pathway
PAN Shenghui, WANG Ruixing, LIN Chuan*
(School of Electrical, Electronic and Computer Science, Guangxi University of Science and Technology,
Liuzhou 545006, China)
Abstract: Edge detection is a key step in image processing. In recent years, edge detection has built an encoding-decoding network based on Convolutional Neural Networks(CNNs), and has achieved good results. Among them, the coding network is usually built based on classic networks such as VGG16, and researchers more focus on the design of the decoding network. Considering that the existing coding network has limited ability to extract features and ignores the complex information flow between neurons, this study simulates the biological vision mechanism of the retina, the lateral geniculate body(LGN), and the front end of the ventral pathway("what" pathway), including V1, V2, and V4, to build a new encoding network and decoding network. In this paper, the encoding network simulates the information transfer mechanism of the retina-LGN-V1-V2 to fully extract the feature information in the image; the decoding network simulates the information integration function of the V4 area, and the adjacent fusion module is designed to integrate the feature prediction of the encoding network to realize the full integration of feature information. This neural network model has performed a large number of experiments on the BSDS500 dataset and NYUD-V2 dataset, and the results have been significantly improved compared with competitors in recent years. Through comparative experiments, the F value(ODS)of the encoding-decoding method built in this paper is 0.820, which is about 0.49% higher than that of LRCNet.
Key words: edge detection; biological vision; encoding-decoding network; feature extraction; conventional neural networks(CNNs)
(責任编辑:黎 娅)
