融合信息熵的TextRank 关键词抽取方法*
2022-04-07于腊梅杨良斌
于腊梅 杨良斌
(国际关系学院信息科技学院 北京 100091)
1 引言
随着移动互联网的发展,信息大爆炸式的增长,难以从纷繁复杂的文章中精准获取所需内容,关键词可以帮助人们快速理解文章的主旨、把握文章的主体脉络。关键词抽取技术是在文章中抽取若干具有实际意义且有代表性的词语或词组,以便快速获取文章主旨的重要方法,其在文献检索、自动摘要、文本聚类和文本分类等方面都有重要应用。关键词抽取主要分为如下三个步骤:1)文本预处理,包括分词、标注词性、去除停用词。2)获取待选关键词列表,一般情况下,只有具有实际意义的名词、形容词、动词可以作为关键词,其中形容词一般作为英文文章的关键词,动词一般作为中文文章的关键词。3)得到关键词,通过调节权重等手段给2)中获取的待选关键词打分、排序,根据实际需求,截取分数最高的N个关键词。
关键词的抽取既可以仅根据文章内容和结构特征实现,也可以通过大量训练语料构建模型实现,由于前者不需要大量的训练,更为简单有效,因此更受欢迎,最具有代表性的是TextRank[1]算法。
TextRank是基于分词的一种关键词提取算法,而分词本身的不准确会影响最终的关键词提取准确率。本文基于信息熵可以发现文本中聚合度很高的新词,结合TextRank算法就可以提高提取文本关键词的准确度。
2 相关工作
中文关键词抽取按照是否标记语料分类可以分为有监督关键词抽取和无监督关键词抽取两种。很多研究者把有监督关键词抽取看做二分类问题[2~3],需要预先人工标注文档的关键词,然后判断文档中的词是否为关键词,人工成本较高。也有很多研究者从事无监督关键词抽取研究。
现在较为常见的无监督关键词抽取分为如下三种:基于TF-IDF[4~7]词频统计的关键词抽取、基于LDA[8~10]主题的关键词抽取、基于词图的关键词抽取。其中,基于TF-IDF 的词频统计关键词抽取没有考虑到低频但重要的词语,并且忽略了词汇间以及词汇与主题间的关系,在短文本关键词抽取领域效果不佳;基于LDA 主题的关键词抽取需要通过大量的语料训练获得“文档-主题”和“主题-词汇”的概率矩阵,关键词抽取效果与语料中主题的分布强相关。孙明珠等[11]提出利用LDA 对语料做主题建模,获得候选关键词的主题词分布和语料主题分布,结合候选关键词主题分布计算词图各节点权重,获得“文档-主题”和“主题-词汇”作为随机跳转概率以构建新的概率转移矩阵;基于词图的关键词抽取以TextRank 算法为代表,由于TextRank算法构建词图时没有考虑权重,因此很多研究者通过加权提高关键词抽取的准确度。夏天[12]提出词语位置加权,综合考虑词语的覆盖影响力、位置影响力和频度影响力三个方面构建候选关键词概率转移矩阵,结合抽税机制改善关键词抽取结果。夏天[13]后又提出词向量聚类加权,先使用Word2Vec模型训练文本获得词向量并聚类,然后依据词向量的分布情况对TextRank词图节点非均匀加权,获得了较好的关键词抽取效果。刘竹辰等[14]提出利用TextRank构建候选关键词词图,结合文档写作中词位置分布情况构建概率转移矩阵,迭代计算候选关键词得分,取得分高的N个关键词。
上述关键词抽取方法都注重改进关键词抽取的步骤2),获取待选关键词列表与步骤3)待选关键词打分、排序,忽视了步骤1)文本预处理,但是实际上步骤1)才是关键词抽取的基础,当语料中出现新词作为关键词时,上述方法就束手无策。本文在分词前,先用信息熵的方式提取文章的关键新词,加入到分词字典中,让分词器能自主识别出新词,以增强文章关键词提取的准确性。
3 研究方法
TextRank 算法可以看做PageRank[15]算法的升级版。PageRank 最初是由谷歌的两位创始人佩奇和布林借鉴学术界评判论文重要性的方法提出用同样的方法判断网页的重要性,因此PageRank 算法的核心思想就产生了:若多个网页链接到同一个网页,则该网页较为重要,PageRank 值相对较高;若PageRank 值高的网页链接到一个其他网页,则被链接到的网页的PageRank 值也会相应提高。同样地,用PageRank 算法的思想来解释TextRank 算法的核心思想,若某词汇出现在很多词汇之后,则该词汇较为重要,TextRank 值相对较高;TextRank值高的词汇后面接着的一个词汇的TextRank 值也会相应提高。
3.1 TextRank算法提取关键词主要步骤
根据TextRank算法提取关键词的基本思想,提取一篇语料的关键词,首先需要对语料分词,然后把每个词语当做无向词图的节点,最后计算出词语的权重并取分数最高的N 个关键词。其具体步骤描述如下。
1)对给定的语料T进行分词,即T=[w1,w2,…,wn];
2)去除T 中的停用词、标注词性并保留重要词性词,如名词、动词,即V=[w1,w2,…,wm];
3)构建候选关键词图G=(V,E),其中V 为节点集,是步骤2)中得到的候选关键词的集合,E⊆V×V,对关键词图中的任意一个节点vi,j∈V,vi,j+1∈V,有 <vi,j,vi,j+1>∈E。 令:In(vi)=「vj|<vj,vi>∈E」;Out(vi)=「vj|<vi,vj>∈E」。In(vi)代表指向节点vi的节点的集合,Out(vi)代表节点vi指向的节点的集合。用其中ωji表示节点vi指向节点vj所在边的权重,可以理解为两个节点之间的边连接的重要程度,则节点vi的分数WS(vi)的计算方法,同时也是TextRank 算法的核心公式,如式(1)如下:
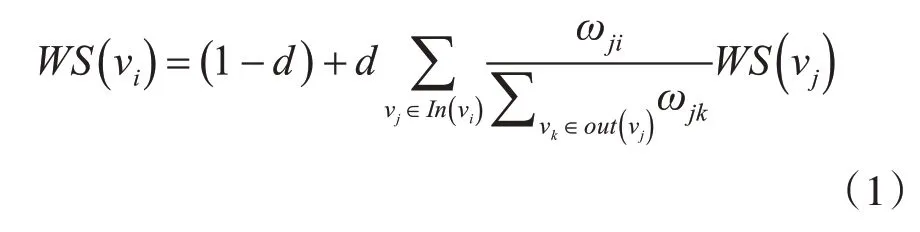
可以看出,步骤1)对给定的语料T进行分词是TextRank算法提取关键词的基础,作者将把信息熵加入TextRank算法的分词器,使分词器可以识别新词以改善分词效果,完成关键词抽取。
3.2 融合信息熵分词
1948 年香农提出“信息熵”,它是信息论中的一个重要概念,用来描述信息的不确定度,其计算过程如式(2)所示,其中w表示某事件,P(x)表示事件发生的概率。
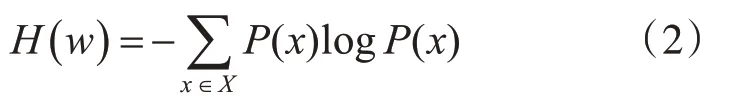
根据式(2),信息熵大小与事件可能出现的结果数量有关,在概率均等的情况下,存在的可能越多,信息熵越大。而一篇语料中的关键词必定具备这样的特点,即能够与之匹配的词语有很多,根据香农信息熵的公式给出一个词语信息熵的计算公式,如式(3)所示,其中w表示某词语,p 表示词语左右不同词语的数量。

例如,若在某篇语料中出现三次X W Y 组合,一次M W N 组合,则w左侧的信息熵H( )w左=表示X 在四次中出现三次,表示M 在四次中出现一次。若在某篇语料中出现三次X W Y组合,一次M W Y组合,则w左侧的信息熵不变,而右侧的信息熵H(w右)= -1 log 1=0。
对语料中去除停用词后剩下的词语分别计算其左右信息熵,若某个词语的左右信息熵都很大,则此词大概率是关键词。进一步,若某个词语的左侧信息熵很大,右侧信息熵很小,而该词语右侧词语的左侧信息熵很小,右侧信息熵很大,则可以把该词语及其右侧词语的整体作为一个关键词,具体描述为M X Y N 型组合,X 和Y 常常共同出现,而M和N 不定,故可以把X 和Y 组合起来看做一个新的关键词。譬如,“张三向李四安利了一款防晒霜”,其中的“安利”本是一个公司的品牌名称,后因其“安利式销售”不厌其烦等特点慢慢演变成为最近网络流行的词语,意为推荐。
如下给出作者所提修改TextRank 算法分词器部分核心代码的伪代码。
算法TextRank算法融合信息熵的分词器部分伪代码
Input:语料
Output:关键词候选列表
1:function GetKeywordList(article)
2:nodeTree ←[]
3:mutualInfo ←search_bi(nodeTree)
4:leftRightEntropy ←search_leftRight
5:combination ←calculateCombinedWordScore
6:TopN ←sorted(combination)
7:return TopN
8:end function
4 实验
4.1 实验环境
作者实验的运行环境是Inter Core i7,内存是16GB,操作系统是Mac OS,编程环境是Python3.5,算法的实验程序采用TextRank4zh 开源代码,中文分词使用常用的jieba分词代码库。
4.2 准备实验数据
目前被广大研究者认可的常见语料集主要有中科院自动化所的中英文新闻语料库、各版本的搜狗中文新闻语料库、南方周末网站语料库等,作者在各个语料库中各选取一篇语料,对比后认为自带关键词的南方周末网站语料库较为适合做关键词提取,故选取文献[10]中的数据集做数据来源。由于作者着眼于新词发现的关键词提取,故诚邀了五名实验室成员对语料进行人工核查,遴选出具有如下标准的语料1000 篇左右:1)关键词个数3 个~5个。2)语料文字数量在300 个~700 个。3)关键词需在语料中出现且与主题相关。4)10%以上语料的关键词包含新词。
4.3 实验结果及其分析
作者选用TF-IDF 算法、TextRank 算法与本文的融合信息熵的TextRank 算法En-TextRank 对关键词抽取结果做对比,目前较为广大研究者接受和认可的判断关键词抽取算法的指标为准确率P、召回率R、F值,它们的计算公式如式(4)~(6)所示:

三种算法在抽取3个和5个关键词时上述三个指标的表现如表1所示。
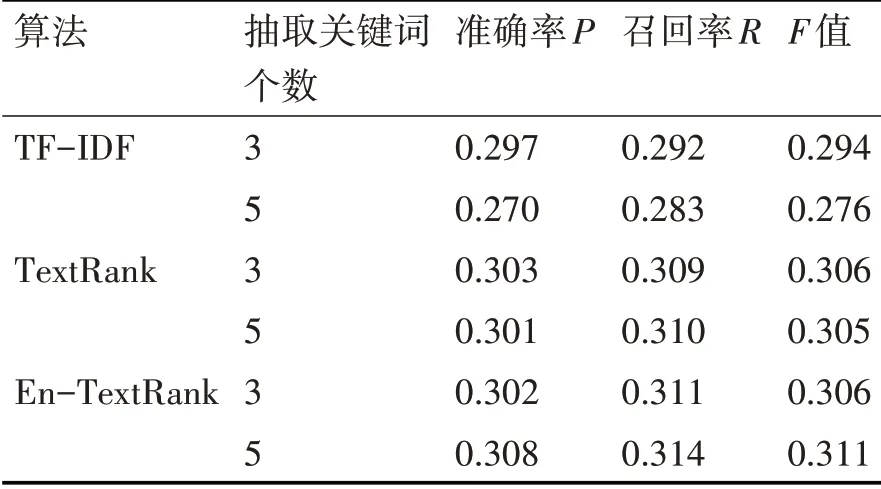
表1 3种算法准确率、召回率、F值对比
针对上表结果,分析得出如下结论。
1)TF-IDF 算法抽取关键词结果要略逊色于TextRank和En-TextRank算法。
2)TextRank算法抽取关键词结果较为平稳。
3)由于En-TextRank 算法着眼于新词发现,抽取包含新词的语料中的关键词时准确率并无明显提升。
为展示出En-TextRank 算法在抽取包含新词的语料的关键词的优势,表2以27号文档为例给出TextRank 算法与En-TextRank 算法抽取关键词结果。

表2 TextRank、En-TextRank算法抽取关键词结果
从表2可以看出En-TextRank算法在抽取关键词时更善于发现新词,“株式会社”指向广泛,而“三井株式会社”是有具体指向的,“海事法院”也比“法院”更具象。南方周末标注的关键词中不包含“海事法院”,但在认真研读该篇语料后研究人员普遍认为“海事法院”也应当作为关键词。
综上所述,En-TextRank 算法在抽取包含新词的语料的关键词时较传统的TextRank 算法更具优势,但是在发现新词方面还有可改进之处,譬如,表2 中的“三井株式会社”,虽然要比“株式会社”具象,但是未抽取出“商船三井株式会社”,这也是作者后续研究的重点。
5 结语
现如今的互联网信息十分发达,各种文化不断碰撞,活跃在网络社区的网民数量日益攀升,造新词的速度、数量也随之加快,因此抽取关键词的算法在抽取新词方面的研究必须要与时俱进。实验结果显示,En-TextRank 算法在抽取包含新词的语料的关键词方面有一定贡献,但在准确性方面还有待提升,因此,在后续研究中,作者将着眼于提升包含新词语料关键词抽取的准确性,同时,也希望更多的研究者投身于此类研究。
