一种基于Hadoop 的Apriori 改进算法*
2022-04-07宣正邦黄树成
宣正邦 黄树成 王 逊
(江苏科技大学 镇江 212003)
1 引言
随着数据时代的到来,我们的生活方式也随着发生天翻地覆的变化,各行各业都会产生数亿级别的数据量,这些数据中隐含着重要知识,如何挖掘和利用这些知识具有重要意义。结合当前海量数据的环境对Apriori 算法进行改进并与时下流行的Hadoop 云计算平台相结合,设计出一个有效的算法,可以快速有效地挖掘大数据,提取重要知识。
2 Hadoop平台的设计
Hadoop 平台支持在服务器集群之间进行分布式处理,可以从集群中的单个服务器扩展到数千个服务器。Hadoop 平台现已在各研究和实践领域得到广泛应用,其中包括社交网络、生物信息学和商业智能化等方面。Hadoop 平台最主要的两大核心模块分别为HDFS 分布式文件系统和MapReduce框架。
2.1 HDFS分布式文件系统
在Hadoop 架构中,HDFS 是一个负责在集群中多个节点之间进行可靠地存储并复制数据的模块。HDFS被设计的初衷是能够在廉价机器上部署分布式文件系统,它的优势和特点能够为我们提供高吞吐量的数据访问、高容错性能以及安全保障等。
2.2 MapReduce框架
MapReduce 是由Google 公司开发的分布式编程框架,它是Hadoop 平台最重要的核心模块之一。MapReduce具体执行步骤如下:
1)文件输入并将其划分为n 个大小在16MB-64MB 之间的片段数据,将这些划分好的数据分发给Hadoop 集群中各个计算节点。管理机主程序给计算节点分发所需要执行的Map 或Reduce作业,并进行状态监控,降低容错并提供决策依据给任务调度。
2)工作机程序接受分配任务,并读取有关任务数据和格式化处理,将键值对
3)用函数分类中间结果写入本地磁盘,管理机主程序获取这些中间结果的存储路径并将路径信息分配给工作机程序。工作机程序执行Reduce 工作并在得到路径信息之后,访问各存储中间键值对节点缓冲区,并逐一读取其数据,完成中间结果的整合和排序任务。此任务结束后,Reduce 会把最终结果输入并存储在文件里。
3 Apriori算法分析
3.1 Apriori算法简述
Apriori 算法通过逐层搜索的迭代过程来挖掘出数据之间的关联规则,它通过限制生成候选项来挖掘频繁项集,在两个重要集合(频繁项集与候选项集)之间交替进行。第一个是从先前迭代的频繁项集中生成候选项集,第二个是扫描数据库针对所有事务对候选项进行计数。在第k 次迭代(k≥2)中,从k-1 频繁项集Ck-1生成候选k 项集Ck,然后针对Ck候选项集剪枝那些不满足最小支持度的项集,如果Ck-1中不存在任何k-1 个子集,则可以从Ck中删除所有Ck项集。
3.2 Apriori算法缺点
传统Apriori 算法在如今数亿网民产生的数据量下,它的不足之处显而易见:第一,Apriori算法只能对单一事务数据进行分析,效率低下;第二,算法在迭代过程中频繁扫描数据库,耗时长;第三,算法候选项对比工作量大,并且算法自身产生的数据内存也会导致系统I/O过于负载,效率得不到保证。
4 Apriori算法改进
对于Apriori算法的不足之处进行如下改进:
1)降低算法对数据库的遍历次数。通过减少相应数据库扫描,将数据库遍历分为可变多阶段扫描。原先每次扫描数据库之后将会产生一个候选项集Ck,多阶段扫描则在数据扫描的前后两阶段之间同时产生Ck,Ck+1…,C(k+m-1)n(其中n为可变值)个候选项集。
2)减少算法在连接步时的对比次数。Apriori算法中Ck-1通过自连接产生候选项集Ck,对于Ck-1随着迭代次数的不断增加其规模也随之变大,而对于候选项集Ck所需要的自连接次数可能比前一次次数更多。让Ck-1取消自连接过程,转变成Ck-1与J1连接生成新的Ck。这时不需要Ck-1的每一项进行两两比较,而是用Ck-1最后一项对J1每一项进行大小对比,大幅度降低对比工作以提高运行效率。
5 实验结果分析
5.1 实验数据
本次实验数据为MSD 音乐数据网站所提供,这里提取其站内114 万条音乐播放记录,涉及歌曲989 首,并通过实验所需要的事务数据格式,按照相同用户播放不同曲目合并为一条事务,共计生成88256 条事务数,并将同一歌曲名称替换成同一数字形式(计1~989)。
5.2 实验分析与讨论
实验1:采取四种不同运行方式的对照实验,对改进算法的完成时间进行验证。四种方法分别为:原Apriori算法单机运行、原Apriori算法Hadoop平台运行、改进Apriori 算法单机运行、改进Apriori算法Hadoop 平台运行。其中最小支持度计数、最小置信度数值在四种方法中保持一致。首先,对四组实验对象进行单次数据库全局扫描进行计时。在单机上算法改进前后对全局数据库单次扫描时间为7.6s,在Hadoop集群下算法改进前后单次全局数据扫描时间为2.8s(算法的改进对数据库一次全局扫描时间并没有受到影响)。在数据库一次全局扫描时间消耗上,Hadoop 平台极大的利用它对数据库分块处理能力,多个计算节点被平均分配任务,扫描时间对比单机扫描时间下降很多,而单机工作则承受全部数据库扫描的压力,在这种程度上算法效率提高不少,也是在本实验中第一次展露出Hadoop 集群对大量数据处理的优势。实验1 中四种方法最终完成时间如图1所示。
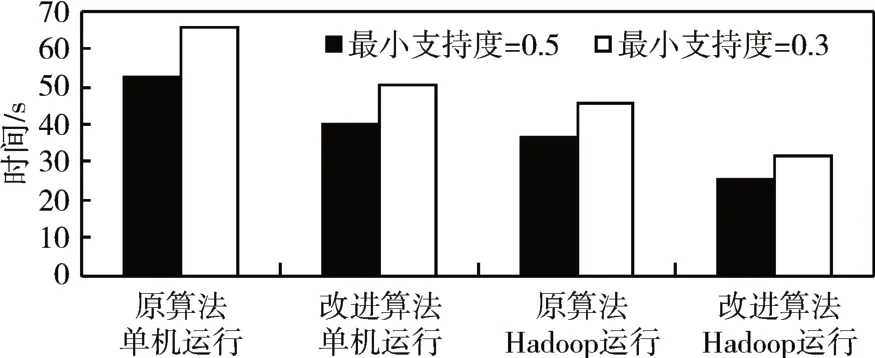
图1 四种方法完成时间图
本组实验通过设置最小支持度分别为0.5、0.3来分别对四种实验方式进行比较。从图1 中可直观了解到原算法与改进算法在Hadoop 集群与单台计算机中工作时间耗费都明显降低。当支持度越低的时候,频繁项集的项会更多,计算量程度也是随之加大,改进算法在Hadoop 集群上的时间消耗差也是比其他三种方法更小。
实验2:在单机运行环境下,对改进算法与原算法进行候选频繁项集消耗时间对比,实验中最小支持度设置为0.5。由于候选频繁项集C1是通过候选1 项集直接对比最小支持度计数产生而无须先进行自连接,这里便不与其他候选频繁项集消耗时间作对比。从C2开始各项集产生的消耗时间如图2所示。
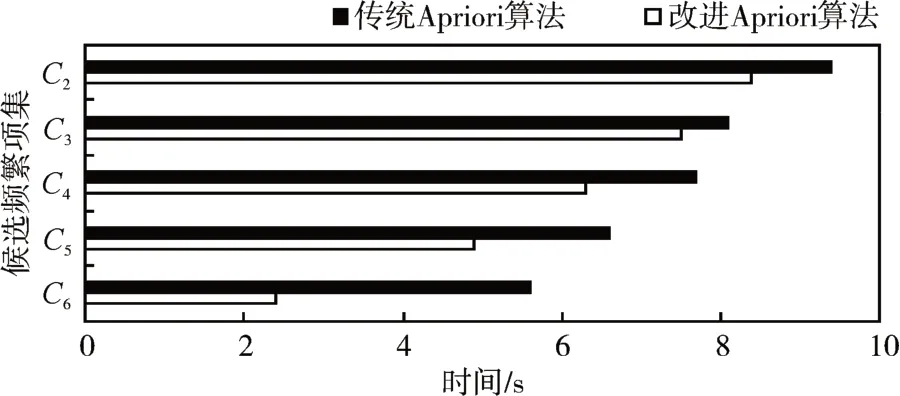
图2 候选频繁项集消耗时间图
通过实验数据对比,自连接过程在传统算法中伴随k 值增大而频繁候选项集的产生时间逐渐递减,但随着迭代不断进行K 值变大之后,(k-2)项的对比次数也增多,各项集之间消耗时间下降量变化并不显著。改进后算法的连接方法不需要再进行自连接过程,在对比时只用频繁1 项集各项和频繁k 项集的末尾项比较大小便可以生成k+1 频繁项集。在时间消耗上,k 值变大时节省时间优势更加显著。
实验3:在Hadoop 平台运行环境下,保持最小支持度不变的条件下进行三组对照实验。第一组:对1 个候选项集生成后遍历数据库进行最小支持度对比并剪枝的消耗时间计时。第二组:对每3 个候选项集生成后遍历数据库进行最小支持度对比并剪枝的消耗时间计时。第三组:在第一组与第二组的条件下,继续对频繁项集消耗时间进行计时对比。改变频繁项集的产生规则:C1由第1 次与第2次扫描数据库之间生成;C2由第2、3 次扫描数据库之间生成;C3由第3、4 次扫描数据库之间生成;C4、C5在第4、5 次扫描数据库之间生成;C6、C7、C8在第5、6 次扫描数据库之间生成……以此类推。三组实验对迭代次数更改后生成各频繁项集所消耗时间具体如下:
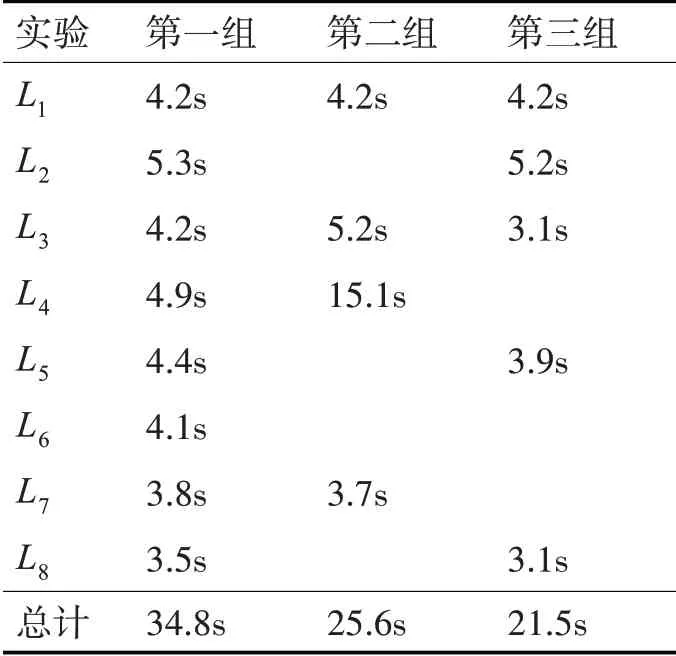
表1 实验对比结果表
由上表三组数据对比可知,在Ck-1和L1连接生成频繁Ck项集的迭代中,当k从1开始较小的前几项中,因C1项数生产量过大,对数据库进行频繁扫描再通过统计局部候选项集计数并进行全局剪枝任务,对去除算法中不需要的候选项集有很好的作用,也为后面迭代过程生成新的候选项集减少任务负担。随着迭代不断的进行,Ck的大小会随着k值变大而减小,但Ck的项数减少并没有减少相应扫描数据库所需时间,这时在两次数据库扫描之间提高候选集个数,平衡在各迭代过程中所需工作时间,以此达到提高算法效率的目的。
根据实验1、实验2、实验3的实验结果,将改进后Apriori算法移植到Hadoop 平台后的效率有显著提高。其次,对于本文改进的算法,通过可变多阶段扫描机制与改变自连接方式的方法对算法的工作效率提升也得以证明是有效的。
6 结语
Apriori算法虽然已经有几十年历史,但传统的运算模式无法适应当前大数据环境,本文将传统Apriori 算法不足之处进行改进,并与Hadoop 平台相结合,提出一种改进的知识提取算法,通过实验证明了此算法的优势。
